CMU15445(2023fall) Project #1 - Buffer Pool Manager优化分析
暮色从勒勒车的辙痕里漫上来时
长生天点燃了云絮
风是沉默的萨满
将草浪诵成经文
完整代码见:
SnowLegend-star/CMU15445-2023fall: Having Conquered the Loftiest Peak, We Stand But a Step Away from Victory in This Stage. With unwavering determination, we press onward, for destiny favors those brave enough to forge ahead, cutting through the thorns and overcoming every obstacle that dares to stand in their way.
目录
一、问题背景
二、解决思路
2.1 优化思路
2.2 架构设计
2.3 写操作的执行流程
2.4 可行性分析
三、性能展示
3.1 优化前
3.2 加入WriteRequestQueue
3.3 加入ThreadPool
3.4 对比总结
未完待续
一、问题背景
我们在实现基础版本时候,可以发现当前的读写过程有个很明显的阻塞现象。
就拿Write的调用链来分析:
auto BufferPoolManager::FlushPage(page_id_t page_id) -> bool {std::scoped_lock<std::mutex> lock(latch_);BUSTUB_ASSERT(page_id != INVALID_PAGE_ID, "page_id is invalid");auto it = page_table_.find(page_id);if (it == page_table_.end()) {return false;}auto w_frame_id = it->second;auto promise = disk_scheduler_->CreatePromise();auto future = promise.get_future();disk_scheduler_->Schedule({true, pages_[w_frame_id].data_, pages_[w_frame_id].page_id_, std::move(promise)});future.get();pages_[w_frame_id].is_dirty_ = false;return true;
}auto CreatePromise() -> DiskSchedulerPromise { return {}; };void DiskScheduler::Schedule(DiskRequest r) { request_queue_.Put(std::move(r)); }void DiskScheduler::StartWorkerThread() {std::optional<DiskRequest> request;while ((request = request_queue_.Get())) {if (request) {if (request->is_write_) {disk_manager_->WritePage(request->page_id_, request->data_);request->callback_.set_value(true);continue;}disk_manager_->ReadPage(request->page_id_, request->data_);request->callback_.set_value(true);}}
}void DiskManager::WritePage(page_id_t page_id, const char *page_data) {std::scoped_lock scoped_db_io_latch(db_io_latch_);size_t offset = static_cast<size_t>(page_id) * BUSTUB_PAGE_SIZE;// set write cursor to offsetnum_writes_ += 1;db_io_.seekp(offset);db_io_.write(page_data, BUSTUB_PAGE_SIZE);// check for I/O errorif (db_io_.bad()) {LOG_DEBUG("I/O error while writing");return;}// needs to flush to keep disk file in syncdb_io_.flush();
}具体如下:
| 阶段 | 执行线程 | 动作 |
|---|---|---|
| (1) 创建 promise/future | 前端线程(比如 B+Tree Executor) | auto future1 = promise1.get_future() |
| (2) 提交请求到队列 | 前端线程 | request_queue_.Put() |
| (3) 阻塞等待结果 | 前端线程 | future1.get() 阻塞 |
| (4) 工作线程取任务 | I/O worker 线程 | 调用 disk_manager_->WritePage() |
| (5) 写入完成后唤醒 | I/O worker 线程 | request->callback_.set_value(true) |
| (6) 前端线程恢复 | 前端线程 | future1.get() 成功,继续执行后续逻辑 |
在阅读了leveldb等工业级的代码之后,我们就可以发现【同步等待】其实是很不可取的现象,实在是太浪费CPU了。主要有三大弊端:
-
用户需要等待这个【IO操作】结束之后才能收到msg。表面上这么做是合理的,但是如果BPM当前存在大量IO,那用户侧可能会过很久才能收到操作的msg。这无疑会极大地降低用户对服务质量的评价。虽然bustub还只是一个偏教学的项目,但我还是推荐咱们在优化的过程中尽量往工业级实现靠拢——为了【提高QPS】可以不择手段hhh。
-
【单线程】写入。在调用了
disk_scheduler_的R/W接口后,其实之后一个StartWorkerThread在后台执行。最朴素的执行思路带来的就是最缓慢的写入效率。 -
每次Read都是从磁盘读取。这点就比较难发现了,需要我们真正去实现了前面两点之后才能进一步想到这个缺陷。
二、解决思路
2.1 优化思路
在明确当前系统存在的待改进之处后,我们就可以着手设计对应的解决思路了。对应的,可以大致想到三种应对之策:
-
异步写入。划重点,这个真得考的。在工业级别的代码实现上,更愿意采用异步写入的方式来处理请求,大致思路就是:用户发来一个请求,系统把请求扔给后台线程就继续执行了,通过callback函数来处理后序的逻辑。主进程不会一直干等这个处理线程执行完毕。相当于主线程谎报军情,提前告诉用户这次IO操作【执行完毕】了,注意这里不是告诉用户【执行成功】。
-
多线程执行(线程池)。我们去细看
DiskManager这个类的WritePage操作,可以发现在写入磁盘的时候也是会加入一把锁db_io_latch_的,即同一时刻只有一个线程可以去写磁盘。那为什么还需要线程池呢?我的理解是线程池也相当于一个【缓冲】,同时可以接受更多IO请求,在用户层面看来系统的QPS确实是会更高。但是,磁盘IO的QPS在当前情况下时恒定不变的。所以,我们加入【线程池】这个优化后,实际上的QPS提升没那么明显。 -
设计Write队列。在采用了【异步写入】和【线程池】两种策略之后,那我们还需要某个数据结构来存储还没正式执行的IO操作,同时还要保证对于每个PAGE,IO操作的先后顺序不能颠倒。则【请求队列】这个思路自然而然了,那是否需要设计【Read队列】呢?我个人感觉都行
-
设计一个cache进行读取。既然有了【写入队列】,那就说明某个【PAGE】的Write操作还没正式落盘,仍然驻留在内存里面。此时,如果我们需要读取这个磁盘的内容,那就直接读取内存中这份还没落盘的最新修改即可。故而,我们给每个【写入队列】设置一个【cache_】成员变量,就用来存储最新的那次修改。
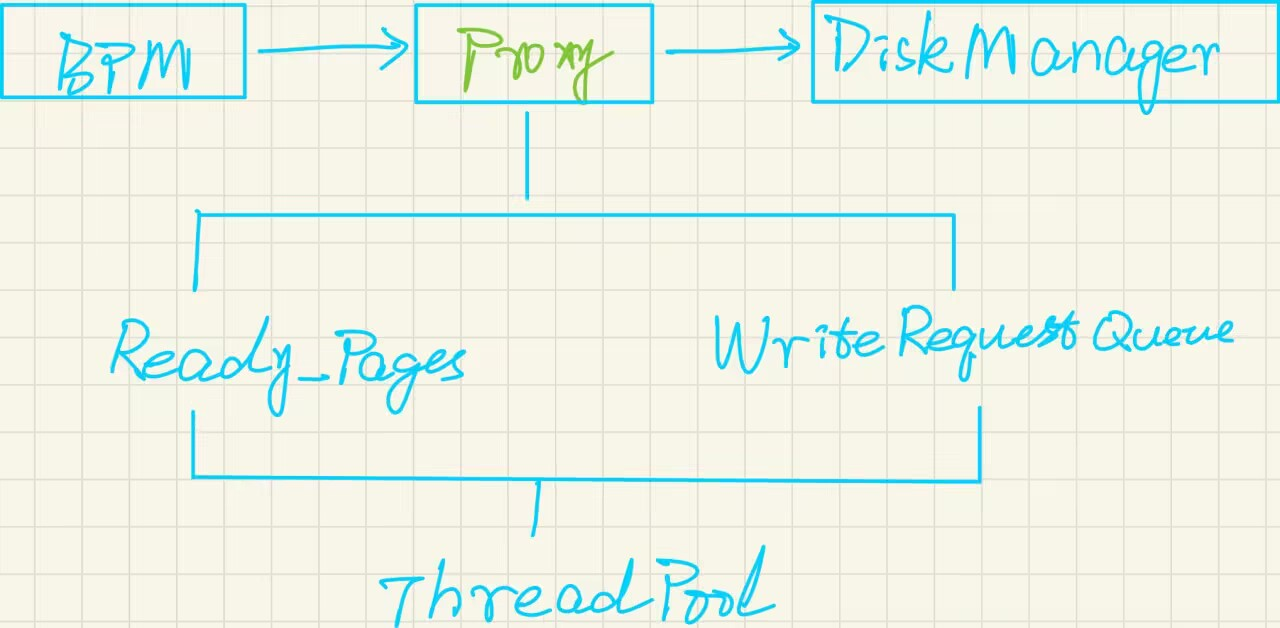
2.2 架构设计
我们在BufferPoolManager和DiskManager类之间添加一个Proxy模块,这个Proxy模块里面就承载了我们的优化方案,大致的设计架构如下
-
DiskWriteRequest类,用来包装每个Write请求。 -
DiskWriteRequestQueue类。每个PAGE对应一个Queue,只有队列的头部元素可以被处理,确保单个PAGE的写入顺序符合预期。 -
ThreadPool类。一个简单的线程池,不再赘述。 -
DiskManagerProxy类。就是Proxy模块的具体实现。考虑到并发性,我们还需要把当前有Write任务的PAGE用队列组织起来,然后依次处理。
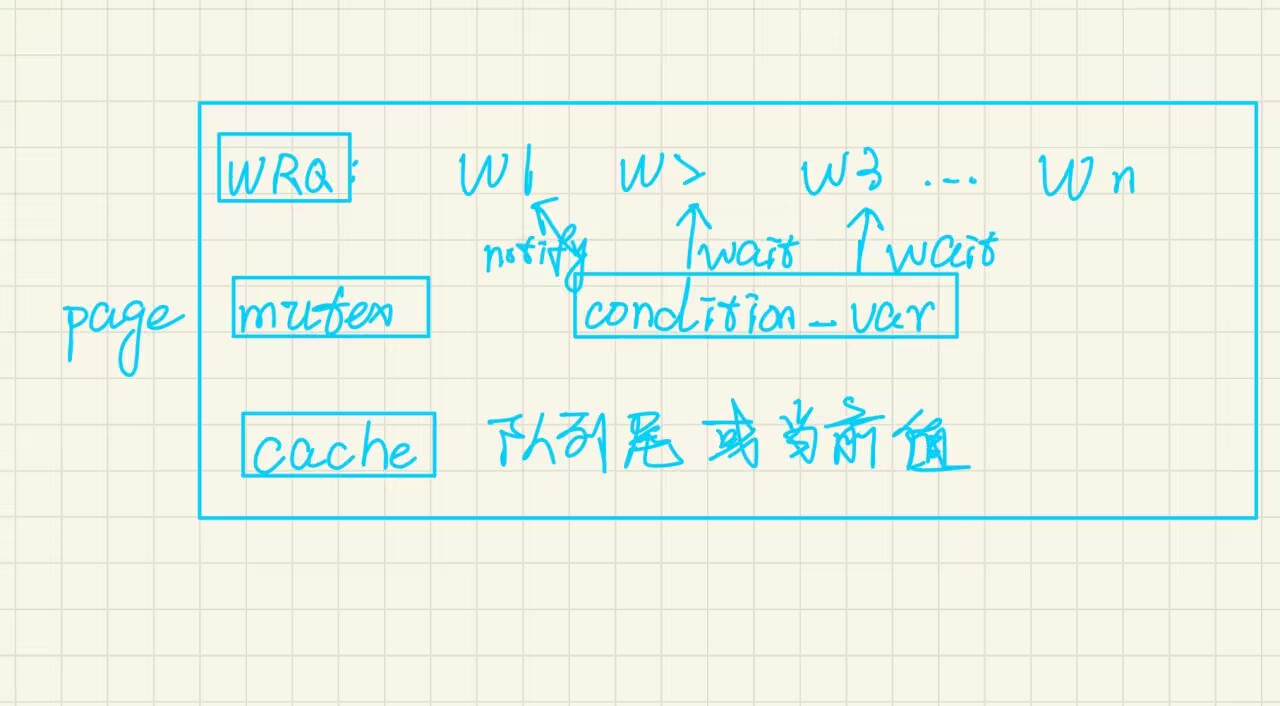
下图则是DiskWriteRequestQueue类的大致架构图。就是用【condition】和【mutex】维护队列的有序性,具体实现可以随意发挥。
2.3 写操作的执行流程
| 步骤 | 执行线程 | 说明 |
|---|---|---|
① WritePage(pid, data) | 前端线程 | 复制数据 → 入队 |
| ② 判断是否队列为空 | 前端线程 | 如果为空说明无其他写,立即加入 ready 队列 |
③ WorkerLoop() | 后端线程池 | 取出一个 ready pid |
④ WaitUntilHead() | 后端线程池 | 确保当前写请求是队首(保证 per-page 顺序) |
⑤ disk_manager_->WritePage() | 后端线程池 | 实际写盘(阻塞I/O) |
⑥ PopFrontAndNotify() | 后端线程池 | 出队 + 通知下一个等待者 |
| ⑦ 若仍有剩余请求 | 后端线程池 | 再次将该 pid requeue,继续调度 |
⑧ ReadPage() | 任意线程 | 若写缓存命中,则直接 memcpy 最新版本;否则从磁盘同步读。 |
2.4 可行性分析
看完了上述优化思路后,各位【敏锐的架构师】很容易意识到一个问题——上述的优化思路需要大量的内存作为支撑,这不就是用空间换时间吗?Bingo!还真是如此。
既然这样,那一开始根据内存容量给BPM分配足够的PAGES不行吗?这样就不用反复对PAGE进行Evict并刷盘的操作了。或者说,我们设计的DBMS根据当前的吞吐动态申请或者释放PAGE。在我看来,我们用本文的方案要比DBMS动态申请PAGE要更灵活。本文的方案只是用了额外的内存而已,并没有引入其他复杂的管理机智。而如果要在DBMS层面来设计申请PAGE的方案,那就势必会引入多种复杂的机制了。如果DBMS涉及频繁的动态调整,那无疑会浪费CPU的性能。
一言蔽之,我认为本文方案的可取之处还是要更优的。
三、性能展示
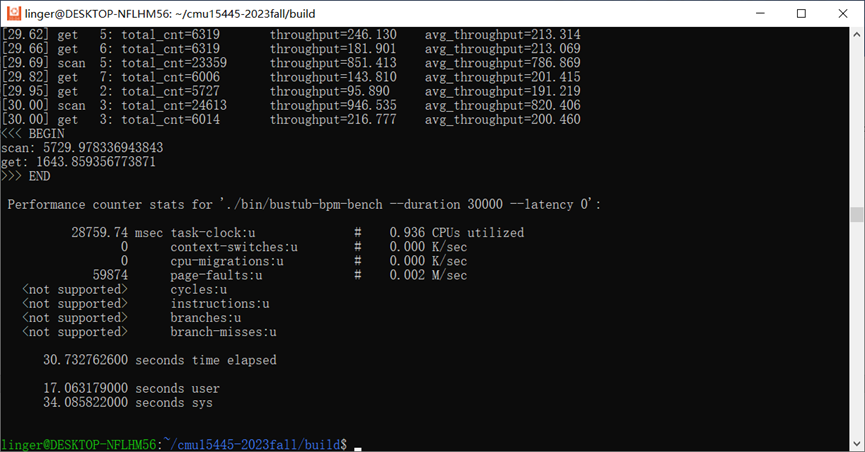
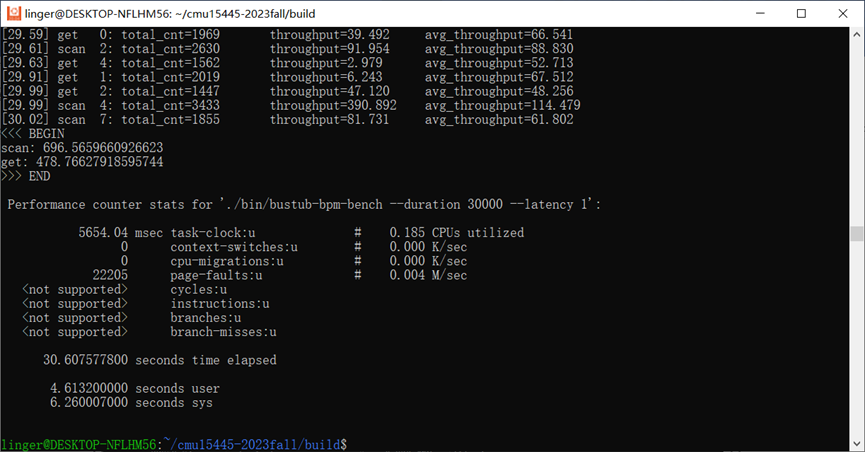
3.1 优化前
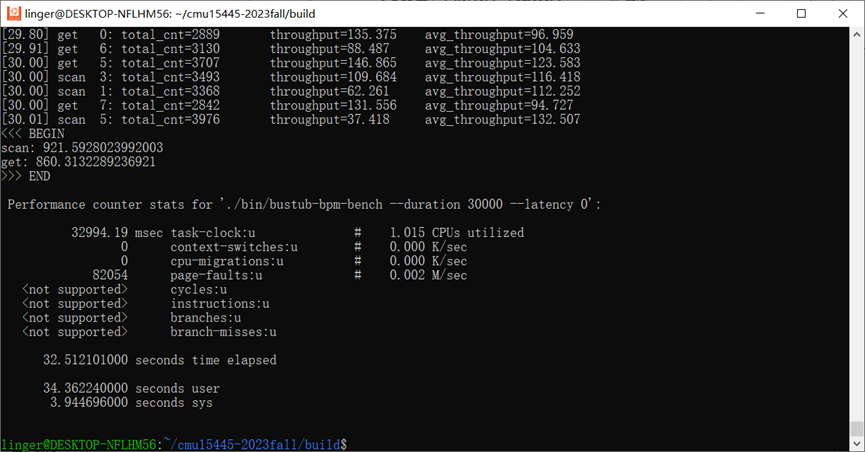
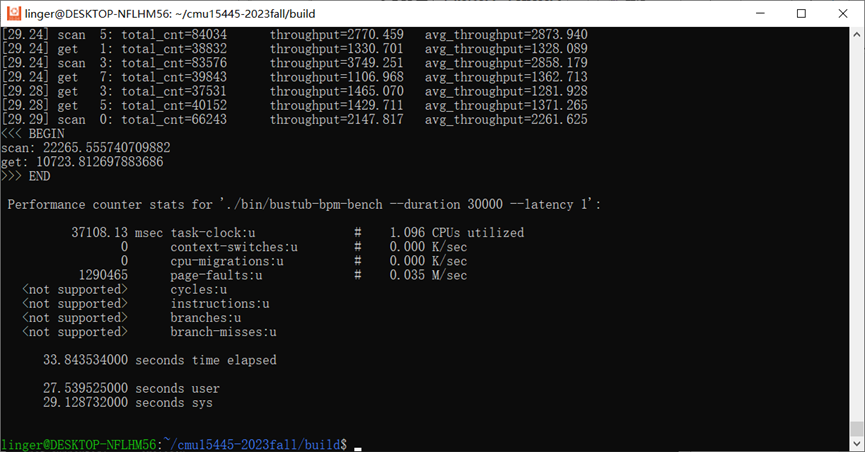
3.2 加入WriteRequestQueue
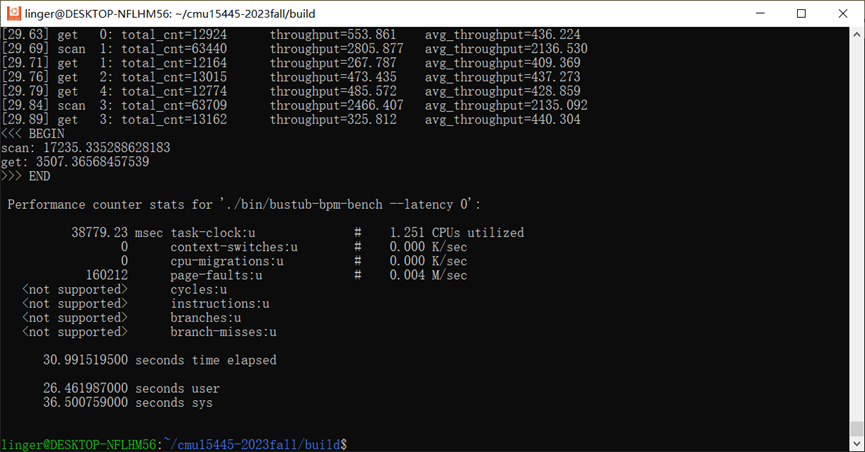
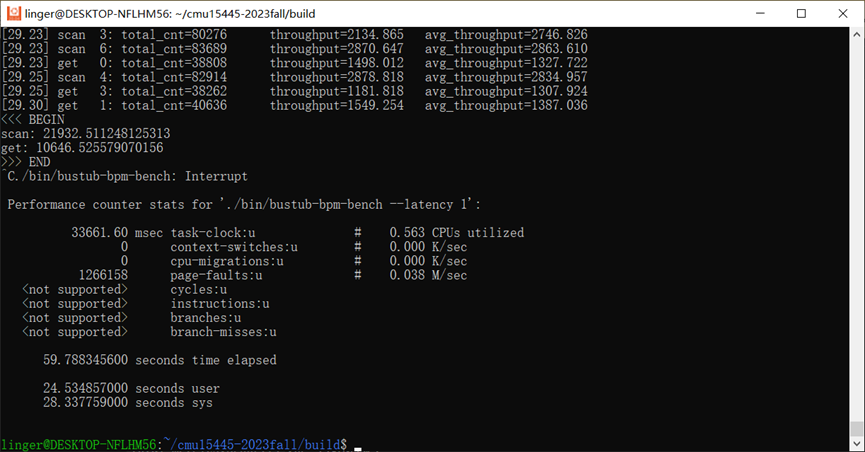
3.3 加入ThreadPool
3.4 对比总结
我们可以发现,单纯加入了WriteRequestQueue后,在写入磁盘IO延迟为0的条件下,性能反而下降了。我的猜测是加入了写队列后,由于mutex和condition机制本身也会有一定的处理时间,故总体导致了更差的性能。其实在工业环境中,磁盘IO延迟必然是存在的,而且要远远大于我们操作内存同步原语的时间,所以我们重点关注存在磁盘IO延迟的情况。
而ThreadPool通过先缓存下来大量的写操作,是确确实实可以提到Client端的QPS的。把ThreadPool和WriteRequestQueue结合起来后,我们在磁盘IO延迟为0的情况下也明显表现更优了。
未完待续
除了文中提到的优化,还有其他方案可以加进来。比如【写合并】和【批量写】就是很常用的设计思路。
-
写合并。一个 page 被多次修改,只在最终落盘时写一次。
-
批量写。让多个写请求合并成一个批量写(比如每 4MB 批次),减少系统调用与磁盘寻道次数。
如果各位架构师此前没有接触过工业级的代码,那要想到这几个方案其实真的有点困难。倒也不必气馁,闻道有先后嘛,按部就班完成bustub已经胜过许多人了。至于后续的学习历程,可以去看看leveldb的源码分析。然后找段实习看看工业界的设计思路。最后回过头来看我们最初设计的bustub,和当初懵懂的自己来一场跨越时间的对话,其实也是很浪漫的。
诸位共勉~
TO BE CONTINUED