Spark源码中的AQS思想
1. AQS 是什么?
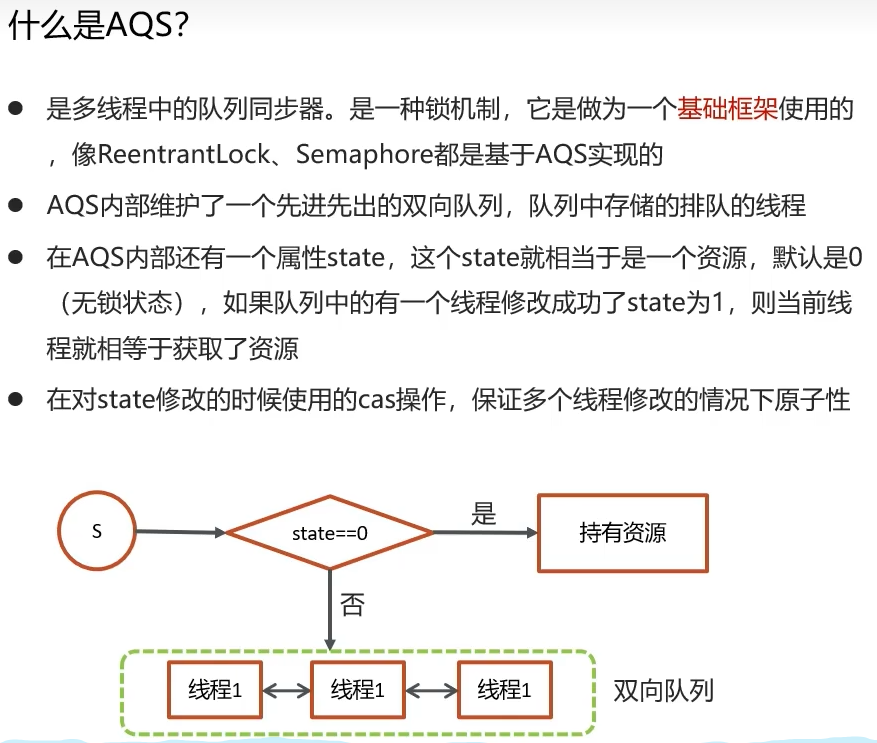
AQS 核心是一个 “状态变量(state)” + 一个 “FIFO 双向线程等待队列”。
工作流程简述:
线程调用
acquire(1)尝试获取资源。AQS 调用子类重写的
tryAcquire(1)方法。如果成功(通常是通过 CAS 将
state从0改为1),则线程继续执行。如果失败,AQS 会将当前线程包装成一个
Node,CAS 操作插入到等待队列的尾部,然后线程可能会被挂起(LockSupport.park())。当持有资源的线程释放时(调用
release(1)),它会调用tryRelease(1),成功后,AQS 会负责唤醒队列中下一个等待的线程。
可能读完上面的仍然不知道AQS具体用来作什么的,这里重点标记一下。 AQS 是“通过一个状态变量和一個等待队列来构建同步器”的核心架构思想。
在 Spark 的核心源码中,不会直接找到一个 extends AbstractQueuedSynchronizer的类。这是因为 Spark 主要使用 Scala 编写,且作为一个分布式计算框架,其核心的同步问题(如任务调度、资源协调)是跨网络的,需要通过其他方式(如 RPC 消息、主从架构)来解决,而不是依赖于单机 JVM 内的锁机制。
然而,这绝不意味着 AQS 的思想与 Spark 无关。恰恰相反,AQS 所代表的“状态管理 + CAS + 队列同步”的核心思想,是 Spark 乃至所有高性能并发框架的基石。Spark 在解决单个 JVM 内的并发问题时,大量运用了与 AQS 完全一致的并发编程模式。
AQS 的核心理念在 Spark 中主要体现在以下两个层面:
层面一:JVM 内部的并发控制(直接应用AQS理念)
Spark 在 Driver 和 Executor 进程内部,需要管理多线程并发访问共享资源。在这里,你随处可见 AQS 思想的“影子”,但它们通常使用更底层的工具或更轻量的实现。
volatile变量 + CAS 操作(AQS 的基石)
state的等价物:Spark 中有大量用作状态标志的volatile变量。例如:
org.apache.spark.SparkContext中的@volatile private var stopped: Boolean。它相当于一个简单的“锁状态”,通知所有线程该上下文是否已停止。
CAS 的广泛应用:Spark 使用
AtomicInteger,AtomicLong,AtomicReference等原子类(其内部实现就是 CAS)来进行无锁计数和状态更新。例如:生成唯一任务 ID、累加器(Accumulator)的更新、管理内存页分配等。这在
TaskMemoryManager、AccumulatorV2等类中非常常见。
等待队列(AQS 队列的抽象体现)
Spark 内部大量使用
java.util.concurrent包下的同步工具,而这些工具很多本身就是基于 AQS 实现的。例如:
CountDownLatch(基于 AQS 共享模式)被用于等待任务阶段完成。JobWaiter类中就使用了countDownLatch。例如:线程池。Spark 内部使用的线程池,其底层实现就依赖于类似 AQS 的机制来管理等待执行的任务队列(
BlockingQueue)。
层面二:分布式的协调与同步(AQS思想的延伸)
这是 Spark 更核心的部分。AQS 中“状态-队列”的思想被抽象和升华,用于解决分布式环境下的协调问题。
Driver 的调度器:分布式状态机
state的延伸:在DAGScheduler和TaskScheduler中,每个作业(Job)、阶段(Stage)、任务(Task)都有其生命周期状态(如:WAITING、RUNNING、FAILED、SUCCESS)。这些状态由 Driver 统一管理,是集群的“全局状态”。
队列的延伸:TaskScheduler维护着不同优先级或调度模式的作业队列和任务队列。当 Executor 资源空闲时,Driver 会从队列中取出任务分配给它们。这正是一个 “FIFO 或公平的双向队列” 在分布式场景下的体现。
Executor 的心跳与任务执行
Executor 会定期向 Driver 发送心跳,报告自己的状态(如:空闲、繁忙)和资源情况(可用的 CPU Core 数)。
Driver 根据这些心跳信息,决定将队列中的任务分配给哪个 Executor。这可以看作是一种跨进程的“获取/释放资源”信号。
总结
虽然在 Spark 源码中找不到直接继承 AbstractQueuedSynchronizer的类,但 AQS 所代表的“通过一个状态变量和一個等待队列来构建同步器”的核心架构思想,是 Spark 并发设计的灵魂所在。
在单机层面:Spark 使用
volatile、CAS和基于 AQS 的并发工具(如CountDownLatch)来实现高效、无锁的并发控制。在分布式层面:Spark 将这种思想扩展,用 Driver 作为中央协调器,维护着全局状态和全局任务队列,通过 RPC 消息机制 来协调多个节点间的同步,从而构建了整个分布式计算框架。