(论文速读)DiffBlender:可组合和通用的多模态文本到图像扩散模型
论文题目:DiffBlender: Composable and versatile multimodal text-to-image diffusion models(可组合和通用的多模态文本到图像扩散模型)
期刊:Expert Systems With Applications(ESWA)
摘要:在本研究中,我们的目标是通过在统一框架内整合文本描述以外的多种模式来增强基于扩散的文本到图像(tt2i)生成模型的能力。为此,我们将广泛使用的条件输入分为三种情态类型:结构、布局和属性。我们提出了一个多模态T2I扩散模型DiffBlender,它能够在单个架构中处理所有三种模态。重要的是,这是在不修改预训练扩散模型参数的情况下实现的,因为只有一小部分组件被更新。我们的方法通过与现有条件生成方法进行广泛的定量和定性比较,为多模态生成设定了新的基准。我们证明了DiffBlender有效地集成了多个信息源,并支持详细图像合成的各种应用。
源码链接:https://github.com/sungnyun/diffblender
引言
一个能同时理解草图、布局和色彩的AI图像生成器
文本生成图像(T2I)技术正在快速发展,但如何精确控制生成结果仍是一大挑战。最近发表在《Expert Systems With Applications》上的DiffBlender论文提出了一个创新解决方案,让我们能够通过多种方式同时控制图像生成。
🎯 核心问题:现有方法的三大痛点
1. 单一模态的局限性
现有的T2I模型大多只支持一种控制方式:
- ControlNet 主要依赖结构信息(草图、深度图)
- GLIGEN 主要处理布局信息(边界框、关键点)
- T2I-Adapter 专注于特定类型的视觉条件
这种单一性严重限制了用户的创作灵活性。
2. 多模态支持成本高昂
想要支持多种控制方式,现有方法通常需要:
- 为每个模态训练独立的适配器
- 巨大的计算和存储开销
- 复杂的模型管理和部署
3. 模态间冲突难以解决
当同时使用多种条件时:
- 不同模态可能产生冲突的指导信号
- 难以平衡各模态的影响权重
- 生成质量往往不如单模态情况
🚀 DiffBlender的创新解决方案
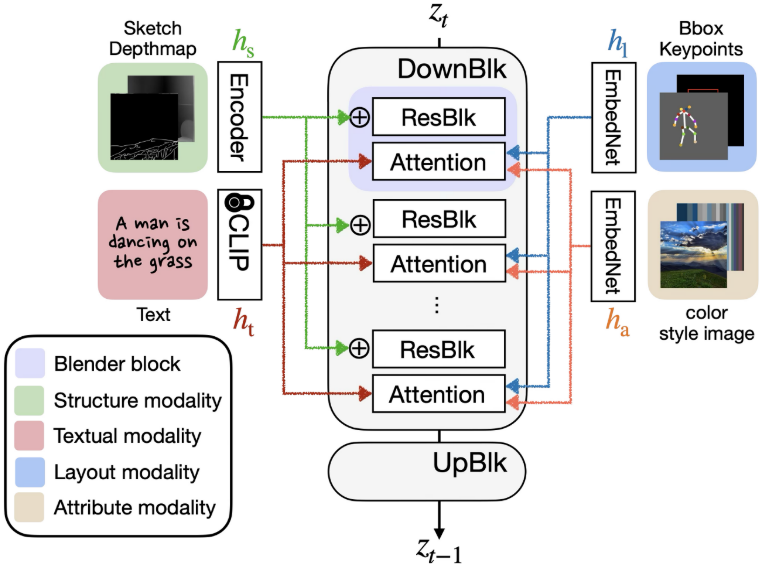
三元模态分类框架
DiffBlender首先重新定义了控制模态,将输入条件分为三大类:
🎨 结构模态(Structure)
- 草图、边缘图、深度图
- 提供精确的形状和构图指导
- 适合需要精细控制的场景
📍 布局模态(Layout)
- 边界框、关键点、空间坐标
- 控制对象的位置和姿态
- 更容易编辑和操作
🌈 属性模态(Attribute)
- 颜色调色板、风格参考图
- 控制整体外观和美学风格
- 影响全局视觉特征
统一架构设计
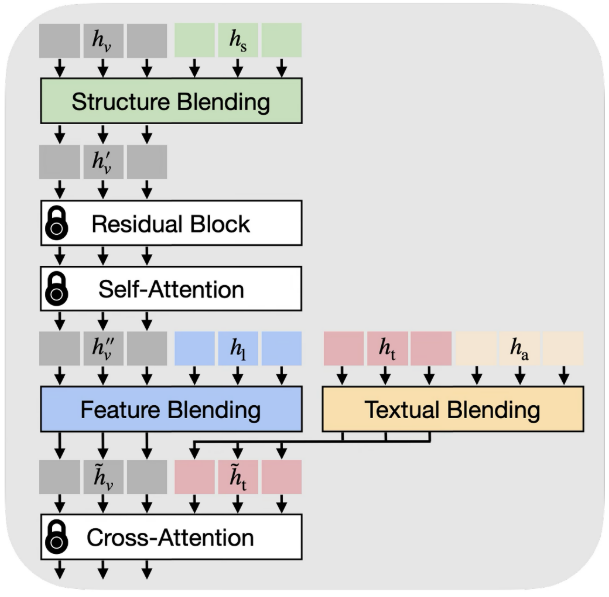
DiffBlender在Stable Diffusion基础上设计了创新的"Blender Block":
# Blender Block的核心设计理念
class BlenderBlock:def __init__(self):self.sbm = StructureBlendingModule() # 处理结构模态self.fbm = FeatureBlendingModule() # 处理布局模态 self.tbm = TextualBlendingModule() # 处理属性模态def forward(self, visual_tokens, text_tokens, conditions):# 结构混合:直接融入视觉特征visual_tokens = self.sbm(visual_tokens, conditions.structure)# 特征混合:通过自注意力整合布局visual_tokens = self.fbm(visual_tokens, conditions.layout)# 文本混合:将属性投影到文本空间text_tokens = self.tbm(text_tokens, conditions.attribute)return visual_tokens, text_tokens
模式特定引导(MSG)
DiffBlender的另一项重要创新是模式特定引导,它扩展了传统的分类器自由引导:
传统CFG的局限:
- 对所有条件应用相同的引导强度
- 无法独立控制不同模态的影响
MSG的优势:
- 可以独立调节每种模态的影响力
- 减少模态间的冲突
- 提供更精细的控制能力
# 模式特定引导的实现思路
def mode_specific_guidance(noise_pred, condition_m, gamma):# 计算移除特定模态m后的噪声预测noise_pred_without_m = model(input, conditions_except_m)# 计算该模态的引导方向direction = noise_pred - noise_pred_without_m# 应用模态特定的引导强度return noise_pred + gamma * direction
🎯 技术细节深度解析


1. 结构混合模块(SBM)
处理图像形式的结构输入:
- 使用ResNet编码器处理草图、深度图
- 在四个下采样层级进行特征融合
- 通过加法运算直接混合到视觉latent中
def structure_blending(visual_latent, structure_inputs):structure_features = []for structure in structure_inputs:encoded = resnet_encoder(structure)structure_features.append(encoded)return visual_latent + sum(structure_features)
2. 特征混合模块(FBM)
处理token化的布局信息:
- 将边界框、关键点转换为token
- 使用自注意力机制进行特征融合
- 只保留视觉token位置的输出
def feature_blending(visual_tokens, layout_tokens, beta_l):# 连接视觉token和布局tokencombined_tokens = torch.cat([visual_tokens, layout_tokens], dim=1)# 自注意力融合attended = self_attention(combined_tokens)# 只保留视觉token部分,应用门控机制blended_visual = visual_tokens + torch.tanh(beta_l) * attended[:visual_length]return blended_visual
3. 文本混合模块(TBM)
处理全局属性信息:
- 将颜色、风格信息投影到文本空间
- 避免与文本提示产生冲突
- 通过门控机制控制融合强度
def textual_blending(text_tokens, attribute_tokens, beta_t):# 连接文本token和属性tokencombined_tokens = torch.cat([text_tokens, attribute_tokens], dim=1)# 自注意力处理attended = self_attention(combined_tokens)# 只保留文本token部分blended_text = text_tokens + torch.tanh(beta_t) * attended[:text_length]return blended_text
📊 实验结果与性能分析
定量评估结果
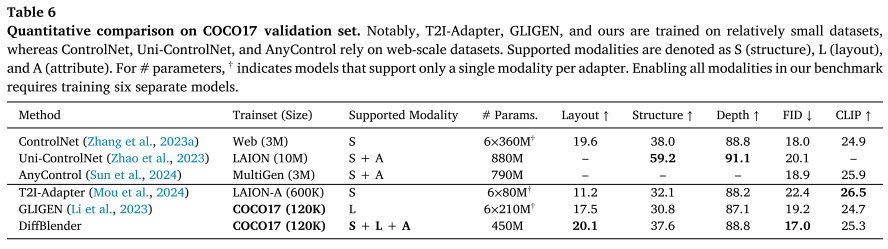

在COCO2017验证集上的表现:
| 指标 | DiffBlender | ControlNet | GLIGEN | T2I-Adapter |
|---|---|---|---|---|
| FID↓ | 17.0 | 18.0 | 19.2 | 22.4 |
| Layout↑ | 20.1 | 19.6 | 17.5 | 11.2 |
| Structure↑ | 37.6 | 38.0 | 30.8 | 32.1 |
| CLIP↑ | 25.3 | 24.9 | 24.7 | 26.5 |
关键优势:
- 仅使用450M参数就超越了需要多个适配器的方法
- 在相对小的数据集(COCO2017,12万图片)上训练
- 同时在多个指标上取得最佳或接近最佳表现
用户体验评估
通过42名用户的主观评估:
颜色控制准确性
- 有颜色条件:81.9%
- 无颜色条件:18.1%
风格反映准确性
- DiffBlender:88.6%
- PAIR-diffusion:11.4%
整体用户意图反映
- DiffBlender:65.7%
- ControlNet:18.6%
- T2I-Adapter:15.7%
模式特定引导效果
- 能改变输出:96.8%
- 改变合理:95.2%
- 保持其他模态:97.6%
消融实验分析
训练策略影响:
| 策略 | 早期阶段 | 后期阶段 | Layout分数 | FID |
|---|---|---|---|---|
| 同时训练 | S+L+A | S+L+A | 13.1 | 14.8 |
| 稀疏到密集 | L+A | S+L+A | 15.8 | 15.0 |
| 推荐策略 | L+A | S | 15.6 | 14.1 |
模块重要性验证:
- 移除结构混合模块:Layout分数从19.7降至15.8
- 移除文本混合模块:属性控制效果显著下降
- 各模块都对最终性能有重要贡献
🎨 实际应用场景
1. 内容创作工作流
传统方式:
- 画家先画草图 → 确定构图
- 设计师标注位置 → 布局规划
- 调色师选择配色 → 确定风格
- 反复修改和沟通
DiffBlender方式:
- 输入简单草图定义基本形状
- 用边界框指定对象精确位置
- 选择调色板和参考风格
- 一次生成,精确控制
2. 游戏资产生成
场景设计:
- 用深度图定义地形结构
- 用边界框放置建筑和道具
- 用色彩方案适应不同时段和天气
角色生成:
- 用关键点控制姿态和动作
- 用草图定义细节和装饰
- 用参考图统一美术风格
3. 产品原型设计
UI设计:
- 线框图定义界面结构
- 坐标约束确定元素位置
- 品牌色彩系统保持一致性
产品外观:
- 3D模型轮廓定义形状
- 材质参考确定质感
- 配色方案适应品牌调性
🔧 部署和使用建议
硬件要求
最低配置:
- GPU:8GB显存(如RTX 3070)
- CPU:8核心处理器
- 内存:32GB RAM
- 存储:SSD 100GB
推荐配置:
- GPU:24GB显存(如RTX 4090)
- CPU:16核心处理器
- 内存:64GB RAM
- 存储:NVMe SSD 500GB
超参数调优
推理时关键参数:
# 分类器自由引导强度
cfg_scale = 5.0# 模式特定引导强度(范围建议)
msg_structure = [-1.5, 1.5] # 结构模态敏感,范围较小
msg_layout = [-3.0, 3.0] # 布局模态,标准范围
msg_attribute = [-3.0, 3.0] # 属性模态,标准范围# 调度系数(控制不同阶段的条件强度)
alpha_s = 0.7 # 结构模态,全程保持
alpha_l = 1.0 if step < 0.3*total_steps else 0.0 # 布局模态,前30%步骤
alpha_a = 1.0 if step < 0.3*total_steps else 0.0 # 属性模态,前30%步骤
训练时数据增强:
# 条件随机丢弃率
structure_drop_rate = 0.5
layout_drop_rate = 0.1
attribute_drop_rate = 0.1
text_drop_rate = 0.1# 结构输入掩码策略
segmentation_mask_prob = 0.7 # 使用分割掩码的概率
foreground_mask_prob = 0.5 # 掩码前景vs背景的概率
🚧 当前局限和改进方向
已知局限性
1. 模态冲突问题 当提供的条件彼此矛盾时(如草图显示汽车但文本说"飞机"),模型可能产生不一致的结果。
解决方案:
- 改进条件一致性检测
- 增强跨模态语义对齐
- 提供冲突提醒机制
2. 复杂场景处理能力 对于包含大量细节和对象的复杂场景,控制精度可能下降。
改进方向:
- 层次化场景分解
- 多尺度特征融合
- 注意力机制优化
3. 实时生成性能 当前模型在消费级硬件上的生成速度有待提升。
优化策略:
- 模型蒸馏和压缩
- 推理加速技术
- 边缘计算适配
未来发展方向
短期目标(6-12个月):
- 支持视频生成的时序一致性
- 增加更多控制模态(如音频、手势)
- 优化移动端部署性能
中期规划(1-2年):
- 与3D生成技术结合
- 支持交互式实时编辑
- 多模态prompt工程工具
长期愿景(3-5年):
- 通用创意AI助手
- AR/VR环境集成
- 跨模态创作生态系统
📚 相关资源和工具
开源代码和模型
- GitHub仓库: https://github.com/sungnyun/diffblender
- 预训练模型: 基于Stable Diffusion v1.4
- 数据集: COCO2017 (训练), 支持自定义数据集
社区和文档
- 论文链接: Expert Systems With Applications 2026
- 技术文档: 详细的API文档和使用指南
- 社区论坛: 用户交流和技术支持
相关工具链
- 数据预处理: PiDiNet (草图), MiDaS (深度), CLIP (特征)
- 评估工具: FID计算, CLIP分数, 自定义评估指标
- 部署框架: Docker容器, Kubernetes集群, 云端API
💡 最佳实践和使用技巧
1. 条件设计原则
结构条件:
- 草图应该简洁明了,突出主要形状
- 深度图要有明显的前后层次
- 避免过度复杂的线条和细节
布局条件:
- 边界框不要重叠过多
- 关键点标注要准确,特别是人体姿态
- 合理利用空间,避免过度拥挤
属性条件:
- 颜色调色板应该和谐统一
- 参考图风格要与目标一致
- 避免色彩过于饱和或对比过强
2. 模式特定引导调优
保守策略(适合新手):
# 较小的引导强度,更稳定的结果
msg_scales = {'structure': 0.5,'layout': 1.0, 'attribute': 1.0
}
激进策略(适合专家):
# 更大的引导强度,更强的控制力
msg_scales = {'structure': 1.2,'layout': 2.5,'attribute': 2.0
}
动态调整:
# 根据生成步骤动态调整
def dynamic_msg_scale(step, total_steps, base_scale):# 前期强引导,后期弱引导ratio = 1.0 - (step / total_steps)return base_scale * (0.5 + 0.5 * ratio)
3. 多模态组合策略
风格迁移场景:
- 结构:源图像的边缘或深度图
- 布局:保持原始对象位置
- 属性:目标风格的参考图
创意设计场景:
- 结构:简单草图定义主体
- 布局:精确的位置和姿态控制
- 属性:品牌色彩和设计语言
内容编辑场景:
- 结构:局部区域的细节草图
- 布局:新增或移动的对象位置
- 属性:保持整体色调一致
🎊 结语
DiffBlender代表了多模态AI图像生成技术的重要里程碑。它不仅解决了现有方法的技术局限,更重要的是为创作者提供了前所未有的控制灵活性和创作自由度。
技术价值:
- 统一的多模态架构设计
- 高效的参数利用和训练策略
- 创新的模式特定引导机制
应用价值:
- 降低了专业创作的门槛
- 提高了设计迭代的效率
- 扩展了AI辅助创作的边界
未来意义: 随着技术的不断完善和应用场景的扩展,DiffBlender这样的多模态生成工具将成为数字创作的核心基础设施,推动创意产业向着更加智能化、个性化的方向发展。
每一次技术突破都是为了更好地释放人类的创造力。DiffBlender通过其优雅的多模态设计和强大的控制能力,正在让这个愿景一步步成为现实。