【第十六周】自然语言处理的学习笔记01
文章目录
- 摘要
- Abstract
- 一、机器学习
- 1. 支持向量机(SVM)
- 1.1 项目实操:数字识别器
- 1.2 步骤说明:
- 2. K近邻算法(KNN)
- 2.1 使用K近邻算法预测电影类别
- 2.2 距离公式
- 2.3 K值的选择
- 2.4 kd树
- 2.4.1 如何构建kd树
- 2.4.2 搜索
- 二、自然语言处理NLP
- 1. 词
- 2. 语言模型
- 3. Word2Vec神经网络
- 3. 1 CBOW模型
- 3. 2 continuous skip-gram模型
- 4. 神经网络模型
- 4.1 循环神经网络RNN
- 4.1.1 RNN模型类型
- 4.1.2 RNN模型结构
- 4.1.3 RNN模型对词的预测流程
- 4.1.4 RNN应用场景以及优缺点
- 4.1.5 梯度消失和梯度爆炸
- 4.1.6 双向RNN
- 4.1.7 CNN与RNN比较
- 4.2 门控循环单元GRU
- 4.2.1 核心结构
- 4.2.2 计算过程
- 4.3 长短期记忆网络LSTM
- 4.3.1 核心部分
- 总结
摘要
本周主要对支持向量机SVM进行实操,并对过程进行分析说明,补充了部分K近邻算法。同时开始学习自然语言处理的内容,了解词的表示方法,语言模型类别,Word2Vec神经网络以及神经网络模型:循环神经网络RNN,门控循环单元GRU,长短期记忆网络LSTM。
Abstract
This week, I mainly carried out practical operations on the Support Vector Machine (SVM) and provided an analytical explanation of the process, while also supplementing some knowledge about the K-Nearest Neighbors (KNN) algorithm. Meanwhile, I started learning content related to Natural Language Processing (NLP), including understanding word representation methods, categories of language models, the Word2Vec neural network, as well as neural network models such as Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRUs), and Long Short-Term Memory (LSTM) networks.
一、机器学习
1. 支持向量机(SVM)
1.1 项目实操:数字识别器
目标:从数万手写图像的数据集中正确识别数字。使用MNIST数据集。
训练文件和测试文件包含0-9,尺寸为28×28的手写数字灰度图。
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split#1,gain dataset
train = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")train_img = train.iloc[:,1:]
train_label = train.iloc[:,0]#View specific images
def to_plot(n):num = train_img.iloc[n,:].values.reshape(28,28)plt.imshow(num) #将数组num以图像形式 “绘制” 到内存中的 “画布”plt.axis("off") #关闭坐标轴(去掉刻度、边框等),这是对已有图像的补充设置。plt.show() #将画布数据显示在屏幕上#2,Processing data
#Normalization processing
train_img = train_img.values / 255
train_label = train_label.values#data split
#train_size训练集比例
x_train , x_val , y_train , y_val = train_test_split(train_img,train_label,train_size= 0.8,random_state= 0)#3,training model
#多次使用PCA,确定最后优化模型。
def n_component_analysis(n,x_train,y_train,x_val,y_val):#记录开始时间start = time.time()#特征降维和模型训练#n_components 用于指定降维后保留的特征维度数量或保留的信息比例# >1表示保留特征数量,<1表示保留信息比例pca = PCA(n_components = n)print("特征降维,传递的参数为:{}".format(n))pca.fit(x_train) #PCA模型训练的核心步骤,用于计算数据的主成分并初始化模型参数。#在训练集和验证集进行降维x_train_pca = pca.transform(x_train)x_val_pca = pca.transform(x_val)#利用svc进行训练,训练一个支持向量机(SVM)分类模型print("开始使用SVC进行训练")ss = svm.SVC() #创建了一个 SVM 分类器实例:SVCss.fit(x_train_pca,y_train) #调用分类器的fit方法,用训练数据对模型进行训练#获取accuracy结果accuracy = ss.score(x_val_pca,y_val)#记录结束时间end = time.time()print("准确率是:{},消耗时间是:{}".format(accuracy,end-start))return accuracy#传递多个n_components,寻找合理的n_components:
n_s = np.linspace(0.7,0.85,num=5) #将0.7-0.85分成五份
accuracy = []
for n in n_s:tmp = n_component_analysis(n,x_train,y_train,x_val,y_val)accuracy.append(tmp)#准确率可视化
plt.plot(n_s,np.array(accuracy),"r")
plt.show()#4,确定最优模型
pca = PCA( n_components= 0.8)
pca.fit(x_train)
pca.n_components_ #能明确知道最终保留了多少个主成分x_train_pca = pca.transform(x_train)
x_val_pca = pca.transform(x_val)
ssl = svm.SVC()
ssl.fit(x_train_pca,y_train)
accuracy = ssl.score(x_val_pca,y_val)
1.2 步骤说明:
1,获取数据。
①整理数据。查看数据形状,其中数据列数为785=1+28×28,1为标签且为第一列。因此对数据进行处理分为标签和特征值。
train.iloc[: , 0 ] 获取数据标签。
train.iloc[: , 1: ] 获取特征。数据的1-784列数据(数组下标由0开始),整理后数据为图片特征值。
②head()方法查看数据前几行。
③查看具体图片
转换数据格式,并展示。
plt.imshow(num) #将数组num以图像形式 “绘制” 到内存中的 “画布”
plt.axis(“off”) #关闭坐标轴(去掉刻度、边框等),这是对已有图像的补充设置。
plt.show() #将画布数据显示在屏幕上
2,处理数据
①对数据特征值归一化处理
3,特征降维和模型训练
①svm为什么又要升维又要降维?分别什么时候进行
升维和降维的本质区别:
降维:减少特征维度(从高维→低维),目的是去除冗余 / 噪声,提升效率;
升维:增加特征维度(从低维→高维),目的是解决线性不可分问题。
SVM 的完整流程中,降维和升维可能先后发生,目标互补:
先降维:对原始高维数据进行预处理,剔除冗余 / 噪声,得到 “精简的有效特征”(如从 784 维图像→100 维主成分);
再升维:通过核函数将精简后的低维特征映射到更高维空间(如用 RBF 核),解决剩余的非线性可分问题,最终找到最优超平面。
②模型准确率升高后带来的负面影响
消耗的时间越来越长,模型越来越复杂,因此可以综合准确率以及消耗时间进行综合考虑。
③对传递参数的说明
使用PCA降维时:PCA(n_components = n)
n_components 用于指定降维后保留的特征维度数量或保留的信息比例,当数值 >1表示保留特征数量,当数值<1表示保留信息比例。
当n_components<1时,保留的特征数量并不是输出输入特征个数×n_components的值。
PCA中数据的 “信息” 用特征的 “方差” 衡量。“保留 95% 信息” 本质是:保留所有 “主成分” 中,累计方差占比达到 95% 的前 k 个主成分,k 就是最终的降维维度。
4,确定最优模型。
2. K近邻算法(KNN)
概念:如果一个样本在特征空间中K个最相似(即特征空间最邻近)的样本中的大多数属于某一类别,则该样本也属于这个类别。
2.1 使用K近邻算法预测电影类别
根据特征个数来判别电影类型。其中几个特征就使用几维的欧氏距离。
案例中使用镜头类型作为特征,进行距离计算。
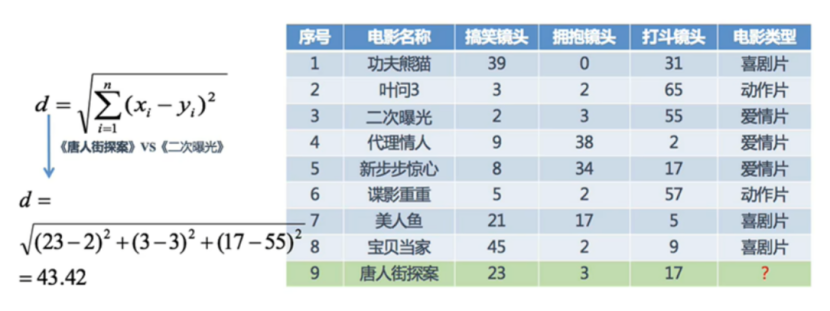
计算预测电影与每一部电影的举例,并且按照从小到大顺序排列,由于K=5,因此选出离预测电影距离最近的5部电影。
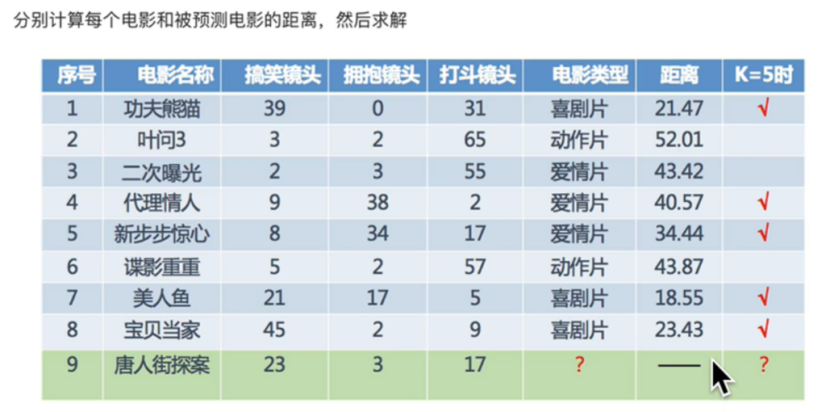
流程总结:
1,计算已知类别数据集中的点与当前点之间的距离
2,按距离递增次序排序
3,选取与当前距离最小的K个点
4,统计当前K个点类别出现的频率
5,返回K个点出现频率最高的类别作为当前点的预测
距离度量
1,距离性质:
非负性
同一性:两点距离等于0,两点为同一点
对称性:a到b的距离 = b到a的距离
直递性:a到c的距离 < ( a到b的距离 + b到c的距离 )
2.2 距离公式
(1)欧氏距离
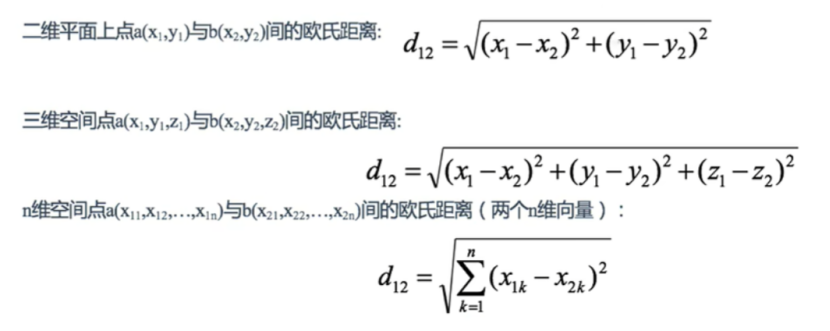
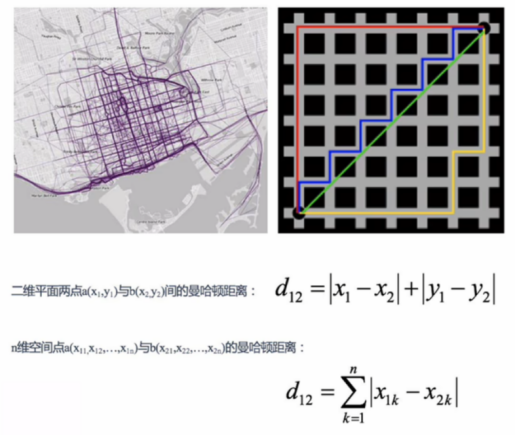
(2)曼哈顿距离
当无法在两点之间连直线时
(3)切比雪夫距离
可以直走,斜着走,横着走,从a至b的最小步数
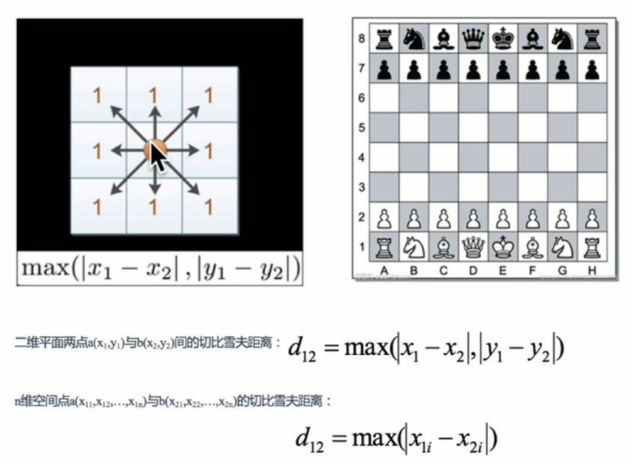
(4)闵可夫斯基距离
闵式距离是一组距离的定义,是对多个距离度量公式的概括性表示。

闵式距离缺点:
1,将各个分量的量纲(即单位)同样看待
例如存在身高和体重的三个样本:a(180,50),b(190,50),c(180,60)
dis(a,b) = dis(a,c),但是实际上升高的差距不能和体重差距划等号。
2,未考虑各个分量的分布(期望、方差等)可能是不同的
2.3 K值的选择
K过大:受样本均衡的问题。即当K正好均分时无法判别预测数据的类型。发生欠拟合。
K过小:容易受异常点影响,发生过拟合。
近似误差:
1,对现有训练集的训练误差,关注训练集
2,如果近似误差过小可能出现过拟合现象
3,模型本身不是最接近最佳模型
估计误差:
1,对现有测试集的训练误差,关注测试集
2,估计误差小说明对未知数据的预测能力好
3,模型本身最接近最佳模型
K值的选择:
1,选择较小的K值,相当于用于较小领域的训练。“学习”的近似误差会减小,同时“学习”的估计误差会增大。K值的减小意味着整体模型变复杂,容易过拟合。
2,选择较大的K值,相当于用于较大领域的训练。可以减少估计误差,但是近似误差可能会增大。与输入实例不相似的实例也会对预测结果起作用,产生预测错误。
3,K=N,N为训练样本个数。此时无论输入什么只会输出训练实例类型最多的类别。
实际应用中K值选取一个比较小的数值,采用交叉验证法来选择最优K值。
2.4 kd树
kd树:为避免每次重新计算一遍距离,算法会把距离信息保存在一颗树里,可以从树里查询之前的距离信息。基本原理,如果a与b很远,b与c很近,那么a与c很远。
kd树原理:搜索树
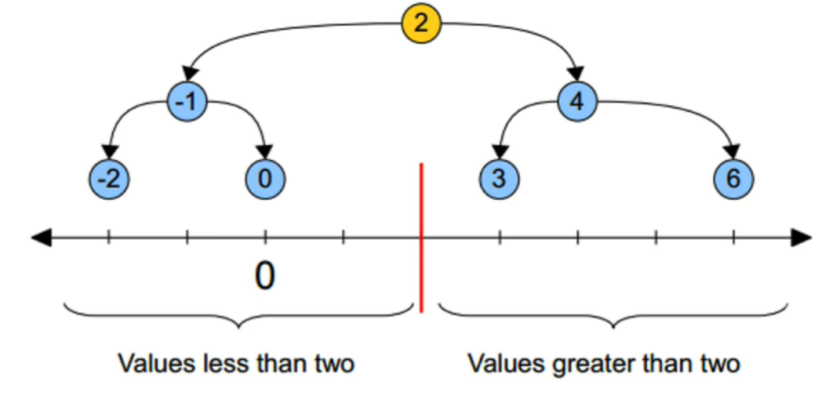
黄色的点为根节点,上面的点归左子树,下面的点归右子树。分割的线叫分割超平面。一维为点,二维为线,三维为面。
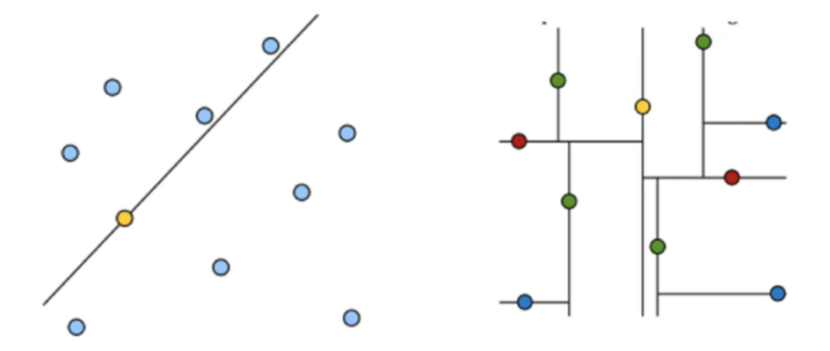
右图中黄色点为根,下一层是红色,再下一层是绿色,再下一层是蓝色。
2.4.1 如何构建kd树
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区域;
(2)通过递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形区域上选择一个坐标轴,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中位数为切分点,这样得到的kd树是平衡二叉树。
注:kd树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,kd树每层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。
在构建kd树时,关键需要解决2个问题:
(1)选择向量的哪一维进行划分
随机挑选维度或者按照顺序选择。但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。
(2)如何划分数据;
好的划分方法可以使构建的树比较平衡,可以每次选择中位数来进行划分。
案例分析:树的建立
(1)二维数据
①当数据拥有两个维度的时候,选取方差最大的维度作为划分依据。并按照选出维度进行排序选出该维度的中位数a1。距离中位数a1最近的点p1作为根节点。
例如:T={( 2,3 ) , ( 5,4 ) , ( 9,6 ) , ( 4,7 ) , ( 8,1 ) , ( 7,2 ) }。维度1:2,5,9,4,8,7;维度2:3,4,6,7,1,2。维度1数据由:2-9;维度2数据由:1-7,因此维度1的数据的方差更大,因此以维度1为划分依据。其中2,5,9,4,8,7按序排列为:2,4,5,7,8,9,中位数为6,因此5,7均可以作为根节点,选择7作为根节点
②以x1= p1将平面划分为左右两个子矩阵,左矩阵以x1排序后p1左侧的点的x2值为基准进行排序,选择中位数。
上述例子中x1=7左侧有数据:2,4,5对应的第二个维度为:3,7,4,进行排序结果为:3,4,7.得到中位数为4,因此x2 =4 为根进行下一次划分。同理,右侧以x2=6进行划分。
③递归进行上述操作。
上述例子最后可以得到特征空间的划分以及kd树如下:
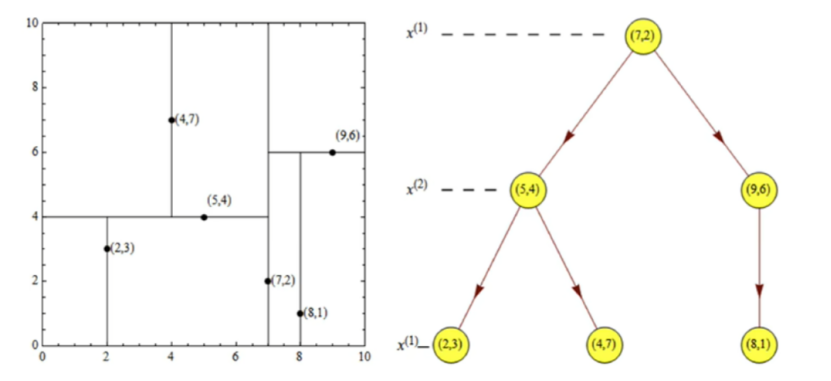
由图可知:后续在划分又是以x1为基准进行排序划分。
(2)多维数据
当数据维度为多维时,划分数据的维度如何选取?
仍然以方差为评判标准进行数据维度的选择。假设数据为5维,方差由小到大:a1,a2,a3,a4,a5,其中a5为第一次划分维度的选择,a4为第二次,a3为第三次
2.4.2 搜索
最近邻域搜索
以具体例子说明:
(1)在上述构建的kd树查找点(2.1,3.1).
①由于划分首先以x1为基准,因此2.1 < x1=7,在根的左子树进行查找
②第二层以x2为基准,因此3.1 < x2=4,此时在该节点左侧进行下一步查找
③查找得到(2,3).寻找路径为<(7,2),(5,4),(2,3)> ,取出(2,3)作为当前最佳节点nearest,dist = 0.141=√(2.1-2)2+(3.1-3)2
④回溯至(5,4),以(2.1,3.1)为圆心,dist = 0.141为半径画圆,画出的圆并不和超平面y=4相交,因此不存在更近的距离了。

(2)在上述构建的kd树查找点(2,4.5).
①由于划分首先以x1为基准,因此2 < x1=7,在根的左子树进行查找
②第二层以x2为基准,因此4.5> x2=4,此时在该节点右侧进行下一步查找
③查找得到(4,7).寻找路径为<(7,2),(5,4),(4,7)> ,取出(4,7)作为当前最佳节点nearest,dist = 3.202=√(2-4)2+(4.5-7)2
④回溯至(5,4),以(2,4.5)为圆心,dist_1 = 3.202为半径画圆,画出的圆和超平面y=4相交,因此需要跳至(5,4)的左子空间搜索,将(2,3)加入到寻找路径中,当前寻找路径<(7,2),(2,3)> ,另外(5,4)与(2,4.5)的距离dist_2=3.04 < dist_1=3.202
⑤回溯至(2,3),判断(2,3)与(2,4.5)的距离dist_3=1.5 < dist_2=3.04,更新最近距离为dist_3=1.5
⑥回溯至(7,2),以(2,4.5)为圆心,dist_3 = 1.5为半径画圆,画出的圆不和超平面x=7相交,因此无需跳转至(7,2)右子空间搜索。因此最近距离为1.5。
二、自然语言处理NLP
1. 词
词的表示的基本目的
1.判别词的相似度
例如:motel与hotel
2.推测词的关系
例如:China与Beijing的关系=Japen与Tokyo的关系
词义的表示
(1)相关的词表示词:近义词,上位词(该词属于哪一类别…)
使用相关词表示存在的问题:
1.词语之间的较小差异无法区分
2.词义会发生变化,出现新的词义。例如:苹果(水果/公司)
3.主观性的问题,受限于词典的标注
4.数据吸收
5.大量的人工去构建、维护词典
(2)把每个词表示成独立的符号
和词表一样长的向量去找一维跟这个词相对应,整个向量的维度跟词表的长度是相当的。(独热编码)
用来表示文档时非常有效,能较好地完成两个文档之间的相似度计算

方法存在的问题:
会假设词根词之间的向量任意之间都是正交的,导致任意两个词之间进行相似度计算都是0。
(3)上下文表示
任何一个词都可以用它出现的频率或者重要性去进行表示,可以得到关于每一个词的稠密向量,就可以在这个空间里面利用稠密向量来计算两个词之间的相似度

问题:
1.词表变大,存储需求也会变大
2.有些词出现频度特别少,上下文少,这种方法不好表示
基于上下文统计表示存在的问题的解决方案
词向量(Word Embedding):核心为分布式表示
词向量:将词语映射为低维、稠密的实数向量(如维度为 50、100 或 300),且向量的数值能体现词语的 “语义信息”。

分布式表示:词语的语义信息 “分布式” 存储在向量的每个维度上。不是单个维度代表 “是否为动物”,而是多个维度的数值组合共同编码 “动物属性”“大小”“习性” 等语义特征。
2. 语言模型
目的:有能力根据前文预测下一个词
主要任务
1.计算一个序列的词成为一句合法的话的概率(联合概率)
2.根据前面说过的话,预测下一个词是什么(条件概率)
如何完成任务
基本假设:一个要被预测的词只会受到它前面的词的影响

将一个句子拆解为一个个条件概率,该句成立的概率为各个条件概率的积。
语言模型架构
(1)N-gram Model(N元模型)
每一个词是一个单独的符号
4-gram只会考虑相邻的4个词,也就是前面出现的三个词来预测下一个词

4-gram图中例子,则为考虑too late to 后面出现wj的概率,在一个大规模的数据里面,分子统计too late to wj出现的频度,分母为too late to出现的频度。只考虑相邻的词,不考虑更远的词。
Bigram就是2-gram,考虑连续出现的两个词,相当于只考虑前面出现的一个词,预测下一个词是什么
Trigram就是3-gram

N-gram遵守Markov(马尔可夫)的假设,一个n元联合概率,只考虑前面的有限的几个词
问题:
1.考虑的长度通常短,N多是2或者3
2.背后还是会假设所有词相互之间都是独立的,上下文基于符号去做统计,不能理解词与词之间的相似度造成了什么
N-gram 模型存在的问题:
1,N-gram基于符号的统计方式,N越大 连续出现需预测的N个词的概率 越小,导致预测结果稀疏。
2,仍使用独热编码,无法捕捉词间类似度,仅看作一个个独立个体。例如:walking和running。
(2)神经语言模型(Neural Language Model NLM)
每一个词是一个低维的向量
用分布式的表示建构前文和当前词的预测条件概率
1.把词表示成低维的向量
2.把低维的向量拼在一起,形成一个更高的上下文的向量
3.经过非线性的转换,用向量去预测下一个词是什么
通过对上下文的表示完成,相似的词会有一个相似的向量,就有可能在语境中发挥相似的作用
预训练模型:从无标注的数据中去学习,通过自监督的一些任务然后做预训练。
无标注数据是指没有明确标签或分类信息的数据,即数据本身不包含任何预设的分类、评级或目标输出。
3. Word2Vec神经网络
Word2Vec神经网络的应用:利用简单神经网络训练得到词向量,是词的低维表示。
Word2Vec中词的分布表示:

可以展示语言规律:king与woman间的关系平行男人与女人。当词与词间关系几乎平行时表示关系几乎相同。因此Word2Vec可以学习到词汇丰富的内涵,从而捕获语言规律。
Word2Vec
使用滑动窗口构造训练数据,滑动窗口是在一段文本中连续出现的几个单词,在窗口的最中间的词叫Target目标词,其他词汇被叫做context上下文词。
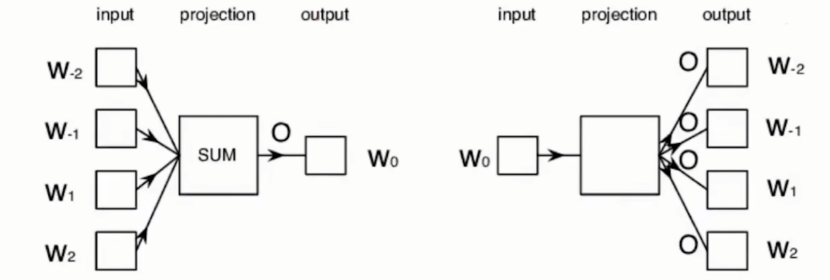
Word2Vec有两类模型
(1)CBOW(continuous bag-of-words):给定context,预测target的可能。下图左侧。
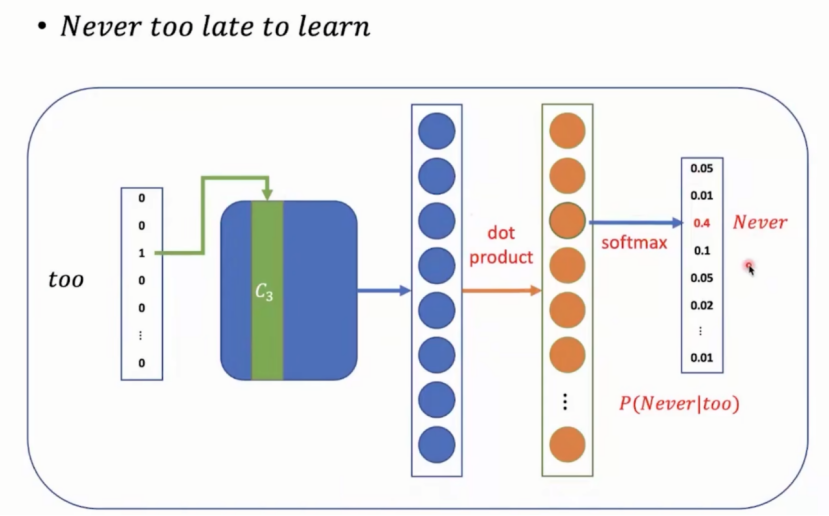
(2)continuous skip-gram:给定target,预测context的可能。下图右侧。
窗口图如下:以窗口大小=5为例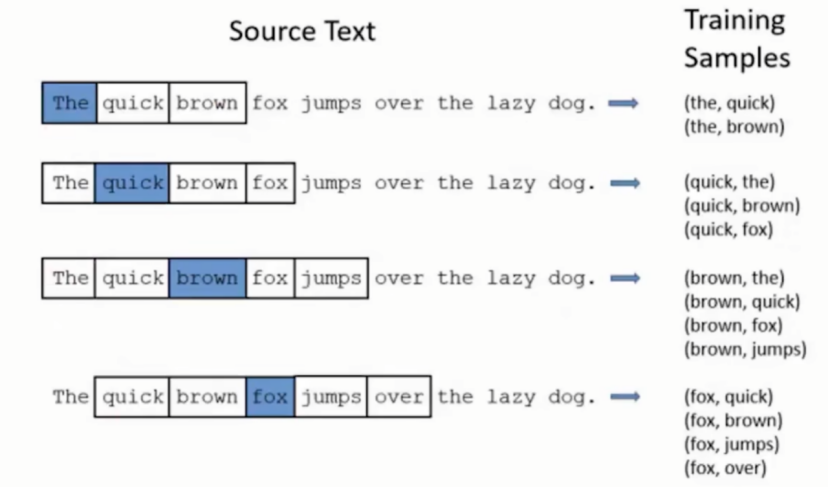
需要注意当target在最左侧时,窗口并不完整,无需补齐。
3. 1 CBOW模型
CBOW:假设context顺序不影响对target的预测
给出never和late预测中间too的可能的过程分析:
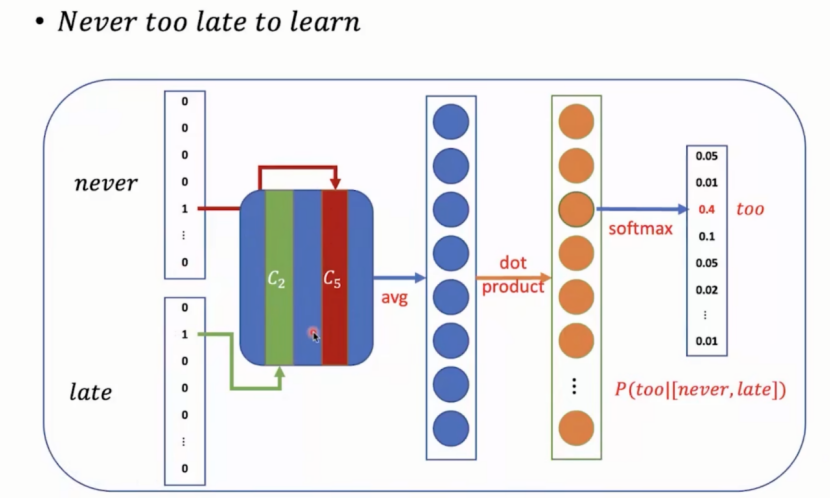
context使用one-hot表示,在最终的词向量矩阵中找到never和late分别对应的词向量,将两者相加取均值,得到一个新向量。为了预测too的可能性,将问题视作N分类问题,对所有词进行分类(N表示词表大小)。因此输出层设置为词表大小N维度,并进行softmax。若要N维向量则需要将得到的取均值的新向量经过变换得到一个N维新向量。Softmax后得到词的概率。
CBOW补充理解:
(1)词向量矩阵:
- 行数=词表中词的数量;
- 列数=每个词向量的维度。是人为设定的超参数,词向量尺寸的选择会影响模型对词语义信息的表示能力,维度越高理论上能捕捉到的语义信息越丰富,但同时也会增加计算量和模型训练的复杂度。
- 词表大小:
词表大小主要与语料库中出现的不同词的数量有关。
两者间的关系:词表大小决定了词向量矩阵的行数
(2)
Softmax 函数主要用于将一组任意实数的向量,转换为一个概率分布
3. 2 continuous skip-gram模型
对于句子never too late to learn,如果too是target,窗口大小为5,模型需要预测出never,late,to。模型结构同CBOW
在模型计算过程中由于词库中词的数据量大,计算量也非常大,因此需要对计算过程进行取舍,有两种方法提高效率:
(1)负采样
不对整个库数据使用softmax计算概率,采取一小部分作为负例(负例非预测词)。
如何进行负例采样?
按照词的频率采样,频率越高被采样可能越大。同时做出调整将词汇概率取四分之三次方,使得低频词汇也有概率被采样到。
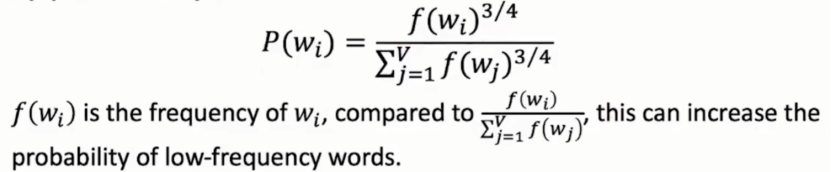
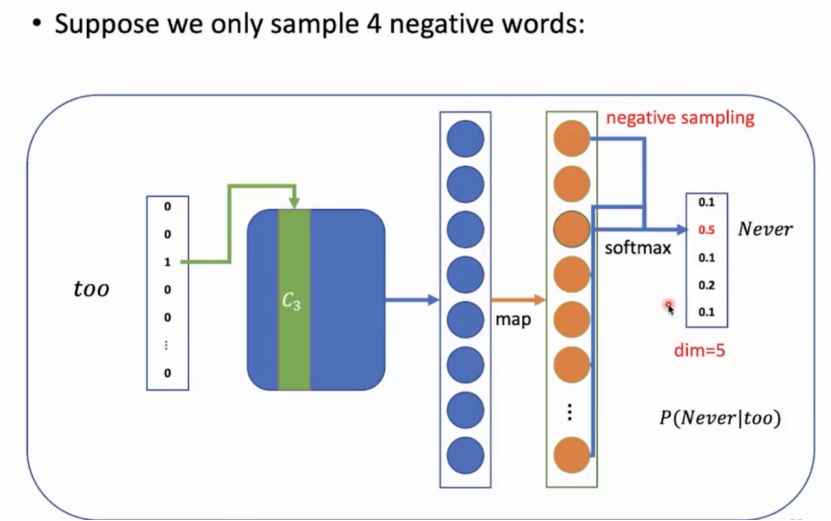
具体例子:continuous skip-gram模型为例进行负采样:
只取四个负样因此最终只展示五个概率
负采样优点:大量减少计算量
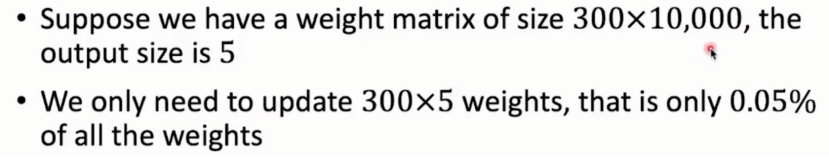
(2)分层softmax
Word2Vec其他训练技巧:
(1)Sub-sampling:平衡常见词和罕见词。罕见词出现概率低,包含丰富的语义。Sub-sampling会在具体训练过程中去掉一些词,去掉概率如下:
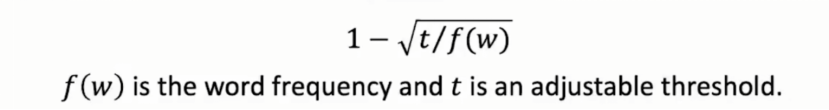
由公式可知:当词频率越高,被去掉的可能性也越高,t为可调整参数。
(2)word2vec拥有非固定的滑动窗口。
窗口大小:设置一个滑动窗口最大值Smax,生成数据时由1-max之间采样,并让该值作为本次训练滑动窗口的大小。此时,离target更近的词会有更大概率被采样成context进行训练。
4. 神经网络模型
4.1 循环神经网络RNN
处理序列数据期间会进行递归更新顺序记忆。
序列数据:一段文字,音频都是序列数据。
顺序记忆:对字母表a-z的顺序十分熟悉,但是对于z-a逆向就需要时间反应。因此顺序记忆更有利于使我们的大脑更容易识别这些序列模式的数据的机制。
4.1.1 RNN模型类型
1 V 1(1对1):
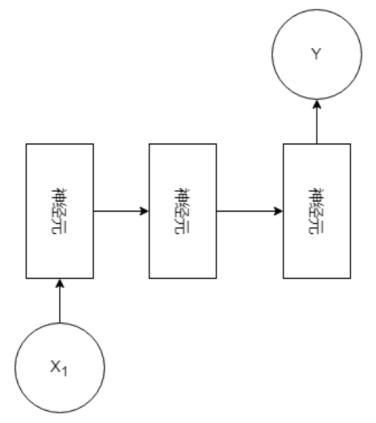
1 V N(1对多):
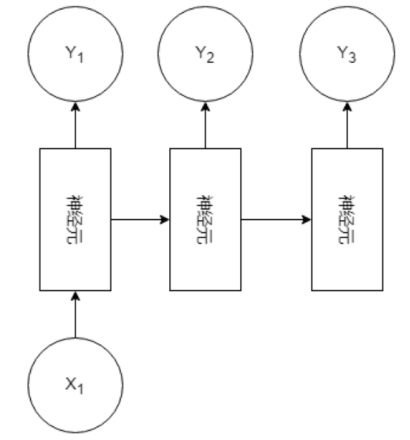
N V 1(多对1):
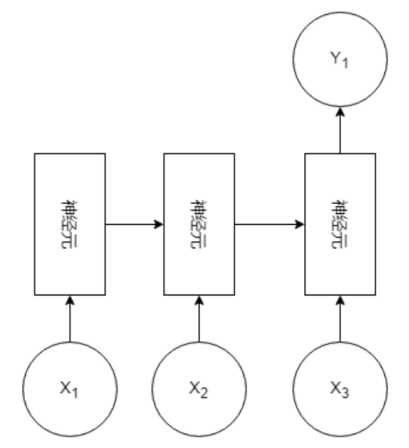
N V N(多对多):
4.1.2 RNN模型结构
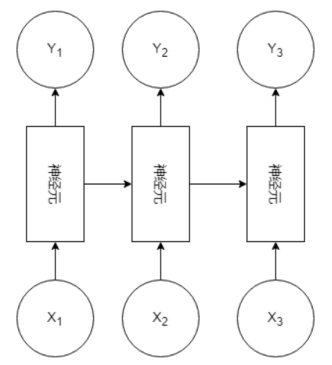
- 输入层:x为一个个不定长的序列数据
- 隐藏层:h为一个不同时间步下的一个状态变量,存储一些输入信息。时间步:可能不是传统意义上的时间,而是一个具有前后顺序的变量
- 输出层:y对应每一个x的输出。例如:h1接触x1与隐藏状态h0后才传入输出层得到输出结果y1
一个基本RNN 单元(RNN Cell):
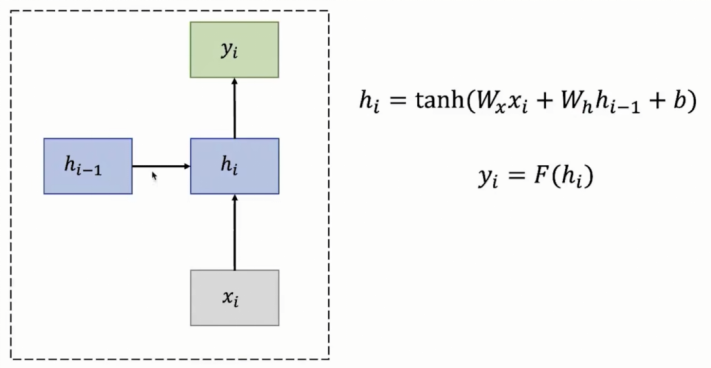
数据说明:
- W(x)负责输入到隐藏状态的信息传递权重,W(h)负责隐藏状态间的信息传递权重,二者都在模型训练过程中通过反向传播自动学习得到。
补充说明:
① W(h)是上一时刻隐藏状态h(i-1)到当前时刻隐藏状态h(i)的权重矩阵。它体现了 RNN 中 “记忆” 的传递,即上一时刻的隐藏状态对当前时刻隐藏状态的影响。
② W(x)是输入x(i)到隐藏状态h(i)的权重矩阵。它用于衡量当前时刻输入x(i)对当前隐藏状态h(i)的影响程度。通过反向传播算法进行优化
由数据可知,每一次隐藏层时间步的状态变量计算结果都依赖于过去的一个时间步的状态变量进行计算,因此RNN是一个顺序记忆
4.1.3 RNN模型对词的预测流程
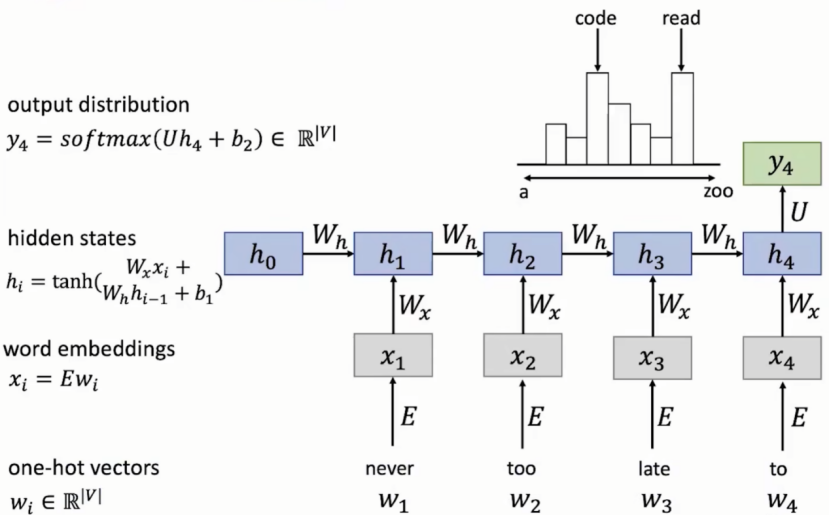
①输入一个句子,首先将它们划分为一个个词never,too,late,to,因为RNN按照顺序工作,每次仅接受一个词进行处理。
②将never输入,经计算得会得到一个输出
③并前一层的状态变量传给下一层,层层计算得到h4,由于h4已经包含前面所有词的状态变量,因此h4对句子下一个词的预测把握最大
④输出y4并进行softmax计算词库中所有词位于预测位的概率,由上图知下一个词code和read的概率最大。
注:隐藏层中的计算类似下图:
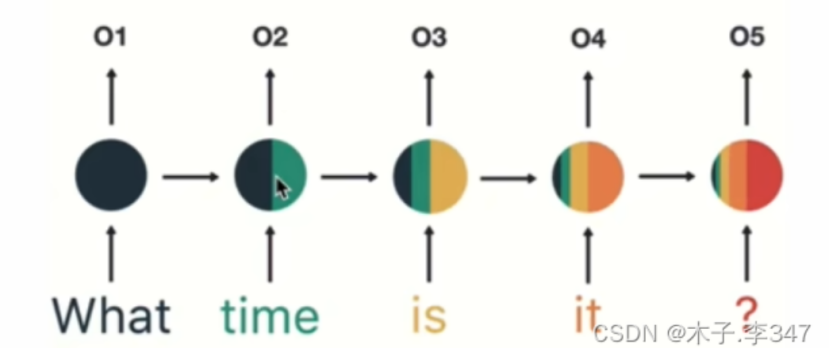
W(h)(循环权重矩阵)和W(x)(输入权重矩阵)确实是固定的、共享的,原因如下:
(1)减少参数数量,提升训练效率;
(2)学习通用的时序模式,增强泛化能力;
每一个RNN单元都是不断地复制,因此每个RNN单元功能相同,可以很好实现参数共享。如果每个时间步都用不同的W(x)和W(h),模型参数会爆炸式增长。
(3)让模型以统一的逻辑处理序列中每个位置的信息。
4.1.4 RNN应用场景以及优缺点
RNN应用场景
- 序列标注(Sequence Labeling):给出一个句子,推测句中单词词性的要求
- 序列预测(Sequence Prediction):给出一周温度,预测天气
- 图像描述(Photograph Description):给定图片描述图片内容
- 文本分类(Text Classification)
RNN优点:
- 输入任何长度
- 模型大小不受输入影响
- 参数共享
- 步骤循环
RNN缺点:
- 需要计算前一个单元的学习结果,才能得到后面的结果,时间较久。
- 当RNN单元过多,后面单元的计算很难获取前面单元的结果。
4.1.5 梯度消失和梯度爆炸

随着层数增加,反向传播的计算层数也越来越多。
当梯度>1时,随层数(时间步)增加梯度呈指数增长,出现梯度爆炸;
当梯度<1时,随层数(时间步)增加梯度呈指数衰减,出现梯度消失。
解决办法:
(1)优化单元:寻找更好更复杂的单元计算,常见单元变体方法:
1,门控循环单元GRU
2,长短期记忆网络LSTM
两者核心:计算时保存周围信息进行数据处理以捕捉长距离依赖性。
4.1.6 双向RNN
传统RNN依赖已输入的数据,实际应用中可能需要完整的输入序列才能得到输出。完整的序列指已输入的数据以及待输入数据序列。
双向RNN结构图:
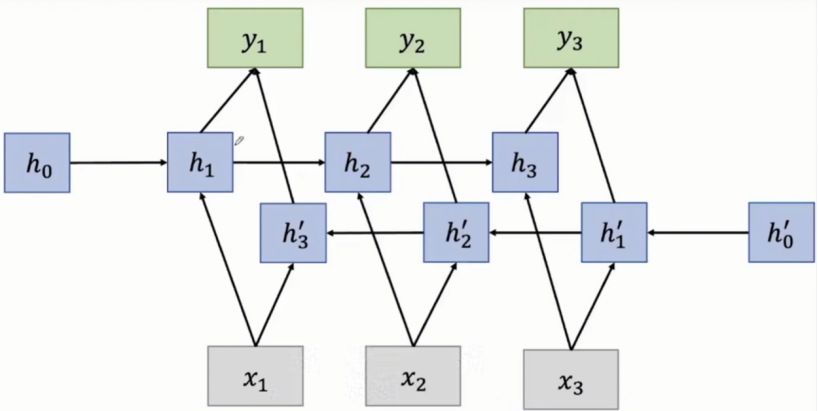
每一个时刻对应的输入同时会拿到正向RNN的状态向量h(对过去信息的总结)以及逆向RNN的状态向量h`(对未来信息的总结)
4.1.7 CNN与RNN比较
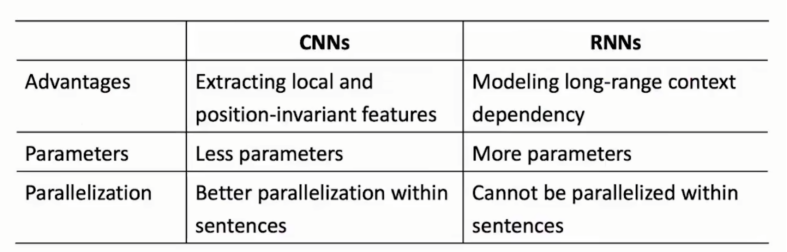
- CNN擅长提取局部特征,CNN 通过卷积操作和池化操作,能够自动识别数据中的局部特征(如边缘、纹理、形状等),并通过层级结构组合成更复杂的全局特征。
- RNN擅长处理 “时序序列数据”。RNN 通过循环结构将上一时刻的输出作为当前时刻的输入,能够处理长度可变的序列数据,并学习时序上的依赖关系。
由于机制不同:
①RNN的参数量较多;
②CNN的核心计算于卷积部分,且计算间无相互依赖,可以很好并行;RNN需要上一步的计算结果才能计算当前数据。
4.2 门控循环单元GRU
引入门控机制。“门”打开,信息进来,“门”关闭,信息滞留,因此该机制决定哪些信息可以传入下一层。
4.2.1 核心结构
更新门和重置门。

其中,σ是 Sigmoid 激活函数,它将值映射到0-1 区间。式子中也需要上一次的状态变量以及输入x,但是权重矩阵发生变化。每个门都有自己的专属权重。
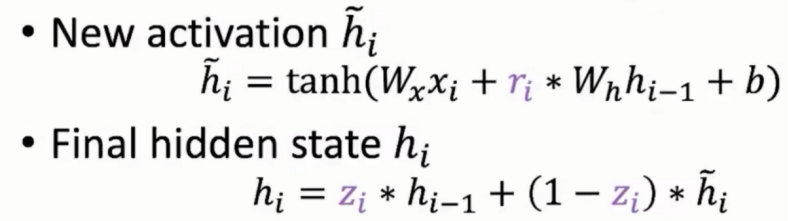
tanh是双曲正切激活函数,将值映射到 -1 - 1区间。重置门考虑到上一层隐藏的状态对当前的影响,须通过计算获取新的激活h_1(i)。更新门权衡当前新得到的激活h_1(i)和过去状态h(i-1)
4.2.2 计算过程
①首先计算更新门和重置门的门值,分别是 z (i) 和 r (i),计算方法就是使用 X (i) 与 h (i-1) 拼接进行线性变换,再经过 sigmoid 激活。
②之后更新门门值作用在了 h (i-1) 上,代表控制上一时间步传来的信息有多少可以被利用。接着就是使用这个更新后的 h (i-1) 进行基本的 RNN 计算,即与 x (i) 拼接进行线性变化,经过 tanh 激活,得到 h_1(i)。
③最后(1-更新门的门值)会作用在 h_1 (i),而更新门值会作用在 h (i-1) 上,随后将两者的结果相加,得到最终的隐含状态输出 h (i),这个过程意味着重置门有能力重置之前所有的计算,当门值趋于 1 时,输出就是新的 h (i),而当门值趋于 0 时,输出就是上一时间步的 h (i-1)。
当重置门无限接近于0时,新的激活值就与上一个隐藏状态无关。
具体事例中:在一个新文章的开头,它过去的信息对当下结果是无用的。
对于更新门,控制过去状态和当前激活的关系大小

4.3 长短期记忆网络LSTM
结构图
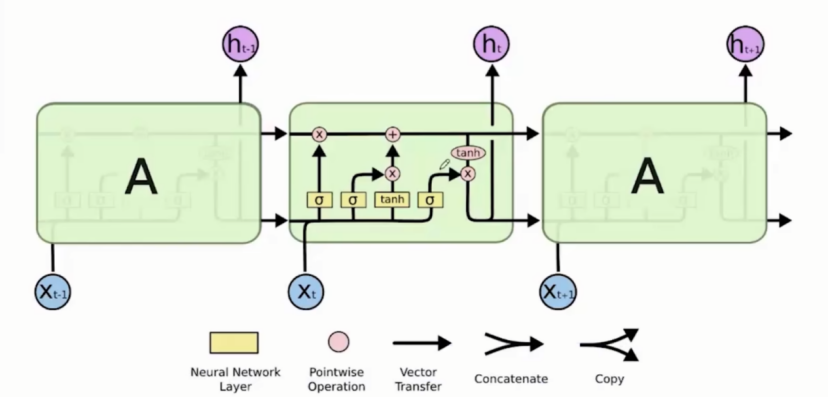
数据说明:
黄色方框:神经网络层
粉色圈圈:元素间操作
一个箭头:箭头走向表示向量流的传递
线的合并:向量间进行合并
线的分叉:表示向量间的拷贝与复制
4.3.1 核心部分
- 遗忘门:决定可以当前上一个状态有哪些信息可以从细胞状态(cell state)中移除
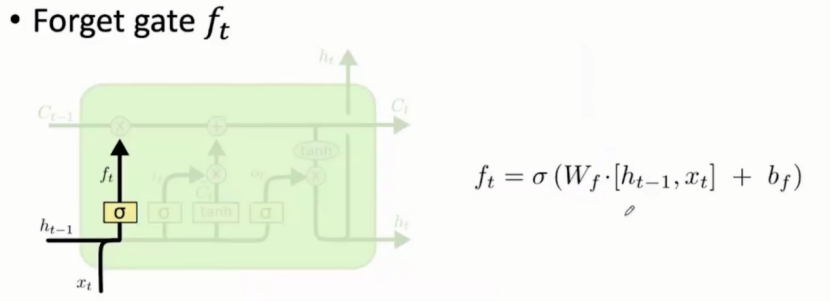
计算小细节:当前输出与上一层状态连接,再与遗忘门专属权重矩阵和偏置值进行运算。最终结果 0 - 1。
如果f(t)=0,表示是遗忘门,过去的信息直接丢弃。
-
输入门:决定哪些信息需要被存储到细胞状态(cell state)
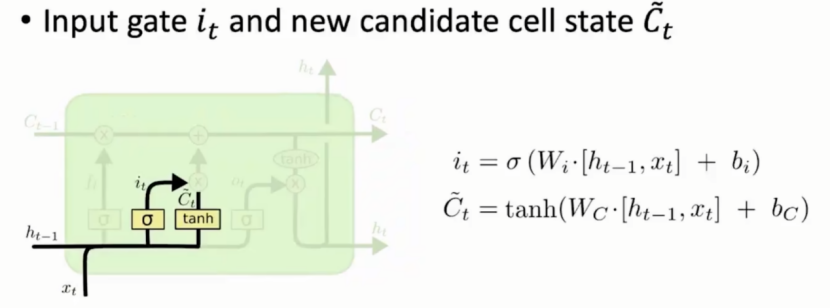
输入门的计算和遗忘门类似,同时还需要通过当前输入计算待选信息向量C`(t)。
由图可知输入门主要控制待选信息向量C(t)中的哪些信息需要存入细胞状态 -
细胞状态(cell state): LSTM关键的新增值。
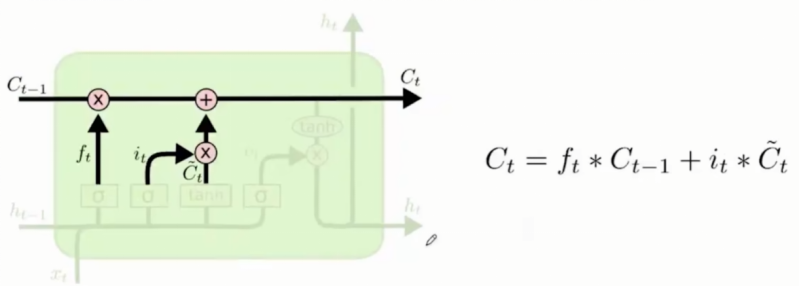
对之前的信息向量进行筛选:遗忘门与前一个细胞状态乘积来更新旧的细胞状态。还需要加入新的信息:待选新的信息向量与输入门的乘积,最终将两者结合得到当前哪些信息能够加入cell state内。 -
输出门:决定哪些信息可以进行输出
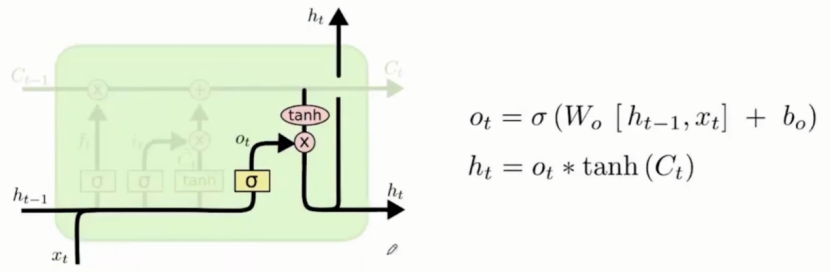
对信息的调整来适应一些特定单词的表达。
总结
下周将完成K近邻算法的学习,并对K近邻算法进行实操。同时继续自然语言处理的学习。需要注意的是对于内容要及时复习,否则容易遗忘。