RAG:解锁大语言模型新能力的关键钥匙
什么是 RAG?
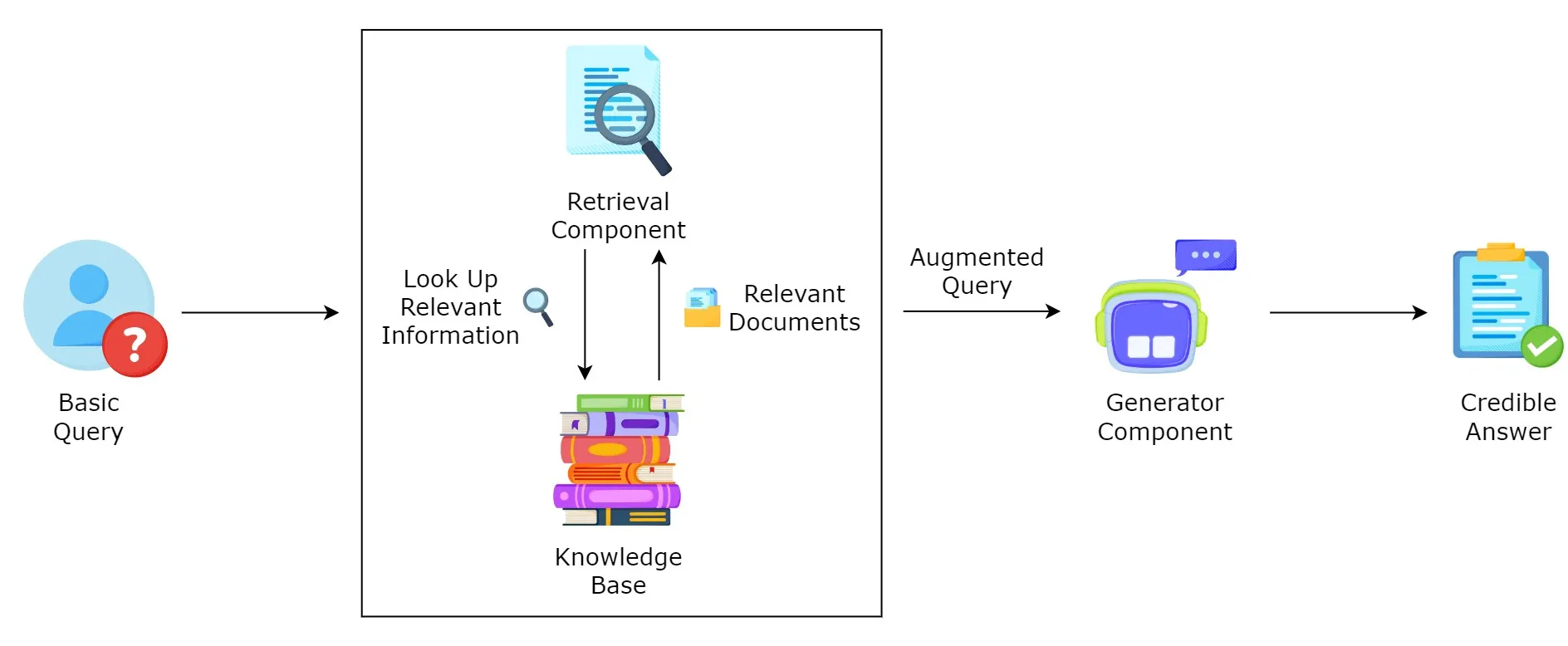
RAG全称 Retrieval-Augmented Generation, 是一种将检索模型与生成模型相结合的混合技术,它将检索组件集成到生成模型中
主要的核心思想是:在模型生成答案之前,先从知识库或向量数据库中检索出相关信息,并将这些信息作为上下文传递给大语言模型(LLM),从而生成更加准确和有依据的回答。
RAG的常见使用场景
内容创作(Content Creation)
RAG 可以帮助内容创作者快速获取相关资料,并生成连贯的文章、博客、产品描述等,大幅提升写作效率和质量。
教育与学习(Educational Assistance)
在学术研究、课程开发或论文写作中,RAG 模型能够为学生和教师检索相关知识,并生成解释性或扩展性的内容,辅助学习与研究。
知识检索与发现(Knowledge Discovery)
在科研、医疗、金融等数据密集型领域,研究人员可以利用 RAG 在海量文献与数据中快速定位关键信息,提炼洞见,加速知识发现与创新。
客服问答系统(Question Answering)
借助 RAG,客服机器人可以基于知识库和历史交互记录检索信息,向用户提供更加准确、详细和个性化的回答,从而提升服务体验与效率。
RAG的工作原理
RAG(Retrieval-Augmented Generation)的核心思想是:先找到相关信息,再结合大模型生成答案。
它的工作流程可以拆解为两个关键环节:
- 索引(Indexing):对原始文档进行切分、嵌入向量化,并存入向量数据库,形成一份“语义目录”。
- 检索与生成(Retrieval & Generation):当用户提问时,系统会将问题转化为向量,在数据库中检索最相关的片段,然后与问题一起交给大模型生成答案。
索引
索引是为了加速向量检索过程而创建的数据结构。
如果没有索引,搜索庞大的数据集就像在一个庞大的图书馆中翻阅每本书的每一页,以找到一条单一的信息——这是一项非常耗时且低效的任务。通过以结构化的方式组织数据,索引使系统能够快速定位相关信息,方法是参考索引,而不是扫描每一份文档。
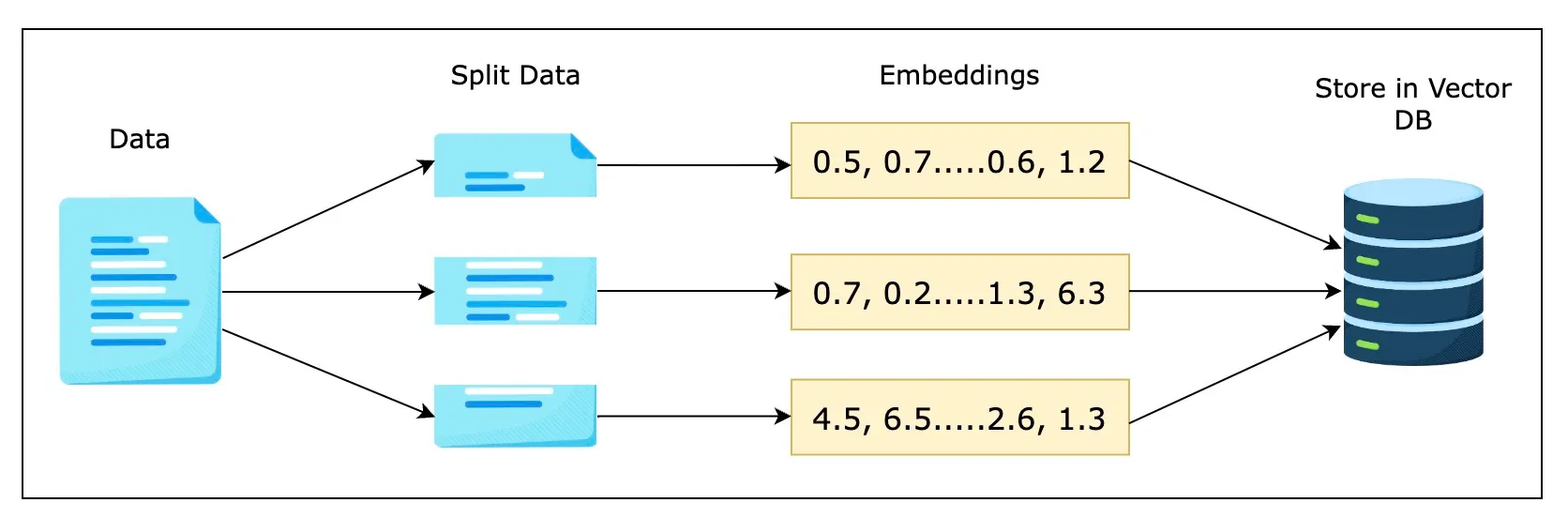
RAG索引建立的过程
- 收集数据 : 从多种数据来源收集数据
- 数据分割和解析:将数据分割成Chunk,这是由于LLM通常有一个上下文的上限。同时,解析数据以提取有用的元数据(如文档标题、作者、发布日期等),这些元数据有助于提高检索效果和上下文理解。
- 嵌入: 将数据块Chunk使用一些嵌入模型转换为高纬度的词向量表示,用于表示语义关系和文本相似性以便大模型可以理解
- 向量数据库:将生成的嵌入向量和相关的元数据存储在向量数据库中(如ChromaDB、Pinecone、Milvus等)。这些数据库针对大规模高维数据进行了优化,支持高效的查询和检索。
嵌入
嵌入(Embedding)就像人类依靠视觉、听觉、触觉去感知世界一样,是大模型理解外部信息(如文本、图像、音视频等)的关键方式。
嵌入可以被理解为一种特殊的“翻译技术”:将我们日常使用的词语、句子、段落,甚至图像和视频等内容,翻译成计算机能够理解的数字表示——向量。这些向量不仅是数字序列,更能承载语义信息,使得大模型能够识别和理解文本或多模态数据的含义与上下文。
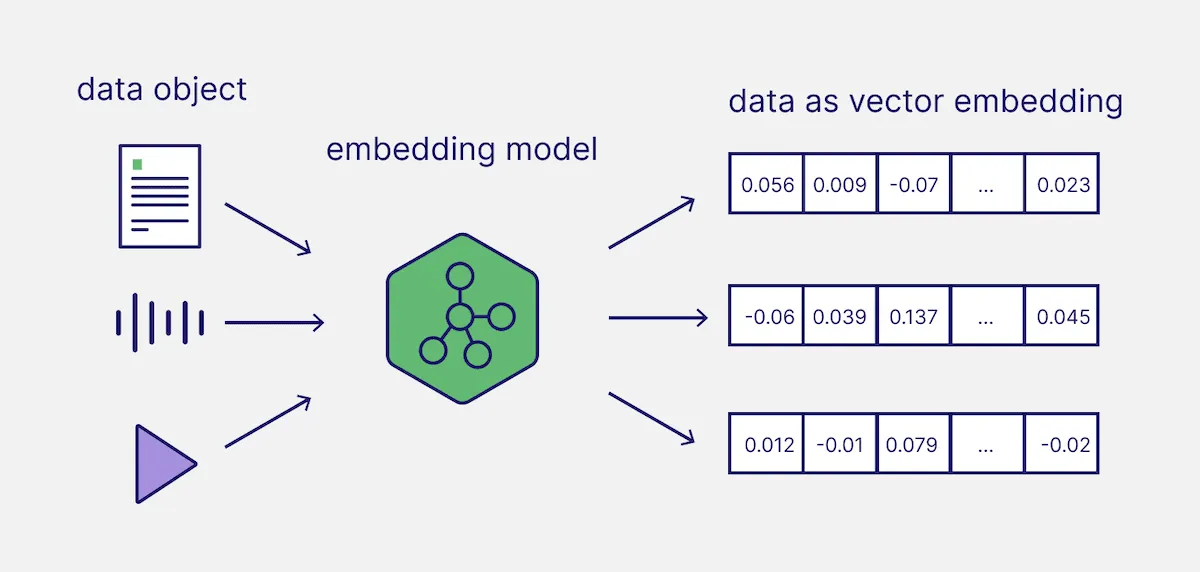
什么是向量
举个例子:当用户提出一个问题,例如 “什么是机器学习?”,首先会把这句话转化为一个 查询向量:如:[0.15, 0.2, 0.45, ...]。
这个过程称为 向量化(Vectorization)。向量化(Vectorization)是通过嵌入模型将文本或图像等内容转化为固定长度的向量表示。这些向量虽然比原始数据更简洁,但仍然处于一个多维语义空间中,使得语义相近的内容在空间中彼此更接近。
嵌入的类型
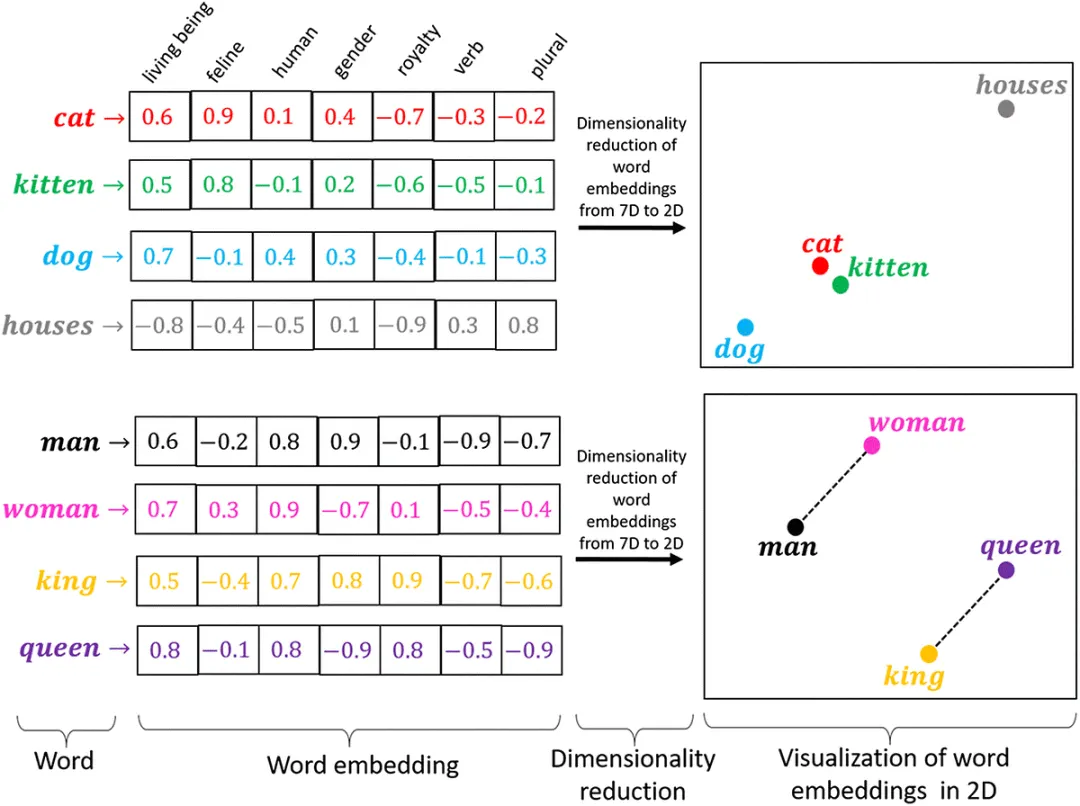
词嵌入(Word Embeddings)
词嵌入将单个单词表示为向量。经典模型包括 Word2Vec、GloVe、FastText。
词嵌入是自然语言处理的基础,使模型能够理解单词之间的语义关系。
示例:在 Word2Vec 中,单词 “king” 可能被表示为 [0.5, 0.8, -0.1, 0.3, 0.9]。而单词 “queen” 的向量与之相似,表明两者语义接近;而 “apple” 的向量则与它们距离更远,反映了语义上的差异。
句子嵌入(Sentence Embeddings)
句子嵌入用于捕捉整个句子或段落的语义。常见模型有 Universal Sentence Encoder 和 Sentence-BERT (SBERT)。它们通常通过对词向量进行平均或池化,得到一个能表示整体语义的向量。
示例:句子 “The cat sat on the mat” 会被映射到一个向量,这个向量并不是单纯拼接各个词,而是整体表达“猫坐在垫子上”这一语义。
图像嵌入(Image Embeddings)
在计算机视觉中,图像嵌入用于将图像表示为向量。卷积神经网络(CNN) 常作为生成图像嵌入的核心结构,这些向量可以用于图像检索、分类等任务。
示例:一张猫的图片会被映射到一个向量,该向量会靠近其他猫的图片向量,从而帮助模型识别相似的物体。
图嵌入(Graph Embeddings)
图嵌入将图中的节点或子图 映射为向量,同时保留它们之间的结构关系。常见方法包括 DeepWalk、GraphSAGE。
示例:在一个社交网络图中,用户可以被表示为向量,两个用户的向量越接近,就表示他们之间的关系越紧密。
检索和生成
最后当用户提出问题时,系统会先将问题向量化,并在向量数据库中进行相似度匹配,检索出与之最相关的内容片段。
随后,系统会将 用户的原始问题 + 检索到的内容 一并传递给大语言模型。大模型在获取到这些上下文后,能够结合用户需求和检索信息,生成更加准确、具有依据的回答。
举个例子
当用户提问:“RAG的应用场景有哪些?”
- 检索阶段:系统在知识库中找到相关片段,例如“RAG 常用于客服、问答系统、教育辅助和知识发现”。
- 生成阶段:大模型会结合用户问题和检索到的内容,生成一个更完整的答案:
“RAG 的典型应用包括客户支持聊天机器人、开放领域问答、教育研究助手以及知识发现等场景。”
通过这种方式,模型的回答不仅流畅自然,而且具备可追溯的知识来源,降低了“幻觉”风险。