GraphQL 工程化篇 I - REST vs GraphQL 的取舍与基础配置
GraphQL 工程化篇 I - REST vs GraphQL 的取舍与基础配置
最近两个月开始的新项目,后端用的就是 GraphQL,因此确实对 GraphQL 的认知有了一些比较深入的了解,所以就抽空手撸了一个小项目,从零开始配置了一下,进行了更系统地学习,对之前简单过了一遍的内容也有了更好的了解
项目 repo 在:
https://github.com/GoldenaArcher/graphql-case-studies
目前后端的部分整合了一下,v1(使用 json mock 数据)是完成了,v2(接入 ORM 使用真实数据)还在复习之前的笔记,需要修改一些配置
一些比较简单的配置这里不会深挖,感兴趣的可以到 repo 里看一下完整的代码,或者跟着这几篇笔记泡一下:
- GraphQL 入门篇:基础查询语法
- GraphQL 实战篇:Apollo Client 配置与缓存
- GraphQL 工程篇:分页、数据优化与 React Hooks 实战
- GraphQL 进阶篇:订阅机制与 TypeScript 类型生成实战
这篇笔记更多的是查漏补缺,梳理一下项目取舍和设计上的一些思路
Rest vs Graph
具体关于什么是 rest,以及什么是 graph 这种就不提了,根据自己的使用/开发经验简单地提一下二者的对比、区别和优劣分别在哪里
文档
这一点 GraphQL 和 Rest 各有优势
GraphQL 开发的时候,服务器端往往会自动生成 playground 和 docs,如果开放 introspection,production build 的同时也会开放对应的 docs——也有可能会开放 playground,这一点是要注意的。如果 playground 并不涉及到 production db,而且是内部项目,这对调用 API、对比结果是一个非常好的辅助功能。但是如果是公开项目,那么就会有安全隐患
GraphQL 生成的文档如下,类型都非常好的 typed 了,在 playground 中调用也非常的简单,不需要借助第三方工具:
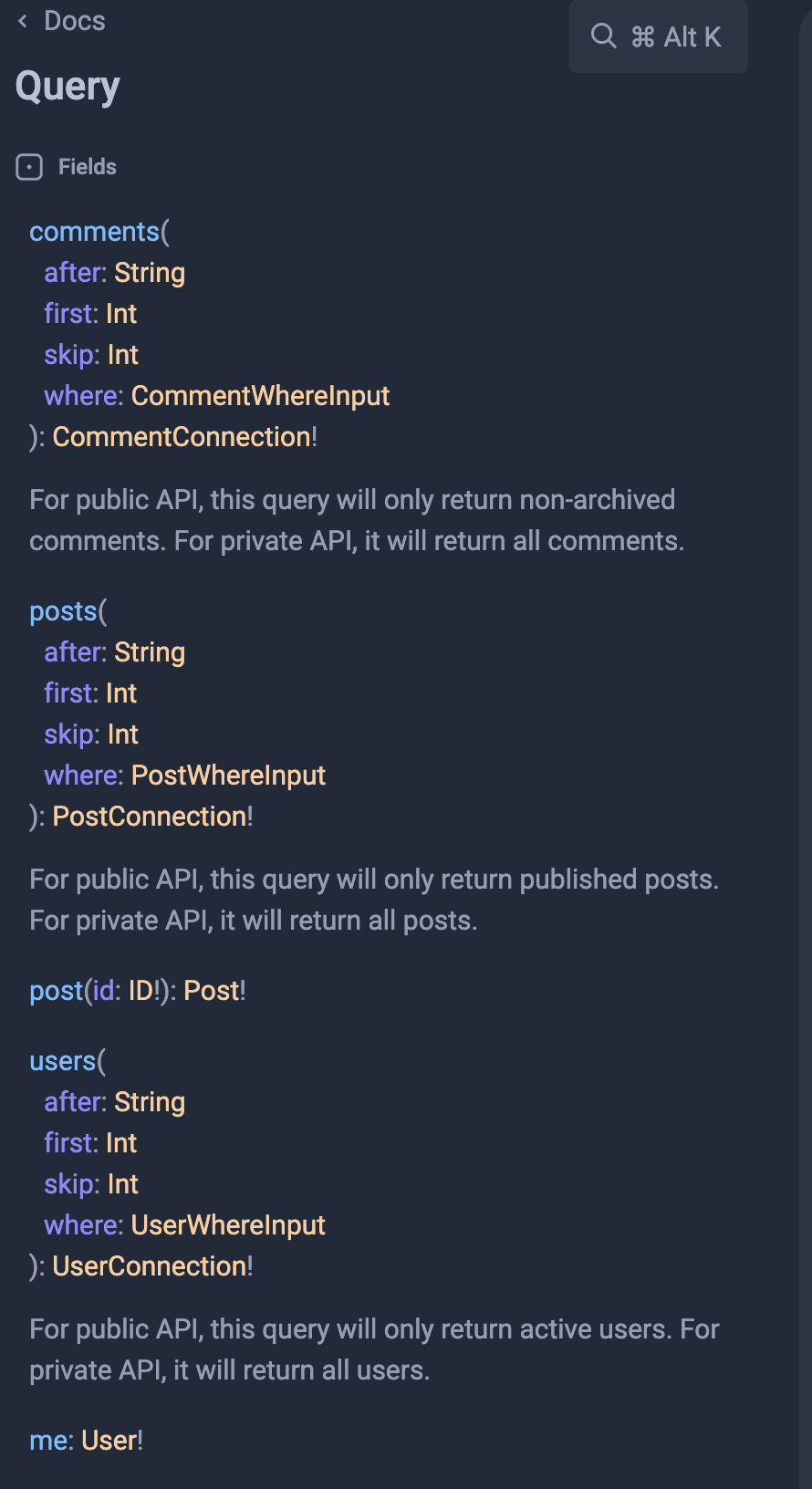
Rest 缺乏这种一站式工具,往往需要借助 swagger 去生成对应的 docs。不过大多数的生态圈都有对应的 swagger 工具——尽管无法一站式地暴露所有的 parameters,但是 swagger docs 可以独立部署这一点又是它的优势
开发体验 - 前端
这一点各有千秋,而且非常取决于项目类型
- 社交网络
GraphQL 在这有无可比拟的优势,尤其是需要深层嵌套获取数据时——Facebook 也真是因为有这样的需求,才会研发出 GraphQL 这套工具并整出了这样一套规范 - 传统电商
强数据类型,这种情况下使用 rest 调取数据会更加的方便 - 中台
如果同样的数据需要支持不同的服务,并且每个服务对数据的需求都不太相同,那么 GraphQL 在这点有着天然的优势——它可以很好的解决 underfetch 和 overfetch 的问题,不像传统 rest 那样,会把所有的数据一股脑儿地丢出来,然后前端需要各种各样的过滤 - 工具/文档
这一点 Rest 有更多的优势,目前上 rest 的工具和文档都太多了,尤其是 axios 的插件,基本上只有想不到,没有找不到。而且它们最大的优点在于——不被前端的框架所绑定
相比较而言,GraphQL 所有的工具就比较有局限性,比较出名和综合的就一个 Apollo Client。Meta 自家的 Relay 虽然也能使用,但是它是与 React 生态圈进行一个强绑定的,换句话说,跳开 React 这个框架,目前我能够想到的工具也只有 Apollo Client
开发体验 - 后端
这一点 rest 的优势比 GraphQL 强很多:
- 鉴权
GraphQL 每一个 endpoint 都很活泛,并且这就是他的特点,因此很难像 rest 一样,通过单独设立 endpoints,并且在对应的 controller 设置权限管理 - 数据库调用
GraphQL 很容易出现 N+1 的调用问题,就算 query 层使用了 data loader,但是在 controller 层如果分别需要调用其他的数据库,那依旧会出现 N+1 的问题,而且这种逻辑上的漏洞是非常难以查询的
相比较,rest 因为没有 GraphQL 那样嵌套式的调用,因此 N+1 这一块的问题有的时候可以被遮掩掉,甚至是可以基于数据的一致性而被容忍
对比起来 GraphQL 也是有一定的优点:
- 统一入口
rest 的多 endpoint,在鉴权的角度是优点,但是在管理实现的情况是缺点。这一点 GraphQL 只有一个 entry point,相比较而言可以更好地进行管理 - 强契约
schema 本身就是 contract,我们现在用的项目里还在 hook 中实现了一个工具,就是在推送前端代码之前先 validate 后端的 schema,如果二者出现不一致——即前端 schema 中包含了额外的数据,那么 hook 就会自动 block commit
这点对于前端开发或许有些痛苦,但是对于后端来说意味着更少的沟通成本——schema 本身就是 single source of truth,开发的时候只需要匹配对应的 schema 即可 - 内置 subscription 支持
这一点后端如果要额外实现,就必须要新增 socket 的支持,这个我之前在学习 socket.io 的时候也发现了,socket 的 instance 其实管理起来还是有点麻烦,不像 GQL 直接内置这么方便
还有一个我个人觉得不太好分的点
- schema 渐进式演化
这个往往会被归类成 GQL 的优点,但是我在实际使用的时候发现,不太好说。如果只是新增字段或者 deprecation,那么 GQL 和 Rest 的区别不是很大——后者如果 client 有 schema 的 runtime validation,那么可能会失败,而 GQL 对新增字段不太敏感
但是,rest 也可以通过版本控制避免这个问题,而且,一旦涉及到删除和修改字段名称,那么 rest 完全可以通过不同的版本去规避客户端的验证问题,而 GQL 因为缺乏对版本的支持,这就导致调用也会出现更大的问题
总体来说,我觉得二者是各有优势的,这个完全取决于团队互相的沟通
缓存机制
缓存是 REST 和 GraphQL 差异比较大的一点,这一点 Rest 毋庸置疑的占据着绝对优势
- Rest 的天然优势
REST 接口是基于 URL 的,GET /products/123这种请求可以很自然地被 CDN、浏览器缓存,甚至 HTTP proxy 都能直接命中缓存,这对静态内容或者更新频率低的接口特别有利 - GraphQL 的局限
GraphQL 所有请求都是 POST 到/graphql,查询内容放在 request body 里,CDN 或浏览器根本无法识别具体是哪个资源,所以无法直接利用 HTTP 缓存。要做缓存只能走应用层:- 前端:Apollo Client 内置 InMemory Cache 或 normalized cache,可以对 query 结果做本地缓存
- 后端:通常需要 resolver 层缓存(比如 Redis),逻辑上和 REST 接近,但需要自己设计 cache key(常用做法是 query hash + 参数)
目前我也看到一些插件,就是将这些 cached key 以类似 rest 的管理方式进行缓存,但是如果真的要走这个程度的话,感觉还是不如走 rest 啊 - DataLoader 缓存:这是 GraphQL 特有的一层。它的目标是解决 N+1 问题(比如同一次请求里多次查询
user(id=1)),通过批量合并与缓存来减少数据库查询。但这个缓存 生命周期只在单次请求内,请求结束就会被清空
如果想跨请求缓存,就必须再接入 Redis/Memcached。换句话说,GraphQL 除了要考虑全局缓存策略,还得额外设计 DataLoader 的缓存周期
服务端配置
下面就是把基础的框架兜起来
简单的说一下,这个项目是一个非常简单的 blog/bbs 类型的项目,entities 只包含了 3 个:user, post 和 comment,主要目标就是为了快速地推一遍 GQL 的功能,因此有些 edge cases 不会做的特别的细
server 算则
目前来说 nodejs 上 graphql 的 server 选择还是有好几个的,本来是想适配 prisma 的,就特地到官网上找了下,有这么四个选项:
- @apollo/server
不太想用,我自己知道这个是比较 heavy 的,我前端也不打算用对应的 client,跳过 - express-graphql
This package is no longer maintained. We recommend using
graphql-httpinstead.
但是我又不确定能不能和 prisma 合作,跳过 - fastify-gql
This package has been deprecated
Author message:
fastify-gql is now renamed to mercurius基于相同理由,跳过
- graphql-yoga
就是你了,皮卡丘!
原因就是这么的简单粗暴,后来实际折腾了一下之后发现,自己的这个选择还是比较正确的,yoga 本身的配置比较简单,同时对插件/中间件的支持、类型推导的支持,和 prisma 的对接都挺方便的。或许其他的工具可能也不差,不过目前 yoga 是满足了我的需求
http 配置
基础配置 http 服务器是比较简单的,官方文档是这么实现的:
import { createServer } from "node:http";
import { createSchema, createYoga } from "graphql-yoga";const yoga = createYoga({schema: createSchema({typeDefs: /* GraphQL */ `type Query {hello: String}`,resolvers: {Query: {hello: () => "Hello from Yoga!",},},}),
});const server = createServer(yoga);server.listen(4000, () => {console.info("Server is running on http://localhost:4000/graphql");
});
从我个人感觉来说,这个配置比 Apollo GraphQL 还要简单一些,毕竟不用折腾 express
socket 配置
但是就像 Apollo server 一样,配置 subscription 就需要额外配置 socket,不过二者都是使用 graphql-ws/use/ws,所以创建的方式也是比较相似的,官方的配置代码如下:
import { createServer } from "node:http";
import { useServer } from "graphql-ws/use/ws";
import { createYoga } from "graphql-yoga";
import { WebSocketServer } from "ws";const yogaApp = createYoga({graphiql: {// Use WebSockets in GraphiQLsubscriptionsProtocol: "WS",},
});// Get NodeJS Server from Yoga
const httpServer = createServer(yogaApp);
// Create WebSocket server instance from our Node server
const wsServer = new WebSocketServer({server: httpServer,path: yogaApp.graphqlEndpoint,
});// Integrate Yoga's Envelop instance and NodeJS server with graphql-ws
useServer({execute: (args: any) => args.rootValue.execute(args),subscribe: (args: any) => args.rootValue.subscribe(args),onSubscribe: async (ctx, _id, params) => {const { schema, execute, subscribe, contextFactory, parse, validate } =yogaApp.getEnveloped({...ctx,req: ctx.extra.request,socket: ctx.extra.socket,params,});const args = {schema,operationName: params.operationName,document: parse(params.query),variableValues: params.variables,contextValue: await contextFactory(),rootValue: {execute,subscribe,},};const errors = validate(args.schema, args.document);if (errors.length) return errors;return args;},},wsServer
);httpServer.listen(4000, () => {console.log("Server is running on port 4000");
});
👀:注意 node 版本,比较新的 node 会出现下面的报错:
Cannot find module ‘graphql-ws/use/ws’ or its corresponding type declarations.
There are types at ‘/Users/__/study/graphql-case-studies/basics/node_modules/graphql-ws/dist/use/ws.d.ts’, but this result could not be resolved under your current ‘moduleResolution’ setting. Consider updating to ‘node16’, ‘nodenext’, or ‘bundler’.ts(2307)
但是等我注意到这点的时候,除了 graphql-ws/use/ws 其他的配置都做好了,再换也挺麻烦的,就先这么过了
这个时候,只要正常配置了 schema,resolvers 和 subscriptions,那么项目就可以正常运行起来了。不过这样的项目还不够工程化—— typeDefs 的实现还比较麻烦,而且也没有配置 codegen,所以没办法完全使用 yoga 中对 TS 的支持功能。而且现在输出的结果也比较的差,没有时间戳,也比较难 debug,接下来就一步步解决这点工程问题
PubSub 配置
Yoga 对 PubSub 的实现也是内置集成的,比起来 Apollo 还需要下载 graphql-subscriptions,Yoga 就不需要,类型推导方面比较容易和 Yoga 整体的适配度比较高
但是换个方向来说,因为没有直接暴露 graphql-subscriptions ,也就无法直接使用底层的 asyncIterableIterator,在刚开始学习研究的时候还花了不少的时间,现在处在一种能用,但是没有能够非常好的完成之前有过的一个设想
基于篇幅原因,codegen/TS 支持这一篇就不会放了,不过这里会简单地提一下 PubSub 的类型定义之类 💦
-
类型定义
这一部分比较简单直观:import type { Post, Comment, EventType } from "../../generated/graphql"; import type { pubsub } from "./pubsub";export type EntityMap = {comment: Comment;post: Post; };export type EventPayload<T> = {type: EventType;data: T; };type GlobalPubSubEvents = {[K in keyof EntityMap]: [EventPayload<EntityMap[K]>]; };type ScopedPubSubEvents = {[K in keyof EntityMap as `${K & string}:${string}`]: [EventPayload<EntityMap[K]>]; };export type PubSubEvents = {count: [number]; } & GlobalPubSubEvents &ScopedPubSubEvents;export type GraphQLContext = {pubsub: typeof pubsub;requestId?: string; };核心想法是可以自动拼接获取
post,comment,post:<id>和comment:<id>这种数据格式,之后如果有其他需要 subscribe,并且遵从同样格式的 entity,只需要在EntityMap中添加即可 -
使用
这个也比较直观,如果不想拆分代码的话,直接创建一个新的 pubSub,然后丢到 context 中即可:import { createPubSub } from "graphql-yoga";export const pubsub = createPubSub<PubSubEvents>();// context 更新const yogaApp = createYoga<GraphQLContext>({schema,graphqlEndpoint: "/graphql",context: (): GraphQLContext => {return { pubsub };},graphiql: {// Use WebSockets in GraphiQLsubscriptionsProtocol: "WS",}, });👀:我是整个项目功能都实现了后,重新去搞类型的时候才发现,
createYoga<GraphQLContext>类型不太准确,不过这块会在后面解决
以实现日常功能,不需要折腾 plugins/middleware 为前提,传GraphQLContext不会产生语法冲突的问题,毕竟这是整体 context 的一个子集 -
publish
其实没想到,实现count这个反而是最难的,其他的功能,直接使用pubSub.publish()即可,但是count是一个 self-ticking 的功能,所以这个就比较头疼
总体来说有两个实现方案,第一个是直接在subscribe中返回一个 async generator 即可,因为 subscribe 的类型是:(property) subscribe: (_parent: Record<PropertyKey, never>, _args: Record<PropertyKey, never>, { pubsub }: GraphQLContext) => Repeater<number, any, unknown>本质上要求返回一个
Repeater<number, any, unknown>,简单来说就是AsyncIterableIterator的一个封装,换句话说可以直接返回一个 generator:export const Subscription: SubscriptionResolvers<GraphQLContext> = {count: {subscribe: async function* () {let i = 0;while (true) {await setTimeout$(1000);yield { count: i++ };}},}, };这是最简单实现一个 self-ticking 功能的实现了:

这不是一个通常的用法,下面一个用法会更简单直观一些:,具体如下:import { pubsub } from "../context/pubsub";export function startMockCountPublisher() {let count = 0;setInterval(() => {pubsub.publish("count", count++);console.log(`[MockPubSub] published count: ${count}`);}, 1000); }这种是确实在 pubsub 上 publish 了一个事件,也是大多数 pubsub 的使用情况
-
subscription
实现如下:count: {subscribe: (_parent, _args, { pubsub }) => {return pubsub.subscribe("count");},resolve: (payload: number) => payload,},这个是大部分 subscription 处理流程所要实现的功能,一个
subscribe和一个resolve,并非使用自绑定的 generator,其返回对象也是 Yoga 封装好的 Repeater,使用上是等价的,只不过后者更加的简单
实现效果如下:

可以看到,这个时候的 UI 是直接 subscribe 了后端的事件流