Apache StreamPark 快速上手从一键安装到跑起第一个 Flink SQL 任务
一、两种最快上手姿势
1)一键安装(推荐给想立即体验的你)
直接在终端执行:
curl -L https://streampark.apache.org/quickstart.sh | sh
命令执行完毕若出现类似下图的日志,表示安装成功,Flink 集群也已自动就绪:(streampark.apache.org)
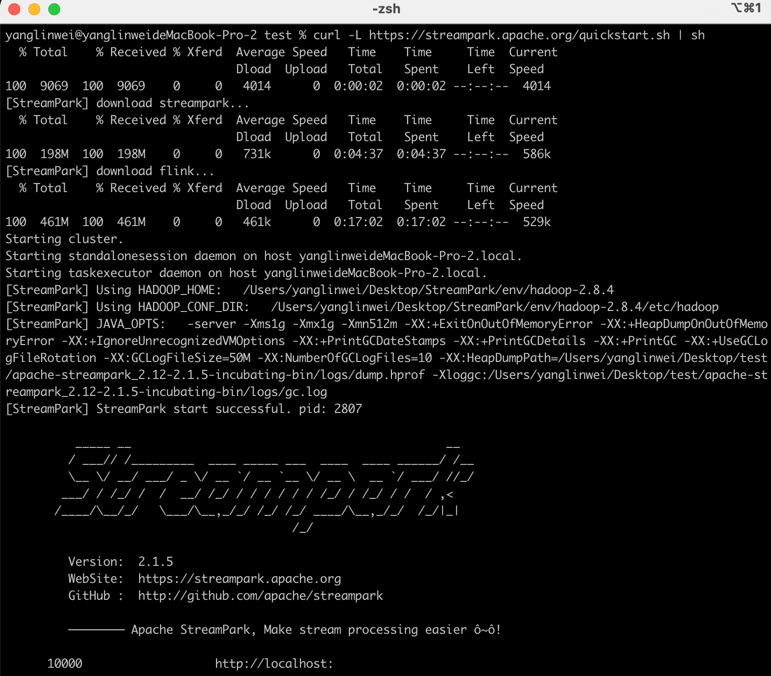
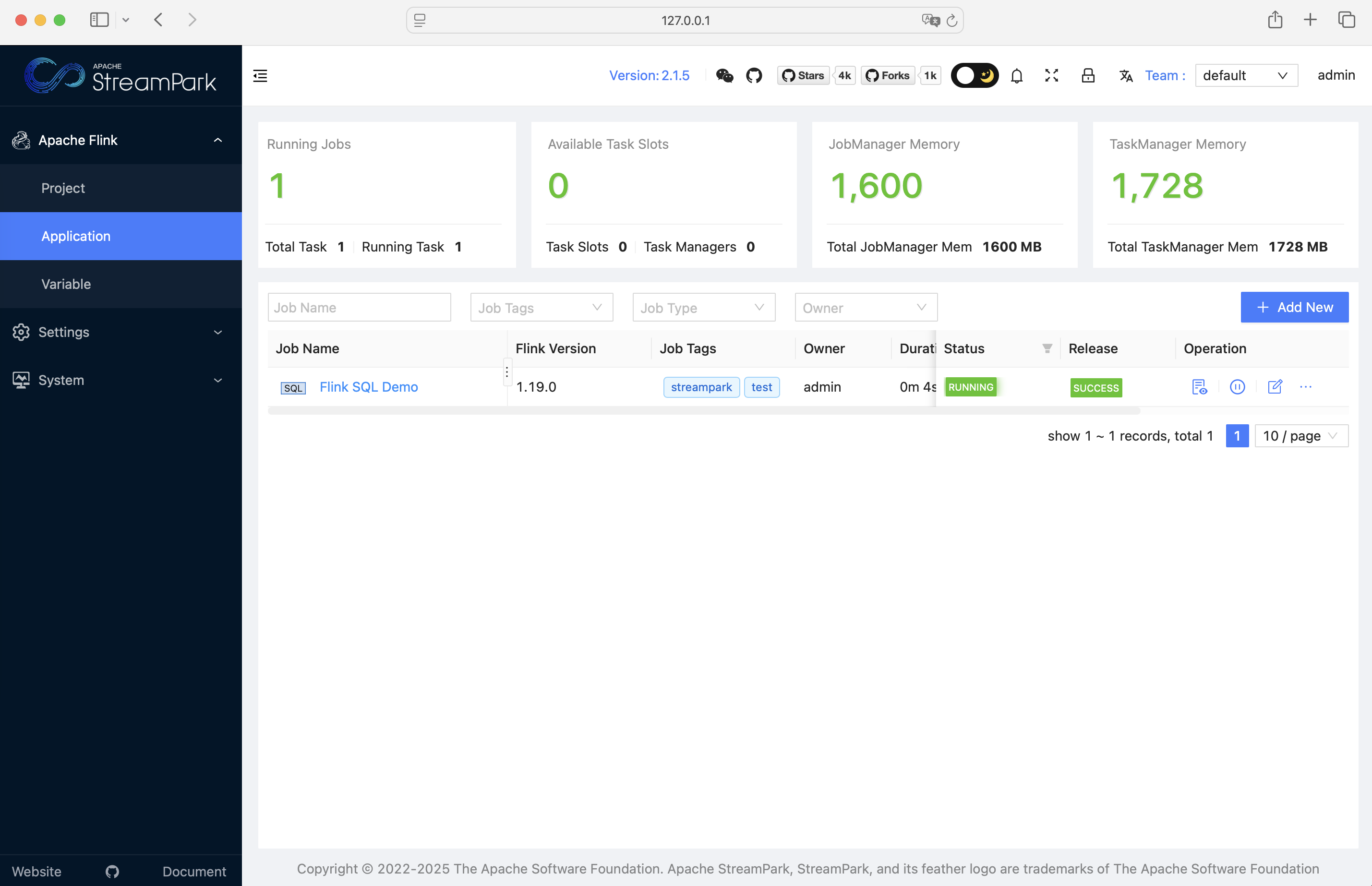
随后访问 http://127.0.0.1:8081 (账号 admin / streampark),控制台中直接点击“启动”即可跑起默认作业:(streampark.apache.org)
2)手动安装(三步走)
Step 1:环境准备
官方示例环境与最低版本要求如下(示例版本仅供参考):
- 操作系统:Linux / macOS(示例:macOS)
- Java:JDK ≥ 1.8(示例:1.8.0_362)
- Scala:≥ 2.12(示例:2.12.18)
- Flink:≥ 1.12(示例:1.19.0)
- StreamPark 安装包:任意版本(示例:2.1.5)
默认假定本地已安装 JDK 与 Scala。(streampark.apache.org)
Step 2:安装并启动 StreamPark
从官网下最新版(示例用 2.1.5),解压并启动:(streampark.apache.org)
# 解压安装包
tar -zxvf apache-streampark_2.12-2.1.5-incubating-bin.tar.gz# 启动 StreamPark
cd apache-streampark_2.12-2.1.5-incubating-bin/bin
./startup.sh
启动成功终端会打印类似信息,并给出访问地址(默认 **http://localhost:10000**): (streampark.apache.org)
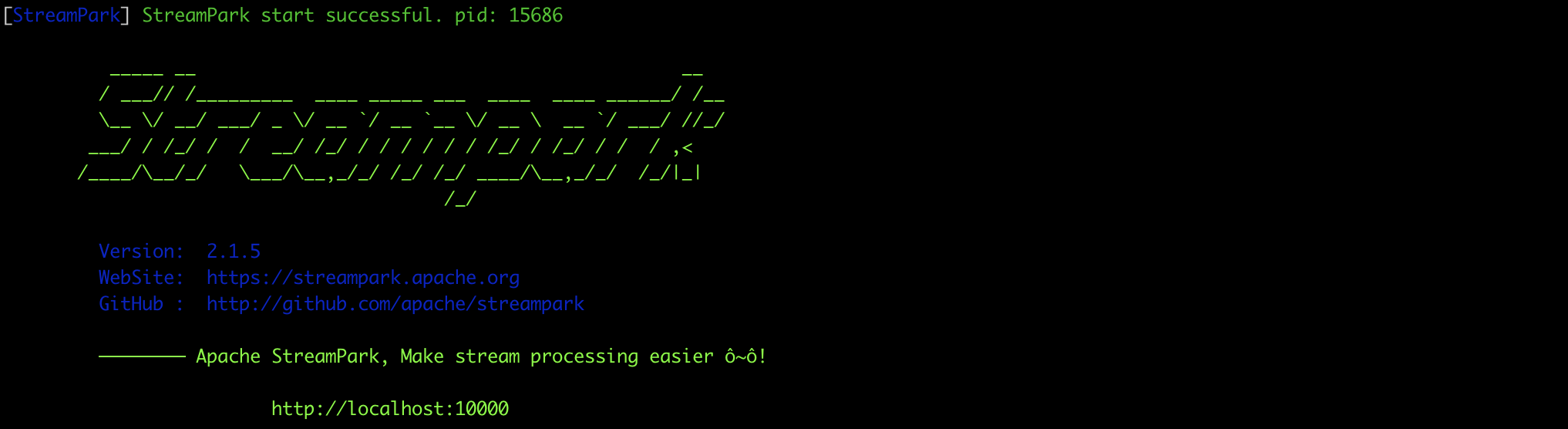
登录控制台地址 **http://127.0.0.1:10000**,账号密码 admin/streampark。(streampark.apache.org)
若你需要登录页截图作为对照,可参考官方图示(可能加载较慢):
https://streampark.apache.org/zh-CN/assets/images/login_page-c6ab3b7f831c4215e1e3f52d16ebb71c.png。(来源同上)
Step 3:部署第一个作业
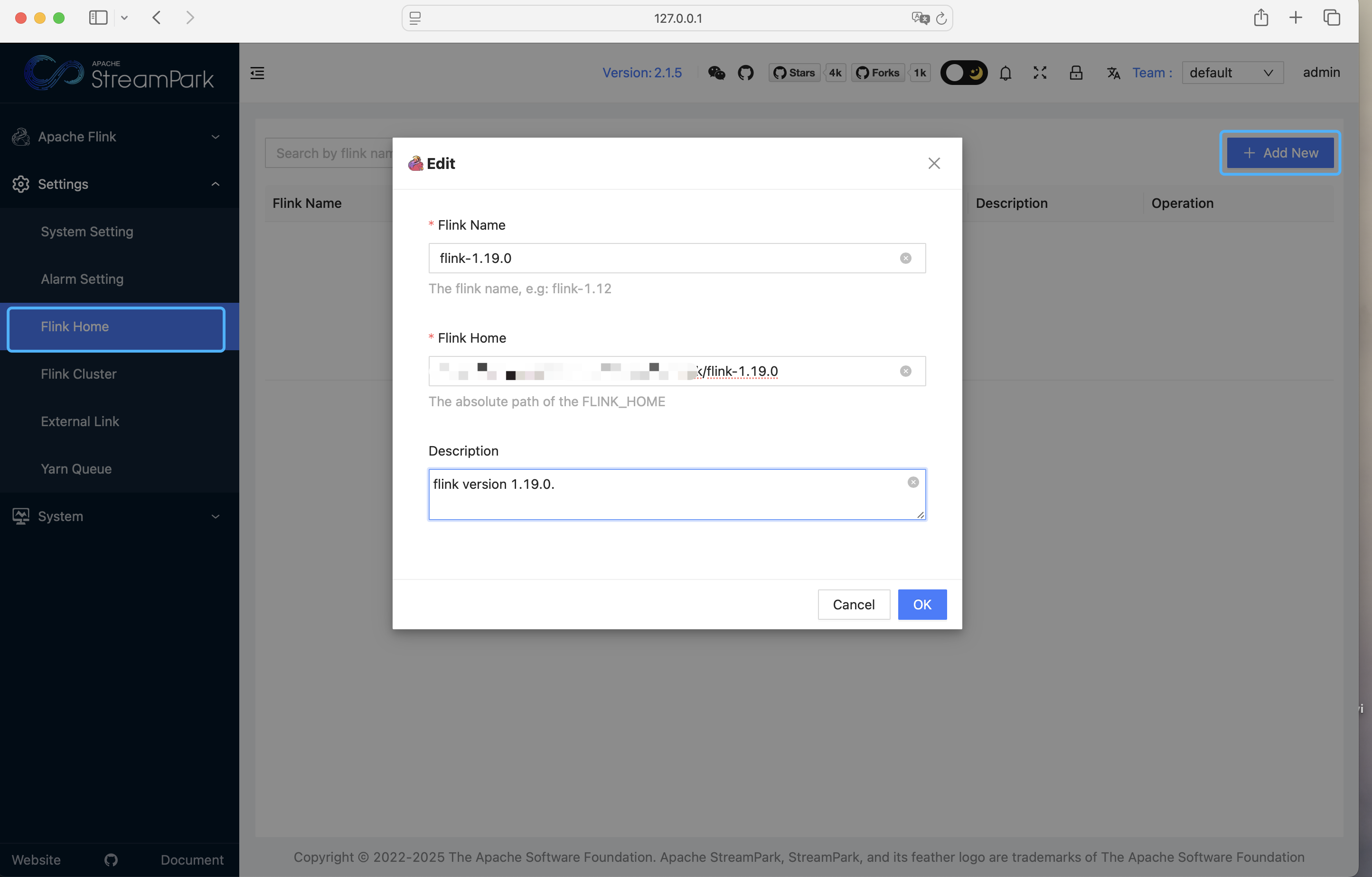
3.1 配置 Flink 版本
确保 Flink 安装包与 StreamPark 在同一台机器上。进入「设置中心 → Flink 版本 → 新建」,指向本地 FLINK_HOME:(streampark.apache.org)
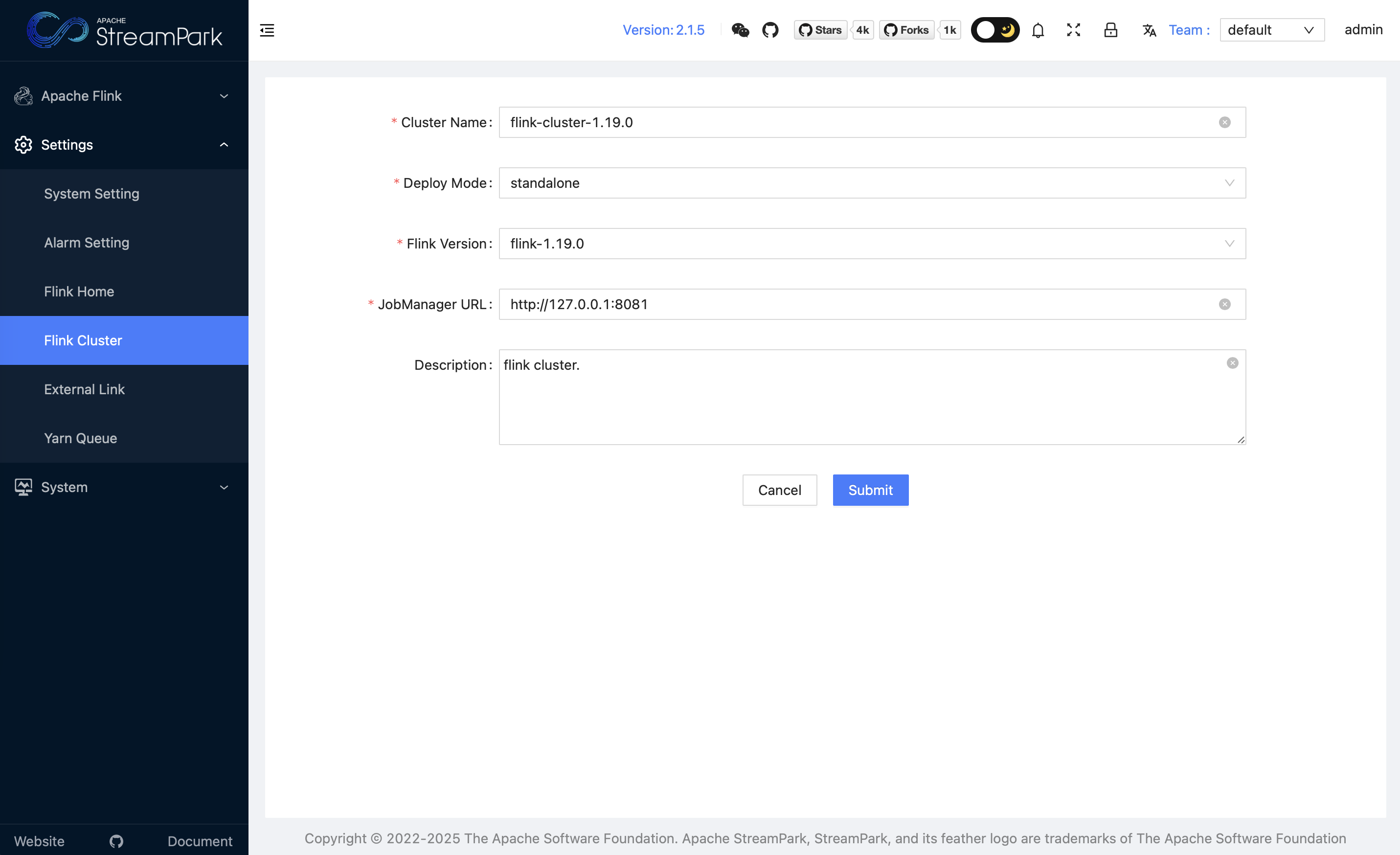
3.2 关联 Flink 集群
先启动本地 Flink(./start-cluster.sh),然后在「设置中心 → Flink 集群 → 添加」中填写信息(示例为 standalone 模式):(streampark.apache.org)
3.3 配置并上线 Demo 作业
首次登录已内置一个 Flink SQL Demo。进入「应用 → Flink SQL Demo → 配置」,把部署模式 / Flink 版本 / Flink 集群对齐为你刚刚设置的选项并保存:(streampark.apache.org)
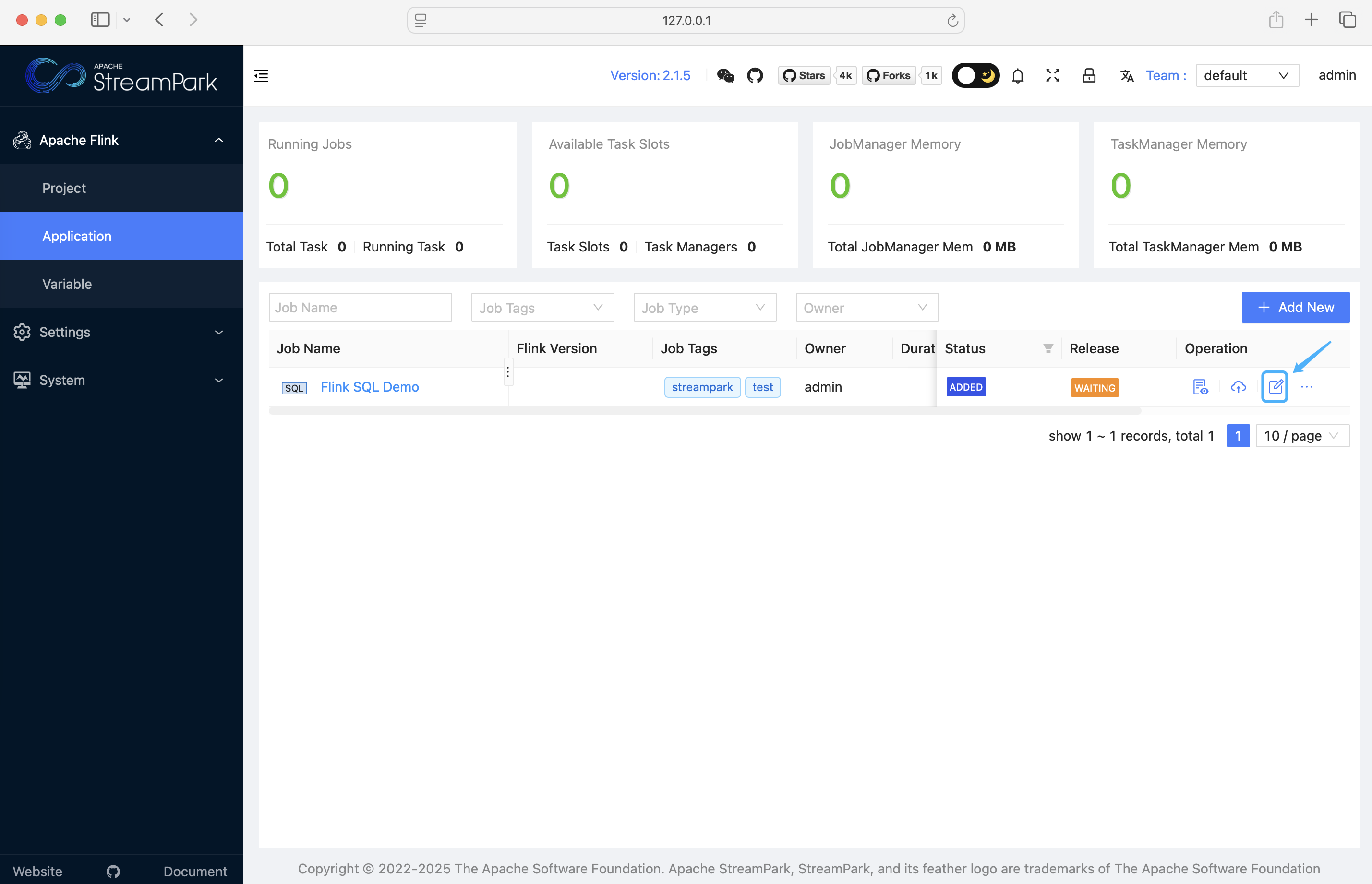
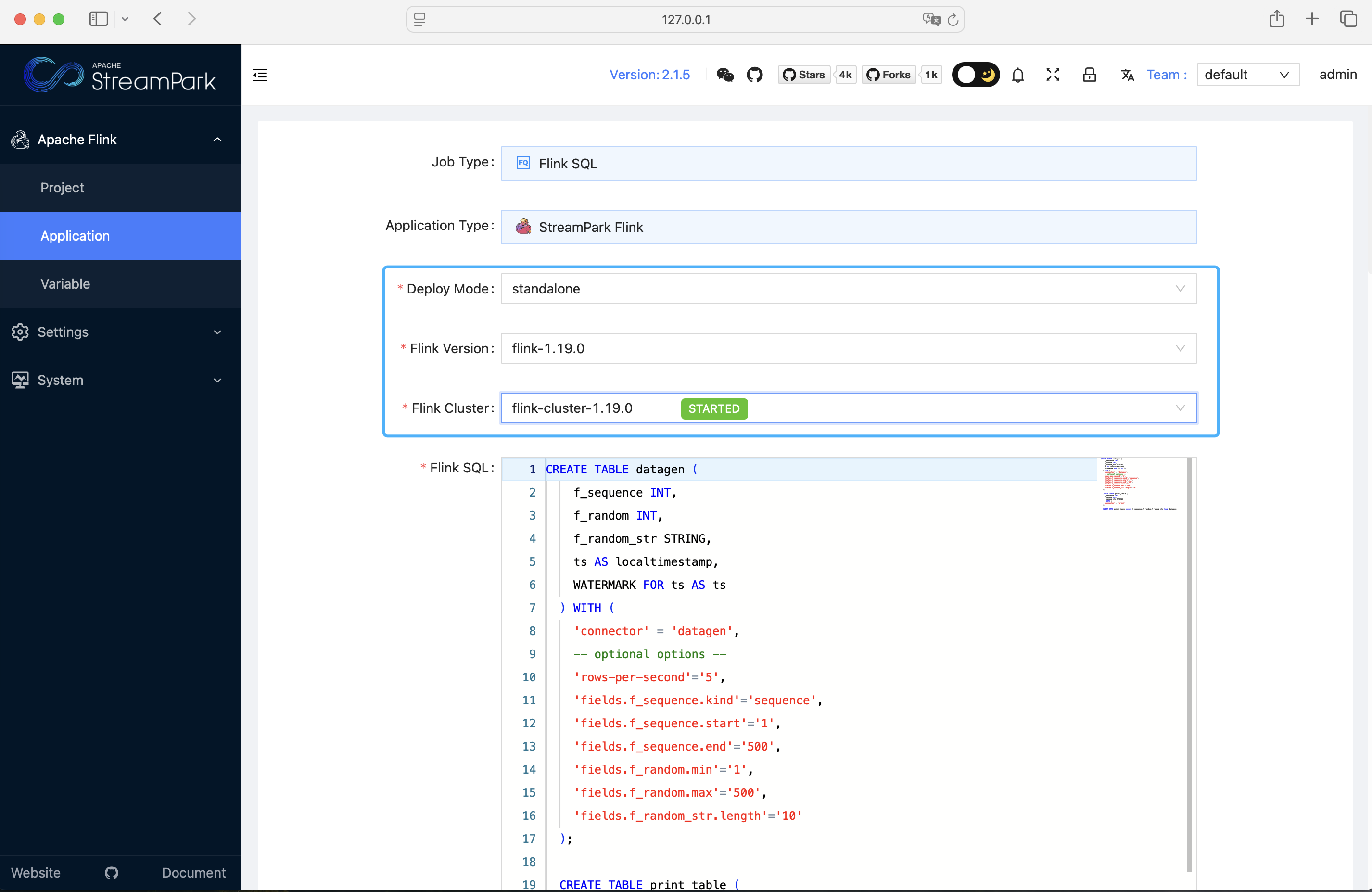
点击 Release / 上线:(streampark.apache.org)
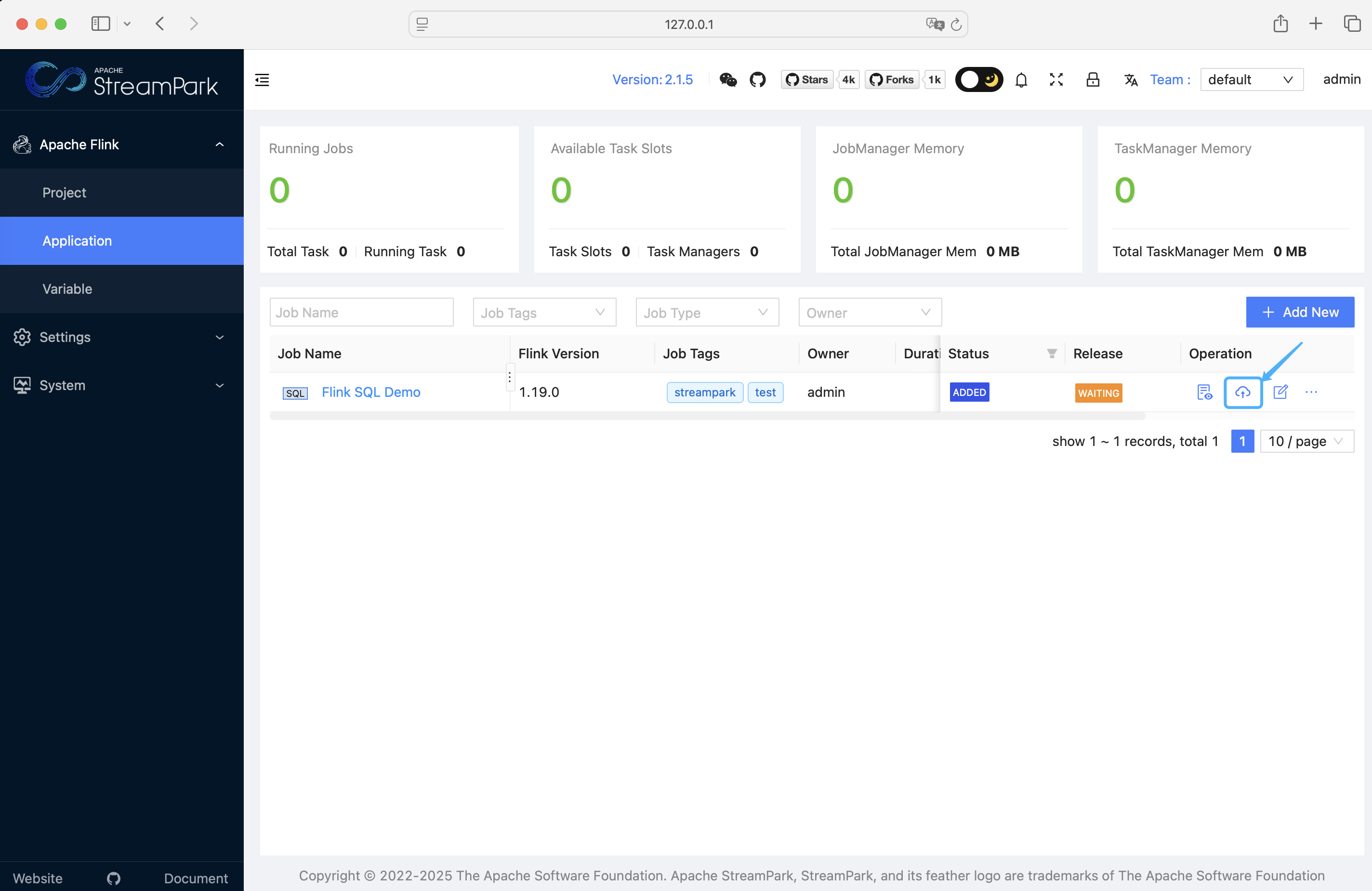
点击 Start / 启动:(streampark.apache.org)
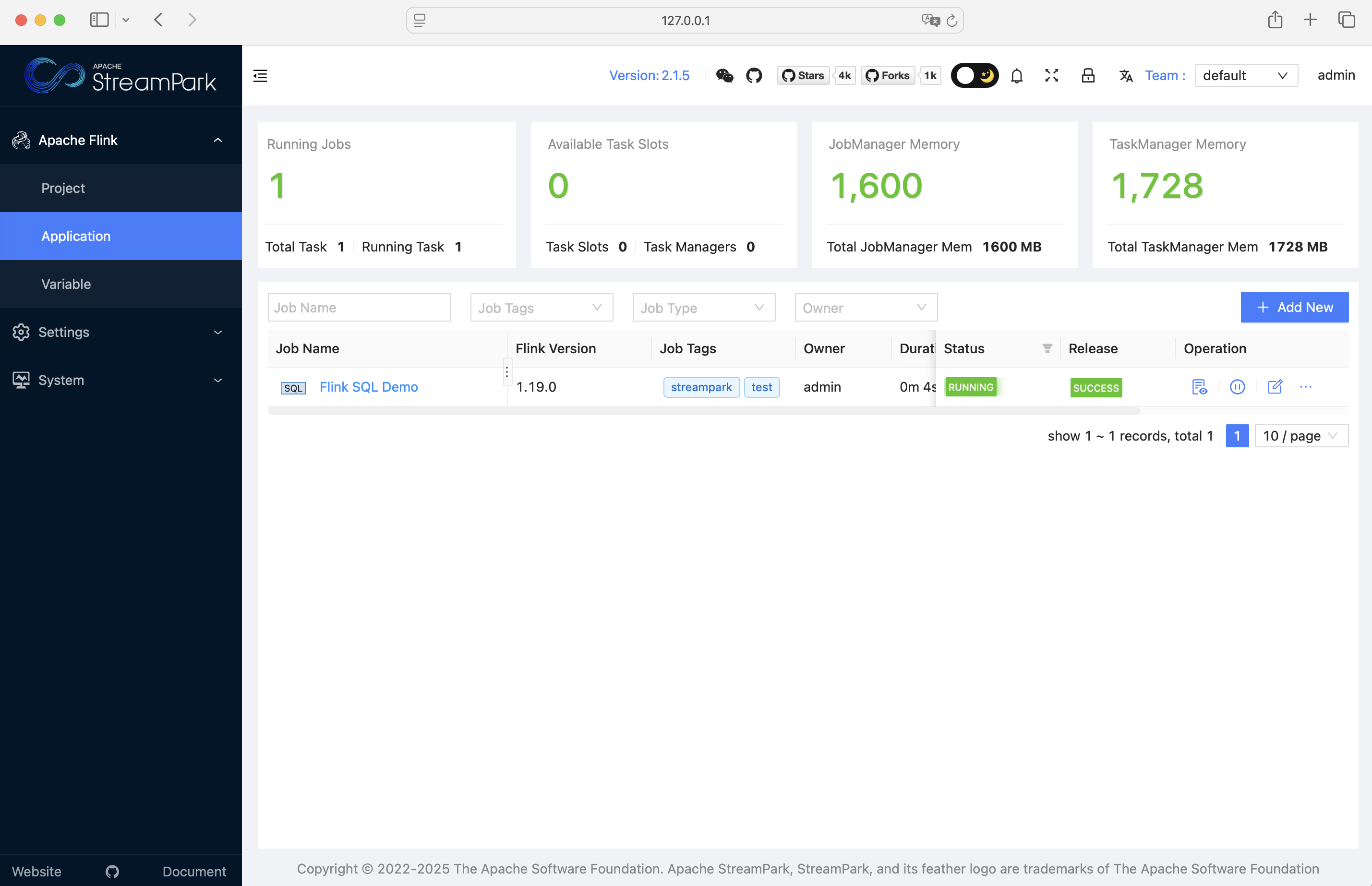
看到状态变为 RUNNING 即表示第一个任务已正常运行:(streampark.apache.org)
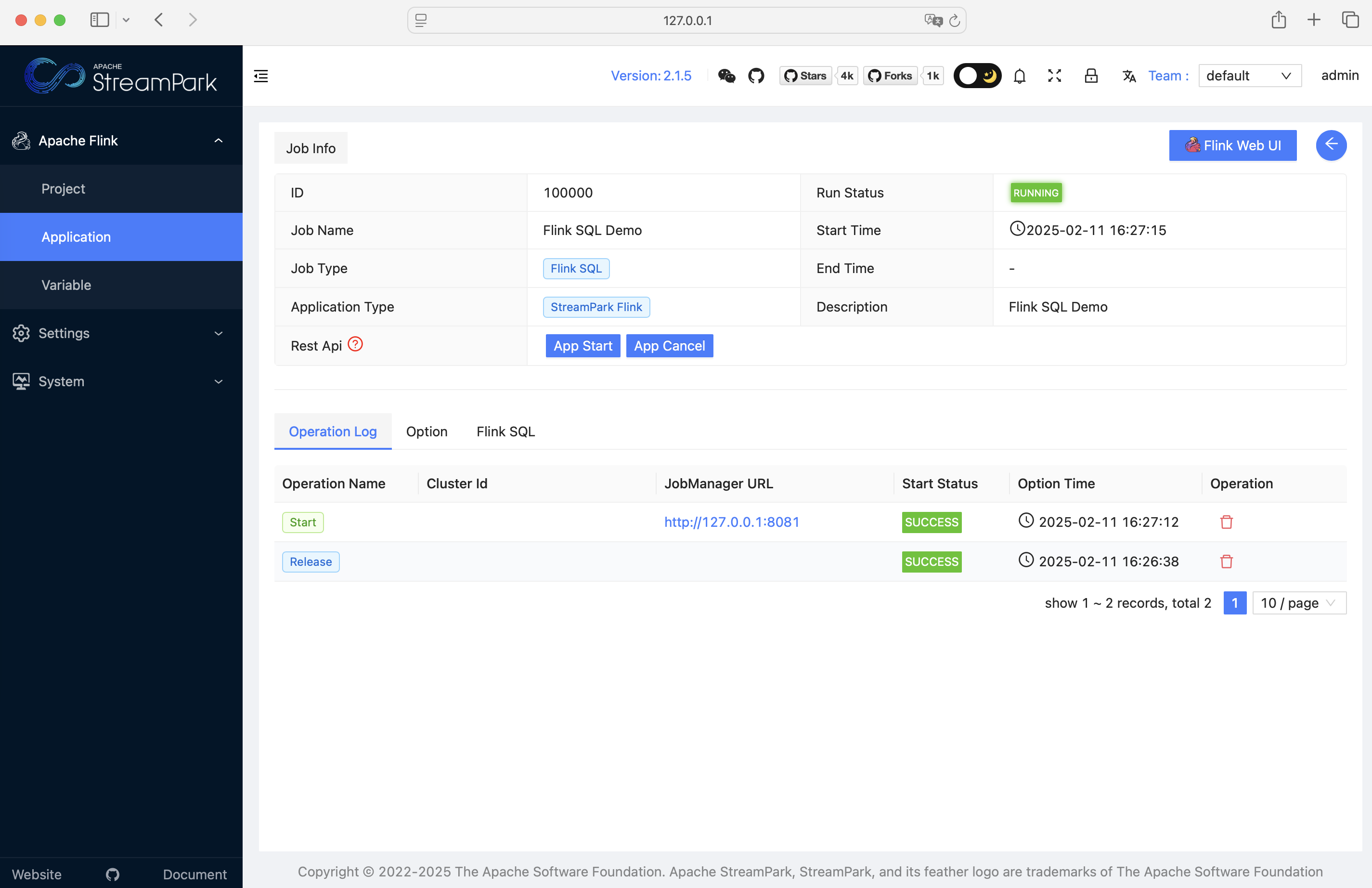
你也可以进入 详情页查看运行日志与操作历史:(streampark.apache.org)
二、常见问题速排
Q:启动时报错 ERROR: streampark.workspace.local: "/tmp/streampark" is an invalid path 怎么办?
A:在系统 /tmp 下创建 streampark 目录,或在安装目录的 conf/config.yaml 中将 streampark.workspace.local 配置为一个合法的本地临时路径。(streampark.apache.org)
三、小结与建议
- 最快路径:优先用一键脚本体验(同时帮你拉起 Flink),确认可用后再转到「手动安装」完成精细配置。
- 关键前置:确保本地 JDK/Scala/Flink 版本满足最低要求;Flink 与 StreamPark 同机更省事。
- 观测闭环:上线后多用控制台的“应用/详情”页观察任务状态与运行日志,方便后续接入告警与保存点策略。以上流程与截图均来自官方“快速入门”,可随时对照操作。(streampark.apache.org)