深入理解操作系统中的线程
文章目录
-
- 写在文章开头
- 详解线程结构设计与常见问题
-
- 线程的历史和基本理念
- 线程基本数据结构分配
- 线程的基本使用示例
- 线程的调度
- 详解线程栈的基本调用
- 线程栈的内存分配策略
- 用户态线程和内核态线程的探究
- 小结
- 参考
写在文章开头
本文将从操作系统底层深入探究线程的诞生及其出色的设计理念和调度策略,通过对本文的阅读,你将对计算程序设计的基本理念和设计思想有着更深一步的掌握。
详解线程结构设计与常见问题
线程的历史和基本理念
传统操作系统的理念下,进程是一个相对重量级的单位,本质上都是由一个地址空间和一个控制线程构成。对于现代计算机而言,许多的应用活动会随着时间的推移而陷入组阻塞。于是就有了基于进程这一单位衍生出一个更加轻量级的准并行运行单位——线程。
通过多个轻量级进程共享进程的地址空间和所有可用的数据,以更加轻量级、创建效率比进程快10~100倍的表现快速完成多道工序并销毁,保证降低开销都同时,提升程序执行效率。
这种设计理念在现代操作系统表现会带来质的提升,例如一个支持查找、全局替换、生成分页的字处理软件,按照单进程(线程)的情况下,针对如下工作这种单文件视为单进程(线程单位),都可以通过一条指令一次性针对一个文本书籍进行全局管理:
- 文本检查
- 指定文字替换
- 生成页分隔符
对此我们试想一下这样一个场景,我们的字处理软件收到一个300页的未整理过的文件,此时我们希望定位到600页并删除某一行数据,在原有的线程模型模式下,对应处理步骤则是:
- 整理文件,确定分页
- 定位到指定数据行
- 删除数据,重新分页
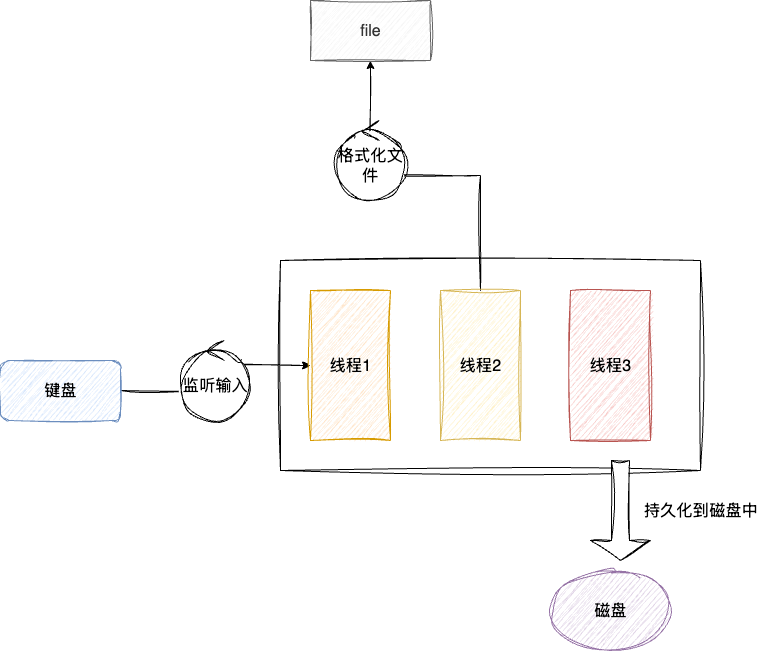
这种模式就意味着如果在分页未完成之前,步骤二和步骤三就无法执行。此时我们就可以引入多线程的方案,分别确立:
- 一个后台写入刷盘持久化
- 自动分页格式化建立分隔符
- 读取键盘输入
这3个线程处理这些工作,在理想的情况下,我们的修改操作完全在格式化线程处理完成之后,快速定位到600页数据完成修改,通过多线程尽可能利用CPU时间片的每一个时间片,尽可能完成文件处理的任何一个工序,避免单进程阻塞带来耗时等待,这就是多线程的设计的哲学:
线程基本数据结构分配
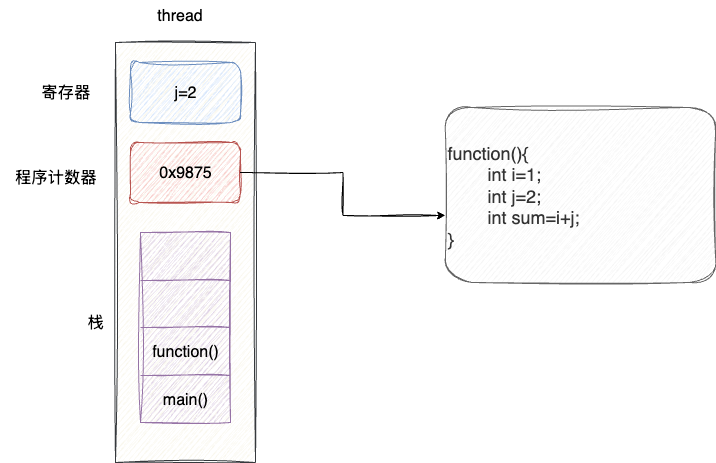
以同一个进程为例,针对单一进程的职责,开发者可以拆解并创建出多个线程,共享进程之间的地址空间和内存数据、文件句柄和字符串环境信息,并在多核CPU下并行的执行,对应的每个线程都具备如下组件:
- 程序计数器:记录接下来要执行的指令
- 寄存器:保存程序当前的工作变量
- 堆栈:记录每个线程的执行历史,例如本示例中的线程通过main调用function1,通过栈帧就可以记录调用历史完成过程调用和返回
由于线程也具备进程中的某些特质,所以线程常常也被称之为轻量级进程:
线程的基本使用示例
关于线程的基本使用,我们从更加接近于底层的c语言展开探究,在Linux系统下,通过c语言内置的库函数就可以完成线程基本的创建和使用,如下代码我们以线程1为例:
- 通过
pthread_create指明线程执行的函数thread_function_1、通过参数3传值给thread_function_1告知线程id号,并通过返回值确定线程是否成功创建 - 通过
join使其加入主线程,确保该线程完成执行后才能推出 - 通过
pthread_exit结束线程的调用
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>// 线程函数1
void* thread_function_1(void* arg) {int thread_id = *(int*)arg;for (int i = 0; i < 5; i++) {printf("线程%d正在执行: %d\n", thread_id, i);sleep(1); // 模拟工作}printf("线程%d执行完毕\n", thread_id);