面试_常见大厂面试题
1. String对象值修改保持引用不变
String ss= “abc”, 如何将其修改成“abcd”, 并保证ss引用对象不变。
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {String ss = "1234567890";Field field = ss.getClass().getDeclaredField("value");field.setAccessible(true);field.set(ss, "abcd".toCharArray());
}2. 如何分词,分词器
IK分词器:基于Java实现的中文分词器
HanLP : 中文分词, 引入相应依赖
分词方式:基于字典、基于机器学习
3. 倒排索引
普通索引:ID -> 内容
倒排索引:内容 -> ID
示例:文章 -> 分词term -> 排序term dictionary -> term index -> Posting List(文章ID、在文章中出现的偏移量、权重信息TFIDF)
倒排索引好处:适合关键词检索;数据总量可以得到控制;提高查询效率
4. 二叉树
强平衡二叉树(AVL)、弱平衡二叉树(红黑树)
1. AVL相对红黑树平衡的程度更加严格,想通节点的情况下,AVL树的高度<= 红黑树
2. 红黑树中引入的颜色节点概念
3. AVL树的旋转操作比红黑树的旋转操作更耗时
二叉搜索树 与 平衡二叉树
1. 二叉搜索树:节点左边的节点值都比该节点小,右边节点的值都比该节点大
2. 平衡二叉树:也可以叫做平衡二叉搜索树,在二叉搜索树的基础上,规定了节点左右两边的节点的高度差的绝对值不能超过1
5. 设计模式
创建型、结构型、行为型
常用的:工厂模式、单例模式;过滤器模式;策略模式、模板模式
常见的框架或中间件使用的设计模式:

6. 图遍历
深度优先:从一个节点出发,一直沿着边向下深度去找节点,如果找不到则返回上一层找其他节点(类似二叉树的 左中右 遍历)
广度优先:从一个节点出发,向下先把第一层节点遍历完,再去遍历第二层节点,直到遍历到最后一层。(类似二叉树 层次遍历)
7. Maven命令
| 命令 | 作用 | 使用场景 |
|---|---|---|
mvn clean compile | 清理并编译 | 检查代码是否能编译通过 |
mvn clean test | 清理并运行测试 | 本地验证功能 |
mvn clean package | 清理并打包 | 生成可部署的构件, 打成jar包或war包 |
mvn clean install | 清理并安装到本地仓库 | 最常用,准备依赖给其他项目 |
mvn dependency:tree | 分析依赖树 | 解决依赖冲突 |
mvn clean deploy | 清理并部署到远程仓库 | 发布版本 |
8. liunx命令
查看:cd 、 ls 、pwd、file filename.txt、grep
增删改:
- mkdir xx 创建目录
- touch file 创建文件
- mv 、 rm 、cp
- ln -s /path/target link_name 创建软链接
查看文件内容
- cat、vim
- head -n 20 filename //查看前20行
- tail -n 20 filename // 查看后20行
网络命令:
ps -ef | grep '' 、ping
压缩、解压
- tar -czf archive.tar.gz /path # 压缩
- tar -xzf archive.tar.gz # 解压
9. 聊项目
- 项目及主要负责模块
- 项目架构图,自己所处的模块
- 聊聊最优成就感的项目
- 自己最优挑战的项目、难点


10. ES写入数据和查询数据
ES架构简图
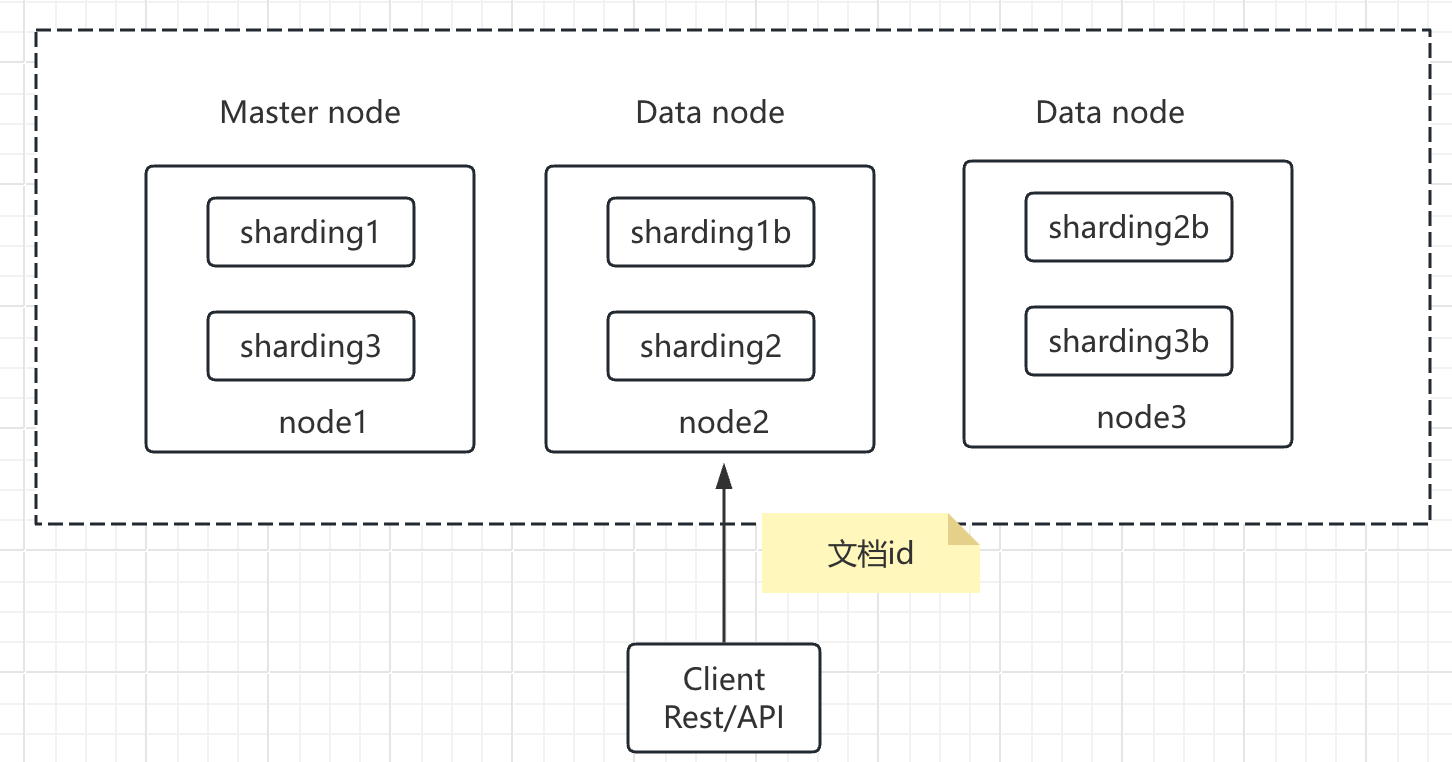
1. 客户端发写数据请求时,可以往任意节点发,这个节点就会成为coordinating node协调节点
2. 协调节点计算 要写入的分片(sharding):计算时采用hash取模的方式计算,按照文档id计算
3. 协调节点就会进行路由,将请求转发给对应的primary sharding所在的dataNode
4. dataNode节点上的primary sharding处理请求,写入数据到索引库,并且将数据同步到对应的replica sharding
5. 等primary sharding和replica sharding都保存到文档之后,返回客户端响应。
查询数据原理:
1. 客户端发请求可以给任意节点,这个节点成为协调节点
2. 协调节点将查询请求广播到每个数据节点,这些数据节点的分片就会处理查询请求
3. 每个分片进行数据查询,将符合条件的数据放到一个队列当中,并将这些数据的 文档ID、节点信息、分片信息都返回给协调点
4. 由协调点将所有的结果进行汇总,并排序
5. 协调节点向包含这些ID分片发送get请求,对应的分片文档数据返回给协调节点,最后协调节点将数据整合返回给客户端。
11. ES部署时优化
1、集群部署优化
- 关于ES的参数,大部分情况下不需要调整,如果由性能问题,最好的办法是安排合理的sharding 布局并且增加节点数量
- 调整ES的一些参数,path.data目录尽量使用SSD(固态硬盘), JVM堆内存大小
2、更合理的sharding布局
让sharding和对应的replica sharding尽量在同一个机房,但是有时候为了容灾的考虑,会特意部署在不同的机房
3、Liunx服务器上的优化策略
不要用root用户;修改虚拟内存大小;修改普通用户可以创建的最大线程数。
ES生态:ELK日志收集解决方案 - filebeat(读log日志) -> logstash -> ElaticsSearch -> kibana、Grafana、自研报表平台
ES使用场景:大数据量的搜索场景, 另外ES也有很强的计算能力,用户画像
12. ES概念
ES:是一个局域Lucene框架的搜索引擎产品。 you know for search, 提供了Restful风格的操作接口。
Lucene:是一个非常搞笑的全检检索引擎框架,java语言开发,提供的jar包。所以不太通用。
ES核心概念:
- 索引index : 关系数据库的table
- 文档document: 关系数据库的一行数据
- 字段field text\keyword\byte: 关系数据库的列
- 映射Mapping : Schema
- 查询方式DSL
- 分片sharding 和副本 replicas