Redis 常见面试题
1.介绍一下什么是 Redis,有什么特点?
redis是基于键值对的内存数据库,与传统的关系型数据库(Mysql)不同,不依赖“表”结构存储数据。
核心特点:
高性能:使用内存存储
支持多种数据结构:核心结构string,list,set,Zset,hash;扩展结构:bitmaps,bitfields,geo,hyperloglog,stream
持久化机制:RDB,AOF
单线程处理请求:单线程处理客户端请求,避免线程切换和竞态。多线程处理网络IO,提高效率。
支持主从复制:主节点负责写入,从节点负责读取(读写分离,数据备份)
支持哨兵模式:自动的故障转移。
支持集群模式:横向扩展存储和性能
支持多语言客户端:提供简单的tcp通信协议,支持C、C++、Java、PHP等编程语言的客户端
2.Redis 支持哪些数据类型?
常用类型:String,hash,list,set,zset
扩展类型:bitmap(二进制表示某个数字是否存在)
,bitfields(把字符串当作位图,进行位操作)
,geo(地理信息,存储经纬度,空间计算)
,stream(消息队列)
,hyperloglog(基于位图实现“计数”,不能查看具体信息,只计数)
3.Redis 数据类型底层的内部编码是什么?
String :
int (整型)
embstr(短字符串,连续存储)
raw(长字符串,存储不连续)
hash:
ziplist(压缩列表):field短时,节省内存
hashtable(哈希表):field长时,提高访问效率
list:
ziplist(压缩列表):元素短时,省内存
linkedlist(链表):链表+压缩列表
set:
inset(整数集合):全为整数且 数量级小
hashtable(哈希表):非整数/数量级大,保证去重和快速查询
zset:
ziplist:数量小时省内存
skiplist(跳表):优化查询,支持logN 的排序和查询
4.ZSet 为什么用跳表实现,而不是红黑树?
跳表的插入/查询/删除 的时间复杂度都是log N ,和红黑树是一样的。
而跳表的实现更简单,只需要“多层索引”定位范围边界。红黑树要额外存储颜色、父节点指针,开销大。还需要旋转去保持平衡。
5.Redis 的常见应用场景有哪些?
缓存:redis存储热点数据,降低查询数据库的次数。
消息队列:通过提供的stream 类型(或blpop\brpop),可以作为简单的消息队列。
计数器:统计 点击、访问次数、收藏等
排行榜:基于Zset可以轻松实现
分布式会话:将用户的session消息存储到redis中,使用户登录不同模块时都能使用同一个公共会话(共享基础信息)
分布式锁:基于setnx + lua脚本,实现分布式环境下的并发控制,保证原子性
地理信息服务:geo类型
标签系统:基于set的交集,并集运算,实现标签管理,找到“共同爱好”
6.怎样测试 Redis 服务器的连通性?
登录redis服务器,输入ping,如果连通,会返回pong
7.如何设置 key 的过期时间?
1.set ex(秒) set px(毫秒)
2.先set k,再expire k
可以通过ttl查看过期时间
8. Redis 为什么是单线程模型?
redis的逻辑简单,使用单线程去处理命令请求,避免竞争。
redis6.0后,引入多线程处理网络IO+协议解析,进一步提高IO效率。(执行redis命令还是单线程)
9.Redis 里的 IO 多路复用是怎么回事?
redis单线程通过IO 多路复用,处理多个客户端的连接。
基于Linux的epoll机制实现多路复用:一个线程管理多个socket(文件描述符),监听多个客户端的IO事件,按需触发处理。
多个客户端,有的可能是在挂机,并不是所有的都同时活跃,监听状态,活跃的就触发处理。
9.2 为什么用epoll而不是select或poll
select/poll会遍历所有注册的socket,时间复杂度O(N),客户端多时效率低。
epoll基于红黑树管理socket,通过回调机制返回就绪的socket,时间复杂度O(1)
10.10.Redis 的持久化机制有哪些?
RDB(内存快照)
触发后,redis生成当前数据的二进制快照(dump.rdb),恢复时直接加载快照到内存。
手动触发:save(阻塞主线程,适合小数据)、bgsave(fork子进程生成快照,主线程不受影响)
自动触发:通过配置save m n (m秒发生n次修改则触发)
RDB文件是二进制文件,体积小,适合全量复制、主从复制。但无法实现持久化
AOF
原理:将命令以文本形式追加到aof文件,恢复时执行文件中的命令重建数据。
开启aof:appendonly :yes
同步策略:
always:每次命令写入后立刻同步到硬盘(性能低,安全高)
everysec:每秒调用一次fsync(兼顾性能和安全性)
no:由操作系统决定什么时候fsync(性能高,安全性低)
AOF重写:随着命令增多,aof文件膨胀,redis会通过bgrewriteaof,重写机制去除冗余,根据当前内存的状态,重写aof,并追加重写期间的aof文件,形成新的aof。
混合持久化:
开启aof-use-rdb-preamble yes后,aof重写时,会先以rdb格式写入快照,再追加后续命令,结合rdb加载快和aof实时性的特点
11. RDB 的持久化触发条件是怎样的?
手动触发:
save:阻塞其他命令,主线程直接生成rdb快照(生产环境慎用)
bgsave:主线程fork子进程,子进程生成rdb快照,不影响主线程处理客户端命令
自动触发:
1.配置文件save m n (m秒内产生n次修改自动触发)
2.从节点首次连接主节点时,全量复制,自动触发
3.shutdown关闭redis时,自动bgsave确保数据持久化
4.flushall清空数据时,触发,生成空的rdb文件
12. AOF 的文件同步策略有哪些?
always:每次执行命令写入aof缓冲区后,立刻调用fsync同步到硬盘。
everysec:每秒同步数据到硬盘
no:由操作系统自主决定fsync时机
(fsync:强制将内核缓冲区的数据同步到硬盘。)
13. AOF 的重写机制是怎样的?
重写机制用来压缩不断膨胀的aof文件,通过对 当前内存的状态生成对应的命令 进而生成aof文件,再替换掉旧的aof文件。
触发条件:
手动:执行bgrewriteaof,fork子进程进行重写
自动:当aof文件大小> auto-aof-rewrite-min-size ,文件大小超过配置要求时触发。
过程:
fork子进程根据当前内存的状态,生成对应的指令。(相当于 移除过期命令、合并重复命令、忽略无效命令)
主节点会将新写入的命令写入 “原aof缓冲区” 和 “重写缓冲区”。(原aof缓冲区是父子进程都有,重写缓冲区内是子进程在重写过程中,主节点产生的新数据)
子进程生成新的aof文件后,主节点将重写缓冲区追加给子进程,然后新文件替换原aof文件。
14. Redis 的 key 的过期删除策略是怎样的?
惰性删除:当客户端访问到某个key时,才检查是否过期,过期则删除返回nil。
定期删除:每隔一定时间定期扫描,删除过期的key
15. 如果大量的 key 在同一时间点过期,会产生什么问题?如何处理?
当大量key同时过期,如果全部删除,可能会产生阻塞主线程(再次访问时发生redis上没有,只能去数据库中访问)
解决措施:
- 添加随机过期时间,给key设置过期时间时,附件一个随机值(分散过期时间)
- 采样删除:删除前提前统计过期的key,若超过25%,则会持续删除过期的key(直到最大删除时间,25ms)而不是一次性删除。
16.Redis 的淘汰策略是怎样的?
内存不足时,继续添加key,就会引发淘汰策略,把之前旧的key删除掉。
1.在设置过期时间的key中选择 (volatile)
LRU:淘汰“最近最少使用”的key
LFU:淘汰“最近最少访问”的key
random:随机淘汰
TTL:淘汰“剩余过期时间最短”的key
2.在所有的key中选择(allkeys)
LRU:淘汰“最近最少使用”的key
LFU:淘汰“最近最少访问”的key
random:随机淘汰
3.不淘汰(noeviction)
内存满了再写入,直接报错
建议:核心数据,仅淘汰过期key;非核心数据,淘汰allkeys;数据无优先级,random; 不允许数据丢失:noeviction;
17.Redis 如果内存用完了,会出现什么情况?
触发淘汰策略。
noeviction
volatile-
allkeys-
18.Redis 为什么把数据放到内存中?
内存访问速度比硬盘快得多(3-4个数量级)
所以redis相比MySQL就有了显著优势。当然这是某方面的
19. Redis 的主从同步 / 主从复制是怎么回事?
主从复制让redis实现 读写分离(降低主节点的压力)、高可用(主节点挂了从节点可以快速顶替,不影响服务器的功能)、数据备份(从节点同步主节点的数据,主节点挂了从节点可以放心顶替)
主节点负责写数据,也可以读数据。
从节点负责读数据。
20. Redis 的 pipeline(流水线 / 管道)是什么?
作用:减少网络开销,允许客户端将多个命令批量发送到服务器,一次执行并返回结果,避免多次网络往返(RTT)。
发送N条指令:
普通命令 t=N x(RTT+命令执行时间)
管道 t=1x RTT + N x 命令执行时间
如果单次pipeline命令过多,可能会阻塞服务器
21. 介绍下 Redis 哨兵?
哨兵 帮助redis实现高可用,哨兵可以监视主从节点,当主节点挂掉了,哨兵会 自动进行故障转移,选从节点晋升成主节点,并通知客户端,避免主节点故障造成服务器无法运行。
监控:哨兵节点每秒向主节点、从节点、其他哨兵节点 发送ping命令,检测节点活跃状态。
故障判定:
主观下线:当哨兵节点多次未收到主节点的pong响应,会判定主节点故障。
客观下线:当半数哨兵节点判定主节点故障了,就会投票确认这个主节点 真正故障了。
故障转移:
- 哨兵节点先选举一个leader哨兵
- leader哨兵在从节点中选主节点(优先选 优先级高、复制偏移量offset大 的从节点)
- 新主节点和其他从节点建立关系,若故障节点恢复,则转化为从节点
- 通知客户端新主节点的地址
哨兵的数量建议为奇数个,避免竞选leader哨兵 或 判断主观下线时出现投票平票的情况。
22. Redis 哨兵如果发现主节点宕机了,接下来会做哪些事情?
-
故障判定:
a.单个哨兵节点超时未收到主节点的响应,判定为主观下线
b.向其他哨兵节点询问那个主节点的状态,若半数都判定下线,则得出 客观下线 的结论,并同步给所有哨兵节点 -
选举leader哨兵
a.每个哨兵节点向其他哨兵发送“拉票请求”,声明自己要成为leader
b.收到拉票请求的哨兵就直接投票(不再申请leader,就是谁先发出请求基本谁就是leader)
c.某个哨兵节点的票数超过哨兵节点数的一半,则成为leader -
故障转移:
a.leader哨兵选新的主节点(优先级越高、offset越大、运行id越小。越优先)
b.选中的从节点执行slaveof no one命令,变成新的主节点
c.同步从节点:向其他从节点发送slaveof 新主节点ip port ,让它们变成新主节点的从节点
d.若原故障节点恢复,则变成新主节点的从节点
e.通知客户端:将新主节点的地址更新给客户端
23. Redis 的集群是干什么的?
集群主要是为了解决,主从+哨兵 架构中,单主节点容量有限的问题。
作用:
- 存储扩容:将数据分片存储到多个主节点上,提高内存容量
- 性能扩展:多个主节点并行处理写请求,支持更高的并发量
24. Redis 的哈希槽是怎么回事?
哈希槽(hash slot)是redis集群实现 数据分片 的核心机制,通过固定数量的槽将数据均匀分配到多个主节点上,简化数据的定位和集群扩容。
核心设计:
- 槽数量固定:集群默认有16384个哈希槽
- 数据定位:客户端计算key的哈希槽:slot=crc16(key)%16384,然后将请求发送给负责该槽位的主节点。
- 槽位灵活分配:哈希槽可手动/自动分配给主节点,主节点负责的槽可连续,可不连续
优势:
4. 简化扩容/缩容:扩容只需迁移部分槽位,无需计算所有key的哈希。缩容同理
5. 数据均匀分布:通过槽在不同分片上相当的数量,实现key在分片上的均匀分布
6. 故障隔离:每个主节点负责不同的槽,某个主节点挂了,不影响其他的槽
25. Redis 集群的最大节点个数是多少?
虽然没有硬性要求,可以一个槽一个主节点。
但作者建议主节点数不超过1000个。
原因:
- 心跳包开销:集群中每个节点每秒都会向其他节点发送ping命令,节点越多,心跳包数量以N^2增长,网络开销越大。
- 节点越多,故障的检测和转移耗时越长,影响集群可用性
- 管理复杂
26. Redis 集群会有些操作丢失吗?
redis 集群 不保证数据的强一致性。
特定场景下可能会丢失:
1.主从同步故障:从节点没有完全同步主节点的信息,主节点挂后,从节点晋升为主节点,就丢失了没有同步的信息
降低风险:开启aof持久化配置appendfsync everysec
27. Redis 集群如何选择数据库?
redis集群不支持选择数据库,仅能使用默认数据库0
原因:
- 数据分片冲突:redis支持16个数据库,但集群中数据按哈希槽分配到主节点。若支持多个数据库,可能导致同一key在不同数据库中属于 不同的槽
- 一致性维护困难:集群的心跳包、故障转移的复杂度提高
- 业务场景适配:多数据库的隔离,可以通过加 前缀来解决
28. 介绍下一致性哈希算法?
一致性哈希算法,解决“传统哈希求余” 在节点扩容/缩容时,大量数据 “迁移”的问题。
通过将数据 和 节点 映射到同一个环形哈希空间,实现节点变动时最小化的数据迁移。
步骤:
将哈希值范围映射成一个圆环,计算得出key的哈希值,在圆环上从该哈希值顺时针查找,遇到第一个节点就是该数据的所属节点。
扩容/缩容时:仅需迁移该节点在圆环上覆盖的区域;
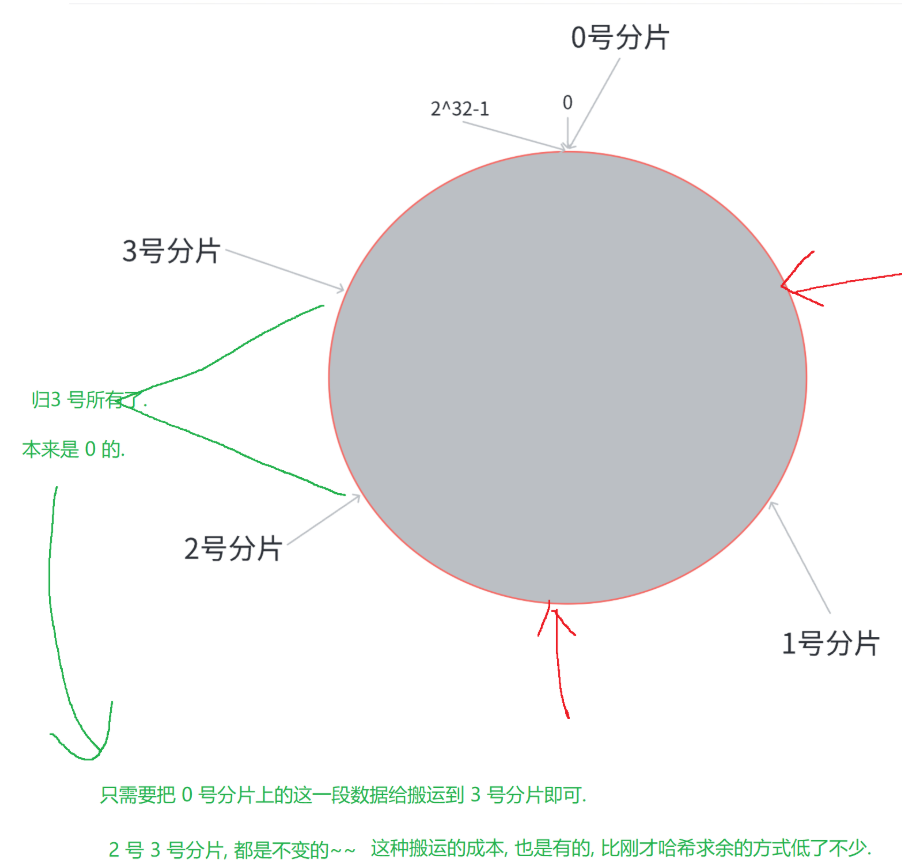
29. 如何理解 Redis 的事务?和 MySQL 的事务有啥区别?
redis事务是一组命令的批量执行,通过multi开启事务,exec执行事务,discard取消事务,watch监视key的变化 实现。
原子性:
MySQL:强原子性(要么全成,要么全回滚)
redis:弱原子性(命令失败不回滚)
一致性:
MySQL:保证一致性(通过约束,回滚实现)
redis:不保证一致性(无约束,逻辑错误可能导致不一致)
隔离性:
MySQL:4种隔离级别
redis:天然隔离(单线程执行命令)
持久性:
MySQL:redo log 实现
redis:rdb、aof、混合持久化
30. Redis 和事务相关的命令有哪些?
- multi:开启事务,开启后后续命令会放入“事务队列”,不立即执行,返回OK。
- exec:执行事务队列 中的所有事务,返回每个命令的结果。若watch的key被修改,则事务取消,返回nil。
- discard:取消事务,情况事务队列,返回OK。
- watch key[key…]:监视一个或多个key,若被监视的key被修改,事务会取消(乐观锁)
31. 为什么在生产环境上不应该使用 keys * 命令?
key* 会遍历所有符合的key,如果存储的数据量非常大,这个操作就很耗时,甚至阻塞redis,影响服务器正常处理其他请求。
可以通过scan扫描来平替
32. 如何使用 Redis 作为消息队列?
-
基于list实现简单阻塞队列:lpush(rpush)生成消息,brpop(blpop)阻塞式消费消息,从而支持多个消费者“争抢”。
-
基于发布订阅(PUB/SUB)实现:生产者通过publish 向指定频道发布消息,消费者通过 subscribe 订阅频道。
-
基于stream实现专业的消息队列
33. 如何使用 Redis 实现分布式锁?
分布式锁主要是解决分布式系统中“多个节点竞争同一资源”的问题。redis基于set + lua脚本+过期时间 实现。思路:用一个key标识锁,只有成功设置key的节点能获取锁。
步骤:
- set key value nx ex time :原子性实现key不存在则设置+过期时间
- 通过lua脚本 校验value+删除key,避免误删
- 续约锁(watch dog):若业务执行时间超过锁的过期时间,每隔一段时间,给锁续约(重新设置过期时间),避免锁提前释放
- redlock算法:避免单节点故障导致锁失效,可以部署多个独立的redis节点,获取/释放 锁时当半数以上的节点都成功设置/删除key时,才算成功。提高锁的可用性
34. 什么是缓存穿透、缓存雪崩、缓存击穿?
缓存穿透:访问的key在redis和数据库中均不存在,请求会直接穿透到数据库,导致数据库压力大。
措施:
- 当发现key在redis和数据库都不存在时,可以设置一个key,value取空值即可,避免后续的请求穿透。
- 缓存前部署布隆过滤器,提前判定key是否存在
缓存雪崩:短时间大量的key同时过期,导致大量的请求穿透到数据库,数据库压力激增。
措施:
- 优化过期时间:给过期时间添加随机值,避免同时过期
- 部署哨兵、集群,避免单点故障
- 对热点key设置永不过期
缓存击穿:某个热点key突然过期,大量请求穿透到数据库,数据库压力激增。
措施
- 设置热点key永不过期
- 缓存预热:系统启动时,先将热点key加载到redis
- 添加分布式锁,当一个请求访问到数据库时,阻塞其他请求
35. 什么是热 key 问题?如何解决?
热key :某些key访问频率特别高。可能高到会时redis崩溃
措施:
- 扩大redis集群的规模,部署更多的slave节点分担读压力
- 对热key进行二次哈希,分散到更多的redis分片上
- 通过监视工具识别出热key,热key使用单独的redis集群部署,赋予更多的机器
- 使用应用程序本地缓存
36. 如何实现 Redis 高可用?
主从复制:一主多从,实现数据备份和读写分离,从节点处理读请求,分担主节点压力
哨兵模式:哨兵自动转移故障,当主节点挂后,哨兵自动选出leader节点,leader选出新的主节点。
集群模式:将数据分片到多个主节点上,扩大内存,提高性能
37. Redis 和 MySQL 如何保证双写一致性?
“双写一致性”:当用户修改数据时,需要修改数据库,同时也要更新缓存中的事件。
如果直接写入数据库 /写入redis ,此时若一方失败了,就会发生数据不一致的情况。
解决措施:
- 延时双删(多一重保障)
a.先删缓存中的旧数据
b.再更新数据库
c.延迟一段时间,再次删除redis中的数据 - 删除缓存重试
a.更新数据库数据
b.尝试删除redis缓存,若删除失败,则把“需要删除的key和 删除任务”放入消息队列
c.消费者获取消息队列的任务,重试删除。如果删除成功就结束,删除失败就把删除任务放回消息队列,等待下一次消费。直到删除成功
38. 生成 RDB 期间,Redis 是否可以处理写请求?
生成rdb有两种方式。
save:redis主线程直接执行rdb生成,期间主线程阻塞,无法处理其他请求
bgsave:主线程fork一个子进程,子进程负责生成rdb快照,主线程继续处理其他请求。
39. Redis 的常用管理命令有哪些?
dbsize:返回当前数据库中key的数量
info :查看redis服务器状态和一些统计信息,可指定section(查看主从信息)
monitor:实时监听并打印redis服务器接收的所有命令,用于调试
shutdown:把数据同步到硬盘,并关闭redis服务器
config get parameter : 获取一个redis配置参数信息
config set parameter value:设置一个redis配置参数信息
debug object key: 获取一个key的调试信息
debug segfault:制造一次服务器宕机
flushdb:删除当前数据库中所有key。不会失败
flushall:删除全部数据库中的所有key。不会失败
40. Redis 用到的网络通讯协议是怎样的?
redis使用自定义的redis serialization protocol(RESP,redis序列化协议)作为客户端 和 服务器的通信协议。纯文本协议。
协议格式规则:
RESP通过首字符标识数据类型:
数组 *
字符串 $
简单字符 +
整数 :
错误 -
41. Redis 如何遍历 key?
使用keys* 可以一次性获取到所有key,但开销大,可能会卡死服务器。
推荐使用scan命令
scan是渐进式遍历key,每次遍历部分的key,时间复杂度为O(1),不会阻塞线程。
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
每次scan都能返回一批keys,同时告诉我们下次从什么地方开始scan,执行多次scan完成整个遍历
cursor表示遍历key的光标,从0开始,每次执行scan返回下次开始的光标,当返回结果为0表示遍历结束。
特殊类型的渐进式遍历:
对应hash、set、zset等复合数据类型,还提供了hscan、sscan、zscan等,用法类似
42. Redis 如何实现 “查找附近的人”?
通过Geospatial类型,存储每个人的地理位置。(geoadd key )
使用 georadius key [经度] [纬度] [距离] 查询以(经度,纬度)为圆心,距离为半径,里面哪些member符合条件。
GEODIST:计算两个 member 之间的距离
GEOPOS:获取 member 的经纬度
43. 什么是 Redis 的 “bigkey” 问题?如何解决?
bigkey是指某个key对应的value占用过多的存储空间。(如string类型过长、hash/set等类型包含元素过多)
解决措施:
核心思路是拆分,把一个大key拆成多个小key,每个小key对应value的一部分数据。
使用redis-cli --bigkey查看bigkey
删除bigkey 不要直接使用del,可能阻塞redis,使用unlink命令在后台删除。