C# 获取docx文档页数的古怪方法
文章目录
- C# 获取docx文档页数的古怪方法
- 1. 背景
- 2. docx是一个zip
- 3. 使用C#代码解压docx文档
- 4. 那个自称document的XML
- 5. 查找并统计分页标签
C# 获取docx文档页数的古怪方法
1. 背景
有时候,我们需要获取一个Word格式文档(docx)的页数,甚至在某一页做某些操作,如果我们使用COM+调用office或wps这些商用软件,是相当方便的,而使用aspose.word这些商业库,也是短短几行代码的事情。然而,当程序跑在某些特定的环境(例如没有Office软件的环境),或者我们资金有限而又有道德洁癖(不愿意使用盗版),获取docx文件页数,这种看似简单的问题反而变得复杂,因为我们常用的开源库poi/npoi或OpenXML SDK等,并没有提供这样的操作。
本着“自己动手,丰衣足食”的原则,那就自己手工写代码看看吧,顺道把坑踩一遍。
2. docx是一个zip
既然是要自己写代码处理这种问题,那么我们要回到问题的本质——word的docx文档究竟是什么?.docx 文件本质上就是一个 ZIP压缩包。我们将.docx 文件扩展名改为.zip,然后使用解压缩工具来打开它。解压后,你会发现其中包含许多XML文件和媒体文件(如下图),它们共同构成了Word文档的内容和格式。

可见,我们可以从这对xml文件着手,解决问题,而Word的这种docx文档有什么特点呢?我也请教了AI:
- 基于 Open XML 标准:.docx 格式是微软Word(从2007版本开始)所使用的基于Office Open XML标准的文件格式。
- 包含大量XML文件:与旧的二进制格式的.doc文件不同,.docx 文件是一个包含多个XML文件的压缩集合。
- 主要内容:解压后,核心的文本内容通常保存在
word/document.xml文件中,而文档的样式信息、媒体文件等则分别存储在其他文件夹或文件中。 - 优点:这种基于XML和压缩的格式使得文件更小,并且允许更灵活地访问和编辑文档的内部结构。
那么,我们的这个奇奇怪怪的获取docx文档页数的方法,就从word/document.xml文件开始了。
3. 使用C#代码解压docx文档
解压这样的文档,并不复杂,直接用ZipFile这样的库即可(具体可参考我的博文C# 压缩解压文件的常用方法),示例代码如下:
var docxFile = $@"{Environment.CurrentDirectory}{Path.DirectorySeparatorChar}test.docx";
var extractedPath = $@"{Environment.CurrentDirectory}{Path.DirectorySeparatorChar}extracted";
var xmlPath = $@"{extractedPath}{Path.DirectorySeparatorChar}word{Path.DirectorySeparatorChar}document.xml";if (File.Exists(docxFile))
{System.IO.Compression.ZipFile.ExtractToDirectory(docxFile, extractedPath, true); // 最后一个参数为true,目录已存在则覆盖Console.WriteLine($"Extracted {docxFile} to {extractedPath}");
}
else
{Console.WriteLine($"File {docxFile} does not exist.");
}
解压后的目录如下:

4. 那个自称document的XML
进入解压后的word目录了,我们可以找到document.xml文件,敢自称document,也肯定是有点东西的,打开一看,确实名副其实:
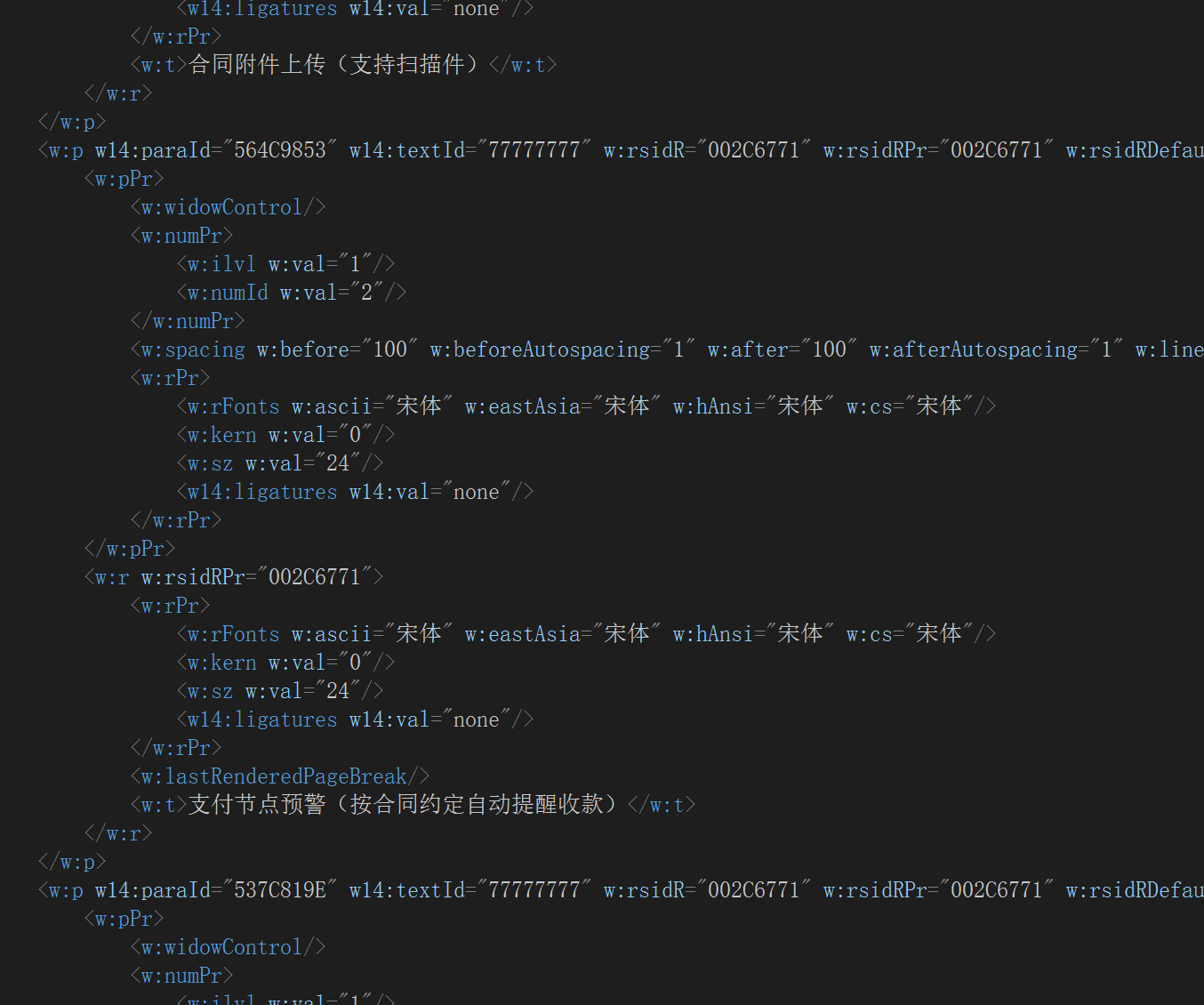
可见一个word文档的整体脉络以及主要的行文,都在这里面了。当然,文档里的图片等资源也是记录在这里,例如对某个资源的引用<a:blip r:embed="rId7"/>等,当然这还牵涉到media和document.xml.rels中的引用关系等等,有机会再细说。那么,回到本次描述的“获取文档页数”这个操作,就比较简单了,只要我们找到里面的<w:lastRenderedPageBreak/>元素,问题就可以解决了。顾名思义,该元素是用于给word文档分页的,相当于用它来“切香肠”,一刀分两页,两刀分三页,以此类推……
5. 查找并统计分页标签
使用自带的System.Xml库,可以对xml文件进行解析,查找并获取<w:lastRenderedPageBreak/>,实现定位和统计等功能(本文就以统计为例)。
if (File.Exists(xmlPath))
{var xmlContent = File.ReadAllText(xmlPath);var xmlDoc = new System.Xml.XmlDocument();xmlDoc.LoadXml(xmlContent);var nsmgr = new System.Xml.XmlNamespaceManager(xmlDoc.NameTable);nsmgr.AddNamespace("w", "http://schemas.openxmlformats.org/wordprocessingml/2006/main");var nodes = xmlDoc.SelectNodes("//w:lastRenderedPageBreak", nsmgr);var cnt = nodes?.Count ?? 0;Console.WriteLine($"使用XML解析的方式找到 <w:lastRenderedPageBreak /> 节点数量: {cnt}");Console.WriteLine($"该文档共有 {cnt + 1} 页");
}
else
{Console.WriteLine($"File {xmlPath} does not exist.");
}
以本文中的测试文档为例,文档共7页,查找并计算出来的页数也是7页,结果与实际一致。

