CVPR 2025 | 频率动态卷积FDConv,标准卷积的完美替代,即插即用,高效涨点!
1. 基本信息

-
标题: Frequency Dynamic Convolution for Dense Image Prediction
-
论文来源: https://arxiv.org/pdf/2503.18783
2. 核心创新点
-
揭示了传统动态卷积的频率冗余问题:通过频率分析发现,现有动态卷积方法虽参数量大,但其多组权重在频域响应上高度相似,导致适应性受限。
-
提出傅里叶不相交权重(FDW):在傅里叶域划分参数,以固定的参数预算生成大量频域多样化的权重,从根本上解决了参数冗余和频率单一的问题。
-
设计了两种精细化调制策略:引入核空间调制(KSM)和频带调制(FBM),分别在权重和特征层面实现更精细的动态调整,前者微调每个权重元素,后者实现空间可变的频率滤波。
-
实现了高效且广泛的适用性:FDConv以极小的参数增量(+3.6M)在多项任务上超越了参数量巨大(+65M~90M)的先前方法,并能无缝集成到ConvNets和Transformer等多种主流架构中。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/ccJosDLtn3ZIPxlJRHy4-w
https://mp.weixin.qq.com/s/ccJosDLtn3ZIPxlJRHy4-w
3. 方法详解
整体结构概述
Frequency Dynamic Convolution (FDConv) 是一种创新的动态卷积框架,旨在不增加额外参数成本的前提下,提升卷积核的频率适应性。其核心思想是在傅里叶域学习和构建权重,并引入多层次的调制机制。数据流首先通过傅里叶不相交权重(FDW)模块生成一组具有频率多样性的基础权重,接着,核空间调制(KSM)模块根据输入特征对这组权重进行元素级的精细调整,最后,频带调制(FBM)模块对特征/权重进行频带分解和空间自适应调制,从而实现最终的卷积输出。
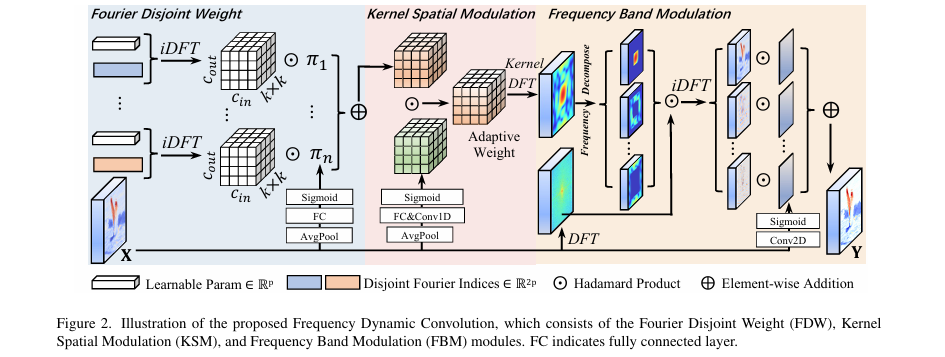
FDConv整体架构图
步骤分解
- 傅里叶不相交权重(Fourier Disjoint Weight, FDW)
-
核心思想: 在傅里叶域而非空间域学习卷积核参数,以固定参数预算生成多组频率特性各异的权重。
- 实现流程:
-
参数分组: 将总参数预算视为傅里叶域的谱系数,依据频率(傅里叶索引的L2范数)从低到高排序,并均匀划分为
n个互不相交的组(P₀, ..., Pₙ₋₁)。 -
傅里叶逆变换: 对每个参数组进行逆离散傅里叶变换(iDFT),将其从傅里叶域转换到空间域。对于第
i组,只有属于该组的傅里叶索引位置才有值,其余位置为零。
-
权重重组: 将变换后的空间域结果
Sᵢ裁剪并重组为标准卷积权重Wᵢ(维度为k×k×Cᵢₙ×Cₒᵤₜ)。由于每个Pᵢ对应一个独特的频带,生成的Wᵢ自然具有独特的频率响应。
-
-
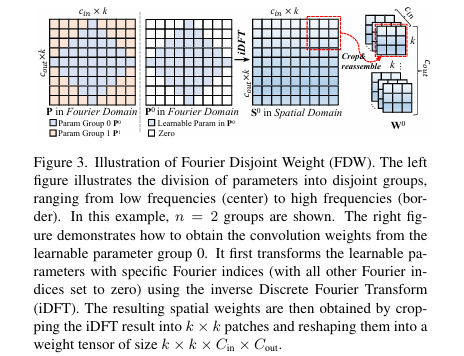
FDW 工作原理解析图
- 核空间调制(Kernel Spatial Modulation, KSM)
-
核心思想: 对生成的权重进行元素级的精细调整,以增强其对输入的适应能力。
- 实现流程:
-
双分支结构: 包含局部通道分支和全局通道分支。
-
局部通道分支: 使用轻量级的1D卷积捕获局部通道间的相互依赖关系,生成一个与权重维度完全相同的密集调制矩阵
α ∈ R^(k×k×Cᵢₙ×Cₒᵤₜ)。 -
全局通道分支: 使用全连接层捕获全局通道信息,生成三个维度上的稀疏调制向量(输入通道、输出通道和核空间维度),作为局部信息的补充。
-
融合调制: 融合两个分支的输出,对基础权重进行元素级别的乘法调制(Hadamard Product)。
-
-
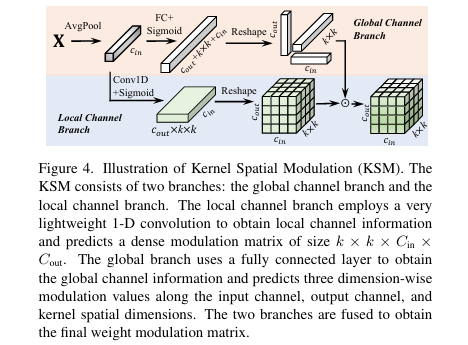
KSM 结构示意图
- 频带调制(Frequency Band Modulation, FBM)
-
核心思想: 将卷积操作分解到不同频带上,并对每个频带的响应进行空间自适应的调制,使模型能根据局部内容动态调整其频率滤波特性。
- 实现流程:
-
核/特征频率分解: 将卷积核
W或输入特征X通过傅里叶变换和二进制掩码Mᵦ分解为B个独立的频带Wᵦ或Xᵦ。
-
空间调制图生成: 对输入特征
X使用一个标准卷积层和Sigmoid函数,为每个频带b生成一个空间调制图Aᵦ。 -
动态频率滤波: 在实践中,为了效率,先将输入特征分解为多个频带
Xᵦ,然后用Aᵦ对其进行调制,最后将所有调制后的频带特征相加,与原始卷积核W进行一次卷积。
-
效果: 该模块能够根据图像不同区域的内容(如边界区域强调高频,平滑区域抑制高频),实现空间可变的频率响应。
-
-

FBM 模块的可视化效果
4. 即插即用模块作用
适用场景
- 密集预测任务:
-
目标检测 (Object Detection)
-
实例分割 (Instance Segmentation)
-
语义分割 (Semantic Segmentation)
-
- 基础视觉任务:
-
图像分类 (Image Classification)
-
- 架构集成:
-
可作为即插即用模块替换传统卷积层,适用于各类**卷积神经网络 (ConvNets)**,如 ResNet, ConvNeXt。
-
可替换**视觉Transformer (Vision Transformers)**中的
1x1卷积(即线性层),如 Swin-Transformer, Mask2Former, MaskDINO。
-
主要作用
-
模拟/替代能力: 替代标准卷积和现有动态卷积,提供更强的特征表达和输入自适应能力。
-
降低参数成本: 在达到甚至超越SOTA性能的同时,大幅降低由动态卷积引入的额外参数开销。例如,相比CondConv(+90M)和ODConv(+65.1M),FDConv仅增加3.6M参数。
-
增强模型性能: 通过提升权重的频率多样性和精细的动态调制,显著提升模型在各类视觉任务(尤其是分割和检测)上的准确率。
-
增强部署性与泛化性: 参数效率高,且能无缝集成到不同架构中,展示了其作为通用视觉模块的强大泛化能力和部署潜力。
总结
FDConv 是一个从傅里叶域视角出发,通过解耦频率和空间动态性,以极低参数成本实现高效、强大自适应能力的通用卷积算子。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/ccJosDLtn3ZIPxlJRHy4-w
https://mp.weixin.qq.com/s/ccJosDLtn3ZIPxlJRHy4-w
5. 即插即用模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd
import numpy as np
import matplotlib.pyplot as plt
from numpy.linalg import matrix_rank
from torch.utils.checkpoint import checkpoint
from mmcv.cnn import CONV_LAYERS
from torch import Tensor
import torch.nn.functional as F
import math
from timm.models.layers import trunc_normal_
import time
class StarReLU(nn.Module):"""StarReLU激活函数:增强对正特征的响应,提升特征表达能力公式:out = scale * (ReLU(x))² + bias核心逻辑:- ReLU保留有效正特征,平方项放大强响应特征- 可学习的scale和bias动态调整激活强度,适配不同任务参数:scale_value: 初始缩放因子(默认1.0)bias_value: 初始偏置(默认0.0)scale_learnable: 缩放因子是否可学习(默认True)bias_learnable: 偏置是否可学习(默认True)inplace: 是否原地操作(默认False,避免覆盖原始数据)输入:x (Tensor) - 任意形状特征张量输出:激活后特征张量(与输入形状一致)"""def __init__(self, scale_value=1.0, bias_value=0.0,scale_learnable=True, bias_learnable=True,mode=None, inplace=False):super().__init__()self.inplace = inplaceself.relu = nn.ReLU(inplace=inplace)# 定义可学习参数(或固定值)self.scale = nn.Parameter(scale_value * torch.ones(1), requires_grad=scale_learnable)self.bias = nn.Parameter(bias_value * torch.ones(1), requires_grad=bias_learnable)def forward(self, x):return self.scale * self.relu(x) ** 2 + self.biasclass KernelSpatialModulation_Global(nn.Module):"""全局核空间调制模块(KSM-Global)功能:基于全局特征统计,生成四类注意力权重,动态调整卷积核的通道、滤波器、空间位置及核选择核心逻辑:1. 全局平均池化提取特征统计,压缩空间冗余2. 1×1卷积+StarReLU构建轻量注意力生成器3. 针对卷积核不同维度(通道/滤波器/空间/核)生成适配权重参数:in_planes: 输入特征通道数out_planes: 输出特征通道数kernel_size: 卷积核尺寸(如3)groups: 分组卷积数(默认1,=in_planes时为深度可分离卷积)reduction: 通道压缩系数(默认0.0625=1/16,降低注意力计算量)kernel_num: 候选卷积核数量(默认4,通过注意力选择最优核)temp: 注意力温度系数(控制权重分布尖锐程度,默认1.0)ksm_only_kernel_att: 是否仅启用核注意力(默认False,全维度调制)act_type: 注意力激活函数(默认'sigmoid',可选'tanh'/'softmax')输入:x (Tensor) - [B, in_planes, H, W](通常为全局池化后的特征)输出:(channel_att, filter_att, spatial_att, kernel_att) - 四类注意力权重"""def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16,temp=1.0, kernel_temp=None, kernel_att_init='dyconv_as_extra', att_multi=2.0, ksm_only_kernel_att=False, att_grid=1, stride=1, spatial_freq_decompose=False,act_type='sigmoid'):super().__init__()self.act_type = act_typeself.kernel_size = kernel_sizeself.kernel_num = kernel_numself.temperature = tempself.kernel_temp = kernel_temp if kernel_temp is not None else tempself.ksm_only_kernel_att = ksm_only_kernel_attself.att_multi = att_multi # 注意力权重放大系数# 注意力通道数:取“输入通道×压缩系数”与“最小通道数”的最大值attention_channel = max(int(in_planes * reduction), min_channel)# 全局特征提取:平均池化+1×1卷积+批归一化+StarReLUself.avgpool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)self.bn = nn.BatchNorm2d(attention_channel)self.relu = StarReLU()# 1. 通道注意力:控制输入通道的重要性if ksm_only_kernel_att:self.func_channel = self.skip # 仅核注意力时,通道注意力失效(返回1.0)else:out_c = in_planes * 2 if (spatial_freq_decompose and kernel_size > 1) else in_planesself.channel_fc = nn.Conv2d(attention_channel, out_c, 1, bias=True)self.func_channel = self.get_channel_attention# 2. 滤波器注意力:控制输出通道(滤波器)的重要性if (in_planes == groups and in_planes == out_planes) or ksm_only_kernel_att:self.func_filter = self.skip # 深度可分离卷积时,滤波器注意力失效else:out_f = out_planes * 2 if spatial_freq_decompose else out_planesself.filter_fc = nn.Conv2d(attention_channel, out_f, 1, stride=stride, bias=True)self.func_filter = self.get_filter_attention