StrFormatByteSize 函数:从字节到可读大小的转换
trFormatByteSize 函数:从字节到可读大小的转换
在编程中,将字节大小转换为人类可读的格式是一个常见需求,本文将分析一个高效实用的 C++ 实现。
1. 函数概述与设计思路
在文件管理系统、网络传输监控等场景中,我们经常需要将原始的字节大小转换为如"KB"、"MB"这样的人类可读格式。原始字节数对用户来说缺乏直观性,而StrFormatByteSize函数正是为了解决这一问题而设计的。
这个函数的核心目标是:接收一个整数类型的字节大小,返回带合适单位的格式化字符串。例如,将1024字节转换为"1 KB",将1536字节转换为"1.5 MB"。
本文将分析的 C++ 实现版本采用了循环除法和查找表的方法,具有代码简洁、效率高的特点。与Windows API中的StrFormatByteSize函数相比,这个实现提供了更直观的控制逻辑和可定制性。
2. 代码解析与注释
以下是添加了详细中文注释的完整代码实现:
// 函数定义:将Int64类型的字节大小格式化为易读的字符串
// noexcept表示此函数不会抛出异常,适合性能敏感场景
ppp::string StrFormatByteSize(Int64 size) noexcept {// 定义单位名称数组,从字节到NB(目前最大单位)// 注意:单位按照1024进制递增,每个单位比前一个大1024倍static const char* aszByteUnitsNames[] = { "B", // 字节(Base)"KB", // 千字节(KiloByte)"MB", // 兆字节(MegaByte)"GB", // 吉字节(GigaByte)"TB", // 太字节(TeraByte)"PB", // 拍字节(PetaByte)"EB", // 艾字节(ExaByte)"ZB", // 泽字节(ZettaByte)"YB", // 尧字节(YottaByte)"DB", // 刀字节(DottaByte)"NB" // 诺字节(NonaByte)};// 使用long double确保除法运算的精度,llabs处理size可能为负数的情况long double d = llabs(size);unsigned int i = 0; // 单位索引,初始为0(字节单位)// 循环判断:当字节数大于1024且未达到最大单位时,继续转换// 最多支持到NB单位,避免无限循环while (i < 10 && d > 1024) {d /= 1024; // 每次除以1024,进位到更大的单位i++; // 单位索引递增,指向下一个更大的单位}// 创建字符数组缓冲区,用于存储格式化结果// 预留1000字符空间+1个空字符,确保足够容纳结果char sz[1000 + 1];// 使用snprintf安全格式化字符串,避免缓冲区溢出// %Lf表示输出long double类型,%s输出对应的单位名称snprintf(sz, 1000, "%Lf %s", d, aszByteUnitsNames[i]);return sz; // 返回格式化后的字符串
}
3. 算法流程详解
3.1 单位转换的核心逻辑
该函数的核心算法可以通过以下流程图直观展示:
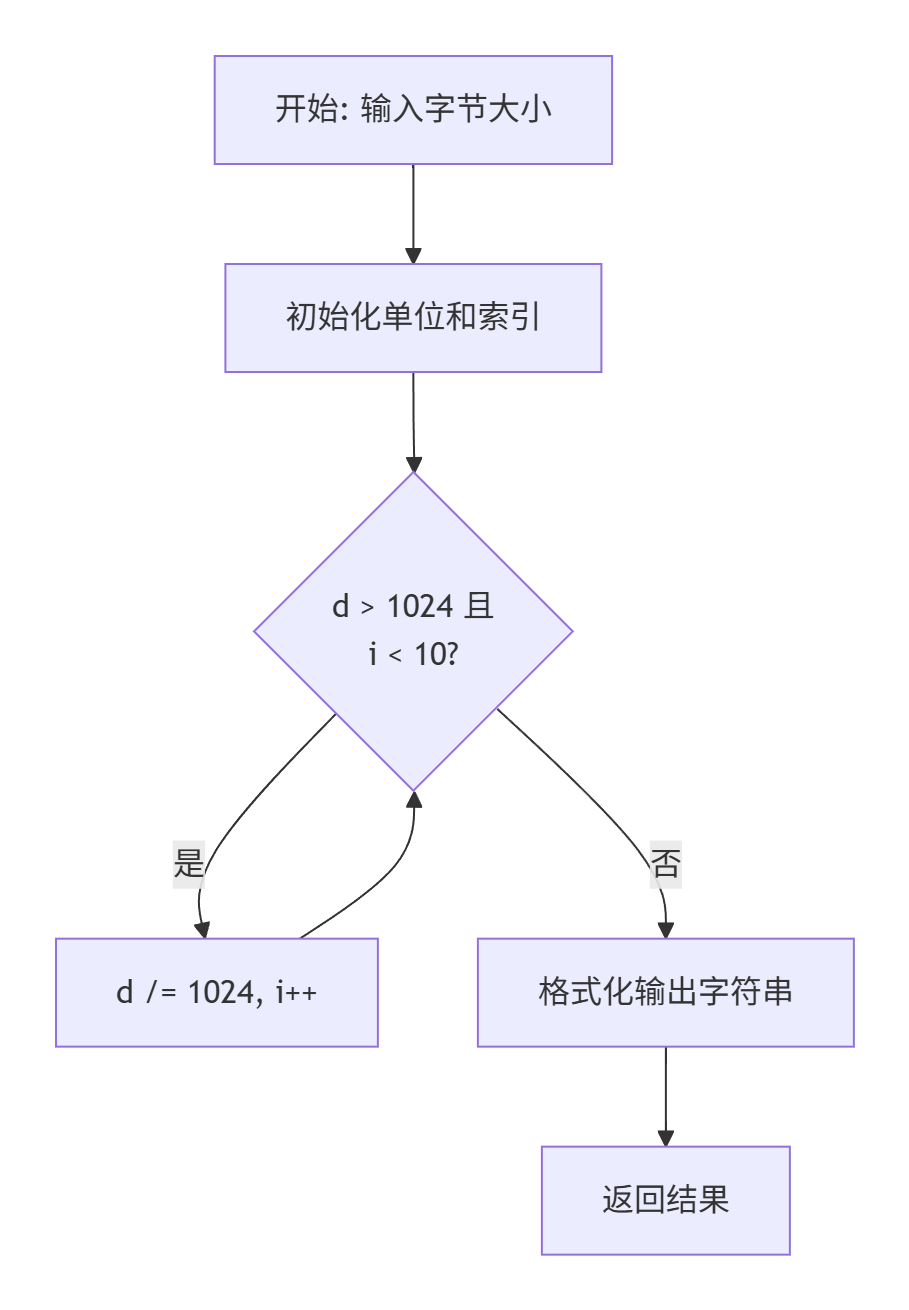
单位转换过程遵循二进制前缀标准(IEC标准),即每个单位都是前一个单位的1024倍。这与十进制前缀(1000倍关系)有所不同,在计算机科学中更为常用。
3.2 关键变量作用分析
d变量:使用long double类型确保高精度除法运算,llabs确保处理负数时不会出错i变量:作为单位数组的索引,通过循环递增选择最合适的单位- 单位数组:预定义的静态字符串数组,避免每次函数调用时重复创建
4. 函数执行示例分析
让我们通过几个具体例子来理解函数的执行过程:
示例1:小文件大小转换(500字节)
输入: size = 500
执行流程: d=500, i=0 → 500≤1024 → 不进入循环
输出: "500.000000 B"
示例2:典型文件大小转换(1.5MB)
输入: size = 1572864 (1.5×1024×1024)
执行流程: 初始: d=1572864, i=0第1次循环: d=1536, i=1 (KB)第2次循环: d=1.5, i=2 (MB) → 1.5≤1024 → 退出循环
输出: "1.500000 MB"
示例3:大文件大小转换(2.5TB)
输入: size = 2748779069440
执行流程: 经过多次循环直至TB单位
输出: "2.500000 TB"
5. 函数优势与局限性
5.1 设计优势
- 代码简洁高效:使用简单循环和查找表,算法时间复杂度为O(1)
- 缓冲区安全:使用
snprintf而非sprintf,防止缓冲区溢出 - 大数支持:支持从字节到NB的极大范围数值处理
- 异常安全:
noexcept关键字表明函数不会抛出异常
5.2 存在的局限性
- 精度控制不足:总是输出6位小数,可能显示多余尾随零
- 本地化缺失:单位名称使用英文,未考虑本地化需求
- 格式化固定:输出格式固定为"数值+空格+单位",缺乏灵活性
- 负数处理:使用
llabs会丢失原始数值的正负信息
6. 优化建议
基于上述分析,我们可以提出几种优化方案:
6.1 精度控制改进
// 改进的精度控制:移除多余尾随零
int precision = 2;
long double rounded = round(d * pow(10, precision)) / pow(10, precision);
6.2 增强格式化选项
可以借鉴其他实现中的优点,增加更多格式化参数:
// 支持空格控制、精度指定和截断选项
_tstring FormatByteSize(uint64_t nBytesSize, bool bSpace, int nPrecision, bool bTruncate)
6.3 使用标准库增强安全性
#include <string>
std::string result = std::to_string(d) + " " + aszByteUnitsNames[i];
7. 与其他实现的对比
与Windows API的StrFormatByteSize相比,这个实现更加轻量且透明。Windows API版本:
// Windows API版本需要复杂的函数声明和缓冲区管理
LPTSTR StrFormatByteSize(DWORD dw, LPSTR pszBuf, UINT cchBuf);
而与PHP等高级语言中的实现相比,C++版本性能更高,但代码稍显冗长:
// PHP版本更为简洁,但性能较低
function format_bytes($size, $delimiter = '') {$units = array('B', 'KB', 'MB', 'GB', 'TB', 'PB');for ($i = 0; $size >= 1024 && $i < 5; $i++) $size /= 1024;return round($size, 2) . $delimiter . $units[$i];
}
8. 实际应用
这个函数在以下场景中特别有用:
- 文件管理器开发:显示文件大小信息
- 网络监控工具:展示数据传输量
- 系统信息工具:报告内存、磁盘使用情况
- 日志分析系统:统计日志文件大小
总结
StrFormatByteSize函数展示了如何通过简洁的算法解决实际编程问题。虽然存在一些局限性,但其核心思路——循环除法和查找表——是许多单位转换问题的通用解决方案。通过本文的分析和改进建议,开发者可以根据具体需求调整和优化这一基础实现。
单位转换是编程中的常见任务,理解其原理和实现方式有助于我们编写更高效、更可靠的代码。这个简单的函数背后,体现了算法设计、内存安全和API设计等多个编程重要概念。