RocketMQ-生产常见问题汇总
生产者端
RocketMQ一行代码造成大量消息丢失
由于项目组并没有对消息发送失败做任何补偿,因为Broker端的发送快速失败机制(TIMEOUT_CLEAN_QUEUE),导致丢失消息发送失败,故需要对这个问题进行深层次的探讨,并加以解决
RocketMQ 消息发送高可用设计一个非常关键的点,重试机制,其实现是在 for 循环中使用 try catch 将 sendKernelImpl 方法包裹,就可以保证该方法抛出异常后能继续重试。从上文可知,如果 SYSTEM_BUSY 会抛出 MQBrokerException,但发现只有上述几个错误码才会重试,因为如果不是上述错误码,会继续向外抛出异常,此时 for 循环会被中断,即不会重试。
这里非常令人意外的是连 SYSTEM_ERROR 都会重试,却没有包含 SYSTEM_BUSY,显然违背了快速失败的设计初衷,故笔者断定,这是 RocketMQ 的一个BUG,将 SYSTEM_BUSY 遗漏了,后续会提一个 PR,增加一行代码,将 SYSTEM_BUSY 加上即可
RocketMQ 一行代码造成大量消息丢失
消息发送失败常见错误与解决方案
RocketMQ消息发送常见错误与解决方案
Broker端
RocketMQ生产环境主题扩分片后遇到的坑
问题复盘
潜在原因:DefaultCluster 集群进行过一次集群扩容,从原来的一台消息服务器( broker-a )额外增加一台broker服务器( broker-b ),但扩容的时候并没有把原先的存在于 broker-a 上的主题、消费组扩容到 broker-b 服务器。
触发原因:接到项目组的扩容需求,将集群队列数从4个扩容到8个,这样该topic就在集群的a、b都会存在8个队列,但Broker不允许自动创建消费组(订阅关系),消费者无法从broker-b上队列上拉取消息,导致在broker-b队列上的消息堆积,无法被消费。
解决办法:运维通过命令,在broker-b上创建对应的订阅消息,问题解决。
经验教训:集群扩容时,需要同步在集群上的topic.json、subscriptionGroup.json文件。
RocketMQ 理论基础,消费者向 Broker 发起消息拉取请求时,如果broker上并没有存在该消费组的订阅消息时,如果不允许自动创建(autoCreateSubscriptionGroup 设置为 false),默认为true,则不会返回消息给客户端,其代码如下:
RocketMQ生产环境主题扩分片后遇到的坑
消费端
rocketMq的消息堆积如何处理
1,消费端出问题了,比如消费阻塞
2,生产者生产速率突然变大很多
如果是突然激增的一部分流量导致消息积压,后续逻辑又不注重时效性,并且消费者没有出现一些自身性能问题,则可以先观察让它慢慢消费即可
rocketmq没有提供针对每条消息过期时间设置的API,也就是消息本身不会过期,但是commitlog会过期
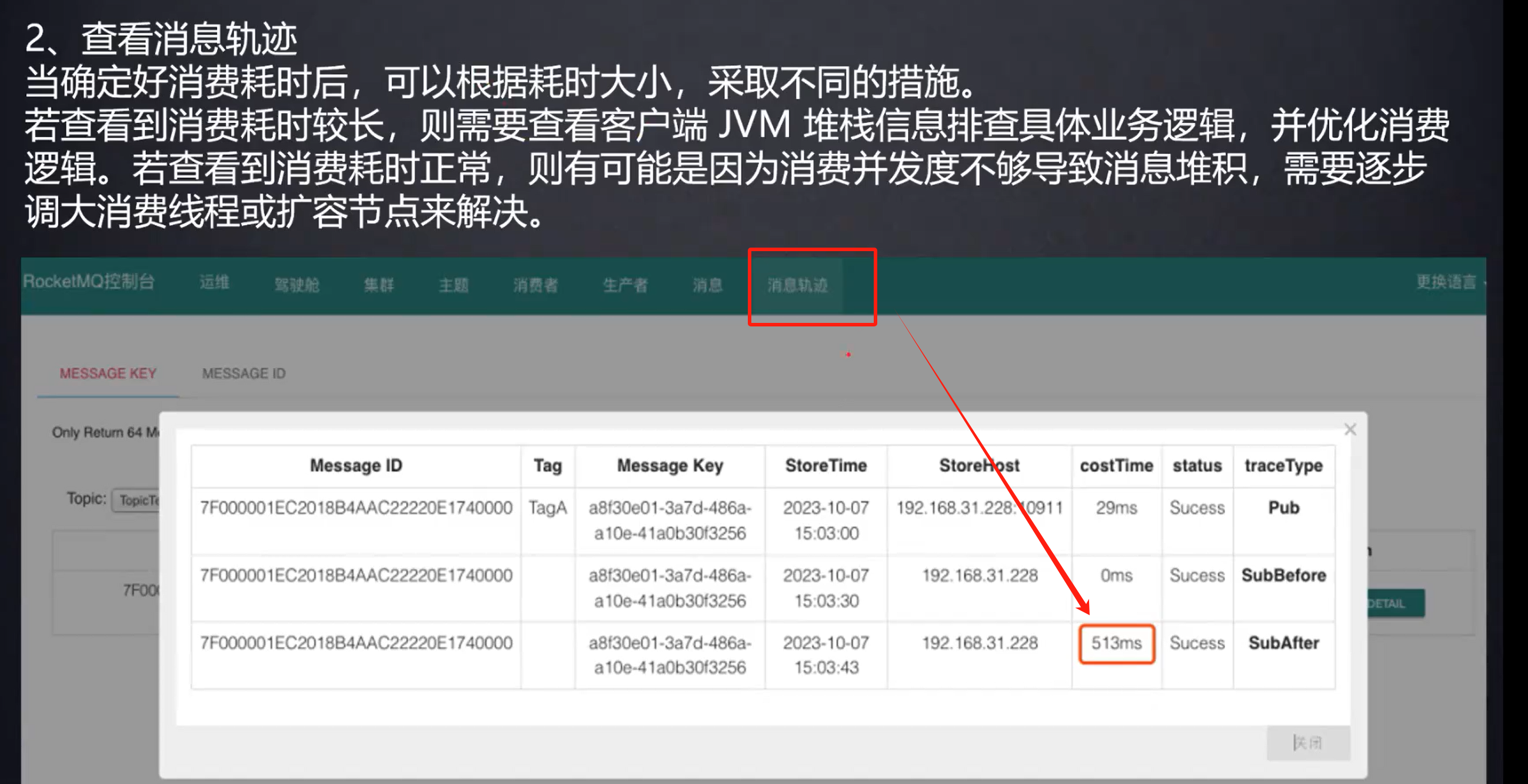
消费慢的问题排查
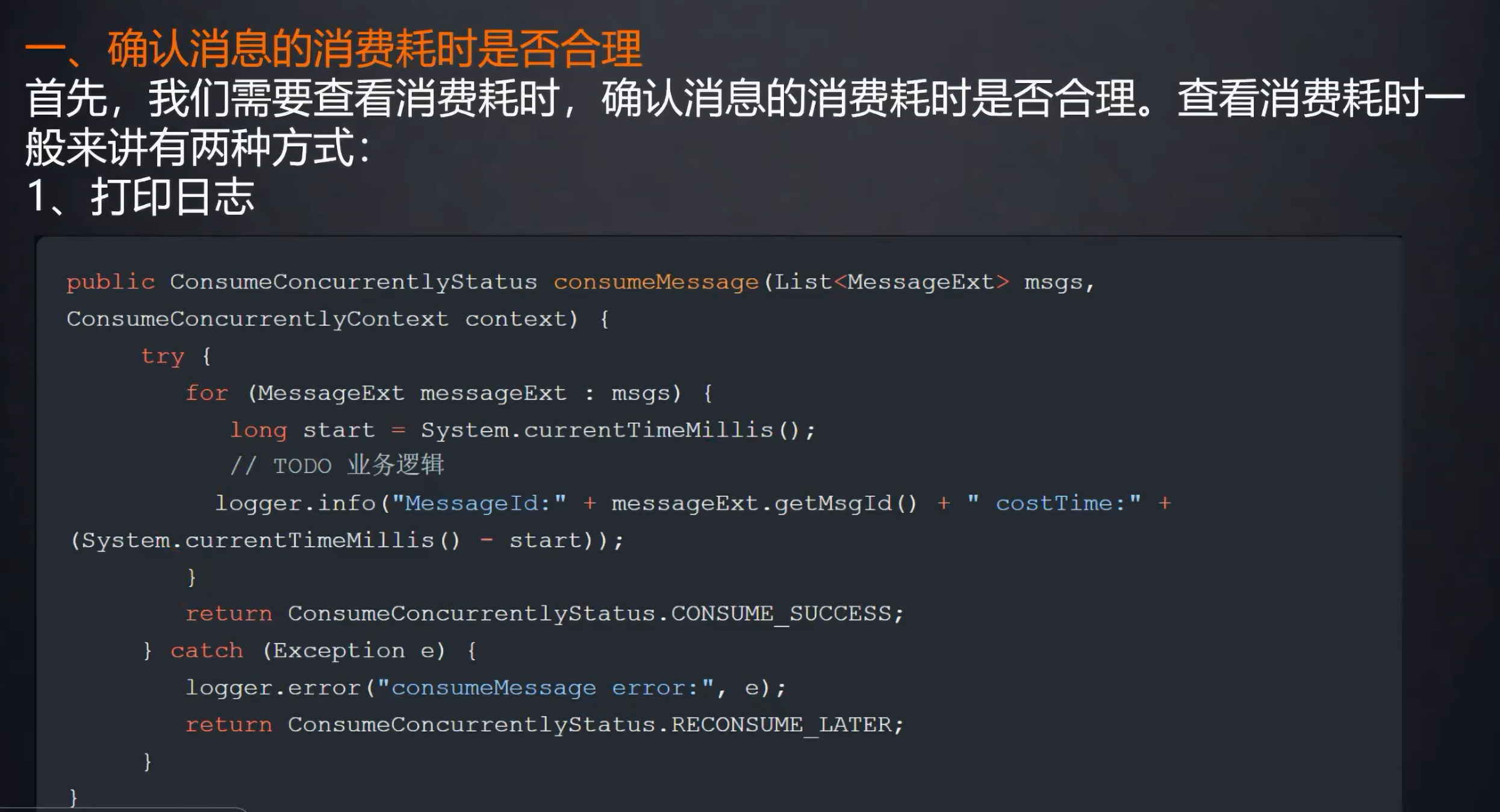
通过打日志查看,耗时长短
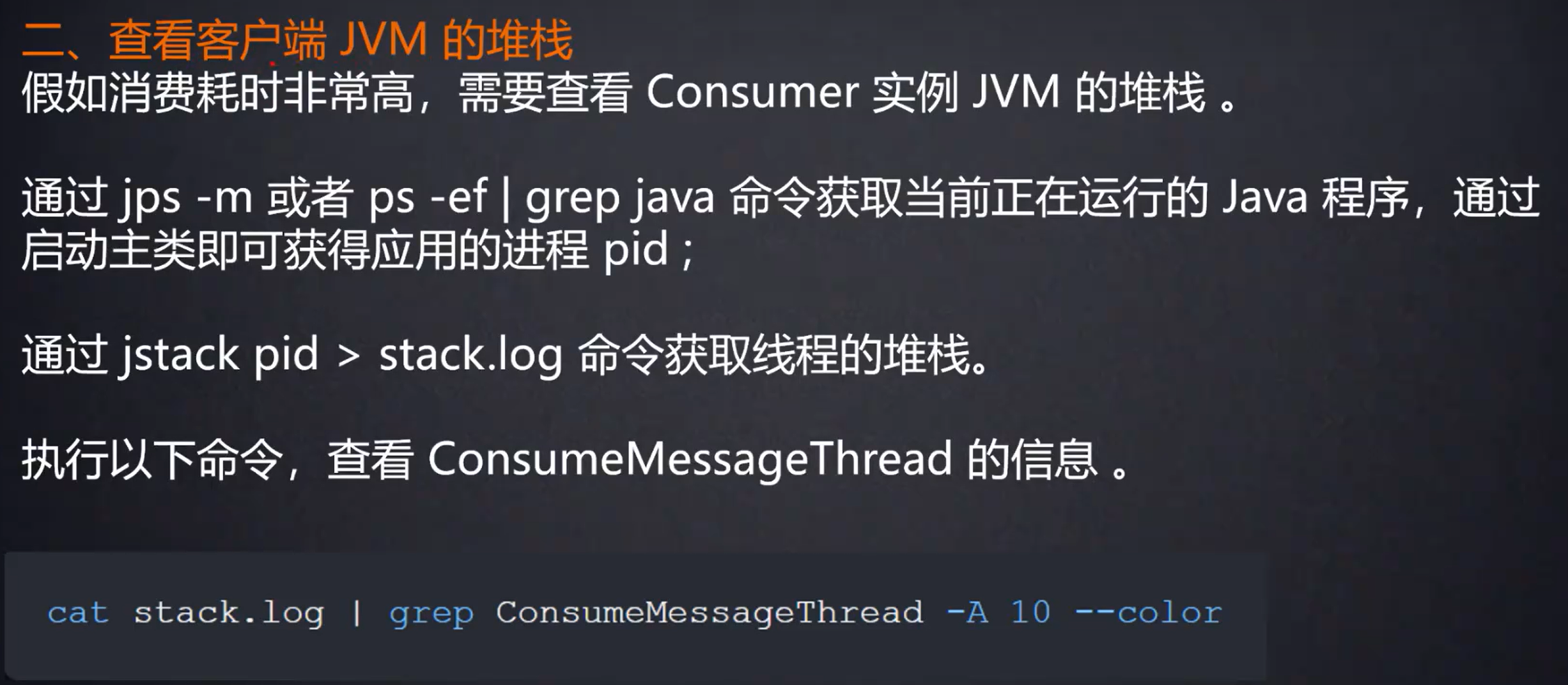
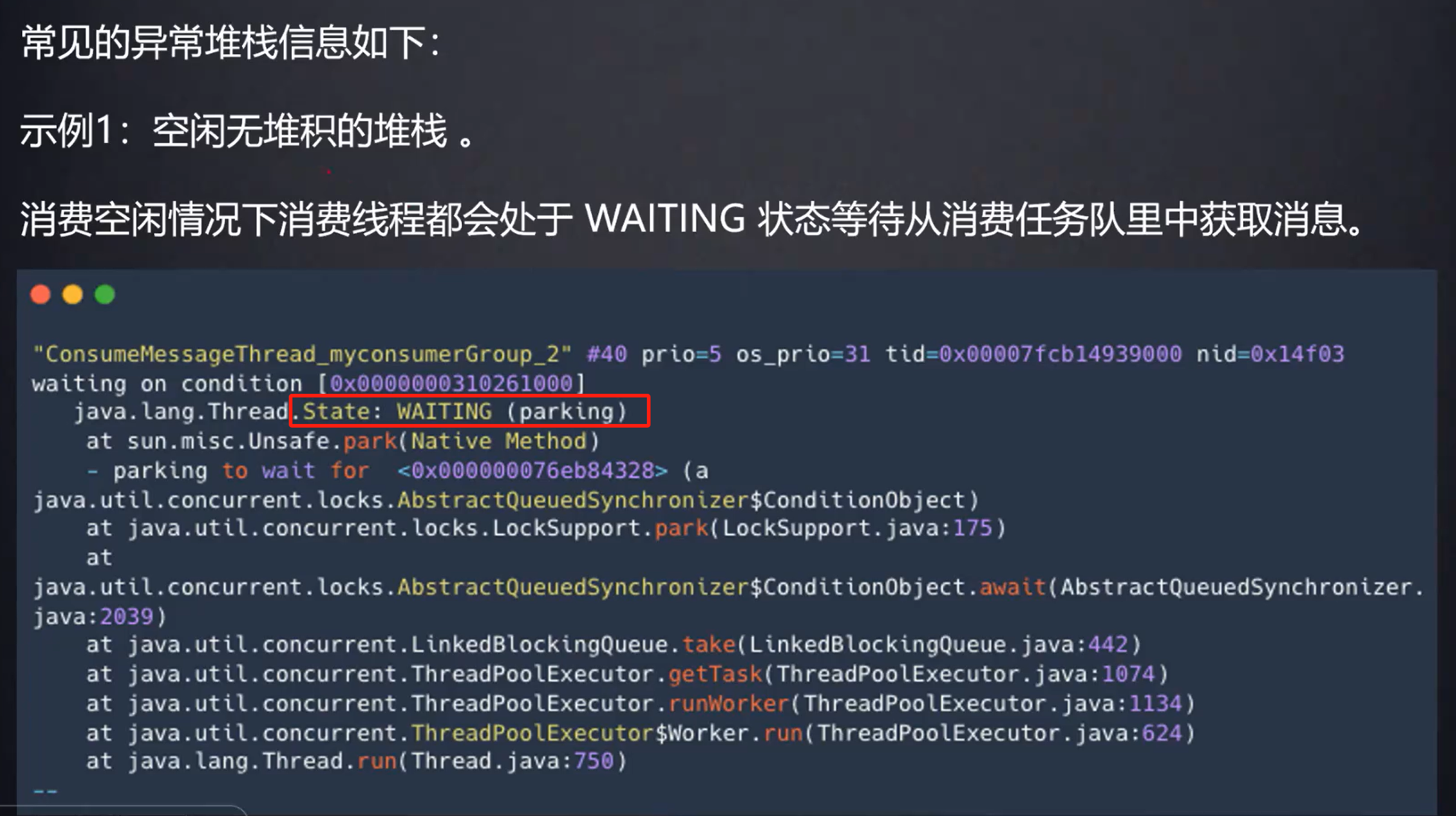
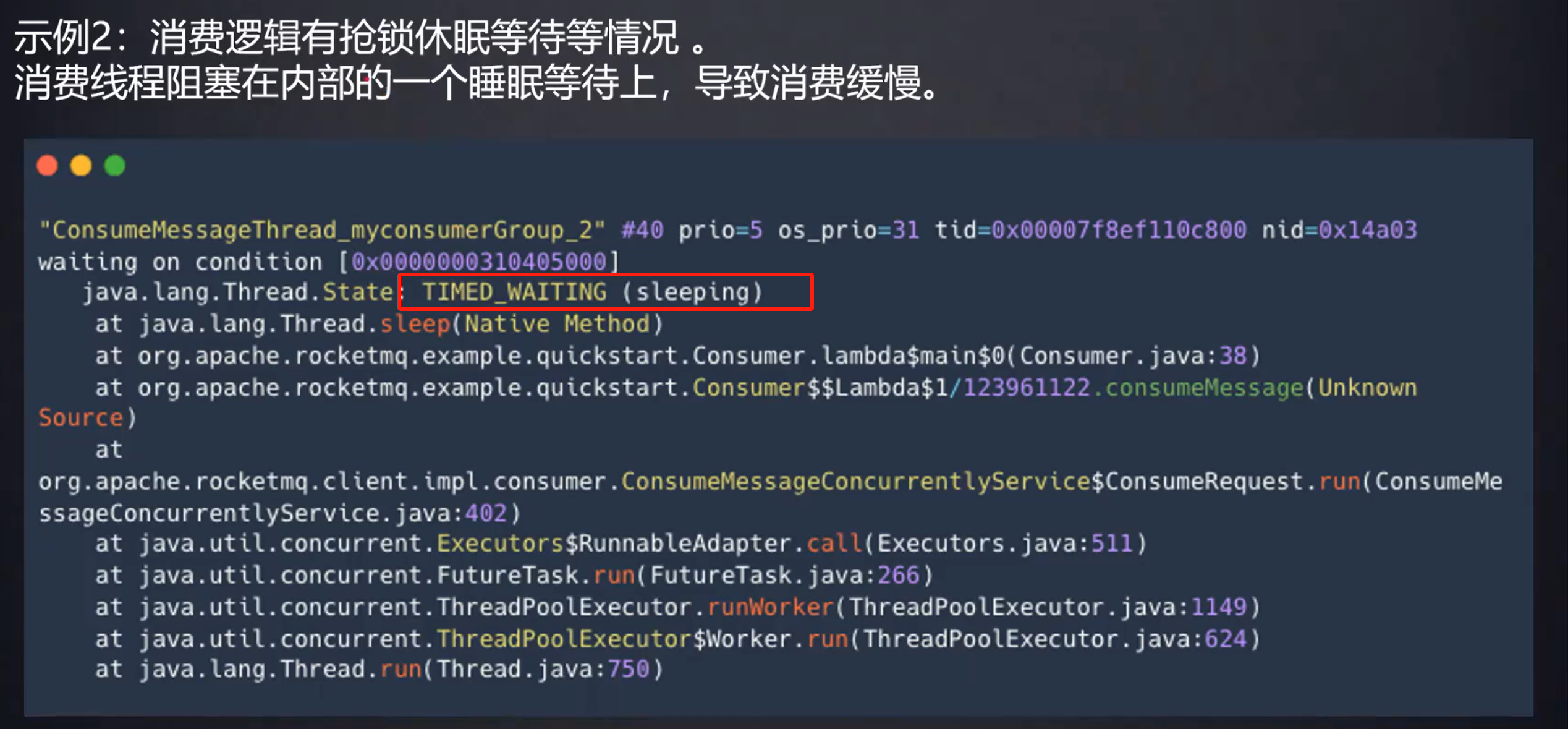
这是sleep()时的线程状态
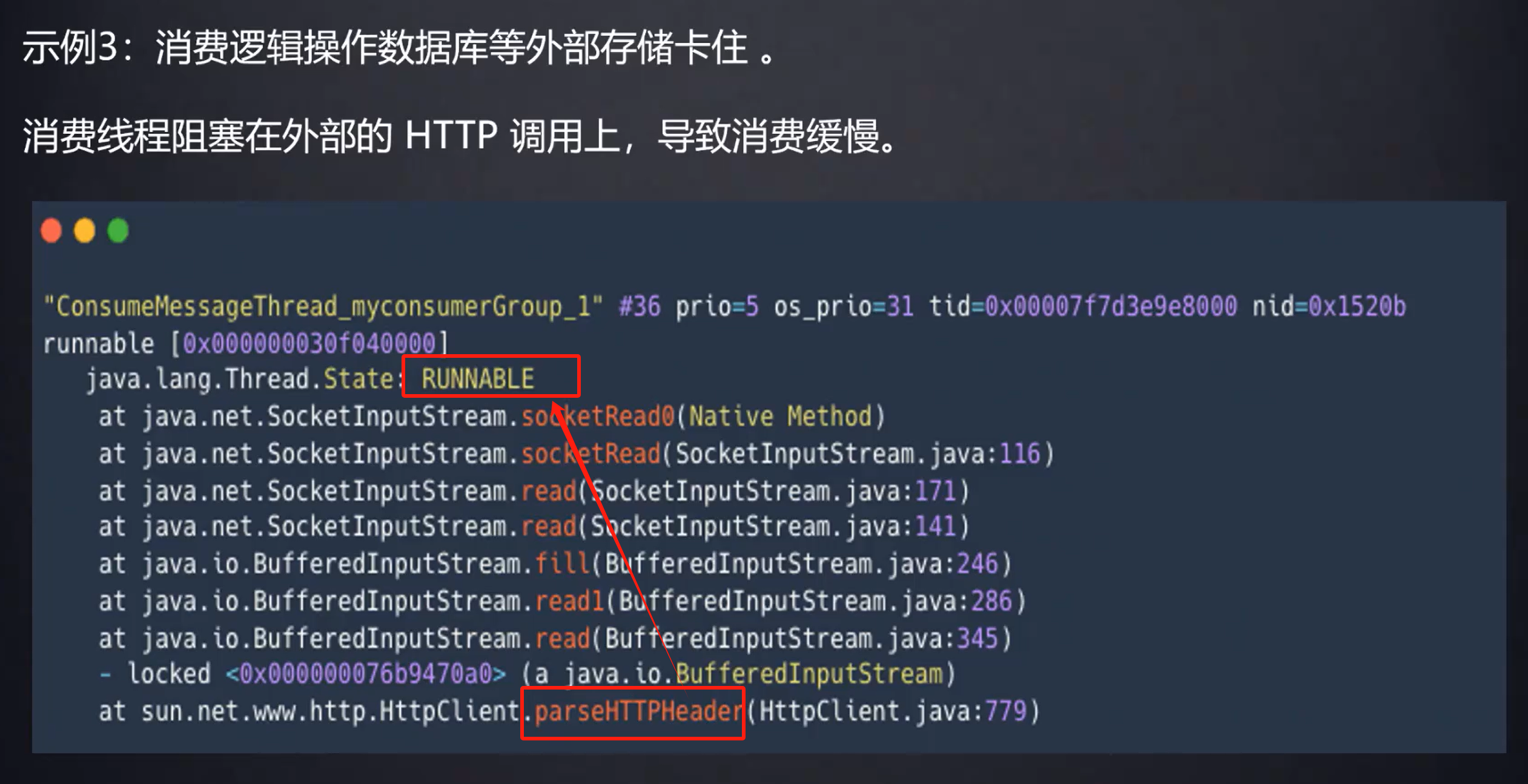
可以看到是卡在HTTP方法上,线程状态又是RUNNABLE,那么就说明可能是线程卡在了某个远程调用上面
通常情况下,如果消费的瓶颈来自于某个慢的代码,那么进程中的那些线程在一瞬间(进行jstack 的时候)大概率都在执行相同的代码,所以它们的堆会非常相像
下游消费系统如果宕机了,导致几百万条消息在消息中间件里积压,此时怎么处理?
你们线上是否遇到过消息积压的生产故障?如果没遇到过,你考虑一下如何应对?
具体表现为 用户操作界面中转圈圈
对于大规模消息发送接收可以使用pull模式,手动处理消息拉取速度,消费的时候统计消费时间以供参考
临时解决方案
创建一个新的consumeGroup并增加几台机器,
如果consumer数量和topic的queue数量不对等,上线了多台也在短时间内无法消费完堆积的消息怎么办?
-
准备一个临时的topic,临时topic对应的queue的数量,是正在堆积的老topic的queue的几倍
-
临时topic对应的queue分布到多个broker中
-
上线一台“搬运consumer”(consumeGroupName和老的消费组Group-A不相同)做消息的搬运工,把原来topic中的消息挪到新的topic里,不做业务逻辑处理,只是挪过去(搬运consumer此时相当于新topic的生产者)
-
上线N台新consumer(Group-B)同时消费临时新topic中的数据
-
改老消费组Group-A中的消费者的代码bug
-
恢复老消费组的Group-A,继续消费之前的topic
-
a) 需要通过控制台修改老消费组Group-A的消费进度,从而跳过N台新consumer(Group-B)消费过的数据,跳到接近没有消费过offset,交界处有少量重复消费也没有问题
-
b) 让“搬运consumer”和Group-B继续运行,让老消费组的Group-A重新上线,并让老消费组的Group-A的从CONSUME_FROM_LAST_OFFSET开始消费起来,最后关闭“搬运consumer”和Group-B继续运行
-

堆积时间过长消息超时了?
RocketMQ中的消息本身不会超时过期,只会在commitLog被删除的时候才会消失,不会超时
堆积的消息会不会进死信队列?
不会,消息在消费失败后会进入重试队列(%RETRY%+consumergroup),多次重试失败(默认16次)才会进入死信队列(%DLQ%+consumergroup)
根本解决方案
消费慢的原因
先要问消费慢的原因,为什么慢?是因为CPU密集型运算、网络IO、数据库IO慢三个部分来排查。消息的拉取这个过程,一般不会成为消费慢的瓶颈
CPU密集型运算,只能多加消费者机器
网络IO,需要让被调用方,提高接口响应性能,让对方可以先落表快速返回,再私下去处理等手段

数据库IO
数据库插入一般不会有太多问题,数据库行记录插入不会引起锁竞争,插入慢可能就是表中记录太多导致新增数据时同步维护索引结构引起的慢。
主要是针对同一行的记录的并行修改,会引起行锁竞争导致慢,这时可以考虑将一行记录分而治之,将一行记录拆分为分多行记录。最后就是引入分库分表、或者直接使用分布式数据库
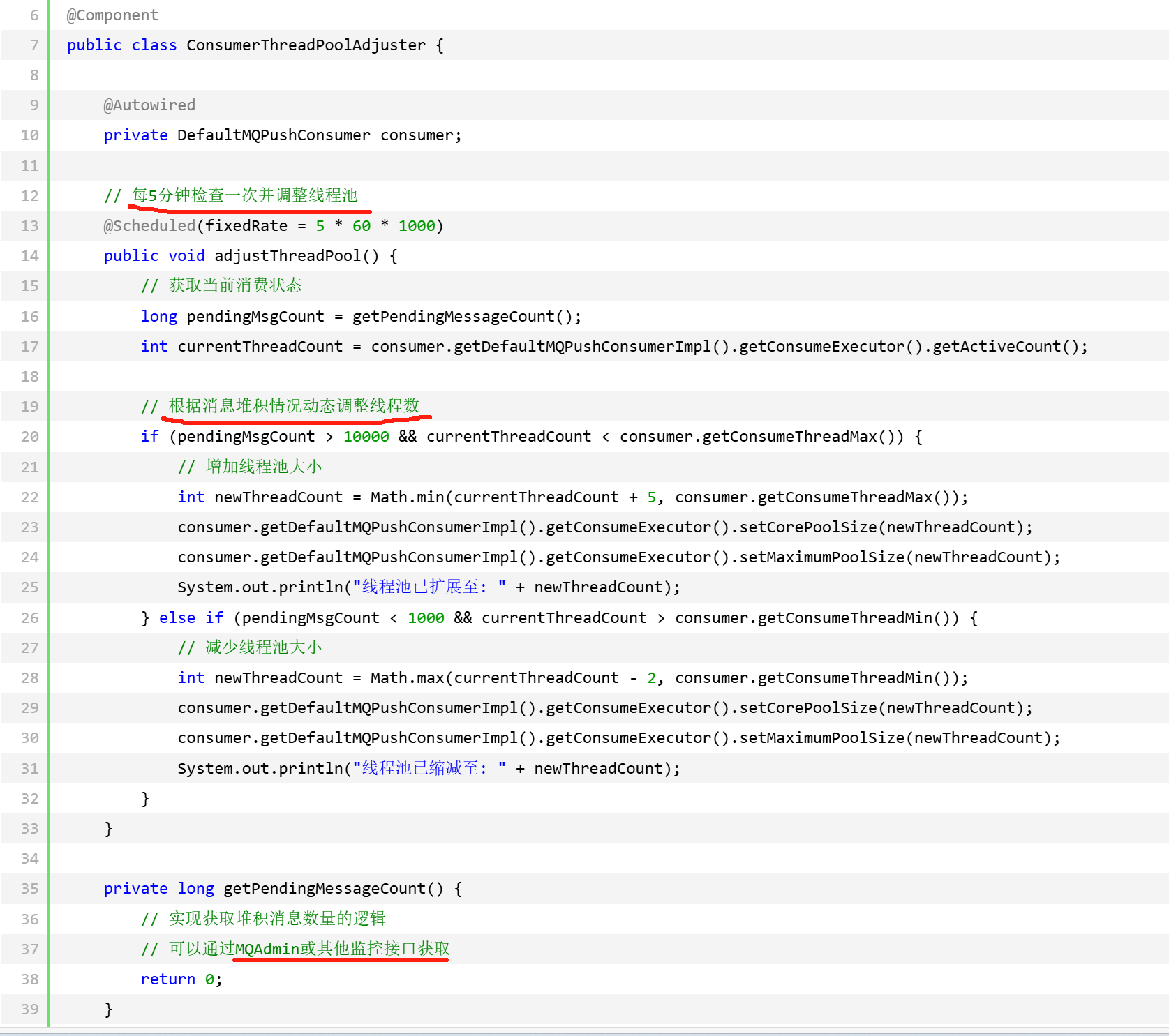
动态调整线程池线程数


线程池特性
Push模式底层依赖ConsumeMessageConcurrentlyService的线程池,默认使用无界队列,consumeThreadMax可能无法生效
解决方案:
消费模型
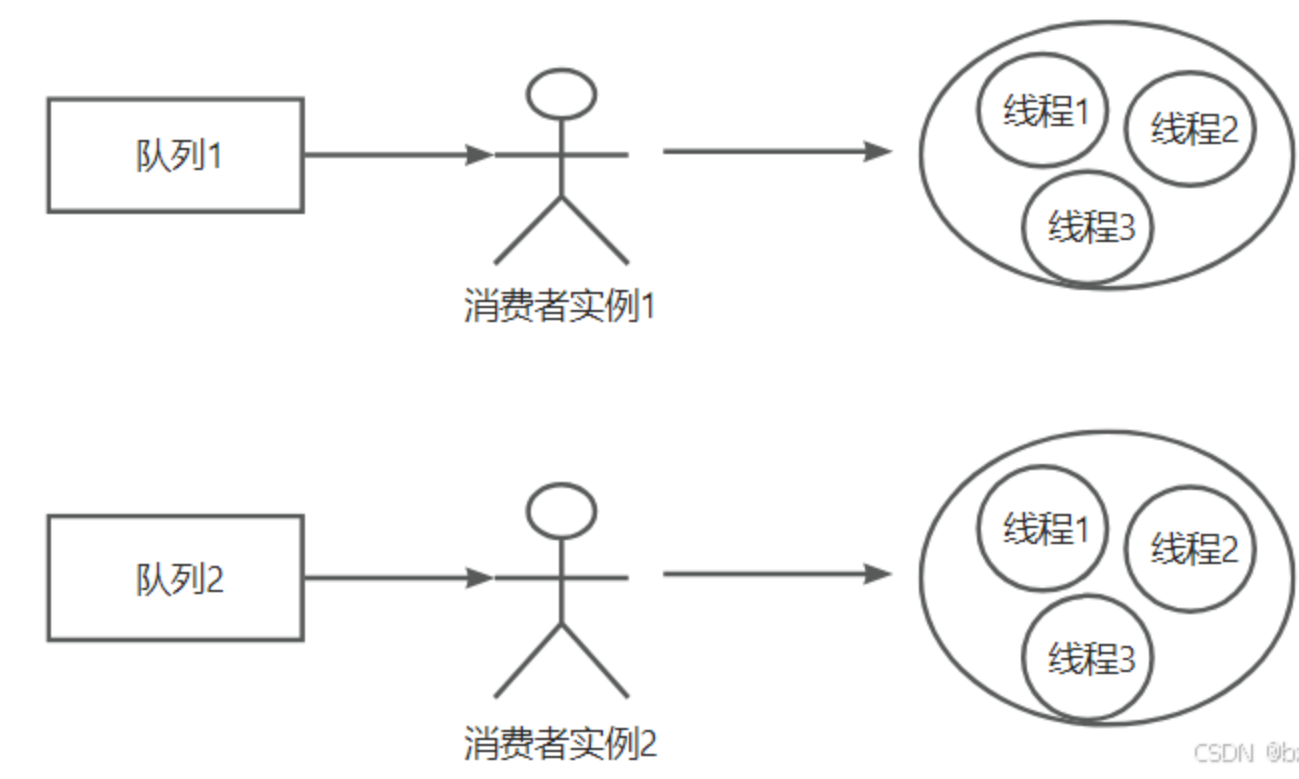
最大程度下,是一个队列对应一个消费者实例,一个消费者实例里面又有一个消费线程池,默认这个消费线程池中的消费线程数是20,如果消费逻辑中IO操作很多,那么就可以适当把20的数值再提高
高吞吐量下如何优化生产者和消费者的性能?
消费
-
同一group下,多机部署,并行消费
-
单个consumer提高消费线程个数(IO密集型可以提高线程数)
-
批量消费
-
消息批量拉取(生产者可以批量发送)
-
业务逻辑批量处理
-
消费端提高消费性能方法-批量消费
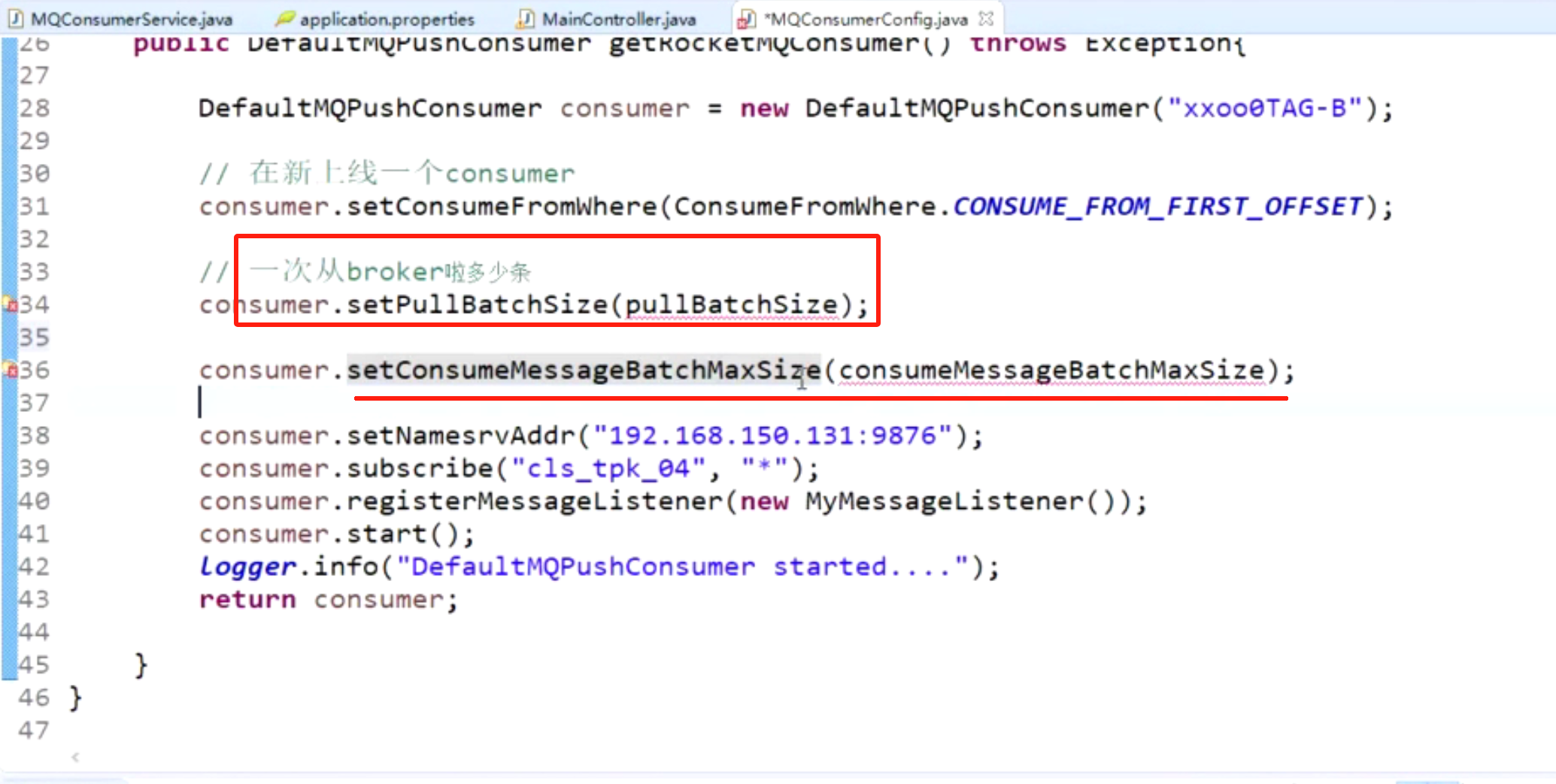
默认每次拉32条,可以适当提高
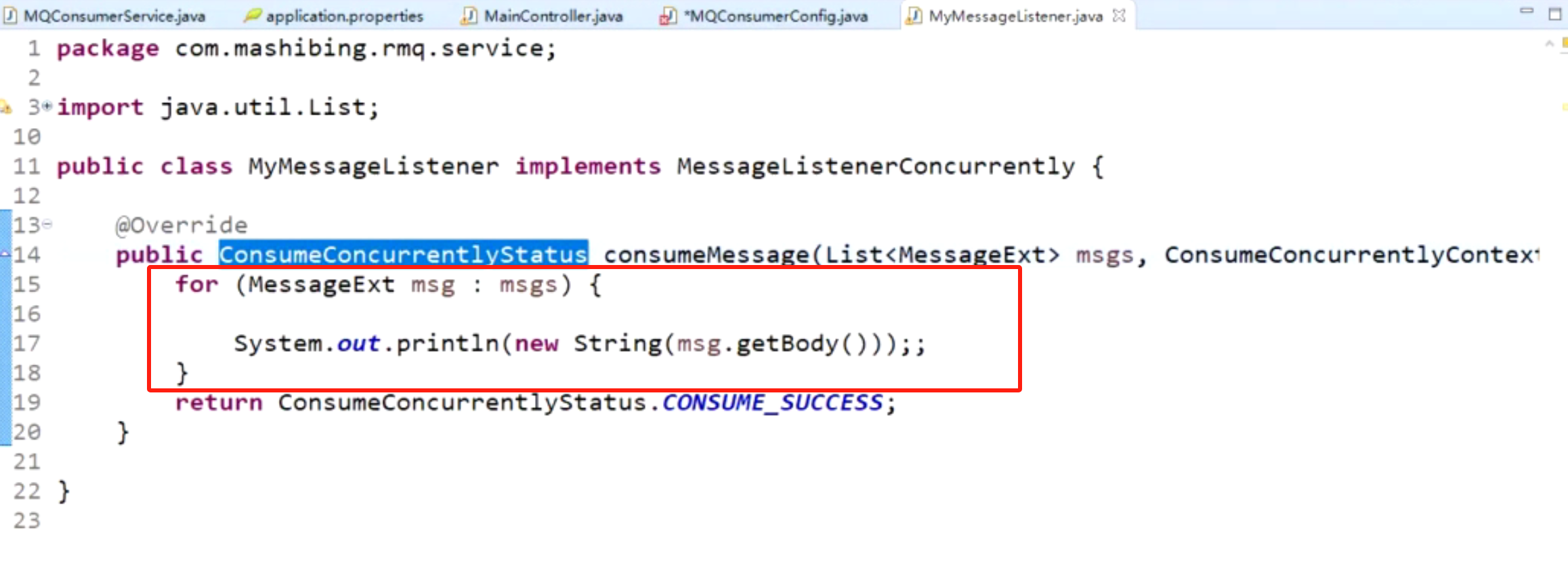
如果这个消费回调方法中,又很多阻塞调用,同步等待多,那么可以把消息的处理丢入另外的线程池提高性能
但是,如果这个消费回调方法中,就是很普通的方法处理,等待不多,那么就没必要开另外的线程池处理,线程开太多反而影响性能
运维
-
网卡调优
-
jvm调优
-
多线程与cpu调优
-
Page Cache
死信队列
死信队列堆积问题
学习可以通过mqadmin命令,查看死信队列的相关信息
学习可以通过一个consumer,同时订阅多个topic:业务topic + DLQ-topic
RocketMQ死信队列问题排查与实战解决方案_rocketmq 死信队列-CSDN博客