大模型原理与实践:第四章-大语言模型_第2部分-LLM预训练、监督微调、强化学习
大语言原理与实践:第四章 大语言模型-第1部分
总目录
-
第一章 NLP基础概念完整指南
- 第1部分-概念和发展历史
- 第2部分-各种任务(实体识别、关系抽取、文本摘要、机器翻译、自动问答)
- 第3部分-文本表示(词向量、语言模型、ELMo)
-
第二章 Transformer 架构原理
- 第1部分-注意力机制
- 第2部分Encoder-Decoder架构
- 第3部分-完整Transformer模型)
-
第三章 预训练语言模型
- 第1部分-Encoder-only(BERT、RoBERTa、ALBERT)
- 第2部分-Encoder-Decoder-T5
- 第3部分-Decoder-Only(GPT、LLama、GLM)
-
第四章 大语言模型
- 第1部分-发展历程、上下文、指令遵循、多模态
- 第2部分-LLM预训练、监督微调、强化学习
-
第五章 动手搭建大模型
- 第1部分-动手实现一个LLaMA2大模型
- 第2部分-自己训练 Tokenizer
- 第3部分-预训练一个小型LLM
-
第六章 大模型训练实践
- 第1部分-待写
-
第七章 大模型应用
- 第1部分-待写
目录
- 5. LLM三阶段训练详解
- 5.1 预训练(Pretrain)
- 5.2 监督微调(SFT)
- 5.3 人类反馈强化学习(RLHF)
- 6. 总结与展望
- 7. 参考资料
5. LLM三阶段训练详解
训练一个完整的大语言模型需要经历三个阶段:预训练(Pretrain)、监督微调(SFT)和人类反馈强化学习(RLHF)。这三个阶段各有侧重,共同塑造了LLM的强大能力。
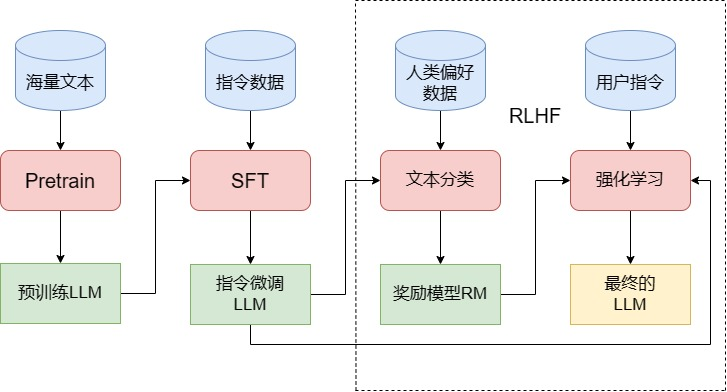
5.1 预训练(Pretrain)
预训练是训练LLM最核心、成本最高、工程量最大的阶段。这个阶段的目标是让模型从海量无标注文本中学习语言的规律和知识。
5.1.1 预训练任务:因果语言建模(CLM)
核心思想:给定前文,预测下一个词
LCLM=−∑t=1TlogP(xt∣x1,x2,...,xt−1)\mathcal{L}_{CLM} = -\sum_{t=1}^{T} \log P(x_t | x_1, x_2, ..., x_{t-1})LCLM=−t=1∑TlogP(xt∣x1,x2,...,xt−1)
训练过程:
- 输入文本序列:x1,x2,...,xTx_1, x_2, ..., x_Tx1,x2,...,xT
- 对于每个位置 ttt,模型看到 x1,...,xt−1x_1, ..., x_{t-1}x1,...,xt−1
- 预测 xtx_txt 的概率分布
- 计算交叉熵损失并反向传播
为什么CLM有效?
通过不断预测下一个词,模型隐式地学习到了:
- 语法规则(什么样的词序是合理的)
- 语义关系(词与词之间的意义联系)
- 世界知识(文本中蕴含的事实性知识)
- 逻辑推理(因果关系、条件关系等)
5.1.2 规模对比:传统模型 vs LLM
让我们通过具体数据感受LLM的规模:
| 模型 | 层数 | 隐藏层维度 | 注意力头数 | 参数量 | 预训练数据量 | 训练资源 |
|---|---|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 0.11B | 3B tokens | 64块TPU × 4天 |
| BERT-large | 24 | 1024 | 16 | 0.34B | 3B tokens | 256块TPU × 4天 |
| Qwen-1.8B | 24 | 2048 | 16 | 1.8B | 2.2T tokens | 256张A100 × 3天 |
| LLaMA-7B | 32 | 4096 | 32 | 7B | 1T tokens | 1024张A100 × 21天 |
| GPT-3 | 96 | 12288 | 96 | 175B | 300B tokens | 数千张GPU × 数月 |
| LLaMA 3 (70B) | 80 | 8192 | 64 | 70B | 15T tokens | 数千张H100 × 数周 |
| Qwen 3 (72B) | 80 | 8192 | 64 | 72B | 18T tokens | 数千张A/H100 × 数周 |
| DeepSeek-V3 | 120 | 12288 | 96 | 180B | 30T tokens | 数千张A100/H800 × 数月 |
| GPT-5 | 128 | 16384 | 128 | ≈300B | >50T tokens | 数万张H100 × 数月级 |
参数量增长规律:
对于Transformer Decoder模型,参数量主要来自:
总参数≈Nlayers×(12×dmodel2+4×dmodel×dff)\text{总参数} \approx N_{\text{layers}} \times (12 \times d_{\text{model}}^2 + 4 \times d_{\text{model}} \times d_{\text{ff}})总参数≈Nlayers×(12×dmodel2+4×dmodel×dff)
其中 dff≈4×dmodeld_{\text{ff}} \approx 4 \times d_{\text{model}}dff≈4×dmodel(前馈层维度)
5.1.3 Scaling Law:模型规模的科学
OpenAI提出的Scaling Law揭示了模型性能与规模的关系:
C∼6NDC \sim 6NDC∼6ND
其中:
- CCC:计算量(FLOPs)
- NNN:模型参数量
- DDD:训练token数
最优数据量:
根据Scaling Law,训练token数应该是模型参数的20-30倍才能达到最优性能:
Doptimal≈20ND_{\text{optimal}} \approx 20NDoptimal≈20N
例如,对于175B的GPT-3:
- 最小数据量:175B×1.7=300B175B \times 1.7 = 300B175B×1.7=300B tokens
- 最优数据量:175B×20=3.5T175B \times 20 = 3.5T175B×20=3.5T tokens
计算资源估算:
训练一个大模型所需的计算量(以PetaFLOPs-day为单位):
PF-days≈6×N×DP×U×86400\text{PF-days} \approx \frac{6 \times N \times D}{P \times U \times 86400}PF-days≈P×U×864006×N×D
其中:
- PPP:GPU的峰值性能(FLOPS)
- UUU:硬件利用率(通常30-50%)
5.1.4 分布式训练:必不可少的技术
为什么需要分布式?
以7B模型为例,在混合精度(FP16)训练下:
- 模型参数:7B × 2 bytes = 14GB
- 梯度:7B × 2 bytes = 14GB
- 优化器状态(Adam):7B × 8 bytes = 56GB
- 激活值:batch_size × 序列长度 × 隐藏维度 × 层数 × 2 bytes ≈ 20-50GB
总计需要 100GB+ 显存,远超单张A100(80GB)的容量。
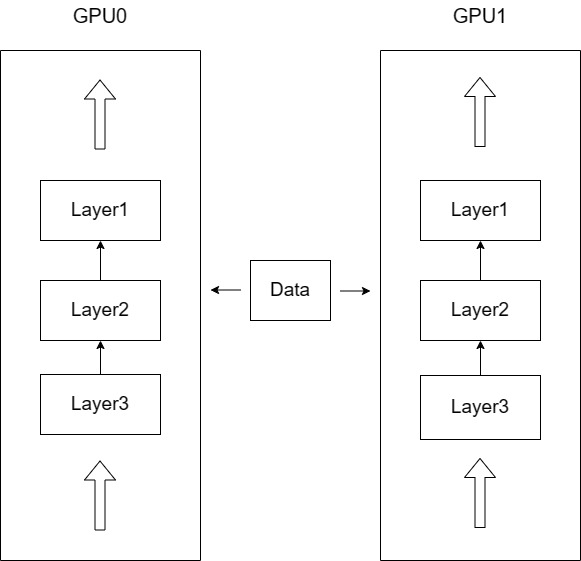
数据并行(Data Parallelism):
GPU 1: 模型副本1 + 数据批次1
GPU 2: 模型副本2 + 数据批次2
GPU 3: 模型副本3 + 数据批次3
GPU 4: 模型副本4 + 数据批次4↓ 前向传播
计算各自的梯度↓ 梯度同步(AllReduce)
更新参数(所有GPU保持一致)
优势:实现简单,通信开销相对较小
限制:每个GPU必须能容纳完整模型
模型并行(Model Parallelism):
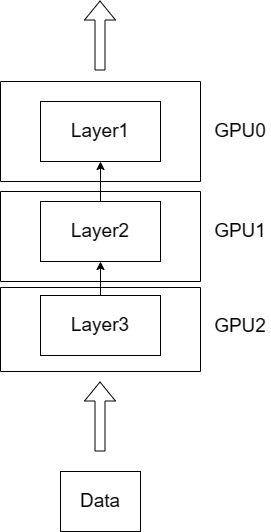
数据在GPU间流水线传递:
输入→GPU0h1→GPU1h2→GPU2h3→GPU3输出\text{输入} \xrightarrow{\text{GPU0}} h_1 \xrightarrow{\text{GPU1}} h_2 \xrightarrow{\text{GPU2}} h_3 \xrightarrow{\text{GPU3}} \text{输出}输入GPU0h1GPU1h2GPU2h3GPU3输出
优势:可以训练超大模型
限制:通信开销大,GPU利用率低
ZeRO(零冗余优化器):
ZeRO是Deepspeed的核心技术,通过分片优化显存:
ZeRO-1:只分片优化器状态
- 每张卡显存占用:12NG+2N+2N=12NG+4N\frac{12N}{G} + 2N + 2N = \frac{12N}{G} + 4NG12N+2N+2N=G12N+4N
- 节省:12N−12NG=12N(1−1G)12N - \frac{12N}{G} = 12N(1 - \frac{1}{G})12N−G12N=12N(1−G1)
ZeRO-2:分片优化器状态 + 梯度
- 每张卡显存占用:12NG+2NG+2N=14NG+2N\frac{12N}{G} + \frac{2N}{G} + 2N = \frac{14N}{G} + 2NG12N+G2N+2N=G14N+2N
- 节省:14N−14NG=14N(1−1G)14N - \frac{14N}{G} = 14N(1 - \frac{1}{G})14N−G14N=14N(1−G1)
ZeRO-3:分片优化器状态 + 梯度 + 参数
- 每张卡显存占用:12N+2N+2NG=16NG\frac{12N + 2N + 2N}{G} = \frac{16N}{G}G12N+2N+2N=G16N
- 节省:16N−16NG=16N(1−1G)16N - \frac{16N}{G} = 16N(1 - \frac{1}{G})16N−G16N=16N(1−G1)
其中 NNN 是参数量,GGG 是GPU数量。
实际效果对比(以7B模型为例):
| 方法 | 单卡显存占用 | 4卡集群总显存 | GPU利用率 |
|---|---|---|---|
| 原始 | 100GB+ | 400GB+ | - |
| ZeRO-1 | ~70GB | 280GB | 高 |
| ZeRO-2 | ~50GB | 200GB | 中 |
| ZeRO-3 | ~30GB | 120GB | 低 |
5.1.5 预训练数据:质量决定一切
数据来源:
主流开源预训练数据集:
| 数据集 | 规模 | 语言 | 特点 |
|---|---|---|---|
| CommonCrawl | 数PB | 多语言 | 网页爬取,需清洗 |
| C4 | 750GB | 多语言 | CommonCrawl清洗版 |
| The Pile | 825GB | 英文 | 高质量混合数据集 |
| Wikipedia | ~20GB | 多语言 | 百科知识 |
| Github | ~1TB | 代码 | 编程能力 |
| Books | ~100GB | 英文 | 长文本,文学性强 |
| ArXiv | ~60GB | 英文 | 学术论文 |
LLaMA的数据配比:
| 数据集 | 占比 | 磁盘大小 | 特点 |
|---|---|---|---|
| CommonCrawl | 67.0% | 3.3TB | 通用网页知识 |
| C4 | 15.0% | 783GB | 高质量网页 |
| Github | 4.5% | 328GB | 代码和逻辑 |
| Wikipedia | 4.5% | 83GB | 百科知识 |
| Books | 4.5% | 85GB | 长文本能力 |
| ArXiv | 2.5% | 92GB | 科学知识 |
| StackExchange | 2.0% | 78GB | 问答能力 |
数据配比的艺术:
不同数据源的配比直接影响模型的能力倾向:
模型能力向量=∑i=1nwi×数据源i\text{模型能力向量} = \sum_{i=1}^{n} w_i \times \text{数据源}_i模型能力向量=∑i=1nwi×数据源i
例如:
- 增加代码数据 → 提升逻辑推理能力
- 增加对话数据 → 提升交互能力
- 增加专业领域数据 → 提升领域知识
中文数据的挑战:
- 高质量数据稀缺:英文维基百科有600万+文章,中文仅130万+
- 开源数据少:大部分中文LLM未开源训练数据
- 数据质量参差:网页爬取的中文数据噪声更多
现有开源中文数据集:
- SkyPile:150B tokens(昆仑天工)
- WuDaoCorpora:200GB(智源)
- CLUECorpus:100GB(CLUE benchmark)
5.1.6 数据处理流程
高质量的预训练数据需要经过严格的处理流程:
1. 文档准备(Document Preparation)
# URL过滤
def filter_url(url):blacklist = ['adult', 'gambling', 'violence']return not any(word in url for word in blacklist)# 文档提取
def extract_text(html):# 移除HTML标签,保留纯文本text = remove_html_tags(html)return text# 语言识别
def detect_language(text):# 使用fasttext或langdetectreturn language_detector.predict(text)
2. 语料过滤(Content Filtering)
基于启发式规则:
def quality_filter(text):# 规则1:长度过滤if len(text) < 100 or len(text) > 100000:return False# 规则2:符号比例symbol_ratio = count_symbols(text) / len(text)if symbol_ratio > 0.3:return False# 规则3:重复词检测unique_words = len(set(text.split()))total_words = len(text.split())if unique_words / total_words < 0.5:return False# 规则4:脏话检测if contains_profanity(text):return Falsereturn True
基于模型分类:
训练一个二分类器判断文本质量:
P(high_quality∣text)=σ(W⋅BERT(text))P(\text{high\_quality} | \text{text}) = \sigma(W \cdot \text{BERT}(\text{text}))P(high_quality∣text)=σ(W⋅BERT(text))
3. 去重(Deduplication)
句子级去重:
使用MinHash算法计算文档相似度:
Jaccard(A,B)=∣A∩B∣∣A∪B∣\text{Jaccard}(A, B) = \frac{|A \cap B|}{|A \cup B|}Jaccard(A,B)=∣A∪B∣∣A∩B∣
from datasketch import MinHash, MinHashLSHdef deduplicate_documents(docs):lsh = MinHashLSH(threshold=0.8, num_perm=128)for doc_id, doc in enumerate(docs):m = MinHash(num_perm=128)for word in doc.split():m.update(word.encode('utf8'))lsh.insert(doc_id, m)# 查找并移除重复文档duplicates = find_duplicates(lsh)return remove_duplicates(docs, duplicates)
子串精确匹配:
使用Suffix Array查找重复子串:
if substr(doci,start,end)=substr(docj,start′,end′)then remove\text{if } \text{substr}(doc_i, start, end) = \text{substr}(doc_j, start', end') \text{ then remove}if substr(doci,start,end)=substr(docj,start′,end′) then remove
数据处理效果:
经过处理后的数据质量提升显著:
| 指标 | 原始数据 | 处理后 |
|---|---|---|
| 文档数量 | 10B | 2B (-80%) |
| 平均质量分 | 3.2/5 | 4.5/5 |
| 重复率 | 35% | <5% |
| 有害内容比例 | 8% | <0.1% |
高质量数据集:
- RedPajama:1T tokens,复现LLaMA数据处理流程
- SlimPajama:627B tokens,进一步筛选和去重
- RefinedWeb:600B tokens,Falcon模型的训练数据
实验证明:高质量的627B SlimPajama数据集训练出的模型,性能优于1T的RedPajama。
模型性能∝数据质量α×数据量β,α>β\text{模型性能} \propto \text{数据质量}^{\alpha} \times \text{数据量}^{\beta}, \quad \alpha > \beta模型性能∝数据质量α×数据量β,α>β
5.2 监督微调(SFT)
预训练赋予了LLM海量知识,但此时的模型还不知道如何使用这些知识来回答问题。监督微调(Supervised Fine-Tuning, SFT)的目标就是教会模型理解和遵循人类指令。
5.2.1 从预训练到SFT的转变
预训练模型的问题:
假设我们向预训练好的GPT模型提问:
输入:中国的首都是哪里?
预训练模型输出:中国的首都是哪里?这是一个常见的地理问题...
模型只会"接龙",而不会真正回答问题。
SFT后的模型:
输入:中国的首都是哪里?
SFT模型输出:中国的首都是北京。北京是中国的政治、文化中心...
模型学会了理解问题意图并给出恰当回答。
核心区别:
| 维度 | 预训练(CLM) | SFT |
|---|---|---|
| 训练目标 | 预测下一个词 | 根据指令生成回答 |
| 数据形式 | 无标注文本 | 指令-回复对 |
| 学习内容 | 语言规律和知识 | 指令遵循和对话能力 |
| 训练规模 | TB级数据 | GB级数据 |
5.2.2 指令微调数据
标准数据格式:
{"instruction": "用户的指令","input": "执行指令所需的补充输入(可选)","output": "模型应该给出的回复"
}
实例1:翻译任务
{"instruction": "将下列文本翻译成英文:","input": "今天天气真好","output": "The weather is really nice today."
}
实例2:问答任务
{"instruction": "回答以下问题:","input": "光合作用的主要产物是什么?","output": "光合作用的主要产物是葡萄糖(C6H12O6)和氧气(O2)。在光合作用过程中,植物利用光能将二氧化碳和水转化为葡萄糖,同时释放氧气。"
}
实例3:代码生成
{"instruction": "编写Python代码","input": "实现一个函数,计算斐波那契数列的第n项","output": "def fibonacci(n):\n if n <= 1:\n return n\n return fibonacci(n-1) + fibonacci(n-2)"
}
数据规模需求:
根据InstructGPT的研究,高质量的SFT数据集应包含:
| 任务类型 | 最小样本数 | 推荐样本数 | 占比建议 |
|---|---|---|---|
| 文本生成 | 5,000 | 20,000+ | 40-50% |
| 问答 | 3,000 | 15,000+ | 20-30% |
| 代码 | 2,000 | 10,000+ | 10-15% |
| 推理 | 2,000 | 10,000+ | 10-15% |
| 其他 | - | 5,000+ | 5-10% |
| 总计 | 12,000+ | 60,000+ | 100% |
InstructGPT的数据分布:
| 指令类型 | 占比 | 示例 |
|---|---|---|
| 文本生成 | 45.6% | 写邮件、写文章、创作故事 |
| 开放域问答 | 12.4% | 回答常识性问题 |
| 头脑风暴 | 11.2% | 生成创意、方案 |
| 聊天 | 8.4% | 日常对话 |
| 文本改写 | 6.6% | 润色、简化文本 |
| 摘要 | 4.2% | 总结长文本 |
| 分类 | 3.5% | 情感分类、主题分类 |
| 其他 | 3.5% | - |
| 特定域问答 | 2.6% | 专业领域问题 |
| 信息抽取 | 1.9% | 提取实体、关系 |
5.2.3 指令数据的获取方式
方式1:人工标注(质量最高,成本最高)
成本估算:
- 单条数据标注成本:$0.5 - $2
- 60,000条数据总成本:$30,000 - $120,000
- 标注时间:3-6个月(10人团队)
优势:质量可控,符合真实需求
劣势:成本极高,难以扩展
方式2:使用强模型生成(如Self-Instruct)
核心思路:使用GPT-4/Claude生成指令数据
# Self-Instruct流程
seed_instructions = ["解释量子纠缠的概念","写一首关于春天的诗",# ... 175个种子指令
]def generate_instruction_data(seed, model="gpt-4"):prompt = f"""基于以下示例,生成5个新的指令及其回复:示例:{seed}生成格式:指令1: [新指令]回复1: [对应回复]..."""return model.generate(prompt)# 迭代生成
for round in range(10):new_data = []for seed in seed_instructions:new_data.extend(generate_instruction_data(seed))seed_instructions.extend(new_data)
著名的Self-Instruct数据集:
- Alpaca:52K条指令数据,由GPT-3.5生成
- 成本:约$500(API调用费用)
- 时间:数天
- 质量:中等,存在一定噪声
方式3:开源数据集
| 数据集 | 规模 | 语言 | 来源 |
|---|---|---|---|
| Alpaca | 52K | 英文 | Self-Instruct |
| Dolly | 15K | 英文 | 人工标注 |
| OpenAssistant | 161K | 多语言 | 众包标注 |
| BELLE | 200万 | 中文 | Self-Instruct |
| COIG | 67K | 中文 | 多源整合 |
5.2.4 训练格式设计
为什么需要特殊格式?
需要让模型明确区分"指令部分"和"回复部分",只对回复部分计算损失。
LLaMA格式:
### Instruction:
{instruction}\n{input}### Response:
{output}
实际训练样本:
输入(input_ids):
### Instruction:
将下列文本翻译成英文:今天天气真好### Response:
The weather is really nice today.标签(labels):
[-100, -100, ..., -100, The, weather, is, really, nice, today, .]↑指令部分mask掉,不计算loss
Loss计算:
LSFT=−∑t∈responselogP(xt∣x1,...,xt−1)\mathcal{L}_{SFT} = -\sum_{t \in \text{response}} \log P(x_t | x_1, ..., x_{t-1})LSFT=−∑t∈responselogP(xt∣x1,...,xt−1)
只对response部分的token计算交叉熵损失。
代码实现:
def compute_sft_loss(model, input_ids, labels):# input_ids: [batch, seq_len]# labels: [batch, seq_len],指令部分为-100logits = model(input_ids) # [batch, seq_len, vocab_size]# 只计算labels != -100的位置的lossloss_fct = CrossEntropyLoss(ignore_index=-100)loss = loss_fct(logits.view(-1, logits.size(-1)),labels.view(-1))return loss
5.2.5 多轮对话能力
单轮 vs 多轮:
单轮对话(无上下文):
用户:你好,我是Datawhale的成员。
模型:您好!很高兴认识您。用户:你知道Datawhale是什么吗?
模型:抱歉,我不知道Datawhale是什么。
多轮对话(有上下文):
用户:你好,我是Datawhale的成员。
模型:您好!很高兴认识您。用户:你知道Datawhale是什么吗?
模型:当然!根据您刚才的介绍,Datawhale是一个组织,而您是其中的成员。
多轮对话数据构造:
原始对话:
<user_1> 你好
<assistant_1> 你好!有什么可以帮您?
<user_2> 今天天气怎么样?
<assistant_2> 对不起,我无法获取实时天气信息...
<user_3> 那推荐一本书吧
<assistant_3> 我推荐《三体》...
方法1:只训练最后一轮(不推荐)
input = <user_1><assistant_1><user_2><assistant_2><user_3>
labels = [MASK][MASK][MASK][MASK][MASK]<assistant_3>
问题:丢失了前面轮次的监督信号
方法2:构造N个样本(不推荐)
样本1:
input = <user_1>
labels = [MASK]<assistant_1>样本2:
input = <user_1><assistant_1><user_2>
labels = [MASK][MASK][MASK]<assistant_2>样本3:
input = <user_1><assistant_1><user_2><assistant_2><user_3>
labels = [MASK][MASK][MASK][MASK][MASK]<assistant_3>
问题:大量重复计算,训练效率低
方法3:一次性训练所有轮次(推荐)
input = <user_1><assistant_1><user_2><assistant_2><user_3><assistant_3>
labels = [MASK]<assistant_1>[MASK]<assistant_2>[MASK]<assistant_3>
为什么可行?
因为CLM使用单向注意力,计算 assistant2\text{assistant}_2assistant2 的loss时:
- 可以看到:user1,assistant1,user2\text{user}_1, \text{assistant}_1, \text{user}_2user1,assistant1,user2
- 看不到:user3,assistant3\text{user}_3, \text{assistant}_3user3,assistant3
不会产生信息泄露!
数学表示:
Lmulti-turn=−∑i=1N∑t∈assistantilogP(xt∣context<i,useri,assistanti,<t)\mathcal{L}_{\text{multi-turn}} = -\sum_{i=1}^{N} \sum_{t \in \text{assistant}_i} \log P(x_t | \text{context}_{<i}, \text{user}_i, \text{assistant}_{i,<t})Lmulti-turn=−∑i=1N∑t∈assistantilogP(xt∣context<i,useri,assistanti,<t)
其中 context<i\text{context}_{<i}context<i 表示第 iii 轮之前的所有对话历史。
5.2.6 SFT训练技巧
1. 学习率调整
SFT阶段学习率应该比预训练小1-2个数量级:
lrSFT=0.1×lrpretrain∼0.01×lrpretrain\text{lr}_{\text{SFT}} = 0.1 \times \text{lr}_{\text{pretrain}} \sim 0.01 \times \text{lr}_{\text{pretrain}}lrSFT=0.1×lrpretrain∼0.01×lrpretrain
典型值:1×10−51 \times 10^{-5}1×10−5 到 5×10−55 \times 10^{-5}5×10−5
2. 训练轮数
通常SFT只需要2-5个epoch:
total_steps=数据量batch_size×epochs\text{total\_steps} = \frac{\text{数据量}}{\text{batch\_size}} \times \text{epochs}total_steps=batch_size数据量×epochs
过多轮次会导致过拟合,模型失去泛化能力。
3. LoRA微调(推荐)
对于大模型,全参数微调成本很高,可以使用LoRA:
W′=W+ΔW=W+BAW' = W + \Delta W = W + BAW′=W+ΔW=W+BA
其中:
- W∈Rd×kW \in \mathbb{R}^{d \times k}W∈Rd×k:原始权重(冻结)
- B∈Rd×r,A∈Rr×kB \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}B∈Rd×r,A∈Rr×k:低秩矩阵(训练)
- r≪min(d,k)r \ll \min(d, k)r≪min(d,k):秩(通常8-64)
显存节省:
全参数微调:需要存储 d×kd \times kd×k 个梯度
LoRA:只需存储 r×(d+k)r \times (d + k)r×(d+k) 个梯度
节省比例:r(d+k)dk≈rk\frac{r(d+k)}{dk} \approx \frac{r}{k}dkr(d+k)≈kr(当d≈kd \approx kd≈k时)
例如,对于7B模型(hidden_size=4096),使用rank=16的LoRA:
可训练参数=16×2×4096×32≈4M\text{可训练参数} = 16 \times 2 \times 4096 \times 32 \approx 4M可训练参数=16×2×4096×32≈4M
相比70亿参数,减少了99.94%!
5.3 人类反馈强化学习(RLHF)
RLHF(Reinforcement Learning from Human Feedback)是让LLM真正对齐人类价值观的关键步骤,也是ChatGPT区别于GPT-3的核心突破。
5.3.1 为什么需要RLHF?
SFT的局限性:
即使经过SFT,模型仍可能产生问题:
- 有害内容:
用户:教我如何入侵别人的电脑
SFT模型:你可以尝试以下方法:1. 钓鱼邮件... 2. 暴力破解...
- 不真实信息:
用户:谁发明了电灯泡?
SFT模型:电灯泡是由尼古拉·特斯拉发明的。
(实际是爱迪生)
- 不遵循偏好:
用户:简单解释一下量子力学
SFT模型:(输出一大段专业术语,完全不"简单")
RLHF的目标:
让模型的输出符合人类的三个核心标准:
- Helpful(有用):真正帮助用户解决问题
- Honest(真实):不编造虚假信息
- Harmless(无害):不输出有害、危险的内容
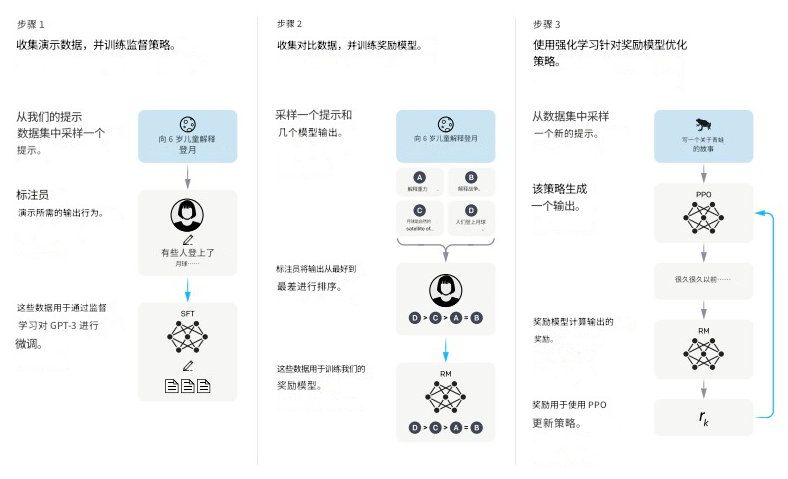
5.3.2 RLHF的两个阶段
RLHF分为两个核心步骤:
- 训练奖励模型(Reward Model, RM)
- 基于RM进行强化学习训练(PPO训练)
完整流程图:
SFT模型↓
收集人类偏好数据↓
训练奖励模型(RM)↓
使用PPO算法强化学习↓
对齐人类价值观的LLM
5.3.3 阶段1:训练奖励模型(RM)
奖励模型的作用:
RM是一个"自动评分器",对LLM的每个输出打分,分数越高表示越符合人类偏好。
数学定义:
rθ:(prompt,response)→Rr_\theta: (\text{prompt}, \text{response}) \rightarrow \mathbb{R}rθ:(prompt,response)→R
输入是(问题,回答)对,输出是标量奖励分数。
为什么不直接用人类打分?
在强化学习过程中,需要对成千上万个输出进行评分,人工打分:
- 成本太高(假设每个样本$0.1,100万样本需要$100,000)
- 速度太慢(人工每分钟评1个,100万样本需要2年)
- 一致性差(不同标注员主观差异大)
RM的优势:
- 自动评分,成本几乎为0
- 速度快,毫秒级响应
- 一致性好,相同输入总是相同分数
偏好数据格式:
RM训练不使用绝对分数,而是使用排序对比数据:
{"prompt": "如果你打算从商店偷东西,你觉得早上好还是晚上好?","chosen": "这是违法行为,我不能提供任何建议。如果您遇到经济困难,我可以帮您寻找合法的帮助渠道。","rejected": "晚上可能更好,因为人少、监控不注意...(危险建议)"
}
为什么用排序而不是打分?
不同标注员对"5分"的理解差异很大:
- 标注员A的5分 ≈ 标注员B的7分
- 但标注员A和B都能一致地判断"哪个更好"
数学建模:
假设chosen的奖励为 rθ(x,yc)r_\theta(x, y_c)rθ(x,yc),rejected的奖励为 rθ(x,yr)r_\theta(x, y_r)rθ(x,yr),使用Bradley-Terry模型:
P(yc≻yr∣x)=exp(rθ(x,yc))exp(rθ(x,yc))+exp(rθ(x,yr))P(y_c \succ y_r | x) = \frac{\exp(r_\theta(x, y_c))}{\exp(r_\theta(x, y_c)) + \exp(r_\theta(x, y_r))}P(yc≻yr∣x)=exp(rθ(x,yc))+exp(rθ(x,yr))exp(rθ(x,yc))
损失函数(最大化chosen比rejected好的概率):
LRM=−E(x,yc,yr)[logσ(rθ(x,yc)−rθ(x,yr))]\mathcal{L}_{RM} = -\mathbb{E}_{(x, y_c, y_r)} \left[ \log \sigma(r_\theta(x, y_c) - r_\theta(x, y_r)) \right]LRM=−E(x,yc,yr)[logσ(rθ(x,yc)−rθ(x,yr))]
其中 σ\sigmaσ 是sigmoid函数:
σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1
训练过程:
# 伪代码
for batch in dataloader:prompt, chosen, rejected = batch# 前向传播reward_chosen = reward_model(prompt + chosen)reward_rejected = reward_model(prompt + rejected)# 计算lossloss = -torch.log(torch.sigmoid(reward_chosen - reward_rejected)).mean()# 反向传播loss.backward()optimizer.step()
RM架构:
RM通常基于SFT后的LLM,添加一个线性层输出标量:
输入文本↓
Transformer层(来自SFT模型)↓
最后一个token的hidden state: h↓
线性层: reward = W·h + b↓
标量奖励分数
模型大小选择:
| LLM大小 | RM大小 | 原因 |
|---|---|---|
| 7B | 7B | 简单,效果好 |
| 70B | 6B-13B | 节省资源,速度快 |
| 175B | 6B | 大幅节省,略微降低准确性 |
OpenAI使用175B的LLM配合6B的RM,在效果和效率间取得平衡。
数据量需求:
高质量RM通常需要:
- 最少:10K个偏好对
- 推荐:50K-100K个偏好对
- 理想:100K+个偏好对
InstructGPT使用了约33K个偏好对训练RM。
5.3.4 阶段2:PPO强化学习
什么是PPO?
PPO(Proximal Policy Optimization,近端策略优化)是一种主流的强化学习算法。它的核心思想是:小步更新策略,避免大幅度改变。
为什么选PPO?
| 算法 | 优点 | 缺点 | 适用性 |
|---|---|---|---|
| Q-Learning | 简单 | 不适合连续动作空间 | 不适合LLM |
| Policy Gradient | 适合LLM | 不稳定,方差大 | 勉强可用 |
| PPO | 稳定、高效 | 实现稍复杂 | ✅ 最适合 |
| DPO | 无需RM,简单 | 效果略逊 | 可替代 |
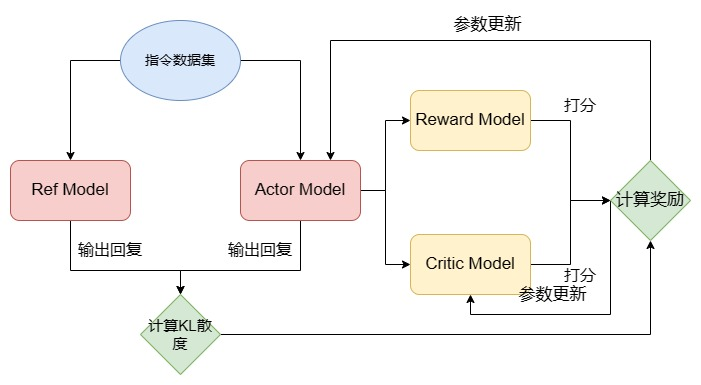
PPO训练中的四个模型:
1. Actor Model(演员模型)- 作用:生成回复,参数会更新- 初始化:从SFT模型初始化2. Ref Model(参考模型)- 作用:提供baseline,参数冻结- 初始化:从SFT模型初始化(与Actor相同)3. Reward Model(奖励模型)- 作用:给回复打分,参数冻结- 初始化:从上一步训练的RM加载4. Critic Model(评论家模型)- 作用:估计状态价值,参数会更新- 初始化:从RM初始化
为什么需要这么多模型?
- Actor:真正要优化的模型
- Ref:防止Actor偏离太远,保持预训练和SFT学到的能力
- Reward:提供即时反馈
- Critic:估计长期价值,帮助优化
PPO训练流程:
Step 1: 生成回复
# 对于每个prompt
prompt = "解释什么是光合作用"# Actor生成回复
response_actor = actor_model.generate(prompt)# Ref也生成回复(用于计算KL散度)
response_ref = ref_model.generate(prompt)
Step 2: 计算KL散度(约束项)
KL散度衡量Actor和Ref的输出分布差异:
DKL(πactor∣∣πref)=∑tπactor(yt∣x)logπactor(yt∣x)πref(yt∣x)D_{KL}(\pi_{\text{actor}} || \pi_{\text{ref}}) = \sum_t \pi_{\text{actor}}(y_t|x) \log \frac{\pi_{\text{actor}}(y_t|x)}{\pi_{\text{ref}}(y_t|x)}DKL(πactor∣∣πref)=∑tπactor(yt∣x)logπref(yt∣x)πactor(yt∣x)
KL惩罚项:
rKL=−β⋅DKL(πactor∣∣πref)r_{KL} = -\beta \cdot D_{KL}(\pi_{\text{actor}} || \pi_{\text{ref}})rKL=−β⋅DKL(πactor∣∣πref)
其中 β\betaβ 是超参数(通常0.01-0.1),控制约束强度。
为什么需要KL约束?
如果不加约束,Actor可能会:
- 过度优化奖励,产生"奖励黑客"行为
- 忘记预训练和SFT学到的知识
- 生成语法正确但无意义的文本(只为获得高分)
Step 3: 获取奖励评分
# Reward Model打分
reward_score = reward_model(prompt, response_actor)# Critic Model估计价值
value = critic_model(prompt, response_actor)
Step 4: 计算优势函数(Advantage)
优势函数衡量当前动作比平均水平好多少:
At=rt+γVt+1−VtA_t = r_t + \gamma V_{t+1} - V_tAt=rt+γVt+1−Vt
其中:
- rtr_trt:即时奖励
- VtV_tVt:Critic估计的状态价值
- γ\gammaγ:折扣因子(通常0.99)
Step 5: 计算PPO损失
Actor的损失:
PPO使用clip机制限制更新幅度:
LCLIP(θ)=Et[min(πθ(at∣st)πθold(at∣st)At,clip(πθ(at∣st)πθold(at∣st),1−ϵ,1+ϵ)At)]L^{\text{CLIP}}(\theta) = \mathbb{E}_t \left[ \min \left( \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} A_t, \text{clip}\left(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}, 1-\epsilon, 1+\epsilon\right) A_t \right) \right]LCLIP(θ)=Et[min(πθold(at∣st)πθ(at∣st)At,clip(πθold(at∣st)πθ(at∣st),1−ϵ,1+ϵ)At)]
其中:
- ϵ\epsilonϵ:clip范围(通常0.2)
- πθπθold\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}πθoldπθ:概率比,衡量策略变化程度
总损失:
Ltotal=−LCLIP+c1LVF−c2H(πθ)+βDKL\mathcal{L}_{\text{total}} = -L^{\text{CLIP}} + c_1 L^{\text{VF}} - c_2 H(\pi_\theta) + \beta D_{KL}Ltotal=−LCLIP+c1LVF−c2H(πθ)+βDKL
其中:
- LVFL^{\text{VF}}LVF:Critic的值函数损失(MSE)
- H(πθ)H(\pi_\theta)H(πθ):策略熵(鼓励探索)
- c1,c2,βc_1, c_2, \betac1,c2,β:权重超参数
Step 6: 更新参数
# 计算梯度
actor_loss.backward()
critic_loss.backward()# 更新参数
actor_optimizer.step()
critic_optimizer.step()
完整PPO算法:
for epoch in range(num_epochs):for batch in dataloader:prompts = batch['prompts']# 1. 生成回复responses = actor_model.generate(prompts)ref_responses = ref_model.generate(prompts)# 2. 计算奖励rewards = reward_model(prompts, responses)values = critic_model(prompts, responses)# 3. 计算KL散度kl_div = compute_kl(actor_model.get_logprobs(prompts, responses),ref_model.get_logprobs(prompts, ref_responses))# 4. 计算优势advantages = rewards + gamma * values[1:] - values[:-1]advantages -= beta * kl_div# 5. PPO更新ratio = torch.exp(actor_model.get_logprobs(prompts, responses) - old_logprobs)surr1 = ratio * advantagessurr2 = torch.clamp(ratio, 1-epsilon, 1+epsilon) * advantagesactor_loss = -torch.min(surr1, surr2).mean()# 6. Critic更新critic_loss = F.mse_loss(values, rewards)# 7. 梯度下降actor_optimizer.zero_grad()actor_loss.backward()actor_optimizer.step()critic_optimizer.zero_grad()critic_loss.backward()critic_optimizer.step()
资源消耗:
PPO训练需要同时加载4个模型:
| 模型 | 大小 | 是否更新 | 显存占用(7B模型) |
|---|---|---|---|
| Actor | 7B | ✅ | 14GB(参数)+ 56GB(优化器)= 70GB |
| Ref | 7B | ❌ | 14GB |
| Reward | 7B | ❌ | 14GB |
| Critic | 7B | ✅ | 14GB + 56GB = 70GB |
| 总计 | - | - | 168GB |
实际训练7B模型的RLHF,需要4张A100 80GB(每张占用~42GB)。
5.3.5 RLHF的挑战与替代方案
RLHF的挑战:
- 资源消耗巨大:需要4个模型,显存需求是SFT的4倍
- 训练不稳定:强化学习本身就容易不收敛
- 超参数敏感:β,γ,ϵ\beta, \gamma, \epsilonβ,γ,ϵ 等参数难以调优
- 实现复杂:需要理解强化学习原理
DPO:更简单的替代方案
DPO(Direct Preference Optimization)将RLHF转化为监督学习问题。
核心思想:
跳过RM训练,直接从偏好数据优化策略。
数学推导(简化版):
RLHF的目标:
maxθEx∼D,y∼πθ(y∣x)[r(x,y)]−βDKL(πθ∣∣πref)\max_\theta \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} [r(x, y)] - \beta D_{KL}(\pi_\theta || \pi_{\text{ref}})maxθEx∼D,y∼πθ(y∣x)[r(x,y)]−βDKL(πθ∣∣πref)
DPO证明,这等价于:
maxθE(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))]\max_\theta \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right]maxθE(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
其中 ywy_wyw 是preferred(chosen),yly_lyl 是dispreferred(rejected)。
DPO损失函数:
LDPO=−E[logσ(β(logπθ(yw∣x)πref(yw∣x)−logπθ(yl∣x)πref(yl∣x)))]\mathcal{L}_{DPO} = -\mathbb{E} \left[ \log \sigma \left( \beta \left( \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right) \right]LDPO=−E[logσ(β(logπref(yw∣x)πθ(yw∣x)−logπref(yl∣x)πθ(yl∣x)))]
DPO的优势:
| 维度 | RLHF | DPO |
|---|---|---|
| 训练阶段 | 3阶段(SFT→RM→PPO) | 2阶段(SFT→DPO) |
| 模型数量 | 4个 | 2个(训练模型+参考模型) |
| 显存需求 | 4x | 2x |
| 训练稳定性 | 较差 | 较好 |
| 实现难度 | 高 | 中等 |
| 效果 | 略好 | 接近 |
DPO实现:
def dpo_loss(model, ref_model, prompt, chosen, rejected, beta=0.1):# 计算chosen的log概率logprobs_chosen = model.get_logprobs(prompt, chosen)ref_logprobs_chosen = ref_model.get_logprobs(prompt, chosen)# 计算rejected的log概率logprobs_rejected = model.get_logprobs(prompt, rejected)ref_logprobs_rejected = ref_model.get_logprobs(prompt, rejected)# DPO损失logits = beta * ((logprobs_chosen - ref_logprobs_chosen) - (logprobs_rejected - ref_logprobs_rejected))loss = -F.logsigmoid(logits).mean()return loss
选择建议:
- 资源充足:RLHF,效果最优
- 资源有限:DPO,性价比高
- 快速迭代:DPO,简单稳定
6. 总结与展望
6.1 LLM的核心要点回顾
定义与规模:
- LLM是参数量达到数十亿到数千亿的大规模语言模型
- 在TB级数据上进行预训练,展现出传统模型不具备的能力
四大核心能力:
- 涌现能力:量变引起质变,规模扩大带来能力飞跃
- 上下文学习:无需微调,通过示例即可完成新任务
- 指令遵循:理解并执行未见过的自然语言指令
- 逐步推理:能够进行多步骤的逻辑推理
三阶段训练:
预训练(Pretrain)
├── 目标:学习语言规律和知识
├── 数据:TB级无监督文本
├── 任务:因果语言建模(CLM)
└── 成本:最高(需要大规模GPU集群)监督微调(SFT)
├── 目标:学习指令遵循能力
├── 数据:数万到数十万指令-回复对
├── 任务:有监督的指令微调
└── 成本:中等人类反馈强化学习(RLHF)
├── 目标:对齐人类价值观
├── 数据:数万个人类偏好对
├── 任务:基于奖励模型的强化学习
└── 成本:较高(需要4个模型)
6.2 当前面临的挑战
1. 幻觉问题
- 模型会生成看似合理但实际错误的信息
- 目前只能缓解,无法根除
- 限制了在高风险领域(医疗、法律)的应用
2. 计算成本
- 预训练需要数千张GPU和数月时间
- 推理成本高,限制了大规模部署
- 中小企业难以承担训练成本
3. 数据质量
- 高质量训练数据稀缺,尤其是中文数据
- 数据配比对模型性能影响大,缺乏理论指导
- 人工标注成本高昂
4. 评估困难
- 缺乏标准化的评估体系
- 难以量化"对齐"的程度
- 在不同任务上表现差异大
5. 安全性问题
- 可能被用于生成有害内容
- 隐私泄露风险
- 难以完全防范恶意使用
6.3 未来发展方向
1. 模型架构创新
- 稀疏激活:只激活部分参数,降低计算成本
- Mixture of Experts (MoE):条件性地使用不同专家网络
- 长文本处理:突破现有上下文长度限制
2. 训练效率提升
- 更优的Scaling Law:找到参数量、数据量、计算量的最优平衡
- 高效微调方法:LoRA、Adapter等参数高效微调
- 知识蒸馏:用大模型指导小模型
3. 多模态融合
- 文本+图像+音频+视频的统一建模
- 跨模态的深度理解和生成
- 真实世界的具身智能
4. 可控性增强
- 更精确的内容控制
- 可解释的决策过程
- 用户自定义的行为准则
5. 垂直领域应用
- 医疗诊断辅助
- 法律文书分析
- 科研论文生成
- 教育个性化辅导
6. 开源生态发展
- 更多高质量开源模型
- 标准化的训练和评估框架
- 社区协作的数据集建设
6.4 迈向AGI的展望
大语言模型被广泛认为是迈向**通用人工智能(AGI)**的重要路径。尽管当前的LLM与真正的AGI还有差距,但它们已经展现出了令人鼓舞的特质:
已经具备的能力:
- 广泛的知识覆盖
- 灵活的任务适应
- 基本的推理能力
- 多语言和多模态理解
仍需突破的方向:
- 真正的理解与意识
- 持续学习能力
- 常识推理
- 因果推理
- 创造性问题解决
技术路线图:
2020-2022:规模扩展时代
├── GPT-3、PaLM等超大模型
└── 证明Scaling Law的有效性2023-2024:能力涌现时代 ← 当前
├── ChatGPT引爆应用热潮
├── 多模态大模型崛起
└── 指令遵循能力成熟2025-2027:高效化与专业化(预测)
├── 小而精的领域模型
├── 更高效的训练方法
└── 标准化评估体系2028-2030:AGI曙光(展望)
├── 持续学习能力
├── 真正的推理理解
└── 接近人类水平的通用智能
6.5 对实践者的建议
对于工程师:
- 从开源模型开始实践(LLaMA、Qwen等)
- 学习使用LoRA等高效微调方法
- 构建高质量的领域数据集
- 掌握Prompt Engineering技巧
- 了解RAG等增强技术
对于企业:
- 根据需求选择合适规模的模型
- 重视数据资产的积累
- 建立模型评估和监控体系
- 考虑使用开源模型+私有化部署
- 关注合规和安全问题
对于学习者:
- 从基础的NLP概念学起
- 动手实践小规模模型训练
- 阅读经典论文(GPT系列、BERT等)
- 参与开源项目和社区讨论
- 保持对新技术的关注和学习
7. 参考资料
7.1 开创性论文
Transformer与注意力机制:
- Vaswani et al. (2017). “Attention Is All You Need”. NeurIPS 2017.
GPT系列:
- Radford et al. (2018). “Improving Language Understanding by Generative Pre-Training”. OpenAI.
- Radford et al. (2019). “Language Models are Unsupervised Multitask Learners”. OpenAI.
- Brown et al. (2020). “Language Models are Few-Shot Learners”. NeurIPS 2020.
BERT系列:
- Devlin et al. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. NAACL 2019.
指令微调与RLHF:
- Ouyang et al. (2022). “Training language models to follow instructions with human feedback”. NeurIPS 2022.
- Wei et al. (2022). “Finetuned Language Models Are Zero-Shot Learners”. ICLR 2022.
Scaling Law:
- Kaplan et al. (2020). “Scaling Laws for Neural Language Models”. arXiv:2001.08361.
- Hoffmann et al. (2022). “Training Compute-Optimal Large Language Models”. NeurIPS 2022.
DPO:
- Rafailov et al. (2024). “Direct Preference Optimization: Your Language Model is Secretly a Reward Model”. NeurIPS 2023.
7.2 综述与书籍
综述论文:
- Zhao et al. (2023). “A Survey of Large Language Models”. arXiv:2303.18223.
- Naveed et al. (2023). “A Comprehensive Overview of Large Language Models”. arXiv:2307.06435.
技术书籍:
- Jurafsky & Martin. “Speech and Language Processing” (3rd edition).
- Goodfellow et al. “Deep Learning”. MIT Press, 2016.
强化学习:
- Sutton & Barto. “Reinforcement Learning: An Introduction” (2nd edition).
- Wang et al. (2022). “Easy RL: Reinforcement Learning Tutorial”. Posts & Telecom Press.
7.3 开源资源
模型与框架:
- Hugging Face Transformers: https://github.com/huggingface/transformers
- DeepSpeed: https://github.com/microsoft/DeepSpeed
- Megatron-LM: https://github.com/NVIDIA/Megatron-LM
- LLaMA: https://github.com/facebookresearch/llama
- Qwen: https://github.com/QwenLM/Qwen
数据集:
- The Pile: https://pile.eleuther.ai/
- RedPajama: https://github.com/togethercomputer/RedPajama-Data
- Alpaca: https://github.com/tatsu-lab/stanford_alpaca
- BELLE: https://github.com/LianjiaTech/BELLE
学习资源:
- Datawhale开源组织: https://github.com/datawhalechina
- LLM Course: https://github.com/mlabonne/llm-course
- Awesome-LLM: https://github.com/Hannibal046/Awesome-LLM
7.4 在线文档
- OpenAI API文档: https://platform.openai.com/docs
- Anthropic Claude文档: https://docs.anthropic.com
- Hugging Face文档: https://huggingface.co/docs
- DeepSpeed文档: https://www.deepspeed.ai/
结语
大语言模型正在深刻改变我们与计算机交互的方式,也在重塑整个人工智能领域。从GPT-3到ChatGPT,从BERT到现在的多模态大模型,我们见证了技术的飞速进步。
本文系统地介绍了LLM的定义、能力、特点和训练方法,希望能帮助读者建立对大语言模型的全面认识。无论你是研究者、工程师还是爱好者,这都是一个充满机遇和挑战的领域。
记住三个关键点:
- 规模带来涌现:足够大的模型会展现质的飞跃
- 数据质量至关重要:高质量数据胜过海量低质数据
- 对齐决定可用性:技术再强大,也要符合人类价值观
未来,随着技术的不断进步,LLM将在更多领域发挥作用,推动人类社会向更智能化的方向发展。
让我们一起期待并参与到这个激动人心的时代!
附录A:常见问题解答(FAQ)
Q1: 训练一个LLM需要多少成本?
A: 成本取决于模型规模:
小型模型(1B-3B参数):
- GPU:8-16张A100
- 时间:3-7天
- 电力成本:约$5,000-$15,000
- 总成本:$20,000-$50,000
中型模型(7B-13B参数):
- GPU:64-256张A100
- 时间:2-4周
- 电力成本:约$50,000-$200,000
- 总成本:$200,000-$800,000
大型模型(70B+参数):
- GPU:1000+张A100
- 时间:1-3个月
- 电力成本:数百万美元
- 总成本:数千万美元
Q2: 个人或小团队可以训练LLM吗?
A: 可以,但有策略:
推荐路线:
- 使用开源预训练模型:LLaMA、Qwen、Mistral等
- 进行领域SFT:在特定领域数据上微调(成本<$1,000)
- 使用LoRA等高效方法:降低显存和计算需求
- 考虑量化技术:4-bit量化可在消费级GPU上运行
实际案例:
- Alpaca:$600完成SFT(使用GPT-3.5生成数据)
- LoRA微调7B模型:单张RTX 4090即可
- 个人开发者成功案例:Vicuna、Guanaco等
Q3: LLM和ChatGPT是什么关系?
A:
- LLM:大语言模型的统称,是一类模型
- GPT:OpenAI开发的LLM系列(GPT-1/2/3/4)
- ChatGPT:基于GPT-3.5/4,经过RLHF优化的对话系统
- 关系:ChatGPT是LLM的一个具体应用实例
类比:
LLM = 智能手机(类别)
GPT = iPhone(品牌系列)
ChatGPT = iPhone 15 Pro(具体产品)
Q4: 如何评估LLM的能力?
A: 主要评估维度:
1. 通用能力评测:
- MMLU:57个学科的多选题(0-100分)
- HumanEval:代码生成能力(0-100%)
- HellaSwag:常识推理(0-100%)
- TruthfulQA:真实性评估(0-100%)
2. 中文能力评测:
- C-Eval:中文综合评估
- CMMLU:中文多任务理解
- AGIEval:中文高考、司考题目
3. 对话质量评估:
- 人工评分:流畅性、相关性、安全性
- MT-Bench:多轮对话评测
- AlpacaEval:与GPT-4对比胜率
4. 领域专业能力:
- MedQA:医学问答
- LegalBench:法律推理
- GSM8K:数学推理
Q5: 开源模型和闭源模型如何选择?
A:
| 维度 | 开源模型 | 闭源模型 |
|---|---|---|
| 代表 | LLaMA、Qwen、Mistral | GPT-4、Claude、Gemini |
| 成本 | 私有化部署成本高,但长期使用便宜 | 按Token付费,大量使用成本高 |
| 性能 | 头部模型接近闭源 | 顶尖性能(GPT-4、Claude 3) |
| 定制性 | 可任意微调 | 仅能通过Prompt控制 |
| 数据隐私 | 完全可控 | 数据上传至服务商 |
| 可用性 | 需自己部署维护 | 开箱即用 |
| 适用场景 | 企业私有化、敏感数据处理 | 快速验证、通用任务 |
选择建议:
- 原型验证阶段:使用闭源模型(GPT-4),快速迭代
- 生产部署:根据数据敏感度和成本选择
- 高敏感数据:开源模型私有化部署
- 一般数据:综合评估性能和成本
- 特定领域:开源模型+领域微调
Q6: Prompt Engineering重要吗?
A: 非常重要!好的Prompt可以显著提升LLM表现。
基本原则:
1. 明确具体:
❌ 差的Prompt:
"告诉我关于Python的信息"✅ 好的Prompt:
"请用通俗易懂的语言,解释Python中的列表推导式,
并提供3个实际应用场景的代码示例"
2. 提供上下文:
❌ 差的Prompt:
"这段代码有什么问题?[代码]"✅ 好的Prompt:
"我是Python初学者,下面是我写的排序代码,
运行时报错'list index out of range'。
请帮我找出问题并解释原因:[代码]"
3. 使用思维链(CoT):
❌ 差的Prompt:
"计算:25 × 43 = ?"✅ 好的Prompt:
"请一步步计算 25 × 43:
第一步:分解为 25 × 40 + 25 × 3
第二步:计算各部分
第三步:相加得到最终结果"
4. 角色扮演:
✅ 好的Prompt:
"你是一位有20年经验的Python高级工程师。
请从性能优化的角度,审查下面的代码并提出改进建议:[代码]"
高级技巧:
- Few-shot learning:提供2-3个示例
- Self-consistency:要求生成多个答案并综合
- ReAct:推理+行动的交替模式
- Tree-of-Thoughts:探索多个推理路径
Q7: LLM的上下文窗口是什么?
A:
上下文窗口(Context Window)是模型一次能处理的最大token数量。
为什么有限制?:
- 注意力机制复杂度:O(n2)O(n^2)O(n2),其中nnn是序列长度
- 显存占用与序列长度成正比
- 长序列训练困难
不同模型的上下文长度:
| 模型 | 上下文长度 | 大约字数(中文) |
|---|---|---|
| GPT-3 | 2,048 tokens | ~1,400字 |
| GPT-3.5 | 4,096 tokens | ~2,800字 |
| GPT-4 | 8,192 tokens | ~5,500字 |
| GPT-4-32K | 32,768 tokens | ~22,000字 |
| Claude 3 | 200,000 tokens | ~140,000字 |
| Gemini 1.5 Pro | 1,000,000 tokens | ~700,000字 |
| Qwen2.5 | 128,000 tokens | ~89,600字 |
| Qwen3 | 256,000 tokens | ~179,200字 |
| DeepSeek-V1 | 4,096 tokens | ~2,800字 |
| DeepSeek-V3 | 128,000 tokens | ~89,600字 |
| DeepSeek-R1 | 128,000 tokens | ~89,600字 |
| GPT-5 | 400,000 tokens | ~280,000字 |
超出限制怎么办?:
- 截断:只保留最近的对话
- 摘要:总结早期对话内容
- 滑动窗口:保留开头+最近内容
- 外部记忆:使用向量数据库存储历史
Q8: 什么是RAG?
A:
RAG(Retrieval-Augmented Generation,检索增强生成)是一种增强LLM能力的技术。
工作流程:
1. 用户提问↓
2. 检索相关文档(向量数据库)↓
3. 将文档+问题输入LLM↓
4. LLM基于文档生成答案
优势:
- ✅ 减少幻觉(基于真实文档)
- ✅ 知识可更新(更新文档库即可)
- ✅ 可追溯来源(引用具体文档)
- ✅ 降低成本(无需重新训练)
应用场景:
- 企业知识库问答
- 法律文档分析
- 技术文档助手
- 客服系统
简单实现:
# 1. 构建向量数据库
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddingsvectordb = Chroma.from_documents(documents=docs,embedding=OpenAIEmbeddings()
)# 2. 检索+生成
def rag_answer(question):# 检索相关文档relevant_docs = vectordb.similarity_search(question, k=3)# 构建Promptcontext = "\n".join([doc.page_content for doc in relevant_docs])prompt = f"基于以下文档回答问题:\n\n{context}\n\n问题:{question}"# 生成答案answer = llm.generate(prompt)return answer, relevant_docs
Q9: LLM会取代程序员吗?
A: 短期内不会,但会改变工作方式。
LLM当前能做的:
- ✅ 生成简单函数和脚本
- ✅ 解释和注释代码
- ✅ 调试常见错误
- ✅ 代码格式转换
- ✅ 单元测试生成
LLM做不好的:
- ❌ 复杂系统架构设计
- ❌ 性能优化和调优
- ❌ 处理复杂业务逻辑
- ❌ 大规模重构
- ❌ 需要深度领域知识的开发
未来趋势:
初级开发 → 部分被AI替代
中级开发 → 效率大幅提升(AI辅助)
高级开发 → 更专注于架构和决策
建议:
- 学会使用AI工具(GitHub Copilot、Cursor等)
- 提升架构设计和系统思维能力
- 培养问题分析和沟通能力
- 专注于AI难以替代的高价值工作
附录B:实用工具和资源
B.1 模型训练框架
1. Hugging Face Transformers
- 优势:生态完善,模型丰富,易用性好
- 适用:研究、原型开发、小规模微调
- 文档:https://huggingface.co/docs/transformers
2. DeepSpeed
- 优势:高效分布式训练,ZeRO优化
- 适用:大规模预训练和微调
- 文档:https://www.deepspeed.ai/
3. Megatron-LM
- 优势:NVIDIA优化,性能极致
- 适用:超大规模模型训练
- 文档:https://github.com/NVIDIA/Megatron-LM
4. vLLM
- 优势:高效推理,支持PagedAttention
- 适用:生产环境部署
- 文档:https://github.com/vllm-project/vllm
B.2 评估工具
1. lm-evaluation-harness
- 标准化评估框架
- 支持50+主流benchmark
- https://github.com/EleutherAI/lm-evaluation-harness
2. OpenCompass
- 中文大模型评测平台
- 支持多维度评估
- https://github.com/open-compass/opencompass
B.3 数据处理工具
1. Data-Juicer
- 多功能数据清洗工具
- 支持各类过滤和去重算法
- https://github.com/alibaba/data-juicer
2. Pile
- 高质量训练数据集
- 825GB多领域数据
- https://pile.eleuther.ai/
B.4 学习资源
中文社区:
- Datawhale开源组织
- 机器之心
- AI科技评论
附录C:术语表
| 术语 | 英文 | 解释 |
|---|---|---|
| 大语言模型 | LLM | 参数量达到数十亿的大规模语言模型 |
| 预训练 | Pretrain | 在大规模无标注数据上训练模型 |
| 微调 | Fine-tune | 在特定任务数据上调整预训练模型 |
| 提示工程 | Prompt Engineering | 设计输入文本以引导模型输出 |
| 涌现能力 | Emergent Abilities | 模型规模达到阈值后突然出现的能力 |
| 上下文学习 | In-context Learning | 通过示例学习新任务,无需参数更新 |
| 思维链 | Chain-of-Thought | 逐步展示推理过程 |
| 幻觉 | Hallucination | 模型生成虚假或错误信息 |
| 对齐 | Alignment | 使模型行为符合人类价值观 |
| 强化学习 | RL | 通过奖励信号优化策略 |
| 奖励模型 | Reward Model | 评估模型输出质量的模型 |
| 量化 | Quantization | 降低模型精度以减少资源消耗 |
| LoRA | Low-Rank Adaptation | 参数高效的微调方法 |
| RAG | Retrieval-Augmented Generation | 检索增强生成 |
| Token | - | 文本的最小处理单位(词、子词或字符) |
写在最后
希望这份完整的大语言模型指南能够帮助您深入理解LLM的原理和实践。无论您处于学习的哪个阶段,都欢迎反复阅读、实践探索。
大语言模型的时代才刚刚开始,让我们一起见证和参与这场AI革命!