DecDEC论文精读:动态误差补偿的低比特LLM推理优化方案
DecDEC论文精读:动态误差补偿的低比特LLM推理优化方案
DecDEC: A Systems Approach to Advancing Low-Bit LLM Quantization Yeonhong Park* Jake Hyun* Hojoon Kim Jae W. Lee
Seoul National University
- 研究背景与核心问题
大型语言模型(LLM)的部署面临内存和延迟挑战,量化技术通过降低精度缓解这一问题,但低比特量化(如3-bit/4-bit)会导致明显的模型质量下降。本文提出DecDEC(Decoding with Dynamic Error Compensation),一种在保持量化优势(GPU内存节省、延迟降低)的同时,通过CPU内存动态补偿量化误差的推理方案。
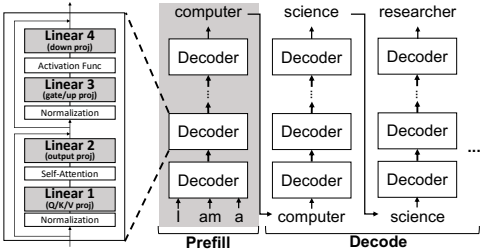
- 核心机制设计
2.1 基本架构
DecDEC在CPU中存储残差矩阵(全精度权重与量化权重的差值),在解码阶段动态获取与显著通道(由激活异常值标记)对应的残差,补偿这些通道的量化误差。显著通道通过每步分析输入激活动态识别,适应激活分布的动态特性。

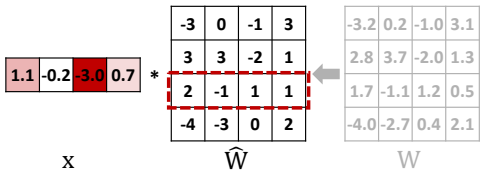
2.2 残差量化与传输优化
• 残差量化:采用4-bit对称均匀量化,每输出通道仅需一个缩放因子作为元数据:
Q_{r, i}®=\operatorname{clip}\left(\operatorname{round_to_int}\left(\frac{r}{S_i}\right),-7, 7\right)
• 零拷贝传输:使用CUDA零拷贝而非DMA传输,减少小块数据传输开销
• 动态通道选择:基于输入激活幅度的近似Top-K算法,分块处理降低同步开销
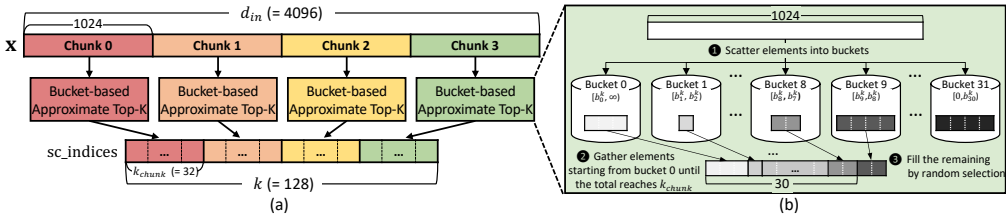
- 关键技术实现
3.1 近似Top-K算法
• 分块处理:将输入向量分块(如1024维),每块内独立选择Top-kₕₐₙₖ
• 桶排序优化:使用32个桶进行分布排序,避免全局同步
• 动态边界调整:通过校准集分析激活值分布,设置优化桶边界
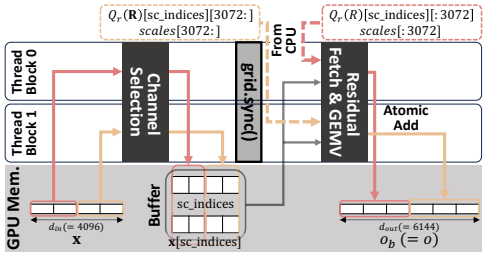
3.2 内核融合优化
将所有动态误差补偿操作融合到单个内核中:
• 线程块处理分段选择通道
• 网格级同步确保全局索引一致性
• 原子操作直接累加残差GEMV结果到基础输出
- 参数调优系统
4.1 调优必要性
两个关键参数需要精细调优:
• nₜᵦ:动态误差补偿使用的线程块数量
• kₕₐₙₖ:每块补偿的通道数
调优挑战来自巨大的设计空间和平台特性差异。
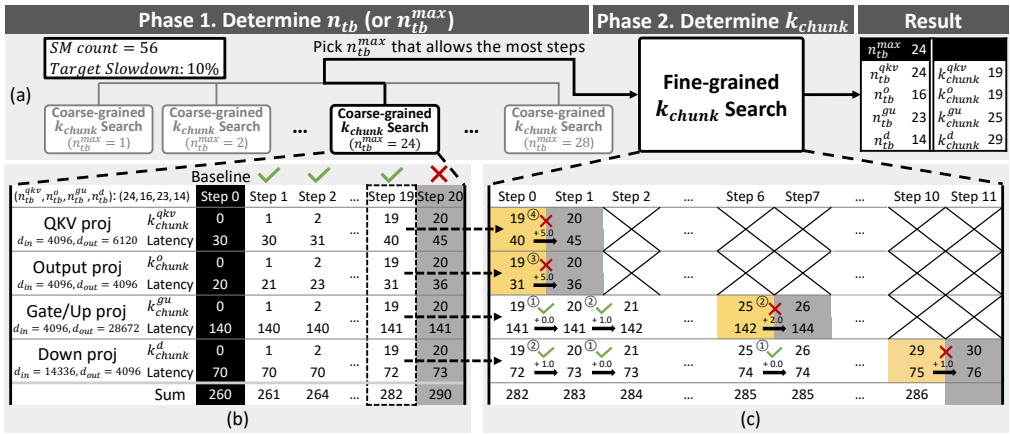
4.2 两阶段调优流程
- Phase 1 - nₜᵦ确定:通过元参数nₘₐₓ简化搜索空间
- Phase 2 - kₕₐₙₖ确定:细粒度搜索,优先增加对延迟影响小的层
- 实验评估与结果
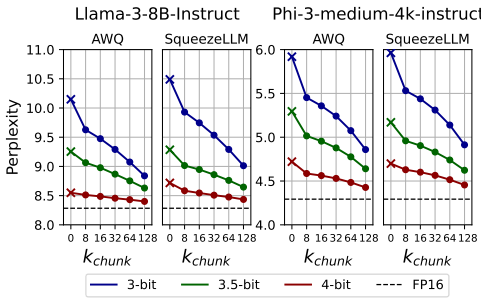
5.1 质量提升效果
在多个模型和量化方法上验证:
• 3-bit Llama-3-8B:困惑度从10.15降至9.12,优于3.5-bit版本
• 多基准测试:在WikiText、BBH、MT-Bench上均显示显著提升
• 残差位宽:4-bit残差在效果和传输效率间达到最佳平衡
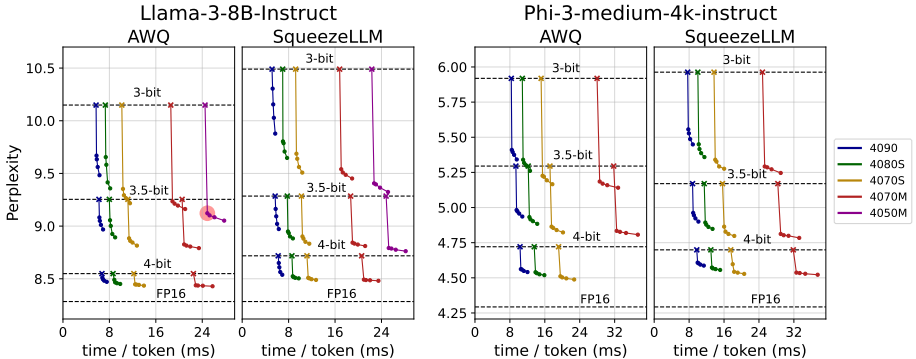
5.2 延迟开销分析
• 极低GPU内存增加:仅增加0.0003% GPU内存使用
• 最小延迟影响:在RTX 4050 Mobile上仅1.7%推理减速
• 多平台适配:在桌面和笔记本GPU上均表现良好
- 系统贡献与创新点
动态误差补偿:首次实现基于运行时激活分析的动态量化误差补偿
跨内存层次优化:有效利用CPU-GPU异构内存架构
实用调优系统:提供面向延迟目标的自动参数配置方案
广泛平台支持:覆盖从移动端到服务器的多种GPU平台
- 应用前景与局限性
优势领域
• 边缘设备部署:在严格内存约束下提升模型质量
• 实时应用场景:低延迟要求的对话和生成任务
• 多精度需求:支持同一模型在不同精度需求下的灵活部署
当前局限
• 服务器级GPU收益受限:因L1瓶颈而非DRAM瓶颈
• 批量处理场景:当前针对单批处理优化,批量处理需进一步优化
- 结论
DecDEC通过创新的动态误差补偿机制,在几乎不增加GPU内存和延迟开销的前提下,显著提升了低比特量化LLM的模型质量。该系统为解决量化与模型质量的权衡问题提供了实用化的系统级解决方案,为LLM在资源受限环境中的部署开辟了新途径。