C++_STL和数据结构《3》_仿函数作为STL中算法参数的用法、匿名函数、序列容器使用、关联容器使用、无关联容器使用、容器适配器使用
0、前言:
- “算法是舞台,迭代器是跑道,仿函数是剧本,换剧本,同一舞台就能演出完全不同的戏 。” 具体而言:容器是算法的“数据仓库”,真正和算法打交道的是这个容器对应的迭代器区间。仿函数是一段可以调用的用户逻辑,是算法核心逻辑调节剂。
- 这篇笔记目的是找到适合自己记忆STL中容器的方法。
- 在这一篇笔记中,目的是把c++中STL常见的一些容器加以总结使用,同时总结相关其他知识,其中涉及STL开头标题就是STL部分知识,其中涉及ADD开头标题就是补充知识。
1、STL_仿函数作为算法参数的使用:
1.1、基础概念:
- 之前已经介绍过仿函数了,对仿函数的认识停留在“仿函数”就是某个类的对象调用类中重载的“()”运算符,实现用类的对象模拟函数的做法。
1.2、STL的算法中如何调用仿函数
- 代码:其中std::accumulate,在下面代码中把其逻辑表达了出来,方便阅读,现实中是通过<numeric>引入之后,直接调用的。
#include <iostream>
#include <vector>
#include <string>
using namespace std;// 最简版,和 std::accumulate 原理 100% 相同
template<class InputIt, class T, class BinaryOp>
T my_accumulate(InputIt first, InputIt last, T init, BinaryOp op)
{for (; first != last; ++first)init = op(init, *first); // ← 关键就这一行return init;
}class Sum {
public:int operator()(int a, int b) const { return a + b; }
};class Max {
public:int operator()(int a, int b) const { return a > b ? a : b; }
};class Json {
public:string operator()(const string& s, int x) const {return s.empty() ? "[" + to_string(x): s + "," + to_string(x);}
};/*---------- 使用场景 ----------*/
int main() {vector<int> v{ 3, 1, 4, 1, 5 };Sum o_sum;Max o_max;Json o_json;// 剧本 1:求和int sum = my_accumulate(v.begin(), v.end(), 0, o_sum);cout << "sum = " << sum << '\n';// 剧本 2:最大值/*INT_MIN 是 C/C++ 标准头文件 <climits>(C 语言里是 <limits.h>)定义的一个宏,表示当前平台上 int 类型所能取到的最小(最负)值-2的31次方。*/int mx = my_accumulate(v.begin(), v.end(), INT_MIN, o_max); cout << "max = " << mx << '\n';// 剧本 3:拼 JSONstring json = my_accumulate(v.begin(), v.end(), string{}, o_json) + "]";cout << "json = " << json << '\n';// lambda也是匿名类int mul = my_accumulate(v.begin(), v.end(), 1, [](int a, int b) {return a * b; });cout << "mul = " << mul << '\n';
}
- 运行结果
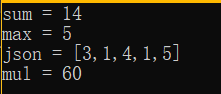
1.3、为什么放着普通函数不用,要用仿函数?
- 之前的理解就是对象可以携带类中的一些属性,而普通函数无法携带属性值,用普通函数就需要用全局变量了,不安全,也不方便。【仿函数的活,普通函数可以干,但是干的不漂亮】
- 用仿函数实现:如果需要调用accumulate算法实现加法操作,当容器中的值加到10的时候,停止,并返回最终的值,以及相加的次数
#include <iostream>
#include <vector>
#include <string>
#include <numeric>
using namespace std;
// 普通函数
int add(int a, int b) { return a + b; }
// 用类实现加法计数和最大值停止
class Add
{
public:int limit;int count;// 构造函数Add(int l): limit(l),count(0){}// 添加拷贝构造函数,观察复制行为Add(const Add& other) : limit(other.limit), count(other.count) {cout << "调用拷贝构造函数(对象被复制)" << endl;}int operator()(int a, int b){return a + b > limit ? limit : [this, a, b]() {++(this->count); return a + b; }();}
};/*---------- 使用场景 ----------*/
int main() {vector<int> v{ 1,2,5,7,9 };int sum = accumulate(v.begin(), v.end(), 0, add); // 普通函数也可以编译cout << sum << endl; // 24Add ad(5);int lim_sum = accumulate(v.begin(), v.end(), 0, ad);cout << "运行次数:" << ad.count <<"极限和为:" << lim_sum << endl; // 运行次数:0 极限和为:5
}
运行结果:
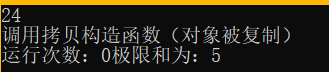
- 通过运算结果可以看出起到限制作用的limit起到了让仿函数携带状态的作用,但记录次数的count,并没有起到作用,从运行结果中看到了在程序运行过程中调用拷贝构造函数,这就涉及仿函数调用的一个很重要的问题,那就是被调用的仿函数是拷贝出来的一个对象,而非原始对象ad;
- 解决方案:
①、引入<functional>库,需包含此头文件使用std::ref
②、修改如下代码,这样就可以通过 std::ref(ad) 替代直接传递 ad,确保 accumulate 使用的是原始对象的引用,而非副本。
int lim_sum = accumulate(v.begin(), v.end(), 0, ref(ad));
修改后运行结果:

2、ADD_匿名函数:
2.1、引言:
- 在1.3中看到了c++中匿名函数的影子:
[this, a, b]() {++(this->count); return a + b; }()
这个函数匿名函数 [ ] 是捕获列表、第一个()表示匿名函数参数列表,{ } 当中是匿名函数的函数体。最后一个(),表示调用该匿名函数。
2.2、匿名函数概念
- 匿名函数由来:c++11之前,当需要传递一个简短的 “回调函数”(比如给 sort 算法传排序规则,给 for_each 传遍历操作)时,有两种方式:定义一个普通函数、定义一个仿函数(重载 () 的类)普通函数需要单独定义,逻辑上面太分散,仿函数,又要定义类,语法繁琐。
- C++11 引入了 lambda 表达式,允许在需要函数的地方 “就地定义” 一个匿名函数,无需单独命名,直接作为参数传递。
- 匿名函数的作用: 在 C++ 中,匿名函数通常指 lambda 表达式(C++11 引入),它是一种 “就地定义的匿名函数对象”,可以简化代码编写,尤其适合作为短回调函数使用。
2.3、匿名函数书写格式
- 完整格式如下:
[capture-list] (parameters) mutable -> return-type { function-body }
- 其中[capture-list]是捕获列表,(parameters)是参数列表,mutable允许修改按值捕获的变量副本,如果是引用捕获的变量可以修改,不用再加mutable(默认值捕获不可修改)【可选】,-> return-type是返回类型:指定 lambda 的返回值类型(多数情况可省略,由编译器自动推导)【可选】, { function-body }是函数体。
- 关于捕获列表
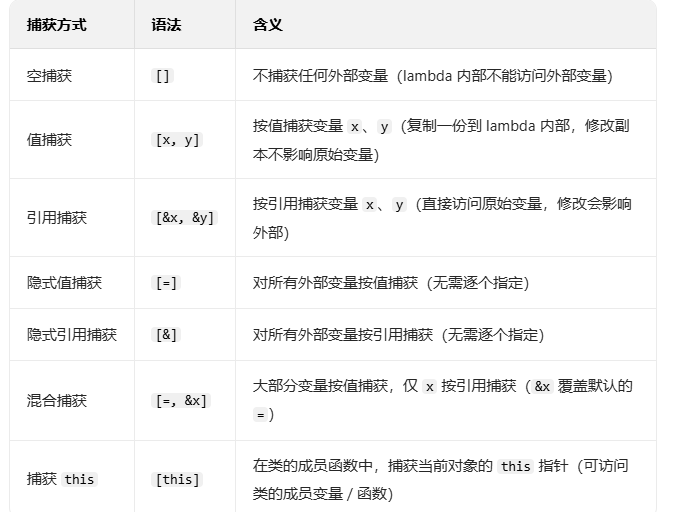
- 对于捕获列表的解释:mutable只对"值捕获"的副本能否被修改起作用,即使加了mutable,修改的也只是副本不影响原值,也就是说,只要不是引用捕获,修改的都是副本,包括获取this也是一样,修改的也是this的副本,但因为this是指向对象的指针,相应的对象的属性也可以通过this的副本被修改。
- 关于返回类型,一般匿名函数是自动推导返回类型,但也有特殊情况,需要显式指定:
// 第一种:显式指定返回类型为double(int可隐式转换为double)
auto func2 = [](bool flag) -> double {if (flag) return 1; // 1 → 1.0else return 2.5; // 保持double
};// 第二种:无return语句,默认返回void
auto print = [](int x) { cout << x << endl; };
auto print2 = [](int x) -> void { cout << x << endl; };
- 在 C++ 中,匿名函数(lambda 表达式)本质上是编译器自动生成的一个 “匿名类”(闭包类型)的实例(对象)。也就是说,lambda 表达式本身是一个 “对象”,而这个对象的类型是编译器为其创建的匿名类。每个 lambda 表达式会被编译器自动生成一个独一无二的匿名类(比如第一个 lambda 对应 “匿名类 1”,第二个对应 “匿名类 2”)。 验证代码如下:
#include <iostream>
#include <typeinfo>int main() {// 两个看似相同的lambda,类型不同auto lambda1 = []() {};auto lambda2 = []() {};// 输出lambda的类型名称(编译器生成的匿名类名)std::cout << typeid(lambda1).name() << std::endl; // class `int __cdecl main(void)'::`2'::<lambda_1>std::cout << typeid(lambda2).name() << std::endl; // class `int __cdecl main(void)'::`2'::<lambda_2>(与lambda1不同)// 验证类型是否相同(结果为false)std::cout << std::boolalpha<< (typeid(lambda1) == typeid(lambda2)) // 输出:false<< std::endl;return 0;
}
3、序列容器(Sequence Containers):
- 序列容器共有特征: 是一类用于存储 有次序 元素集合的容器;【这里的有序是指每个元素有先后顺序】
3.1、vector【动态数组】
- ★★★概述:在连续内存中存储元素的动态数组【元素的位置由插入顺序决定,而非元素的值】
- 内存结构示意:

3.1.1、数据结构特点
- 特点:连续内存存储,支持随机访问(通过索引快速访问元素)。尾部插入 / 删除效率高(O (1)),适合 / 扩容时可能需要移动大量元素(O (n))。需要频繁随机访问,且尾部操作较多的场景(如动态数组、缓存等)。
- 问题:在中间插入的时候,需要移动大量元素。
- vector中迭代器:begin()和end():指向第一个元素和最后一个元素
- 常用函数
#include <iostream>
#include <vector>
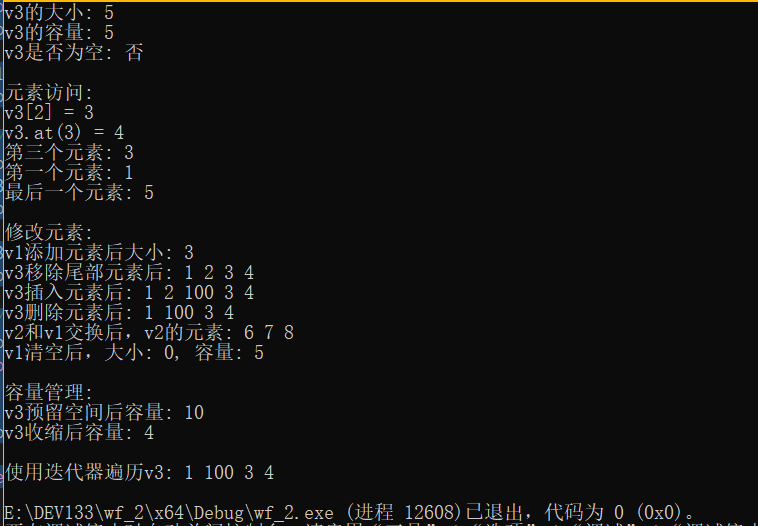
using namespace std;int main() {// 1. 构造函数:创建vector的几种方式vector<int> v1; // 空vectorvector<int> v2(5, 10); // 包含5个10的vectorvector<int> v3 = { 1, 2, 3, 4, 5 };// 初始化列表构造vector<int> v4(v3.begin(), v3.end()); // 用v3的迭代器范围构造// 2. 常用属性cout << "v3的大小: " << v3.size() << endl; // 元素数量cout << "v3的容量: " << v3.capacity() << endl; // 可容纳的元素数量(不重新分配内存)cout << "v3是否为空: " << (v3.empty() ? "是" : "否") << endl; // 是否为空// 3. 元素访问cout << "\n元素访问:" << endl;cout << "v3[2] = " << v3[2] << endl; // 下标访问(无越界检查)cout << "v3.at(3) = " << v3.at(3) << endl; // at方法(有越界检查,抛出异常)cout << "第三个元素: " << *(v3.begin()+2) << endl; // 第一个元素cout << "第一个元素: " << v3.front() << endl; // 第一个元素cout << "最后一个元素: " << v3.back() << endl; // 最后一个元素// 4. 修改元素的函数cout << "\n修改元素:" << endl;v1.push_back(6); // 尾部添加元素v1.push_back(7);v1.push_back(8);cout << "v1添加元素后大小: " << v1.size() << endl;v3.pop_back(); // 移除尾部元素cout << "v3移除尾部元素后: ";for (int num : v3) cout << num << " ";cout << endl;// 插入索引指向位置,其他元素后移v3.insert(v3.begin() + 2, 100); // 在索引2位置插入100cout << "v3插入元素后: ";for (int num : v3) cout << num << " ";cout << endl;v3.erase(v3.begin() + 1); // 移除索引1位置的元素cout << "v3删除元素后: ";for (int num : v3) cout << num << " ";cout << endl;v2.swap(v1); // 交换两个vector的内容cout << "v2和v1交换后,v2的元素: ";for (int num : v2) cout << num << " ";cout << endl;v1.clear(); // 清空所有元素(大小变为0,容量不变)cout << "v1清空后,大小: " << v1.size() << ", 容量: " << v1.capacity() << endl;// 5. 容量管理函数cout << "\n容量管理:" << endl;v3.reserve(10); // 预留至少能容纳10个元素的空间cout << "v3预留空间后容量: " << v3.capacity() << endl;v3.shrink_to_fit(); // 减少容量以匹配实际大小(C++11)cout << "v3收缩后容量: " << v3.capacity() << endl;// 6. 迭代器用法cout << "\n使用迭代器遍历v3: ";for (vector<int>::iterator it = v3.begin(); it != v3.end(); ++it) {cout << *it << " ";}cout << endl;return 0;
}
3.2、deque【双端队列】
- ★★★概述:通过段指针表(map)在内存中是分段(block)存储元素的双端(头尾均可插删)队列【普通队列只能尾部插入,头部删除(FIFO),双端的含义就是可以头和尾都可以插入和删除】
- 内存结构示意:
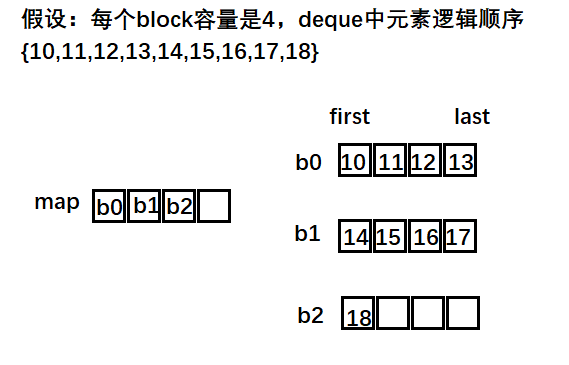
3.2.1、数据结构特点
- 特点:在内存中是分段(block)存储的,段指针在中央数组 (map) 中,可以高效的在头部和尾部插入和删除(O (1)),解决了 vector 头部插入时需要移动所有元素的问题。同时由于map的存在,deque也支持随机访问(O (1))。
- deque中迭代器:begin()和end():指向第一个元素和最后一个元素
- 常用函数
#include <iostream>
#include <deque>
#include <algorithm> // 用于sort等算法
using namespace std;int main() {// 1. 构造函数:创建deque的几种方式deque<int> dq1; // 空dequedeque<int> dq2(3, 100); // 包含3个100的dequedeque<int> dq3 = { 10, 20, 30, 40 }; // 初始化列表构造deque<int> dq4(dq3.begin(), dq3.end()); // 用dq3的迭代器范围构造// 2. 常用属性:size、empty、deque不能获取capacity// 3. 元素访问:dq3[1]、dq3.at(2)、dq3.front() 、dq3.back()// // 4. 双端插入和删除(deque的核心优势)cout << "\n双端操作:" << endl;dq1.push_back(1); // 尾部插入dq1.push_back(2);dq1.push_front(0); // 头部插入(deque特有高效操作)cout << "dq1元素: ";for (int num : dq1) cout << num << " "; cout << endl;dq1.pop_back(); // 尾部删除dq1.pop_front(); // 头部删除(deque特有高效操作)cout << "dq1操作后元素: ";for (int num : dq1) cout << num << " "; cout << endl;// 5. 中间插入和删除: dq3.insert(dq3.begin() + 2, 25)、dq3.erase(dq3.begin() + 1)// 6. 其他修改操作:dq2.swap(dq1)、dq3.clear()// 7. 迭代器: for (auto e : dq5) cout << e << " ";
}
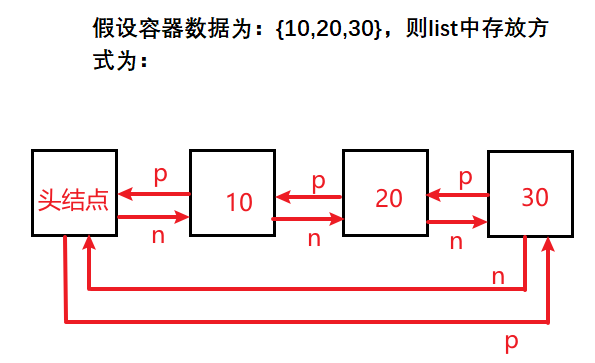
3.3、list【双向链表】
- ★★★概述:在内存中随机存储有序元素的循环双向链表。
- 内存结构示意:内存中各个元素都是随机位置,通过p指针和n指针连接起来。
3.3.1、数据结构特点
- 特点:双向环形链表,就像散落堆中的珠子 + 两根线串成环。节点离散,指针导航,只擅长两头增删,不支持随机访问。
- 如果是头插和尾插,有了deque就可以,随机查找vector和deque都可以,那么要list有什么用?【如果涉及占用内存较多的 大对象 的插入,用vector或者deque都需要拷贝和移动,而list这时候的优势就显现了,它只改变两个指针指向,0拷贝和0移动】
- 常用函数
#include <iostream>
#include <list>
#include <algorithm> // 用于find等算法
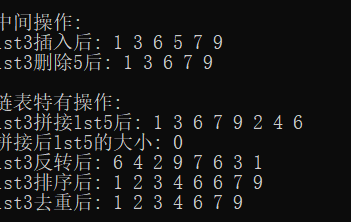
using namespace std;int main() {// 1. 构造函数:创建list的几种方式list<int> lst1; // 空listlist<int> lst2(4, 20); // 包含4个20的listlist<int> lst3 = { 1, 3, 5, 7, 9 }; // 初始化列表构造list<int> lst4(lst3.begin(), lst3.end()); // 用lst3的迭代器范围构造// 2. 常用属性:size()、max_size()、empty()// 3. 元素访问:list不支持随机访问,无[]和at()、front()、back()// 4. 两端插入和删除:push_back()、push_front()、pop_back()、pop_front()// 5. 中间插入和删除(list的核心优势):cout << "\n中间操作:" << endl;// 在第2个元素后插入新元素auto it = lst3.begin();advance(it, 2); // 移动迭代器到第3个元素(索引2)lst3.insert(it, 6); // 插入操作(O(1)时间复杂度)cout << "lst3插入后: ";for (int num : lst3) cout << num << " "; cout << endl;// 特殊迭代器操作:auto it = lst3.begin();lst3.insert(std::next(it,1), 20);lst3.insert(std::prev(it,1), 20);// 删除指定值的元素lst3.remove(5); // 直接删除所有值为5的元素cout << "lst3删除5后: ";for (int num : lst3) cout << num << " "; cout << endl;// 删除迭代器指向的元素:lst3.erase((lst3.begin()+1)); // 6. 链表特有操作cout << "\n链表特有操作:" << endl;list<int> lst5 = { 2, 4, 6 };lst3.splice(lst3.end(), lst5); // 将lst5的所有元素移动到lst3末尾cout << "lst3拼接lst5后: ";for (int num : lst3) cout << num << " "; cout << endl;cout << "拼接后lst5的大小: " << lst5.size() << endl; // 输出: 0(元素已移动)lst3.reverse(); // 反转链表cout << "lst3反转后: ";for (int num : lst3) cout << num << " ";cout << endl;lst3.sort(); // 链表自带排序(不能用std::sort,因为list迭代器不是随机访问)cout << "lst3排序后: ";for (int num : lst3) cout << num << " "; cout << endl;lst3.unique(); // 删除连续重复元素cout << "lst3去重后: ";for (int num : lst3) cout << num << " "; cout << endl;// 7. 其他操作:swap(lst2)、clear()return 0;
}
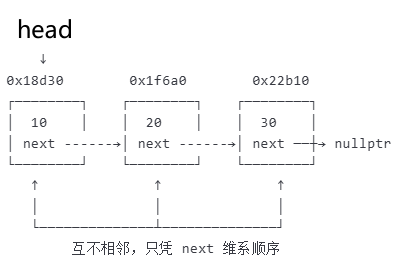
3.4、forward_list【单向链表】
- ★★★概述:在堆上随机存储的单向链表。
- 内存结构示意:一条散落在堆上的单向节点链,每个节点单独 malloc,地址随机,只留一个 next 指针指向下一家。
3.4.1、数据结构特点
- 特点:它是 最省内存的链表,适合“前向一路插到底”的轻量任务。forward_list 的优势在于任意位置的插入 / 删除操作效率为 O (1)(只需修改指针指向,无需移动元素),尤其是头部操作(push_front、pop_front)非常高效,不支持随机访问。
- 常用函数及常用算法
#include <iostream>
#include <forward_list>
#include <algorithm> // 用于find等算法
using namespace std;// 打印forward_list内容的辅助函数
void printFL(const forward_list<int>& fl, const string& name) {cout << name << ": ";for (int num : fl) {cout << num << " ";}cout << endl;
}int main() {// 1. 构造函数:创建forward_list的几种方式forward_list<int> fl1; // 空单向链表forward_list<int> fl2(3, 5); // 包含3个5的单向链表forward_list<int> fl3 = { 1, 2, 3, 4 }; // 初始化列表构造forward_list<int> fl4(fl3.begin(), fl3.end()); // 用fl3的迭代器范围构造// 2. 常用属性:empty()cout << "fl3是否为空: " << (fl3.empty() ? "是" : "否") << endl;cout << "fl3的最大容量: " << fl3.max_size() << endl; // 理论最大元素数// 注意:forward_list没有size()函数,需通过遍历获取长度// 3. 元素访问:仅支持访问第一个元素front()、不支持back()和随机访问(无[]、at())、// 4. 头部操作(核心基础操作):push_front()、pop_front()// 5. 后插(需通过迭代器指定插入位置的前一个元素)cout << "\n中间插入:" << endl;// 在第2个元素(值为2)前插入100auto it = fl3.begin();advance(it, 1); // 移动到值为2的元素(插入点的前一个元素)it++;fl3.insert_after(it, 100); // 在it之后插入100printFL(fl3, "fl3插入100后"); // 插入多个元素fl3.insert_after(fl3.begin(), { 5, 6 }); // 在第一个元素后插入5、6printFL(fl3, "fl3插入5、6后"); // 6. 查找后删(需指定删除位置的前一个元素)cout << "\n中间删除:" << endl;// 删除值为6的元素(先找到其前一个元素it)it = find(fl3.begin(), fl3.end(), 5); // it指向5fl3.erase_after(it); // 删除it之后的元素(6)printFL(fl3, "fl3删除6后"); // 删除范围内的元素([first, last)之后的元素)auto first = fl3.begin();auto last = fl3.begin();advance(first, 2); advance(last, 3); // last += 3 错误fl3.erase_after(first, last); // 删除first之后、last之前的元素(100)printFL(fl3, "fl3删除100后"); // 1 5 2 3 4// 7. 单向链表特有操作cout << "\n特有操作:" << endl;forward_list<int> fl5 = { 10, 20, 30 };// 拼接:将fl5的所有元素移到fl3开头fl3.splice_after(fl3.before_begin(), fl5); // before_begin()返回首元素前的位置printFL(fl3, "fl3拼接fl5后"); // 10 20 30 1 5 2 3 4printFL(fl5, "fl5拼接后(已空)"); // 空// 移除指定值的元素fl3.remove(5); // 删除所有值为5的元素printFL(fl3, "fl3移除5后"); // 10 20 30 1 2 3 4// 反转链表fl3.reverse();printFL(fl3, "fl3反转后"); // 4 3 2 1 30 20 10// 8. 其他操作:sort()(自带sort,不支持std::sort)、swap()、clear()return 0;
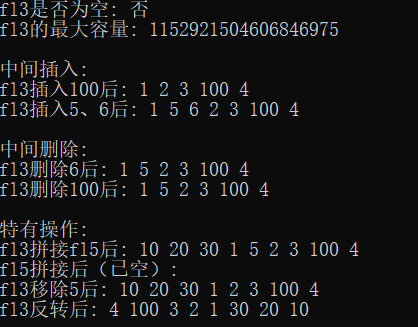
}
3.5、array【静态数组】
- ★★★概述:给 C 数组 套了层 STL 接口的静态数组;
- 就是一块纯粹的 C 数组,元素在内存里排排坐,没有头信息、没有指针、没有开销。

3.5.1、数据结构特点
- 特点:std::array 就是 给 C 数组 套了层 STL 接口的零开销壳,内存里 除了元素本身,什么也没有。元素个数在编译期就确定,且生命周期内不会改变,可以不选择vector,用array。
- 常用函数及常用算法
#include <iostream>
#include <array>
#include <algorithm> // 用于sort等算法
using namespace std;int main() {// 1. 构造函数:创建array(大小必须在编译期确定)array<int, 5> arr1; // 大小为5的int数组(未初始化)array<int, 5> arr2 = { 1, 2, 3, 4, 5 };// 初始化列表构造(可省略部分元素,剩余补0)array<int, 5> arr3(arr2); // 拷贝构造array<int, 5> arr4 = arr2; // 赋值构造// 2. 核心属性:size()、max_size() 、empty()// 3. 元素访问(支持多种方式,与原生数组类似):arr2[2]、at(3)、front()、back()// 4. 元素修改:swap()cout << "\n元素修改:" << endl;arr1.fill(0); // 用0填充所有元素cout << "arr1填充后: ";for (int num : arr1) cout << num << " "; // 0 0 0 0 0cout << endl;// 5. 迭代器与算法支持:begin()、end()、// 6. 反向迭代器:rbegin()、rend()return 0;
}4、关联容器(Associative Containers):
- 关联容器共有特征:这类容器的元素按照键的比较规则(默认升序)有序存储,底层通常采用红黑树实现,查找效率为 O (log n)。
- 与序列式容器对比:序列式容器侧重按照顺序存储元素,关联式容器侧重按“键值”高效查找、匹配元素。
4.1、ADD_红黑树(自平衡二叉搜索树):
- 特点:
- 每个节点不是红色就是黑色
- 根节点必须是黑色
- 红色节点的两个子节点必须是黑色(不能有两个红节点相连)
- 从任意节点到它所有后代叶子节点的路径中,黑色节点的数量都相同
- 叶子节点(空节点)都是黑色
- 这些规则就像书架的 “整理规范”,当插入或删除节点打破这些规则时,红黑树会自动通过两种操作来修复:
- “旋转”:就像把书架某一层整体转一下,调整节点位置
- “变色”:改变节点的红黑颜色,类似给书本贴不同颜色的标签
- 这样做的好处是,无论数据怎么变化,树的高度都不会太大(大致保持在 log₂n 左右),保证了各种操作的效率都比较高(时间复杂度为 O (log n))。
- 红黑树在很多地方都有应用,它就像一个聪明的管理员,总能让数据保持有序且容易查找的状态。
4.2、set【红黑树(自平衡二叉搜索树)】
- ★★★概述:“有大小关系的键的集合”【键本身不能重复】
- 内存结构:红黑树
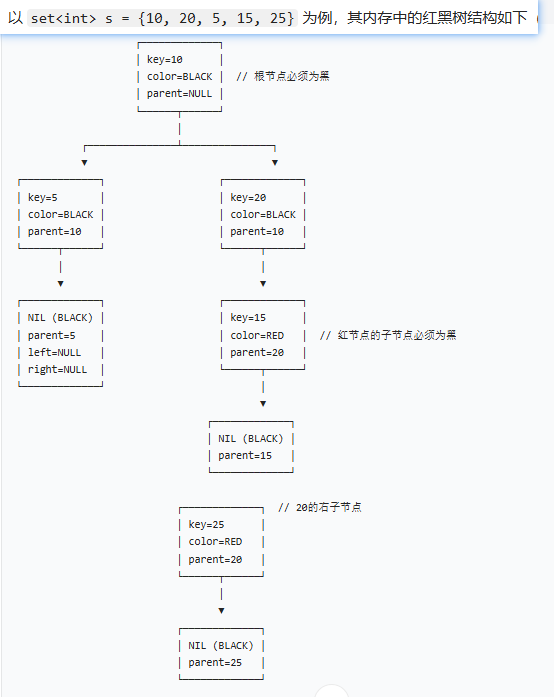
4.2.1、数据结构特点
- 特点:自动排序、不允许重复元素。 因为 set 中的元素是有序的,直接修改会破坏排序规则,所以 set 的元素默认是 “常量”,不能直接修改。 如果需要改某个元素,只能先删除旧的,再插入新的。
- 键在set中的作用:在 set 中,“键(key)” 其实就是容器中存储的元素本身,而 “键的比较规则” 就是用来决定元素排列顺序的依据。set 存储的每个元素都同时扮演两个角色 —— 既是 “存储的数据”,也是用来排序的 “键”。
- 常用函数及常用算法:
#include <iostream>
#include <set>
#include <string>using namespace std;int main() {// 1. 创建set(默认升序排序)set<int> s;// 2. 插入元素 (insert)s.insert(30);s.insert(10);s.insert(20);s.insert(20); // 插入重复元素,会被自动忽略s.insert(40);cout << "set中的元素(自动排序且去重):";for (auto num : s) {cout << num << " "; // 输出:10 20 30 40}cout << endl;// 3. 重要属性:大小和空判断:size()、empty()// 4. 查找元素 (find)【键的作用】int target = 20;auto it = s.find(target);if (it != s.end()) {cout << "找到元素:" << *it << endl; // 输出:找到元素:20}else {cout << "未找到元素:" << target << endl;}// 5. 计数元素 (count) - 对于set只能是0或1cout << "元素20的个数:" << s.count(20) << endl; // 输出:1cout << "元素50的个数:" << s.count(50) << endl; // 输出:0// 6. 删除元素 (erase)// 6.1 按值删除s.erase(30);// 6.2 按迭代器删除it = s.find(20);if (it != s.end()) {s.erase(it);}// 7. 范围查询(lower_bound/upper_bound)s.insert(20);s.insert(30);s.insert(50);// lower_bound(x):返回第一个 >= x 的元素迭代器auto lower = s.lower_bound(25);// upper_bound(x):返回第一个 > x 的元素迭代器auto upper = s.upper_bound(35);cout << "大于等于25且小于等于35的元素:";for (auto i = lower; i != upper; ++i) {cout << *i << " "; }cout << endl;// 8. 清空容器 :clear()// 9. 自定义排序规则(降序)set<int, greater<int>> s_desc; // 使用greater<int>作为比较器s_desc.insert(30);s_desc.insert(10);s_desc.insert(20);cout << "降序set中的元素:";for (auto num : s_desc) {cout << num << " ";}cout << endl;// 10. 字符串set(默认按字典序排序)set<string> s_str;s_str.insert("banana");s_str.insert("apple");s_str.insert("cherry");cout << "字符串set中的元素:";for (auto str : s_str) {cout << str << " "; // 输出:apple banana cherry}cout << endl;return 0;
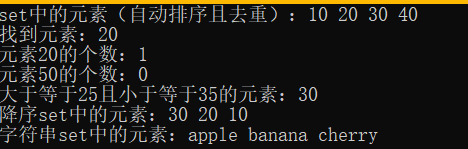
}
4.3、multiset【红黑树(自平衡二叉搜索树)】
- ★★★概述:
- 内存结构:红黑树
4.3.1、数据结构特点
- 特点:multiset 继承了 set 的所有排序和高效操作特性,自动排序、允许重复元素。
- 常用函数及常用算法:
- count() 函数:multiset 中 count(val) 可能返回大于 1 的数(表示该值出现的次数),而 set 中只能是 0 或 1。
- erase() 函数:multiset 用 erase(val) 会删除所有等于 val 的元素;若只想删一个,需要用迭代器指定位置。
4.4、map【红黑树(自平衡二叉搜索树)】
- ★★★概述:
- 内存结构:红黑树
4.4.1、STL容器_pair
- 在C++ STL中,std::pair 是一个 模板类 ,用于将两个值组合成一个单一对象,通常用于表示键值对或关联数据。它是STL中许多容器(如std::map、std::unordered_map)和算法的基础组件之一。
- std::pair 是一个模板类,接受两个类型参数 T1 和 T2,分别表示第一个和第二个元素的类型:
template<typename T1, typename T2>
struct pair {T1 first; // 第一个元素T2 second; // 第二个元素
};
- 使用pair
std::pair<int, int> p1(1, 2);
cout << p1.first << p1.second // 12
4.4.2、数据结构特点
- 特点:可以把 map 理解成一本 “字典”,“键(key)” 就像字典中的 “单词”,是查找的依据,且不能重复,“值(value)” 就像单词对应的 “解释”,是与键关联的数据,整个字典会按 “单词” 的顺序(默认升序)自动排列。【天生统计圣体】
- 适用场景:存放统计信息。
- 常用函数及常用算法:
#include <iostream>
#include <map>
#include <string>using namespace std;int main() {// 1. 创建map(键为string类型,值为int类型,默认按键升序)map<string, int> dict;// 2. 插入键值对(三种方式)dict["apple"] = 10; // 方式1:直接赋值dict.insert(pair<string, int>("banana", 20)); // 方式2:用pair插入dict.insert({ "cherry", 30 }); // 方式3:用初始化列表(C++11) 【√】// 插入重复键(会覆盖原有值)dict["apple"] = 15; // "apple"的原值10被覆盖为15// 3. 遍历map(按键的字典序排列)cout << "map中的键值对:" << endl;for (auto& pair : dict) {// first是键,second是值cout << pair.first << " : " << pair.second << endl;}// 输出顺序:apple : 15 → banana : 20 → cherry : 30(按字典序)// 4. 查找元素(通过键查找)string key = "banana";auto it = dict.find(key);if (it != dict.end()) {cout << "\n找到 " << key << ",值为:" << it->second << endl;}else {cout << "\n未找到 " << key << endl;}// 5. 访问元素(两种方式):dict["apple"]、dict.at("cherry")// 6. 常用属性:size()、empty()// 7. 删除元素(按键删除):erase("banana")// 8. 自定义排序(按键降序)map<string, int, greater<string>> dict_desc; // 指定greater排序dict_desc["apple"] = 10;dict_desc["banana"] = 20;dict_desc["cherry"] = 30;cout << "\n降序map中的键值对:" << endl;for (auto& pair : dict_desc) {cout << pair.first << " : " << pair.second << endl;}// 输出顺序:cherry → banana → apple(按字典序降序)// 9. 清空map:clear()return 0;
}
4.5、multimap【红黑树(自平衡二叉搜索树)】
- ★★★概述:
- 内存结构:红黑树
4.5.1、数据结构特点
- 特点:multimap 中可以有多个相同的键,每个键可对应不同的值;而 map 的键是唯一的。没有 [] 运算符:multimap 不能用 [] 访问或插入元素(因为同一个键可能对应多个值,无法确定操作哪个)。
- 使用场景:需要一对多的映射关系(比如一个姓名对应多个联系方式)。
- 常用函数及常用算法:
#include <iostream>
#include <map>
#include <string>using namespace std;int main() {// 1. 创建multimap(键为string,值为int,默认按键升序)multimap<string, int> mmap;// 2. 插入键值对(只能用insert,没有[]运算符)mmap.insert({ "apple", 10 }); // 插入"apple"→10mmap.insert({ "banana", 20 });mmap.insert({ "apple", 15 }); // 插入重复键"apple"→15mmap.insert({ "apple", 5 }); // 再插入"apple"→5mmap.insert({ "cherry", 30 });// 3. 遍历(按键排序,相同键的元素连续排列)cout << "multimap中的键值对:" << endl;for (auto& pair : mmap) {cout << pair.first << " : " << pair.second << endl;}// 输出顺序:// apple : 10// apple : 15// apple : 5 (相同键的顺序与插入顺序一致)// banana : 20// cherry : 30// 4. 统计键出现的次数string key = "apple";cout << "\n键\"" << key << "\"出现的次数:" << mmap.count(key) << endl; // 输出:3// 5. 查找键对应的所有值(用equal_range)cout << "\n键\"" << key << "\"对应的所有值:";// equal_range返回一个pair,包含两个迭代器:// first:第一个匹配键的位置// second:最后一个匹配键的下一个位置auto range = mmap.equal_range(key);for (auto it = range.first; it != range.second; ++it) {cout << it->second << " "; // 输出:10 15 5}cout << endl;// 6. 按迭代器删除单个元素(删除第一个"apple")auto it = mmap.find("apple"); // find返回第一个匹配键的迭代器if (it != mmap.end()) {mmap.erase(it); // erase按照迭代器删除}cout << "\n删除第一个\"apple\"后,剩余值:";range = mmap.equal_range(key);for (auto i = range.first; i != range.second; ++i) {cout << i->second << " "; // 输出:15 5}cout << endl;cout << "查找不存在的键:" << (mmap.find("monkey"))->second << endl;// 7. 按键删除所有匹配元素(删除所有"apple")mmap.erase(key); // erase按照键删除cout << "\n删除所有\"apple\"后,剩余键值对:" << endl;for (auto& pair : mmap) {cout << pair.first << " : " << pair.second << endl;}// 输出:// banana : 20// cherry : 30// 8. 常用属性:size()、empty()// 9. 清空容器:clear()return 0;
}
5、无序关联容器(Unordered Associative Containers,C++11 新增):【无大小关系】
- 无序关联容器基于哈希表实现,元素的存储顺序与关键字无关,通过哈希函数快速定位元素,提供平均 O (1) 的高效操作。 远快于有序容器的 O (log n)。这是因为哈希表通过哈希函数直接定位元素位置,无需像红黑树那样维护树结构和排序。
5.1、简介:
- STL 中的无序关联容器(如 unordered_set、unordered_map 及其对应的 unordered_multiset、unordered_multimap),核心作用是在不要求元素有序的场景下,提供更快的插入、删除和查找操作。
6、补充:容器_适配器(基于一般容器,扩充的容器)
- 容器适配器底层选择的依据是为了实现它们自身特点的同时,要操作高效,内存占比小;
- stack(栈): 后进先出,栈顶进,栈顶删(尾插、尾删)【底层:vector或deque或list】
- queue(队列):先进先出,队尾进,队首出(头删、尾插)【底层:deque或list】
- priority_queue(优先队列):每次出队的元素都是 “优先级最高” 的(默认是最大元素),本质是一个堆结构。(插入后调整,要求随机访问能力)【底层:vector或deque】
总结:
6.1、如何记忆每一种容器的函数操作?
- 方法:STL中容器很多,这些容器有哪些函数这记起来很多,但对于学习最有效的一点,就是记住这些容器的特征,依据特征分析,这些容器有哪些操作就一目了然了。
6.1.1、序列容器:【有次序】
- vector,它的别名是动态数组,是在连续内存中存储元素的动态数组;
- 1、构造vector:可以构造空的vector、可以通过“初始化列表”构造、可以传入另一vector容器的begin()和end()拷贝构造;
- 2、常用属性:size()、capacity()、empty();
- 3、元素访问的方式:v[下标]、v.at(下标)、*(v.begin()+2)、v.front()、v.back();
- 4、元素修改:v[下标]赋值修改、尾插(push_back)、尾删(pop_back)、v.insert(迭代器, 值)在迭代器位置插入、v.erase(迭代器)在迭代器位置删除、v1.swap(v2)交换两个容器的值、clear()清空容器;
- deque,它的别名是双端队列,通过段指针表(map)在内存中是分段(block)存储元素的双端(头尾均可插删)队列;
- 1、构造deque:与vector一致;
- 2、常用属性:size()、empty()、不能获取capacity因为capacity是给连续内存的数据结构设计的属性;
- 3、元素访问的方式:与vector一致;
- 4、元素修改:除了与vector一致外,还多了push_front()和pop_front(),这也是双端的含义所在;
- list,它的别名是双向链表,在内存中随机存储元素的循环双向链表
- 1、构造list:与vector一致;
- 2、常用属性:size()、empty()、不能获取capacity;
- 3、元素访问的方式:front()、back(),每个元素都不连续,不支持随机访问,由于其特殊内存,迭代器特殊的移动方式:std::next(it, 2)向后移动2个位置,std::prev(it, 3)向前移动3个位置;
- 4、元素修改:insert()、clear()、erase()、头删、头插、尾删、尾插;
- 5、list特有操作:remove(val)删除所有val元素、reverse()反转链表、sort()链表自带排序、splice()链表拼接,被拼接的链表变为空、unique()删除链表中重复元素;
- forward_list,它的别名是单向链表,它是在堆上随机存储的单向链表。
- 1、构造list:与vector一致;
- 2、常用属性:empty()、不能获取capacity、没有设计size();
- 3、元素访问的方式:front()、每个元素都不连续,不支持随机访问,由于其特殊内存,迭代器特殊的移动方式:std::next(it, 2)向后移动2个位置;
- 4、元素修改:clear()、头删、头插;
- 5、特有操作:insert_after、erase_after()后删、splice_after后连接同类型容器、remove(val)删除所有val元素、sort()、unique()、reverse();
- array,它的别名是静态数组,它是给 C 数组 套了层 STL 接口的静态数组
- 1、构造list:array<int,6> h{ 1,2,3,4 };需要在类型列表中给出大小;
- 2、常用属性:size()、max_size()、empty();
- 3、元素访问的方式:h[下标]、at(下标)、front()、back();
- 4、元素修改:a1.swap(a2);
- 5、特有操作:fill();
6.1.2、关联容器:【有大小关系】
- set:有序不重复的集合
- 1、一般是创建空集合,然后逐个插入键值;
- 2、一般用于创建“有序不重复集合”
- multiset:别名是键值可重复的有序集合
- 1、同set,只不过可以重复
- map:有序且键值不重复的字典
- 1、一般是创建空字典,然后逐个插入键和值;
- 2、一般用于创建“有序且键值不重复的字典”
- multiset:键值可重复的有序字典
- 1、同map,只不过可以重复