PySpark 安装教程及 WordCount 实战与任务提交
学习 PySpark 安装教程是掌握大数据处理的第一步。无论你是在 Windows 还是 Linux 系统上进行 PySpark 安装与部署,都需要正确配置环境才能顺利运行。PySpark 作为 Apache Spark 的官方 Python API,结合了 Python 的简洁和 Spark 的分布式计算能力,被广泛应用于 大数据分析、机器学习和数据科学。
一、准备 PySpark 的 Win/Linux 环境
在开始之前,无论是 Windows 还是 Linux,我们都需要准备好基础环境。使用 Anaconda 可以极大地简化环境管理和包安装的复杂性,是目前最推荐的入门方式。
前提条件:
- Java 开发工具包 (JDK):Spark 运行在 JVM 之上,因此必须安装 JDK (推荐 1.8 或 11 版本)。
- Anaconda / Miniconda:一个强大的 Python 环境和包管理器。
1.1.Linux 环境安装部署
1. 安装 Anaconda
Anaconda 是一个包含 Python、常用科学计算包以及conda环境管理器的发行版。
关于如何在 Linux 系统上详细安装和配置 Anaconda,读者可以参考这篇更为详尽的文章:《Anaconda安装与使用详细教程》
2. 创建并激活 Conda 环境
为了保持项目环境的隔离,我们强烈建议创建一个专门用于 PySpark 的新环境。
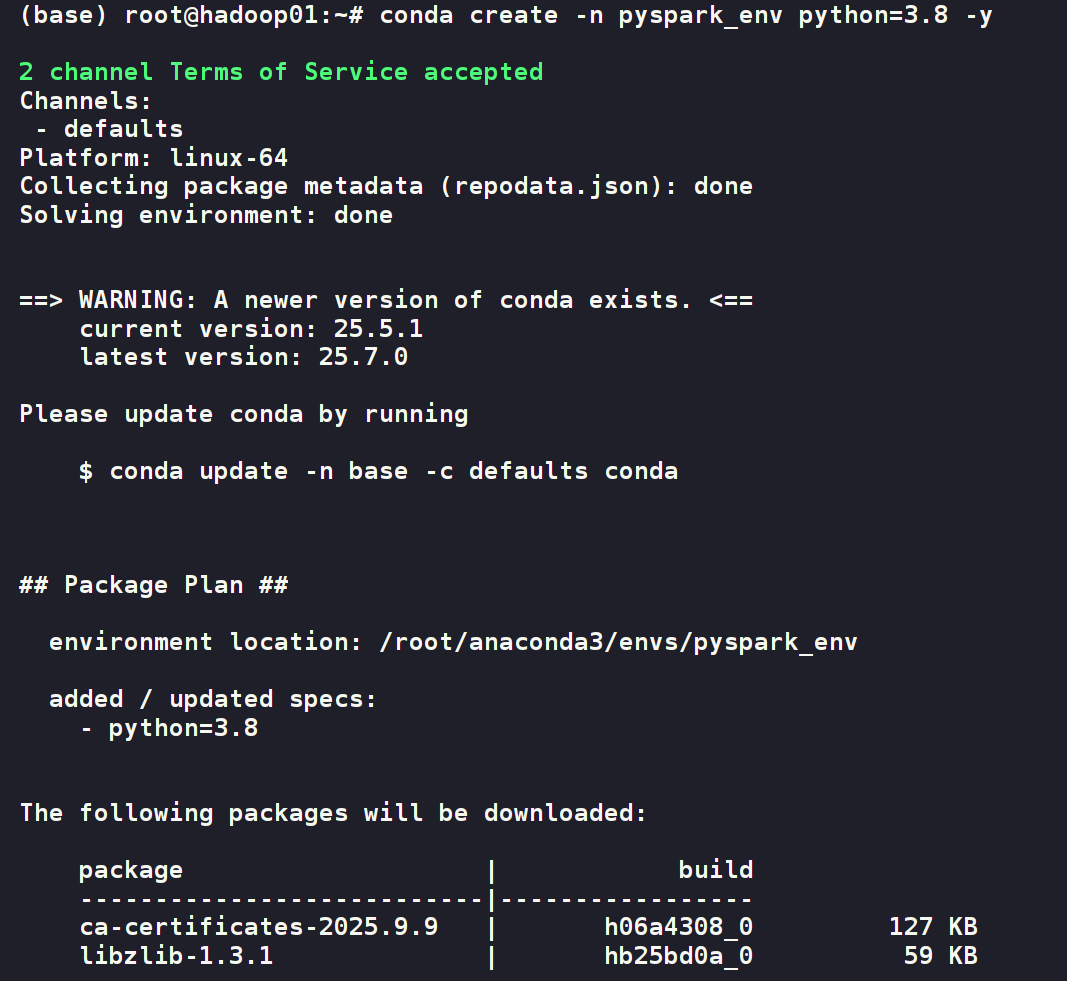
# 创建一个名为 pyspark_env,使用 Python 3.8 的新环境
conda create -n pyspark_env python=3.8 -y# 激活这个新创建的环境
conda activate pyspark_env
3. 通过 conda 或 pip 安装 pyspark
在已激活的 pyspark_env 环境中,使用 conda 或 pip 安装 pyspark 包。pyspark 包会自动处理 Spark 的相关依赖。
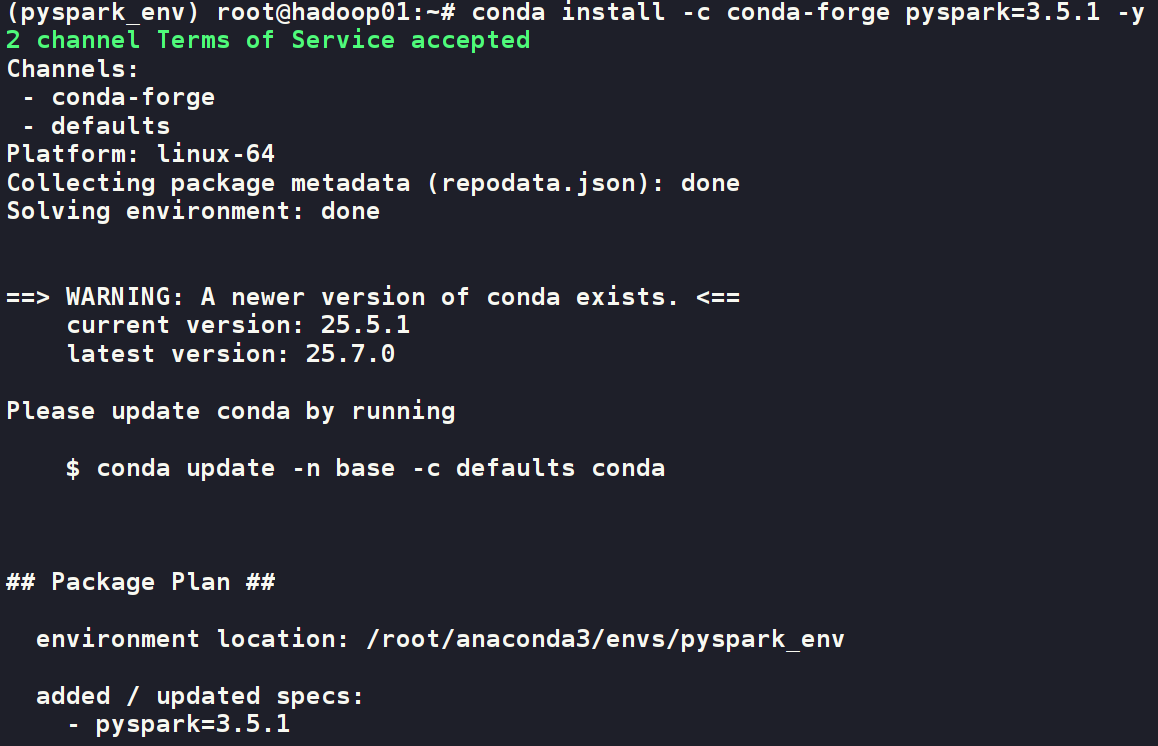
# 推荐使用 conda-forge 渠道
conda install -c conda-forge pyspark=3.5.1 -y
# 或者使用 pip
# pip install pyspark==3.5.1
4. 验证安装
在已激活的 conda 环境中,直接输入 pyspark 命令。
pyspark
如果安装成功,你将看到 Spark 的 Logo 和一个交互式的 PySpark Shell 启动,并自动创建了 SparkContext 对象 (变量名为 sc) 和 SparkSession 对象 (变量名为 spark)。
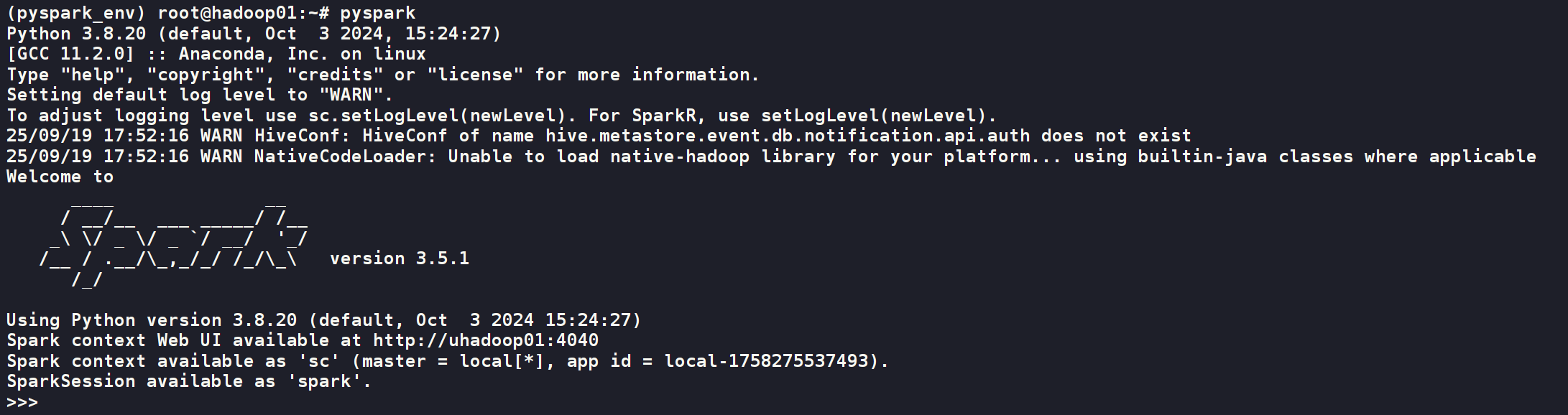
还可以通过http://ip_addr:4040/jobs/,把ip_addr替换成你自己的ip地址,就可以访问到spark的webui界面
1.2.Windows 环境安装部署
1. 安装 Anaconda
这次要在windows端安装部署Anaconda,还是可以参考这篇文章《Anaconda安装与使用详细教程》
2. 创建并激活 Conda 环境
- 打开 Anaconda Prompt (从开始菜单中找到)。这是一个专门配置好
conda环境的命令行工具。 - 执行与 Linux 完全相同的命令来创建和激活环境。
# 创建一个名为 pyspark_env,使用 Python 3.8 的新环境
conda create -n pyspark_env python=3.8 -y# 激活这个新创建的环境
conda activate pyspark_env
- 你看到的命令行界面和提示信息将与Linux环境中的截图非常相似。
3. 通过 conda 或 pip 安装 pyspark
在已激活的 pyspark_env 环境中,同样执行与 Linux 完全相同的安装命令。pyspark 包会自动处理 Spark 的相关依赖,在 Windows 上无需手动下载Spark或配置winutils.exe。
:: 推荐使用 conda-forge 渠道
conda install -c conda-forge pyspark=3.5.1 -y
:: 或者使用 pip
:: pip install pyspark==3.5.1
4. 验证安装
- 在已激活的
pyspark_env的 Anaconda Prompt 中,直接输入pyspark命令。
pyspark
- 如果所有配置都正确,你将看到与 Linux 环境下相同的 Spark Logo 和交互式 Shell 启动。
- 同时,你也可以在浏览器中访问
http://localhost:4040来查看 Spark Web UI,其界面与 Linux 环境完全一致。
二、Spark 的 WordCount 案例实战
WordCount 是大数据处理的 “Hello, World!”,它完美地展示了 Spark 分布式计算的核心流程。在本节中,我们将使用 PyCharm 这个强大的IDE来创建、编写和运行我们的第一个 PySpark 应用。
2.1 在 PyCharm 中创建 PySpark 项目
PyCharm 内置了对 PySpark 项目的良好支持,可以帮助我们快速搭建开发环境。
步骤一:新建项目
打开 PyCharm,选择 “文件 (File)” -> “新建项目 (New Project)”。在左侧的项目类型列表中,找到并选择 “PySpark”。
步骤二:配置项目环境
在新建项目窗口中,你需要配置以下几个关键选项:
位置: 指定你项目代码的存放路径。
解释器类型: 保持默认的 “项目 venv (Project venv)” 即可。
环境: 选择 “生成新的 (Create new)”。PyCharm 会为你的项目创建一个独立的虚拟环境,这是一个非常好的开发习惯。
基础 Python: 选择你系统中已经安装的 Python 解释器。
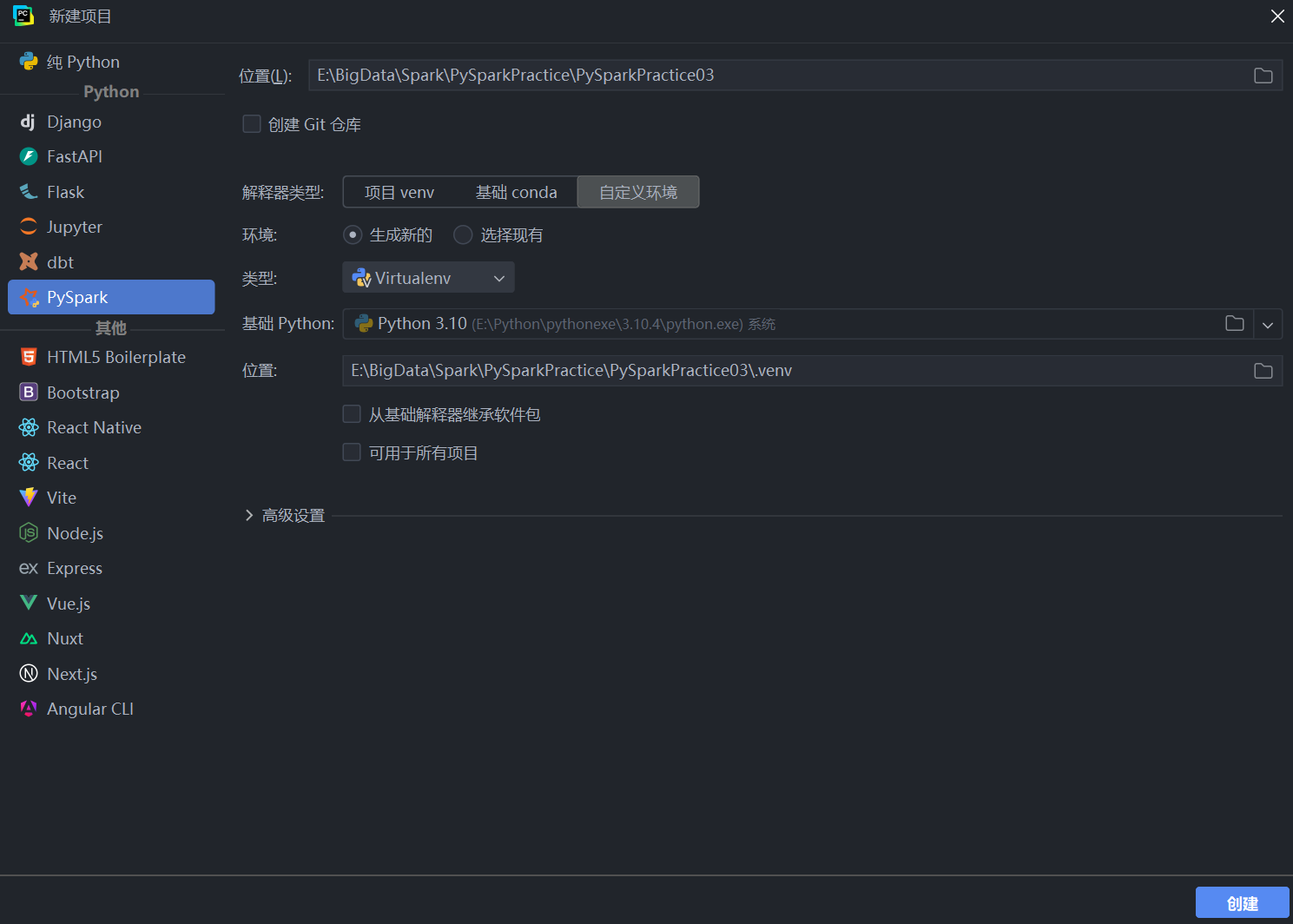
配置完成后,点击右下角的 “创建” 按钮。PyCharm 会自动创建项目结构,并在虚拟环境中安装 pyspark 包
步骤三:测试默认示例代码
项目创建完成后,PyCharm 会自动生成一个名为 main.py 的文件,其中包含一个计算圆周率 (Pi) 的示例代码。这是一个极佳的测试,用于验证你的 PySpark 环境是否配置成功。
直接右键点击 main.py 文件,选择 “运行 ‘main’ (Run ‘main’)”。
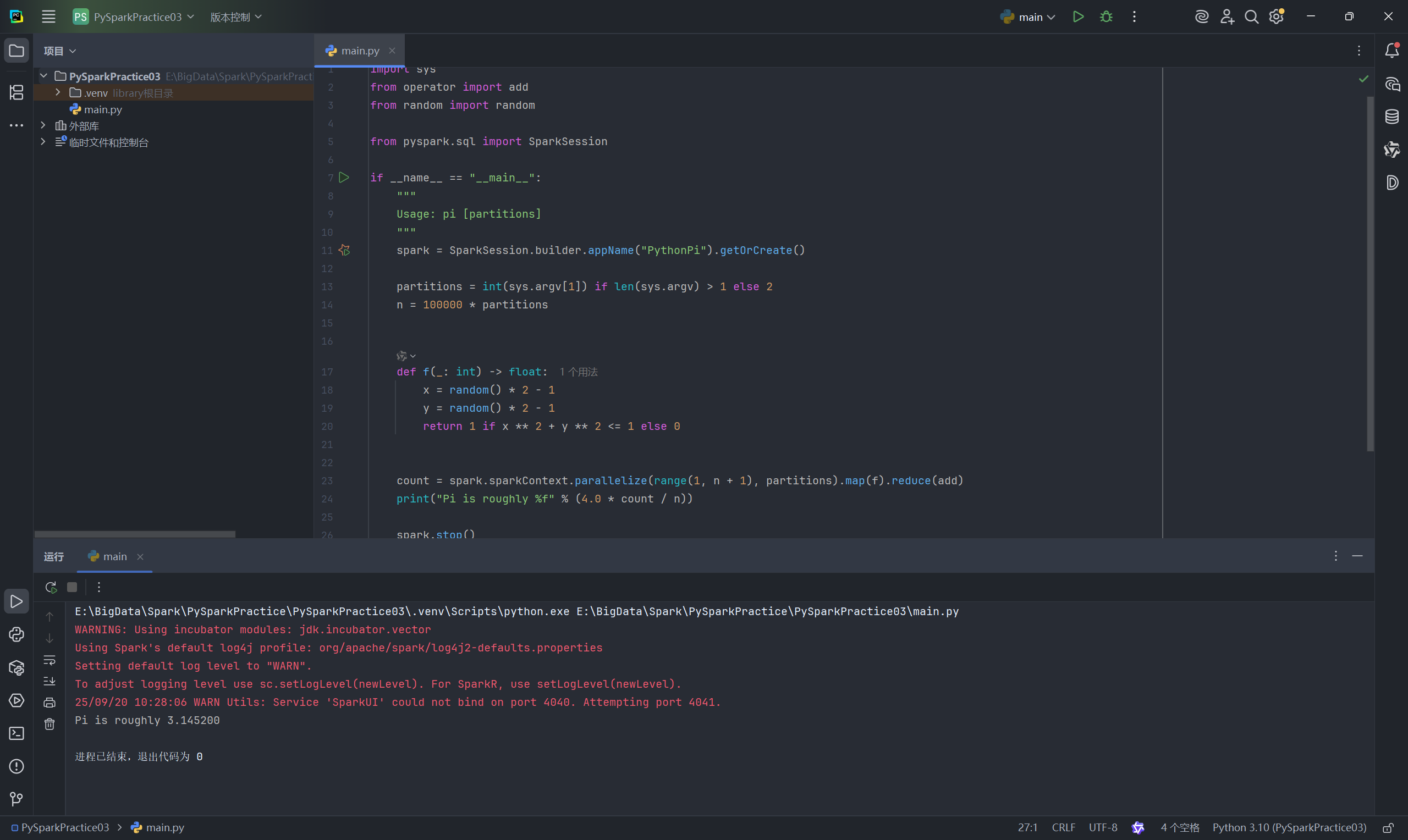
如果你在运行窗口中看到了计算出的Pi值,那么恭喜你,你的 PySpark 开发环境已经准备就绪!
2.2 项目结构与 WordCount 代码实战
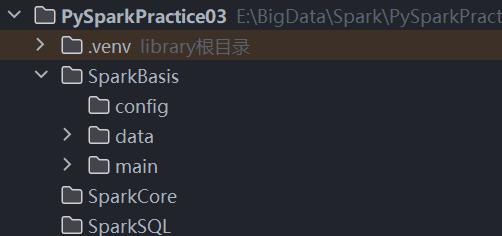
为了更好地组织我们的代码和数据,我们先来规划一下项目目录结构。
推荐目录结构:
在项目根目录下,我们创建 SparkBasis 目录,并在其中再创建 data, main 等子目录。
data: 用于存放我们的输入数据文件。
main: 用于存放我们的主程序脚本。
步骤一:准备输入数据
在 data 目录下,创建一个名为 words.txt 的文本文件,并输入一些单词,用空格隔开,例如:
hello spark flink
doris hello sqoop
flink spark hdfs
步骤二:编写 WordCount 脚本
在 main 目录下,创建一个名为 01.wordcount.py 的 Python 文件,并编写以下代码:
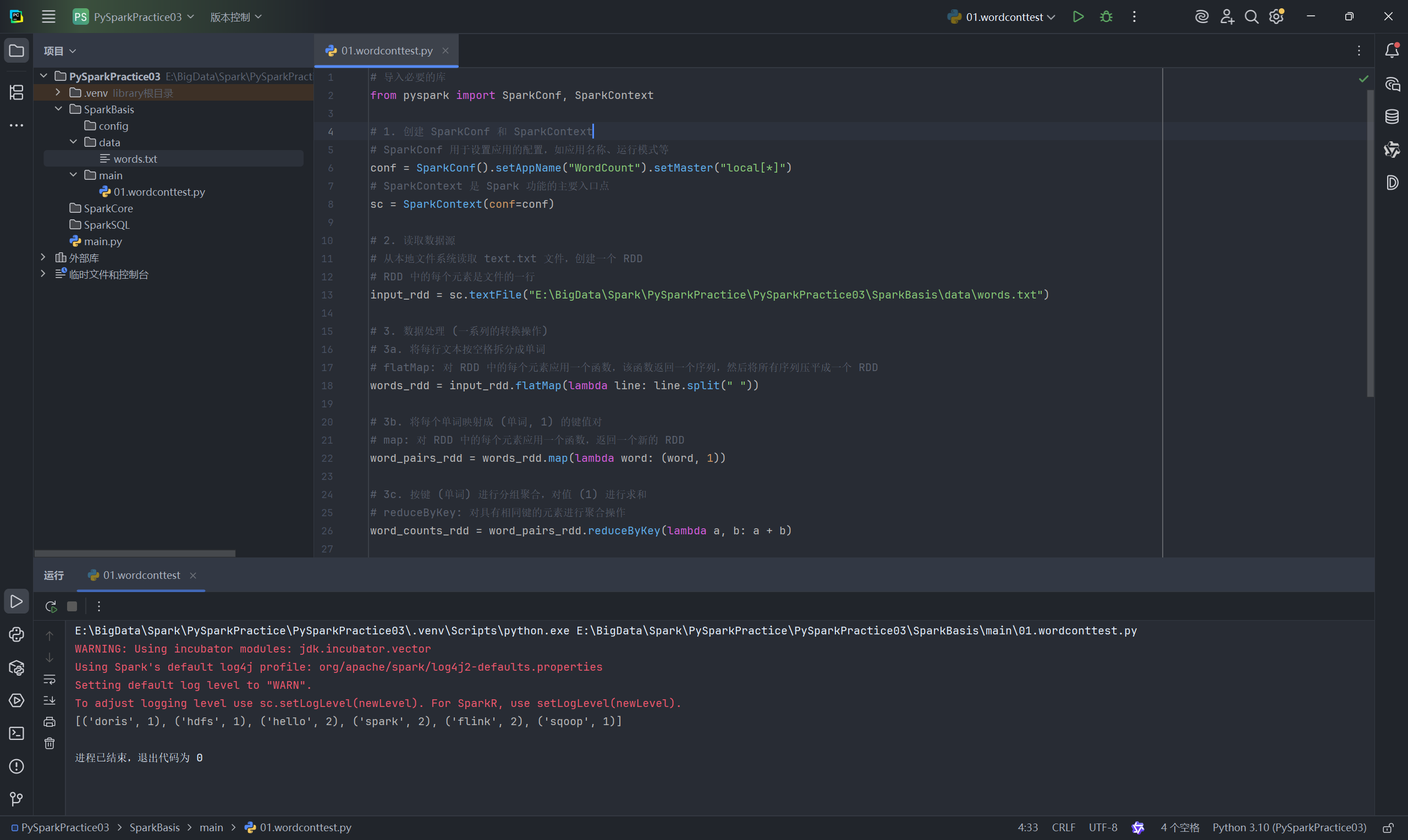
# 导入必要的库
from pyspark import SparkConf, SparkContext# 1. 创建 SparkConf 和 SparkContext
# SparkConf 用于设置应用的配置,如应用名称、运行模式等
conf = SparkConf().setAppName("WordCount").setMaster("local[*]")
# SparkContext 是 Spark 功能的主要入口点
sc = SparkContext(conf=conf)# 2. 读取数据源
# 从本地文件系统读取 words.txt 文件,创建一个 RDD
# RDD 中的每个元素是文件的一行
input_rdd = sc.textFile("E:/BigData/Spark/PySparkPractice/PySparkPractice03/SparkBasis/data/words.txt")# 3. 数据处理 (一系列的转换操作)
# 3a. 将每行文本按空格拆分成单词
# flatMap: 对 RDD 中的每个元素应用一个函数,该函数返回一个序列,然后将所有序列压平成一个 RDD
words_rdd = input_rdd.flatMap(lambda line: line.split(" "))# 3b. 将每个单词映射成 (单词, 1) 的键值对
# map: 对 RDD 中的每个元素应用一个函数,返回一个新的 RDD
word_pairs_rdd = words_rdd.map(lambda word: (word, 1))# 3c. 按键 (单词) 进行分组聚合,对值 (1) 进行求和
# reduceByKey: 对具有相同键的元素进行聚合操作
word_counts_rdd = word_pairs_rdd.reduceByKey(lambda a, b: a + b)# 4. 结果输出 (行动操作)
# collect: 将 RDD 的所有元素作为列表返回到驱动程序
output = word_counts_rdd.collect()# 打印结果
print(output)# 5. 停止 SparkContext
sc.stop()
注意: 请将 sc.textFile() 中的文件路径替换为你自己 words.txt 文件的绝对路径。
步骤三:运行脚本并查看结果
右键点击 01.wordcount.py 文件并运行。你将在下方的运行窗口看到计算结果,它是一个包含 (单词, 词频) 元组的列表。

2.3 将结果输出到文件
通常,我们不会将大规模计算的结果全部 collect() 到驱动程序(可能会导致内存溢出),而是将其直接保存到分布式文件系统 (如 HDFS) 或本地文件系统中。
步骤一:修改代码以保存结果
在 main 目录下创建一个新文件 02.sparkpro01.py,修改代码,将 collect() 和 print() 替换为 saveAsTextFile()。
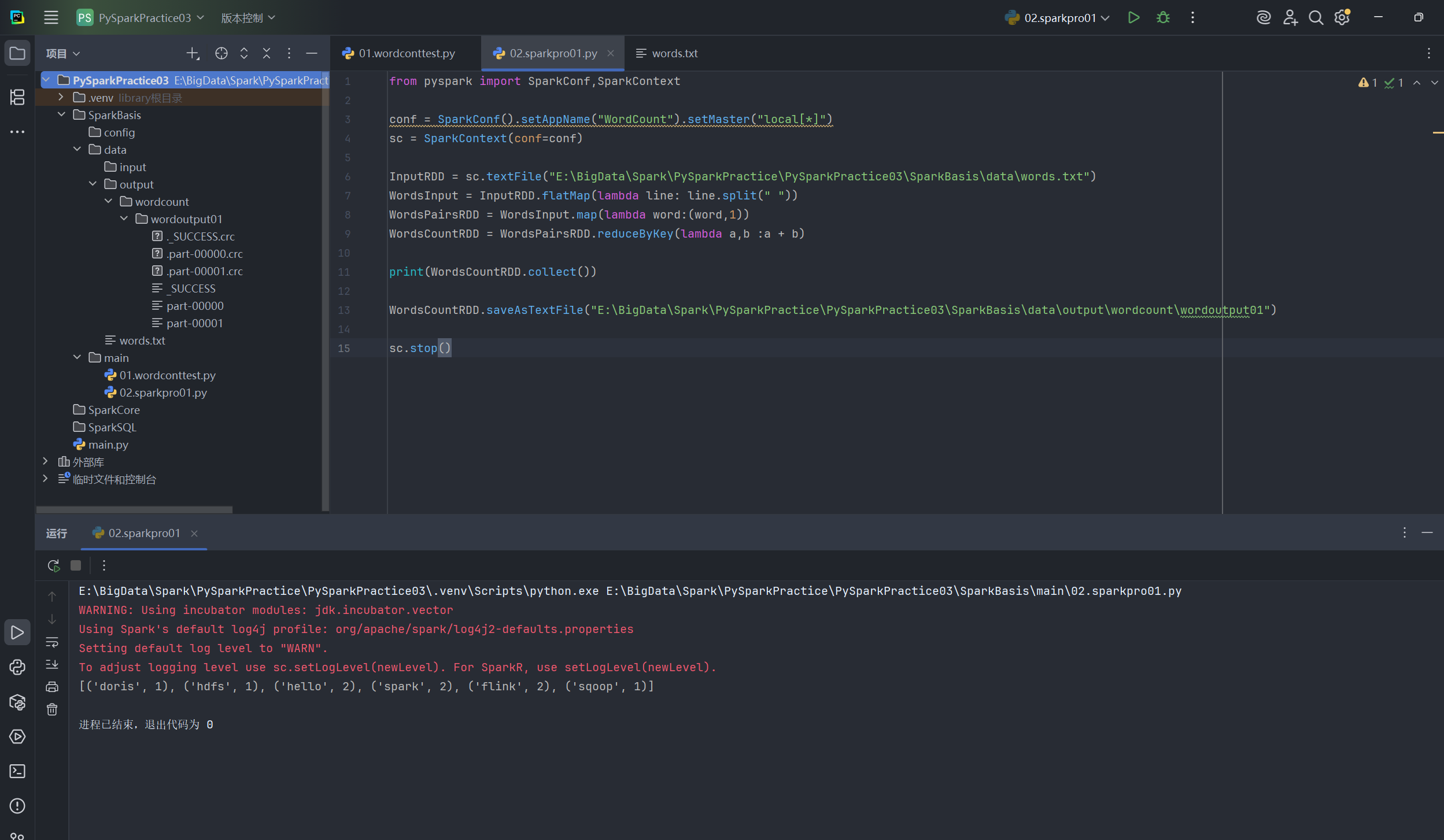
from pyspark import SparkConf, SparkContextconf = SparkConf().setAppName("WordCount").setMaster("local[*]")
sc = SparkContext(conf=conf)inputRDD = sc.textFile("E:/BigData/Spark/PySparkPractice/PySparkPractice03/SparkBasis/data/words.txt")
flatMapRDD = inputRDD.flatMap(lambda line: line.split(" "))
mapRDD = flatMapRDD.map(lambda word: (word, 1))
wordCountRDD = mapRDD.reduceByKey(lambda a, b: a + b)# collect() 会将所有分区的数据都拉取到 Driver 中,数据量大时易内存溢出
print(wordCountRDD.collect())
# saveAsTextFile 会将结果写入到指定的路径,每个分区一个文件
wordCountRDD.saveAsTextFile("E:/BigData/Spark/PySparkPractice/PySparkPractice03/SparkBasis/data/output/wordcount01")sc.stop()
注意:
请将
saveAsTextFile()中的输出路径替换为你自己的路径。
Spark 要求输出目录必须是不存在的,否则会报错。每次运行前,你需要手动删除或指定一个新的输出目录。
步骤二:运行并检查输出
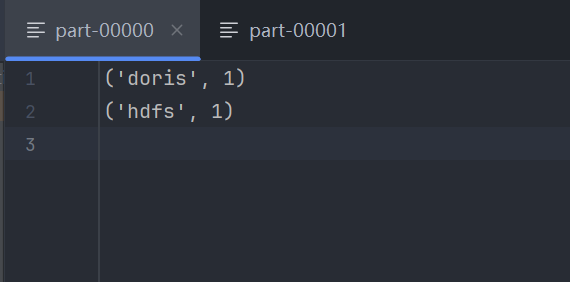
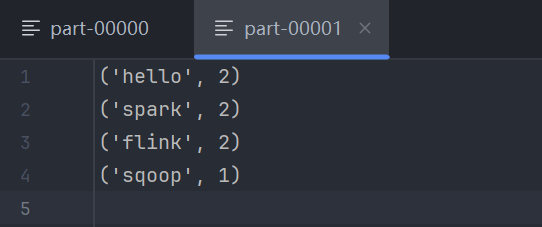
运行 02.sparkpro01.py。脚本执行完毕后,你会在指定的输出路径下看到一个名为 wordcount01 的目录。进入该目录,你会发现:
_SUCCESS文件:一个空文件,表示作业成功完成。
part-xxxxx文件:真正包含计算结果的文件。由于我们在local[*]模式下运行,Spark 可能会启动多个本地线程(分区),因此可能会生成多个 part 文件。打开其中一个,你将看到(单词, 词频)格式的输出。
三、WordCount 进阶操作与总结
3.1 WordCount 的排序操作
通常,我们更关心出现频率最高的词。我们可以对结果进行排序。
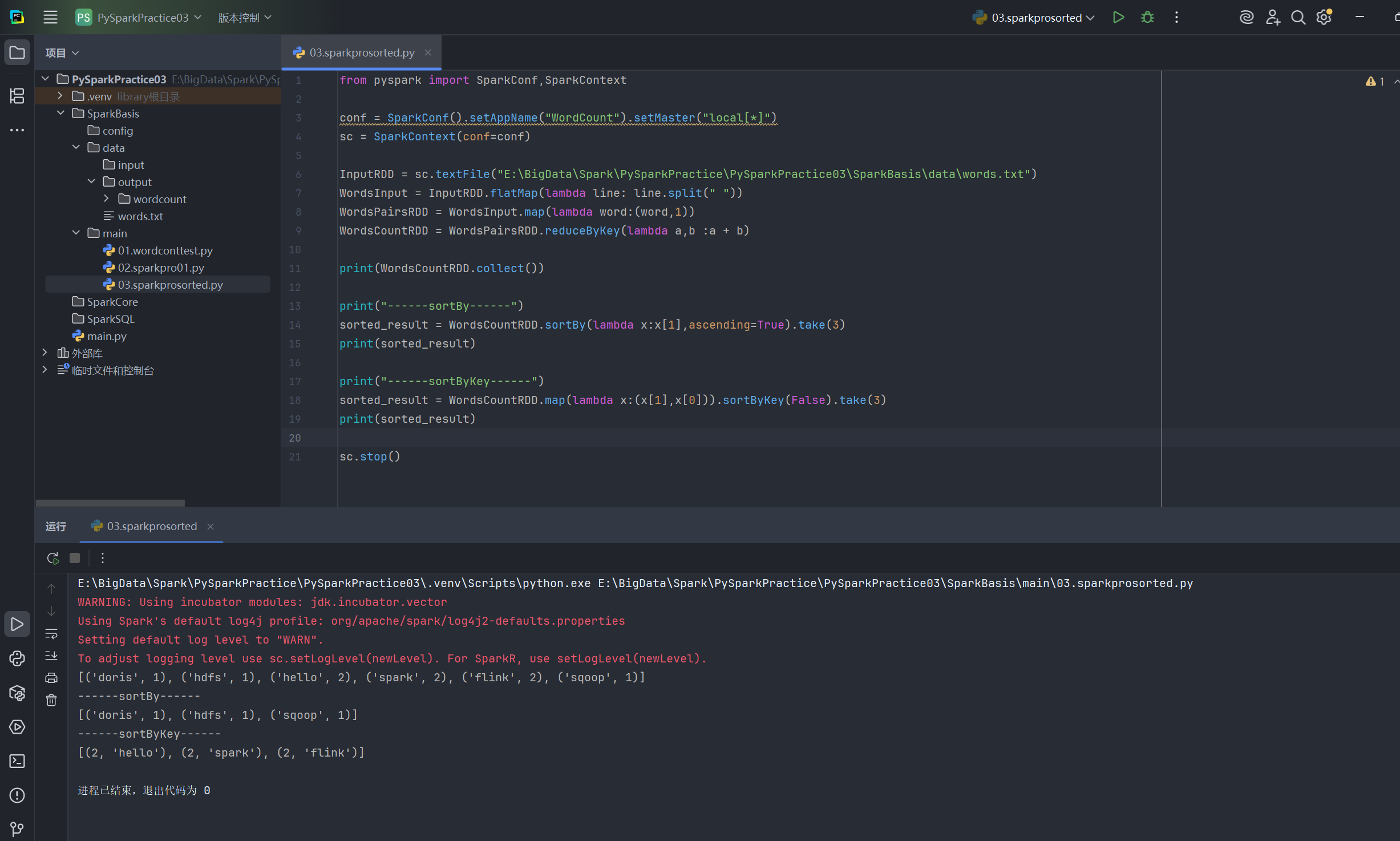
在 02.sparkpro01.py 之后,添加排序步骤:
# sortBy: 根据指定的函数对 RDD 进行排序
# lambda x: x[1] 表示按元组的第二个元素 (也就是 count) 进行排序
# ascending=True 表示升序排列
sorted_result = WordsCountRDD.sortBy(lambda x:x[1],ascending=False).take(3)
print(sorted_result)
# sortByKey: 根据 RDD 的键 (word) 进行排序
# False 表示降序排列
sorted_result = WordsCountRDD.sortByKey(False).take(3)
print(sorted_result)
3.2 从 HDFS 读取文件
在真实的大数据环境中,数据通常存储在 HDFS 上。PySpark 无缝支持从 HDFS 读取数据。
只需修改 sc.textFile() 的路径即可。
代码示例:
from pyspark import SparkConf,SparkContextif __name__ == "__main__":conf = SparkConf().setAppName("ReadFromHDFS").setMaster("local[*]")sc = SparkContext(conf=conf)sc.setLogLevel("WARN")# 读取文件textRDD = sc.textFile("hdfs://hadoop01:9000/pydata/input/words.txt")# 拆分单词flat_mapRDD = textRDD.flatMap(lambda line: line.split(" "))# 映射成 (word, 1) 形式mapRDD = flat_mapRDD.map(lambda word: (word, 1))# 按 key 聚合统计resultRDD = mapRDD.reduceByKey(lambda x, y: x + y)print(resultRDD.take(10))sc.stop()
注意:要让 Spark 能够访问 HDFS,需要确保 Spark 的运行环境 (classpath) 中包含了 Hadoop 的配置文件 (如 core-site.xml, hdfs-site.xml),或者已正确配置了相关的环境变量 (HADOOP_CONF_DIR)。
3.3 Spark 的 WordCount 总结
这个看似简单的案例涵盖了 Spark 编程的核心思想:
RDD:不可变的、可分区的分布式数据集
转换 (Transformation):如flatMap,map,reduceByKey,sortBy。它们是惰性执行的,只定义 RDD 之间的依赖关系,不立即计算
行动 (Action):如collect,count,saveAsTextFile。行动操作会触发之前所有转换操作的实际计算
四、提交任务执行
在开发完成后,我们需要将 Python 脚本提交到 Spark 集群上运行,而不是仅仅在本地单机模式下测试。
4.1 Spark 的四种部署模式
Spark 支持多种部署模式,以适应不同的计算环境。
关于 Spark 四种部署模式 (Local, Standalone, YARN, Kubernetes) 的详细对比和架构图,大家可以参考这篇更为详尽的文章:《三、Spark 运行环境部署:全面掌握四种核心模式》
4.2 提交任务执行 (Standalone 模式)
这里我们以最常见的 Standalone 模式 为例,演示如何提交我们编写的 05.SparkSubmit.py 脚本。
核心命令:spark-submit
spark-submit 是提交 Spark 应用的统一入口。
准备工作:修改脚本以接收参数
为了灵活性,我们将硬编码的文件路径修改为从命令行参数读取。
修改后的 05.SparkSubmit.py (关键部分):
from pyspark import SparkConf,SparkContext
import sysif __name__ == "__main__":conf = SparkConf().setAppName("SparkSubmit").setMaster("local[*]")sc = SparkContext(conf=conf)sc.setLogLevel("WARN")textRDD = sc.textFile(sys.argv[0])flatmap_RDD = textRDD.flatMap(lambda line: line.split(" "))mapRDD = flatmap_RDD.map(lambda word:(word,1))resultRDD = mapRDD.reduceByKey(lambda a,b:a+b)print(resultRDD.collect())sc.stop()
Local方式提交
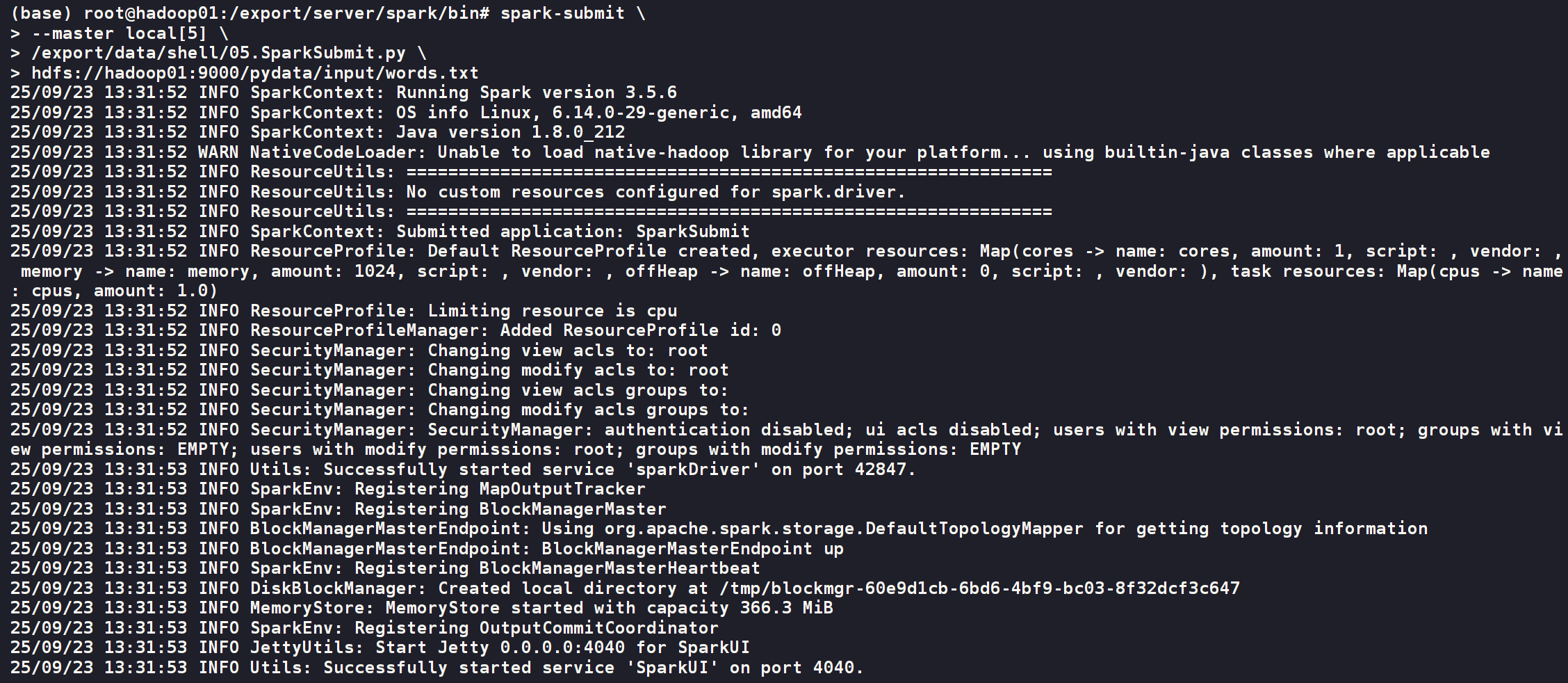
spark-submit \
--master local[5] \
/export/data/shell/05.SparkSubmit.py \
hdfs://hadoop01:9000/pydata/input/words.txt

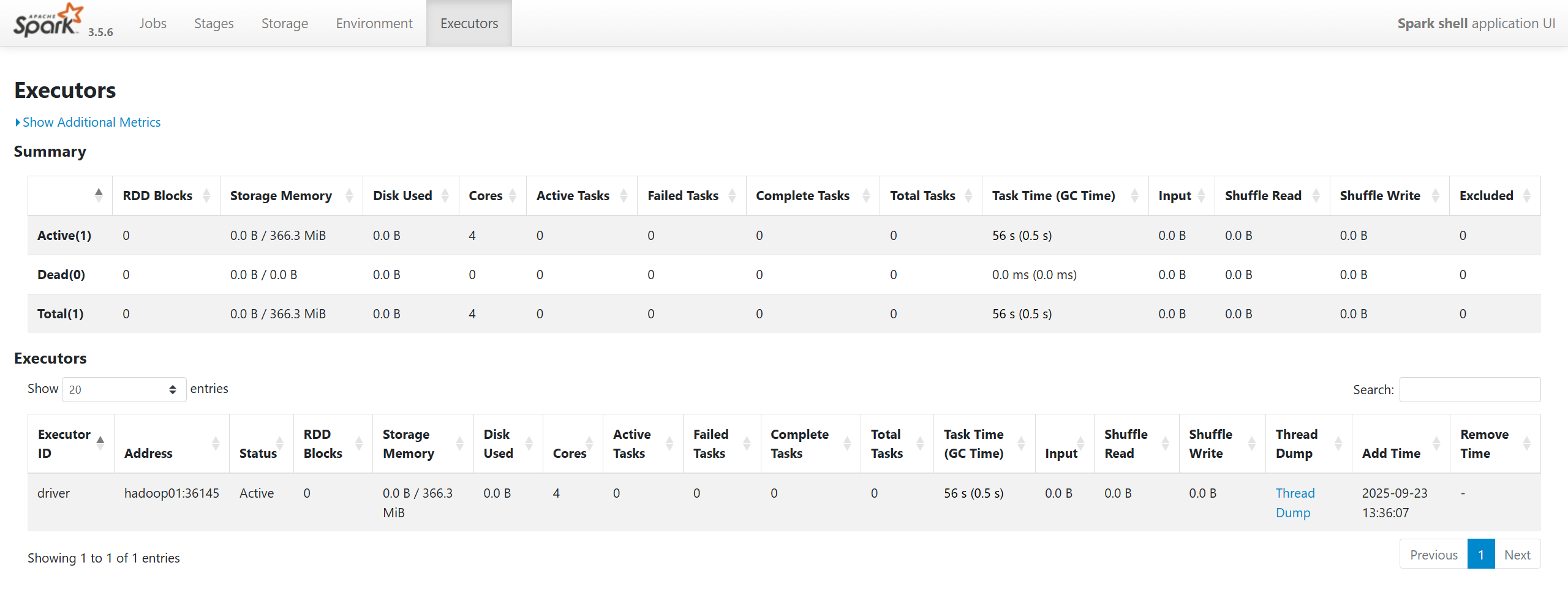
4.2 提交任务到远程服务器
PyCharm 提供了强大的远程开发功能,允许我们直接在 Windows 上的 IDE 编写和调试代码,然后无缝地将代码同步到远程 Linux 服务器上,并直接执行 Spark 任务。
a. 准备脚本以接收参数
为了灵活性,我们将硬编码的文件路径修改为从命令行参数读取。
示例脚本 05.SparkSubmit.py:
from pyspark import SparkConf,SparkContext
import sysif __name__ == "__main__":conf = SparkConf().setAppName("SparkSubmit").setMaster("local[*]")sc = SparkContext(conf=conf)sc.setLogLevel("WARN")# 从命令行第一个参数接收输入文件路径textRDD = sc.textFile(sys.argv[1])flatmap_RDD = textRDD.flatMap(lambda line: line.split(" "))mapRDD = flatmap_RDD.map(lambda word:(word,1))resultRDD = mapRDD.reduceByKey(lambda a,b:a+b)print(resultRDD.collect())sc.stop()
b. 配置 PyCharm 远程 SSH 解释器
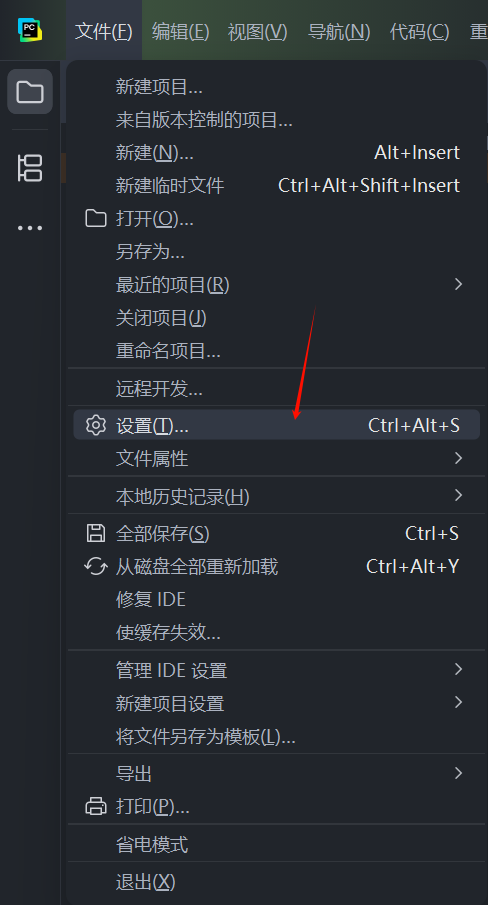
步骤一:打开设置
在 PyCharm 中,通过 “文件 (File)” -> “设置 (Settings)” 打开设置窗口。
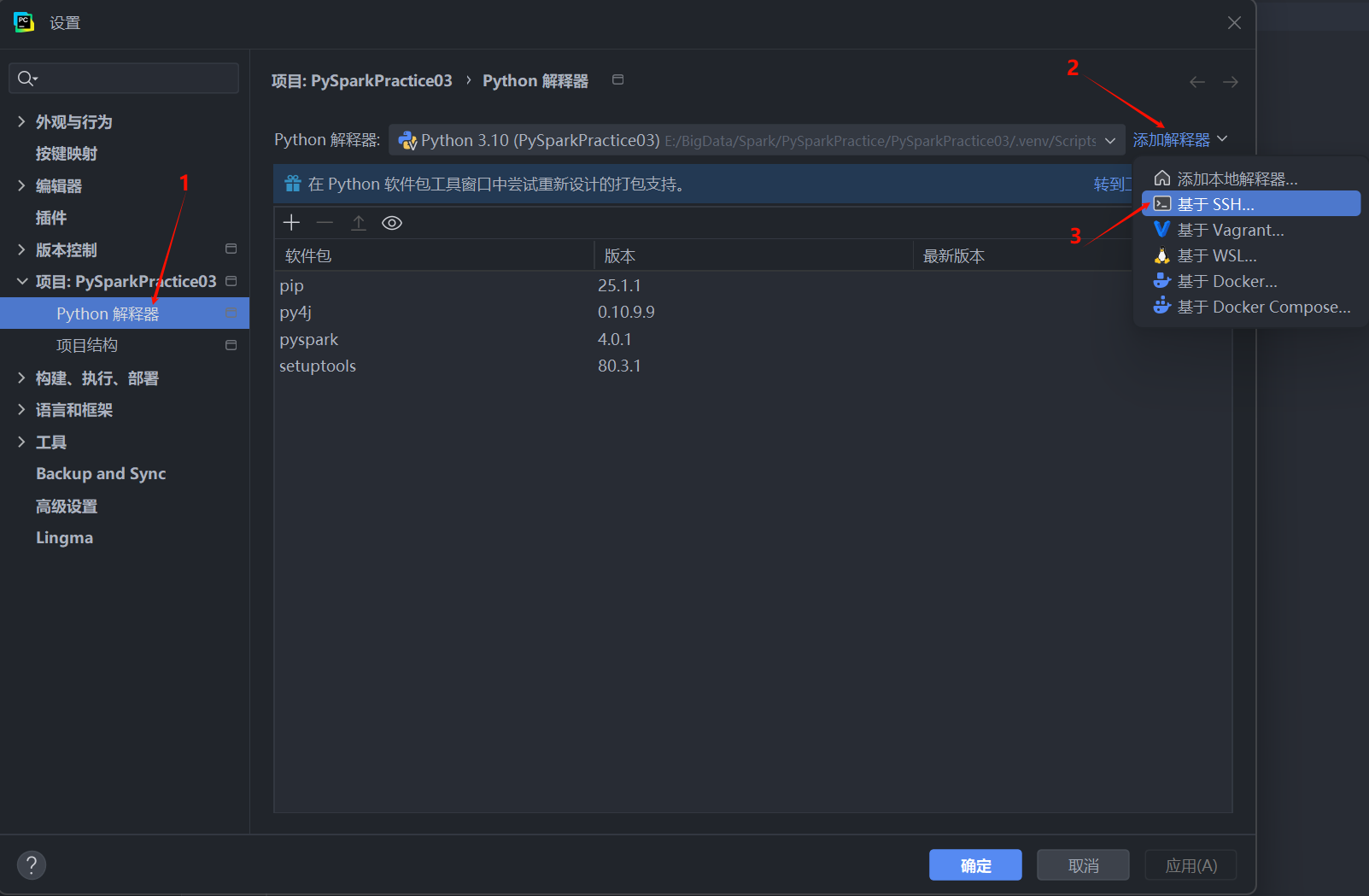
步骤二:添加 SSH 解释器
- 在设置窗口左侧,导航到 “项目 (Project)” -> “Python 解释器 (Python Interpreter)”。
- 点击右上角的齿轮图标,选择 “添加 (Add…)”。
- 在弹出的窗口中,选择 “基于 SSH (On SSH)”。
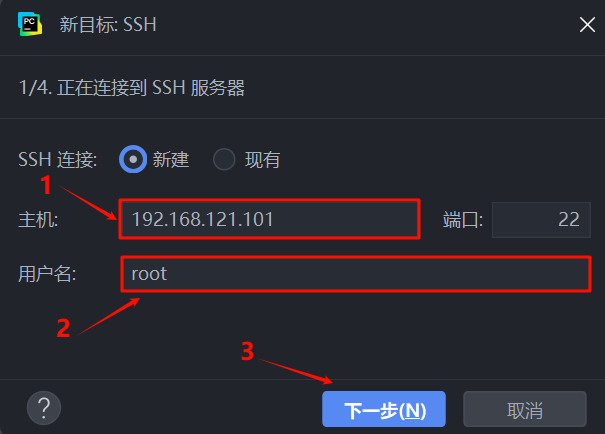
步骤三:配置 SSH 连接信息
- 主机: 输入你的远程 Linux 服务器IP地址,例如
192.168.121.101。 - 用户名: 输入登录服务器的用户名,例如
root。 - 点击 “下一步”。
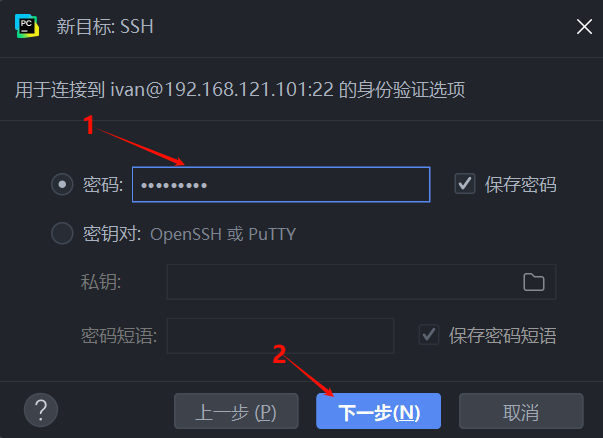
步骤四:输入密码并认证
- 选择 “密码 (Password)” 认证方式,并输入你的服务器密码。
- 点击 “下一步 (Next)”。
PyCharm 会开始连接到 SSH 服务器并进行内省。
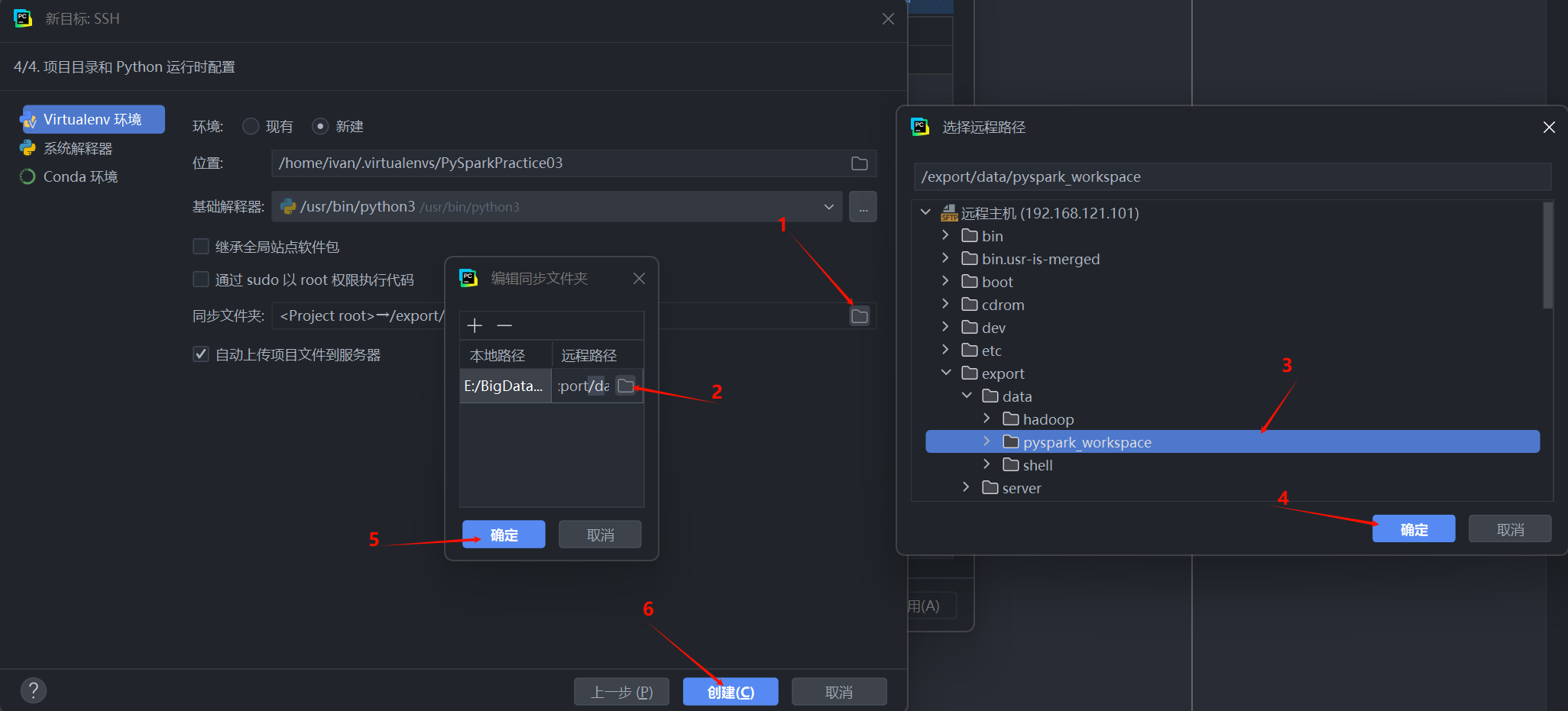
步骤五:配置远程解释器和同步路径
- 解释器路径 (Interpreter): PyCharm 通常会自动检测。你需要确保选择的是你在远程服务器上为 PySpark 准备好的 Conda 环境中的 Python 解释器路径。例如:
/root/anaconda3/envs/pyspark_env/bin/python。 - 同步文件夹 (Sync folders): 这是最关键的一步。它定义了本地项目路径和远程服务器上代码存放路径的映射关系。
- 点击文件夹图标,打开远程路径浏览器。
- 在远程服务器上选择或创建一个工作区目录,例如
/export/data/pyspark_workspace。 - 确认 (OK) 路径映射。
- 点击 “创建 (Create)” 完成配置。
c. 配置远程服务器环境变量 (重要)
为了让 spark-submit 能够正确找到 Python 解释器,我们需要在远程 Linux 服务器上配置 ~/.bashrc 文件。
使用 vi ~/.bashrc 或其他编辑器打开文件,在末尾添加以下内容:
# 根据你的实际JDK安装路径修改
export JAVA_HOME=/usr/lib/jvm/jdk
# 确保Spark的bin目录在PATH中 (如果尚未配置)
# export SPARK_HOME=/path/to/spark
# export PATH=$PATH:$SPARK_HOME/bin# 指定PySpark使用的Python解释器
# 如果你是普通用户(如ivan):
# export PYSPARK_DRIVER_PYTHON=/home/ivan/pyspark_env/bin/python
# export PYSPARK_PYTHON=/home/ivan/pyspark_env/bin/python# 如果你是root用户:
export PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/pyspark_env/bin/python
export PYSPARK_PYTHON=/root/anaconda3/envs/pyspark_env/bin/python
保存文件后,务必执行 source ~/.bashrc 使配置立即生效。
d. 在 PyCharm 中连接远程文件系统 (可选但推荐)
为了方便地查看远程服务器上的文件和上传输入数据,我们可以配置 PyCharm 的 “Big Data Tools” 插件。
步骤一:打开 Big Data Tools 窗口
点击 PyCharm 右侧的 “Big Data Tools” 图标。
步骤二:添加 SFTP 连接
- 点击 “+” 图标,选择 “SFTP”。
- 名称: 给连接起个名字,如
SFTP。 - SSH 配置: 选择我们之前已经创建好的 SSH 连接。
- 点击 “测试连接” 确保一切正常。
- 点击 “确定”。
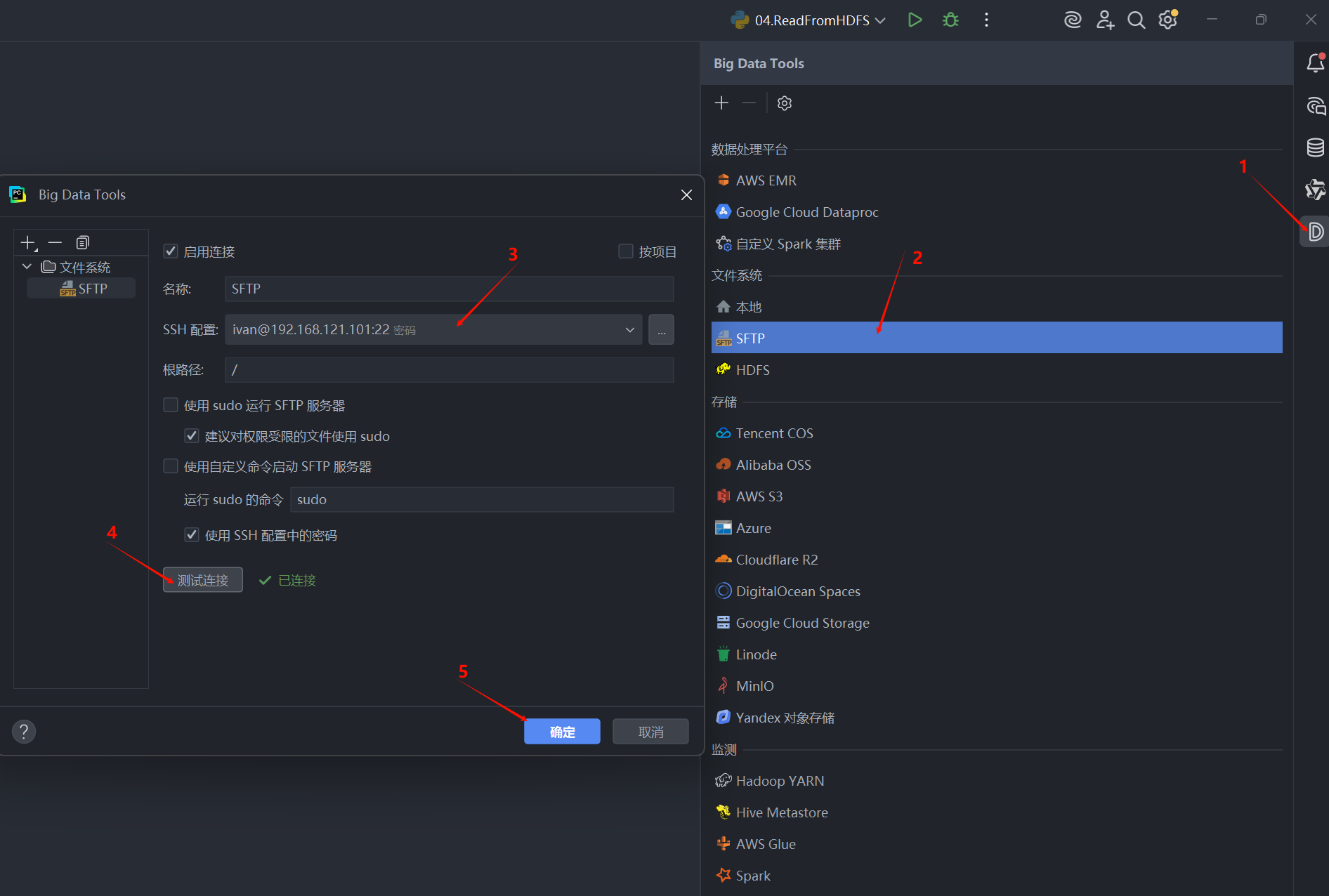
配置完成后,你就可以在 PyCharm 的 Big Data Tools 窗口中直接浏览和操作远程服务器的文件系统了。
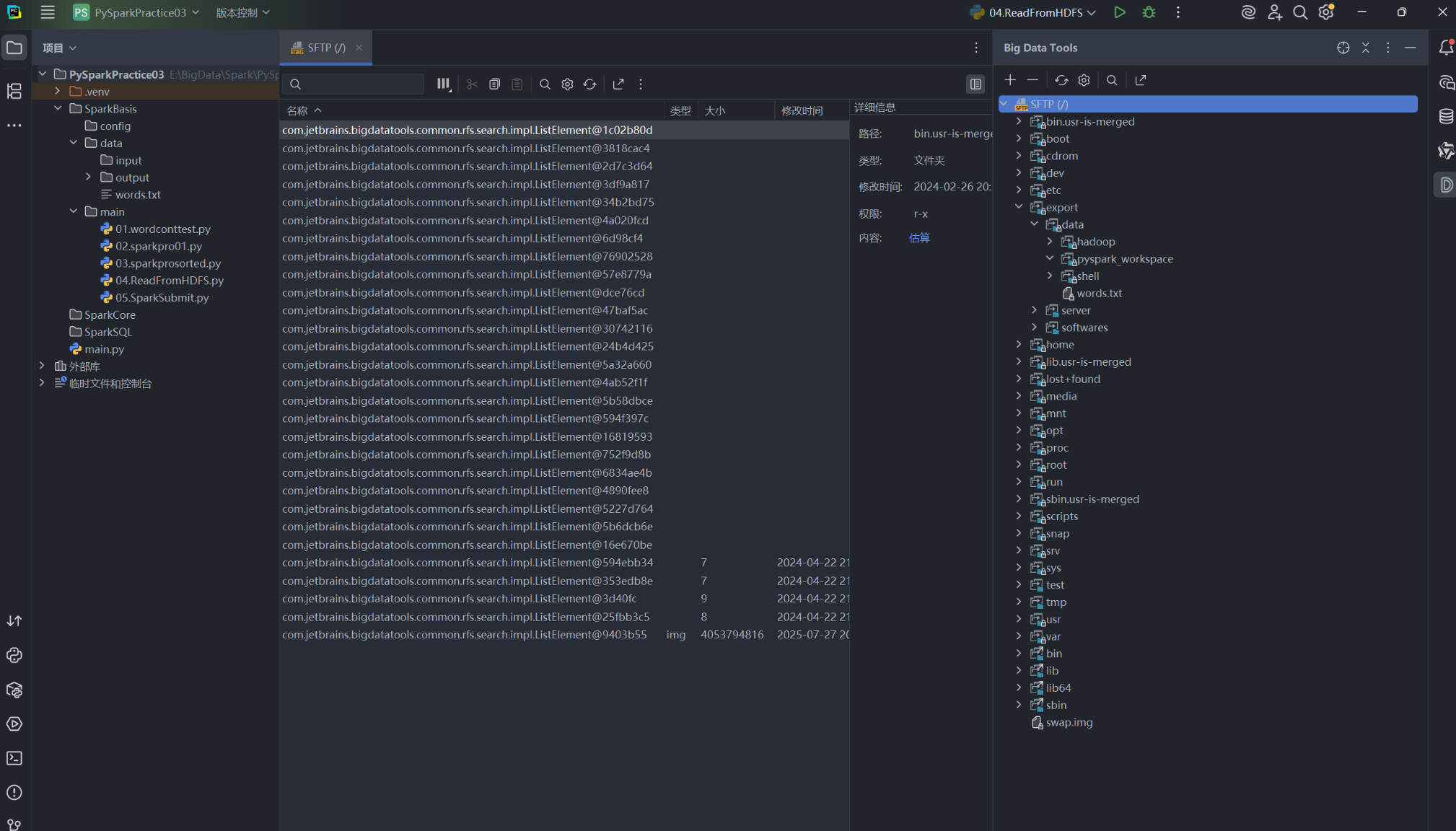
e. 在 PyCharm 中运行远程 Spark 任务
- 同步代码: PyCharm 会自动将你的本地代码同步到之前配置的远程工作区目录。
- 修改代码中的路径: 将
05.SparkSubmit.py(或其他脚本) 中的输入文件路径修改为远程服务器上的绝对路径。
# 修改前: sc.textFile("E:/...")
# 修改后:
textRDD = sc.textFile("/export/data/pyspark_workspace/SparkBasis/data/words.txt")
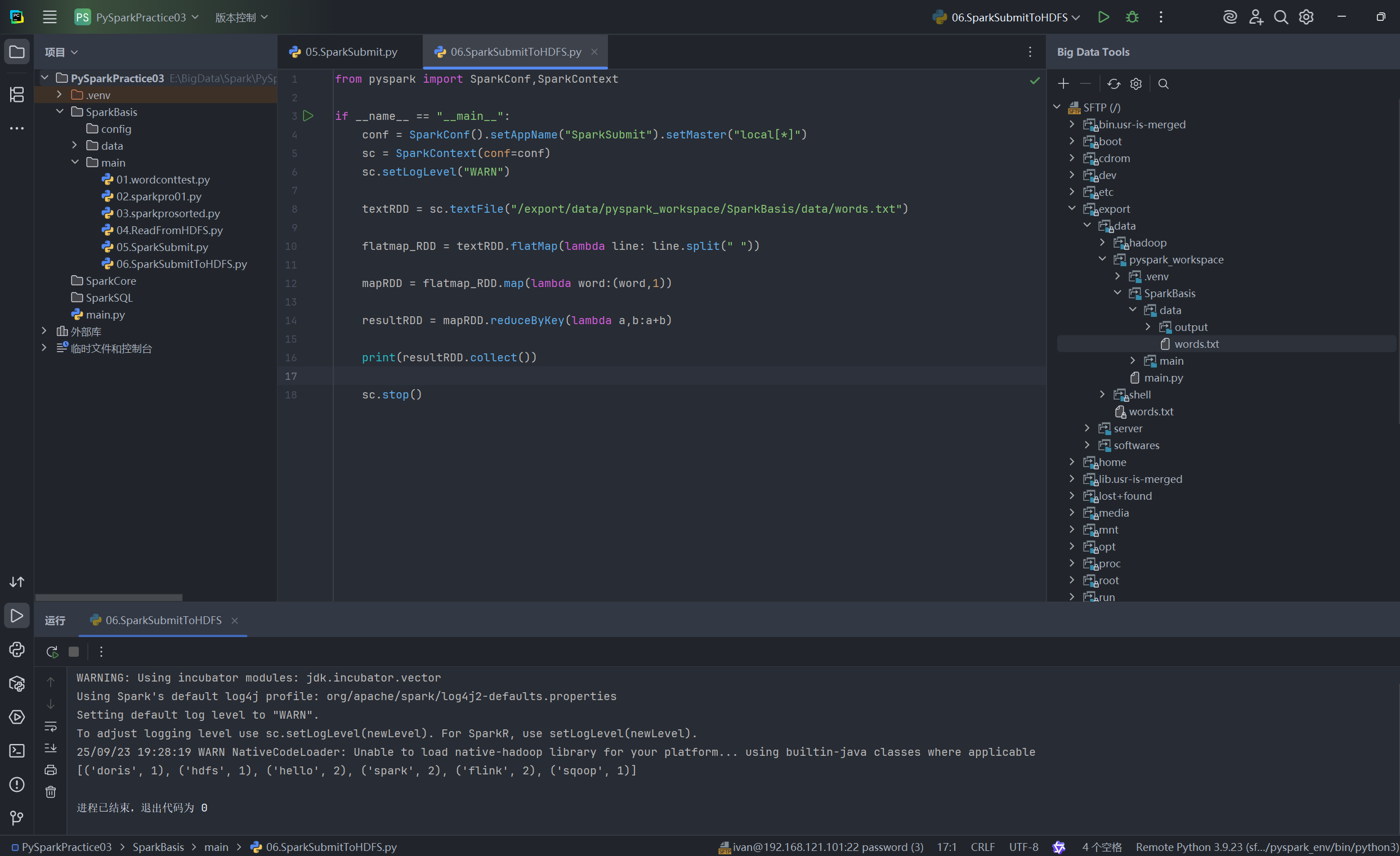
- 运行: 直接在 PyCharm 中右键点击脚本并选择 "运行 "。
PyCharm 会通过 SSH 在远程服务器上执行你的 Python 脚本。由于我们已经配置了远程解释器和环境变量,PySpark 会在远程服务器上正确启动并执行。
你可以在 PyCharm 下方的“运行”窗口中实时看到远程 Spark 任务的日志和最终的输出结果。

日期:2025年9月24日
专栏:Spark教程(PySpark)