深入理解操作系统进程:管理的本质与“先描述,再组织“的核心逻辑
深入理解操作系统:管理的本质与"先描述,再组织"的核心逻辑——进程第一讲
引言:操作系统的定位与管理的意义
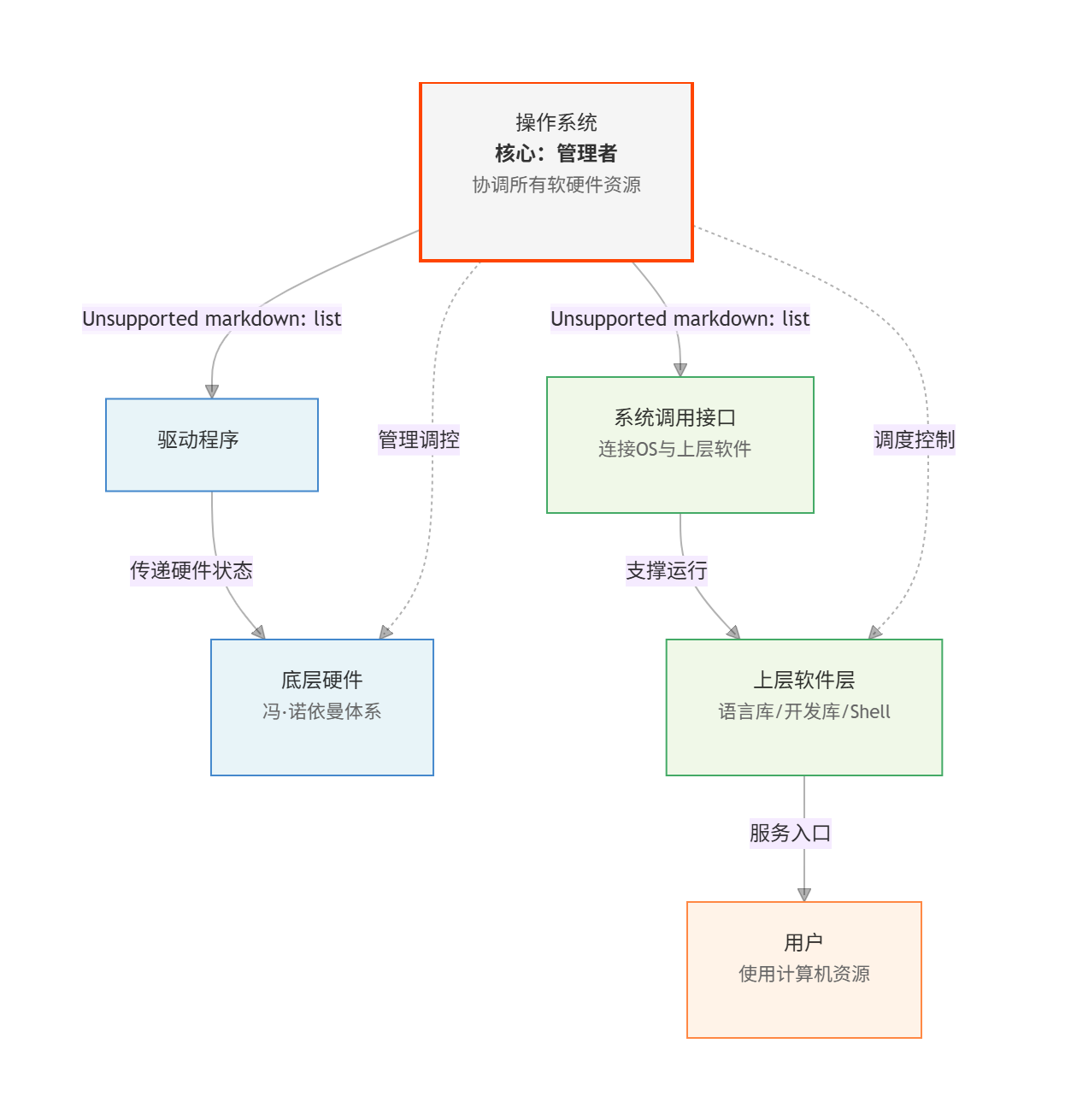
通过前几期的内容,我们知道,在计算机系统的层次结构中,操作系统处于核心位置。从底层到上层,我们可以清晰地梳理出这样的层级:底层硬件(以冯·诺依曼体系结构为基础)、驱动程序、操作系统、系统调用接口,再到接口之上的语言库、开发库、Shell外壳程序,最终面向用户。这一结构中,操作系统扮演着"管理者"的角色——它负责协调和控制计算机的所有软硬件资源,使其高效、稳定地运行。
对于学习计算机的人来说,理解操作系统的管理逻辑至关重要。我们或许会疑惑:"我们学的是计算机,又不是工商管理,为什么要深入理解’管理’?"事实上,计算机领域的"管理"并非对人的管理,而是对复杂系统中资源的有序协调。这种管理能力是操作系统的核心,也是我们理解计算机工作原理的关键。
本文将从生活中的管理场景切入,逐步揭示操作系统管理软硬件资源的本质逻辑,最终落脚到"先描述,再组织"这一贯穿计算机领域的核心思想。
一、管理的本质:从生活场景看管理者与被管理者的关系
要理解操作系统的管理逻辑,我们可以先从生活中最熟悉的管理场景入手——学校的管理体系。
在大学中,管理体系由多个角色构成:校长(高层管理者)、辅导员(执行者)、学生(被管理者)。从这一体系中,我们可以观察到管理的几个核心特征:
1.1 管理者与被管理者无需直接接触
一个典型的现象是:多数学生可能从未见过校长,校长也不会直接干预学生的日常起居(比如不会"踢开宿舍门质问为什么不上课")。但这并不影响校长对学校的整体管理——学校的教学计划、奖惩制度、资源分配等决策依然能有效进行。
这说明:管理者与被管理者是否直接接触,与管理效果无关。在大型组织(如学校、企业)中,这种"非接触式管理"是常态。例如,在字节、腾讯等大型企业中,普通员工可能从入职到离职都不会见到CEO,但企业的战略决策依然能通过层层传递并执行。
1.2 管理的核心是对数据的掌控
既然管理者与被管理者无需见面,那么管理的依据是什么?答案是数据。
校长对学生的管理,依赖于学生的各项数据:选课记录、考勤情况、考试成绩、奖惩记录、基本信息(籍贯、联系方式等)。这些数据足以支撑校长做出决策:比如根据成绩排名发放奖学金,根据挂科学分决定是否劝退学生。即使校长与学生见面,核心目的也是获取信息(如"最近学习有什么困难"),而非见面本身。
企业管理同样如此。老板不需要认识每一位员工,只需通过KPI数据、项目贡献、考勤记录等信息,就能决定员工的晋升、奖励或处罚。古代帝王管理疆域时,也依赖于各地的税收数据、人口统计、灾情报告等信息做出决策。
结论:管理的本质是通过对数据的管理(读/写数据),实现对被管理者的有效调控。
1.3 执行者:连接管理者与被管理者的桥梁
管理者(如校长)无需直接接触被管理者(如学生),但数据如何从被管理者传递到管理者手中?这就需要"执行者"的角色——在学校中,这个角色由辅导员、代课老师等承担。
辅导员的核心职责不是决策,而是执行:收集学生的考勤数据、汇总考试成绩、传达学校的规章制度、反馈学生的问题。这些工作本质上是"数据的传递与初步处理"。例如,校长希望组织编程大赛选拔参赛学生时,会先让辅导员组织比赛并筛选候选人,最终由校长做出决策。
在计算机系统中,这一角色由驱动程序承担。操作系统(管理者)无需直接接触硬件(被管理者),驱动程序负责收集硬件的状态数据(如网卡是否故障、硬盘剩余空间等),并将其传递给操作系统,同时执行操作系统的决策(如启动硬件、关闭设备)。
如图所示:

二、大规模管理的挑战:从"人工处理"到"结构化管理"
当被管理对象数量较少时(如学校只有3名学生),管理者可以通过简单的方式处理数据(如用一张纸记录信息)。但当对象规模扩大到上万人时,混乱的数据会让管理效率急剧下降。
例如,校长若想从万名学生中选出身高最高的5人参加篮球比赛,面对杂乱的纸质数据,只能逐行翻阅,耗时且容易出错。此时,结构化管理成为必然选择。
2.1 第一步:描述——定义标准化的数据结构
为解决数据混乱问题,管理者需要先对被管理对象进行"描述"——提炼其核心属性,形成标准的模板。
在学校中,校长可以设计一张Excel表格,定义学生的核心属性:学院、专业、班级、学号、姓名、性别、身高、体重、成绩、联系方式等。这张表格的本质是数据结构的定义:它规定了"学生"这一对象必须包含哪些信息。
辅导员按照表格模板收集数据后,所有学生的信息将形成统一格式,避免了混乱。此时,校长要查找"身高最高的5人",只需对表格中的"身高"列进行排序即可。

2.2 第二步:组织——用数据结构化管理
标准化的数据(如Excel表格)虽然解决了格式问题,但手动处理仍效率低下。若校长具备编程能力,他会进一步将数据"组织"起来——用代码定义数据结构,并通过算法高效操作。
例如,用C语言定义一个struct student结构体描述学生:
struct student {char college[50]; // 学院char major[50]; // 专业char class[20]; // 班级char id[20]; // 学号char name[20]; // 姓名char gender[5]; // 性别int height; // 身高(cm)float gpa; // 学分绩点struct student *next; // 指向下一个学生的指针
};
这个结构体完整描述了学生的核心属性,而next指针则为"组织"数据提供了可能——通过指针将所有学生结构体连接成链表,形成一个有序的整体。

2.3 管理即对数据结构的增删查改
当学生数据被组织成链表后,所有管理动作都转化为对链表的操作:
- 新增学生:创建一个
struct student实例,填充数据后插入链表; - 删除学生:在链表中查找目标学生节点,移除该节点;
- 查询学生:遍历链表,根据条件(如"身高最高")筛选节点;
- 修改学生信息:找到目标节点后,更新其属性值(如修改成绩)。
例如,校长要开除一名挂科学分超标的学生,只需:①在链表中查找该学生的学号;②通知辅导员执行退学流程;③从链表中删除该节点。整个过程无需校长与学生见面,只需操作数据结构。
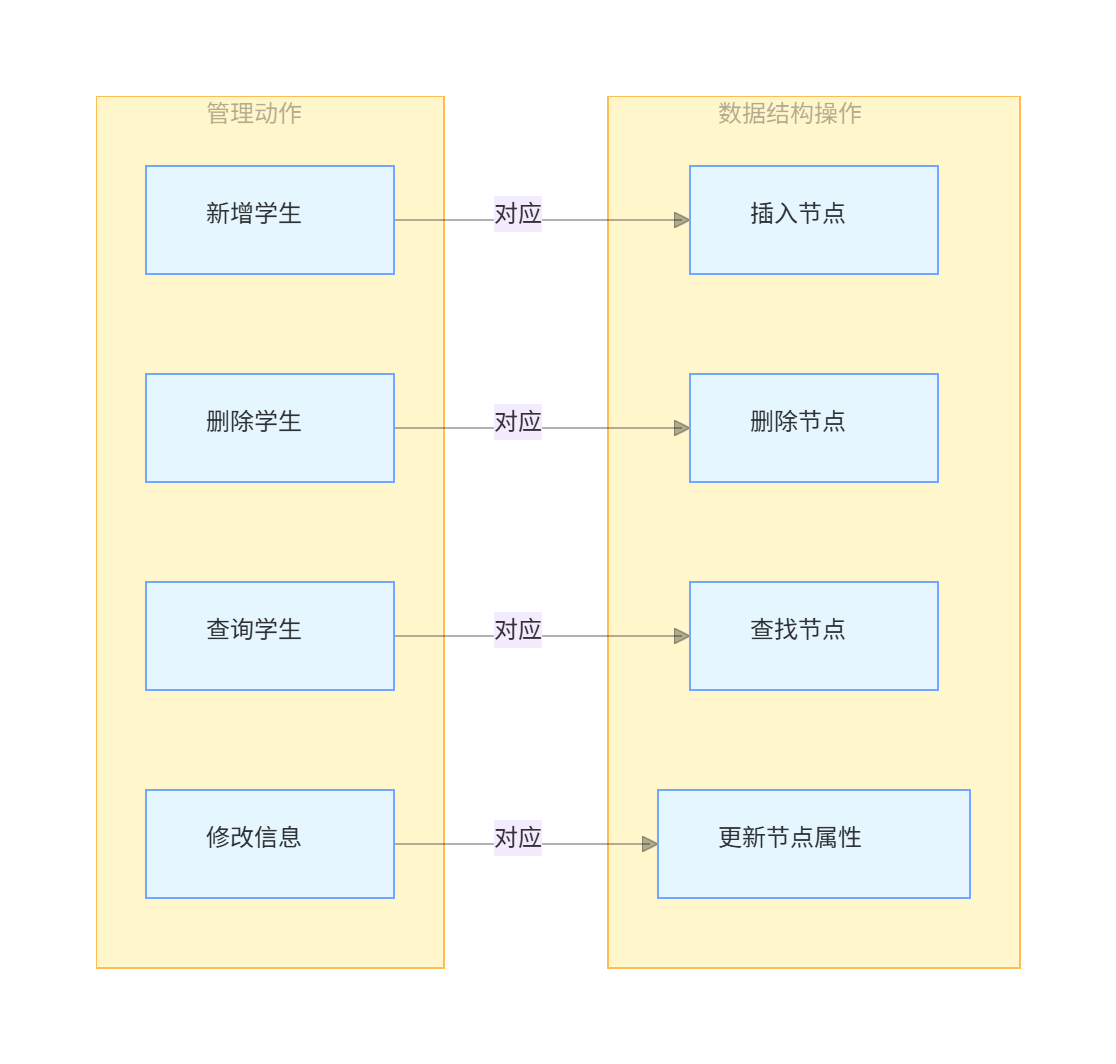
结论:大规模管理的核心是"先描述,再组织"——先定义被管理对象的数据结构,再用数据结构(如链表、树)组织对象实例,最终通过对数据结构的增删查改实现管理。
三、计算机世界的印证:从应用程序到操作系统
"先描述,再组织"的逻辑不仅适用于生活场景,更是计算机领域的通用准则。从简单的应用程序到复杂的操作系统,这一思想贯穿始终。
3.1 应用程序中的"先描述,再组织"
以我们熟悉的"通讯录"程序为例,其设计逻辑完全遵循这一思想:
-
描述:定义
struct Person结构体,描述单个联系人的属性:struct Person {char name[20]; // 姓名int age; // 年龄char telephone[15]; // 电话char address[100]; // 地址 }; -
组织:定义
struct Contact结构体,用数组或链表管理多个联系人:struct Contact {struct Person *persons; // 指向联系人数组的指针int size; // 当前联系人数量int capacity; // 最大容量 }; -
管理:实现增删查改函数,本质是对
struct Contact内部数据结构的操作:// 添加联系人(插入数据) void addPerson(struct Contact *con, struct Person p);// 删除联系人(删除数据) void delPerson(struct Contact *con, char *name);// 查找联系人(查询数据) struct Person* findPerson(struct Contact *con, char *name);
其他程序(如三子棋、扫雷)也遵循同样的逻辑:
- 三子棋:先用二维数组
char board[3][3]描述棋盘状态,再通过数组操作实现落子、判赢; - 扫雷:先用二维数组描述每个格子的状态(是否有雷、周围雷数),再通过数组遍历实现扫雷逻辑。
3.2 编程语言对"先描述,再组织"的支持
不同编程语言虽然语法不同,但都为"描述"和"组织"提供了原生支持:
- 描述:C语言用
struct,C++/Java用class,Python用class,这些机制本质上都是定义对象的属性和行为; - 组织:C++的STL容器(
vector、list、map)、Java的集合类(ArrayList、HashMap)、Python的内置类型(list、dict),都是为了高效组织对象而设计的工具。
例如,C++中用class描述"学生",用vector组织多个学生:
class Student {
private:string college; // 学院string name; // 姓名float gpa; // 绩点
public:// 成员函数(行为)float getGPA() { return gpa; }
};// 用vector组织学生对象
vector<Student> students;
结论:所有编程语言都围绕"先描述,再组织"设计,因为任何软件本质上都是对数据的管理。
3.3 操作系统中的"先描述,再组织"
操作系统作为管理软硬件资源的核心软件,其内部实现完全基于"先描述,再组织"的逻辑。由于操作系统通常用C语言编写(如Linux内核),它主要通过struct和数据结构(链表、树等)实现管理。
3.3.1 对硬件设备的管理
操作系统管理的硬件包括CPU、内存、硬盘、网卡等。每种设备都被抽象为struct device结构体:
struct device {char name[50]; // 设备名称(如"eth0"网卡)int type; // 设备类型(如1=输入设备,2=输出设备)int status; // 设备状态(0=空闲,1=忙碌,2=故障)void (*operate)(); // 设备操作函数指针(如启动、关闭)struct device *next; // 指向下一个设备的指针
};
所有设备的struct device实例被组织成链表(称为"设备链表")。当操作系统需要管理设备时,只需操作该链表:
- 检测故障设备:遍历链表,查找
status=2的节点; - 分配空闲设备:遍历链表,找到
status=0的节点并将其status改为1; - 新增设备(如插入U盘):创建
struct device实例,插入链表。
3.3.2 对进程的管理
进程是程序的执行实例,是操作系统管理的核心对象。Linux内核用struct task_struct描述进程(简化版):
struct task_struct {pid_t pid; // 进程IDint state; // 进程状态(运行、就绪、阻塞)struct mm_struct *mm; // 内存管理信息struct file *files; // 打开的文件列表struct task_struct *next; // 指向下一个进程的指针
};
所有进程的struct task_struct实例被组织成双向链表(称为"进程链表")。操作系统的进程调度、终止、切换等操作,本质上是对该链表的增删查改:
- 调度进程:遍历链表,选择
state=就绪的进程分配CPU; - 终止进程:查找目标
pid的节点,从链表中删除并释放资源; - 创建进程:复制父进程的
task_struct,修改pid后插入链表。
3.3.3 对内存的管理
内存管理同样遵循这一逻辑。操作系统将物理内存划分为多个"页框",用struct page描述每个页框:
struct page {unsigned long flags; // 页框状态(空闲、已分配、锁定)struct address_space *mapping; // 映射关系struct page *next; // 指向下一个页框的指针
};
空闲页框被组织成"空闲链表",当进程申请内存时,操作系统从链表中取出页框并修改其状态;当进程释放内存时,页框被放回链表。
四、总结:"先描述,再组织"的普适性与学习意义
通过对生活场景、应用程序和操作系统的分析,我们可以总结出"先描述,再组织"这一逻辑的核心要点:
- 管理的本质是数据管理:管理者通过数据而非直接接触实现对被管理者的调控;
- 描述是管理的前提:通过定义数据结构(如
struct、class),提炼被管理对象的核心属性; - 组织是高效管理的关键:用数据结构(链表、树、哈希表等)将对象实例有序组织,使管理动作转化为对数据结构的增删查改;
- 普适性:这一逻辑适用于从生活管理到计算机系统的所有领域,是解决复杂系统管理问题的通用思路。
对于学习计算机的人来说,理解这一逻辑具有重要意义:
- 为什么要学数据结构?因为操作系统、应用程序的管理逻辑最终都依赖于数据结构的操作,不懂数据结构就无法理解系统的底层工作原理;
- 为什么要重视抽象能力?"描述"的过程本质是抽象——从具体对象中提炼共性属性,这是设计高质量系统的核心能力;
- 如何分析复杂系统?面对任何系统(如数据库、分布式框架),都可以从"如何描述对象"和"如何组织对象"入手,逐步拆解其核心逻辑。
操作系统的管理逻辑看似复杂,但归根结底是对"先描述,再组织"这一简单思想的落地。掌握这一思想,我们就能从本质上理解计算机系统的工作原理,为深入学习更复杂的技术奠定基础。
本期总结+下期预告
本期内容是进程第一讲,讲解了操作系统管理的本质与“先描述再组织的核心逻辑”,下期内容继续带来进程的深入解析。
感谢大家的关注,我们下期再见!
