3D 和 4D 世界建模:综述(上)
25年9月来自新加坡国立、浙大、地平线机器人公司、慕尼黑工大、香港科大、清华、南京理工、澳门大学和上海AI实验室的论文“3D and 4D World Modeling: A Survey”。
世界建模已成为人工智能研究的基石,使智体能够理解、表征和预测其所处的动态环境。尽管先前的研究主要侧重于二维图像和视频数据的生成方法,但却忽略利用原生三维和四维表征(例如RGB-D图像、占用网格和激光雷达点云)进行大规模场景建模的快速增长研究成果。同时,由于缺乏“世界模型”的标准化定义和分类,导致文献中的观点支离破碎,有时甚至不一致。本综述全面阐述三维和四维世界建模与生成。其建立精确的定义,引入涵盖基于视频(VideoGen)、基于占用(OccGen)和基于激光雷达(LiDARGen)方法的结构化分类法,并系统地总结了针对三维/四维环境的数据集和评估指标。另外,本文进一步讨论实际应用,确定尚未解决的挑战,并强调有前景的研究方向。
世界建模已成为人工智能和机器人技术的一项基本任务,旨在理解、表示和预测其所处的动态环境 [1]、[2]、[3]。生成式建模技术(包括变分自编码器 (VAE)、生成对抗网络 (GAN)、扩散模型和自回归模型)的最新进展,通过实现复杂的生成和预测能力,极大地丰富了该领域 [4]、[5]。
然而,这些进展大多集中在二维数据上,主要是图像或视频 [6]、[7]、[8]。相比之下,现实世界场景本质上存在于三维空间中,并且是动态的,通常需要利用原生三维和四维表示的模型。这些包括 RGB-D 图像 [9]、[10]、[11]、占用网格 [12]、[13]、[14] 和 LiDAR 点云 [15]、[16]、[17],以及捕捉时间动态的序列形式 [18]、[19]。这些模态提供了明确的几何和物理基础,这对于自动驾驶和机器人等具身和安全关键系统必不可少 [20]、[21]、[22]、[23]、[24]、[25]、[26]。除了这些原生格式之外,世界建模也在相邻领域得到了探索 [27]、[28]、[29]。一些工作涉及视频、全景或基于网格的数据,这类系统提供了大规模、通用的视频网格生成功能 [30]、[31]。与此同时,另一项研究则专注于用于资产创建的 3D 目标生成,专注于可控且高保真度的目标合成 [32]、[33]、[34]。与此同时,一些领先公司已经启动了雄心勃勃的世界建模计划,目标是从交互式机器人、沉浸式仿真到大规模数字孪生等实际应用 [35]、[36]、[37]、[38]、[39]、[40],凸显该领域在学术界和工业界日益增长的重要性。
尽管发展势头强劲,“世界模型”一词本身仍然含义模糊,文献中的用法也不一致 [27]、[41]、[42]。一些研究将其狭义地解释为用于感知数据(例如图像和视频)的生成模型,而另一些研究则将其范围扩大到包括预测预报、模拟器和决策框架 [43]、[44]、[45]、[46]、[47]。此外,现有研究主要侧重于二维或纯视觉模式 [6], [48],而原生三维和四维数据所蕴含的独特挑战和机遇尚未得到充分探索。这导致相关文献碎片化,缺乏统一的框架或分类方法。
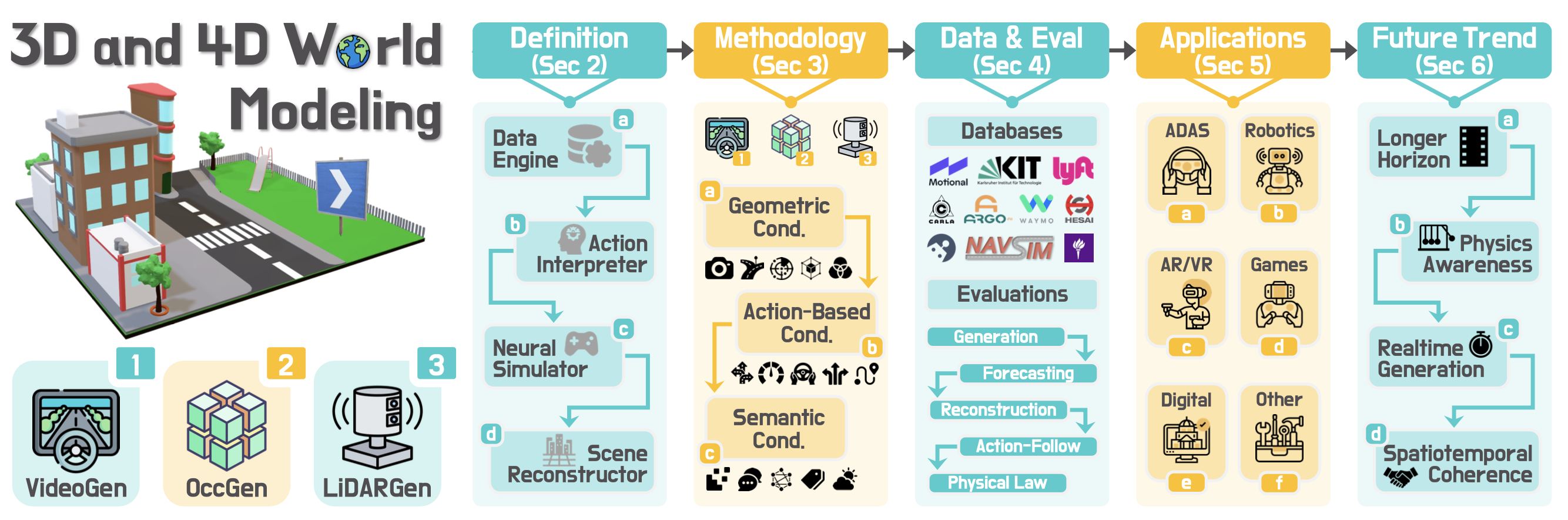
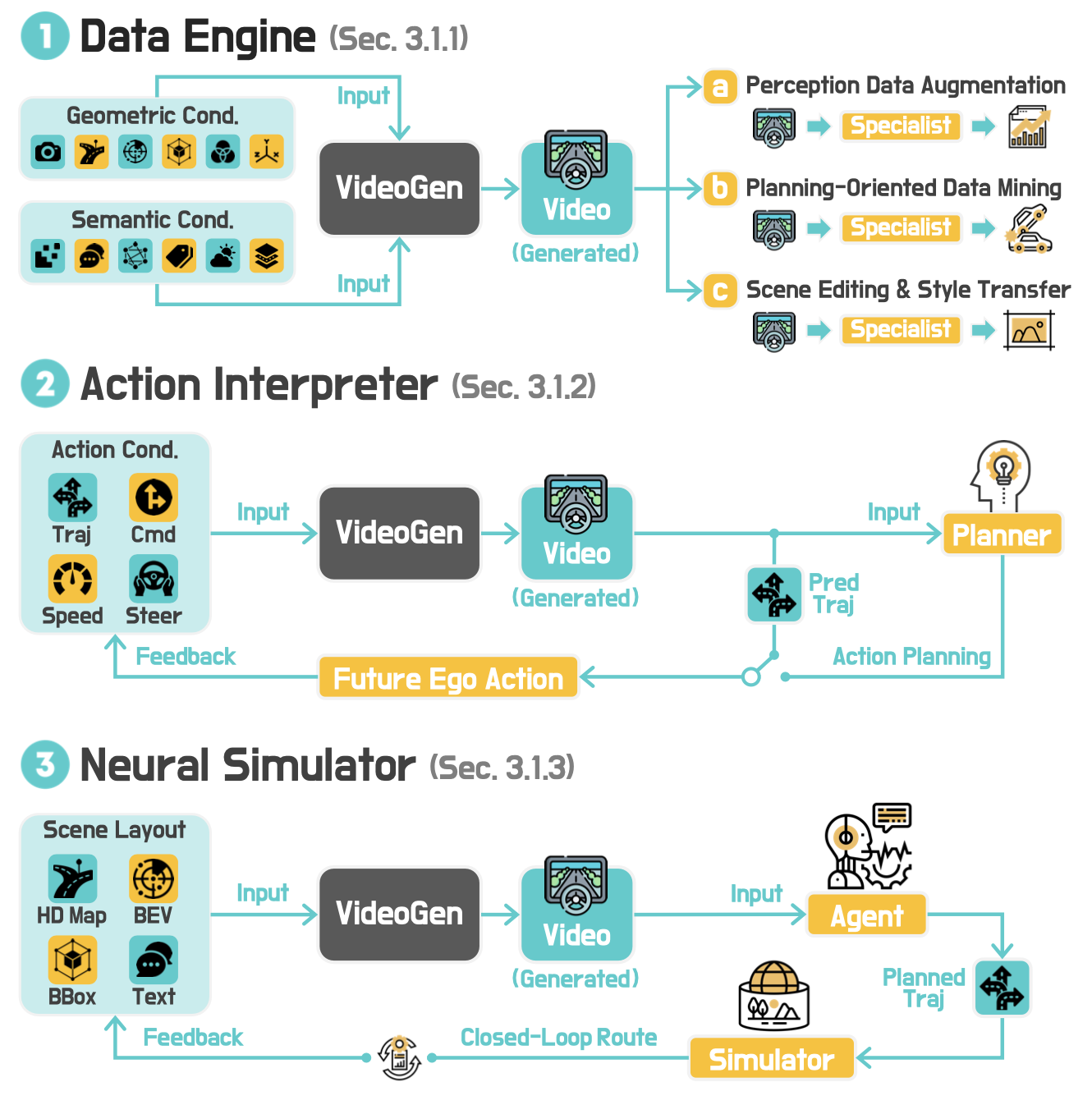
如图所示该综述概要。本研究聚焦于原生 3D 和 4D 表征:视频流、占用网格和 LiDAR 点云,并以几何(Cgeo)、基于动作(Cact)和语义(Csem)条件为指导。方法基于两种范式:生成型(根据观察和条件进行综合)和预测型(根据历史和动作进行预测),并分为四种功能类型。其涵盖三种模态轨迹,并针对不同的生成、预测和下游任务,对评估、应用和未来趋势进行标准化。
3D 和 4D 表示
分析生成和预测过程中用作输入、输出或中间状态的基本场景表示。这些表示在捕捉空间几何、时间动态和语义上下文的方式上有所不同。视频流。视频表示为 x_v,其中 T 表示帧数,H、W、C 分别表示帧的高度、宽度和通道数。与传统的 2D 视频不同,3D/4D 建模强调几何相干性和时间一致性,以确保物理上合理的模拟和准确的预测 [58]、[59]、[60]。
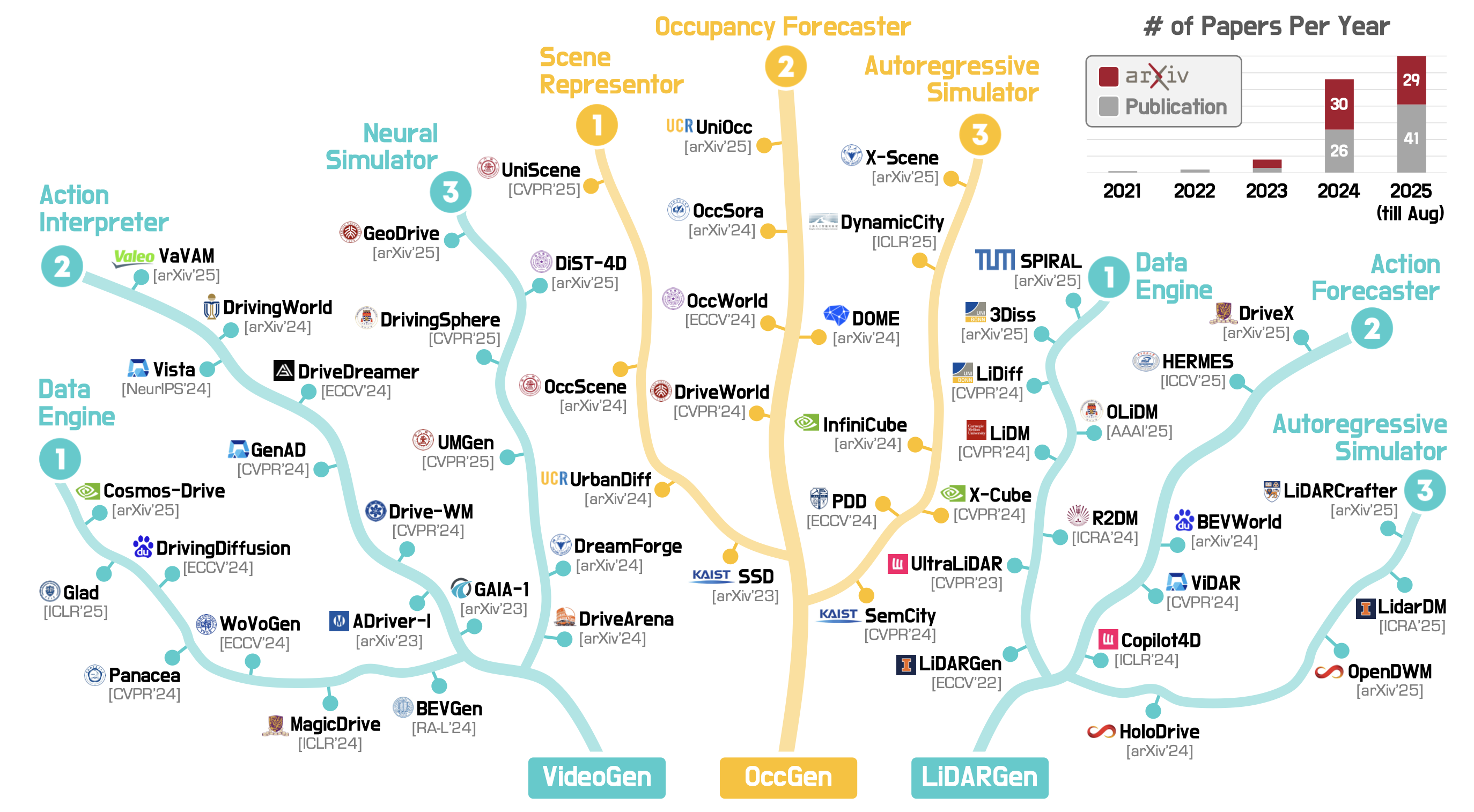
下图是现有文献中基于视频的生成 (VideoGen)、基于占用率的生成 (OccGen) 和基于激光雷达的生成 (LiDARGen) 模型的总结。
3D 和 4D 世界建模的定义
上述场景表征构成 3D/4D 世界模型的结构支柱。在实践中,生成或预测这些模型需要附加条件——辅助信号,用于约束空间结构、描述智体行为或定义高级语义。如表所示,这些条件通常分为:
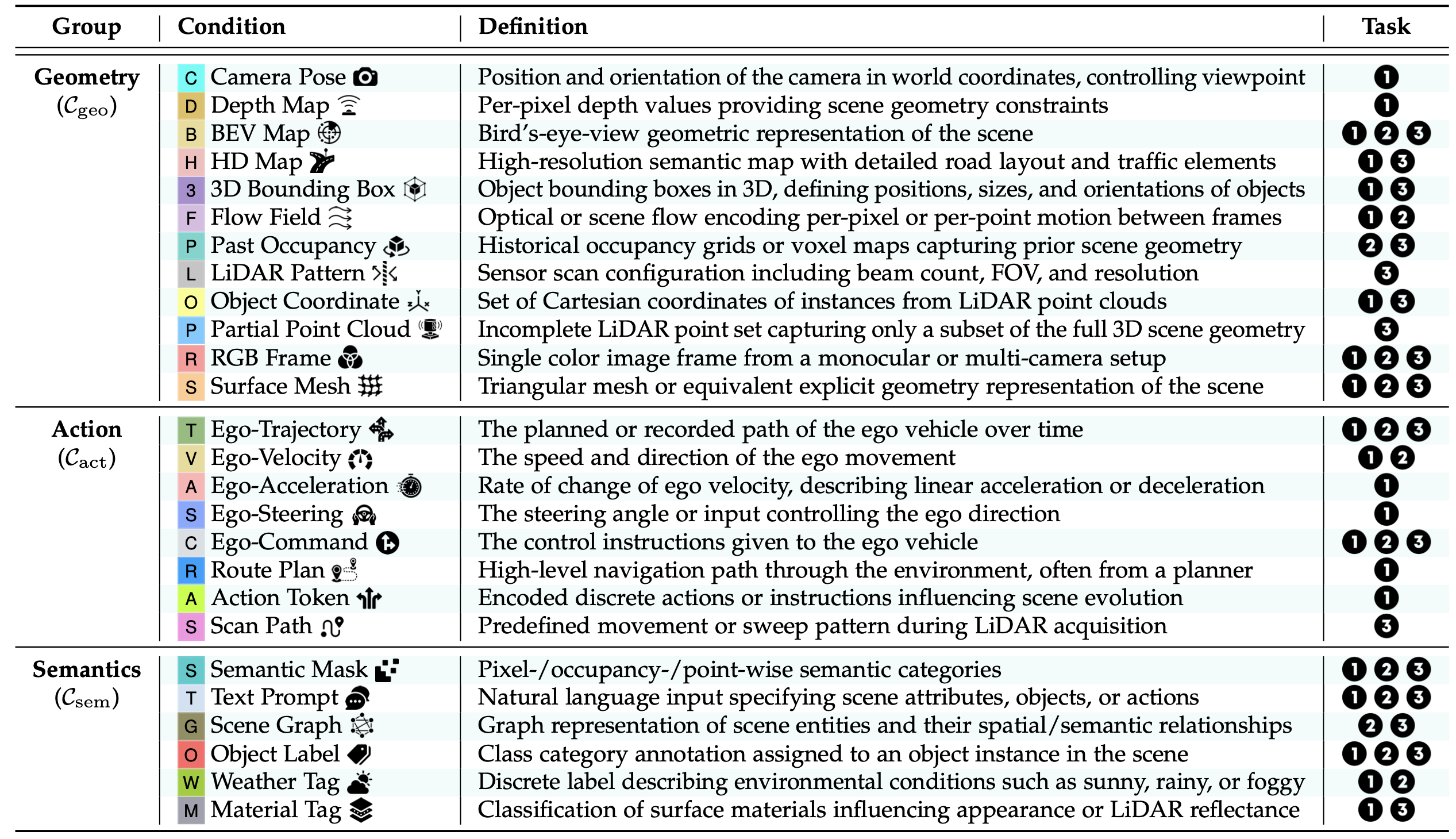
• 几何 C_geo:指定空间布局,例如相机姿态、深度图或占用体;
• 基于动作的 C_act:通过轨迹、控制命令或导航目标描述车辆或智体的运动;
• 语义 C_sem:提供抽象的场景意图,例如文本提示、场景图或环境属性。
这些信号可以单独使用或组合使用,从而塑造 3D 和 4D 生成或预测场景的真实性、可控性和多样性。
根据建模目标的不同,3D/4D 世界模型通常分为两种互补的范式:
生成世界模型专注于在多模态条件的指导下,从零开始或基于部分观测数据合成可信场景。该过程可以表示为:
G(x_i, C_geo, C_act, C_sem) → S_g, (1)
其中 x_i 表示可选的输入表征,i ∈ {∅, v, o, l},例如噪声、部分视频、占用或激光雷达数据。C_geo 、C_act 和 C_sem 分别对应几何、动作和语义条件。输出 S_g 是生成的 3D/4D 场景,例如视频序列、占用网格或激光雷达扫描序列。
预测世界模型则旨在根据历史观测数据预测场景的未来演变,通常是在描述计划或执行的智体行为的动作条件下。该过程可以表述为:
P(x−t:0_i, C_act) → S1:k_p, (2)
其中 x−t:0_i 表示从过去 t 步到当前 i 步的观测值,C_act 编码智体动作(例如,控制命令或规划轨迹)。模型输出 S1:k_p,即未来 k 步的预测场景表征。
模型分类如下 4 个:
类型 1:数据引擎
根据几何和语义线索生成多样化的 3D/4D 场景,并可选地添加动作条件。
• 输入:C_geo(几何条件)、C_act(动作条件,可选)和 C_sem(语义条件)
• 输出:S_g(生成的场景)
专注于大规模数据增强和场景创建的合理性和多样性。
类型 2:动作解释器
根据给定动作条件下的历史观测值预测未来的 3D/4D 世界状态。
• 输入:x−t:0_i(历史观测值)和 C_act(动作条件)
• 输出:S1:k_p(预测序列)
支持基于动作的预测,用于轨迹规划、行为预测和策略评估。
类型 3:神经模拟器
通过生成连续的场景状态,迭代模拟闭环智体与环境的交互。
• 输入:St_g(当前场景状态)和 π_agent(智体策略)
• 输出:St+1_g(下一个场景状态)
支持自动驾驶、机器人技术和沉浸式 XR 训练的交互式模拟。
类型 4:场景重建器
从部分、稀疏或损坏的观测数据中恢复完整且连贯的 3D/4D 场景。
• 输入:xp_i(部分观测数据)和 C_geo(可选几何条件)
• 输出:Sˆ_g(完整场景)
支持高保真地图绘制、数字孪生修复和事件后分析等交互式任务。
生成模型
生成模型构成了 3D/4D 世界建模的算法核心,使智体能够在各种条件下学习、想象和预测传感数据。它们提供了合成现实且物理上合理的场景的机制,不同的范式在质量、可控性和效率方面提供了不同的权衡。代表性的模型包括变分自编码器、生成对抗网络、扩散模型和自回归模型。
变分自编码器 (VAE) [66] 通过概率编码和解码来学习结构化的潜空间。给定输入 x,编码器定义变分后验概率 q_φ(z|x) = N (μ_φ (x), diag(σ2_φ (x))),并使用重参数化技巧对 z 进行采样:z = μ_φ(x) + σ_φ(x) ⊙ ε,其中 ε ∼ N (0, I)。解码器 p_θ(x|z) 重构输入,并训练模型以最大化变分下界,从而平衡重构保真度和潜在正则化。
VAE 提供稳定的训练和可解释的潜空间,但与其他范式相比,可能产生更模糊的样本。
生成对抗网络 (GAN) [67] 通过生成器 G_θ 和鉴别器 D_φ 之间的最小最大博弈来生成数据。生成器将潜变量 z ∼ p(z) 映射到数据空间,旨在欺骗 D_φ,而鉴别器则区分真实样本和合成样本。
GAN 可以生成高保真度的结果样本,但经常受到训练不稳定性以及模式崩溃问题的影响。
扩散模型 (DM) [68]、[69] 学习一个逐渐噪声化的逆过程。正向过程通过 q(x_t | x_t−1) = N(x_t; (1−β_t)0.5 x_t−1, β_t I) 将 x_0 污染为 {x_1,…,x_T},其中 β_t 遵循方差调度。这个逆过程 p_θ(x_t−1|x_t) 经过训练,通过最小化损失来实现去噪。
DM 具有很强的稳定性和样本质量,但由于迭代采样,推理速度可能会比较慢。
自回归模型 (AR) [70], [71] 将联合分布分解为 p(x) = product p(x_i | x_<i),预测每个元素都取决于所有先前元素。基于 Transformer 的 AR 提供精确的似然估计和灵活的序列建模,但由于样本是按顺序生成的,因此生成速度较慢。最近的进展已将 AR 应用于空间和时间 token,使其非常适合结构化 3D 场景的生成和预测。
总结:这些范式构成世界模型的算法支柱。它们在结构、训练稳定性和推理效率方面的差异直接影响 3D 环境的合成、预测和控制方式。一旦进入原生 3D/4D 领域,这些权衡取舍会被放大,因为可扩展性、可控性和多模态集成对于构建可靠的具身 AI 和模拟世界模型至关重要。
基于视频生成的世界建模
基于视频的生成已成为一种新的范式,它提供视觉线索和时间动态来模拟复杂的现实世界场景。通过生成多视角或以自我为中心的视频序列,这些模型可以合成训练数据、预测未来结果并创建交互式模拟环境。根据其主要功能,现有方法可分为三类:1)数据引擎、2)动作解释器和3)神经模拟器。下表总结这些领域下的现有模型:
数据集:N-nuScenes [10]、K-KITTI [11]、W-Waymo Open [95]、Y-OpenDV-YouTube [96]、A-Argoverse 2 [97]、N-nuPlan[98]、N-NAVSIM [99]、C-CARLA [100] 和 P-私有(内部)数据。
输入和输出:噪声潜变量数据、视频(单视图和/或多视图)数据和自动作数据。
架构(架构):AR:自回归模型、MLLM:多模态大语言模型、SD:稳定扩散模型、DiT:扩散transformer、GPT:生成式预训练 transformer。
任务:VG:视频生成、E2E:端到端规划、3SR:3D 场景重建。
类别:数据引擎、动作解释器和神经模拟器。
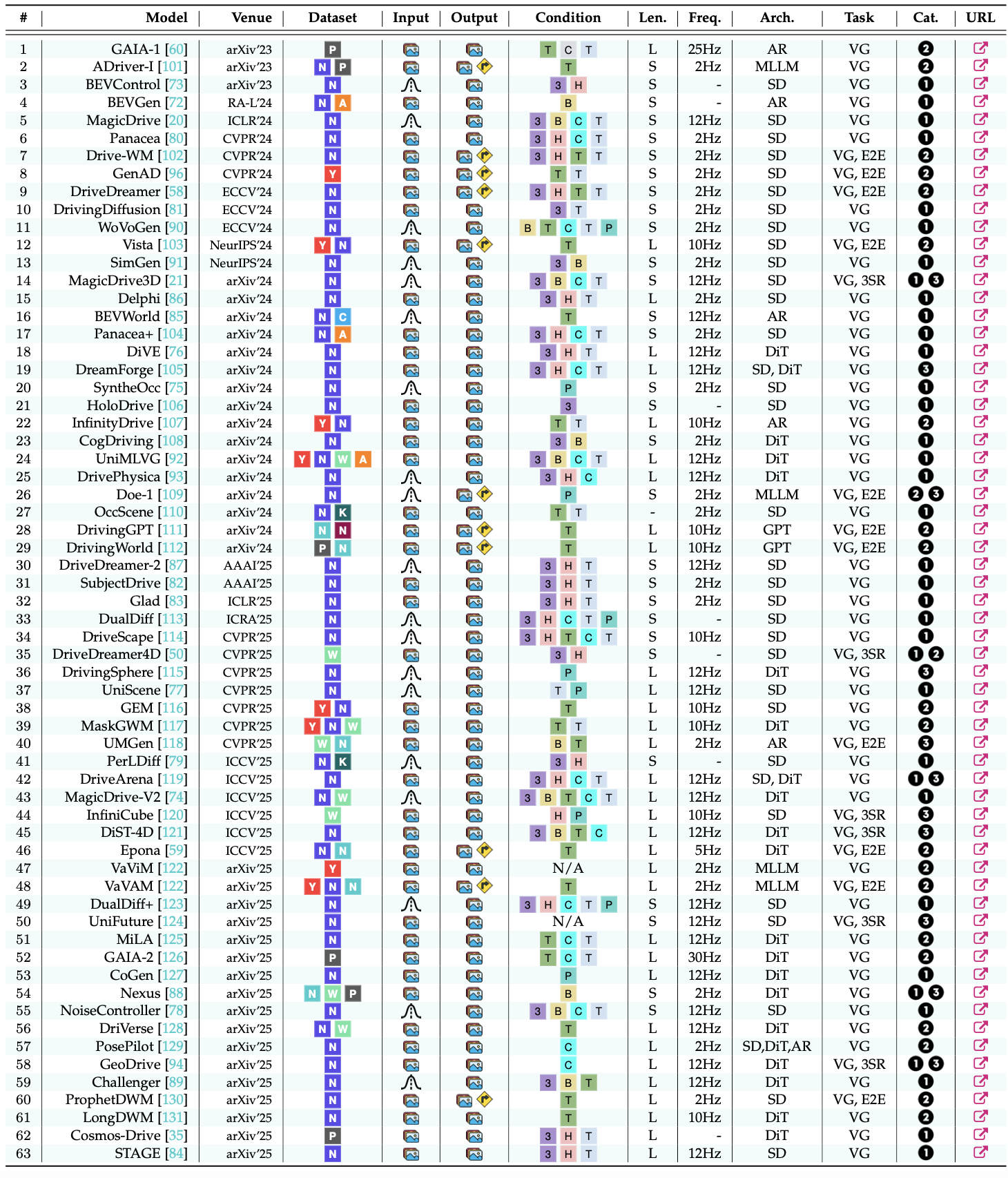
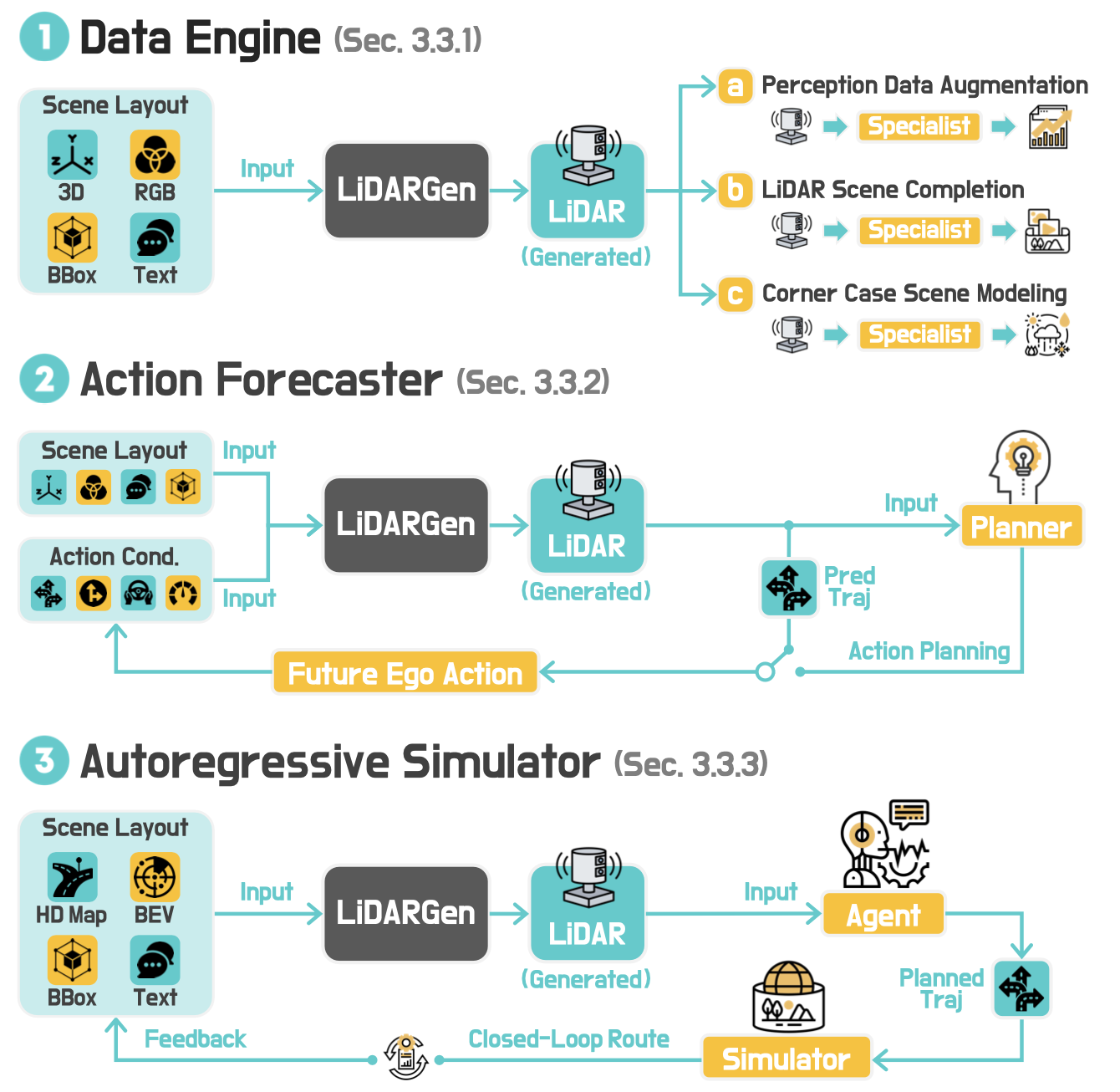
数据引擎
生成式 3D 数据引擎专注于生成多样化、可控的驾驶场景,以支持感知、规划和仿真 [20]、[72]、[73]、[74]、[75]、[76]、[77]、[78]。该方向的研究涵盖三大应用:感知数据增强、面向规划的数据挖掘和场景边界和风格迁移。
动作解释器
动作驱动的生成模型通过 1)动作引导的世界生成和 2)预测驱动的行动规划,将智体意图与环境动态联系起来,从而实现结果预测,并通过将控制映射到合理的未来来统一低级操作和推理。
神经模拟器
闭环模拟器能够生成逼真的虚拟世界,支持有效的规划、决策和交互。根据场景建模的不同,近期的方法大致可分为两种主要方法:生成驱动的仿真和重建为中心的仿真(NeRF 和 3D GS)。
如图直观显示三种方法:
基于占用生成模型的世界建模
基于占用网格的生成模型,旨在提供以几何为中心的表征,该表征编码三维世界的语义和结构细节。通过在 3D/4D 空间中生成、预测或模拟占用情况,这些模型为感知提供几何一致的框架,实现了基于动作的未来预测,并支持逼真的大规模模拟。根据其主要功能,现有方法可分为三类:场景表示器、占用预测器和自回归模拟器。下表总结这些领域下的现有模型:
数据集:S-SemanticKITTI [16]、C-CarlaSC [163]、N-Occ3D-nuScenes [14]、W-Waymo Open [95]、L-Lyft-Level5 [164]、A-Argoverse 2 [97]、3-KITTI-360 [165]、U-NYUv2 [9] 和 O-OpenCOOD [166]。
输入和输出:噪声潜数据、潜码本、图像、3D 位置数据、4D 位置数据和自动作数据。
架构(架构):Enc-Dec:编码器-解码器,LDM:潜扩散模型,MSSM:记忆状态空间模型,AR:自回归模型,DiT:扩散 transformer,LLM:大语言模型。
任务:O3G:3D 占用生成、O4G:4D 占用生成、OF:4D 占用预测、PT:预训练、SSC:语义场景完成、和 E2E:端到端规划。
类别:场景表示、占用预测和自回归模拟。
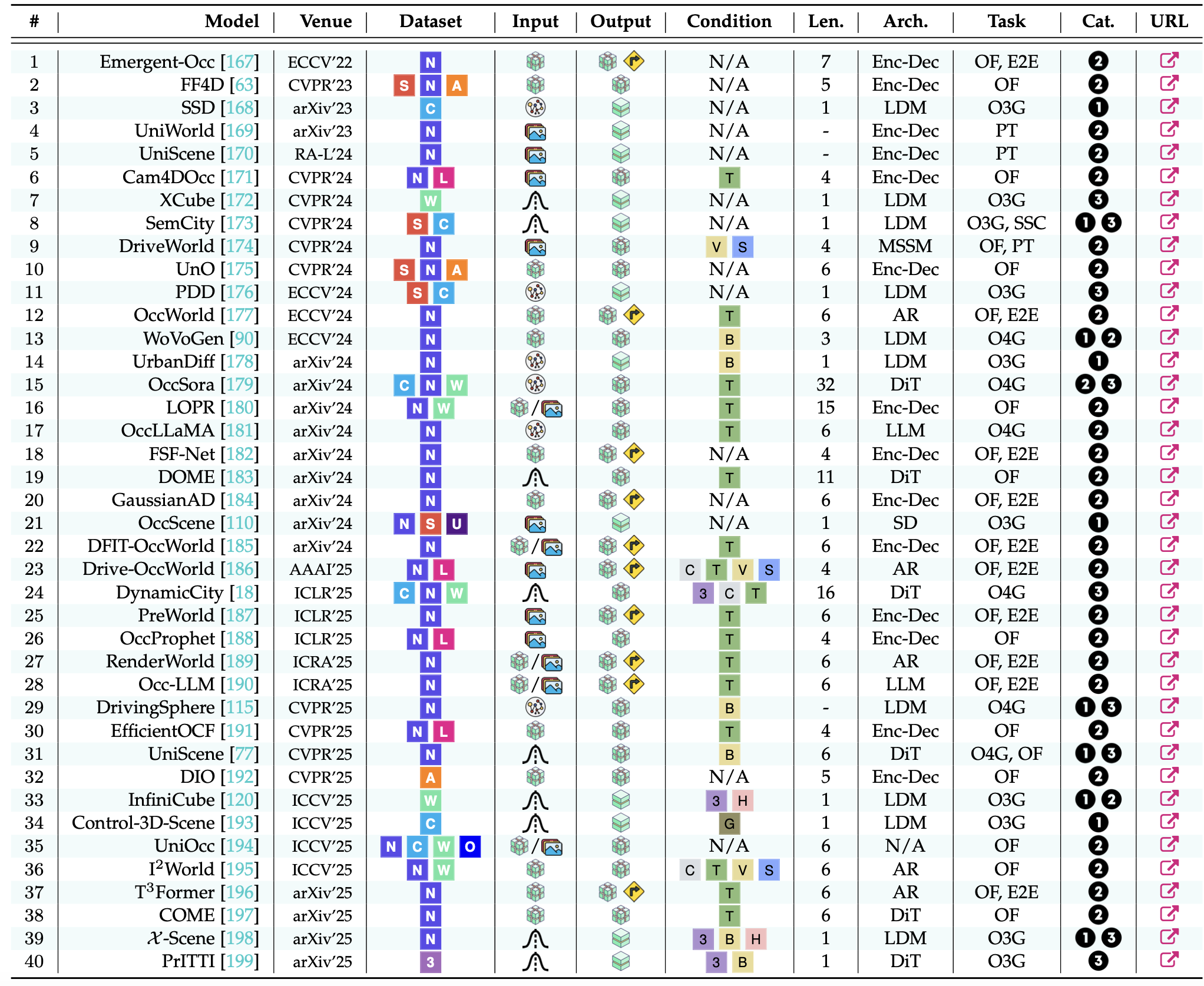
场景表征
基于占用的 3D 和 4D 生成模型旨在学习结构化的 3D 场景表征,将占用网格视为下游任务的几何一致性中间体。这种范式增强感知的鲁棒性,并为两大主要应用领域的 3D 场景生成提供了结构化指导:3D感知鲁棒性增强和生成一致性引导。
占用预测器
4D 占用预测模型能够根据自我行为和过往观察预测未来占用,从而预测环境变化。此功能有两个用途:作为构建可泛化 3D/4D 模型的自监督预训练任务(预测模型预训练),和作为行为-觉察、可控未来场景生成的动态预测器(自我为条件的占用预报)。
#自回归模拟器
基于占用的自回归模拟器能够生成大规模、时间相干的 4-D 占用,用于逼真的交互式模拟。它们可作为感知、规划和决策的基础模拟器,其研究重点包括两个方向:生成可扩展的无界环境,以及建模可控闭环模拟的长视界动态。
基于 LiDAR 生成的世界建模
基于 LiDAR 的生成模型通过从点云建模复杂场景,提供几何-觉察和外观不变的表征。它们能够实现强大的 3D 场景理解和高保真几何模拟,在几何保真度和环境鲁棒性方面均优于基于图像和占用的方法。根据其主要功能,这些方法可分为三类:数据引擎、动作解释器和自回归模拟器。下表总结这些领域的现有模型:
数据集:K-KITTI [11]、S-SemanticKITTI [16]、N-nuScenes [10]、3-KITTI-360 [165]、P-PandaSet [217]、C-Carla [100]、S-SeeingThroughFog [218]、W-Waymo Open [95]、N-NAVSIM [99]、A-Argoverse 2 [97] 和 O-OmniDrive-nuScenes [219]。
输入和输出:噪声潜数据、潜码本、噪声 LiDAR 点云、LiDAR 点云、LiDAR 序列以及图像/视频(单视图和/或多视图)。
架构(Arch.):GAN:生成对抗网络,Enc-Dec:编码器-解码器,LDM:潜扩散模型,AR:自回归模型,DiT:扩散transformer,LLM:大语言模型。
任务:LG:激光雷达生成,L4G:4D 激光雷达生成,SEG:3D 语义分割,DET:3D 物体检测,SC:场景完成,OP:占用预测,E2E:端到端规划。
类别:数据引擎、动作预测器和自回归模拟器。
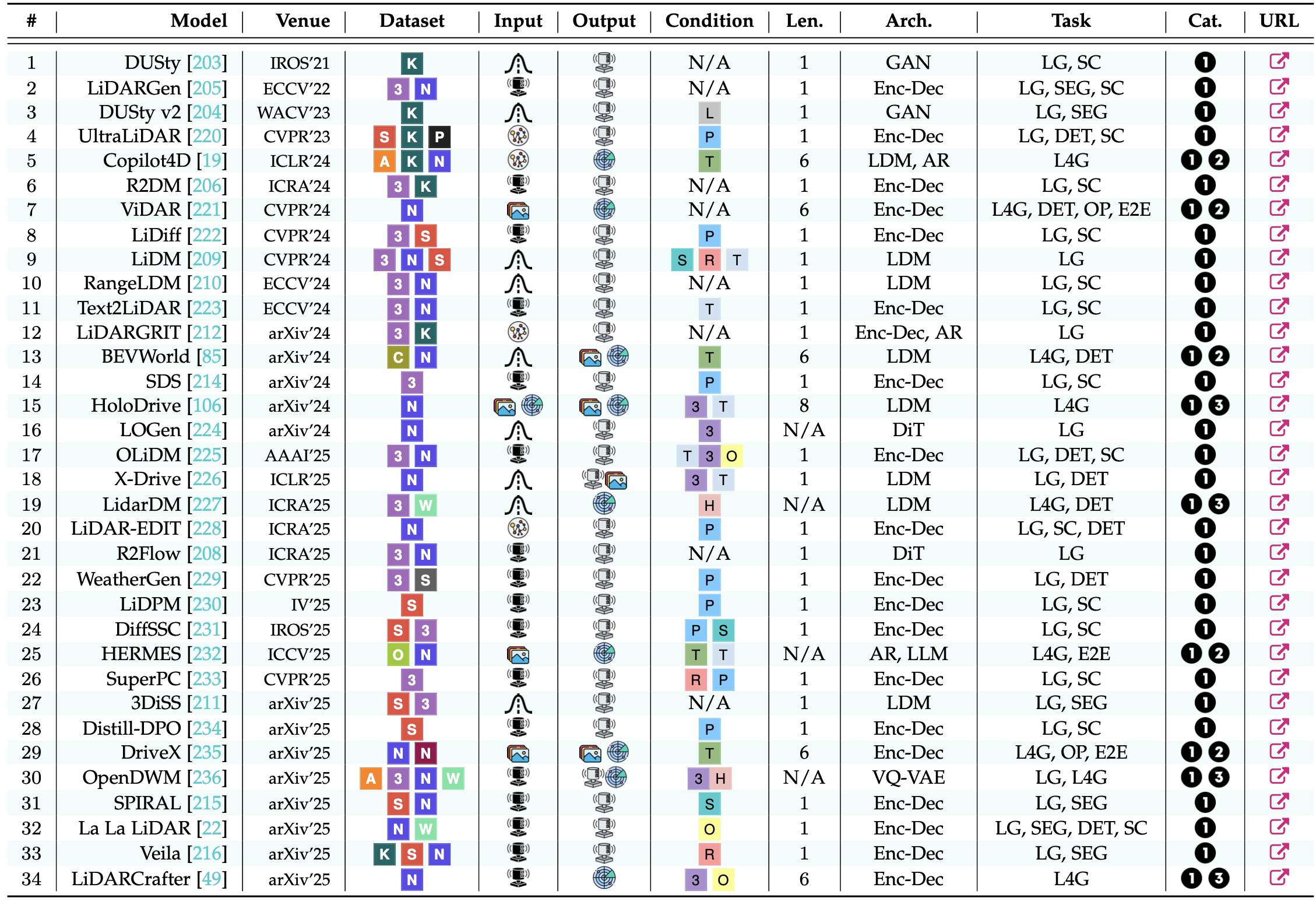
数据引擎
基于激光雷达的数据引擎通过生成多样化且可控的点云,缓解了大规模激光雷达训练数据因高昂的采集成本和标注挑战而造成的稀缺性问题 [201], [202]。此类模型增强了感知的鲁棒性,实现了几何精确的场景补全,并支持罕见或跨模态场景的合成 [49]。近期的方法主要集中在四个主要应用领域:感知数据增强、场景补全、罕见条件建模和多模态生成。
行动预测器
基于激光雷达的世界模型作为行动预测器,基于过去的观测,生成以给定未来状态为条件的未来激光雷达序列,包括时间建模和多模态行动预测器。
自回归模拟器
作为自回归模拟器的世界模型,旨在生成时间相干的激光雷达序列,用于逼真的交互式模拟。这些模型是感知、规划和决策的基础,重点关注几何保真度和时间一致性。现有方法可根据其数据生成范式分为两类:顺序自回归激光雷达生成和基于网格的场景-规模的模拟。
如图直观显示三种类别的方法: