深度学习(十六):数据归一化处理
核心原理与作用
深度学习模型,尤其是基于梯度下降(Gradient Descent)的优化算法,对输入数据的尺度(Scale)非常敏感。数据归一化的主要作用可以归结为以下几个方面:
1. 加快模型收敛速度
在多维输入特征中,如果不同特征的取值范围(即尺度)相差巨大,模型的损失函数(Loss Function)的等高线图会呈扁平的椭圆形。在这种情况下,梯度下降算法在陡峭方向(尺度大)上的步长会非常大,而在平缓方向(尺度小)上的步长则非常小。
- 未归一化:优化路径会呈现**“之”字形**的震荡,需要更多次迭代才能到达最小值。
- 归一化后:所有特征的尺度趋于一致,损失函数的等高线趋近于圆形。此时,梯度方向会更接近指向最小值的方向,优化路径更加平滑和高效,从而显著加快模型的收敛速度。
2. 避免梯度爆炸或梯度消失
深度神经网络通常包含多层结构。在反向传播(Backpropagation)过程中,梯度需要逐层向前传递。
- 当输入数据尺度过大时,经过多层网络的权重相乘,可能导致梯度爆炸(Gradient Explosion),使得模型权重更新过快,无法收敛。
- 当输入数据尺度过小时(尤其是当使用如Sigmoid或Tanh等非线性激活函数时),其导数在输入值较大或较小时会趋近于零,可能导致梯度消失(Gradient Vanishing),使得靠近输入层的权重无法得到有效更新。
归一化将输入值限制在合适的范围内,有助于保持梯度的稳定,使其在每一层都能保持合理的量级,从而避免上述问题。
3. 提高模型的精度和稳定性
归一化确保了所有特征对模型的贡献是公平的,不会因为某个特征的数值范围较大就主导了模型的学习过程,从而使得模型能够更全面地学习到所有特征的内在模式。此外,它还能提高模型在不同数据集上的泛化能力和鲁棒性(Robustness)。
常用数据归一化/标准化方法
在深度学习中,最常用的数据预处理方法通常分为两大类:归一化(Normalization)和标准化(Standardization)。
1. 归一化(Normalization):Min-Max Scaling
目标: 将数据线性地映射到一个指定的范围内,通常是 [0,1] 或 [−1,1]。
公式:
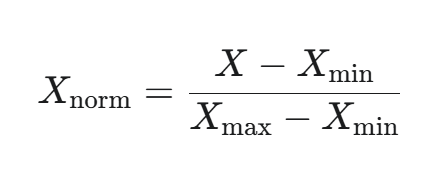
其中,Xmax 和 Xmin 分别是特征列的最大值和最小值。
特点:
- 优点:简单易懂,严格地将数据限制在一个固定范围内,对于某些需要固定输入范围的激活函数(如Sigmoid)非常有用。
- 缺点:对异常值(Outliers)非常敏感。单个极值会严重压缩其他数据的相对差异。
- 适用场景:特征数据的分布范围已知且比较稳定,或者需要将数据映射到 [0,1] 区间。
2. 标准化(Standardization):Z-Score Normalization
目标: 将数据转化为标准正态分布(Standard Normal Distribution),即均值(Mean)为 0,标准差(Standard Deviation)为 1。
公式:
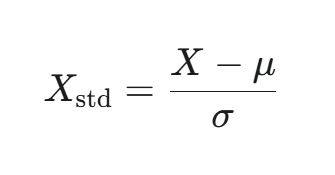
其中,μ 是特征列的均值,σ 是特征列的标准差。
特点:
- 优点:
- 对异常值的鲁棒性较好:因为它不像 Min-Max 归一化那样严格依赖最大值和最小值。
- 能保留数据原本的分布形状和相对关系,对于假设数据呈高斯分布(正态分布)的模型效果更佳。
- 缺点:它没有将数据严格限制在一个固定范围内,尺度是无界的。
- 适用场景:绝大多数深度学习模型的首选方法,尤其当特征数据的分布近似正态或包含较多异常值时。
深度学习独有的归一化技术
随着深度学习网络层数的增加,**内部协变量偏移(Internal Covariate Shift, ICS)**问题变得突出。简单来说,由于网络前一层参数的更新,导致后一层输入的分布(均值和方差)在训练过程中不断变化,迫使后面的网络层需要不断适应新的输入分布,极大地减慢了训练速度。
为了解决这个问题,研究人员引入了内部归一化技术,其中最著名的就是批量归一化(Batch Normalization, BN)。
1. 批量归一化(Batch Normalization, BN)
BN 由 Ioffe 和 Szegedy 在 2015 年提出,是一种将标准化操作嵌入到网络层内的技术。
原理:
BN 在激活函数之前,对**一个批次(Mini-Batch)**中的所有样本进行标准化操作。
-
计算小批量(Mini-Batch)的均值 μB 和方差 σB2。
-
标准化(Normalize):
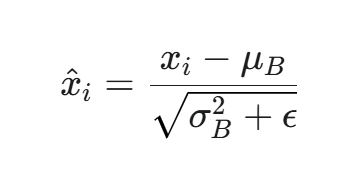
-
缩放和平移(Scale and Shift):
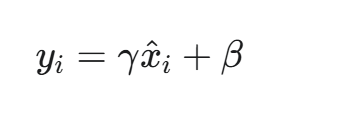
其中,γ 和 β 是可学习的参数(Learned Parameters),它们的作用是恢复模型的表达能力。这是因为单纯的标准化可能将数据强行限制在线性区域,使得非线性激活函数的表达能力受损。引入 γ 和 β 后,网络可以学习是否需要以及如何进行归一化。
特点:
- 训练时:使用当前 Mini-Batch 的均值和方差。
- 测试/推理时:使用整个训练集统计得到的**移动平均(Moving Average)*或*全局均值/方差。
作用:
- 根本上缓解 ICS:使每一层网络的输入分布在训练过程中保持相对稳定。
- 允许更大的学习率(Learning Rate):加速训练。
- 对初始化不那么敏感:减少对良好初始化的依赖。
- 在某些情况下具有正则化作用:可以减少对 Dropout 等正则化技术的依赖。
2. 其他归一化技术
BN 在计算机视觉(CNN)领域效果显著,但在序列模型(如RNN/Transformer)或小批量训练时效果不佳,因此衍生出其他基于不同维度进行归一化的技术:
| 归一化方法 | 归一化维度(计算均值和方差) | 适用场景 |
|---|---|---|
| 层归一化 (Layer Normalization, LN) | 单个样本的所有特征/通道(层内) | 序列模型(RNN、Transformer),小批量训练 |
| 实例归一化 (Instance Normalization, IN) | 单个样本的单个通道/特征(图像风格迁移) | 图像风格迁移,生成对抗网络(GANs) |
| 组归一化 (Group Normalization, GN) | 单个样本的不同通道/特征组 | BN在小批量下失效的场景,如目标检测/分割 |
实践中的关键考量
在实际应用中,处理数据归一化需要注意以下几个关键点:
1. 训练集 vs. 测试集
核心原则: 测试集(Test Set)和验证集(Validation Set)必须使用从 训练集(Training Set) 上计算得到的统计量(均值 μ、标准差 σ、最大值 Xmax、最小值 Xmin)进行归一化。
-
错误做法:在测试集上重新计算统计量进行归一化。这将导致数据泄漏(Data Leakage),因为模型会接触到本不该知道的测试集信息,从而得到一个虚高的性能评估。
-
正确做法:使用训练集计算 μtrain 和 σtrain,并用它们来变换训练集、验证集和测试集。
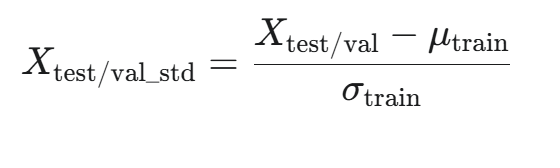
2. 稀疏数据
对于包含大量零值的稀疏数据(Sparse Data,常见于自然语言处理中的 One-Hot 编码或计数特征),进行 Z-Score 标准化可能会破坏其稀疏性,并且效果不佳。对于稀疏特征,通常不进行归一化,或者使用特定的方法如L2 归一化(L2 Normalization)(将特征向量的 L2 范数归一化为 1)。
3. 特征工程
归一化应该在特征工程(如多项式特征生成、特征组合)之后进行,因为归一化的目的是平衡最终输入模型的特征尺度。
总结
数据归一化是深度学习工作流中不可或缺的一环。其核心价值在于重塑特征空间,将不同尺度的特征投影到一个统一且有利于梯度下降优化的空间中。
- 对于传统机器学习和浅层网络,Min-Max 归一化和 Z-Score 标准化是主要的预处理手段,其中 Z-Score 因其对异常值的鲁棒性更受青睐。
- 对于深度神经网络,批量归一化(BN)、层归一化(LN)**等**内部归一化技术成为了标配,它们通过在网络内部实时调整数据分布,从根本上解决了内部协变量偏移问题,极大地提升了模型训练的效率、稳定性和最终性能。