深度学习----ResNet(残差网络)-彻底改变深度神经网络的训练方式:通过残差学习来解决深层网络退化问题(附PyTorch实现)
时间:2025年9月23日 17:37:05 星期二
作者:AI技术爱好者 Sunhen_Qiletian
目录
一、ResNet简介与核心贡献(引言)
二、深层网络的痛点:梯度消失与梯度爆炸
梯度消失/爆炸的三大诱因
1. 激活函数特性限制
2. 层数过深导致的连乘效应
3. 初始权重不合理
三、ResNet的解决方案:残差块与跳跃连接
1.残差块的设计逻辑
2.关键技术:Batch Normalization(批量归一化)
3.不同层数的残差网络模型设计:
四、ResNet核心代码实现(PyTorch)
1. 环境准备与数据加载
2. 数据预处理与加载
3. 残差块(ResBlock)定义
4. 完整ResNet模型定义
5. 训练与测试函数
6. 模型训练与结果可视化
五、总结与扩展
一、ResNet简介与核心贡献(引言)
ResNet(Residual Network,残差网络)由微软亚洲研究院的何凯明团队于2015年提出,凭借其突破性的残差学习思想,在当年ImageNet竞赛中一举斩获分类任务第一名、目标检测第一名,并在COCO数据集的目标检测与图像分割任务中同样登顶。
与传统CNN的改进不同,ResNet并未颠覆卷积神经网络的底层算法原理,而是通过逻辑上的网络结构调整(引入残差块与跳跃连接),有效解决了深层网络的“退化问题”(即层数增加时准确率不升反降的现象)。其核心思想“残差学习”甚至被迁移到自然语言处理(NLP)任务中(如文本分类、机器翻译),显著提升了模型训练效率与性能。
二、深层网络的痛点:梯度消失与梯度爆炸
在理解ResNet的改进前,我们需要先明确深层网络训练的两大核心障碍:梯度消失与梯度爆炸。当网络层数过深时,反向传播的梯度在逐层传递中会因连乘操作(链式法则)逐渐趋近于0(消失)或急剧增大(爆炸),导致模型无法有效学习,训练结果失控。
梯度消失/爆炸的三大诱因
1. 激活函数特性限制
早期CNN常用Sigmoid作为激活函数,但其导数最大值仅为0.25(输入绝对值较大时趋近于0)。深层网络中,梯度经多层Sigmoid激活后会被严重衰减,导致“梯度消失”。
在原来我们采取的措施是把sigmoid函数换成Relu函数:
| 特性 | Sigmoid | ReLU |
|---|---|---|
| 数学表达式 | f(x)=1+e−x1 | f(x)=max(0,x) |
| 输出范围 | (0,1) | [0,+∞) |
| 导数特性 | (0,0.25],大输入时接近0 | 正区间导数为1,负区间导数为0 |
| 计算效率 | 指数运算,成本较高 | 仅比较运算,高效 |
| 零中心输出 | 否(输出恒正) | 否(输出非负) |
| 稀疏激活 | 否(输出稠密) | 是(约50%神经元失活) |
| 主要问题 | 梯度消失、输出非零中心 | 死亡ReLU(神经元永久失活) |
| 适用场景 | 二分类输出层(概率输出) | 隐藏层(深层CNN/大模型) |
总结:现代CNN普遍采用ReLU(或其变体)替代Sigmoid,缓解梯度消失问题。
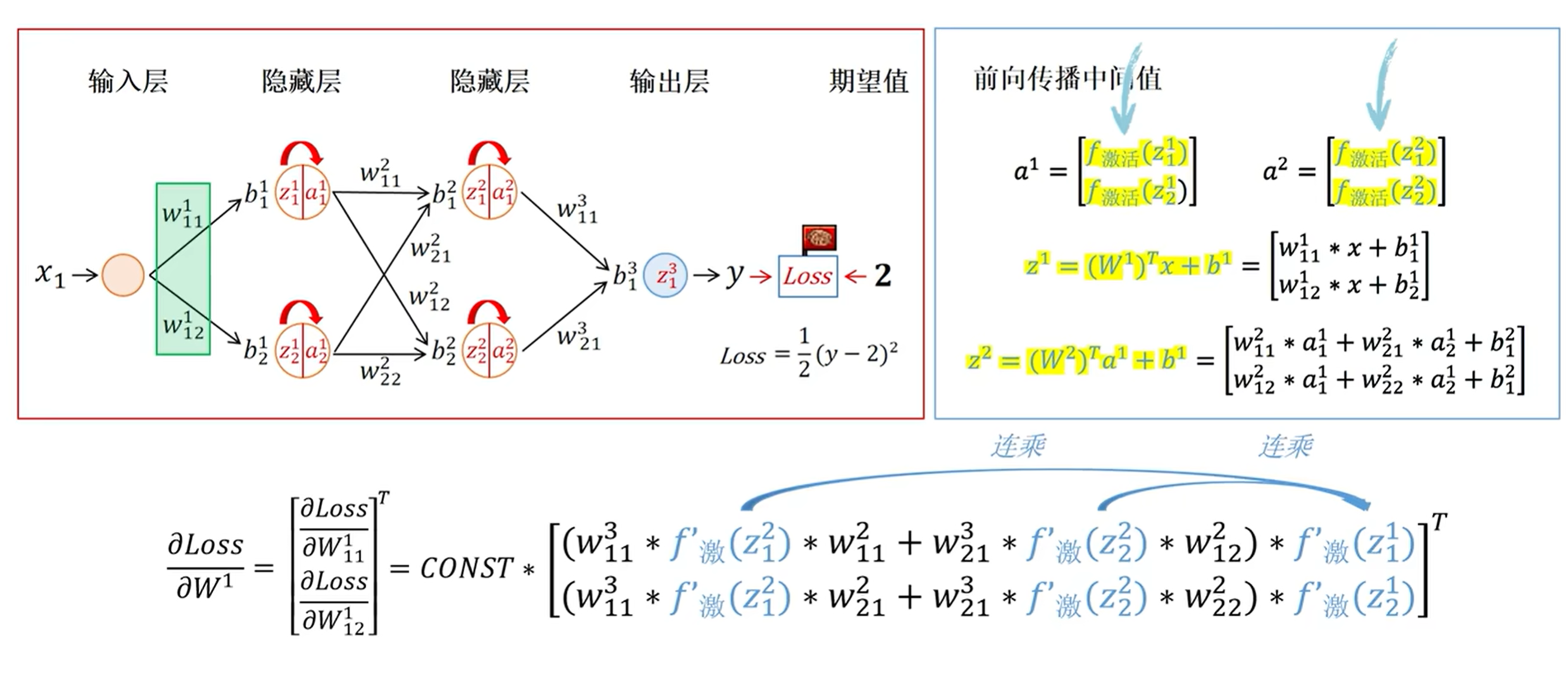
2. 层数过深导致的连乘效应
当我们初始化梯度小于1或者大于1的时候,
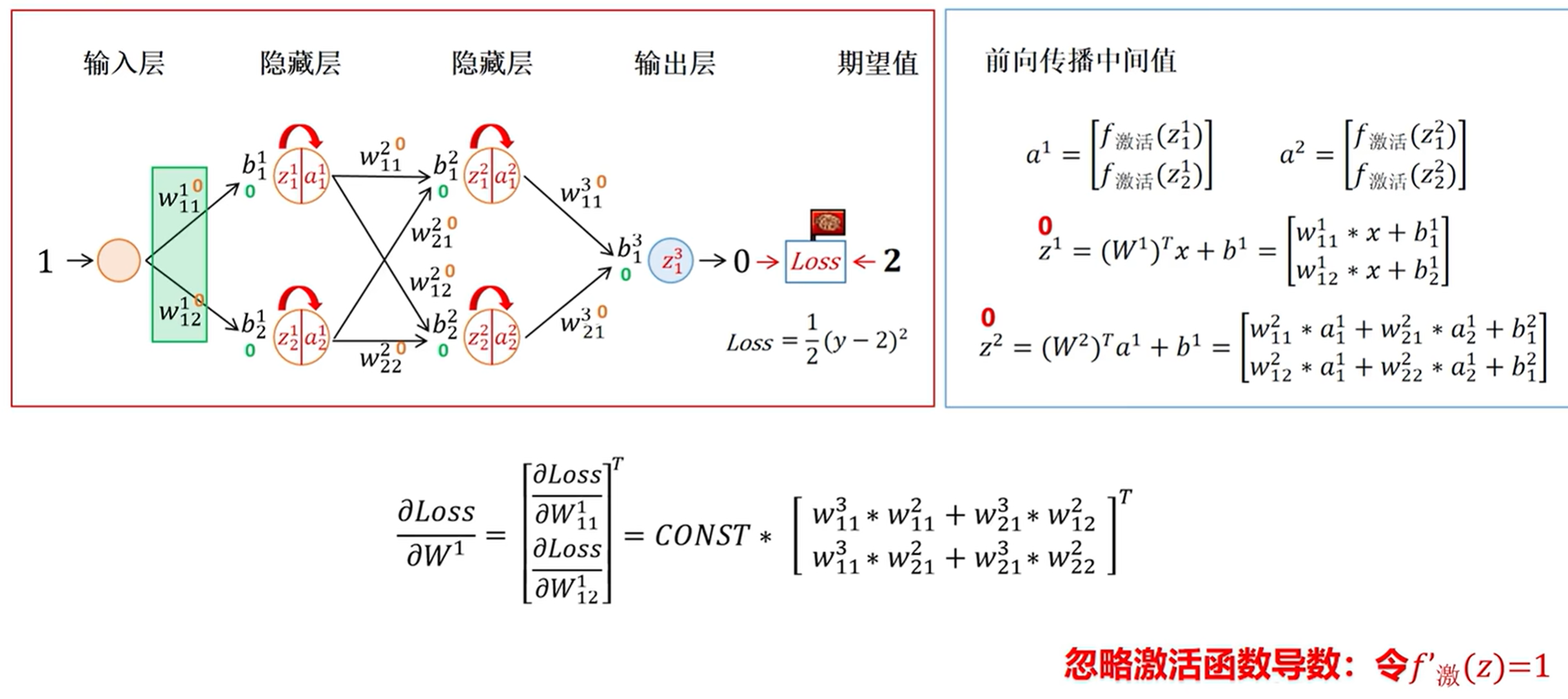
我们梯度更新的时候参数都是连乘的,如果我们初始化参数小于1,或者小于1,这样经过连乘就会产生梯度消失或者梯度爆炸的情况。
总结:假设网络初始化权重w的绝对值均小于1,反向传播时梯度会因多次连乘(如∏w)指数级衰减;若w绝对值大于1,则梯度会指数级增长,最终引发梯度爆炸。
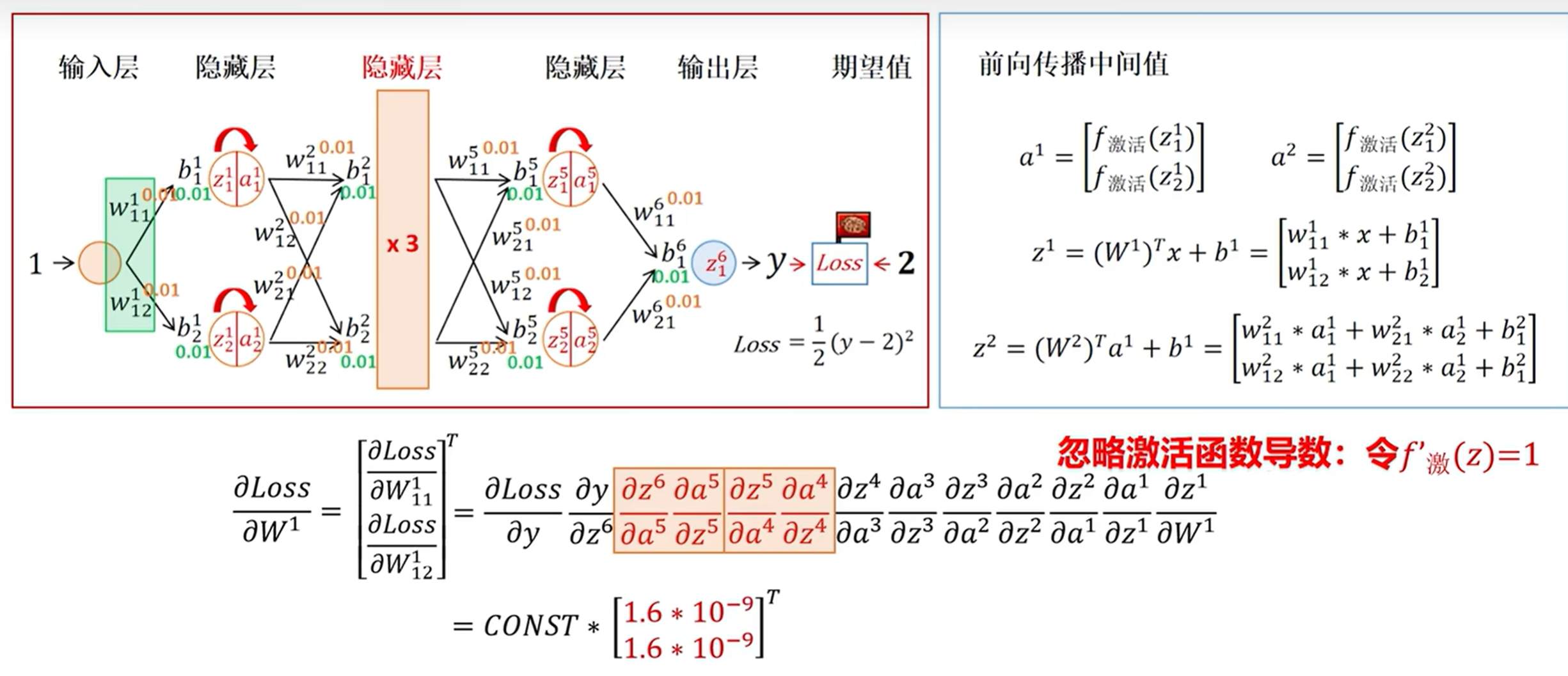
3. 初始权重不合理

例如这个取0.01,然后得到的值就会非常低了。

若初始权重过小(如0.01),梯度传递时会被逐层削弱;若初始权重过大,则可能导致梯度爆炸。
三、ResNet的解决方案:残差块与跳跃连接
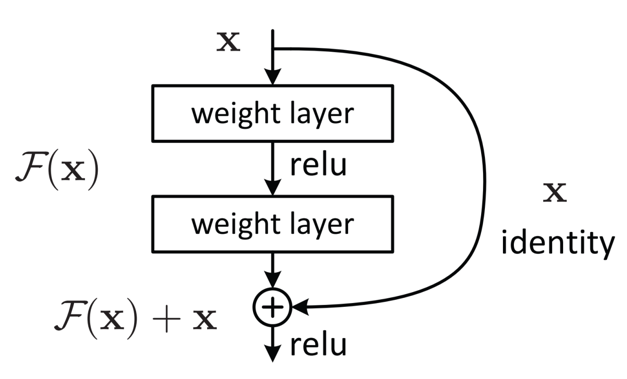
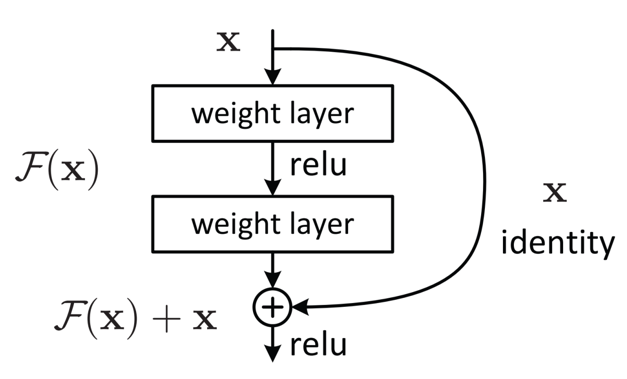
ResNet的核心创新是残差块(Residual Block),其通过引入“跳跃连接(Skip Connection)”直接将输入x传递到输出端,使网络学习“残差映射”而非原始映射。
1.残差块的设计逻辑
传统网络的优化目标是学习映射H(x),而ResNet让网络学习残差映射F(x)=H(x)−x,最终输出为H(x)=F(x)+x。
若H(x)难以优化(如梯度消失导致无法更新),残差块允许通过“跳跃连接”直接保留原始输入x(即令F(x)=0),避免网络性能随层数增加而退化。
2.关键技术:Batch Normalization(批量归一化)
ResNet在每一层卷积后引入BatchNorm,通过对层输入进行归一化(均值0,方差1),减少内部协变量偏移(Internal Covariate Shift),稳定梯度传播,间接缓解梯度消失/爆炸问题。
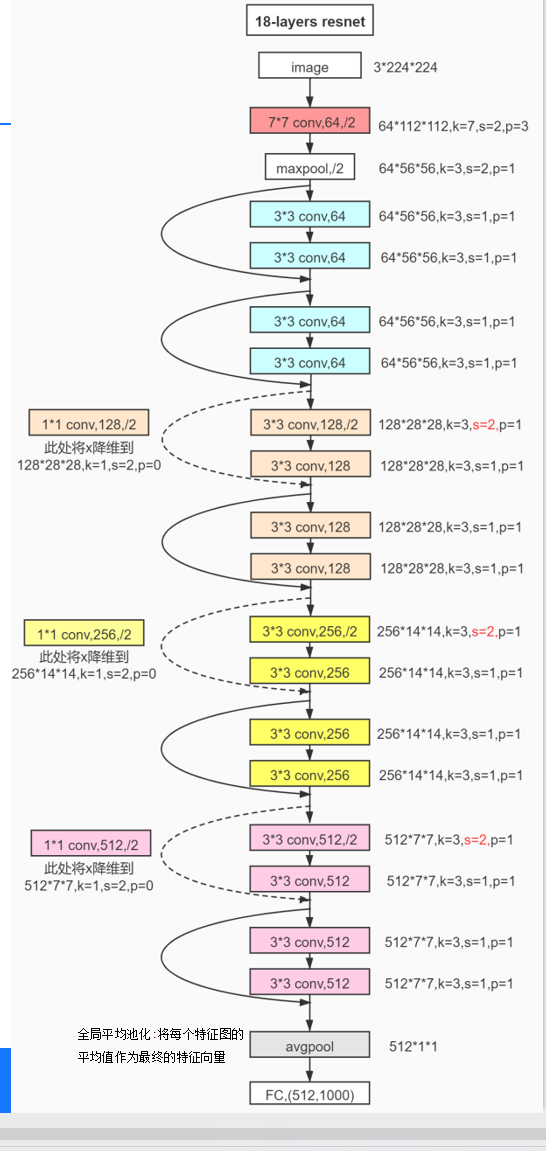
通俗解释:
ResNet在每一层都进行了Batch Normalization,把每一层的梯度进行了归一化。
那么对于梯度消失的或者梯度爆炸的,我们可以把那一层W设置为0,那么这一层就影响不到我们的原本的性能了。然后再加上了我们的副本X,对结果就没有影响了。
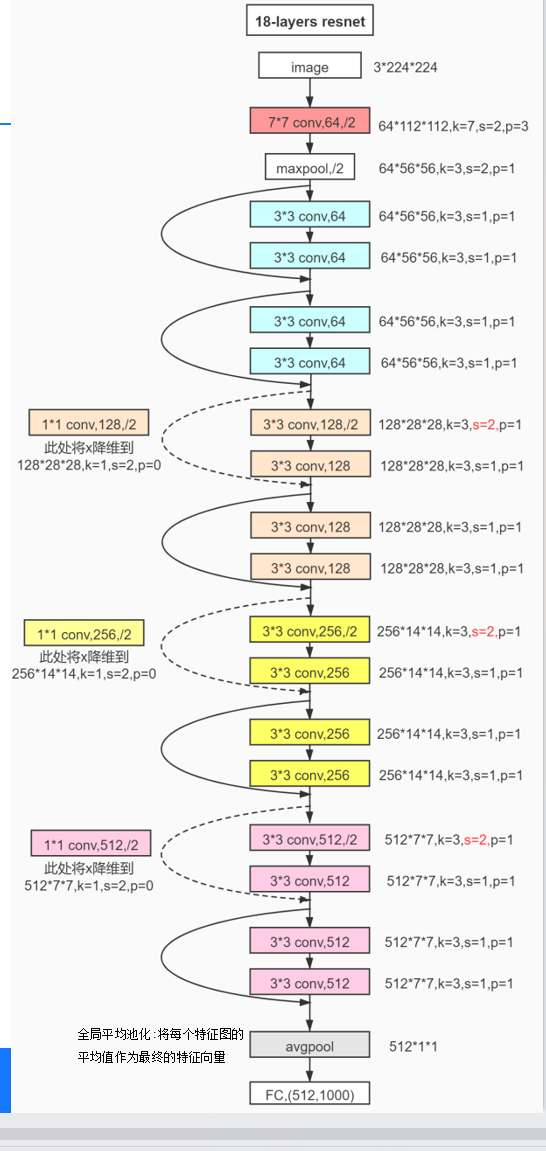
放大看就是这样的。我们这里引入一个残差块,来保存一个副本X,然后如果我这里如果把模型训练坏了,我再进行参数调整的时候,我们可以把这块参数设置为0,就是把跳跃的那一段给省略掉,也不至于让我们的模型更差。所以可以总结为,随着网路层数的增加,不应当让我们的网络性能变的更差。
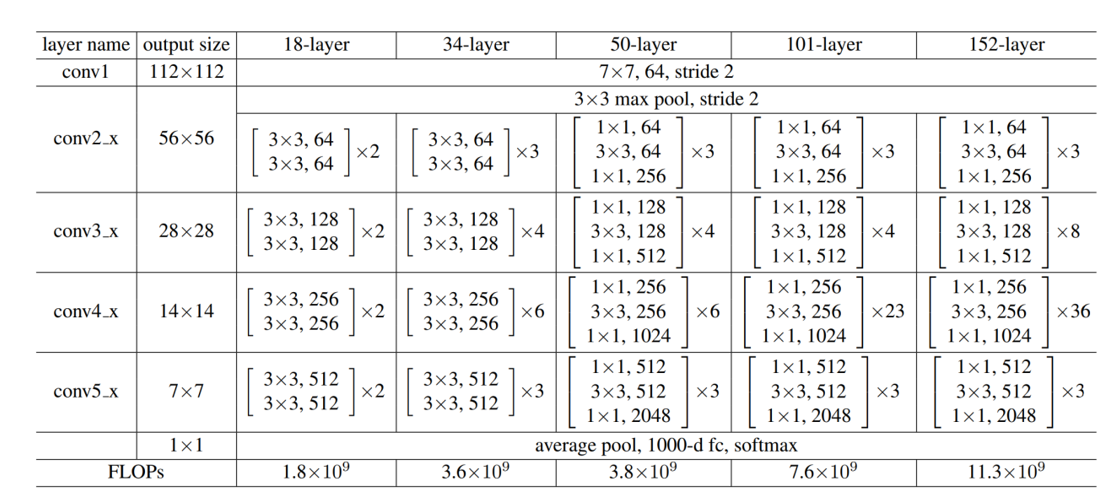
3.不同层数的残差网络模型设计:
四、ResNet核心代码实现(PyTorch)
以下是基于PyTorch的ResNet实现,以MNIST数据集分类任务为例,包含数据加载、模型定义、训练与测试全流程。
1. 环境准备与数据加载
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
from torch.optim.lr_scheduler import ReduceLROnPlateau# 打印PyTorch版本与设备信息
print("PyTorch版本:", torch.__version__)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("当前设备:", device)2. 数据预处理与加载
# 加载MNIST数据集
training_data = datasets.MNIST(root='./data', train=True, download=True, transform=ToTensor()
)
test_data = datasets.MNIST(root='./data', train=False, download=True, transform=ToTensor()
)# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32, shuffle=False)3. 残差块(ResBlock)定义
class ResBlock(nn.Module):def __init__(self, channels_in):super().__init__()# 卷积层1:输入通道->30通道,5x5卷积核,填充2保持尺寸self.conv1 = nn.Conv2d(channels_in, 30, kernel_size=5, padding=2)# 卷积层2:30通道->输入通道,3x3卷积核,填充1保持尺寸self.conv2 = nn.Conv2d(30, channels_in, kernel_size=3, padding=1)def forward(self, x):out = self.conv1(x) # 第一层卷积out = nn.ReLU()(out) # ReLU激活out = self.conv2(out) # 第二层卷积out = nn.ReLU()(out) # ReLU激活# 跳跃连接:输出与原始输入相加后再次激活return nn.ReLU()(out + x)4. 完整ResNet模型定义
class ResNet(nn.Module):def __init__(self):super().__init__()# 初始卷积层self.conv1 = nn.Conv2d(1, 20, kernel_size=5, padding=2) # 1通道->20通道self.conv2 = nn.Conv2d(20, 40, kernel_size=3, padding=1) # 20通道->40通道self.conv3 = nn.Conv2d(40, 80, kernel_size=3, padding=1) # 40通道->80通道self.conv4 = nn.Conv2d(80, 160, kernel_size=3, padding=1)# 80通道->160通道# 最大池化层(用于下采样)self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)# 残差块(对应不同通道数)self.resblock1 = ResBlock(channels_in=20)self.resblock2 = ResBlock(channels_in=40)self.resblock3 = ResBlock(channels_in=80)# 全连接分类层self.fc = nn.Linear(160, 10) # 160特征->10类别def forward(self, x):batch_size = x.shape[0] # 获取批量大小# 第一组:卷积->残差->激活->池化x = self.conv1(x)x = self.resblock1(x)x = nn.ReLU()(x)x = self.maxpool(x)# 第二组:卷积->残差->激活->池化x = self.conv2(x)x = self.resblock2(x)x = nn.ReLU()(x)x = self.maxpool(x)# 第三组:卷积->残差->激活->池化x = self.conv3(x)x = self.resblock3(x)x = nn.ReLU()(x)x = self.maxpool(x)# 第四组:卷积->激活->池化x = self.conv4(x)x = nn.ReLU()(x)x = self.maxpool(x)# 展平特征图并分类x = x.view(batch_size, -1) # 展平为一维向量x = self.fc(x)return x5. 训练与测试函数
# 初始化模型、损失函数与优化器
model = ResNet().to(device)
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失(分类任务)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 学习率调度器(动态调整学习率)
scheduler = ReduceLROnPlateau(optimizer, mode='min', # 监控验证损失(越小越好)factor=0.1, # 学习率降低倍数(每次×0.1)patience=5, # 等待5个epoch无改善后调整verbose=True, # 打印调整信息min_lr=1e-6 # 最小学习率限制
)# 训练函数
def train(dataloader, model, loss_fn, optimizer):model.train() # 开启训练模式total_loss = 0for batch_idx, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device) # 数据移至GPU/CPU# 前向传播pred = model(X)loss = loss_fn(pred, y)# 反向传播与优化optimizer.zero_grad() # 清空梯度loss.backward() # 计算梯度optimizer.step() # 更新参数total_loss += loss.item()# 每100个batch打印一次损失if (batch_idx + 1) % 100 == 0:print(f"Batch {batch_idx+1}, Loss: {total_loss/100:.4f}")total_loss = 0 # 重置累计损失return total_loss / len(dataloader) # 返回平均损失# 测试函数
def test(dataloader, model, loss_fn):model.eval() # 开启评估模式(关闭Dropout等)total_loss = 0correct = 0total_samples = 0with torch.no_grad(): # 关闭梯度计算for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)total_loss += loss.item() * X.shape[0] # 累计损失(带批量权重)# 统计正确预测数correct += (pred.argmax(1) == y).sum().item()total_samples += X.shape[0]avg_loss = total_loss / total_samplesacc = 100 * correct / total_samplesprint(f"测试结果: 准确率 {acc:.2f}%, 平均损失 {avg_loss:.4f}")return acc6. 模型训练与结果可视化
# 超参数设置
epochs = 25
best_acc = 0.0
accuracy_list = []# 训练循环
for epoch in range(epochs):print(f"
===== 第 {epoch+1}/{epochs} 轮训练 =====")train_loss = train(train_dataloader, model, loss_fn, optimizer)test_acc = test(test_dataloader, model, loss_fn)accuracy_list.append(test_acc)# 保存最佳模型if test_acc > best_acc:print(f"最佳准确率更新为: {test_acc:.2f}%")best_acc = test_acctorch.save(model.state_dict(), 'best_resnet_mnist.pth') # 保存模型参数# 调整学习率scheduler.step(train_loss)# 输出最终结果
print(f"
训练完成!最高测试准确率: {best_acc:.2f}%")# 可视化准确率曲线
plt.figure(figsize=(10, 6))
plt.plot(range(1, epochs+1), accuracy_list, marker='o', linestyle='-', color='b', linewidth=2)
plt.title('ResNet在MNIST上的测试准确率变化', fontsize=14)
plt.xlabel('轮次(Epoch)', fontsize=12)
plt.ylabel('准确率(%)', fontsize=12)
plt.xticks(range(1, epochs+1))
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()完整代码:
import torch
from torch.optim.lr_scheduler import ReduceLROnPlateauprint(torch.__version__)import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensortraining_data=datasets.MNIST(root='./data',train=True,download=True,transform=ToTensor())test_data=datasets.MNIST(root='./data',train=False,download=True,transform=ToTensor())train_dataloader=DataLoader(training_data,32)
test_dataloader=DataLoader(test_data,32)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)import torch.nn.functional as Fclass ResBlock(nn.Module):def __init__(self, channels_in): # channels_in: 输入特征图的通道数super().__init__()self.conv1 = torch.nn.Conv2d(channels_in, 30, 5, padding=2) # 卷积层1: 通道数 channels_in -> 30, 使用5x5卷积核,填充2以保持空间尺寸self.conv2 = torch.nn.Conv2d(30, channels_in, 3, padding=1) # 卷积层2: 通道数 30 -> channels_in, 使用5x5卷积核,填充1def forward(self, x):out = self.conv1(x) # 数据通过第一层卷积out = F.relu(out)out = self.conv2(out) # 数据通过第二层卷积out = F.relu(out)return F.relu(out + x) # 关键步骤: 将输出(out)与原始输入(x)相加,然后通过ReLU激活函数# 这里的 `out + x` 就是残差连接class ResNet(nn.Module):def __init__(self):super().__init__()self.conv1 = torch.nn.Conv2d(1, 20, 5, padding=2)self.conv2 = torch.nn.Conv2d(20, 40, 3, padding=1)self.conv3 = torch.nn.Conv2d(40, 80, 3, padding=1)self.conv4 = torch.nn.Conv2d(80, 160, 3, padding=1)self.maxpool = torch.nn.MaxPool2d(2, 2)self.resblock1 = ResBlock(channels_in=20)self.resblock2 = ResBlock(channels_in=40)self.resblock3 = ResBlock(channels_in=80)self.full_c = torch.nn.Linear(160, 10)def forward(self, x):size = x.shape[0] # 获取批处理大小(batch_size)# 第一组: 卷积 -> 池化(带ReLU激活)x=self.conv1(x)x=self.resblock1(x)x=F.relu(x)x=self.maxpool(x)x = self.conv2(x)x = self.resblock2(x)x = F.relu(x)x = self.maxpool(x)x = self.conv3(x)x = self.resblock3(x)x = F.relu(x)x = self.maxpool(x)x = self.conv4(x)x =F.relu(x)x = self.maxpool(x)x=x.view(size, -1)x=self.full_c(x)return xmodel = ResNet()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)scheduler = ReduceLROnPlateau(optimizer,mode='min', # 监控验证损失,越小越好factor=0.1, # 每次降低10倍patience=5, # 给5个epoch的机会verbose=True, # 打印更新信息min_lr=1e-6) # 最低学习率def train(dataloader,model,loss_fn,optimizer):model.train()batch_size_num=1for X, y in dataloader:X,y=X.to(device),y.to(device)output = model(X) #model和model.forward一样效果loss = loss_fn(output,y)optimizer.zero_grad()loss.backward()optimizer.step()a=loss.item()if batch_size_num %100 ==0:print(f"Batch size: {batch_size_num}, Loss: {a}")batch_size_num+=1# print(model)return lossdef test(dataloader,model,loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()batch_size_num=1loss,correct=0,0with torch.no_grad():for X, y in dataloader:X,y=X.to(device),y.to(device)pred = model(X)loss = loss_fn(pred,y)+losscorrect += (pred.argmax(1) == y).type(torch.float).sum().item()loss/=num_batchescorrect/=sizeprint(f'Test result: \n Accuracy: {(100*correct)}%,Avg loss: {loss}')return correct# model.to(device)
# model.load_state_dict(torch.load('best_model.pth'))
# model.eval()
# loss_fn = nn.CrossEntropyLoss()
# # # # optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# # optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# # test(test_dataloader,model,loss_fn)
# test(train_dataloader,model,loss_fn)# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)
accuracy_list=[]
best_acc=0
epochs=25
for i in range(epochs):print(f"Epoch {i+1}")loss=train(train_dataloader,model,loss_fn,optimizer)corrects = test(test_dataloader,model,loss_fn)accuracy_list.append(corrects)if corrects>best_acc:print(f"Best Accuracy: {corrects}%")best_acc=corrects#第一种torch.save(model.state_dict(),'best_model.pth')#第二种# torch.save(model,'best1.pth')scheduler.step(loss)
print('最高:',best_acc)
print(accuracy_list)
model = ResNet()import matplotlib.pyplot as plt# 假设这是你的准确率数据,请替换为你的实际数据
# accuracy_list 应为一个列表,包含每个epoch后的准确率值
epochs = list(range(1, len(accuracy_list) + 1)) # 横坐标,从1开始# 创建图表
plt.figure(figsize=(10, 6)) # 设置图表大小# 绘制准确率曲线
plt.plot(epochs, accuracy_list, marker='o', linestyle='-', linewidth=2, markersize=6, label='Training Accuracy')# 设置图表标题和坐标轴标签
plt.title('Model Accuracy over Epochs', fontsize=15)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Accuracy', fontsize=12)# 设置坐标轴范围,可以根据你的数据调整
plt.xlim(1, len(accuracy_list))
plt.ylim(min(accuracy_list) - 0.01, max(accuracy_list) + 0.05) # 留一些边距# 添加网格线以便于读取数值
plt.grid(True, alpha=0.3)# 显示图例
plt.legend()# 显示图表
plt.tight_layout()
plt.show()五、总结与扩展
ResNet通过残差块与跳跃连接,巧妙解决了深层网络的退化问题,使网络层数突破千层(如ResNet-152),成为CV领域的里程碑模型。其核心思想“残差学习”也被广泛应用于NLP(如Transformer中的残差连接)、语音识别等领域。
对于初学者,建议从ResNet-18/34(使用基本残差块)入手,逐步理解更复杂的残差结构(如瓶颈块)。实际应用中,可根据任务需求调整残差块数量、通道数,或结合注意力机制(如SE Block)进一步优化性能。
完整代码已测试通过(PyTorch 2.0+,CUDA 11.7),可直接复制运行~