每天五分钟深度学习:基于训练集、验证集、测试集迭代模型
本文重点
当我们训练神经网络时,我们需要做出很多决策,例如:神经网络分多少层;每层含有多少个隐藏单元;学习速率是多少;各层采用哪些激活函数等等。我们在搭建神经网络的时候,很难确定这些应该如何设置,那么我们实际中应该怎么做呢?
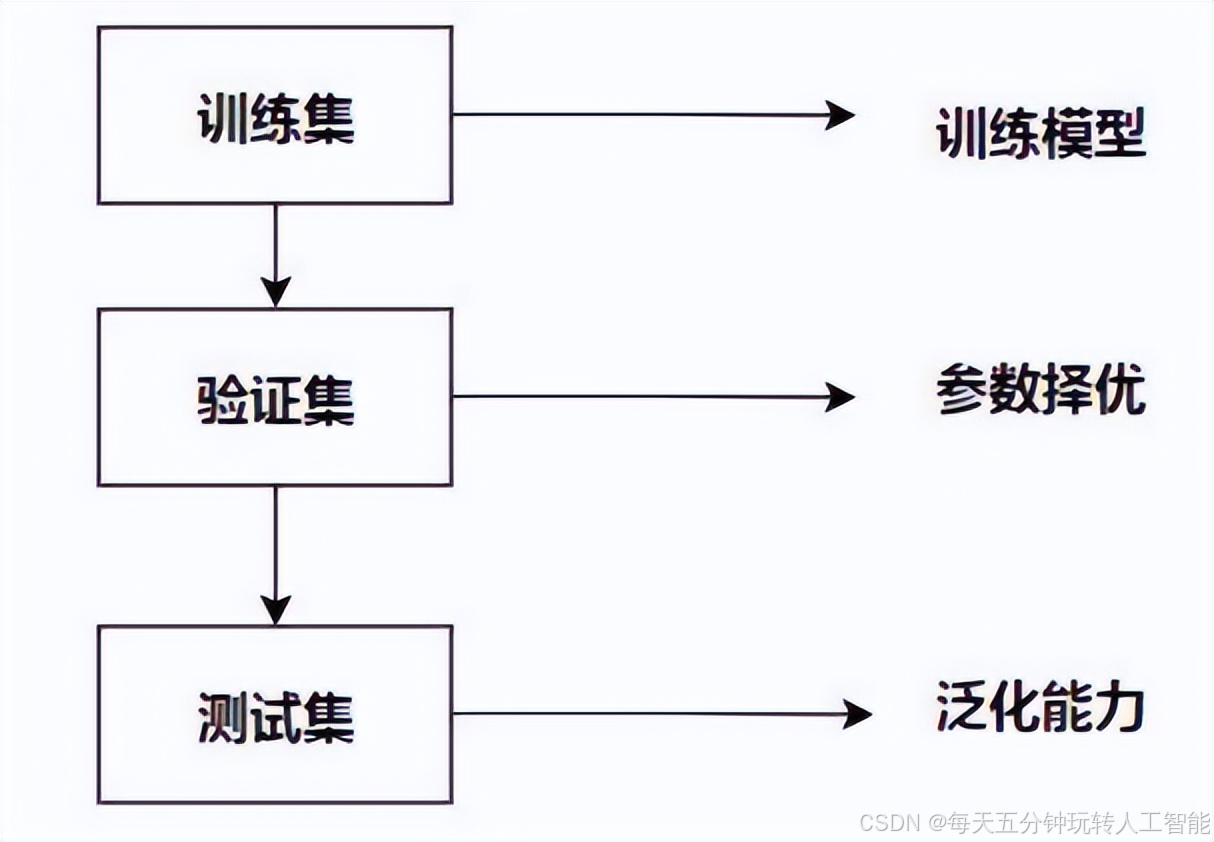
为什么要分割数据集
我们可以先大概计划一下,设置一个初步的模型参数,比如构建一个含有特定层数,隐藏单元数量或数据集个数等等的神经网络,然后运行这些代码,通过运行得到结果,然后根据得到的结果,修改我们的模型的参数,然后继续运行,不断修改,最终达到我们满意的结果。
因此每一次循环的效率是决定项目进展速度的一个关键因素,而创建高质量的训练数据集,验证集和测试集也有助于提高循环效率。那么当我们有一个训练集的时候,那么我们应该如何划分训练数据,验证集数据和测试集数据呢?
数据的划分
我们常常将数据分为70%验证集,30%测试集。当然也可以按照 60%训练,20%验证和 20%测试集来划分。当我们数据比较少的时候,如果只有 100 条,1000 条或者 1 万条数据,那么上述比例划分是非常合理的。
但是在大数据时代,我们现在的数据量可能是百万级别,假设我们有 100 万条数据,其中 1 万条作为验证集, 1 万条作为测试集,100 万里取 1 万,比例是 1%,即:训练集占 98%,验证集和测试集各占 1%。对于数据量过百万的应