《Java操作Redis教程:以及序列化概念和实现》
文章目录
- 一、Jedis
- (1)快速入门
- (2)连接池
- 二、SpringDataRedis
- (1)介绍
- (2)快速入门
- *(2)序列化源码执行流程
- 三、序列化
- (1)介绍
- (2)自定义序列化方式
- 1.方案一
- 2.方案二
Redis 的 Java 客户端是一类在 Java 应用程序中用于连接和操作 Redis 数据库的工具类库。通过这些客户端,Java 开发者能够方便地执行 Redis 的各种命令,实现数据的存储、读取、更新和删除等操作 。
| 客户端 | 特点 |
|---|---|
| Jedis | 以 Redis 命令作为方法名称,学习成本低,简单实用。但 Jedis 实例是线程不安全的,多线程环境下需要基于连接池来使用 |
| lettuce | 基于 Netty 实现,支持同步、异步和响应式编程方式,并且是线程安全的。支持 Redis 的哨兵模式、集群模式和管道模式 |
| Redisson | 是一个基于 Redis 实现的分布式、可伸缩的 Java 数据结构集合。包含了诸如 Map、Queue、Lock、Semaphore、AtomicLong 等强大功能 |
| SpringData Redis | Spring Data Redis 是 Spring 框架中用于操作 Redis 的模块,它基于 Jedis 或 Lettuce 等底层客户端进行了一层封装,提供了更高级的抽象,方便在 Spring 项目中使用 Redis。 |
一、Jedis
Jedis 的官网地址:https://github.com/redis/jedis,我们先来个快速入门:
(1)快速入门
一共四步
1.引入依赖:
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>6.2.0</version>
</dependency>
2.建立连接
private Jedis jedis;@BeforeEach
void setUp () {// 建立连接jedis = new Jedis ("127.0.0.1", 6379);// 设置密码jedis.auth ("1212");// 选择库jedis.select (0);
}
如果没有密码就不要jedis.auth ("1212");,否则会报错。
@BeforeEach是 JUnit 5(Jupiter)中的一个注解,用于标记一个方法,该方法会在当前测试类中的每个测试方法执行之前自动运行。如果你不是在单元测试用测试可以不用加。
后边的@Test同理,作用为标记为一个单元测试方法;@AfterEach,表示每个测方法执行后自动运行
3.测试 string
@Test
void testString () {// 插入数据,方法名称就是 redis 命令名称,非常简单String result = jedis.set ("name", "张三");System.out.println ("result =" + result);// 获取数据String name = jedis.get ("name");System.out.println ("name =" + name);
}
jedis.set(“name”, “张三”),set就是redis原生操控String类型的命令。
4.释放资源
@AfterEach
void tearDown () {// 释放资源if (jedis != null) {jedis.close ();
}
}
(2)连接池
Jedis 本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用 Jedis 连接池代替 Jedis 的直连方式。
1.创建一个工具类:
需要创建:一个①连接池JedisPool,一个②连接池配置JedisPoolConfig,③返回连接池资源的方法
public class JedisConnectionFactory {//①连接池JedisPoolprivate static final JedisPool jedisPool;static {//②连接池配置JedisPoolConfigJedisPoolConfig jedisPoolConfig = new JedisPoolConfig ();// 最大连接jedisPoolConfig.setMaxTotal (8);// 最大空闲连接jedisPoolConfig.setMaxIdle (8);// 最小空闲连接(!设置为1表示即使全空闲依旧保留1个连接不会释放!)jedisPoolConfig.setMinIdle (0);// 设置最长等待时间,msjedisPoolConfig.setMaxWaitMillis (200);//设置地址-端口-超时时间-密码jedisPool = new JedisPool (jedisPoolConfig, "192.168.150.101", 6379, 1000, "123321");}// 获取 Jedis 对象//③返回连接池资源的方法public static Jedis getJedis (){return jedisPool.getResource ();}
}
final修饰的变量一旦初始化后就不能被重新赋值。确保jedisPool实例在整个程序生命周期中唯一且不可替换,避免因误操作导致连接池被意外修改或替换。
static修饰的核心是 “属于类,而非对象”,用于实现类级别的共享资源、工具方法或初始化逻辑,避免了重复创建和资源浪费。
static修饰代码块(称为 “静态代码块”)的核心作用是:在类加载到内存时自动执行,且只执行一次,通常用于初始化类级别的资源(静态变量)。
2.调用该工具类进行连接
现在无需专门使用一个方法来连接redis了,直接调用连接池即可。
@Test
void testString() {jedis = JedisConnectionFactory.getJedisPool();jedis.set("name", "张三");
}
二、SpringDataRedis
(1)介绍
SpringData 是 Spring 中数据操作的模块,包含对各种数据库的集成,其中对 Redis 的集成模块就叫做 SpringDataRedis;
官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同 Redis 客户端的整合(Lettuce 和 Jedis)
- 提供了 RedisTemplate 统一 API 来操作 Redis
- 支持 Redis 的发布订阅模型
- 支持 Redis 哨兵和 Redis 集群
- 支持基于 Lettuce 的响应式编程
- 支持基于 JDK、JSON、字符串、Spring 对象的数据序列化及反序列化
- 支持基于 Redis 的 JDKCollection 实现
(2)快速入门
SpringDataRedis 中提供了 RedisTemplate 工具类,其中封装了各种对 Redis 的操作。并且将不同数据类型的操作 API 封装到了不同的类型中:
| API | 返回值类型 | 说明 |
|---|---|---|
| redisTemplate.opsForValue() | ValueOperations | 操作 String 类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作 Hash 类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作 List 类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作 Set 类型数据 |
| redisTemplate.opsForZSet() | ZSetOperations | 操作 SortedSet 类型数据 |
| redisTemplate | 通用的命令 |
SpringBoot 已经提供了对 SpringDataRedis 的支持,使用非常简单:
一共四步
1.引入依赖
<!--Redis依赖-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency><!--连接池依赖-->
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId>
</dependency>
2.配置文件
在yml配置文件中
spring:data:redis:host: 127.0.0.1port: 6379password: nulllettuce:pool:max-active: 8 # 最大连接max-idle: 8 # 最大空闲连接min-idle: 0 # 最小空闲连接max-wait: 100 # 连接等待时间
Spring中默认使用lettuce的连接池,因为只引入了lettuce的连接池依赖,如果需要使用Jedis连接池需要额外配置
3.注入 RedisTemplate
@Autowired
private RedisTemplate redisTemplate;
4.编写测试
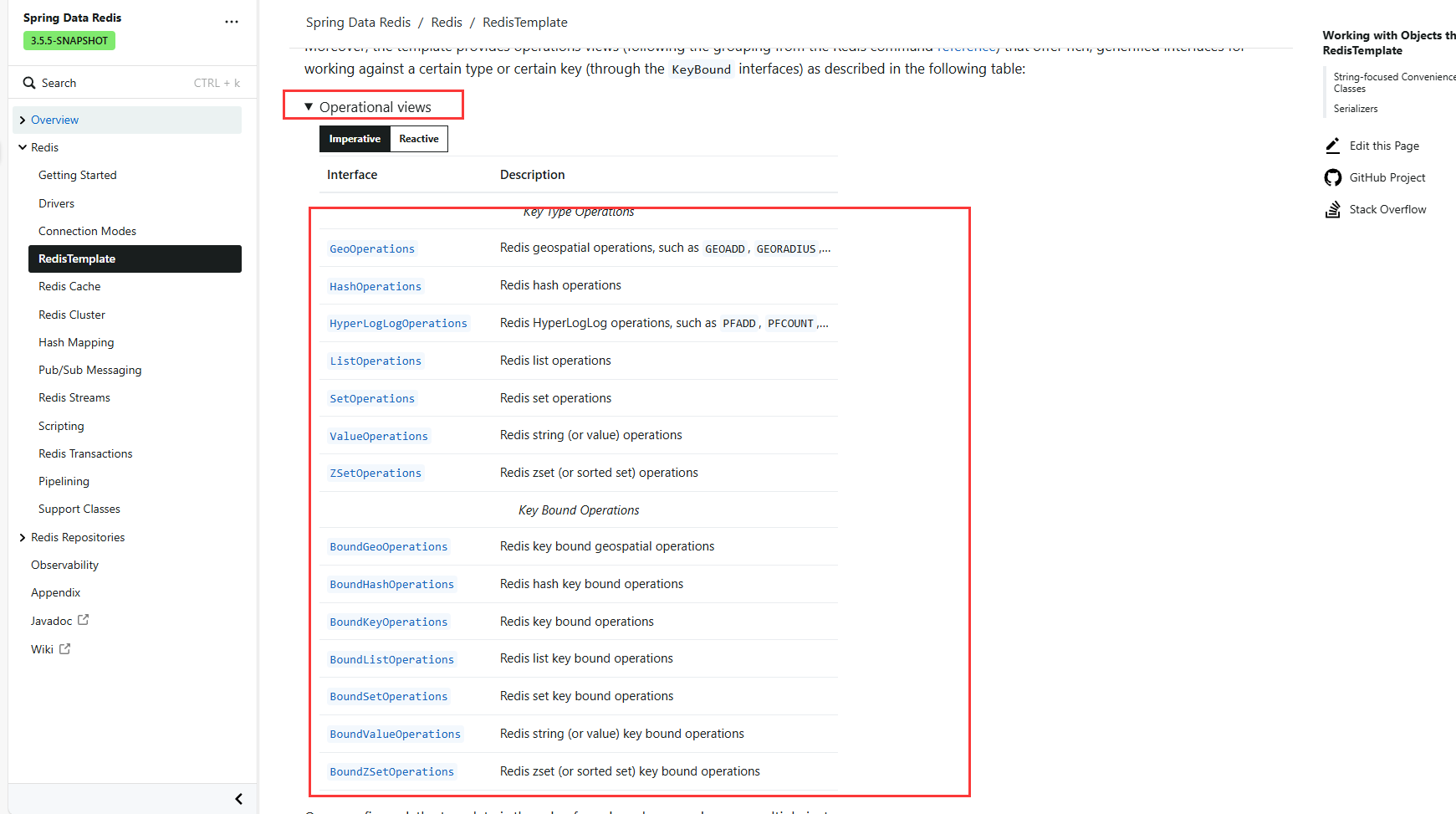
以Redis的String类型为例,Hash等类型可以参考官方文档Working with Objects through RedisTemplate :: Spring Data Redis
文档使用方法:
选择你想操作的类型,点击进入即可,里面就罗列了所有的方法
@SpringBootTest
public class RedisTest {@Autowiredprivate RedisTemplate redisTemplate;@Testvoid testString() {// 插入一条string类型数据redisTemplate.opsForValue().set("name", "李四");// 读取一条string类型数据Object name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}
}
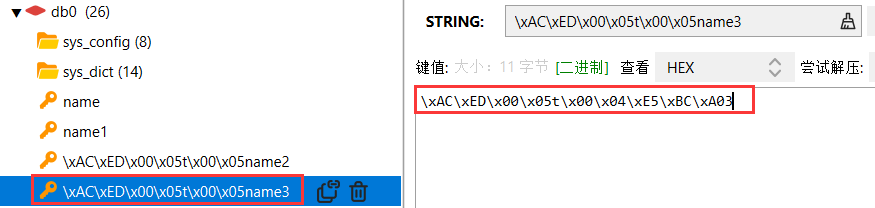
此时存到redis中的键值可能和预料的不一样,是一串类似:\xAC\xED\x00\x05t\x00\x06\xE5\xBC\xA0\xE4\xB8\x89的值
这是因为:SpringDataRedis 的
RedisTemplate默认使用 JDK 序列化器(JdkSerializationRedisSerializer),这种序列化方式会在数据前后添加额外的字节(如\xAC\xED\x00\x05等),用于标识对象类型,导致:
- 存入 Redis 的键(key)和值(value)会被序列化为字节数组,直接在 Redis 客户端查看时会显示为乱码。
- 中文字符(如 “张三”)会被编码为字节序列(如
\xE5\xBC\xA0\xE4\xB8\x89),存储的值不易读。
》》》》》如果想了解详细过程可以看下文《《《《《《
*(2)序列化源码执行流程
默认使用 **JDK 序列化器(JdkSerializationRedisSerializer)**流程讲解:
了解即可,可略过
1.序列化器种类
从操作数据使用的工具类RedisTemplat入手:
我们会发现该工具类中有几个序列化器Serializer

我们可以看到这几个值默认都是为null的。
keySerializer(键序列化器)负责将 Java 中定义的键(通常是字符串类型,但也可以是其他类型)序列化为字节数组,以便存储到 Redis 中;读取数据时,再将从 Redis 中获取的字节数组反序列化为对应的 Java 键对象。
valueSerializer(值序列化器)用于将 Java 对象(比如自定义的实体类、集合等)序列化为字节数组存储到 Redis,读取时再反序列化为对应的 Java
hashKeySerializer(哈希键序列化器)在操作 Redis 的哈希(Hash)数据结构时,专门处理哈希键(field)的序列化和反序列化。即把 Java 中定义的哈希键类型转换为 Redis 能够存储的字节数组形式,以及反向转换。
hashValueSerializer(哈希值序列化器)在操作 Redis 的哈希数据结构时,负责对哈希值(value)进行序列化和反序列化。把 Java 对象形式的哈希值转换为字节数组存储到 Redis,读取时恢复为 Java 对象。也就是说,这几个序列化器不是实际执行序列化的工具,而是用来分工的载体。
比如有一个序列化器叫A,那么把A赋值给
keySerializer就表示它是用来处理键的
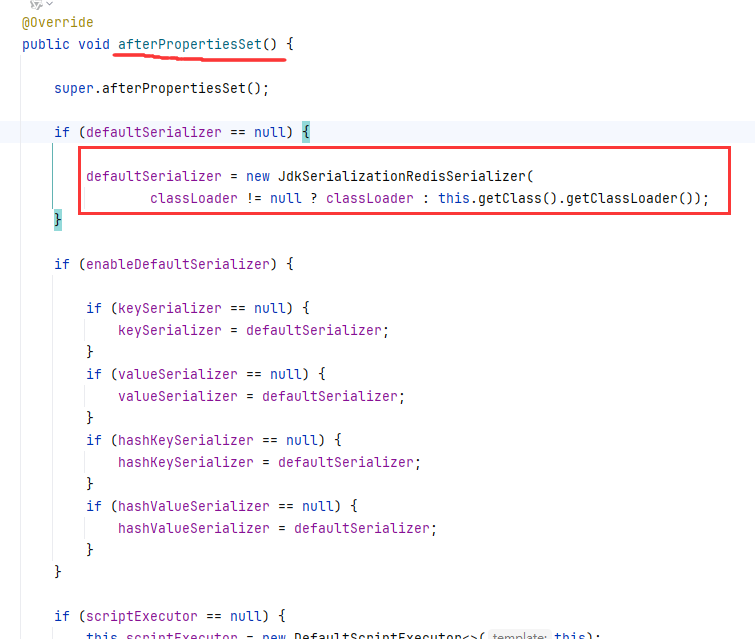
如下图,我们下翻一点就能找到一个方法叫afterPropertiesSet()来初始化他们。也就是说,如果我们不指定他们序列化器的话,就会被这个方法初始化为默认的序列化器。
由下图可知,初始化默认使用的是 JDK 序列化器(JdkSerializationRedisSerializer)
(2)传入Redis的源码执行流程
如我们执行下面这个代码,插入键值到redis中的流程:
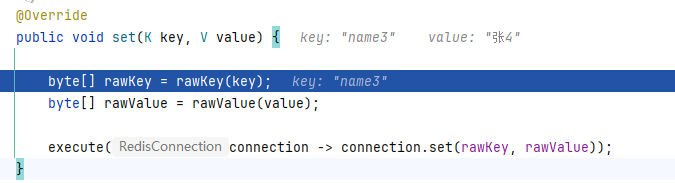
@Testvoid testRedisTemplateForValue() {redisTemplate.opsForValue().set("name3", "张4");}
我们可以通过调试,进入到set(“name3”, “张4”)方法中:
传入的键值值会被处理
一共六步
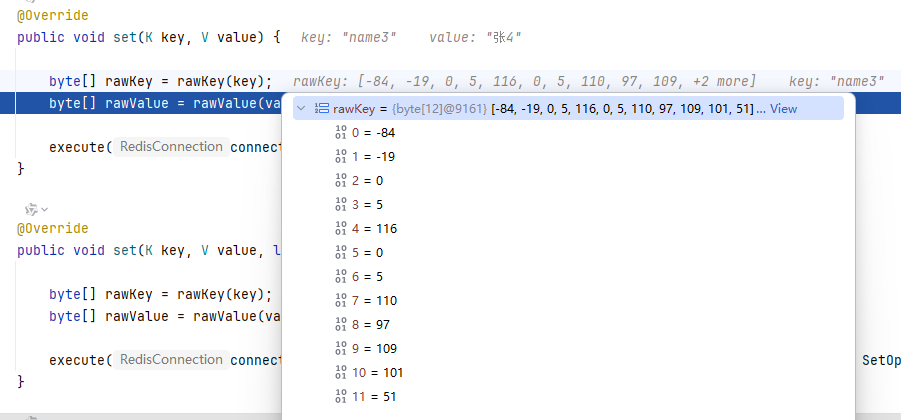
①如图,我们很清晰的看到两个类型为byte[]的值,这就是我们需要的字节数组;
再看蓝色标记这行,我们的key为“name3”,会被传入到rawKey(key)方法中,我们进入该方法
②会发现他会尝试取获取键key的序列化器,也就是我们上面提到的键的序列化器。
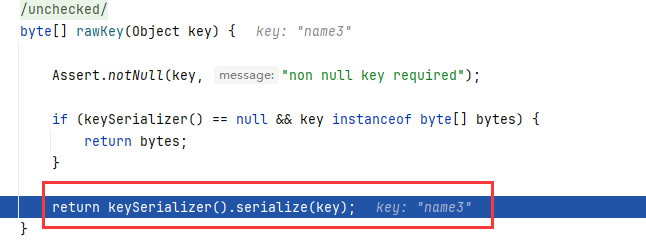
然后就会进入到keySerializer()的serialize(key)方法中,我们继续跟入该方法。
③如下图,会发现这个序列化器是默认的JDK 序列化器(JdkSerializationRedisSerializer),如上文,我们没用指定序列化器,使得keySerializer为空,然后初始化为默认的JdkSerializationRedisSerializer,而jdk序列化器底层使用ObjectOutputStream。
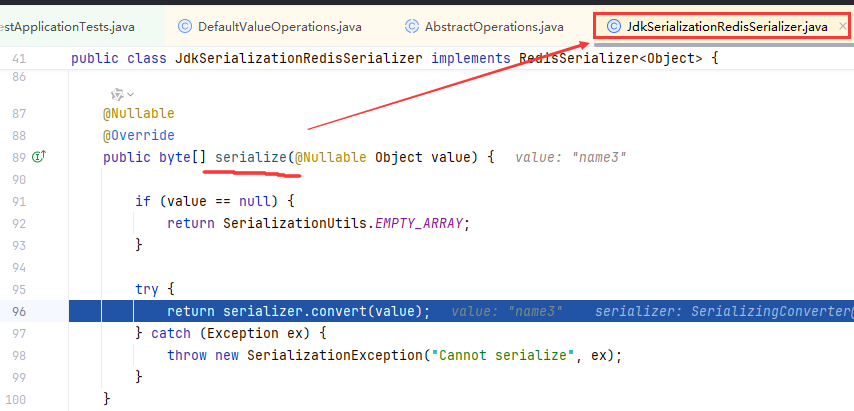
③我们继续跟进return serializer.convert(value);的convert(value)方法中:
会发现它没有处理我们的数据”name3“,而是继续调用方法。

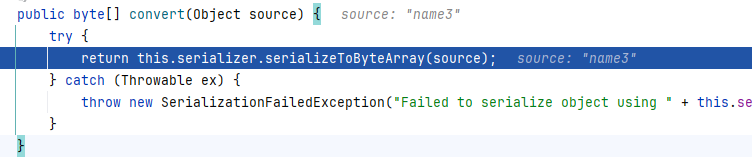
④继续跟进:
会发现它没有处理我们的数据”name3“,而是继续调用方法。

⑤继续跟进:
此时我们就会发现jdk序列化器确实是使用的ObjectOutputStream,这个ObjectOutputStream的作用就是把java对象转成字节,转成字节之后层层返回,最后写入redis


⑥最后返回,如图:
三、序列化
(1)介绍
序列化(Serialization)是计算机科学中的一个概念,指的是将内存中的对象(如 Java 对象、Python 字典等)转换为可存储或可传输的格式(如字节流、JSON 字符串、XML 等)的过程。
对应的,反序列化(Deserialization) 则是相反的过程:将存储或传输的格式(如字节流、JSON)恢复为内存中原始对象的过程。
RedisTemplate工具类 写入数据到Redis前,默认使用JDK序列化器将数据序列化为字节数组格式的数据,类似于:\xAC\xED\x00\x05t\x00\x04\xE5\xBC\xA03
那有没有能够序列化成其他格式的序列化器呢?
有的:
我们进入到RedisTemplate工具类中,通过IDEA的快捷键Ctrl+H就能查看到RedisSerializer接口所有实现类。
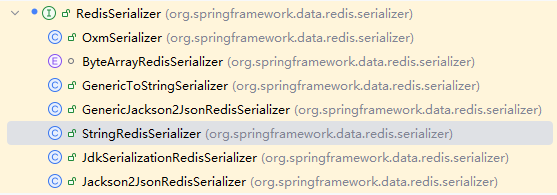
上图就是可以使用的序列化器。
两种常用的序列化器:
StringRedisSerializerSrting类型存储;通常用于String类型的键值存储。
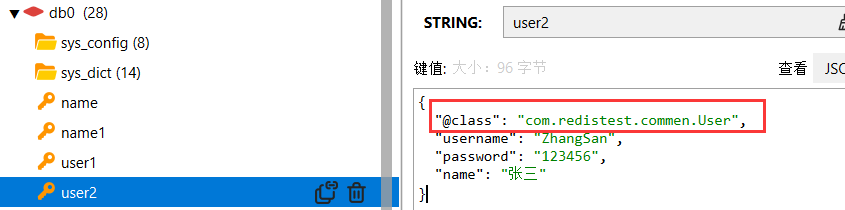
GenericJackson2JsonRedisSerializer将数据转成json格式存储;通常用于值的存储。
json格式存储的时候会多一个字段@class用来存储java类型,反序列化的时候会根据该类型重新转成对应的java对象
(2)自定义序列化方式
当我们直接调用RedisTemplate工具类的时候是只会使用默认的JDK序列化器,但是我们有方案指定使用的序列化器。
我们可以自定义RedisTemplate的序列化方式。
RedisTemplate 的两种序列化实践方案:
方案一:
- 自定义 RedisTemplate
- 修改 RedisTemplate 的序列化器为
GenericJackson2JsonRedisSerializer
方案二:
- 使用 StringRedisTemplate
- 写入 Redis 时,手动把对象序列化为 JSON
- 读取 Redis 时,手动把读取到的 JSON 反序列化为对象
1.方案一
RedisTemplate工具类默认是没有指定键值使用的序列化器,而是统一使用jdk序列化器的。
现在我们要求是键为String类型,值为Object类型的数据集合存储方式为:键使用String存储,值使用json格式存储。
这个时候就需要使用到泛型改造RedisTemplate工具类,首先指定传入值类型RedisTemplate<String, Object>,然后指定键值的序列化器,代码如下:
简单介绍下泛型,了解可以略过:
泛型(Generics)是 Java 等编程语言中的一种特性,它允许在定义类、接口或方法时,不指定具体的类型,而是在使用时再确定类型。
泛型主要有三个好处:1.会检测类型,保证类型安全,2.代码重用,3.消除强制转换。
java中泛型其实是一个伪泛型,JVM运行的时候都是一样的,这是为了兼容java5之前版本无泛型时的情况。
简单示例:
比如,我们有一个存储整数的
Box类:class Box { private Integer value; public void setValue(Integer value) { this.value = value; } public Integer getValue() { return value; } }如果现在需要一个存储字符串的
Box类,不使用泛型的话,可能需要再写一个类似的类:class StringBox { private String value; public void setValue(String value) { this.value = value; } public String getValue() { return value; } }这显然很繁琐。使用泛型后,我们可以这样写:
class Box<T> { private T value; public void setValue(T value) { this.value = value; } public T getValue() { return value; } }这里的
<T>就是泛型参数,它是一个占位符,表示 “某种类型”。当使用Box类时,再指定具体的类型:
- 存储整数:
Box<Integer> intBox = new Box<>();,此时setValue只能接收Integer类型,getValue返回的也是Integer类型。- 存储字符串:
Box<String> strBox = new Box<>();,此时setValue只能接收String类型,getValue返回的也是String类型。
该方法,其返回值是泛型类 RedisTemplate 的一个具体参数化实例(String 作为键类型,Object 作为值类型),能够将该泛型注入到IOC中。
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {// 创建TemplateRedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();// 设置连接工厂redisTemplate.setConnectionFactory(redisConnectionFactory);// 设置序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// key和 hashKey采用 string序列化redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());// value和 hashValue采用 JSON序列化redisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;
}
注意事项:
①key和 hashKey采用 string序列化中使用的是:RedisSerializer.string(),实际你跟进看就能看到这就是一个StringRedisSerializer序列化器:

②GenericJackson2JsonRedisSerializer会需要jackson依赖,一般Spring MVC会自动引入。
<!--Jackson依赖--> <dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId> </dependency>
此时,我们需要的这个Bean对象就能够满足我们的要求了。
如果后面需要配置多个不同的RedisTemplate泛型话,就需要多个@Bean对象了,此时我们可以建一个@Configuration的配置文件,Spring启动的时候自动将所有的@Bean对象注入。如下图:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {//代码实现....}}
在 Spring 框架中,
@Configuration是一个注解,主要用于标识一个类是配置类 ,其作用如下:
@Configuration注解修饰的类中,可以使用@Bean注解来定义一个或多个 Bean(即 Spring 容器管理的对象)。Spring 容器会在启动时扫描这些配置类,创建并管理由@Bean方法返回的对象。
2.方案二
上述方案使用的序列化器GenericJackson2JsonRedisSerializer为了在反序列化时知道对象的类型,JSON 序列化器会将类的 class 类型写入 json 结果中,存入 Redis,会带来额外的内存开销。
为了节省内存空间,我们是统一使用 String 序列化器,要求只能存储 String 类型的 key 和 value。当需要存储 Java 对象时,手动完成对象的序列化和反序列化。
- 我们无需像方案一一样修改RedisTemplate工具类的序列化器,因为有一个新的工具类
StringRedisTemplate,该工具类默认的键值序列化器就是StringRedisSerializer
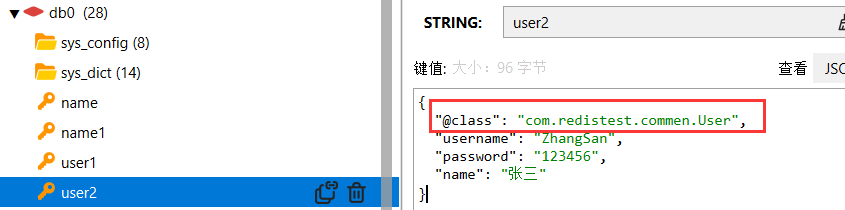
就是多了一组步骤:存->手动序列化,取->手动反序列化。
如果我们希望存到redis的值是json格式,可以使用Json工具,ObjectMapper进行手动序列化。
@Autowired
private StringRedisTemplate stringRedisTemplate;
// JSON工具
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testStringTemplate() throws JsonProcessingException {// 准备对象User user = new User("虎哥", 18);// 手动序列化String json = mapper.writeValueAsString(user);// 写入一条数据到redisstringRedisTemplate.opsForValue().set("user:200", json);// 读取数据String val = stringRedisTemplate.opsForValue().get("user:200");// 反序列化User user1 = mapper.readValue(val, User.class);System.out.println("user1 = " + user1);
}
ObjectMapper是 Jackson 库(Java 生态中最流行的 JSON 处理工具)的核心类,主要用于实现 Java 对象与 JSON 数据之间的相互转换(序列化与反序列化),是 Java 开发中处理 JSON 格式数据的核心工具之一。1.序列化(Java 对象 → JSON)
方法签名 功能描述 示例场景 String writeValueAsString(Object obj)将对象转为 JSON 字符串 接口返回 JSON 响应 void writeValue(File file, Object obj)将对象转为 JSON 并写入文件 对象持久化到本地 JSON 文件 byte[] writeValueAsBytes(Object obj)将对象转为 JSON 字节流 网络传输(如 Kafka 消息) 2. 反序列化(JSON → Java 对象)
方法签名 功能描述 示例场景 <T> T readValue(String json, Class<T> clazz)JSON 字符串转为指定类型的 Java 对象 接收接口 JSON 请求 <T> T readValue(File file, Class<T> clazz)读取 JSON 文件并转为指定类型的 Java 对象 解析本地 JSON 配置文件 <T> T readValue(InputStream in, Class<T> clazz)从输入流读取 JSON 并转为 Java 对象 网络流解析 JSO