东昌府区网站建设公司网站受攻击
文章目录
- LLM 学习(一 序言)
- 知识点1:“Embedding” 在人工智能领域:
- 知识点2:Embedding 引入位置信息的原因
- 知识点3:在 Transformer 的 Decoder 翻译第 i 个单词时进行 Mask 第 i+1 个单词的操作
LLM 学习(一 序言)
1.序言
LLM学习 Transformer 结构大概,图片的视频链接
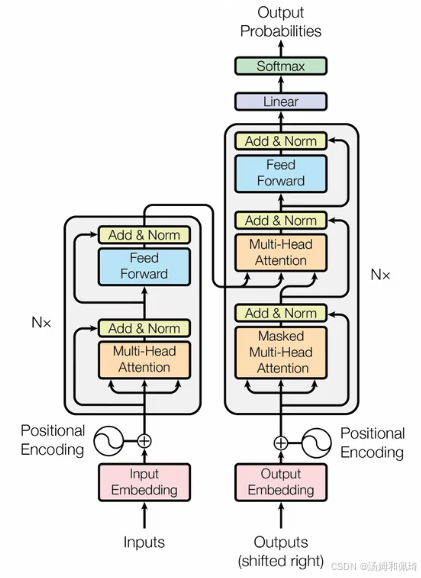
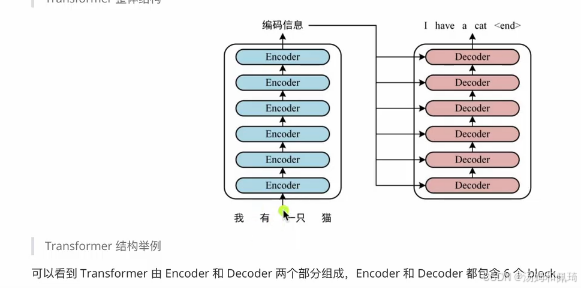
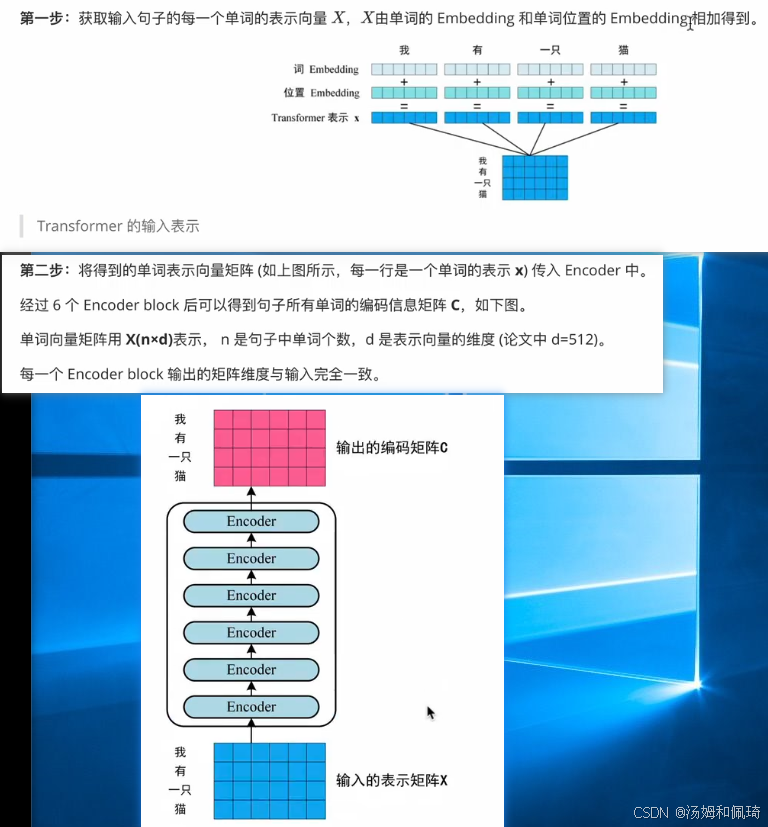

知识点补充:
知识点1:“Embedding” 在人工智能领域:
是一种 “向量化” 或 “向量表示” 的技术,核心是将各类数据映射为连续向量,以在向量空间中体现数据特征及相互关系。
- 机器学习:原理是把离散数据映射为连续向量,从而捕捉数据间潜在关系;通常使用神经网络中的 embedding 层,经训练得到数据的向量表示。该技术能提升模型性能,增强其泛化能力,还可降低计算成本。
- 自然语言处理(NLP):基于分布式假设,将文本转换为连续向量来捕捉语义信息。常采用词嵌入技术(如 word2vec)或复杂模型(如 Bidirectional Encoder Representations from Transformers,BERT,基于 Transformer 的双向编码器表示)学习文本表示,能够解决词汇鸿沟问题,为文本分类、情感分析、机器翻译等复杂 NLP 任务提供支持,助力文本语义理解。在该领域中,语义相近的单词在向量空间中的位置也相近。
- 图像领域:如 image embedding(图像嵌入),是将图像映射为向量,以便计算机更好地处理和理解图像信息,用于图像检索、分类等任务。
知识点2:Embedding 引入位置信息的原因
此外,在一些生成式 AI 工具(如 Stable Diffusion )的应用场景中,Embedding 可理解为提示词打包。通过引入特定的触发词,就能代表原本大量描述性提示词的含义,在文件体积小的情况下,引导生成符合预期的结果,还能用于生成特定动作、特征或画风 。
在 Transformer 等模型中,Embedding 需要引入位置信息主要有以下原因:
- 捕捉序列顺序:自然语言是一种具有顺序结构的信息,词语在句子中的位置不同,句子表达的含义也会不同,如 “我喜欢你” 和 “你喜欢我”。普通的词 Embedding 只是对词本身语义的表示,不包含位置信息 ,引入位置 Embedding 能让模型感知词语在序列中的位置,从而理解句子的正确语义和逻辑顺序。
- 解决模型局限性:Transformer 模型基于自注意力机制,这种机制本身在处理输入时平等对待每个位置的元素,没有内置的顺序信息。若不添加位置 Embedding,模型无法区分 “苹果被我吃了” 和 “我吃了苹果” 这样词相同但顺序不同的句子,位置 Embedding 能弥补这一缺陷,增强模型对序列结构的理解能力。
- 提升模型性能:对于机器翻译、文本生成等任务,准确把握序列顺序至关重要。位置 Embedding 帮助模型更好地学习长距离依赖关系和上下文信息,在处理长句子时,能让模型知道不同词语之间的相对位置,从而更准确地生成或理解文本,提升模型在各类自然语言处理任务中的表现。
知识点3:在 Transformer 的 Decoder 翻译第 i 个单词时进行 Mask 第 i+1 个单词的操作
- 符合翻译的自回归特性
Transformer 的 Decoder 部分是自回归模型,模拟人类翻译过程,即从左到右依次生成译文单词。在翻译第 i 个单词时,模型应该仅依据已经翻译出的 1 到 i-1 个单词以及 Encoder 传递过来的源语言编码信息进行预测,而不应该提前 “看到” 未来要生成的单词(第 i+1 个及之后的单词)。如果不进行 Mask 操作,模型就会利用到未来单词的信息,这与实际的翻译过程和自回归机制不符,也无法真实地学习到单词之间的依赖关系和正确的生成顺序。 - 防止模型信息泄露
在训练过程中,如果不将第 i+1 个及之后的单词 Mask 掉,模型在预测第 i 个单词时,会无意中获取到后续单词的信息,导致模型不是基于正确的上下文来学习和预测,从而产生信息泄露问题。通过 Mask 操作,能够强制模型只能利用当前已有的信息进行预测,让模型学习到如何根据已有的上文生成下一个合理的单词,提高模型对上下文信息的理解和利用能力,增强模型的泛化能力和鲁棒性,使其在实际翻译任务中表现得更好。