【大模型】DeepSeek-V3.2-Exp中的DSA稀疏注意力设计
DeepSeek的稀疏注意力机制DSA主要分为两个模块:1)Lighting Indexer;2)Fine-grained Token Selection。训练的策略很有讲究,采用了CPT(持续预训练)和RL训练。
DSA设计和模型架构
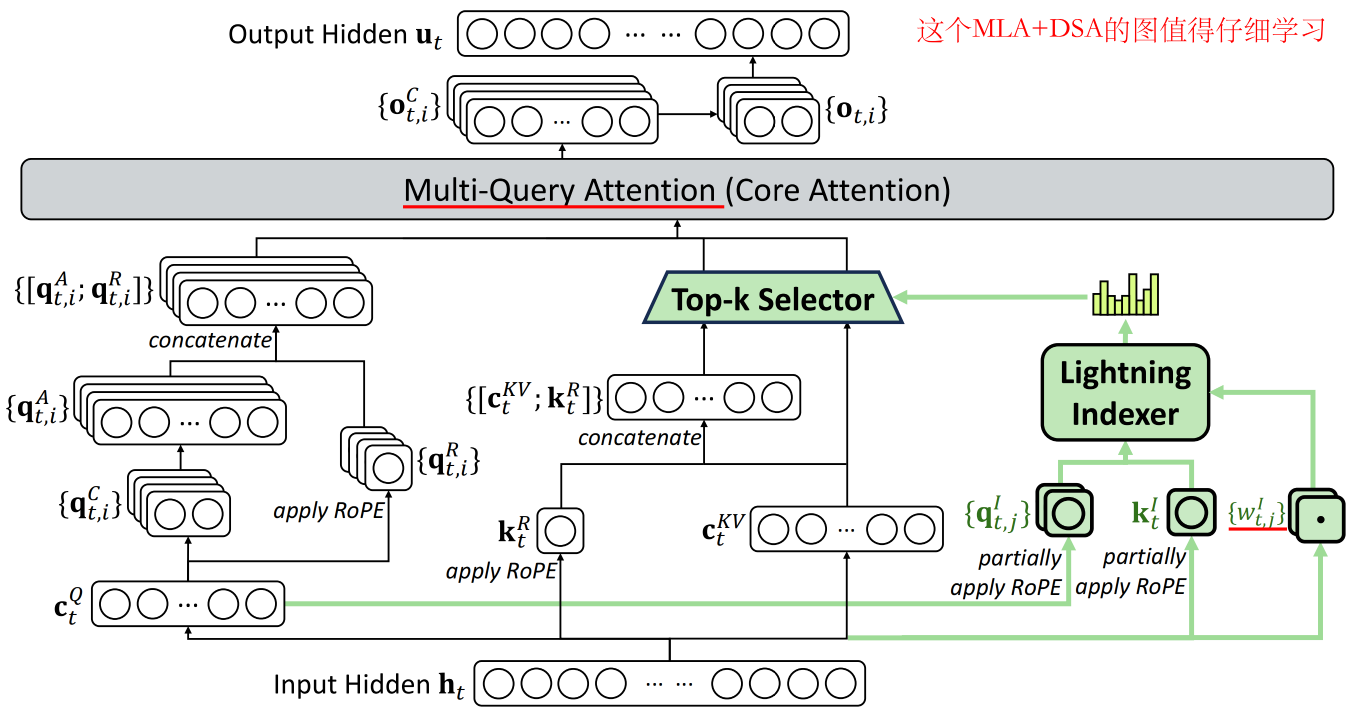
Lighting Indexer
通过dot product计算当前query和之前token key的注意力分数,然后过ReLU,再乘每个head的权重www,最后将head维度加起来,公式如下:
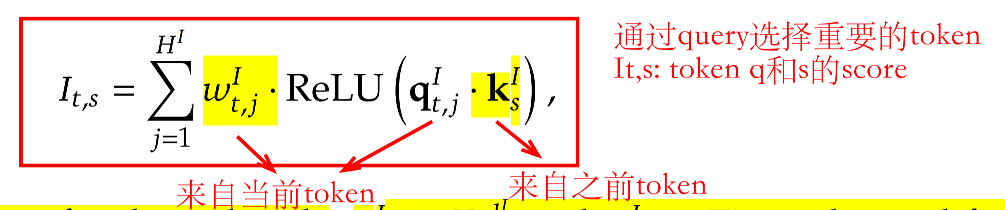
在计算dot product的时候,复杂度仍然是O(L2)O(L^2)O(L2)的,应该如何降低这部分的开销呢?
- FP8低精度实现Lighting Indexer的运算过程
- ReLU激活函数提高计算的吞吐率
- 只使用更少的Indexer Head,即HI<HH^I < HHI<H
Token Selection
直接用top-k选择注意力分数大的token,然后计算attention,公式如下:
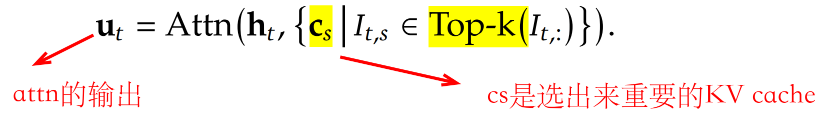
DSA结构:基于MLA,并采用MQA
训练策略
训练checkpoint起点:DeepSeek-V3.1-Terminus(dense attention)
Continued Pre-Training(CPT)
第一步:Dense Warm-up Stage(冷启动热身)
因为Lighting Indexer是全新组件,所以第一步是只训练Lighting Indexer,让indexer的输出分布尽可能接近原来的attention分布,公式如下:
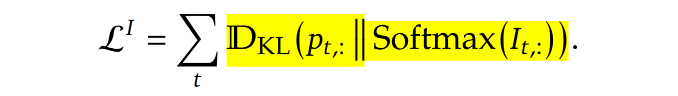
第二步:Sparse Training Stage(稀疏模式训练)
让整个模型适应稀疏attention的模式,需要同时训练模型和Indexer,公式如下:
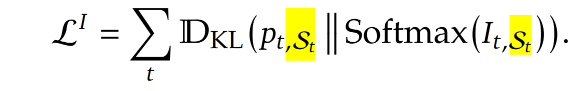
发现和第一步公式非常像,但是不同在于第二步只用了“重要token”的分布,以此让模型适应稀疏模式。
文章中还提到一点,indexer的输入是从计算图中剥离出来的,所以是单独优化indexer和模型部分。Indexer训练指来自LIL^ILI这个loss,而模型优化只来自语言建模的loss。
Post-training(后训练)
Specialist Distillation(专家蒸馏)
为每一个领域训练一个专家模型,然后生成训练数据(两种模式:带CoT和不带CoT),然后蒸馏到DeepSeek-V3.2-Exp中。
Mixed RL Training(单阶段混合训练)
用GRPO算法训练,但是摒弃“多阶段”训练策略(比如R1)。采用单阶段的混合RL训练策略,将所有目标融合在一起。 主要有三个目标:1)推理能力(逻辑推理);2)Agent能力(工具调用);3)人类偏好对齐。