Redis 集群分片算法
引入哨兵模式后,提高了系统的可用性,但由于哨兵节点不存储数据,不能缓解主从节点存储数据的压力,随着主节点与从节点的数据越来越多,最后会超出存储限制。
这时就需要引入 Redis 集群,即在系统中使用多台主节点与从节点共同存储数据,将一个主节点与若干从节点分为一组,每一组都存储一部分数据(分片),加起来就构成了数据的全部。
在上述的情况中,就涉及到将数据分成多个分片。下面介绍三种主流的分片方式。
哈希求余
由于 Redis 中的数据都是键值对结构,就可以根据其中的 key 计算哈希值,将这个值余上分片的数量,得到的结果就是需要存储在哪个分片中。
后续需要根据这个 key 取出数据时,也是先使用同样的算法计算哈希值,将得到结果余上分片的数量,就可以得到数据存储在哪个分片中。
比如,某个 key 计算出的哈希值是5,一共有3个分片,5 % 3 => 2,就是将数据存储在2号分片中。
但是上面的方式存在一定的问题,当该集群需要扩容时,就会有很大的数据搬运成本。

在扩容前,有三个分片,扩容后,有四个分片。当扩容后,只有3个 key 没有被搬运,剩下的21个 key 都需要搬运,当数据量变大时,搬运成本就会很大。
一致性哈希算法
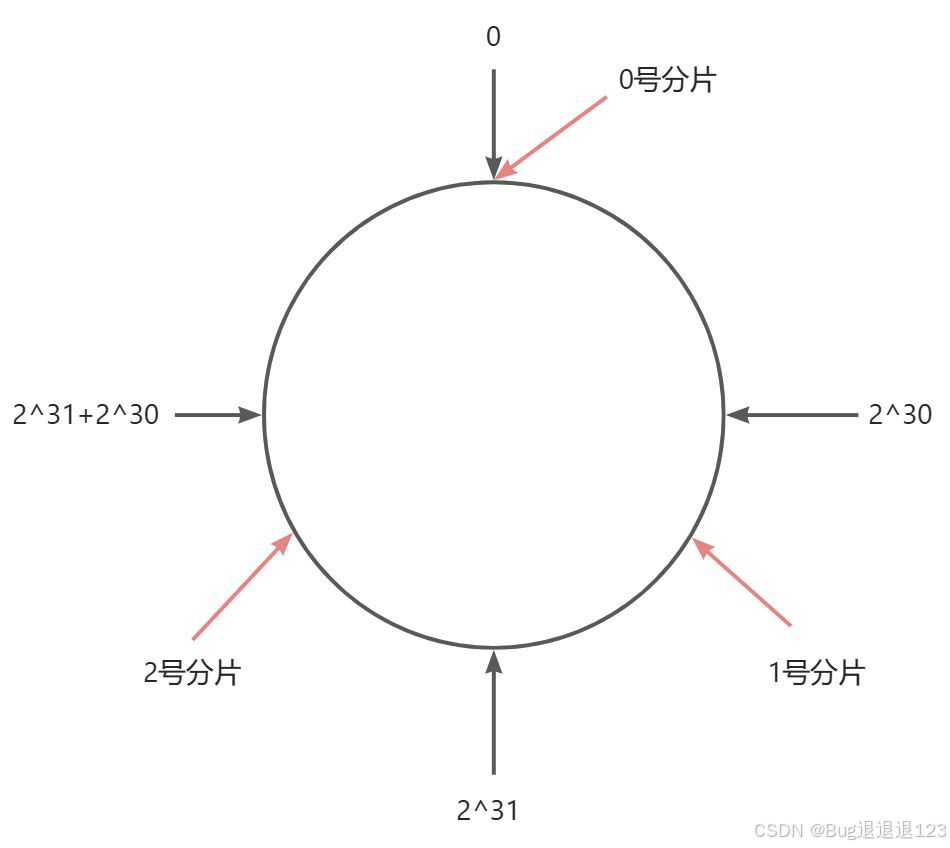
- 将 0 - 2 ^ 32 - 1 的数据空间,映射到一个圆上,数据按顺时针方向增长
- 现有三个分片,就将圆分成三个区域
- 现在有一个 key,