Qwen-Audio:一种新的大规模音频-语言模型
1. 方案简介
现有的多任务语言模型主要关注特定类型的音频(如人类语音)或特定任务(如语音识别和字幕生成),限制了模型的通用性和交互能力。于是提出了一个新颖的音频-语言模型,该模型拥有通用音频理解模型的能力,结构图如下。
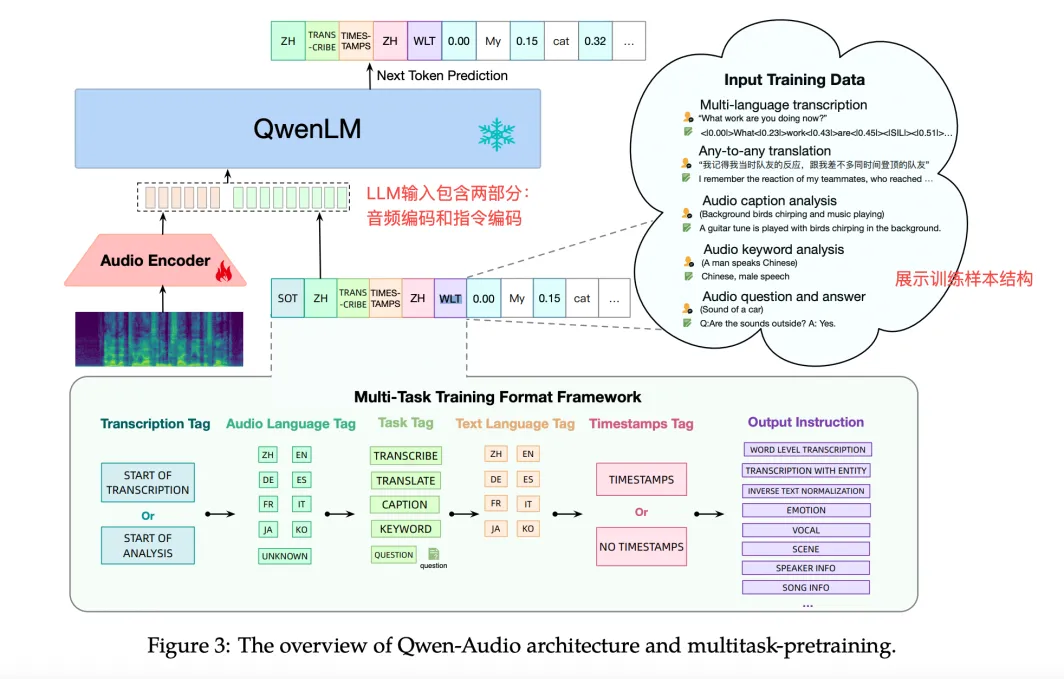
从上图可以看出Qwen-Audio结合了一个音频编码器和一个基于Qwen-7B的大型语言模型。Qwen-Audio在超过30个任务和多种音频类型上进行预训练,包括人类语音、自然声音、音乐和歌曲,以促进通用音频理解能力,从论文(参考文献-1)及官方Demo体验来看效果还是非常不错的。
2. 对比LTU
从架构图上来看,Qwen-Audio和LTU-AS非常像,音频编码都是基于Whisper,然后接一个LLM。这里简单总结一下两者区别:
- 推理方式
-
- Qwen-Audio并没有输出识别结果,而是将Encode后的序列直接送入LLM
- LTU-AS分为两步分,并将两个部分的结果和指令一同编码送入LLM
-
-
- 输出识别结果
- 对Whisper Encode输出送入轻量级的音频标记模型(at-model),生成音频标记序列
-
- 训练方式
-
- Qwen-Audio是采用的联合训练的方式,所有参数都需要训练,训练成本比较高
- LTU-AS模型维持Whisper和LLaMA不变,只训练LoRA、TLTR部分及投影层,训练成本比较低
- 开放度
-
- Qwen-Audio模型是开源的,开放的仓库只提供了eval部分,不过Qwen提供了finetune脚本
- LTU-AS模型都是开源的,提供了完整的环境,train、finetune、eval等过程可以快速验证
- 效果上
-
- Qwen-Audio基于Qwen-7B,词表151936,中文效果明显好于LTU-AS
- LTU-AS是LLM是基于LLaMA,词表只有32000,主要针对英文场景,中文基本不可用
3. 推理运行环境
- 官方体验Demo: https://modelscope.cn/studios/qwen/Qwen-Audio-Chat-Demo/summary/?st=1fuJ0kGSXvsR3TeNt2YKXhg
- 部署Qwen-Audio
-
- https://github.com/QwenLM/Qwen-Audio
- 运行平台:Linux
- 库依赖:按照requirements.txt/requirements_web_demo.txt进行安装,最好在一个独立的docker或conda虚拟环境中安装
- 只提供了eval脚本,没有提供finetune和train脚本,应该和Qwen-7B比较接近:https://github.com/QwenLM/Qwen
- 模型下载地址
-
-
- https://huggingface.co/Qwen/Qwen-Audio-Chat
- https://huggingface.co/Qwen/Qwen-Audio
- 通过HF下载比较慢:https://modelscope.cn/models/qwen/Qwen-Audio-Chat/files
-
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00001-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00002-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00003-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00004-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00005-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00006-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00007-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00008-of-00009.safetensors'
wget 'https://modelscope.cn/api/v1/models/qwen/Qwen-Audio-Chat/repo?Revision=master&FilePath=model-00009-of-00009.safetensors'-
- 运行示例: python web_demo_audio.py
-
-
- 为方便调试并没有采用gradio的方式进行部署,直接运行一个简单示例,故作如下修改
-
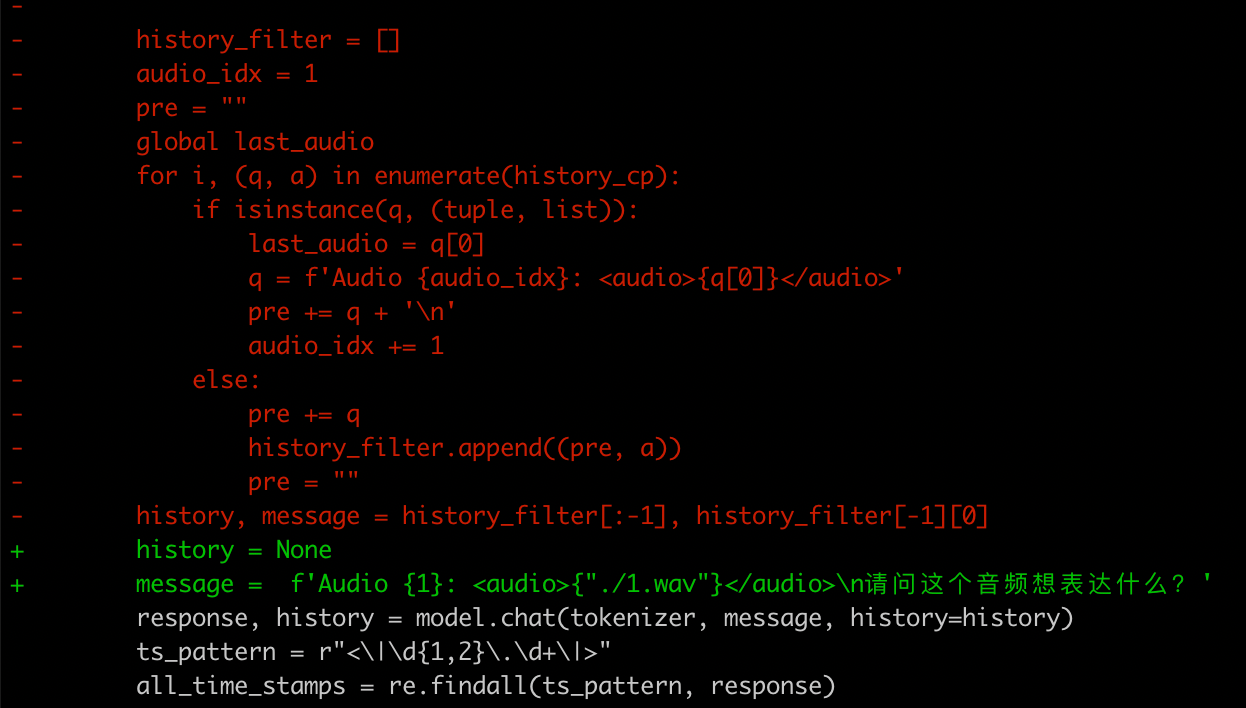
-
- 示例
-
-
- 📎1.wav
- 指令“请问这个音频想表达什么?”
-
-
- 部署遇到问题
-
-
- TypeError: Audio.__init__() got an unexpected keyword argument 'source'
- 修复方案
-
-
-
-
- pip install numpy==1.24.4
- pip install gradio==3.41.2
-
-
4. 推理源码解读
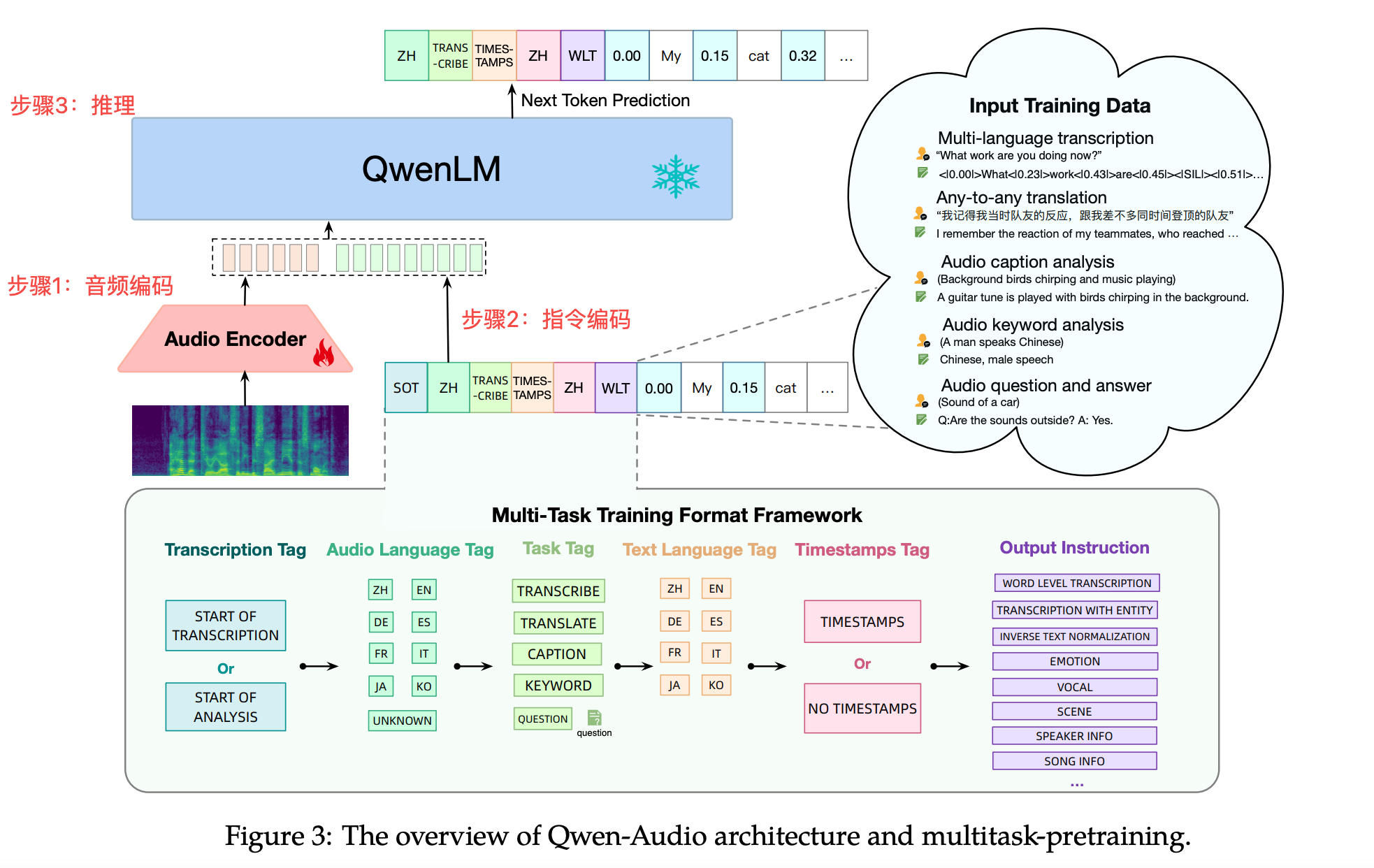
从架构图上可以看出,可以将推理过程分为3个步骤:音频编码、指令编码、LLM推理,其中音频编码和指令编码并无依赖关系,不过在Qwen-Audio代码实现过程中,需要获取音频编码后的长度,所以将音频编码放在步骤一。
步骤1:音频编码
编码模块基于Whisper encode部分(参考文献-2),“特征提取+CNN降低维度+Encode”部分一致,这里不再赘述,差异点是Qwen-Audio在Encode后增加降维模块“avg_pooler+proj”, 如下所示:
(audio): AudioEncoder((conv1): Conv1d(80, 1280, kernel_size=(3,), stride=(1,), padding=(1,))(conv2): Conv1d(1280, 1280, kernel_size=(3,), stride=(2,), padding=(1,))(blocks): ModuleList((0-31): 32 x ResidualAttentionBlock((attn): MultiHeadAttention((query): Linear(in_features=1280, out_features=1280, bias=True)(key): Linear(in_features=1280, out_features=1280, bias=False)(value): Linear(in_features=1280, out_features=1280, bias=True)(out): Linear(in_features=1280, out_features=1280, bias=True))(attn_ln): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(mlp): Sequential((0): Linear(in_features=1280, out_features=5120, bias=True)(1): GELU(approximate='none')(2): Linear(in_features=5120, out_features=1280, bias=True))(mlp_ln): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)))(ln_post): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(avg_pooler): AvgPool1d(kernel_size=(2,), stride=(2,), padding=(0,))(proj): Linear(in_features=1280, out_features=4096, bias=True)(audio_bos_eos_token): Embedding(2, 4096))以1.wav为例,采样率为16000,共包含51236个样本点,帧移是10ms(也就是对应160个点),所以有效帧数L_in=51236/160=320,那么经过“CNN降低维度+avg_pooler”降低维度后帧数应该为320/4=80,增加开始和结束标志后变为82。所以Qwen-Audio AudioEncocerm模块将长度320帧的音频,转成长度82帧维度为4096的序列。
- /root/.cache/huggingface/modules/transformers_modules/Qwen-Audio-Chat/tokenization_qwen.py:550
- /root/.cache/huggingface/modules/transformers_modules/Qwen-Audio-Chat/modeling_qwen.py:764
步骤2:构建Prompt
该步骤可分为两步:prompt生成、prompt序列化
- prompt生成
prompt由“音频信息和指令”构成,如本例中音频是"./1.wav",指令是“请问这个音频想表达什么?”,那么添加对应的tag后,如下:
- 音频信息:'Audio {1}: <audio>{"./1.wav"}</audio>'
- 指令:'请问这个音频想表达什么?'
拼接后构成的prompt为 'Audio {1}: <audio>{"./1.wav"}</audio>\n请问这个音频想表达什么?' 。
- prompt序列化
将prompt按照特定格式打包,并序列化为token_id:
def make_context():# 以history=None为例#'system\nYou are a helpful assistant.'==》[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645]context_tokens = system_tokenscontext_tokens += (nl_tokens+ im_start_tokens+ _tokenize_str("user", query)[1]+ im_end_tokens+ nl_tokens+ im_start_tokens+ tokenizer.encode("assistant")+ nl_tokens)# /root/.cache/huggingface/modules/transformers_modules/Qwen-Audio-Chat/modeling_qwen.py:1191
# 位于函数:QWenLMHeadModel::chat
# 输入query形如:'Audio 1: <audio>./1.wav</audio>\n请问这个音频想表达什么?'
# 输出context_tokens形如:'[151644, 8948, 198, ...'
raw_text, context_tokens, audio_info = make_context(tokenizer,query,history=history,system=system,max_window_size=max_window_size,chat_format=generation_config.chat_format,
)执行后make_context生成prompt序列为:
[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 14755, 220, 16, 25, 220, 155163, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 151851, 155164, 198, 109194, 99487, 111268, 99172, 102124, 99245, 11319, 151645, 198, 151644, 77091, 198]
序列化后的token_id含义如下表,这里仅列出本次任务所涉及token,如果需要了获取更多可以通过函数tokenizer._convert_id_to_token(int)获取
| token | token_id | 含义 |
| system | 8948 | 系统 |
| user | 872 | 用户 |
| assistant | 77091 | 智能助手 |
| <|im_start|> | 151644 | 一般用于角色交替,角色开始说话 |
| <|im_end|> | 151645 | 一般用于角色交替,角色说话结束 |
| <audio> | 155163 | 标识音频的开始位置 |
| </audio> | 155164 | 标识音频结束的位置 |
| [[[AUDIO:modality]]] | 151851 | 音频占位符,后边用音频编码后的序列填充 |
| Audio | 14755 | 标识音频名字 |
| \n | 198 | 换行 |
| 220 | 空格 |
步骤3:LLM推理
该模块是将序列化后的Prompt输入LLM(基于Qwen-7B )进行预测。下边是QWenModel模型结构,可以看出推理过程主要是一个32层维度为4096的残差注意力块(QWenBlock)。
<bound method QWenLMHeadModel.generate of QWenLMHeadModel((transformer): QWenModel((wte): Embedding(155947, 4096)(drop): Dropout(p=0.0, inplace=False)(rotary_emb): RotaryEmbedding()(h): ModuleList((0-31): 32 x QWenBlock((ln_1): RMSNorm()(attn): QWenAttention((c_attn): Linear(in_features=4096, out_features=12288, bias=True)(c_proj): Linear(in_features=4096, out_features=4096, bias=False)(attn_dropout): Dropout(p=0.0, inplace=False))(ln_2): RMSNorm()(mlp): QWenMLP((w1): Linear(in_features=4096, out_features=11008, bias=False)(w2): Linear(in_features=4096, out_features=11008, bias=False)(c_proj): Linear(in_features=11008, out_features=4096, bias=False))))(ln_f): RMSNorm())(lm_head): Linear(in_features=4096, out_features=155947, bias=False)
)推理后输出每个token的得分(QWen词表长度155947),并将得分送入decode_tokens得出文本(通常采用greedy-search),都是标准过程这里不再赘述。下边给出对应的代码位置。
def forward():# 残差注意力模块:由于是递归输出1个维度为[1, 1, 4096]的序列# /root/.cache/huggingface/modules/transformers_modules/Qwen-Audio-Chat/modeling_qwen.py:892# 位于函数: QWenModel::forwardfor i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)......outputs = block( # 32层残差注意力块hidden_states,layer_past=layer_past,rotary_pos_emb_list=rotary_pos_emb_list,attention_mask=attention_mask,head_mask=head_mask[i],encoder_hidden_states=encoder_hidden_states,encoder_attention_mask=encoder_attention_mask,use_cache=use_cache,output_attentions=output_attentions,)......# 将[1, 4096]序列映射成[1, 1, 155947]的序列,即获取每个token的得分# /root/.cache/huggingface/modules/transformers_modules/Qwen-Audio-Chat/modeling_qwen.py:1125# QWenLMHeadModel::forwardlm_logits = self.lm_head(hidden_states)# 如果是greedy-search,获取得分最高的token# /usr/local/lib/python3.10/site-packages/transformers/generation/logits_process.py:419# 自回归解码
# /usr/local/lib/python3.10/site-packages/transformers/generation/utils.py:2709
# 位于函数: QWenLMHeadModel::chat->QWenLMHeadModel::generate->GenerationMixin::generate->GenerationMixin::sample
while True:model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)# forward pass to get next tokenoutputs = forward( # 也就是代码里的self**model_inputs,return_dict=True,output_attentions=output_attentions,output_hidden_states=output_hidden_states)# token解码:将自回归解码获得的token序列转成文本
# /root/.cache/huggingface/modules/transformers_modules/Qwen-Audio-Chat/modeling_qwen.py:1213
# 位于函数: QWenLMHeadModel::chat
# outputs形如: [151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, ...]
# response形如: '这个音频想表达的是一个男人在说话,说的内容是"i have a dream that one day"。'
response = decode_tokens(outputs[0],tokenizer, ...)5. 参考文献
- Qwen-Audio: https://arxiv.org/pdf/2311.07919.pdf
- 《Whisper推理源码解读
》