redis的主从模式的复制
在分布式系统中,希望使用多个服务器来部署redis,存在以下几种redis的部署方式:
1.主从模式 2.主从模式+哨兵模式 3.集群模式
主从模式的优点:可以实现读写分离,数据备份,还能提高读并发。
读取数据都在多个从节点中进行读
多个从节点都是主节点的备份,如果主节点挂了,就可以根据从节点进行数据恢复。
因为服务器多了,不再像之前的单点服务器,在高并发场景下,也能进行读取数据。
主从模式:
假如此时有3台机器,分别部署了redis-server进程。之前一台机器挂了,redis就挂了,但是现在3台机器同时挂的概率就小了,redis也就不容易挂了。
此时就可以把其中一个节点作为“主节点”,另外两个作为“从节点”。从节点就是主节点的一个备份,主节点这边有什么数据修改,都会把这样的修改同步到从节点上。(从节点就是主节点的副本)
注意:redis在主从模式中,是不允许修改从节点的,只能从从节点读取数据。
主从模式的作用:主要针对“读操作”进行 并发量和可用性的提高。
写操作依赖主节点。但是主节点只有一个(如果有多个主节点,同步数据是很麻烦的),在业务场景中,读操作往往就是比写操作更频繁。
主从数据的同步:
redis提供了psync命令,完成了数据同步的过程。
psync不需要咱们手动执行,redis服务器会在建立好主从同步关系之后,自动进行psync。
从节点主动执行psync,从主节点这边拉取数据。
pysnc replicationid offset
replicationid 是主节点生成的,主节点每次重启,生成的replicationid都是不同的,当从节点和主节点建立复制关系的时候,就会从主节点这边获取到replicationid。
offset 偏移量,主节点和从节点都会维护 偏移量(整数)
主节点的偏移量:主节点会收到修改操作的命令,这些命令都会占用几个字节,然后主节点就会把这些修改命令,字节数进行累加。
从节点的偏移量:描述了现在从节点的数据同步到什么位置了。
pysnc这里可以从主节点获取全量数据,也可以获取一部分数据。
如果offset这里写的是-1,就是获取全量数据。
如果offset这里写的是具体的数字,就是从当前偏移量位置来进行获取。
全量复制具体步骤:
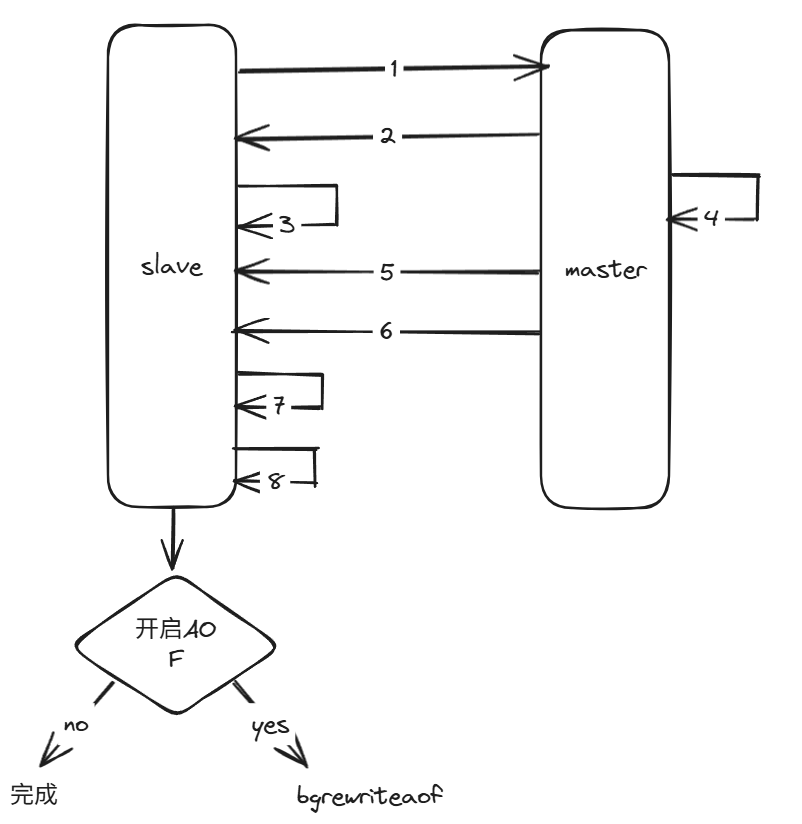
1.从节点发送psync命令给主节点进行数据同步,因为是第一次进行复制,从节点没有主节点的运行ID和复制偏移量,所以发送psync ?-1。
2.主节点根据命令,解析出要进行全量复制,回复+FULLRESYNC响应。
3.从节点接收主节点的运行信息进行保存。
4.主节点执行bgsave进行RDB文件的持久化。
5.主节点发送RDB文件给从节点。从节点保存RDB数据到本地硬盘。
6.主节点将在生成rdb到接收完成期间执行的写命令,在缓冲区中,等到从节点把RDB文件保存完之后,主节点再将缓冲区内的数据补发给从节点。补发的数据扔然按照RDB的二进制格式追加写入到已经接收到的rdb文件中,保持主从一致性。
7.从节点清空自身原有的旧数据。
8.从节点加载RDB文件得到与主节点的一致的数据。
9.如果从节点加载了RDB文件之后,并且开启了AOF持久化功能,它会进行bgrewriteaof操作,得到最近的AOF文件。
部分复制的具体步骤:
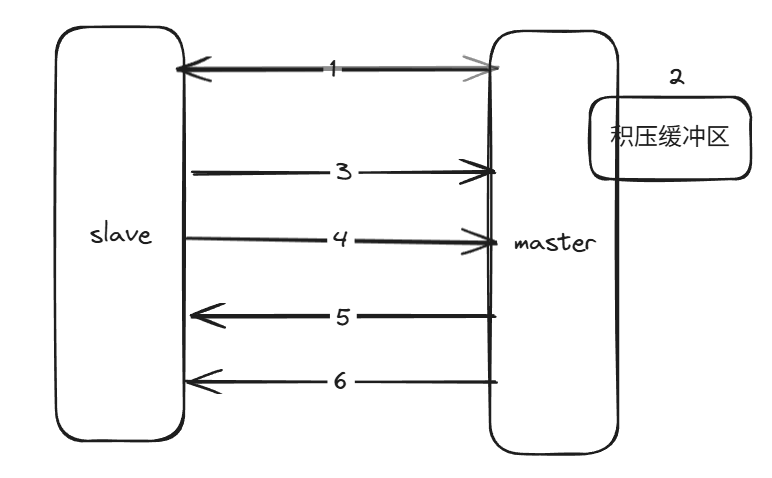
1.当主从节点之间出现网络中断时,如果超过repi-timeout时间,主节点会认为从节点故障并终止复制连接。
2.主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区中。
3.当主从节点网络恢复后,从节点再次连上主节点。
4.从节点将之前保存的replicationid和复制偏移量作为psync的参数发送给主节点。请求进行部分复制。
5.主节点接到psync请求后,进行必要的验证,随后根据offset去复制积压缓冲区查找合适的数据,并响应+COUNTINUE给从节点。
6.主节点将需要从节点同步的数据发送给从节点,最终完成一致性。
实时复制:
从节点和主节点已经同步好了数据,但是主节点会源源不断的进行收到新的修改数据的请求。
主节点上的数据就会随之改变。也需要能够同步到从节点。从节点和主节点会建立TCP的长连接。
然后主节点把自己收到的修改数据的请求,通过上述连接,发给从节点,从节点再根据这些请求,修改内存中的数据。
主从复制的问题:当主节点挂了,只剩下从节点的时候,虽然能够提供读取数据的操作,但是从节点不能自动升级成主节点。此时就需要程序员手动恢复主节点。