《强化学习数学原理》学习笔记10——策略迭代
策略迭代(Policy Iteration)算法是另一个求解最优策略的算法。
一、策略迭代的核心思想
策略迭代算法主要包含两个关键步骤,循环执行这两个步骤,直到得到最优策略。
(一)策略评估(Policy Evaluation)
对于当前的策略 πk\pi_kπk,计算每个状态的价值 vπkv_{\pi_k}vπk。这一步的目的是衡量上一次迭代得到的策略 πk\pi_kπk。此时要用到贝尔曼期望方程:
vπk=rπk+γPπkvπk(1) v_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k} \tag{1} vπk=rπk+γPπkvπk(1)
其中,πk\pi_kπk 是上一次迭代得到的策略,vπkv_{\pi_k}vπk 是该策略对应的状态值,rπkr_{\pi_k}rπk 和 PπkP_{\pi_k}Pπk 通过系统模型得到。
(二)策略改进(Policy Improvement)
这一步基于策略评估结果改进策略,从而得到新策略。具体而言,在第一步中计算出 vπkv_{\pi_k}vπk 后,就能通过下式得到一个新策略 πk+1\pi_{k + 1}πk+1:
πk+1=argmaxπ(rπ+γPπvπk)(2) \pi_{k+1} = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_{\pi_k}) \tag{2} πk+1=argπmax(rπ+γPπvπk)(2)
在对算法有了上述描述后,自然会引出三个问题:
- 在策略评估步骤中,如何求解状态价值 vπkv_{\pi_k}vπk?
- 在策略改进步骤中,为何新策略 πk+1\pi_{k + 1}πk+1 比 πk\pi_kπk 更好?
- 该算法为何最终能收敛到最优策略?
接下来我们逐一回答这些问题。
1、策略评估步骤中如何计算状态价值 vπkv_{\pi_k}vπk?
有两种求解式 (1) 中贝尔曼方程的方法,现在简要记录一下。
第一种是闭式解:
vπk=(I−γPπk)−1rπk(3) v_{\pi_k} = (I - \gamma P_{\pi_k})^{-1} r_{\pi_k} \tag{3}vπk=(I−γPπk)−1rπk(3)
这种闭式解对理论分析很有用,但实际实现效率不高,因为计算矩阵的逆需要借助其他数值算法。
第二种是易于实现的迭代算法:
vπk(j+1)=rπk+γPπkvπk(j), j=0,1,2,…(4) v_{\pi_k}^{(j + 1)} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}^{(j)}, \ j = 0,1,2,\dots \tag{4} vπk(j+1)=rπk+γPπkvπk(j), j=0,1,2,…(4)
其中 vπk(j)v_{\pi_k}^{(j)}vπk(j) 表示对 vπkv_{\pi_k}vπk 的第 jjj 次估计值。从任意初始猜测 vπk(0)v_{\pi_k}^{(0)}vπk(0) 开始,当 j→∞j \to \inftyj→∞ 时,能保证 vπk(j)→vπkv_{\pi_k}^{(j)} \to v_{\pi_k}vπk(j)→vπk ,这也是迭代算法的理论基础。
也就是说,在策略迭代过程中(式(1)),嵌入了另一种迭代算法(式 (4))。理论上,这种嵌入的迭代算法需要无限步(即 j→∞j \to \inftyj→∞)才能收敛到真实的状态价值 vπkv_{\pi_k}vπk,但这在实际中是不可能实现的。在实际应用中,当满足某个准则时,迭代过程就会终止。例如,终止准则可以是 ∥vπk(j+1)−vπk(j)∥\|v_{\pi_k}^{(j + 1)} - v_{\pi_k}^{(j)}\|∥vπk(j+1)−vπk(j)∥ 小于预先指定的阈值,或者 jjj 超过预先指定的值。如果不进行无限次迭代,我们只能得到 vπkv_{\pi_k}vπk 的一个不精确值,而这个值会被用于后续的策略改进步骤。这会造成问题吗?答案是否定的。这在学习截断策略迭代算法中会清楚原因,此处不做进一步说明。
2、策略改进步骤中,为何 πk+1\pi_{k + 1}πk+1 比 πk\pi_kπk 更好?
策略改进步骤能够改进给定的策略,如下所示。
定理 1(策略改进):如果 πk+1=argmaxπ(rπ+γPπvπk)\pi_{k+1} = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_{\pi_k})πk+1=argmaxπ(rπ+γPπvπk),那么 vπk+1≥vπkv_{\pi_{k+1}} \geq v_{\pi_k}vπk+1≥vπk。
这里,vπk+1≥vπkv_{\pi_{k+1}} \geq v_{\pi_k}vπk+1≥vπk 意味着对于所有状态 sss,都有 vπk+1(s)≥vπk(s)v_{\pi_{k+1}}(s) \geq v_{\pi_k}(s)vπk+1(s)≥vπk(s)。这个定理的证明如下。
定理 1 的证明
由于 vπk+1v_{\pi_{k+1}}vπk+1 和 vπkv_{\pi_k}vπk 都是状态价值,它们满足贝尔曼方程:
{vπk+1=rπk+1+γPπk+1vπk+1vπk=rπk+γPπkvπk(5)
\begin{cases}
v_{\pi_{k+1}} = r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}} \\
v_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k} \tag{5}
\end{cases}
{vπk+1=rπk+1+γPπk+1vπk+1vπk=rπk+γPπkvπk(5)
因为 πk+1=argmaxπ(rπ+γPπvπk)\pi_{k+1} = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_{\pi_k})πk+1=argmaxπ(rπ+γPπvπk),所以我们知道:
rπk+1+γPπk+1vπk≥rπk+γPπkvπk(6) r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k} \geq r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k} \tag{6}rπk+1+γPπk+1vπk≥rπk+γPπkvπk(6)
由此可得:
vπk−vπk+1=(rπk+γPπkvπk)−(rπk+1+γPπk+1vπk+1)≤(rπk+1+γPπk+1vπk)−(rπk+1+γPπk+1vπk+1)≤γPπk+1(vπk−vπk+1)
\begin{align*}
v_{\pi_k} - v_{\pi_{k+1}} &= (r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}) - (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}) \\
&\leq (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k}) - (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}) \\
&\leq \gamma P_{\pi_{k+1}} (v_{\pi_k} - v_{\pi_{k+1}}) \tag{7}
\end{align*}
vπk−vπk+1=(rπk+γPπkvπk)−(rπk+1+γPπk+1vπk+1)≤(rπk+1+γPπk+1vπk)−(rπk+1+γPπk+1vπk+1)≤γPπk+1(vπk−vπk+1)(7)
反复调用式(7)可得:
vπk−vπk+1≤γ2Pπk+12(vπk−vπk+1)≤⋯≤γnPπk+1n(vπk−vπk+1)≤limn→∞γnPπk+1n(vπk−vπk+1)=0
\begin{align*}
v_{\pi_k} - v_{\pi_{k+1}} &\leq \gamma^2 P_{\pi_{k+1}}^2 (v_{\pi_k} - v_{\pi_{k+1}}) \leq \dots \leq \gamma^n P_{\pi_{k+1}}^n (v_{\pi_k} - v_{\pi_{k+1}}) \\
&\leq \lim_{n\to\infty} \gamma^n P_{\pi_{k+1}}^n (v_{\pi_k} - v_{\pi_{k+1}}) = 0 \tag{8}
\end{align*}
vπk−vπk+1≤γ2Pπk+12(vπk−vπk+1)≤⋯≤γnPπk+1n(vπk−vπk+1)≤n→∞limγnPπk+1n(vπk−vπk+1)=0(8)
这个极限成立是因为当 n→∞n \to \inftyn→∞ 时,γn→0\gamma^n \to 0γn→0,并且对于任意 nnn,Pπk+1nP_{\pi_{k+1}}^nPπk+1n 是一个非负的随机矩阵。这里,随机矩阵指的是所有行的和都等于 1 的非负矩阵。所以, vπk−vπk+1≤0v_{\pi_k} - v_{\pi_{k+1}} \leq 0vπk−vπk+1≤0,证明策略 πk+1\pi_{k+1}πk+1 要优于 πk\pi_{k}πk。
3、该算法为何最终能收敛到最优策略?
策略迭代算法会生成两个序列,一个是策略序列{π0,π1,…,πk,… }\{\pi_0, \pi_1, \dots, \pi_k, \dots\}{π0,π1,…,πk,…},另一个是状态价值序列{vπ0,vπ1,…,vπk,… }\{v_{\pi_0}, v_{\pi_1}, \dots, v_{\pi_k}, \dots\}{vπ0,vπ1,…,vπk,…}。
假设v∗v^*v∗是最优状态价值,根据引理 1,我们知道对于所有的kkk,都有vπk≤v∗v_{\pi_k} \leq v^*vπk≤v∗。又因为策略是不断改进的,所以状态价值序列满足vπ0≤vπ1≤vπ2≤⋯≤vπk≤⋯≤v∗v_{\pi_0} \leq v_{\pi_1} \leq v_{\pi_2} \leq \dots \leq v_{\pi_k} \leq \dots \leq v^*vπ0≤vπ1≤vπ2≤⋯≤vπk≤⋯≤v∗。
因此,vπkv_{\pi_k}vπk是一个非递减且有上界(v∗v^*v∗)的序列,根据单调收敛定理,当 k→∞k \to \inftyk→∞ 时,vπkv_{\pi_k}vπk会收敛到一个常数,记为v∞v_{\infty}v∞。
定理 2(策略迭代的收敛性):由策略迭代算法生成的状态价值序列 {vπk}k=0∞\{v_{\pi_k}\}_{k=0}^{\infty}{vπk}k=0∞ 会收敛到最优状态价值 v∗v^*v∗。因此,策略序列 {πk}k=0∞\{\pi_k\}_{k=0}^{\infty}{πk}k=0∞ 会收敛到一个最优策略。
下面是该定理的证明:
定理 2 的证明
证明的思路是展示策略迭代算法比价值迭代算法收敛得更快。
具体来说,为了证明{vπk}k=0∞\{v_{\pi_k}\}_{k=0}^{\infty}{vπk}k=0∞的收敛性,我们引入另一个由下式生成的序列{vk}k=0∞\{v_k\}_{k=0}^{\infty}{vk}k=0∞:
vk+1=f(vk)=maxπ(rπ+γPπvk)(9)v_{k+1} = f(v_k) = \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_k) \tag{9}vk+1=f(vk)=πmax(rπ+γPπvk)(9)
这个迭代算法是值迭代算法。我们已经知道,对于任意初始值 v0v_0v0,vkv_kvk 会收敛到 v∗v^*v∗。
对于 k=0k = 0k=0 ,我们总能找到一个 v0v_0v0 ,使得对于任何 π0\pi_0π0,都有 vπ0≥v0v_{\pi_0} \geq v_0vπ0≥v0。
接下来,我们通过归纳法证明对于所有的kkk,都有vk≤vπk≤v∗v_k \leq v_{\pi_k} \leq v^*vk≤vπk≤v∗。
对于k≥0k \geq 0k≥0,假设vπk≥vkv_{\pi_k} \geq v_kvπk≥vk。
对于k+1k + 1k+1,我们有:
vπk+1−vk+1=(rπk+1+γPπk+1vπk+1)−maxπ(rπ+γPπvk)≥(rπk+1+γPπk+1vπk)−maxπ(rπ+γPπvk)(因为根据引理 1,vπk+1≥vπk,且Pπk+1≥0)=(rπk+1+γPπk+1vπk)−(rπk′+γPπk′vk)(假设πk′=argmaxπ(rπ+γPπvk))≥(rπk′+γPπk′vπk)−(rπk′+γPπk′vk)(因为πk+1=argmaxπ(rπ+γPπvπk))=γPπk′(vπk−vk)
\begin{align*}
v_{\pi_{k+1}} - v_{k+1} &= (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}) - \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_k) \\
&\geq (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k}) - \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_k) \\
&\quad \text{(因为根据引理 1,} v_{\pi_{k+1}} \geq v_{\pi_k} \text{,且} P_{\pi_{k+1}} \geq 0\text{)} \\
&= (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k}) - (r_{\pi_k'} + \gamma P_{\pi_k'} v_k) \\
&\quad \text{(假设} \pi_k' = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_k)\text{)} \\
&\geq (r_{\pi_k'} + \gamma P_{\pi_k'} v_{\pi_k}) - (r_{\pi_k'} + \gamma P_{\pi_k'} v_k) \\
&\quad \text{(因为} \pi_{k+1} = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_{\pi_k})\text{)} \\
&= \gamma P_{\pi_k'} (v_{\pi_k} - v_k) \tag{10}
\end{align*}
vπk+1−vk+1=(rπk+1+γPπk+1vπk+1)−πmax(rπ+γPπvk)≥(rπk+1+γPπk+1vπk)−πmax(rπ+γPπvk)(因为根据引理 1,vπk+1≥vπk,且Pπk+1≥0)=(rπk+1+γPπk+1vπk)−(rπk′+γPπk′vk)(假设πk′=argπmax(rπ+γPπvk))≥(rπk′+γPπk′vπk)−(rπk′+γPπk′vk)(因为πk+1=argπmax(rπ+γPπvπk))=γPπk′(vπk−vk)(10)
由于vπk−vk≥0v_{\pi_k} - v_k \geq 0vπk−vk≥0,且Pπk′P_{\pi_k'}Pπk′是非负的,所以Pπk′(vπk−vk)≥0P_{\pi_k'} (v_{\pi_k} - v_k) \geq 0Pπk′(vπk−vk)≥0,因此vπk+1−vk+1≥0v_{\pi_{k+1}} - v_{k+1} \geq 0vπk+1−vk+1≥0。
因此,我们可以通过归纳法证明,对于任何k≥0k \geq 0k≥0,都有vk≤vπk≤v∗v_k \leq v_{\pi_k} \leq v^*vk≤vπk≤v∗。由于vkv_kvk收敛到v∗v^*v∗,所以vπkv_{\pi_k}vπk也会收敛到v∗v^*v∗。
这个证明不仅展示了策略迭代算法的收敛性,还揭示了策略迭代和价值迭代算法之间的关系。大致来说,如果两种算法都从相同的初始猜测开始,由于策略评估步骤中嵌入了额外的迭代,策略迭代会比价值迭代收敛得更快。
二、策略迭代的元素形式与实现
为了实现策略迭代算法,我们需要研究它的元素形式(Elementwise form)。
(一)策略评估的元素形式
首先,策略评估步骤是从 vπk=rπk+γPπkvπkv_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}vπk=rπk+γPπkvπk 中求解 vπkv_{\pi_k}vπk,所用到的迭代算法如式(4)所示,其元素形式为:
vπk(j+1)(s)=∑aπk(a∣s)(∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vπk(j)(s′)), s∈S(11) v_{\pi_k}^{(j + 1)}(s) = \sum_{a} \pi_k(a|s) \left( \sum_{r} p(r|s,a)r + \gamma \sum_{s'} p(s'|s,a) v_{\pi_k}^{(j)}(s') \right), \ s \in \mathcal{S} \tag{11}vπk(j+1)(s)=a∑πk(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπk(j)(s′)), s∈S(11)
其中 j=0,1,2,…j = 0,1,2,\dotsj=0,1,2,…。这里,vπk(j)(s)v_{\pi_k}^{(j)}(s)vπk(j)(s) 表示在策略 πk\pi_kπk 下,对状态 sss 的价值的第 jjj 次迭代估计值。从每个状态 sss 的任意初始猜测 vπk(0)(s)v_{\pi_k}^{(0)}(s)vπk(0)(s) 开始,随着迭代进行,vπk(j)(s)v_{\pi_k}^{(j)}(s)vπk(j)(s) 会逐渐收敛到策略 πk\pi_kπk 下状态 sss 的真实价值 vπk(s)v_{\pi_k}(s)vπk(s)。
(二)策略改进的元素形式
其次,策略改进步骤是求解 πk+1=argmaxπ(rπ+γPπvπk)\pi_{k+1} = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi} v_{\pi_k})πk+1=argmaxπ(rπ+γPπvπk),该方程的元素形式为:
πk+1(s)=argmaxπ∑aπ(a∣s)(∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vπk(s′))⏟qπk(s,a), s∈S(12) \pi_{k+1}(s) = \arg \max_{\pi} \sum_{a} \pi(a|s) \underbrace{\left( \sum_{r} p(r|s,a)r + \gamma \sum_{s'} p(s'|s,a) v_{\pi_k}(s') \right)}_{q_{\pi_k}(s,a)}, \ s \in \mathcal{S} \tag{12}πk+1(s)=argπmaxa∑π(a∣s)qπk(s,a)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπk(s′)), s∈S(12)
其中 qπk(s,a)q_{\pi_k}(s,a)qπk(s,a) 是策略 πk\pi_kπk 下的动作价值(action value)。令 ak∗(s)=argmaxaqπk(s,a)a_k^*(s) = \arg \max_{a} q_{\pi_k}(s,a)ak∗(s)=argmaxaqπk(s,a),那么贪心最优策略为:
πk+1(a∣s)={1,a=ak∗(s),0,a≠ak∗(s)(13) \pi_{k+1}(a|s) = \begin{cases}
1, & a = a_k^*(s), \\
0, & a \neq a_k^*(s) \tag{13}
\end{cases} πk+1(a∣s)={1,0,a=ak∗(s),a=ak∗(s)(13)
这意味着,在状态 sss 下,新策略 πk+1\pi_{k+1}πk+1 会确定性地选择能使动作价值 qπk(s,a)q_{\pi_k}(s,a)qπk(s,a) 最大的动作 ak∗(s)a_k^*(s)ak∗(s),而对其他动作的选择概率为 000。
算法流程的伪代码如下所示:

三、策略迭代的示例说明
为了更直观地理解策略迭代算法的执行过程,我们来看一个简单示例。
(一)示例背景
考虑如图所示的简单示例,存在两个状态,有三个可能的动作:A={aℓ,a0,ar}\mathcal{A} = \{a_{\ell}, a_0, a_r\}A={aℓ,a0,ar},分别代表向左移动、保持不变和向右移动。奖励设置为 rboundary=−1r_{\text{boundary}} = -1rboundary=−1,rtarget=1r_{\text{target}} = 1rtarget=1,折扣率 γ=0.9\gamma = 0.9γ=0.9。
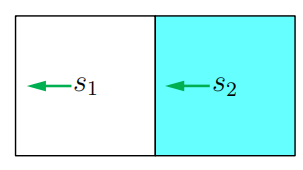
(二)算法分步实现
我们逐步展示策略迭代算法的实现过程。当 k=0k = 0k=0 时,从上图所示的初始策略开始,这个策略并不好,因为它没有朝着目标区域移动。接下来展示如何应用策略迭代算法得到最优策略。
1、策略评估步骤
首先,在策略评估步骤中,需要求解贝尔曼方程:
{vπ0(s1)=−1+γvπ0(s1)vπ0(s2)=0+γvπ0(s1)(14)
\begin{cases}
v_{\pi_0}(s_1) = -1 + \gamma v_{\pi_0}(s_1) \\
v_{\pi_0}(s_2) = 0 + \gamma v_{\pi_0}(s_1) \tag{14}
\end{cases}
{vπ0(s1)=−1+γvπ0(s1)vπ0(s2)=0+γvπ0(s1)(14)
由于方程简单,可以手动求解得到:
vπ0(s1)=−10,vπ0(s2)=−9(15) v_{\pi_0}(s_1) = -10, \quad v_{\pi_0}(s_2) = -9 \tag{15}vπ0(s1)=−10,vπ0(s2)=−9(15)
在实际中,也可以用式 (4) 的迭代算法求解。例如,选择初始状态价值 vπ0(0)(s1)=vπ0(0)(s2)=0v_{\pi_0}^{(0)}(s_1) = v_{\pi_0}^{(0)}(s_2) = 0vπ0(0)(s1)=vπ0(0)(s2)=0,根据式 (4) 有:
{vπ0(1)(s1)=−1+γvπ0(0)(s1)=−1vπ0(1)(s2)=0+γvπ0(0)(s1)=0(16)
\begin{cases}
v_{\pi_0}^{(1)}(s_1) = -1 + \gamma v_{\pi_0}^{(0)}(s_1) = -1 \\
v_{\pi_0}^{(1)}(s_2) = 0 + \gamma v_{\pi_0}^{(0)}(s_1) = 0 \tag{16}
\end{cases}
{vπ0(1)(s1)=−1+γvπ0(0)(s1)=−1vπ0(1)(s2)=0+γvπ0(0)(s1)=0(16)
{vπ0(2)(s1)=−1+γvπ0(1)(s1)=−1.9vπ0(2)(s2)=0+γvπ0(1)(s1)=−0.9(17)
\begin{cases}
v_{\pi_0}^{(2)}(s_1) = -1 + \gamma v_{\pi_0}^{(1)}(s_1) = -1.9 \\
v_{\pi_0}^{(2)}(s_2) = 0 + \gamma v_{\pi_0}^{(1)}(s_1) = -0.9 \tag{17}
\end{cases}
{vπ0(2)(s1)=−1+γvπ0(1)(s1)=−1.9vπ0(2)(s2)=0+γvπ0(1)(s1)=−0.9(17)
{vπ0(3)(s1)=−1+γvπ0(2)(s1)=−2.71vπ0(3)(s2)=0+γvπ0(2)(s1)=−1.71(18)
\begin{cases}
v_{\pi_0}^{(3)}(s_1) = -1 + \gamma v_{\pi_0}^{(2)}(s_1) = -2.71 \\
v_{\pi_0}^{(3)}(s_2) = 0 + \gamma v_{\pi_0}^{(2)}(s_1) = -1.71 \tag{18}
\end{cases}
{vπ0(3)(s1)=−1+γvπ0(2)(s1)=−2.71vπ0(3)(s2)=0+γvπ0(2)(s1)=−1.71(18)
⋮\vdots⋮
随着迭代次数增加,可观察到趋势:vπ0(j)(s1)→vπ0(s1)=−10v_{\pi_0}^{(j)}(s_1) \to v_{\pi_0}(s_1) = -10vπ0(j)(s1)→vπ0(s1)=−10,vπ0(j)(s2)→vπ0(s2)=−9v_{\pi_0}^{(j)}(s_2) \to v_{\pi_0}(s_2) = -9vπ0(j)(s2)→vπ0(s2)=−9。
2、策略改进步骤
其次,在策略改进步骤中,关键是计算每个状态 - 动作对的 qπ0(s,a)q_{\pi_0}(s,a)qπ0(s,a),可通过下表演示该过程:
表 1:图 4.3 示例中 qπk(s,a)q_{\pi_k}(s,a)qπk(s,a) 的表达式
| qπk(s,a)q_{\pi_k}(s,a)qπk(s,a) | aℓa_{\ell}aℓ | a0a_0a0 | ara_rar |
|---|---|---|---|
| s1s_1s1 | −1+γvπk(s1)-1 + \gamma v_{\pi_k}(s_1)−1+γvπk(s1) | 0+γvπk(s1)0 + \gamma v_{\pi_k}(s_1)0+γvπk(s1) | 1+γvπk(s2)1 + \gamma v_{\pi_k}(s_2)1+γvπk(s2) |
| s2s_2s2 | 0+γvπk(s1)0 + \gamma v_{\pi_k}(s_1)0+γvπk(s1) | 1+γvπk(s2)1 + \gamma v_{\pi_k}(s_2)1+γvπk(s2) | −1+γvπk(s2)-1 + \gamma v_{\pi_k}(s_2)−1+γvπk(s2) |
将之前策略评估步骤得到的 vπ0(s1)=−10v_{\pi_0}(s_1) = -10vπ0(s1)=−10,vπ0(s2)=−9v_{\pi_0}(s_2) = -9vπ0(s2)=−9 代入上表:
表 2:k=0k = 0k=0 时 qπk(s,a)q_{\pi_k}(s,a)qπk(s,a) 的值
| qπ0(s,a)q_{\pi_0}(s,a)qπ0(s,a) | aℓa_{\ell}aℓ | a0a_0a0 | ara_rar |
|---|---|---|---|
| s1s_1s1 | −10-10−10 | −9-9−9 | −7.1-7.1−7.1 |
| s2s_2s2 | −9-9−9 | −7.1-7.1−7.1 | −9.1-9.1−9.1 |
通过寻找 qπ0q_{\pi_0}qπ0 的最大值,得到改进后的策略 π1\pi_1π1:
π1(ar∣s1)=1,π1(a0∣s2)=1 \pi_1(a_r|s_1) = 1, \quad \pi_1(a_0|s_2) = 1 π1(ar∣s1)=1,π1(a0∣s2)=1
这个策略如下图所示,显然是最优的:
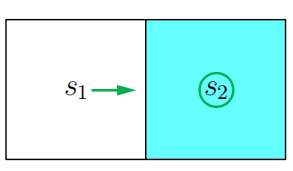
上述过程表明,在这个简单示例中,单次迭代就足以找到最优策略。对于更复杂的示例,则需要更多次迭代。
在策略的演变过程中,还存在以下两个规律:
- 首先,如果我们观察策略的演变过程,会发现一个有趣的规律:靠近目标区域的状态会比远离目标的状态更早找到最优策略。只有当靠近目标的状态先找到通往目标的轨迹,更远的状态才能找到途经这些靠近目标的状态以抵达目标的轨迹。
- 其次,状态价值的空间分布呈现出一个有趣的规律:距离目标更近的状态具有更大的状态价值。这种规律的原因在于,从更远的状态出发的智能体必须经过很多步才能获得正奖励,而这样的奖励会被严重折扣,因此相对较小。