SNN论文阅读——In the Blink of an Eye: Event-based Emotion Recognition
In the Blink of an Eye: Event-based Emotion Recognition
Abstract & Introduction
-
这篇论文的核心是抛弃了传统RGB摄像头+标准CNN的路线,转而采用一种仿生学的解决方案:
- 传感器: 事件相机(Event-based Camera),模仿人眼视网膜的工作方式。
- 处理模型: 脉冲神经网络(Spiking Neural Network, SNN),模仿人脑神经元的工作方式。
这套组合旨在解决传统方法在光照变化和高速运动下的脆弱性问题。
然而,事件相机也带来了新问题:
- 挑战: 事件流看起来就像一堆散点,缺乏纹理和细节信息(如图1所示)。而纹理(如眼周细纹)和细节对于情绪识别至关重要。
- 解决方案 - SEEN模型: 作者提出了一个巧妙的双分支轻量级网络来解决这个问题。
SEEN (Spiking Eye Emotion Network) 的设计:
- 空间特征提取器(分支一):
- 输入: 传统的强度帧(Intensity Frames,事件相机可以偶尔输出几张类似传统相机的图片,但质量不高)。
- 作用: 从质量不高的强度帧中,学习提取关键的空间纹理特征(比如眼睛的形状、眉毛的弯曲度等)。
- 时间特征提取器(分支二):
- 输入: 事件流(Event Stream)。
- 核心: 使用脉冲神经网络(SNN) 来处理。SNN擅长处理这种异步的、时间连续的事件流,能很好地解码出动态的时间信息(比如眉毛上扬的速度、眯眼的快慢)。
- 创新的“权重复制”方案(Weight-Copy Scheme):
- 这是本文的一大创新点。两个分支的底层卷积结构是共享的。
- 如何训练? 只在空间分支(处理强度帧的分支)上训练这些共享的卷积层。训练完成后,将这些层的权重直接复制给时间分支的对应部分。
- 为什么这样做? 这相当于让处理事件流的时间分支 “继承” 了从强度帧中学到的空间先验知识。比如,空间分支学会了“外眼角皱纹”是重要特征,那么时间分支在处理事件流时,也会更关注外眼角区域发生的事件(变化)。这是一种隐式的、高效的空间注意力机制。
- 最终决策: 将两个分支提取到的特征(空间+时间)融合起来,进行最终的情绪分类。
Background
事件相机 (Event-based Cameras)
-
工作原理:
- 与传统相机拍摄“帧”不同,事件相机的每个像素都是独立、异步工作的。
- 它只记录亮度变化(事件),输出的是一个由(x,y,t,p)(x, y, t, p)(x,y,t,p)四元组构成的事件流。
- x,yx, yx,y: 像素位置
- ttt: 事件触发的时间戳(精度在微秒级)
- ppp: 极性(+1表示亮度增加,-1表示亮度减少)
-
特性与挑战:
-
优势: 高动态范围(140 dB)、高 temporal resolution、低延迟、低功耗。
-
固有挑战:
- 缺乏纹理: 事件主要由运动边缘触发,因此事件流看起来是稀疏的点,缺乏静态的纹理信息。而纹理对情绪识别很重要。
- 数据格式不兼容: 异步的事件流与CNN等需要规则网格输入(如图像)的神经网络不兼容。
-
解决方案(预处理): 需要将一段时间内的事件聚合(aggregate) 成一个二维的网格表示(类似于一张图像),才能送入神经网络处理。本文采用了Zhang et al. [2021b]的聚合算法。
这种聚合方式是否破坏了DVS带来的和SNN相匹配的输入方式?换言之DVS的结果是否可以不经处理而直接输入SNN而非CNN?
-
SEEN模型核心架构
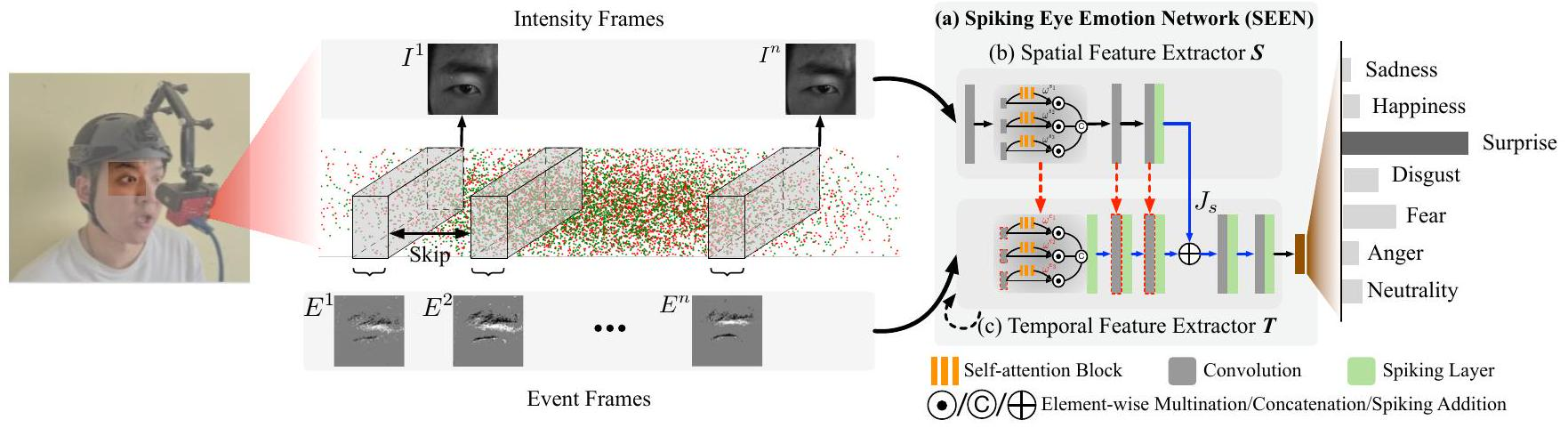
SEEN是一个双分支混合网络,旨在同时利用强度帧(Intensity Frames)的空间纹理信息和事件流(Event Stream)的时间动态信息。其最创新的权重复制(Weight-Copy) 方案解决了事件流缺乏纹理信息的根本问题。
整个系统的流程如图2(a)所示:输入是两个强度帧(I¹, Iⁿ) 和它们之间的 n个聚合事件帧(E¹ to Eⁿ)。系统输出是这n个时间步的情绪预测平均值。
空间特征提取器 SSS
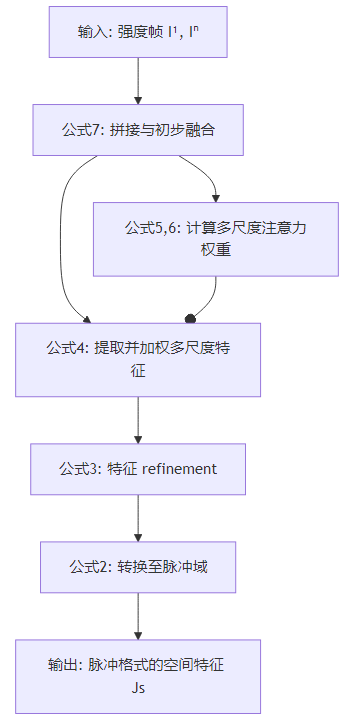
空间特征提取器 SSS 的处理流程是一个前向传播链,其输入是两张强度帧 I1I^1I1 和 InI^nIn,输出是一个脉冲信号 JsJ_sJs。整个过程可以用下图清晰地展示:
流程:
第一步:输入预处理与初步融合 (公式7)
公式: ls=C1([I1,In])l_{s} = C_{1}\left(\left[I^{1}, I^{n}\right]\right)ls=C1([I1,In])
- 操作解读:
- 拼接 (Concatenation): [I1,In]\left[I^{1}, I^{n}\right][I1,In] 将第一帧和最后一帧强度图在通道维度(Channel) 上进行拼接。如果每帧是3通道的RGB图像,拼接后则得到一个6通道的张量。
- 卷积融合: C1(⋅)C_{1}(\cdot)C1(⋅) 使用一个 1x1 的卷积层处理这个6通道的张量。
- 目的:
- 1x1卷积的核心作用是进行跨通道的信息融合和降维。它允许模型学习如何最有效地组合两帧图像的信息。
- 输出 lsl_sls 是一个融合了序列起点和终点信息的“潜表示”(latent representation),作为后续模块的输入。
第二步:多尺度自注意力感知模块(核心)
这个模块是空间提取器的核心,其目的是让网络自主地关注不同尺度的特征,并动态地权衡它们的重要性。它由公式4、5、6共同定义。
1. 计算注意力权重 (公式5 & 6)
公式: ω(x1,…,xn)si=σ(⟨Υ(Cx1(ls)),…Υ(Cxn(ls))⟩)i\omega_{\left(x_{1}, \ldots, x_{n}\right)}^{s_{i}} =\sigma\left(\left\langle\Upsilon\left(C_{x_{1}}\left(l_{s}\right)\right), \ldots \Upsilon\left(C_{x_{n}}\left(l_{s}\right)\right)\right\rangle\right)_{i}ω(x1,…,xn)si=σ(⟨Υ(Cx1(ls)),…Υ(Cxn(ls))⟩)i
- 操作解读:
- 多尺度特征提取: 并行使用多个不同大小的卷积核(如3x3, 5x5, 7x7)对 lsl_sls 进行卷积操作 (Cx1,...,CxnC_{x_1}, ..., C_{x_n}Cx1,...,Cxn),得到多组特征图。每组特征图捕捉了不同感受野下的信息。
- 生成通道描述符 (公式6): Υ(⋅):=C1(BR(C1(A(⋅))))\Upsilon(\cdot) :=C_{1}\left(\mathcal{B} \mathcal{R}\left(C_{1}(\mathcal{A}(\cdot))\right)\right)Υ(⋅):=C1(BR(C1(A(⋅))))
- A(⋅)\mathcal{A}(\cdot)A(⋅): 自适应池化。将每个尺度的特征图全局池化,得到一个固定大小的特征向量(通常是1x1xC),汇聚了全局信息。
- C1(A(⋅))C_{1}(\mathcal{A}(\cdot))C1(A(⋅)): 用一个1x1卷积降维,进一步提炼信息。
- BR\mathcal{BR}BR: BatchNorm + ReLU。加速训练并引入非线性。
- 最外层的 C1C_1C1: 另一个1x1卷积,最终将每个尺度的特征压缩成一个单一的标量数值。这个数值是该尺度特征图的“摘要”。
- 计算权重: 将得到的多个标量(每个尺度一个)组成一个向量,然后通过 Softmax 函数 (σ\sigmaσ)。Softmax 的输出是一个概率分布,其每个值 ωsi\omega^{s_i}ωsi 就代表了对应尺度 iii 的重要性权重。
2. 应用注意力权重并融合 (公式4)
公式: Ω(3,5,7)(⋅):=C1([ωs1C3(⋅),ωs2C5(⋅),ωs3C7(⋅)])\Omega_{(3,5,7)}(\cdot) :=C_{1}\left(\left[\omega^{s_{1}} C_{3}(\cdot), \omega^{s_{2}} C_{5}(\cdot), \omega^{s_{3}} C_{7}(\cdot)\right]\right)Ω(3,5,7)(⋅):=C1([ωs1C3(⋅),ωs2C5(⋅),ωs3C7(⋅)])
- 操作解读:
- 加权: 将第二步第1步中提取的多尺度特征图 Cxi(ls)C_{x_i}(l_s)Cxi(ls) 分别乘以其对应的注意力权重 ωsi\omega^{s_i}ωsi。权重是一个标量,与特征图逐元素相乘,相当于放大了重要特征图的贡献,抑制了不重要特征图的贡献。
- 拼接与融合: 将加权后的多尺度特征图在通道维度进行拼接,然后使用一个 1x1 卷积 (C1C_1C1) 将融合后的多通道信息压缩并融合成一个统一的特征表示。输出是模块 Ω\OmegaΩ 的最终结果。
第三步:特征精炼 (公式3)
公式: Fs=C3(C3(Ω(3,5,7)(ls)))F_{s} = C_{3}\left(C_{3}\left(\Omega_{(3,5,7)}\left(l_{s}\right)\right)\right)Fs=C3(C3(Ω(3,5,7)(ls)))
- 操作解读: 将多尺度模块 Ω\OmegaΩ 的输出,依次通过两个 3x3 卷积层。
- 目的: 3x3卷积是标准的特征提取操作。这里使用两层可以进一步组合和提炼前面得到的多尺度特征,使其更加高级和抽象,最终得到富含空间信息的特征 FsF_sFs。
第四步:转换至脉冲域 (公式2)
公式: Js=Φ1(Fs)J_{s} = \Phi^{1}(F_{s})Js=Φ1(Fs)
- 操作解读: 将连续值的特征张量 FsF_sFs 输入到脉冲层 (Φ1\Phi^1Φ1) 中。
- 目的:
- 脉冲层会根据其膜电位和输入,决定是否发放脉冲(输出1)或不发放(输出0)。这是一个将连续值量化(Quantize) 为二进制脉冲的过程。
- 这使得空间特征 JsJ_sJs 的格式与后续时间特征提取器 TTT 中的SNN层完全兼容,为后续的融合奠定了基础。
- 上标 111 表示这是第一个时间步的脉冲层,其初始膜电位为0。
时间特征提取器 TTT
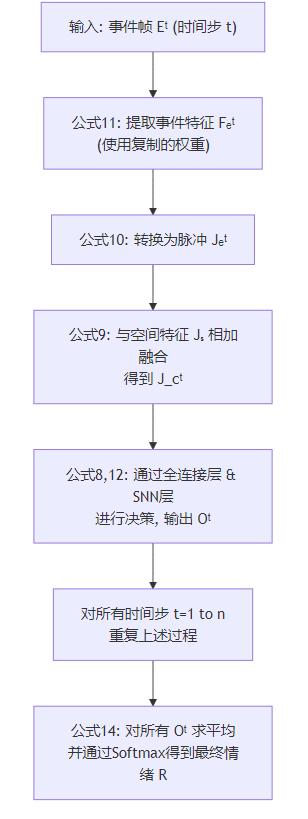
时间特征提取器 TTT 按时间顺序依次处理 nnn 个事件帧 (E1E^1E1 到 EnE^nEn)。对于每一个时间步 ttt,都执行以下操作。其核心数据处理与融合流程如下图所示:
流程:
第一步:提取事件特征 (公式11)
公式: Fet=C3(Φt(C3(Φt(Ω(3,5,7)(Et)))))F_{e}^{t} = C_{3}\left(\Phi^{t}\left(C_{3}\left(\Phi^{t}\left(\Omega_{(3,5,7)}\left(E^{t}\right)\right)\right)\right)\right)Fet=C3(Φt(C3(Φt(Ω(3,5,7)(Et)))))
- 操作解读 (从内到外):
- Ω(3,5,7)(Et)\Omega_{(3,5,7)}(E^t)Ω(3,5,7)(Et): 将当前事件帧 EtE^tEt 输入到多尺度自注意力模块中。注意: 这里的模块 Ω\OmegaΩ 与空间分支中的结构相同,但其权重是从 SSS 分支复制而来,不是自己学习的。这使得该模块能从事件帧中提取出在空间上重要的特征。
- Φt(⋅)\Phi^t(\cdot)Φt(⋅): 将提取的特征通过一个脉冲层。它将连续特征转换为脉冲信号,同时传递膜电位。
- C3(⋅)C_3(\cdot)C3(⋅): 用一个3x3卷积层进一步处理脉冲特征。
- 重复步骤2和3:Φ−>C3−>Φ−>C3Φ -> C₃ -> Φ -> C₃Φ−>C3−>Φ−>C3,逐步提炼特征。
- 目的: 从当前事件帧中提取出具有空间意义的、脉冲形式的初级特征 FetF_e^tFet。
第二步:生成事件脉冲特征 (公式10)
公式: Jet=Φt(Fet)J_{e}^{t} = \Phi^{t}(F_{e}^{t})Jet=Φt(Fet)
- 操作解读: 将上一步得到的特征 FetF_e^tFet 再次通过一个脉冲层 (Φt\Phi^tΦt)。
- 目的: 确保输出 JetJ_e^tJet 是纯脉冲信号,为下一步与空间分支的脉冲特征 JsJ_sJs 直接相加融合做准备。
第三步:时空特征融合 (公式9) - 最关键的一步
公式: Jct=Jet⊕JsJ_{c}^{t} = J_{e}^{t} \oplus J_{s}Jct=Jet⊕Js
- 操作解读: 将当前时间步的事件脉冲特征 JetJ_e^tJet 与从空间分支提取的全局空间脉冲特征 JsJ_sJs 进行逐元素相加(⊕\oplus⊕)。
- 目的与效果:
- JsJ_sJs 是一个富含纹理信息的“静态指南针”,它指示了哪些空间位置对情绪识别是重要的。
- JetJ_e^tJet 包含了当前时刻的动态变化信息,但本身是稀疏的。
- 相加操作相当于用空间特征 JsJ_sJs 来“增强”和“引导”事件特征 JetJ_e^tJet。它放大了重要区域的事件信号,抑制了不重要区域的噪声。这是一种非常巧妙的、隐式的注意力机制。
第四步:决策与输出 (公式8 & 12)
公式: Ot=M(Γ(Γ(Jct)))O^{t} = \mathcal{M}\left(\Gamma\left(\Gamma\left(J_{c}^{t}\right)\right)\right)Ot=M(Γ(Γ(Jct)))
其中: Γ(⋅):=Φt(Ψ(⋅))\Gamma(\cdot) :=\Phi^{t}(\Psi(\cdot))Γ(⋅):=Φt(Ψ(⋅))
- 操作解读 (从内到外):
- Ψ(⋅)\Psi(\cdot)Ψ(⋅): 一个全连接层,负责组合特征。
- Φt(Ψ(⋅))\Phi^t(\Psi(\cdot))Φt(Ψ(⋅)): 一个脉冲层,处理全连接层的输出。Γ\GammaΓ 单元是一个 “全连接层 + 脉冲层” 的复合结构。
- 将融合后的特征 JctJ_c^tJct 通过两个连续的 Γ\GammaΓ 单元进行非线性变换。
- M(⋅)\mathcal{M}(\cdot)M(⋅): 这是一个膜电位读取操作。它不取脉冲层的输出脉冲 PtP^tPt(0或1),而是读取其内部的膜电位 VtV^tVt(一个连续值)。
- 目的:
- 使用全连接层进行高级特征组合和决策。
- 读取膜电位 VtV^tVt 而非脉冲 PtP^tPt 是因为 VtV^tVt 包含了更丰富的置信度信息(距离阈值有多远),比二值的脉冲更适合做回归或分类。
第五步:序列平均与最终分类 (公式14)
公式: R=σ(1n∑t=1nOt)R=\sigma\left(\frac{1}{n} \sum_{t=1}^{n} O^{t}\right)R=σ(n1∑t=1nOt)
- 操作解读: 对所有 nnn 个时间步得到的输出 OtO^tOt (每个都是膜电位向量) 求平均,然后将平均值输入 Softmax 函数 (σ\sigmaσ),得到最终的情绪概率分布 RRR。
- 目的:
- 时序平均可以平滑掉瞬时的不确定性或噪声,使预测更加稳定和鲁棒。
- Softmax 将输出转换为概率形式。
权重复制
- 操作:
- 架构对齐: 确保时间分支 TTT 中、在脉冲相加操作(公式9)之前的所有卷积块(包括多尺度注意力模块 Ω\OmegaΩ),与空间分支 SSS 中的对应部分拥有完全相同的网络架构(对比公式3和公式11)。
- 冻结与复制: 在训练过程中,TTT 分支中的这些卷积块的权重被冻结(不更新)。它们的权重直接从训练中的 SSS 分支的对应部分复制过来(图2(a)中的红色虚线箭头)。
- 仅训练FC层: 在 TTT 分支中,只有脉冲相加操作之后的全连接层(在 Γ\GammaΓ 中)的参数是需要被训练的。
- 效果与原理:
- 知识迁移: SSS 分支处理的是有纹理的强度帧,它在训练中学到的卷积核天然地会提取与情绪相关的空间纹理特征。通过权重复制,TTT 分支“继承”了这种能力。
- 隐式空间注意力: 因此,当 TTT 分支处理事件帧时,虽然输入是稀疏的事件,但其卷积操作实际上是在寻找那些在空间上重要的区域所发生的变化。这相当于为时间分支安装了一个“空间注意力指南针”,引导它关注正确的区域。
- 隐式域适应(Implicit Domain Adaptation): 由于 TTT 分支的卷积权重是固定的,整个模型的损失梯度在反向传播时,全部由 SSS 分支的卷积层来承担。这意味着,SSS 分支的训练不仅要学会从强度帧中提取好的空间特征,还要保证这些特征在复制到 TTT 分支后,能对处理事件帧并最终完成情绪识别任务有帮助。这个过程 implicitly(隐式地)桥接了强度帧和事件帧之间的域间隙(Domain Gap)。
- 扩展到注意力权重:
- 权重复制同样应用于多尺度自注意力模块的权重(公式5产生的 ωsi\omega^{s_i}ωsi)。TTT 分支中的注意力权重直接使用 SSS 分支计算出的权重,而不是基于事件帧自己计算。
实现细节
-
在这个模型中,每个脉冲神经元只接受和处理一个标量值(一个通道的一个位置上的值)。输入的特征图有多少个元素(即维度有多大),就有多少个脉冲神经元在并行工作。
-
假设卷积层输出一个形状为 [16,64,32,32][16, 64, 32, 32][16,64,32,32] 的特征图 xxx:
- 161616: Batch size
- 646464: Channels
- 323232: Height
- 323232: Width
那么这个特征图总共有 16×64×32×32=1,048,57616 × 64 × 32 × 32 = 1,048,57616×64×32×32=1,048,576 个元素。
当这个特征图输入到脉冲层时:
- 系统会初始化一个同样形状为 [16,64,32,32][16, 64, 32, 32][16,64,32,32] 的膜电位张量 memmemmem,初始值为0。
- 每个位置都有一个独立的脉冲神经元:
- 位置 [0,0,0,0][0, 0, 0, 0][0,0,0,0] 的神经元只处理 x[0,0,0,0]x[0, 0, 0, 0]x[0,0,0,0] 这个值,维护 mem[0,0,0,0]mem[0, 0, 0, 0]mem[0,0,0,0],输出 spike[0,0,0,0]spike[0, 0, 0, 0]spike[0,0,0,0]
- 位置 [0,0,0,1][0, 0, 0, 1][0,0,0,1] 的神经元只处理 x[0,0,0,1]x[0, 0, 0, 1]x[0,0,0,1] 这个值,维护 mem[0,0,0,1]mem[0, 0, 0, 1]mem[0,0,0,1],输出 spike[0,0,0,1]spike[0, 0, 0, 1]spike[0,0,0,1]
- …
- 位置 [15,63,31,31][15, 63, 31, 31][15,63,31,31] 的神经元只处理 x[15,63,31,31]x[15, 63, 31, 31]x[15,63,31,31] 这个值
所以总共有 1,048,576 个脉冲神经元在并行工作,每个神经元独立地根据自己接收到的输入值更新自己的膜电位并决定是否发放脉冲。换言之,不同于生物神经元中获取多个输入并产生输出,这里的LIF仅接受一个标量作为输入。
-
代码中的设计看似每个“脉冲神经元”只接受一个输入,但这其实是对生物神经网络不同层次的抽象和等效实现。它并没有违背SNN的原理,而是通过一种更高效的方式实现了相同的数学功能。
我们可以用两种视角来理解这种设计:
视角一:将卷积操作视为“突触前编码”
在生物网络中,是突触前神经元的脉冲通过突触权重影响突触后神经元的膜电位。
在这个代码模型中,这个过程被“打包”处理了:
-
突触处理(卷积层):conv_layer(spikein)conv\_layer(spike_in)conv_layer(spikein)
- 输入:上一层的脉冲 spike_inspike\_inspike_in (0或1)
- 操作:卷积核权重 WWW 模拟了突触权重。卷积运算 W∗spike_inW * spike\_inW∗spike_in 模拟了所有突触前输入的空间加权和。
- 输出:一个连续值的张量 xxx。这个值就相当于所有突触前输入对当前神经元膜电位的总贡献值。
-
胞体处理(脉冲层):mem_update(x,mem,spike)mem\_update(x, mem, spike)mem_update(x,mem,spike)
- 输入:来自卷积层的总贡献值 xxx。
- 操作:mem=mem∗decay+xmem = mem * decay + xmem=mem∗decay+x 模拟了膜电位的积分和泄漏。spike=(mem>thresh)spike = (mem > thresh)spike=(mem>thresh) 模拟了发放机制。
- 输出:一个新的脉冲 spikespikespike (0或1)。
对于全连接层也是一样,虽然每个LIF只接受上一层对应的全连接层的神经元输出(一个标量)作为输入,但这个输入(全连接层ANN的输出)已经被ANN神经元进行加权整合了,每个LIF实际上是接受了一个整合后的结果作为输入,同样已经进行了**“突触前编码”**(通过全连接层)
所以,并不是脉冲神经元只接受一个输入,而是“接受多个输入并进行加权求和”的这个复杂过程,被提前到卷积层中去完成了。 脉冲层只负责完成最后的积分-泄漏-发放过程。
视角二:将整个 Conv+LIFConv + LIFConv+LIF 视为一个“复合神经元”
另一种理解方式是,不要将 conv_layerconv\_layerconv_layer 和 mem_updatemem\_updatemem_update 看作两个独立的层,而是将它们合起来视为一个 “卷积脉冲神经元层”。
- 输入:前一层发出的脉冲 SinS_{in}Sin。
- 内部处理:
- 空间整合:X=W∗SinX = W * S_{in}X=W∗Sin (卷积操作,模拟突触)
- 时空整合与发放:Vt=α∗Vt−1∗(1−St−1)+XtV_t = α * V_{t-1} * (1 - S_{t-1}) + X_tVt=α∗Vt−1∗(1−St−1)+Xt (膜电位更新,模拟胞体)
- 输出:St=Θ(Vt−Vth)S_t = Θ(V_t - V_{th})St=Θ(Vt−Vth) (脉冲发放)
从这个角度看,这个“复合神经元”确实接收了大量了输入(整个感受野内的脉冲),并产生了一个输出脉冲。代码只是将这个过程在实现上分成了两步。
-
-
换言之,在这里LIF脉冲神经元像是一个有记忆性和自身状态的二值激活函数。