【Linux】拆解 Linux 容器化核心:Namespace 隔离 + cgroups 资源控制,附 LXC 容器生命周期实战


🔥个人主页: 中草药
🔥专栏:【中间件】企业级中间件剖析
虚拟化、容器化
概述
物理机:物理机就是实际的硬件服务器,包含 CPU、内存、硬盘、网卡等物理组件,直接运行操作系统(如 Linux、Windows Server),是相对虚拟机而言的对实体计算机的称呼,物理机提供给虚拟机以硬件环境,又是也称为寄主或宿主
虚拟化:虚拟化通过Hypervisor(虚拟化层) 在物理机上模拟出多个独立的逻辑计算机- “虚拟服务器”(VM,虚拟机),每个 VM 拥有独立的操作系统(如单独的 Linux 系统),并且应用程序都可以在相互独立的空间内运行而互不影响,仿佛是一台独立的物理机。
容器化:容器化是轻量级的虚拟化技术,又称操作系统层虚拟化(Operating system level virtualization),这种技术将操作系统内核虚拟化,可以允许用户空间软件实例(instances)被分割成几个独立的单元,在内核中运行,而不是只有一个单一实例运行。这个软件实例,也被称为是一个容器(containers)。对每个实例的拥有者与用户来说,他们使用的服务器程序,看起来就像是自己专用的。容器技术是虚拟化的一种。Docker 是现今容器技术的事实标准。
优势
提升硬件资源利用率
传统物理机部署 Java 应用时,由于担心资源竞争,往往一台机器只跑一个应用,导致 CPU、内存等硬件资源利用率极低(可能不到 20%)。虚拟化允许在一台物理机上运行多个虚拟机(每个虚拟机跑一个或多个 Java 应用),通过动态分配资源(如调整虚拟机的 CPU 核心数、内存),显著提高硬件利用率,用更少的硬件资源运行更多的业务。
简化环境一致性管理
开发、测试、生产环境的差异是 Java 开发的经典痛点(“我这能跑” 问题)。虚拟化可以通过 “虚拟机镜像” 固化环境配置(如预装 JDK、配置好系统参数),开发、测试、运维团队使用相同的镜像,避免因环境差异导致的部署失败。
快速弹性扩展
对于 Java 后端服务(如电商订单系统),流量波动可能很大(如促销活动)。虚拟化支持快速克隆虚拟机、动态调整资源,配合负载均衡可以快速扩容以应对流量峰值,流量下降后再缩容,降低成本。
沙箱安全与资源控制
通过 “隔离与权限控制” 限制程序行为的安全机制,核心目标是防止不可信代码(或潜在风险代码)对系统资源、敏感数据造成未授权访问或破坏。它就像给程序划定一个 “安全区域”(沙箱),代码只能在这个区域内有限度地运行,超出范围的操作会被禁止。
容器虚拟化实现原理
在了解容器虚拟化实现原理之前,我们先了解一下主机虚拟化的实现原理:
主机虚拟化(硬件级虚拟化)
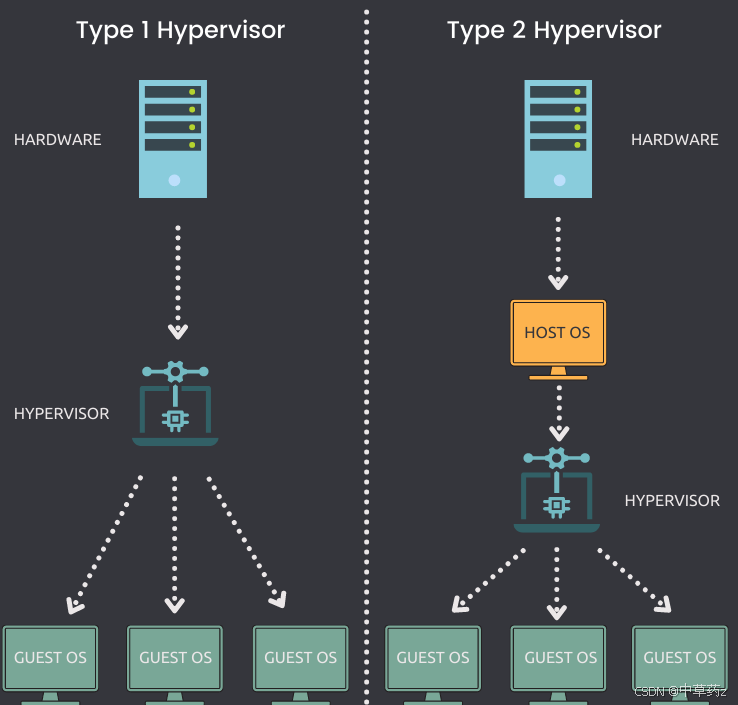
核心是在物理服务器上安装一个虚拟化层来实现,通过 Hypervisor(虚拟机监控器) 对物理硬件进行抽象和模拟,让多个独立的操作系统(虚拟机)能共享一台物理机的硬件资源。
实现原理:
- Hypervisor 直接运行在物理硬件上(Type 1,如 KVM、VMware ESXi),或运行在宿主操作系统上(Type 2,如 VMware Workstation)。
- 它会虚拟出 CPU、内存、磁盘、网络卡等硬件资源,每个虚拟机(VM)会认为自己在独占这些 “虚拟硬件”,并在其上安装完整的操作系统(如 Windows、Linux)。
- Hypervisor 负责调度物理资源给不同虚拟机,同时严格隔离各虚拟机(如内存地址空间、进程、网络),确保虚拟机之间无法直接访问对方资源。
容器虚拟化与之有别,是操作系统层的虚拟化。通过 namespace 进行各程序的隔离,加上cgroups 进行资源的控制,以此来进行虚拟化。
namespace
Namespace(命名空间) 是Linux内核提供的一种资源隔离技术,核心作用是让不同的进程 “看到” 不同的系统资源视图,从而实现 “逻辑上的独立环境”。它就像给进程套上了一个 “滤镜”,每个进程只能看到自己所在 namespace 内的资源,而感知不到其他 namespace 的存在。
Linux 内核提供了多种 Namespace,分别隔离不同类型的系统资源:
| namespace | 系统调用参数 | 被隔离的全局系统资源 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机名和域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 - 进程间通信 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS | 文件系统挂载点 |
| User | CLONE_NEWUSER | 用户和用户组 |
基础命令
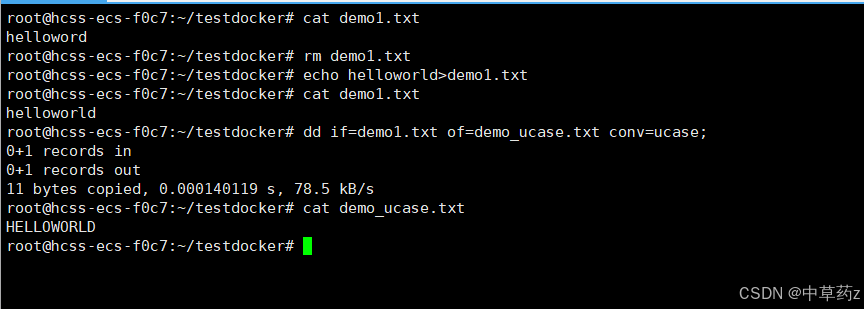
1、dd 命令(数据复制与转换)
作用:读取、转换并输出数据,常用于生成镜像、格式化测试等。可以从标准输入或文件中读取数据,根据指定的格式来转化数据,再输出到文件,设备或标准输出。
语法:
dd if=输入文件 of=输出文件 [参数]关键参数:
if:输入源(如/dev/zero生成空数据)。
of:输出目标(如镜像文件)。
bs:块大小(如8k、4M)。
count:复制块数。
conv=ucase/lcase:大小写转换;conv=sync:填充空字符。
案例:
# 生成10MB镜像文件(8k块×1280块=10MB)
dd if=/dev/zero of=fdimage.img bs=8k count=1280
# 转换文件为大写
dd if=test.txt of=test_ucase.txt conv=ucase
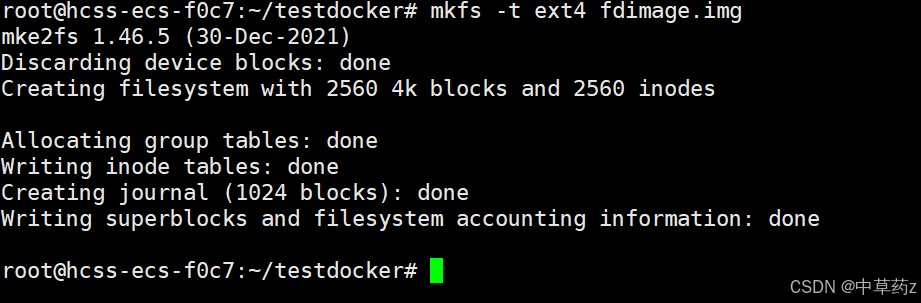
2. mkfs 命令(格式化文件系统)
作用:在设备 / 镜像上创建文件系统(如ext4)俗称格式化。
语法:
mkfs [-V] [-t fstype] [fs-options] filesys [blocks]
#-t fstype:指定要建立何种文件系统;如 ext3,ext4
#filesys :指定要创建的文件系统对应的设备文件名;
#blocks:指定文件系统的磁盘块数。
#-V : 详细显示模式
#fs-options:传递给具体的文件系统的参数案例:
# 格式化镜像为ext4
mkfs -t ext4 fdimage.img
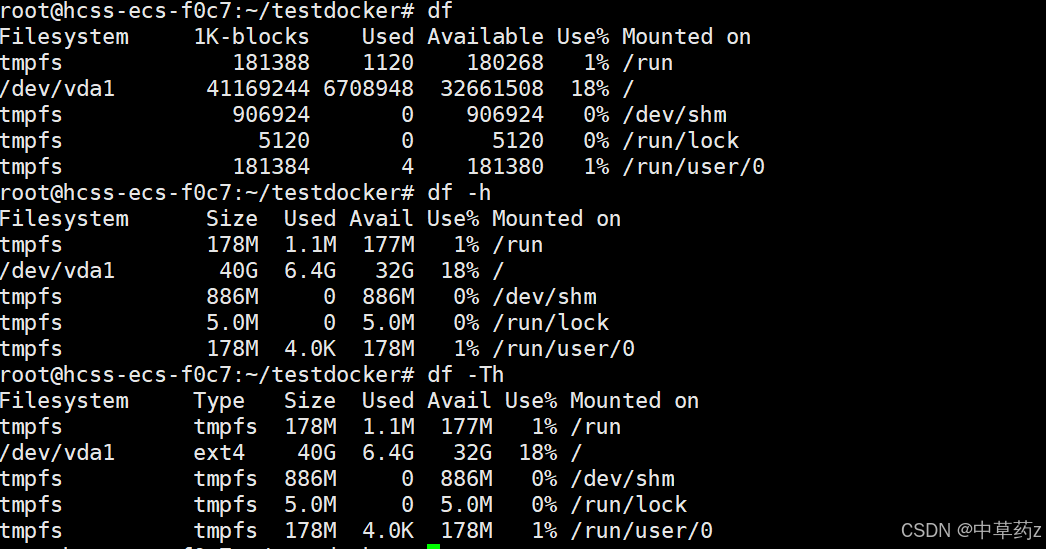
3. df 命令(查看磁盘使用)
df [OPTION]... [FILE]...作用:显示文件系统磁盘占用。
常用参数:
-h:人类可读格式。
-T:显示文件系统类型。
案例:
bash
df -h # 查看系统磁盘使用
df -Th # 查看磁盘系统类型
4. mount 命令(挂载设备 / 镜像)
作用:将设备 / 镜像挂载到目录(挂载点)。
语法:
mount [-l]
mount [-t vfstype] [-o options] device dir参数:
-l:显示已加载的文件系统列表。-t:指定加载的文件系统类型,支持ext3、ext4、iso9660、tmpfs、xfs等;大部分情况可省略,mount能自动识别类型。-o options:描述设备或档案的挂接方式,支持的子选项包括:loop:将一个文件当作硬盘分区挂接至系统。ro:以只读方式挂接设备。rw:以读写方式挂接设备。
案例:
mkdir -p /mnt/test # 创建挂载点,需要确保挂载点也就是目录存在
mount fdimage.img /mnt/test # 挂载镜像
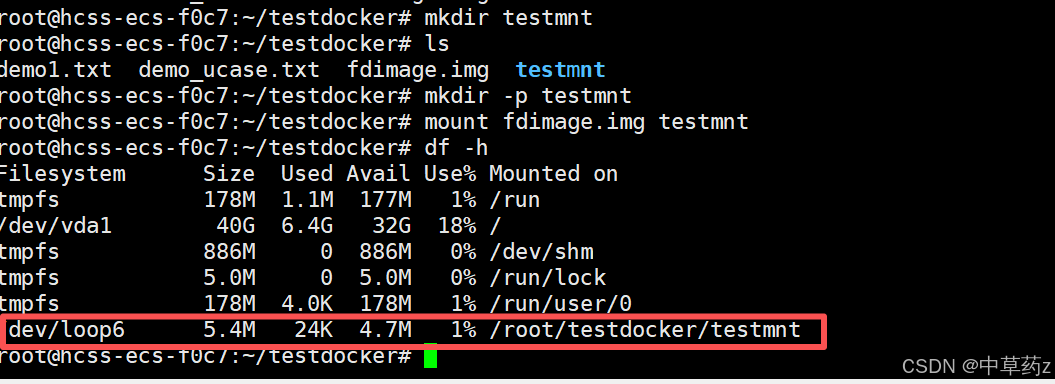
5. unshare 命令(命名空间隔离)
作用:创建独立的 Namespace 环境(如 PID、Mount 隔离)使用与父程序不共享的名称空间运行程序。
unshare [options] program [arguments]关键参数:
| 选项 | 描述 |
|---|---|
-i, --ipc | 不共享 IPC 空间 |
-m, --mount | 不共享 Mount 空间 |
-n, --net | 不共享 Net 空间 |
-p, --pid | 不共享 PID 空间 |
-u, --uts | 不共享 UTS 空间 |
-U, --user | 不共享用户 |
-V, --version | 版本查看 |
--fork | 执行 unshare 的进程 fork 一个新的子进程,在子进程里执行 unshare 传入的参数。 |
--mount-proc | 执行子进程前,将 proc 优先挂载过去 |
mount-proc是因为 Linux下的每个进程都有一个对应的/procIPID 目录,该目录包含了大量的有关当前进程的信息。对一个 PlDnamespace 而言,/proc 目录只包含当前namespace 和它所有子孙后代 namespace 里的进程的信息。创建一个新的 PIDnamespace 后,如果想让子进程中的 top、ps 等依赖/proc 文件系统的命令工作,还需要挂载/proc 文件系统。而文件系统隔离是 mount namespace 管理的,所以linux特意提供了一个选项--mount-proc来解决这个问题。如果不带这个我们看到的进程还是系统的进程信息。
案例:
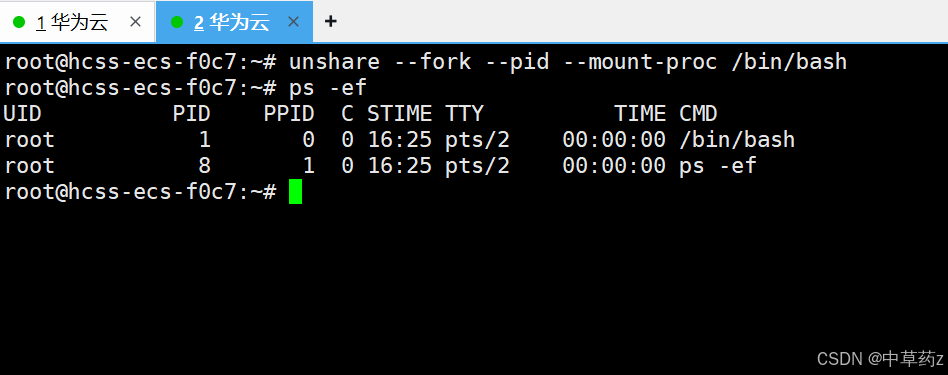
PID隔离
# PID隔离并启动bash
unshare --fork --pid --mount-proc /bin/bash 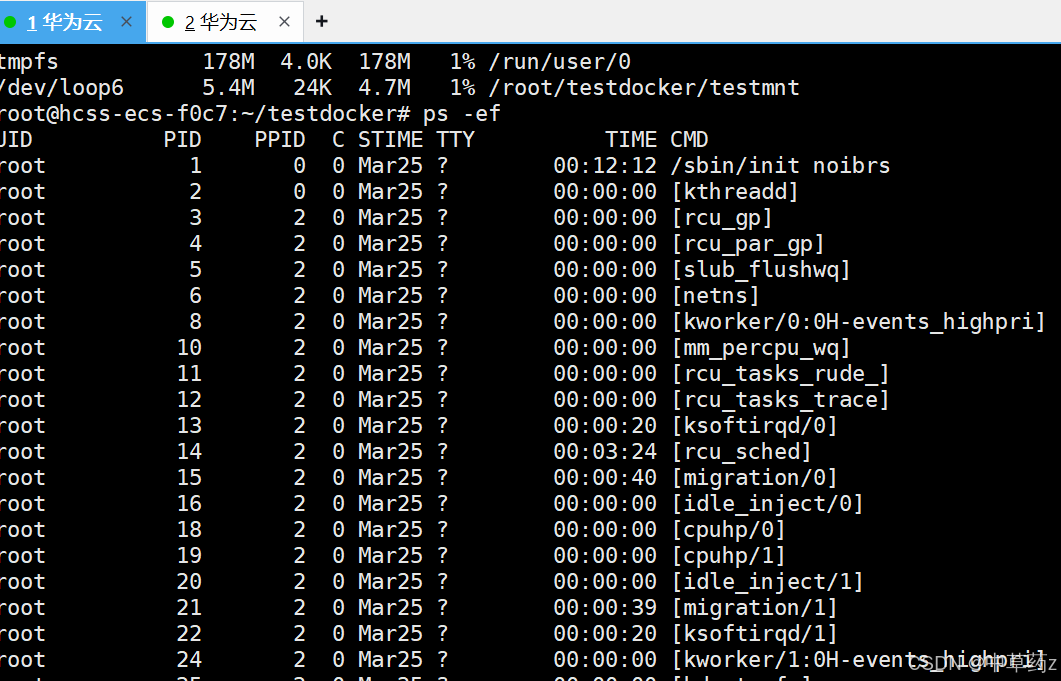
cgroups
cgroups(Control Groups,控制组)是Linux 内核提供的一种精细化资源管理技术,用于对一组进程(任务)的系统资源(CPU、内存、IO 等)进行限制、统计和隔离。它是容器技术(如 Docker、K8s)实现资源隔离的核心底层依赖。
信息查看
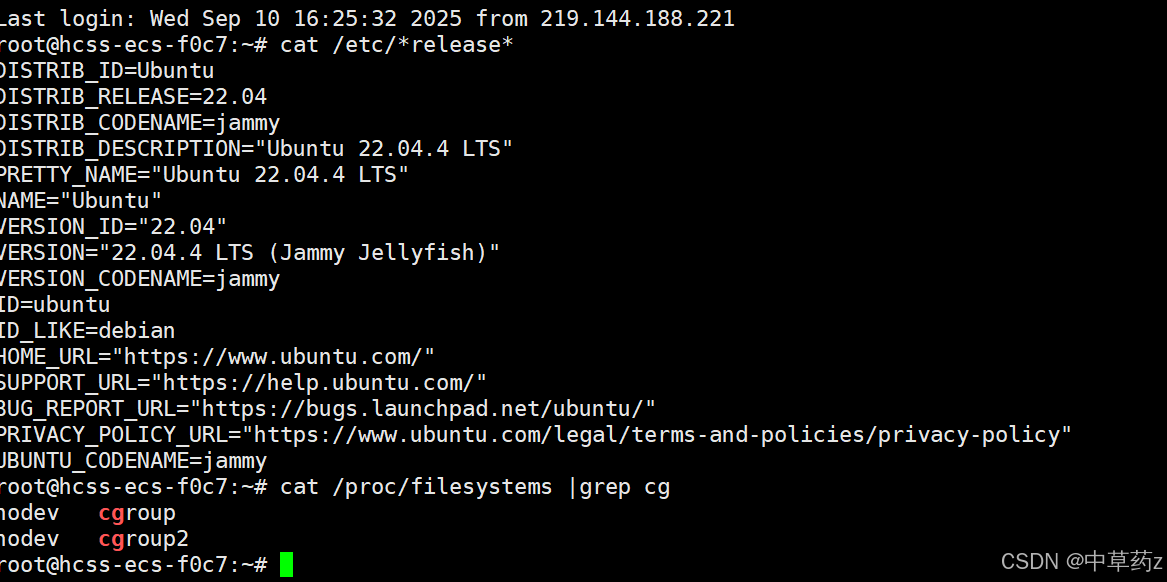
版本查看
cat /proc/filesystems
子系统查看
cat /proc/cgroups
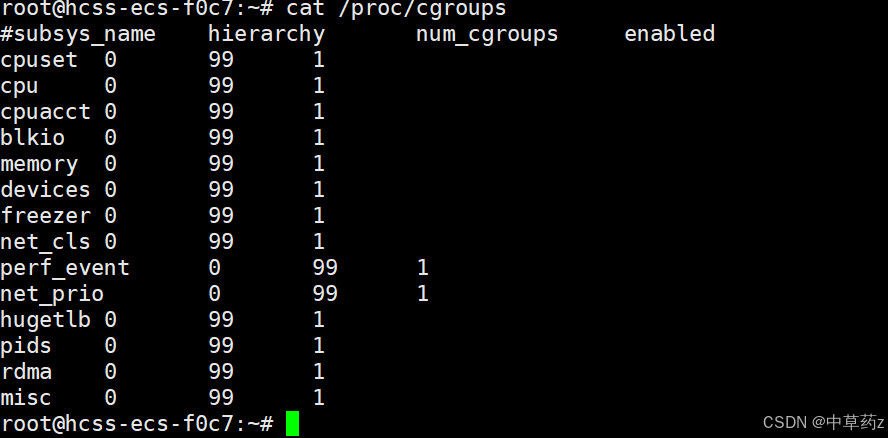
挂载信息查看
mount |grep cgroup

查看进程控制组的信息
cat /proc/$$/cgroup

内存管理
内存管理的核心是限制进程组的最大内存使用量,当进程尝试占用内存超过限制时,会触发 OOM(Out of Memory)机制终止进程,避免单个进程耗尽系统内存。
基于 /sys/fs/cgroup/memory(内存 cgroup 根目录)开展操作,步骤如下:
1、创建内存控制组:进入内存 cgroup 根目录,创建自定义控制组目录(如 test_memory),系统会自动生成该控制组的配置文件(如 memory.limit_in_bytes、tasks 等)。
cd /sys/fs/cgroup/memory
mkdir test_memory # 自动生成内存控制配置文件
2、配置内存限制:通过 memory.limit_in_bytes 文件设置最大内存使用量(单位:字节)。例如限制为 20MB,需先计算字节数(2010241024=20971520),再将数值写入文件。
# 计算20MB对应的字节数
expr 20 \* 1024 \* 1024 # 输出20971520
# 写入内存限制
echo "20971520" > test_memory/memory.limit_in_bytes
3、生成内存压力进程:使用 stress 工具创建占用超量内存的进程(如占用 50MB 内存),模拟内存压力。
stress -m 1 --vm-bytes 50M # 1个进程,每个占用50MB内存
4、关联进程到控制组:通过 test_memory/tasks 文件,将压力进程的 PID 写入,使进程受该控制组的内存限制约束。
# 先通过pidstat找到stress进程的PID(如62518)
pidstat -r -C stress -p ALL 1
# 将PID写入tasks,关联控制组
echo 62518 > test_memory/tasksCPU管理
CPU 管理的核心是通过 “时间配额” 限制进程组的 CPU 使用率,基于 Linux CFS(完全公平调度器)实现,通过控制 “调度周期” 和 “周期内可使用的 CPU 时间” 来约束使用率。
CPU 使用率由两个参数决定,公式如下:
CPU 使用率 = (cpu.cfs_quota_us) / (cpu.cfs_period_us) * 100%
cpu.cfs_period_us:调度周期(单位:微秒),表示 CPU 资源的分配周期,默认值为 100000 微秒(即 0.1 秒);cpu.cfs_quota_us:周期内的 CPU 时间配额(单位:微秒),表示该控制组在一个周期内最多可使用的 CPU 时间,默认值为 -1(无限制);- 约束:
cpu.cfs_quota_us最小值为 1000 微秒(1ms),最大值为 1000000 微秒(1s)。
基于 /sys/fs/cgroup/cpu(CPU cgroup 根目录)开展操作,步骤如下:
1、创建 CPU 控制组:进入 CPU cgroup 根目录,创建自定义控制组目录(如 test_cpu),系统自动生成 CPU 配置文件(如 cpu.cfs_period_us、cpu.cfs_quota_us 等)。
cd /sys/fs/cgroup/cpu
mkdir test_cpu # 自动生成CPU控制配置文件
2、生成 CPU 压力进程:使用 stress 工具创建占用 100% CPU 的进程(如 1 个 CPU 压力进程)。
stress -c 1 # 1个进程,满负荷占用CPU
3、验证初始 CPU 使用率:通过 pidstat -u 监控,可观察到 stress 进程的 CPU 使用率接近 100%。
pidstat -u -C stress -p ALL 1 # 每秒监控一次CPU使用
4、配置 CPU 使用率限制:例如限制为 30%,则设置 cpu.cfs_quota_us=30000(30000/100000=30%),并写入配置文件。
# 写入30%的CPU配额(周期默认100000微秒)
echo 30000 > test_cpu/cpu.cfs_quota_us
5、关联进程到控制组:将 stress 进程的 PID 写入 test_cpu/tasks,使进程受该控制组的 CPU 限制约束。
# 找到stress进程的PID(如62577)
pidstat -u -C stress -p ALL 1
# 关联控制组
echo 62577 > test_cpu/tasks关联后,通过 pidstat -u 监控可观察到:stress 进程的 CPU 使用率从 100% 降至目标值(如 30% 左右),且长期稳定在该范围;
LXC
LXC 是 Linux 容器技术(Linux Containers) 的缩写,是一种操作系统级虚拟化技术,旨在通过 Linux 内核原生功能(cgroups、namespaces)实现轻量级的资源隔离与进程管理,让多个独立的 “容器” 在同一台 Linux 主机上共享内核,但拥有各自独立的文件系统、网络、进程空间等,从而实现类似虚拟机的隔离效果,同时避免硬件虚拟化的性能开销。
LXC 命令行工具集
通过 lxc-* 系列命令管理容器生命周期,常用命令如下:
| 命令 | 功能 | 示例 |
|---|---|---|
lxc-checkconfig | 检查系统环境是否满足容器使用要求 | lxc-checkconfig |
lxc-create | 创建容器(需指定模板和容器名) | lxc-create -t ubuntu -n my-ubuntu(用 Ubuntu 模板创建名为 my-ubuntu 的容器) |
lxc-start | 启动容器 | lxc-start -n my-ubuntu -d(-d 表示后台启动) |
lxc-attach | 进入容器的命令行(类似 ssh) | lxc-attach -n my-ubuntu(进入 my-ubuntu 容器) |
lxc-stop | 停止容器 | lxc-stop -n my-ubuntu |
lxc-destroy | 删除容器(需先停止) | lxc-destroy -n my-ubuntu |
lxc-ls | 列出所有容器及状态 | lxc-ls --fancy(显示详细状态,如运行 / 停止、IP、内存使用) |
lxc-info | 查看容器详细信息 | lxc-info -n my-ubuntu(显示容器的 PID、IP、资源使用等) |
检查
# 一、检查是否安装。清理资源
systemctl status lxc
lxc-stop -n xxx # lxc-ls -f 遍历所有容器,停止运行的容器
lxc-destroy -n xxx # 删除对应的容器
# 二、 卸载软件
apt-get purge --auto-remove lxc lxc-templates
# 三、 检查服务已经没有该服务了
systemctl status lxc安装
#一、安装
#lxc 主程序包
#lxc-templates lxc 的配置模板
#bridge-utils 网桥管理工具
apt install lxc lxc-templates bridge-utils -y#二、检查服务是否正常运行
systemctl status lxcdemo
以 “创建 Ubuntu 容器(命名 lxchost1)” 为例,覆盖从初始化到删除的完整流程:
1. 检查 LXC 环境有效性
# 1. 确认LXC服务已启动(active状态)
systemctl status lxc
# 2. 检查系统对LXC的功能支持(namespaces/cgroups需均为“enabled”)
lxc-checkconfig
# 3. 查看可用容器模板(了解支持的系统:ubuntu/centos/alpine等)
ls /usr/share/lxc/templates/
# 示例输出:含lxc-ubuntu、lxc-centos、lxc-alpine等模板
2. 创建容器(耗时较长,需下载系统包)
# Ubuntu系统创建Ubuntu 16.04(xenial)容器,架构amd64
lxc-create -t ubuntu -n lxchost1 -- -r xenial -a amd64# 关键说明:
# - 若CentOS上创建Ubuntu容器,需用“download”模板:
# lxc-create --name centos-ubuntu --template=download -- --dist=ubuntu --release=xenial --arch=amd64
# - 创建完成后,会提示默认用户“ubuntu”及密码“ubuntu”
3. 查看容器初始状态
# 用lxc-ls -f查看所有容器状态(刚创建的容器为“STOPPED”)
lxc-ls -f
# 示例输出:
# NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
# lxchost1 STOPPED 0 - - - false
4. 启动容器并验证
# 1. 后台启动容器(-d参数避免占用终端)
lxc-start -n lxchost1 -d
# 2. 再次查看状态(应变为“RUNNING”,并显示IPV4)
lxc-ls -f
# 示例输出:lxchost1 RUNNING 0 - 10.0.3.248 - false
# 3. 查看容器详细信息(PID、CPU/内存使用、网络流量)
lxc-info -n lxchost1
# 示例输出:含State: RUNNING、PID: 282127、IP: 10.0.3.248、Memory use: 59.52 MiB
5. 进入容器并操作(两种方式)
方式 1:SSH 登录(需知道容器 IP)
# 容器IP从lxc-info或lxc-ls -f获取(示例:10.0.3.248)
ssh ubuntu@10.0.3.248
# 输入默认密码“ubuntu”,登录后可执行容器内命令(如查看IP、文件系统)
ubuntu@lxchost1:~$ ip addr # 查看容器内网络(eth0为容器网卡)
ubuntu@lxchost1:~$ df -h # 查看容器内磁盘挂载(与宿主机独立)
ubuntu@lxchost1:~$ ps -ef # 查看容器内进程(init进程PID为1,与宿主机隔离)
方式 2:lxc-attach 直接执行命令(无需 SSH)
# 在宿主机执行容器内命令(示例:输出“Hello bit”)
lxc-attach -n lxchost1 --clear-env -- echo "Hello bit"
# 直接进入容器终端(类似SSH登录后的交互环境)
lxc-attach -n lxchost1
6. 停止与删除容器
# 1. 停止运行中的容器
lxc-stop -n lxchost1
# 验证:lxc-ls -f显示“STOPPED”
# 2. 删除已停止的容器(不可逆,需确认)
lxc-destroy -n lxchost1
# 验证:lxc-ls -f无该容器记录
关键注意事项
容器隔离性:容器根文件系统(/var/lib/lxc/<容器名>/rootfs)与宿主机完全独立,修改容器内文件不影响宿主机。
模板差异:Ubuntu 默认模板支持直接创建 Ubuntu 容器,CentOS 若需创建非 CentOS 容器(如 Ubuntu),需用 “download” 模板并指定--dist(系统)、--release(版本)、--arch(架构)。
缓存复用:容器模板缓存存于/var/cache/lxc/,重复创建相同系统 / 版本的容器时,无需重新下载,可加速创建。
服务依赖:CentOS 安装后需启动libvirtd服务(LXC 依赖其虚拟化功能),Ubuntu 无需额外启动该服务。
永久热烈,永久尽享欢愉。永久心跳,永久年少青春。——济慈
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸