LeetCode算法日记 - Day 53: 验证二叉搜索树、二叉搜索树的第K小元素
目录
1. 验证二叉搜索树
1.1 题目解析
1.2 解法
1.3 代码实现
2. 二叉搜索树的第K小元素
2.1 题目解析
2.2 解法
2.3 代码实现
1. 验证二叉搜索树
https://leetcode.cn/problems/validate-binary-search-tree/description/
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 严格小于 当前节点的数。
- 节点的右子树只包含 严格大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
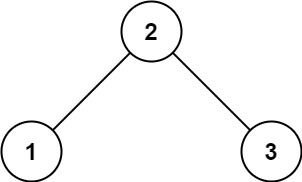
输入:root = [2,1,3] 输出:true
示例 2:
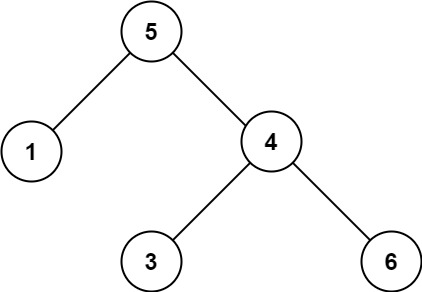
输入:root = [5,1,4,null,null,3,6] 输出:false 解释:根节点的值是 5 ,但是右子节点的值是 4 。
提示:
- 树中节点数目范围在
[1, 104]内 -231 <= Node.val <= 231 - 1
1.1 题目解析
题目本质
把“每个节点值必须大于左子树所有值、小于右子树所有值”转化为:对每个节点,维护它必须落在的开放区间 (low, high)。这个区间来自它所有祖先给它的“家规”。
常规解法
直觉会想:对每个节点递归求左子树最大值、右子树最小值,再比较 leftMax < node.val < rightMin。
问题分析
-
如果每次都去整棵左/右子树找极值,最坏会反复扫描,时间复杂度退化到 O(n²)。
-
还容易忽略“祖先”的约束(深层右-左节点必须同时大于根)。
-
用 int 边界容易在 Integer.MIN_VALUE / MAX_VALUE 附近踩坑(等于边界时被误判)。
思路转折
要想 O(n) 地一次遍历解决,就把“祖先的约束”随着递归一起下传:
-
访问一个节点前,它已经拿到了祖先们合并后的允许区间 (low, high);
-
检查 low < node.val < high,不满足直接剪枝返回 false;
-
继续把更新后的家规传给左右孩子:左子树 (low, node.val),右子树 (node.val, high)。 此外,用 long 作为边界 避免边界值误判。
1.2 解法
算法思想
• 维护每个节点的允许区间 (low, high);
• 空节点合法;
• 若 node.val <= low 或 node.val >= high,违规;
• 左递归用 (low, node.val),右递归用 (node.val, high);
• 初始用整域:(Long.MIN_VALUE, Long.MAX_VALUE)。
i)定义辅助函数 isValid(node, low, high)。
ii)若 node == null 返回 true。
iii)检查当前值是否落在 (low, high) 内(严格不等)。
iv)递归校验左子树:isValid(node.left, low, node.val)。
v)递归校验右子树:isValid(node.right, node.val, high)。
vi)两侧都为真则返回真,否则返回假。
易错点
-
必须是严格不等:< 和 >,不能允许相等。
-
只传一个边界会漏掉“祖先约束”,必须同时维护 low 和 high。
-
初始边界若用 int 的 MIN/MAX,当节点值等于边界会被误判;用 long 更安全。
-
不要把空子树当 0 或其它值参与比较——空子树直接返回 true。
1.3 代码实现
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public boolean isValidBST(TreeNode root) {return isValid(root, Long.MIN_VALUE, Long.MAX_VALUE);}private boolean isValid(TreeNode node, long low, long high) {// 1) 空树合法if (node == null) return true;// 2) 当前节点必须在 (low, high) 的开放区间内(严格不等)if (node.val <= low || node.val >= high) return false;// 3) 递归校验左右子树,并分别更新家规return isValid(node.left, low, node.val)&& isValid(node.right, node.val, high);}
}
复杂度分析
-
时间复杂度:每个节点至多访问一次,O(n)。
-
空间复杂度:递归栈深度为树高,O(h)(最坏退化链表时 O(n),平衡树时 O(log n))。
2. 二叉搜索树的第K小元素
https://leetcode.cn/problems/kth-smallest-element-in-a-bst/
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)。
示例 1:
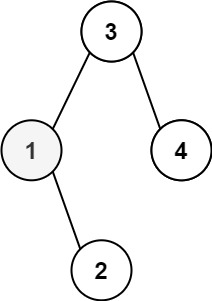
输入:root = [3,1,4,null,2], k = 1 输出:1
示例 2:
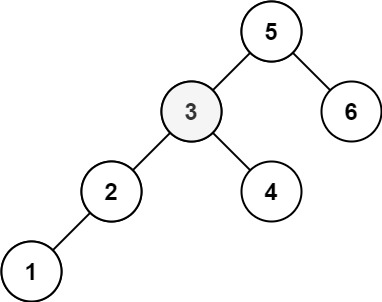
输入:root = [5,3,6,2,4,null,null,1], k = 3 输出:3
提示:
- 树中的节点数为
n。 1 <= k <= n <= 1040 <= Node.val <= 104
2.1 题目解析
题目本质
在二叉搜索树(BST)里,中序遍历(左→根→右)会按非降序输出所有值;因此“第 k 小”就是“中序序列里的第 k 个”。
常规解法
把整棵树做一次中序遍历,收集到数组,然后返回 arr[k-1]。
问题分析
完整收集需要 O(n) 时间与 O(n) 额外空间;而题目只要前 k 个元素,没必要遍历/存储剩余节点。极端情况下(k 很小),完整遍历做了大量“无用功”。
思路转折
要想更快 → 把中序遍历与计数结合,只要数到第 k 个就立刻停止。
这带来两层优化预期:
-
单次查询时,时间降到“走到第 k 个为止”,即 O(h + k)(h 为树高);
-
多次查询时,可在每个节点维护“左子树大小 sizeLeft”,自顶向下比较 k 与 sizeLeft,每次查询 O(h),适合频繁查询的场景。
2.2 解法
算法思想
• 中序遍历序列是升序。维护一个全局/外部变量 remain = k,每访问一个节点就 --remain;当 remain == 0 时,当前节点值就是答案,随后剪枝返回,不再继续遍历。
• 若需要“多次查询”,利用“秩选择”思想:设 L = size(node.left),若 k ≤ L 走左;若 k == L + 1 返回当前;否则令 k = k - (L + 1) 走右。
i)准备两个字段:remain = k,ans 存答案。
ii)递归函数 dfs(node):若 node == null 或 remain == 0 直接返回(剪枝)。
iii)递归左子树 dfs(node.left)。
iv)返回到当前 node 时,执行 --remain;若变为 0,记录 ans = node.val 并返回(后续全靠入口处的剪枝停止)。
v)递归右子树 dfs(node.right)。
vi)主函数调用 dfs(root),最后返回 ans。
易错点
-
忘记剪枝:找到第 k 个后,如不在函数入口处判断 remain == 0,右子树还会继续遍历,既耗时又可能把 remain 变成负数。
-
复用同一个 Solution 实例时,全局状态必须重置(remain、ans)。
-
极端退化链(高度 ≈ n)时,递归可能接近 JVM 栈深度上限;
2.3 代码实现
class Solution {private int remain; // 还需要访问多少个节点private int ans;public int kthSmallest(TreeNode root, int k) {this.remain = k;this.ans = -1;dfs(root);return ans;}private void dfs(TreeNode node) {if (node == null || remain == 0) return; // 基例 + 剪枝dfs(node.left); // 先走左if (remain == 0) return; // 左子树已经找到就不要再处理当前与右子树if (--remain == 0) { // 访问“当前”节点ans = node.val;return; // 已经确定答案,交给入口剪枝阻断后续递归}dfs(node.right); // 再走右}
}
复杂度分析
-
时间复杂度:O(n)(最坏)/ O(h + k)(更精细)。
-
空间复杂度:O(h),即递归深度。