[论文阅读] AI+软件工程 | AI供应链信任革命:TAIBOM如何破解AI系统“可信难题“
AI供应链信任革命:TAIBOM如何破解AI系统"可信难题"?
论文信息
- 论文原标题:Trusted AI Bill of Materials (TAIBOM): Towards Trustworthy AI-Enabled Systems
- 主要作者及研究机构:Vadim Safronov(牛津大学)、Peter Edwards(NquiringMinds)、Sandra Scott-Hayward(牛津大学)等
- APA引文格式:Safronov, V., Edwards, P., Scott-Hayward, S., et al. (2025). Trusted AI Bill of Materials (TAIBOM): Towards Trustworthy AI-Enabled Systems. arXiv preprint arXiv:2510.02169.
- 开源工具包:https://github.com/nqminds/Trusted-AI-BOM/
- 发表情况:This paper has been accepted at the First International Workshop on Security and Privacy-Preserving AI/ML (SPAIML 2025), co-located with the 28th European Conference on Artificial Intelligence (ECAI 2025)
一段话总结
随着开源与AI技术深度融合,软件供应链复杂度飙升,传统SBOM因无法适配AI系统的动态性、松散耦合依赖(如训练数据、模型权重)及分布式治理挑战而失效。为此,论文提出Trusted AI Bill of Materials (TAIBOM) 框架——通过结构化AI依赖模型(定义Data/Code/AI System类及关联)、跨异构管道的完整性声明传播、组件溯源信任证明,解决AI系统信任缺失问题。经4个核心用例验证,TAIBOM在加密签名验证、动态谱系跟踪、全流水线信任保障上显著优于模型卡片、SPDX等现有方案,为AI可信性与合规性奠定基础。
思维导图
研究背景:AI供应链的"信任迷雾"
想象一下:你组装一台电脑,用传统SBOM(软件物料清单)能清晰列出CPU、内存等零件的来源和型号;但如果组装的是一个AI模型——它的"零件"包括PB级训练数据、上千行训练代码、迭代10次的模型权重,甚至还有第三方优化数据集,传统SBOM就像拿着"静态零件清单"去跟踪"动态拼图",完全力不从心。
这就是AI时代软件供应链的真实困境:
- 动态性难题:AI模型不是"一劳永逸"的产品,比如推荐算法会因用户行为变化持续重训练,版本迭代速度远超传统软件;
- 依赖跟踪难题:训练数据、模型权重、推理代码等组件松散耦合,就像"散落的积木",没人能说清某版模型到底用了哪份数据、哪行代码训练;
- 信任验证难题:2024年某电商AI推荐系统因训练数据被恶意投毒,导致向用户推送虚假商品——事后追溯发现,连数据集来源都无法证明,更别提验证完整性。
传统SBOM只能解决"静态软件组件"的溯源,而AI系统需要的是"动态全链路"的信任保障。现有方案如Hugging Face模型卡片,只敢写"数据集来自公开渠道"却拿不出签名证明;SPDX虽能关联代码漏洞,却管不了训练数据是否被篡改。AI供应链正陷入"说不清、查不明、信不过"的信任迷雾。
创新点:TAIBOM的三大"信任密码"
TAIBOM不是简单给SBOM加个"AI标签",而是重构了AI系统的信任框架,核心创新点有三:
1. 结构化AI依赖模型:给AI组件"上户口"
传统方案把AI组件混为一谈,TAIBOM则像"户籍系统"一样给每个组件分类建档:
- Data类:专门管理训练数据,细分为单数据集(TrainingData)和数据集集合(DataPack),每个都带签名哈希、版本号、许可信息;
- Code类:区分训练代码(TrainingCode)和推理代码(InferencingCode),直接关联传统SBOM,同步CVE漏洞信息;
- AI System类:串联前两类组件——TrainedSystem记录"数据+代码→权重"的训练过程,InferenceSystem记录"权重+代码→推理结果"的部署过程。
这套模型第一次把"看不见摸不着"的AI组件,变成了"可定义、可关联、可追溯"的结构化对象。
2. 跨环境完整性声明:让信任"不中断"
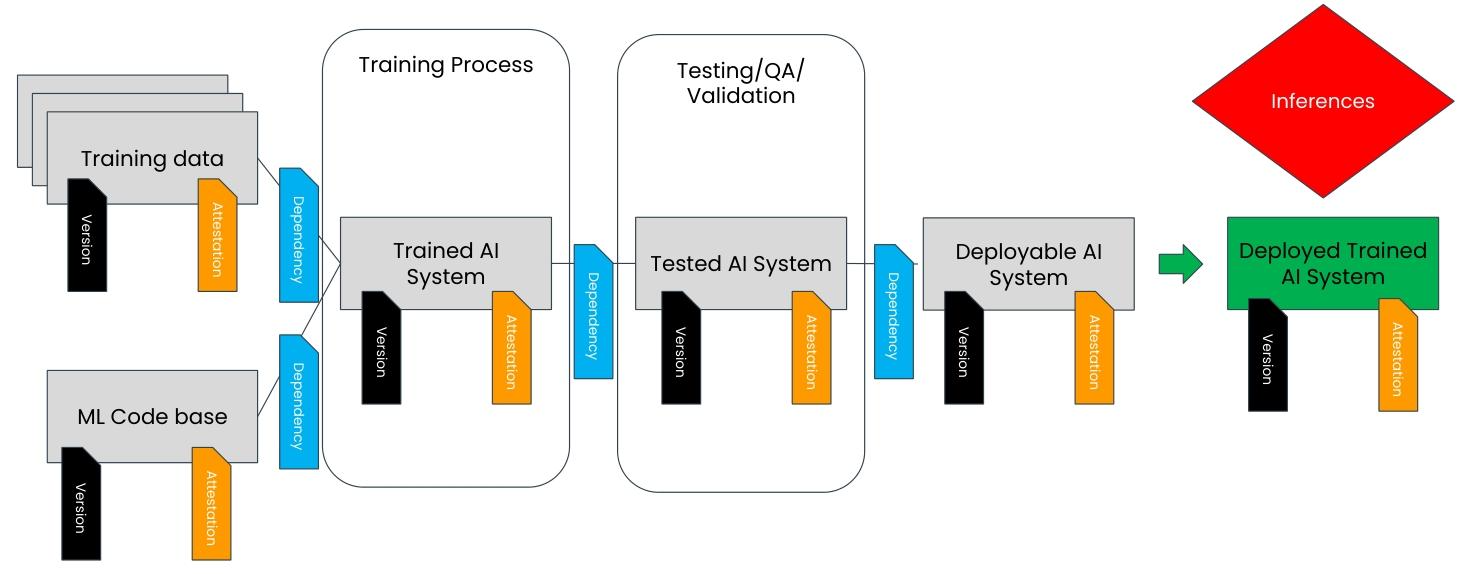
AI系统要经过"训练→测试→部署→推理"多环境流转,TAIBOM设计了"信任接力"机制:每个环节的组件都需加密签名,签名信息随组件同步流转。比如训练数据从本地传到云端时,哈希值会自动校验;模型权重部署到边缘设备时,会验证是否和训练阶段的签名一致。哪怕跨公司、跨平台,信任链也不会断裂。
3. 组件溯源信任证明:给质疑"留证据"
面对"你怎么证明这数据没被改?“的质疑,TAIBOM不是靠"口头保证”,而是靠"证据链":
- 每个组件的哈希值像"指纹"一样唯一;
- 组件间的关联像"族谱"一样清晰(如某权重→某训练数据→某代码版本);
- 任何修改都会导致哈希值变化,触发告警。
这种"可验证、可追溯"的证明机制,让AI信任从"主观宣称"变成"客观事实"。
研究方法和思路:TAIBOM的"信任落地四步走"
TAIBOM的实现不是空中楼阁,而是按"模型设计→机制落地→工作流嵌入→用例验证"四步推进:
步骤1:设计数据模型(见创新点1)
先明确AI组件的分类、属性和关联关系,画出详细的数据模型图(论文图1),确保覆盖从数据到推理的全链路组件。
步骤2:搭建信任机制
- 加密签名:用非对称加密给每个核心组件签名,防止伪造;
- 版本控制:给组件加语义化版本号(如v1.0.0),支持回滚追溯;
- 信任链绑定:通过"父组件→子组件"的签名关联,建立从原始数据到推理结果的完整信任链。
步骤3:嵌入全流程工作流
把TAIBOM融入AI开发全生命周期:
- 训练阶段:绑定版本化的训练数据和代码,生成签名的TrainedSystem;
- 测试阶段:验证TrainedSystem的性能和安全性,不符合要求则打回;
- 部署阶段:用测试通过的组件组装InferenceSystem,再次签名;
- 推理阶段:实时验证InferenceSystem组件的签名完整性。
步骤4:用例对比验证
选择4个AI信任核心场景,对比TAIBOM与模型卡片、SPDX/CycloneDX的效果(论文表1),验证方案的有效性。
主要成果和贡献:AI信任从"不可能"到"可实现"
TAIBOM的核心成果不是理论,而是"能落地、有价值"的信任解决方案,具体贡献体现在:
1. 4大核心场景碾压现有方案
| 场景 | TAIBOM能做什么? | 现有方案短板 |
|---|---|---|
| 训练数据透明声明 | 提供签名+版本+哈希,可验证数据集来源 | 仅文字描述,无验证依据 |
| 数据投毒检测 | 哈希对比发现异常,追溯投毒数据来源 | 无完整性检查,出问题查不清 |
| 系统篡改检测 | 运行时验证组件签名,防未授权修改 | 仅静态检查,部署后无法监控 |
| CVE影响跟踪 | 跨数据/代码/模型跟踪漏洞影响范围 | 仅管代码漏洞,无AI上下文关联 |
比如在数据投毒场景中,TAIBOM能通过"权重→训练数据"的谱系,快速定位被投毒的数据集子集,而现有方案只能全盘弃用所有数据,损失巨大。
2. 开源工具包降低落地门槛
论文配套发布了TAIBOM工具包(GitHub链接),包含数据模型定义、签名验证、谱系跟踪等核心功能,开发者可直接集成到现有AI流水线中,无需从零开发。
3. 为AI合规提供技术基础
欧盟AI法案等 regulations 要求AI系统"可追溯、可解释",TAIBOM的结构化模型和信任证明,正好为合规提供了技术支撑,帮助企业避免因"无法证明可信"而面临的处罚。
关键问题
Q1:TAIBOM和传统SBOM的本质区别是什么?
A:传统SBOM是"静态零件清单",只记录软件组件的"是什么";TAIBOM是"动态信任框架",不仅记录AI组件的"是什么",还跟踪"怎么来、去哪了、是否被改"。比如SBOM能说清用了哪个Python库,但TAIBOM能说清这个库训练出的模型用了哪份数据、是否有投毒风险。
Q2:TAIBOM如何解决大规模训练数据的签名效率问题?
A:目前论文承认这是局限(PB级数据签名耗时),但未来计划通过"采样签名+分层验证"优化——对数据集分片采样签名,同时验证数据集元数据的完整性,在效率和安全性间找平衡。
Q3:如果签名机构不可信,TAIBOM会失效吗?
A:会。TAIBOM假设组件提供者和签名机构是可信的(“可信≠安全”),这是当前的局限。未来计划引入"多机构交叉签名"机制,比如数据集需同时经过数据方和第三方审计机构签名,降低单一机构失信的风险。
Q4:TAIBOM能用于ChatGPT这类大模型吗?
A:能。TAIBOM的设计具有通用性,支持LLM、生成式AI等复杂系统。比如可跟踪大模型的预训练数据、微调数据、不同版本的权重,甚至能验证某段对话生成是否来自特定模型版本。
总结
TAIBOM通过结构化依赖模型、跨环境信任机制、可验证溯源证明,首次将"可信"从抽象概念转化为AI系统的可落地能力。它不仅解决了当前AI供应链"说不清、查不明、信不过"的痛点,更为下一代AI系统的信任、透明与合规奠定了技术基础。
当然,TAIBOM仍有局限:组件描述粒度需进一步优化,信任链召回机制待完善,大规模数据签名效率需提升。但不可否认,它为AI信任难题提供了一条"从被动应对到主动保障"的新思路——当AI系统都带上TAIBOM这张"信任身份证"时,我们或许能真正走进"可信AI"的时代。