ViT实战一:Patch_embedding
前言
本文是针对ViT这篇博文CV攻城狮入门VIT(vision transformer)之旅——VIT原理详解篇-CSDN博客中patch_embedding的笔记
我采用了比较简单的patch_embedding实现-------------利用卷积
原理第一种理解
既然要使用卷积,那么首先就是要解决的几个问题
- 卷积核的个数?也就是通道数
- 卷积核的大小,步长,是否需要填充
- 输出图片的大小,也就是子图的大小,
首先针对问题三,我们子图的大小是人为设定的,因此没有异议
对于卷积核的个数确定
例如我们有一张224*224的RGB三通道图像,要分成的子图大小为16*16三通道图,我们可以分出
这么多的子图数量,那么我们最终能得到的像素点数量是
我们也可以这么写
这样表示的是什么意义呢?因为我们子图的大小为16,如果但从通道数来看,通道的大小也算16,但是通道的个数是3*14*14,为什么要研究通道数呢?因为我们卷积的通道数等于输出图片的通道数总和,至此我们解决了第一个问题,卷积核的个数
卷积核的大小,步长,是否需要填充
目前我们已经知道了:
输入图片的大小:224*224,3通道图像
输出图片的大小:16*16,3通道图像
输出图片的通道总数:14*14=196
我们可以询问AI,在这种情况下,我们要如何设计卷积核的大小,步长,是否需要填充

我们可以就源码进行实验设计
首先本次实验是在notebook上运行,调试,有关Notebook的调试过程可以参考以下教程
(29 封私信 / 83 条消息) VSCode Jupyter断点调试新方法 - 知乎
import torch
import torch.nn as nn
from torch.utils import data
import torchvision
import torchvision.transforms as T
import torch.nn.functional as F
from PIL import Image
import numpy as np
import os#导入数据
# 定义预处理函数
transform = T.Compose([T.Resize((224, 224)),T.ToTensor(),T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
img_dir=r"E:\DeepLearningProject\ViT_Transformer\convimg.png"
img = Image.open(img_dir).convert('RGB')
img = transform(img)
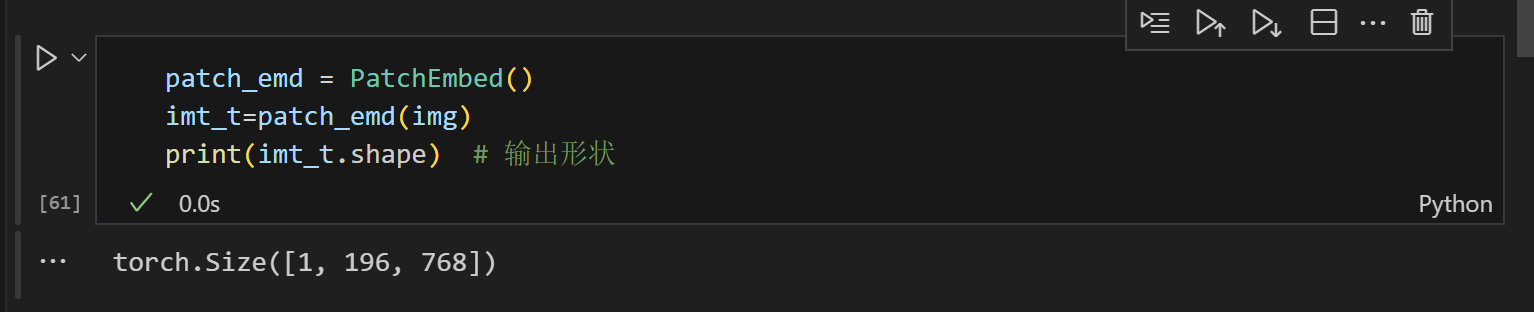
img = img.unsqueeze(0) # 添加批次维度class PatchEmbed2(nn.Module):"""2D Image to Patch Embeddingpatch_size: 子图大小in_c: 输入图像通道数embed_dim: 输出嵌入维度norm_layer: 归一化层"""def __init__(self, img_size=224, patch_size=16, in_c=3, norm_layer=None):super().__init__()img_size = (img_size, img_size)# img_size=(224,224)patch_size = (patch_size, patch_size)# patch_size=(16,16)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) #输出(14,14)self.embed_dim=in_c* self.grid_size[0]**2 # 3*14*14=588print(self.grid_size)self.num_patches = self.grid_size[0]**2*in_cself.proj = nn.Conv2d(in_c, self.embed_dim, kernel_size=self.grid_size[0], stride=self.grid_size[0])#对源代码的改动2,将stride改为self.patch_size[0]self.norm = norm_layer(self.embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x修改完源代码后,我们进行测试
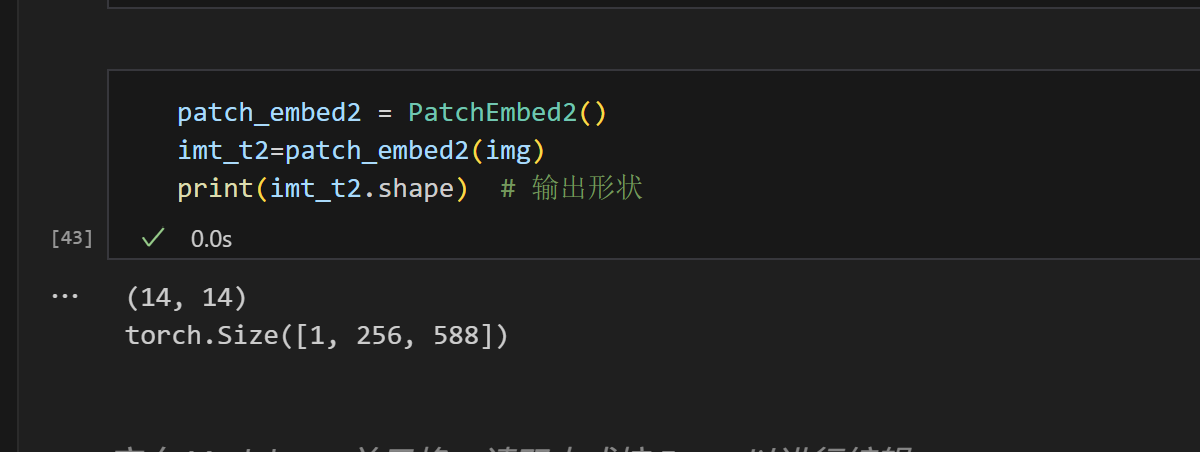
为什么会是1,256,588呢,是因为我们后面对子图进行了展平的操作,16*16展平为256
原理第二种理解
卷积核个数的确定
由第一种理解,我们有这一个公式
我们进行第二种变化
这样怎么解释呢?16*16*3是输出子图的通道数总和,而14*14是输出子图的大小,那么卷积核的个数等于输出子图的通道数,也就是16*16*3=768个卷积核
卷积核大小,步长,是否需要填充
通过第二种理解,我们已有
输入图片是:224*224,3通道
输出图片是:14*14,3通道
输出图片的总数:16*16=256
同样,询问AI,这种情况下,我们该如何设计卷积核

这也就是源代码的方案,如下
import torch
import torch.nn as nn
from torch.utils import data
import torchvision
import torchvision.transforms as T
import torch.nn.functional as F
from PIL import Image
import numpy as np
import os#处理数据
#导入数据
# 定义预处理函数
transform = T.Compose([T.Resize((224, 224)),T.ToTensor(),T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
img_dir=r"E:\DeepLearningProject\ViT_Transformer\convimg.png"
img = Image.open(img_dir).convert('RGB')
img = transform(img)
img = img.unsqueeze(0) # 添加批次维度class PatchEmbed(nn.Module):"""2D Image to Patch Embeddingpatch_size: 子图大小in_c: 输入图像通道数embed_dim: 输出嵌入维度norm_layer: 归一化层"""def __init__(self, img_size=224, patch_size=16, in_c=3, norm_layer=None):super().__init__()#以下有关img_size和patch_size的处理是为了适应输入为整数或元组的情况#具体读者可以自行调试进行理解img_size = (img_size, img_size)patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.embed_dim = in_c * self.patch_size[0]**2 # 针对源代码的改动1#print(self.grid_size)self.num_patches = self.grid_size[0] * self.grid_size[1]self.proj = nn.Conv2d(in_c, self.embed_dim, kernel_size=patch_size, stride=self.patch_size[0])self.norm = norm_layer(self.embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x测试结果