M-LLM Based Video Frame Selection for Efficient Video Understanding论文阅读

2024.11
1.摘要
background
目前的视频多模态大语言模型(M-LLM)在处理长视频时,通常采用均匀采样(Uniform Sampling)的方式来选取视频帧,以减少计算量。然而,这种“一刀切”的方法可能会丢失视频关键片段中的重要视觉信息,导致下游的大模型没有足够的信息来正确回答与视频内容相关的问题。
innovation
为了解决上述问题,论文提出了一个轻量级的、基于M-LLM的视频帧选择器(Frame Selector)。
1.与问题相关的自适应选择: 它能根据用户的具体问题,自适应地选择最相关的视频帧,而不是盲目地均匀采样。
2.伪标签生成策略: 由于缺乏用于训练帧选择器的标注数据,论文独创性地提出了两种监督信号来生成伪标签(Pseudo Labels):
空间信号 (Spatial Signal): 利用一个强大的M-LLM独立评估每一帧与问题的相关性分数。
时间信号 (Temporal Signal): 首先为所有候选帧生成字幕,然后利用一个强大的纯文本LLM,通过理解所有字幕的上下文,来判断哪些帧在时间序列上是重要的。
3.即插即用 (Plug-and-Play): 该选择器经过一次性训练后,可以作为一个独立的模块,无需任何修改或微调,直接搭配各种现有的下游视频M-LLM使用,提升它们的性能和效率。
2. 方法 Method
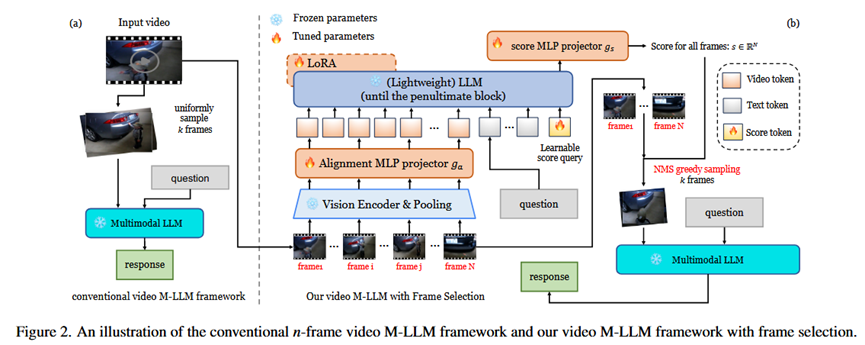
总体流程 (Pipeline):
该方法分为两个主要阶段,如论文图2(b)所示:
1.帧选择阶段: 首先,对输入视频进行密集的均匀采样(例如128帧)。然后,将这些帧和用户问题一起输入到本文提出的轻量级帧选择器中。该选择器会为每一帧输出一个重要性分数。最后,使用带非极大值抑制(NMS)的贪心算法从这些分数中选出最重要且信息不冗余的k帧(例如8帧或16帧)。
2.问答阶段: 将第一阶段选出的k帧输入到一个冻结的、现成的下游视频M-LLM中,由它来生成最终的答案。
各部分细节:
1.帧选择器设计 (Frame Selector Design):
输入: N个视频帧的视觉特征和问题的文本嵌入。
处理:
通过一个视觉编码器和空间池化层,将每个视频帧压缩成少量(例如9个)视觉token,以降低计算复杂度。
在所有视觉token和文本token序列的末尾,拼接一个可学习的“分数查询”向量(score query)。
将整个序列输入到一个轻量级的LLM(例如Qwen2.5 1.5B)中。
取出LLM倒数第二层中与“分数查询”向量对应的输出隐藏状态。
将这个隐藏状态通过一个MLP(多层感知机),最终生成一个N维的向量,其中每个维度代表对应输入帧的重要性分数。
输出: N个输入帧的重要性分数向量s。
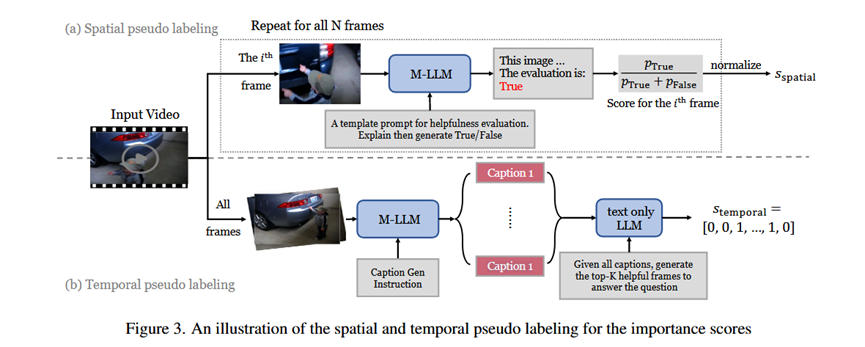
2.伪标签生成 (Pseudo Labels Generation):
输入: N个视频帧和用户问题。
处理:
空间伪标签: 对N帧中的每一帧,单独将其与问题输入到一个强大的M-LLM(Qwen2-VL)中,并提问“这张图片对于回答问题是否有用?”。模型生成“True”的概率被用作该帧的空间重要性分数。
时间伪标签: 首先用M-LLM为所有N帧生成文字描述(caption)。然后,将这N个描述和原始问题一起输入到一个强大的纯文本LLM(GPT-4o mini)中,要求它输出最有帮助的帧的索引列表。在列表中的帧,其时间重要性分数为1,否则为0。
最终标签: 将空间和时间分数进行平均,得到最终用于训练的伪标签。
输出: N个帧的最终重要性分数(伪标签)。
3.训练过程 (Training Process):
采用两阶段训练。
阶段一: 冻结视觉编码器和LLM主干,只训练对齐投影层、分数查询向量和分数MLP。使用两个损失函数交替训练:一个是下游M-LLM的视觉指令遵循损失(即问答的交叉熵损失),另一个是重要性分数预测损失(预测分数与伪标签的二元交叉熵损失)。
阶段二: 在阶段一的基础上,额外使用LoRA技术微调选择器中LLM的权重,此时只使用重要性分数预测损失进行训练。
3. 实验 Experimental Results
实验数据集:
中等长度视频QA: ActivityNet-QA, NEXT-QA
长视频QA: EgoSchema, LongVideoBench, VideoMME
实验结论:
- 与SOTA模型对比 (Tables 1-4): 该帧选择器能稳定提升多个主流视频M-LLM(如PLLaVA, LLaVA-NeXT-Video, Idefics2, Qwen2-VL)在所有测试数据集上的性能。这证明了其方法的有效性和通用性(即插即用)。
2.消融实验 (Table 5): 证明了论文提出的各个组件的有效性。与均匀采样、CLIP相似度等基线方法相比,使用训练好的选择器效果最好。同时证明了结合“空间”和“时间”两种伪标签比只用任何一种都好。
3.效率分析 (Table 6): 实验表明,使用选择器挑选少量帧(如4帧)的性能,可以超过使用均匀采样挑选更多帧(如8帧)的性能,同时推理速度更快,验证了其高效性。
4.长视频性能 (Table 9): 在长视频基准测试LongVideoBench上,使用选择器选择n帧的性能超过了均匀采样2n帧的性能,突显了其在长视频场景下的优势。
4. 总结 Conclusion
本文提出了一个高效且轻量化的M-LLM帧选择器,它能根据问题智能地挑选出视频中的关键帧。通过创新的伪标签生成策略解决了训练数据缺失的难题,并能以即插即用的方式,显著提升现有视频大模型的问答性能和推理效率,尤其是在处理长视频时。