Your ViT is Secretly an Image Segmentation Model
论文基本信息 (Basic Information)
| 标题 (Title) | Your ViT is Secretly an Image Segmentation Model |
|---|---|
| Adress | https://arxiv.org/pdf/2503.19108 |
| Journal/Time | CVPR2025 |
| Author | 荷兰Eindhoven University of Technology\ 意大利Polytechnic of Turin\ 德国RWTH Aachen University |
| Code | https://www.tue-mps.org/eomt/ |
1. 核心思想 (Core Idea)
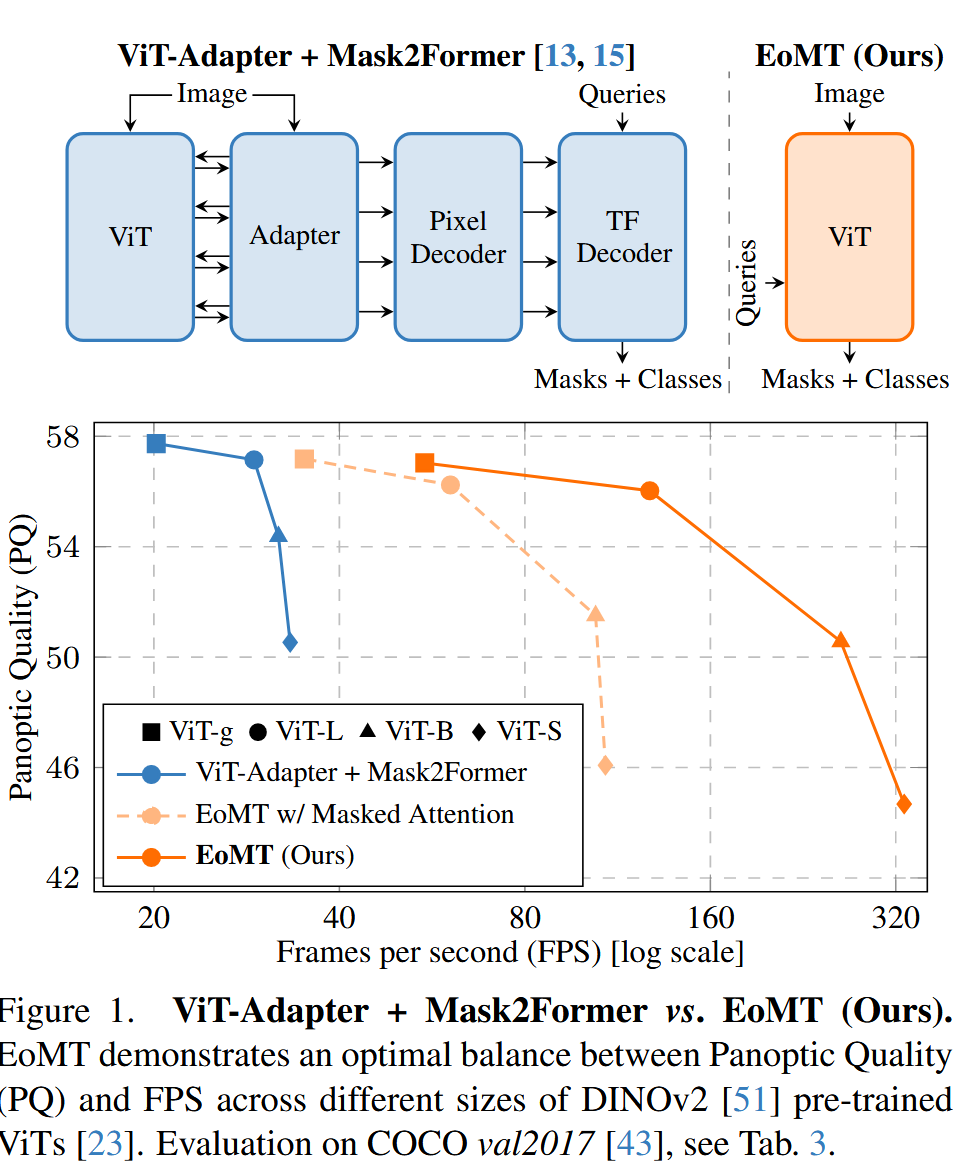
就是将之前的 ViT-Adapter + Mask2Former 变成了 只有 ViT的,在ViT的后面部分进行了一些小改动,达到了 sota。
问题 (Problem):当前将视觉Transformer(ViT)应用于图像分割任务的SOTA方法(如ViT-Adapter + Mask2Former)架构过于复杂。它们普遍依赖于多个为引入卷积归纳偏置而设计的附加组件:1) Adapter,用于生成多尺度特征;2) Pixel Decoder,用于融合多尺度特征;3) Transformer Decoder,用于处理可学习查询(queries)并与图像特征交互。这些组件虽然有效,但导致模型臃肿、计算密集、推理速度慢,且难以实现和优化。
核心假设 (Hypothesis):当ViT骨干网络足够大,并且经过了足够强大的大规模预训练(如DINOv2)后,ViT自身已经具备了学习这些归纳偏置的能力,不再需要这些复杂的外部组件。
解决方法 (Solution):基于该假设,作者提出了一种极简的仅编码器掩码Transformer (Encoder-only Mask Transformer, EoMT)。该方法移除了所有上述的附加组件,通过将可学习的分割查询(queries)直接注入到ViT编码器的中间层,让编码器的后半部分同时承担特征提取和解码的功能。这种设计极大地简化了模型架构,使其回归到一个几乎纯粹的ViT结构,从而在保持高精度的同时,实现了数倍的推理速度提升。
2. 研究背景与动机 (Background and Motivation)
动机 (Motivation): 主要动机是追求模型设计的简洁性(Simplicity)和推理效率(Efficiency)。作者观察到,为了让ViT适用于分割任务,研究社区陷入了一种不断“做加法”的模式,通过堆叠各种模块来弥补ViT所谓的“原生缺陷”(如缺乏多尺度能力)。这导致模型越来越复杂,违背了ViT诞生时简洁统一的初衷,也使其难以完全享受底层计算库(如FlashAttention)对标准Transformer架构的优化红利。
与前人研究的不同 (The Difference):
思路上的根本对立:之前的工作(ViT-Adapter, Mask2Former等)是在“帮助”ViT”,需要外部模块来“赋能”;而本文则认为一个“强大”的ViT“天生就行”,之前的外部模块在高水平的预训练和模型规模面前是“冗余的辅助轮”。这是一种从“做加法”到“做减法”的范式转变。
架构上的极简主义:EoMT几乎完全抛弃了独立解码器的概念,而是通过“复用”编码器的一部分来实现解码功能。这与YOLOS等早期探索encoder-only的模型相比,在方法上更纯粹,并且首次系统性地证明了这种极简设计在强大的基础模型加持下,性能上可以与复杂SOTA模型相媲美。
问题的提出方式 (How the question is proposed):论文的切入点非常精彩。它首先清晰地描绘了当前SOTA分割模型的复杂管线(ViT + Adapter + Pixel Decoder + Transformer Decoder),然后直接提出两个核心假设作为待验证的命题:
- 大规模预训练(特别是MIM)已经教会了ViT提取分割所需的细粒度信息,因此额外的辅助组件可能不再必要。
- 更大的模型容量允许ViT在没有这些附加组件的情况下直接胜任分割任务。
3. 方法论 (Methodology)
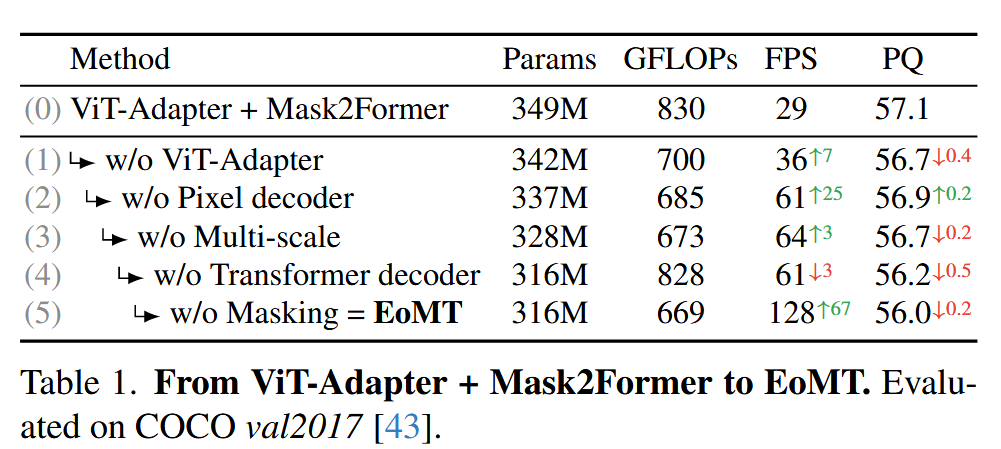
EoMT的构建过程可以看作是一场“拆解实验”,从一个复杂的SOTA模型逐步简化而来:
逐步拆解 (Step-by-step removal):
- 基线: ViT-Adapter + Mask2Former。
- 步骤1 (w/o ViT-Adapter):移除Adapter,用简单的转置卷积和卷积从ViT的单尺度输出(e.g.,
1/16)生成一个简化的特征金字塔。 - 步骤2 (w/o Pixel Decoder):进一步移除Pixel Decoder,将上述简化的特征金字塔直接送入Transformer
Decoder。 - 步骤3 (w/o Multi-scale):移除多尺度特征处理,Transformer Decoder只与ViT的原始单尺度输出F_vit进行交互。
- 步骤4 (w/o Transformer Decoder) -> EoMT诞生: 彻底移除独立的Transformer Decoder。
EoMT 架构:
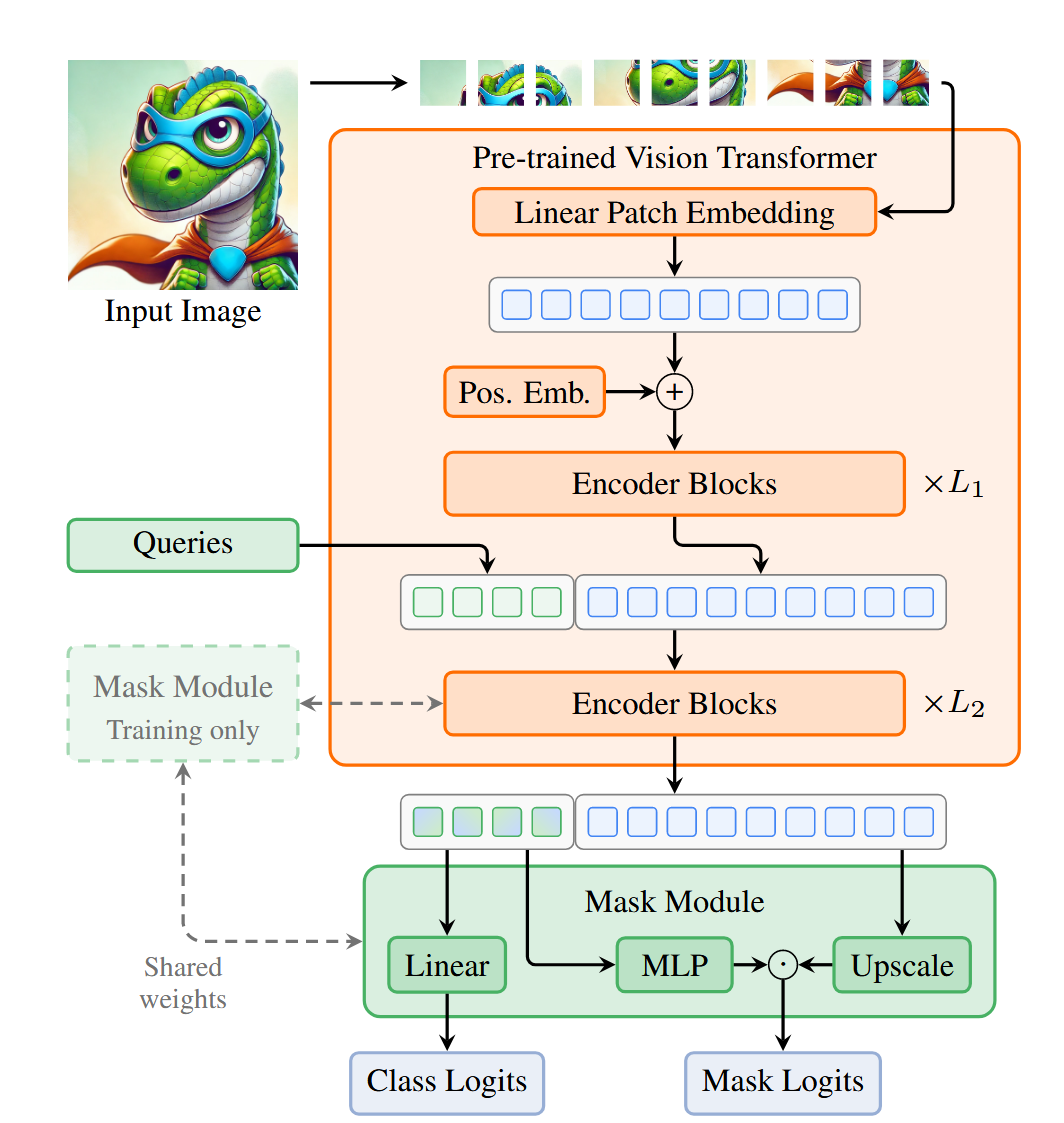
Query注入: 将K个可学习的分割查询(queries)在ViT的第L1 个block之后,与patch tokens进行拼接(Concatenate)。
联合处理: 拼接后的序列(包含patch tokens和query tokens)共同送入剩余的L2个ViT block中。在这些block里,标准的自注意力机制会自然地处理四种交互:patch-patch, patch-query, query-patch, query-query。这巧妙地复用编码器层来实现了传统解码器的功能。
预测头: 经过所有L个block后,取出最终的query tokens,通过一个轻量的MLP预测类别(Class Logits)和掩码(Mask Logits)。

Mask Annealing (掩码退火):
动机:Mask2Former中的masked attention机制在训练时能提升精度,但在推理时需要计算中间掩码,非常耗时。
策略:在训练初期,masked attention以100%的概率被使用,以帮助模型稳定收敛。随着训练的进行,这个概率会分层、逐步地衰减(anneal)到0。例如,先让第21个block的mask概率衰减,再到第22个,以此类推。
效果:模型在训练后期逐渐“忘记”对masked attention的依赖,从而在推理时可以完全关闭它,大大提升速度,同时性能损失极小。
4. 实验结果 (Experimental Results)
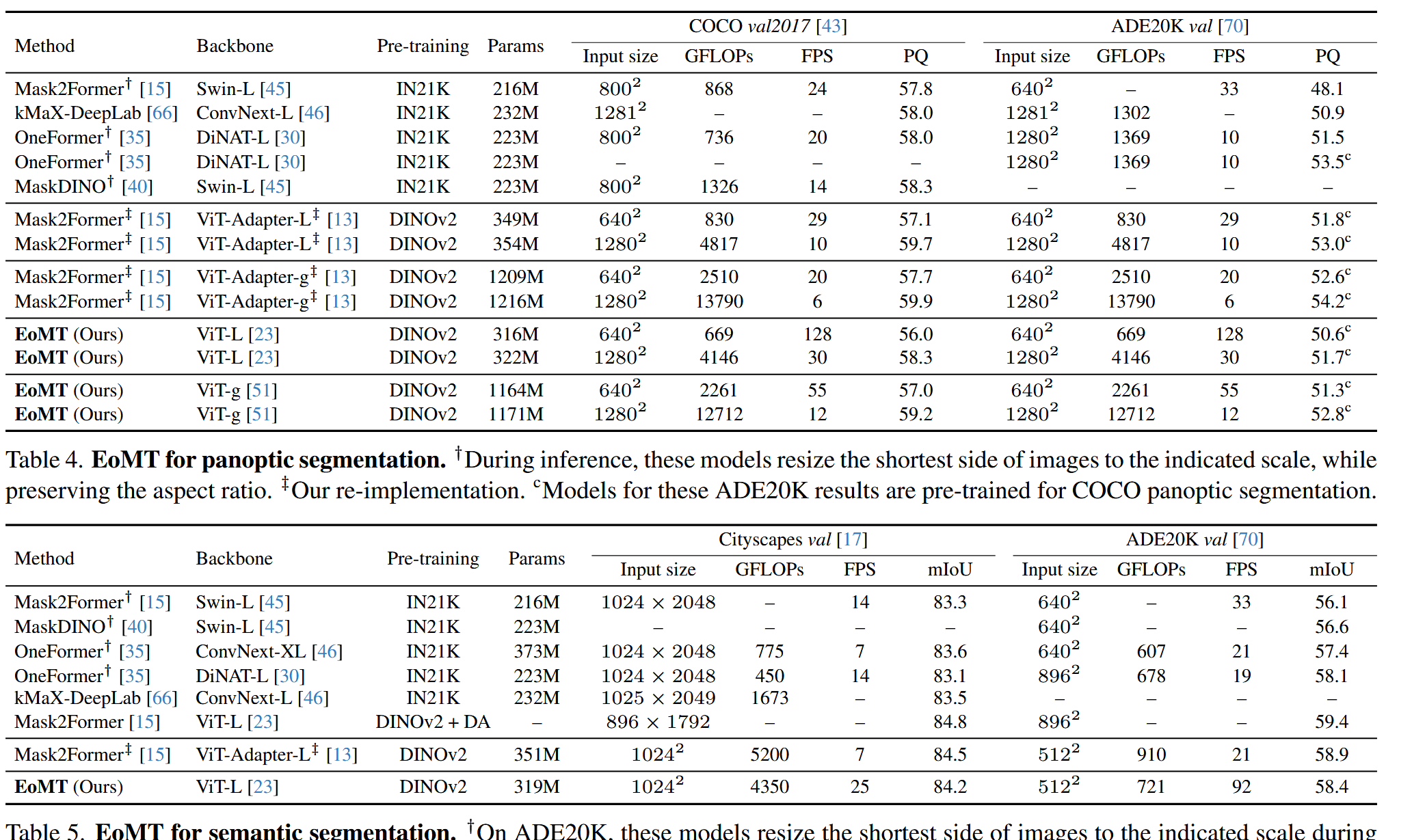
核心消融实验 (Table 1):从ViT-Adapter+M2F逐步简化到EoMT,在COCO数据集上,模型速度提升了4.4倍 (29 -> 128 FPS),而精度(PQ)仅从57.1轻微下降到56.0。这证明了复杂组件的“可替代性”。
预训练的影响 (Table 2):使用弱的ImageNet预训练时,EoMT与复杂模型的性能差距较大(-3.9 PQ);但当换用强大的DINOv2预训练时,差距迅速缩小到-1.1 PQ。这证明了强大的预训练是简化架构的前提。
模型规模的影响 (Table 3 & Figure 1):随着ViT模型从Small增大到Giant,EoMT与复杂模型的性能差距从-5.8 PQ缩小到-0.7 PQ。这证明了模型规模是弥补归纳偏置缺失的关键。Figure 1的精度-速度曲线清晰地表明,EoMT在所有模型尺寸上都提供了更优的帕累托前沿。
各大基准测试 (Tables 4, 5, 6):在COCO, ADE20K, Cityscapes等主流数据集上,无论是全景、语义还是实例分割,EoMT都取得了与SOTA方法(如Mask2Former, OneFormer)相当甚至更好的“精度-速度”权衡。
附加优势:
- OOD泛化 (Table 8):得益于DINOv2预训练和纯ViT架构,EoMT在分布外(OOD)数据集上的泛化能力远强于使用Swin或ConvNeXt等架构的SOTA模型。
- 兼容性 (Table 9):EoMT的简洁架构使其能无缝接入ViT的生态优化,如Token Merging,进一步提升吞吐量;而带有复杂Adapter的模型则因为需要解耦和交互,无法获得同样的速度增益。
5. 结论与讨论 (Conclusion & Discussion)
核心结论:对于图像分割任务,架构的复杂性可以被模型规模和预训练的质量所替代。一个经过大规模自监督预训练的大尺寸ViT,其本身就蕴含了强大的分割能力,无需再为其设计繁琐的外部“辅助结构”。
讨论与展望:这项工作倡导了一种**“少即是多”**的设计哲学。未来的研究重心或许应该从设计越来越精巧的任务头,转向如何更有效地扩大模型规模、提升预训练的质量和效率。EoMT作为一个简单、可扩展的基线,为下一代分割模型的发展奠定了坚实的基础,使其能更好地拥抱Transformer和基础模型领域的飞速发展。
6. 主要贡献总结 (Summary of Key Contributions)
提出并验证了一个核心假设:系统性地证明了,随着模型规模和预训练水平的提升,用于图像分割的ViT模型中复杂的任务专用组件(Adapter, Decoders)变得越来越不重要。
提出了EoMT架构:设计了一种极简、高效的Encoder-only分割模型,它通过在编码器内部处理分割查询,复用了ViT的标准模块,显著提升了推理速度,同时保持了SOTA级的精度。
提出了Mask Annealing策略:发明了一种新颖的训练技巧,能够在不牺牲性能的前提下,移除推理时对计算昂贵的masked attention的依赖,进一步提升了模型的效率。
树立了新的效率标杆:在多个分割基准上,EoMT在“精度 vs. 速度”的权衡上达到了新的SOTA水平,证明了将计算资源投入到扩展ViT本身是比增加架构复杂性更优的选择。