整合亮数据Bright Data与Dify构建自动化分析系统

文章目录
- 引言
- 一、搭建环境
- 1.1 步骤一: 安装 Docker Desktop
- 1.1.1 配置国内镜像
- 1.2 步骤二:部署及启动 Dify
- 1.2.1 获取 Dify 源码
- 1.2.2 配置 Dify
- 1.2.3 启动 Dify 服务
- 1.2.4 访问 Didy 平台
- 1.3 步骤三:第三方大语言模型(LLM)服务
- 1.4 步骤四:获取亮数据 (Bright Data) 服务 API-KEY
- 二、实战演示:亮数据与Dify,实现视频数据的自动化抓取与分析
- 2.1 节点一:开始 (Start) - 定义工作流入口
- 2.2 节点二:数据采集 - 集成亮数据 Web Scraper 工具
- 2.2.1 安装并授权 Bright Data 工具
- 2.2.2 配置亮数据节点
- 2.3 节点三:集成大语言模型 (LLM) - 为工作流注入智能
- 2.3.1 准备工作:安装 OpenAPI 兼容插件
- 2.3.2 关键步骤:添加并配置新模型
- 2.3.3 在工作流中使用新模型
- 2.3.4 核心步骤:编写提示词 (Prompt Engineering)
- 2.4 节点四:结束 (End) - 定义工作流的最终输出
- 2.5 释放数据价值:我们能用这份数据做什么?
- 三、总结与展望:开启你的自动化分析之旅
引言
在当今信息爆炸的时代,视频已成为信息传播和商业分析的关键媒介。然而,海量视频数据的手动抓取、处理和分析不仅效率低下,而且难以规模化,成为许多企业和开发者面临的共同挑战。如何才能高效地从视频中提取有价值的洞察?
本文将为您揭示一种强大的自动化解决方案。我们将深度探讨如何将业界领先的数据收集平台 亮数据 (Bright Data) 与直观的 LLM 应用开发平台 Dify 相结合,构建一个从视频数据抓取到智能分析的端到端自动化工作流。
通过本文,您将学习到:
- 如何配置亮数据以实现稳定、高效的视频数据抓取。
- 如何利用 Dify 快速构建和部署能够处理、分析视频内容(如自动生成摘要、提取关键信息等)的智能应用。
- 如何将两者无缝集成,打造一个无需人工干预的自动化数据处理管道。
无论您是希望提升数据分析效率的开发者,还是寻求数据驱动决策支持的产品经理,本文都将为您提供一套切实可行的实践指南,助您轻松解锁视频数据的巨大潜力
一、搭建环境
本方案的技术实现路径如下:首先,我们利用 Docker 完成 Dify 应用开发平台的部署。核心流程是在 Dify 中构建一个自动化工作流,该工作流将通过 API 调用来整合两大关键服务:
- 数据抓取:调用 Bright Data MCP 的服务接口,实现对目标视频数据的自动化、规模化采集。
- 智能分析:调用由蓝耘提供的第三方大语言模型(LLM)服务,对抓取到的数据进行深度分析与处理。
为实现这一流程,需要预先获取 Bright Data 和蓝耘的有效 API-KEY,以便在 Dify 工作流中进行配置和调用。
1.1 步骤一: 安装 Docker Desktop
官方网址:https://www.docker.com/
提前规划安装路径和数据存储路径,提高操作效率
安装路径:D:\Program Files\Docker
数据存储路径:D:\Program Files\Docker\data
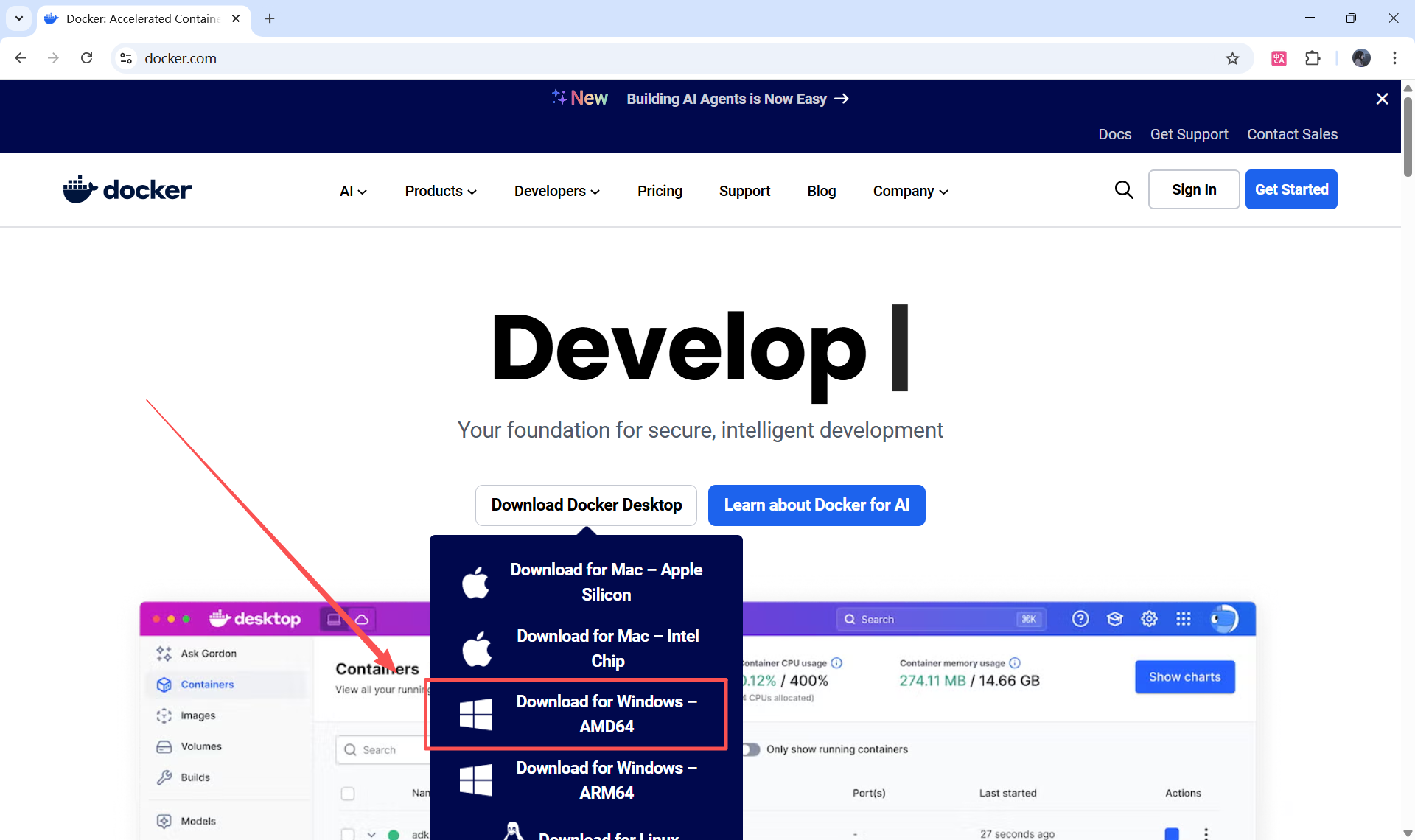
在下载安装包的目录下,右键打开终端,采用命令行形式安装可以配搭参数进行自定义。
- 以管理员身份运行 PowerShell:
- 在开始菜单搜索
PowerShell,右键点击,选择“以管理员身份运行”。
- 在开始菜单搜索
- 使用的命令:
- 在管理员 PowerShell 窗口中,
cd到您的安装包所在目录 (D:\google)。
- 在管理员 PowerShell 窗口中,
PowerShell 中也并没有现成的就地权限提升 Command,不能只敲几个字母实现。
但是可以写这样一长串实现:
Start-Process PowerShell -Verb RunAs "-noexit -command Set-Location -LiteralPath `"$pwd`""
上述脚本复刻了 Windows 资源管理器中“在此处打开 Powershell 窗口(S)”菜单项的运行参数
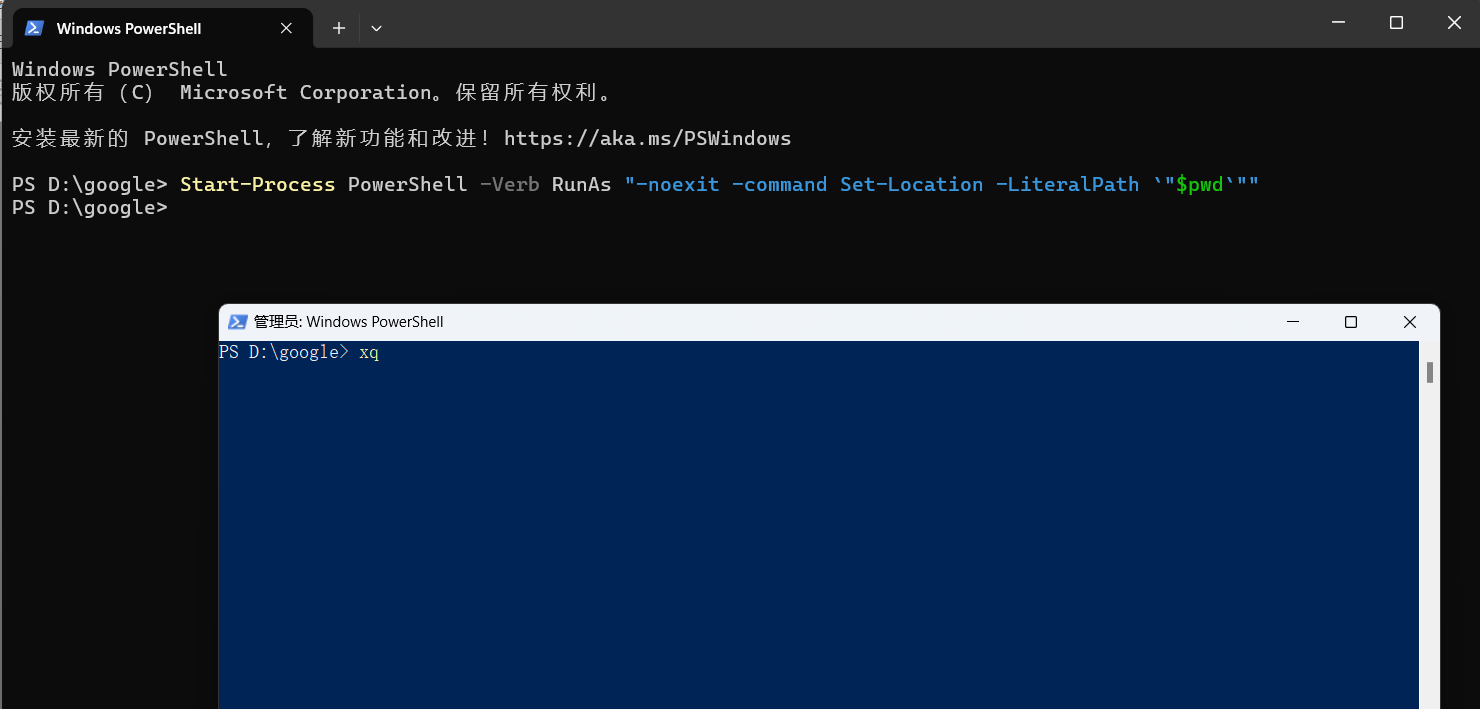
命令如下:
Start-Process -FilePath ".\Docker Desktop Installer.exe" -ArgumentList @("install","--accept-license",'--installation-dir="D:\Program Files\Docker"','--wsl-default-data-root="D:\Program Files\Docker\data"','--windows-containers-default-data-root="D:\Program Files\Docker"'
) -Wait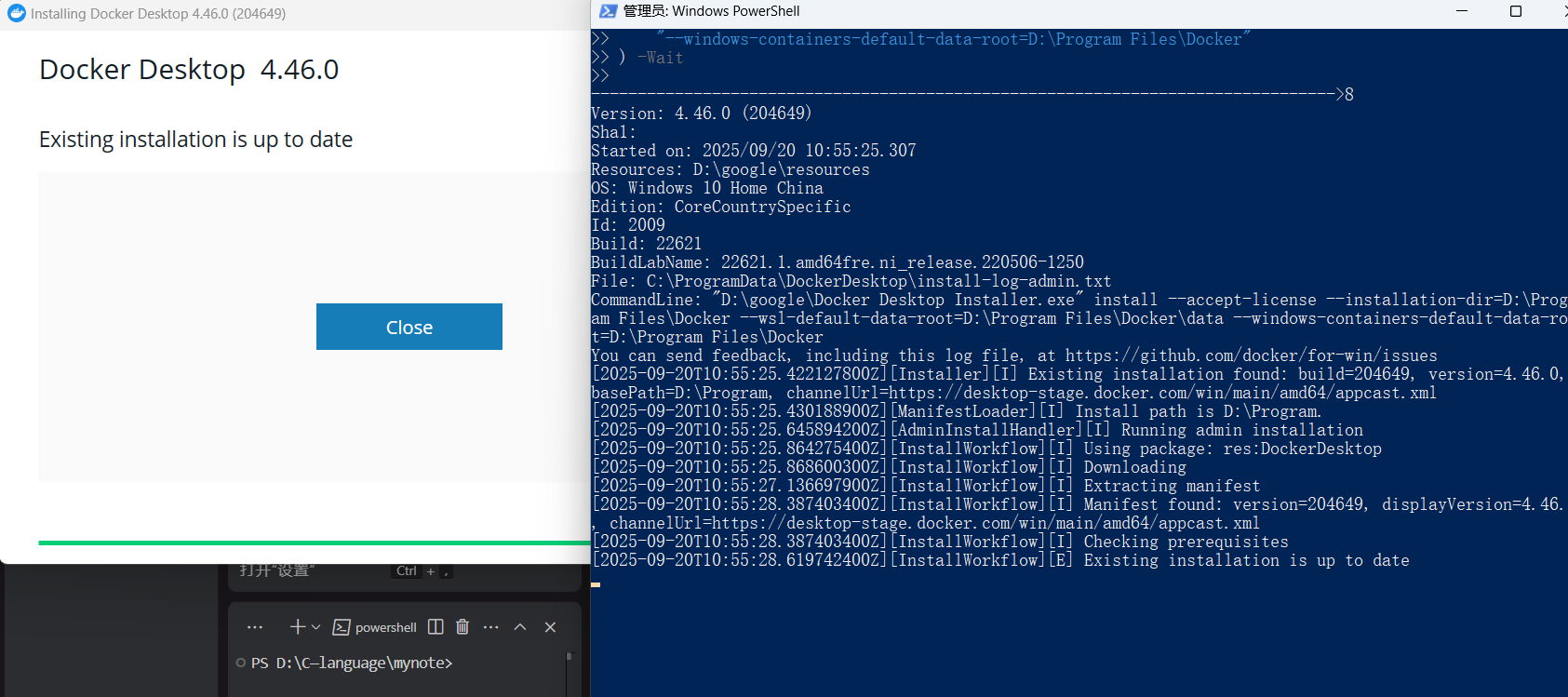
会弹出下载界面,一直点击即可
注意事项:
- 执行此命令需要管理员权限
- 确保目标安装路径有足够的磁盘空间
- 建议在执行前备份重要数据(重点)
- 安装过程中可能需要重启系统以完成WSL2配置
【可能遇到的问题】: 权限不足
最简单的方法:以管理员身份运行 Docker Desktop
- 在你的桌面上找到 Docker Desktop 的快捷方式,或者在 Windows 的开始菜单中搜索它。
- 右键点击 Docker Desktop 的图标。
- 在弹出的菜单中选择 “以管理员身份运行”。
1.1.1 配置国内镜像
配置国内镜像是为了优化 Docker 的构建缓存管理和加速镜像下载,自定义 Dokcer后台服务的行为。
操作流程:在Docker desktop 的 Setting中找到Docker Engine,添加以下配置
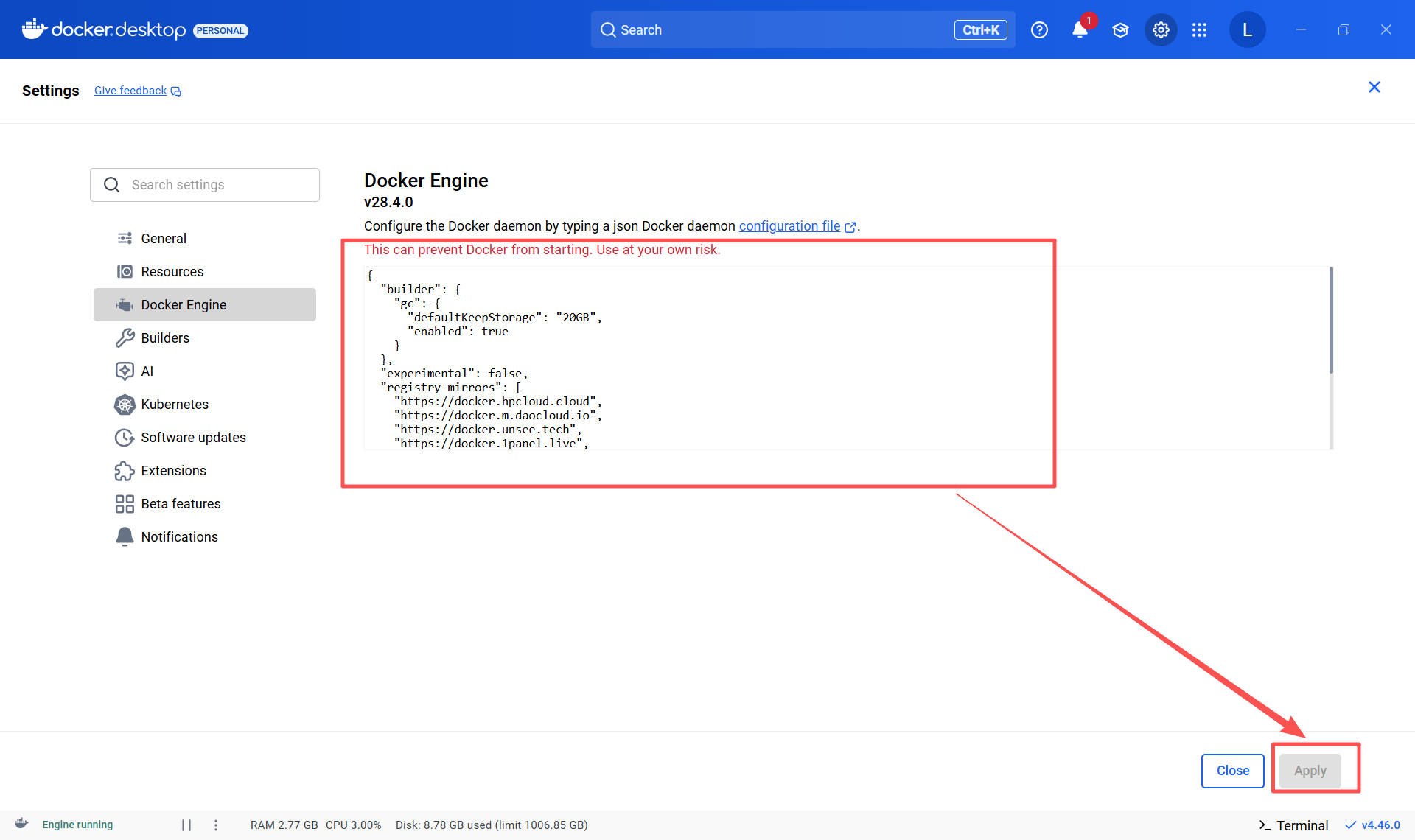
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"registry-mirrors": ["https://docker.hpcloud.cloud","https://docker.m.daocloud.io","https://docker.unsee.tech","https://docker.1panel.live","http://mirrors.ustc.edu.cn","https://docker.chenby.cn","http://mirror.azure.cn","https://dockerpull.org","https://dockerhub.icu","https://hub.rat.dev"]
}Docker 引擎的配置文件部分介绍:
"builder"和"gc":- 这部分是关于 Docker 构建器(builder) 的设置。
"gc"代表 垃圾回收(Garbage Collection)。"enabled": true表示启用了构建缓存的自动清理功能。"defaultKeepStorage": "20GB"表示 Docker 会保留最多 20GB 的构建缓存,超过部分会被清理掉,以节省磁盘空间。"experimental": false:- 这表示你没有启用 Docker 的实验性功能。
"registry-mirrors":- 这是其中一个很关键的配置。它列出了一系列的 Docker 镜像加速器地址。
- 当你使用
docker pull命令从 Docker Hub 拉取镜像时,Docker 会优先尝试从这些配置的镜像地址下载。因为这些服务器通常在国内,所以可以极大地提高镜像下载速度。
1.2 步骤二:部署及启动 Dify
Dify 是一个领先的开源大语言模型(LLM)应用开发平台,旨在帮助开发者和团队快速构建、部署和运营生产级的 AI 应用。
它提供了一套直观的可视化界面,用户可以通过简单的拖拽和配置,轻松创建和管理复杂的自动化工作流(Workflow)和智能体(Agent)。作为一个生产就绪(Production-ready)的平台,Dify 支持包括 GPT、Gemini 在内的多种主流大语言模型,并集成了数据集管理、模型调试和应用监控等全套工具,极大地降低了 AI 应用的开发门槛,让开发者能更专注于业务逻辑的创新。
这里我们需要使用Dify平台创建自动化工作流(Workflow),所以我们先将 Dify 部署。
1.2.1 获取 Dify 源码
官方仓库:https://github.com/langgenius/dify
点击下面链接访问,可以选择ZIP文件或者克隆仓库。虽然这里我选择前者,但是我是比较推荐后者,适用于以后的版本更新。
1.2.2 配置 Dify
首先先解压压缩包,提取里面的文件内容。
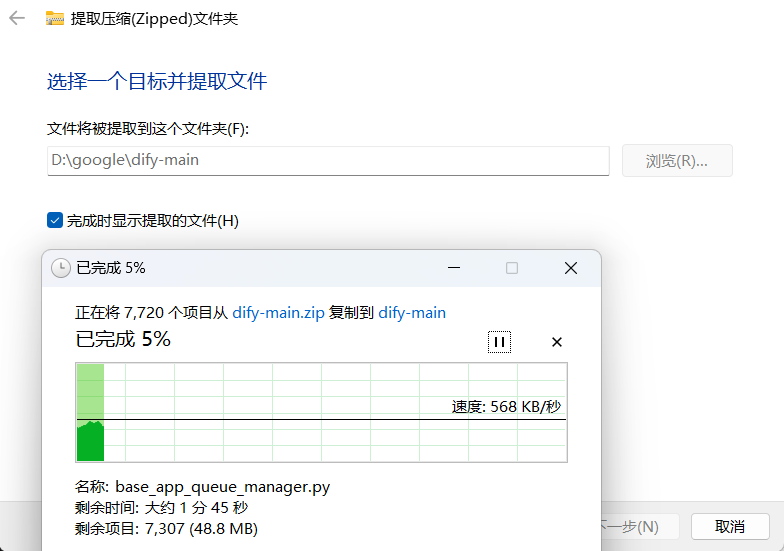
按照提供的操作流程进行操作。
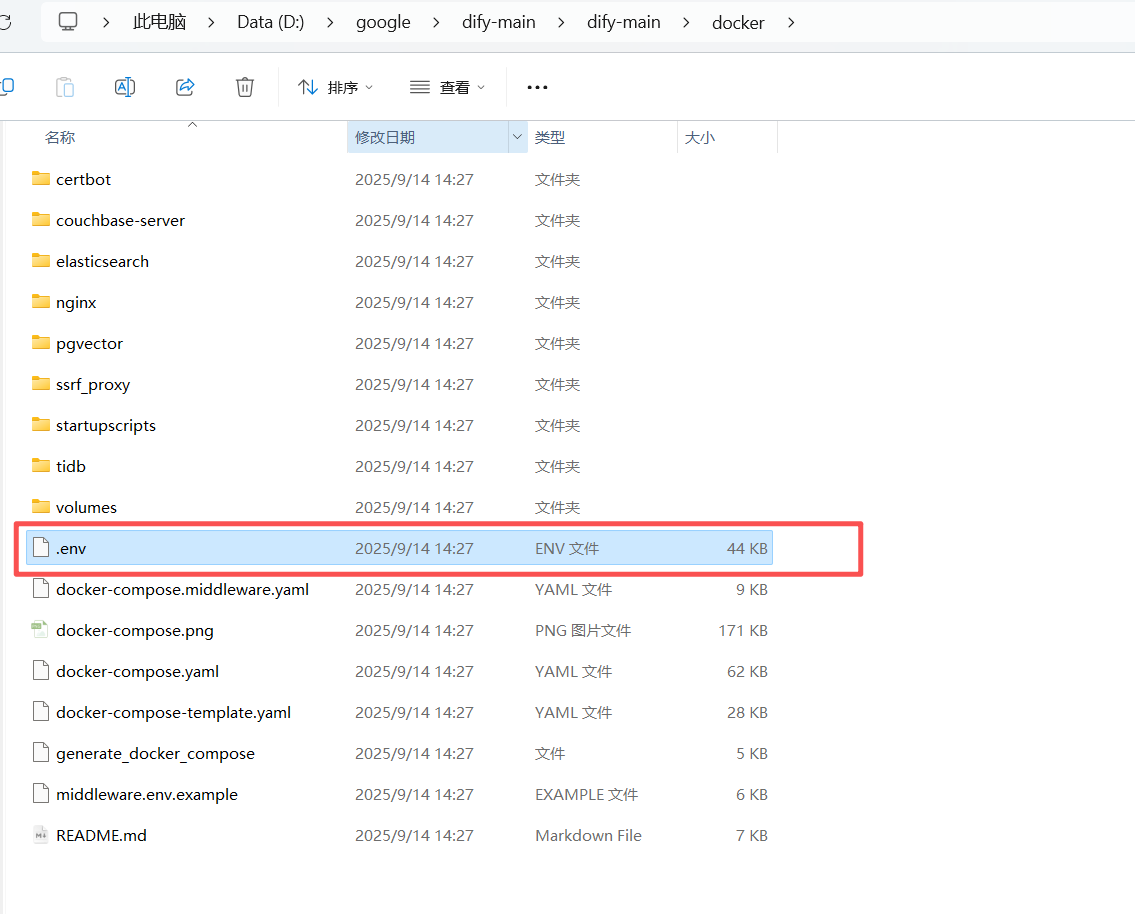
先进入docker目录,将.env.example文件重命名为.env其中,也可以执行上面的cp .env.example .env重命名,两种操作方式。
1.2.3 启动 Dify 服务
在dify-main目录下打开终端,进入docker目录,执行该条命令行。
docker compose up -d
【命令部分介绍】:
Docker Compose 工具会读取当前目录下的 docker-compose.yml 文件,解析出 Dify 应用需要的所有服务(如 API、Web、数据库等),然后在后台创建并启动所有这些容器,让整个 Dify 应用一键运行起来。
up:核心作用:这是docker compose的一个子命令,意为“启动”。-d:这是up命令的一个重要参数,是--detach的缩写,意为“分离模式”或“后台运行”。
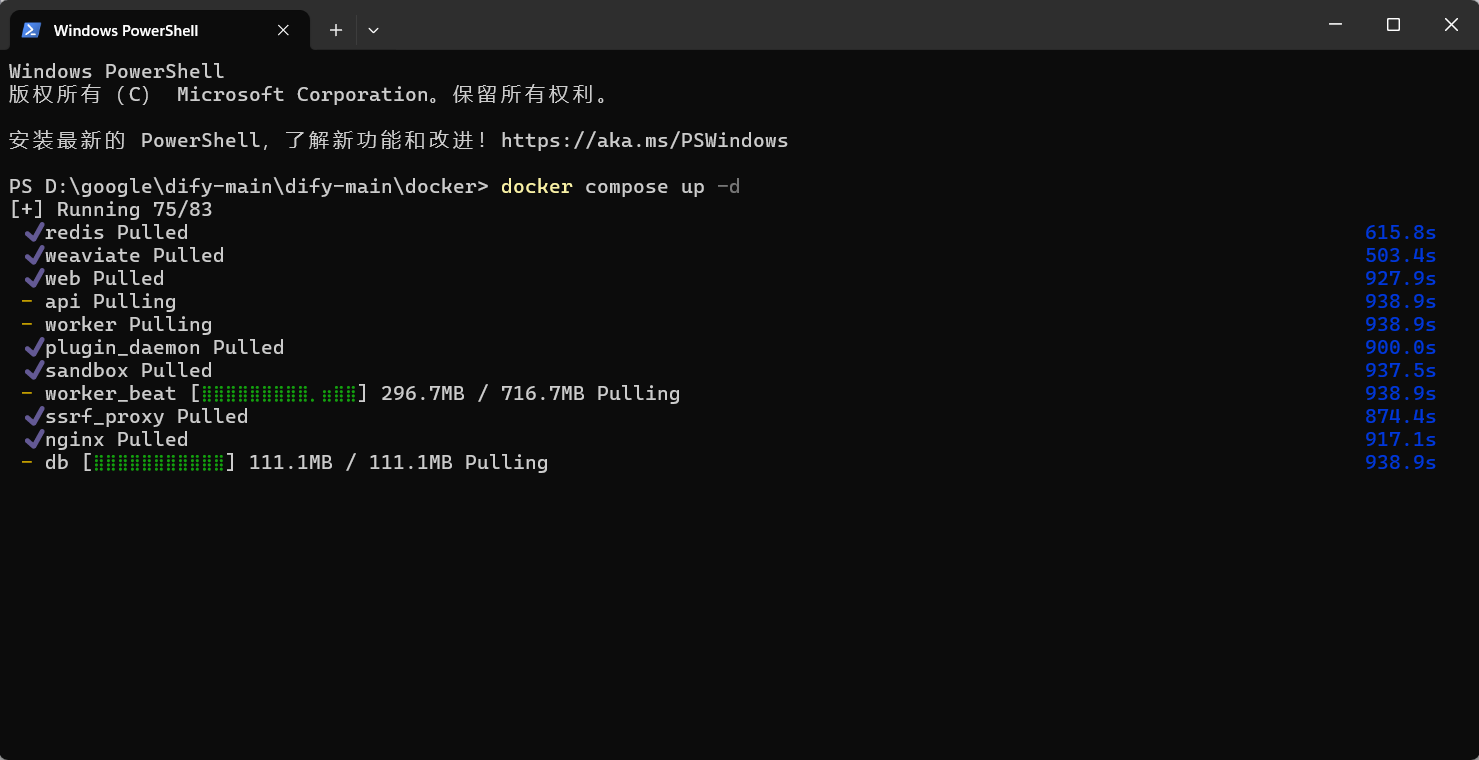
等待Docker下载完多个镜像,过程可能需几分钟,然后Dify就可以成功启动。
以下就是加载完毕,可以正式启动Dify
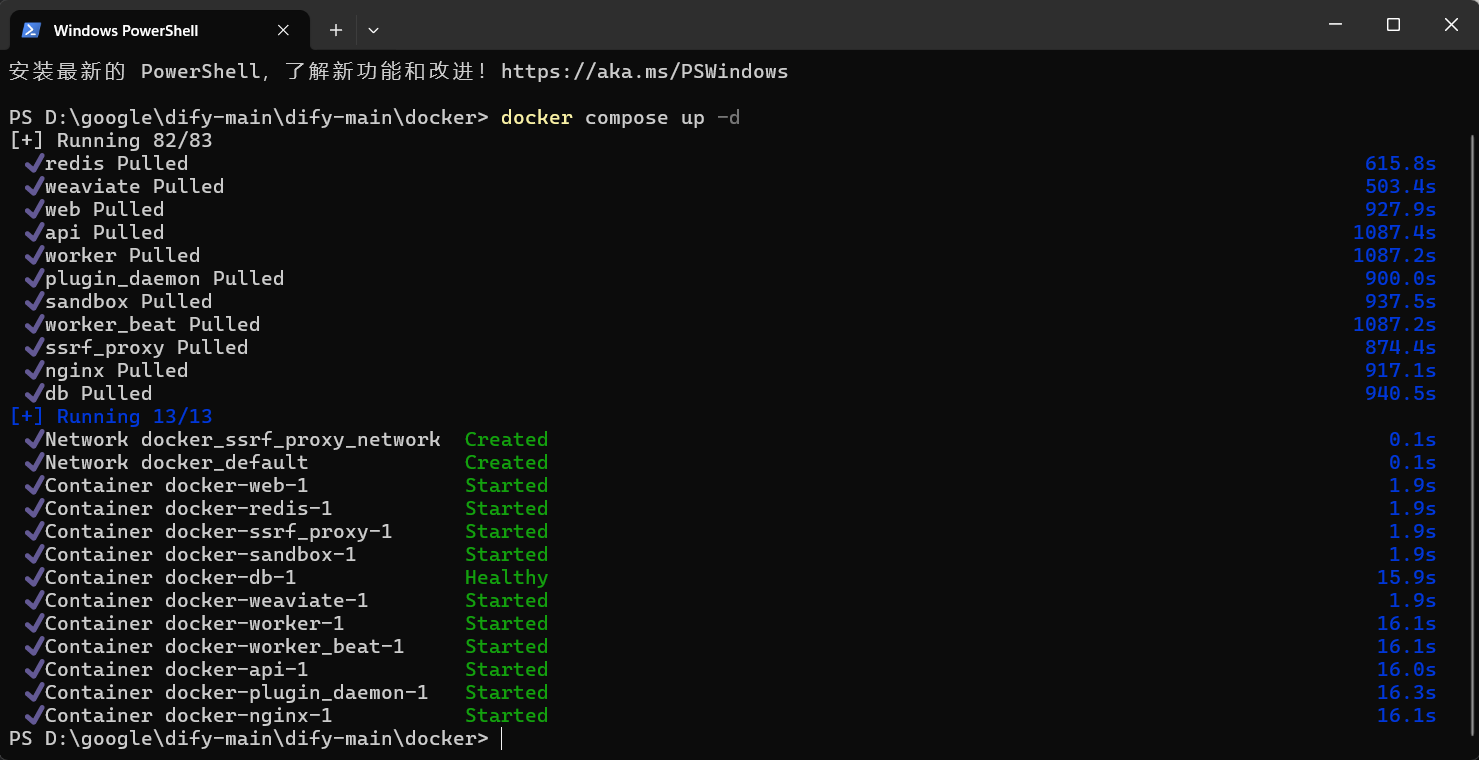
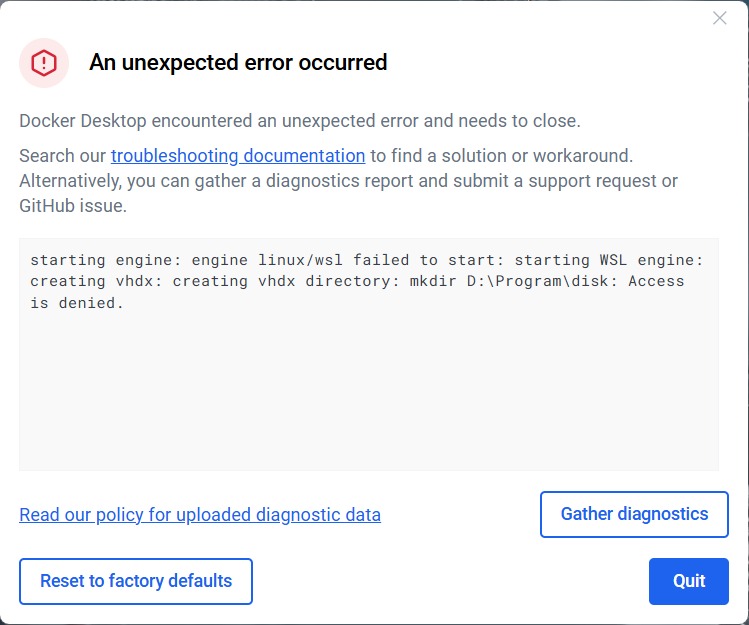
【出现问题】:运行失败
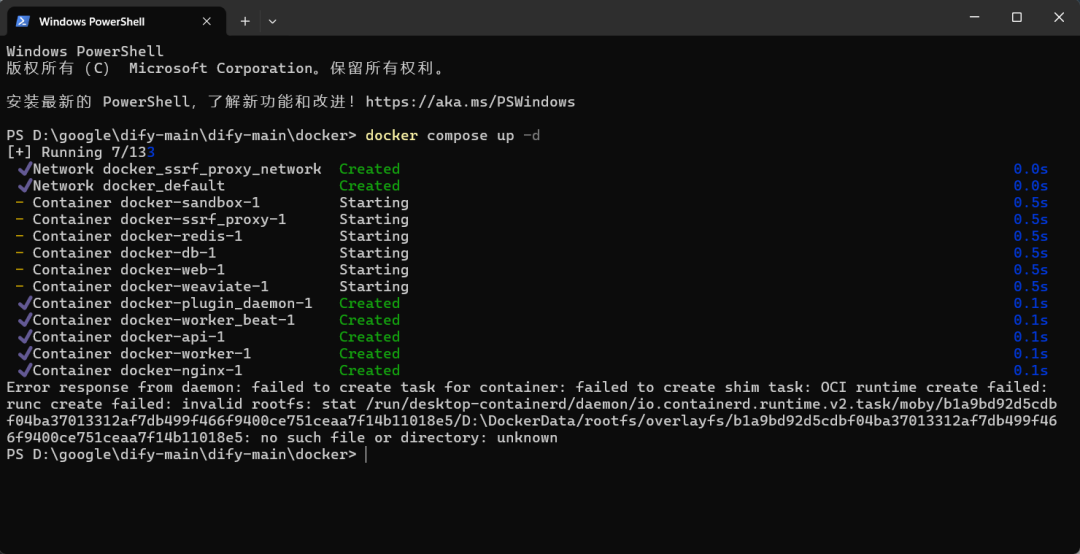
【解决办法】:重置 Docker Desktop
- 打开 Docker Desktop 应用。
- 点击窗口右上角的设置图标(齿轮形状 ⚙️)。
- 在左侧菜单中,选择 “Troubleshoot”(通常是一个小虫子 🐞 图标)。
- 点击 “Reset to factory defaults” 按钮。
- Docker 会弹窗让你确认,请确认并等待它完成重置。这个过程会需要几分钟,Docker 会自动重启。
- 检查 配置文件 内容,重启执行该指令。
1.2.4 访问 Didy 平台
一旦所有服务都正常运行,你就可以通过浏览器访问 Dify 的 Web 界面了(通常是 http://localhost 或 http://127.0.0.1)。这里会自动跳转到注册界面,完成注册后,会自动跳转到Dify主界面。
1.3 步骤三:第三方大语言模型(LLM)服务
蓝耘MaaS平台为开发者提供了极具吸引力的AI模型服务。它不仅汇集了Qwen、DeepSeek、Kimi等多种业界顶尖模型供您灵活选择,更为新用户准备了千万级免费Token,让您能低成本启动项目。平台提供企业级的稳定API,并无缝兼容OpenAI接口,确保您的应用既能可靠运行,又能快速集成。
官方链接:https://maas.lanyun.net/#/maasMarket
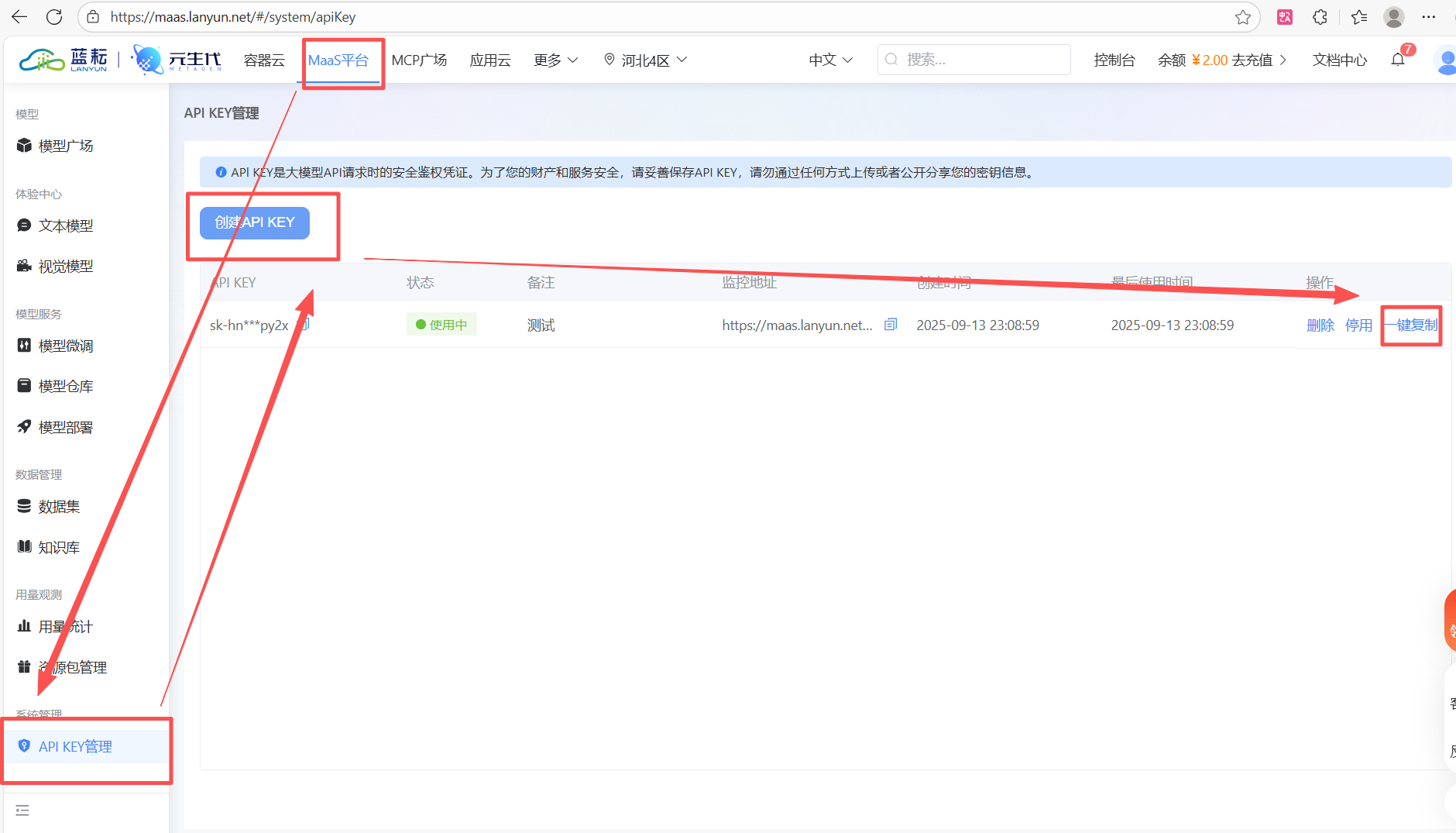
要成功调用蓝耘提供的AI模型服务,您首先需要获取一个专属的API-KEY。请按照以下路径操作:登入蓝耘平台后,依次导航至 MaaS平台 -> API KEY管理,然后点击“创建API KEY”即可生成。
请注意,这个API-KEY是您调用所有AI服务的唯一身份凭证,如同一个“数字身份证”,请务必妥善保管,防止泄露。
1.4 步骤四:获取亮数据 (Bright Data) 服务 API-KEY
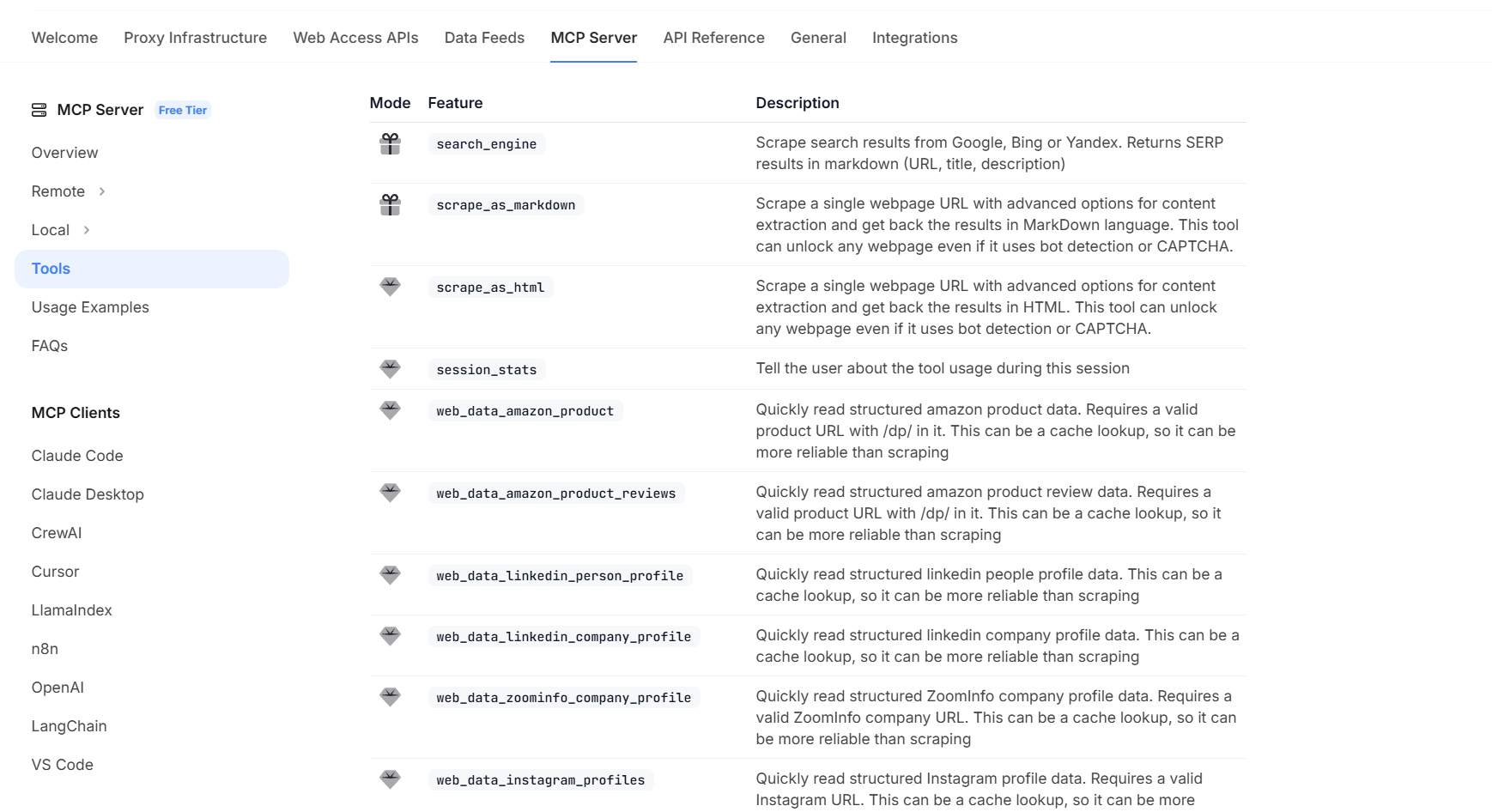
在正式获取API-KEY之前,我们先来深入了解一下本次实践的核心工具——亮数据MCP(Multi-Channel Performance)服务器。
简单来说,它是一个企业级的Web数据和影音API服务,专为大规模、高效率地从主流社交和视频平台抓取公开数据而设计。它强大的能力覆盖了包括 YouTube、TikTok、Instagram 在内的众多热门网站。
Bright Data 可用的影音数据源:
- https://bright.cn/ai/mcp-server/youtube
- https://www.bright.cn/ai/mcp-server/tiktok
- https://www.bright.cn/ai/mcp-server/instagram
通过其丰富的API接口,我们可以轻松获取到各类影音数据,例如:
- 视频详情 (Video Details): 获取单个视频的标题、描述、发布日期、作者信息、观看量等。
- 用户/频道数据 (User/Channel Data): 抓取特定用户或频道下的视频列表、粉丝数、总观看量等。
- 搜索结果 (Search Results): 根据关键词,获取平台的视频搜索结果列表。
- 评论数据 (Comments Data): 提取指定视频下的所有评论内容、评论者信息及互动数据。
要使用这些强大的功能,我们首先需要一个Bright Data账号并获取API密钥,作为我们调用服务的身份凭证。
官方注册链接:https://get.brightdata.com/d_webscraper
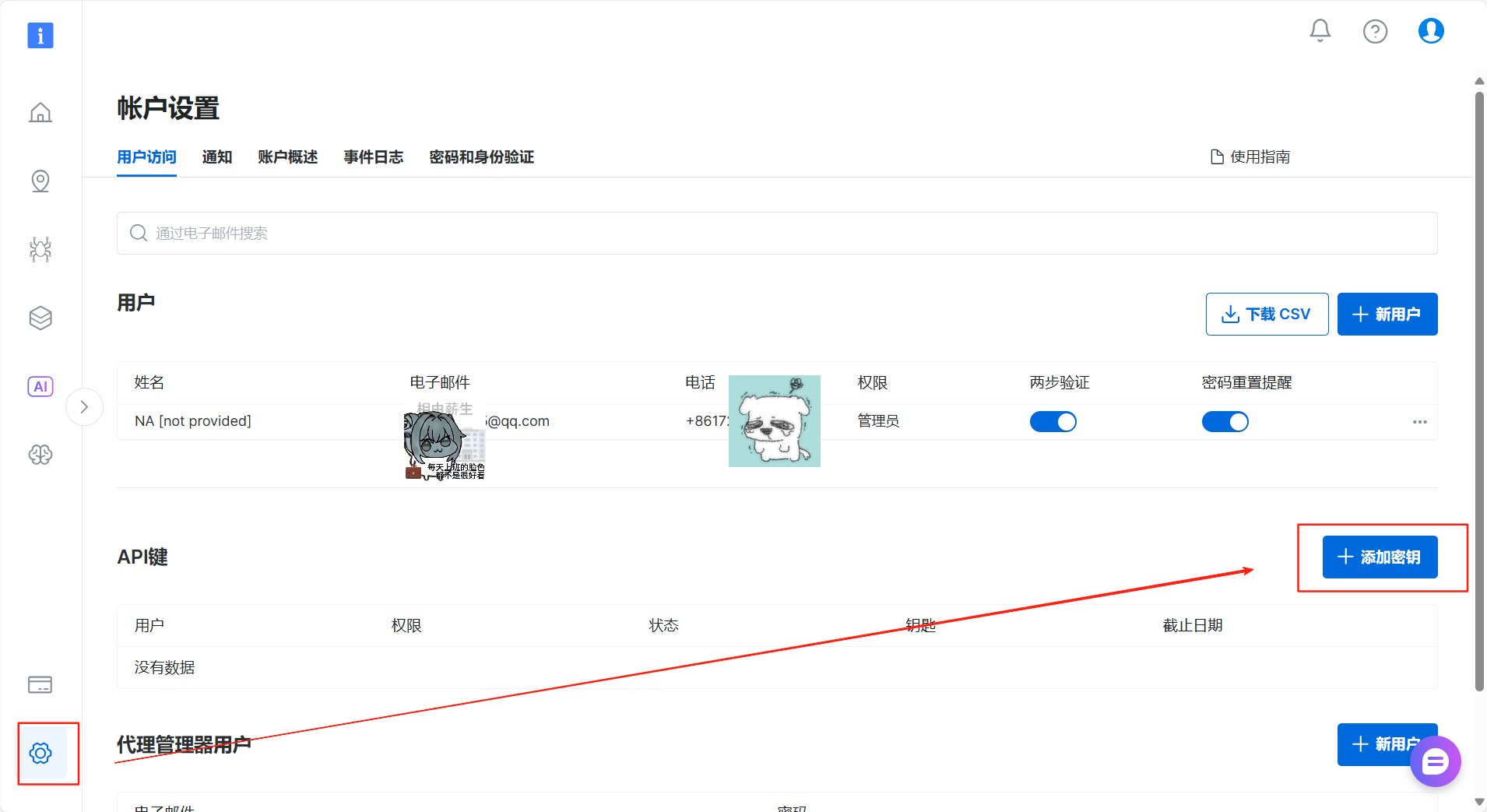
如果您还没有亮数据账号,现在可以通过上述链接注册。新用户每月可免费接收多达5000次的API请求,这对于完成本次实践和后续的探索来说绰绰有余。
【重要提示】:在账户设置中生成API密钥后,请务必立即将其复制并保存在一个安全的地方。出于安全考虑,这个密钥只会完整显示一次。
在完成了所有准备工作后,我们将进入实战环节:结合 亮数据 (Bright Data) 与 Dify 平台,构建一个从视频数据抓取到智能分析的端到端自动化工作流。
二、实战演示:亮数据与Dify,实现视频数据的自动化抓取与分析
本次实践的核心是亮数据 (Bright Data) 提供的“结构化数据订阅” (Structured Data Feeds) 服务。它是一种高度自动化的数据获取范式,旨在将开发者从复杂的数据采集中彻底解放出来。
该服务将数据采集的全部复杂性进行了封装。开发者无需再关心代理管理、爬虫脚本编写、IP轮换、验证码处理和浏览器指纹模拟等棘手问题。您只需通过API提供目标URL和所需数据字段的描述,服务便会在后台自动完成所有采集任务,最终直接返回干净、格式统一的结构化JSON数据。
这种“交钥匙” (turnkey) 的解决方案,使我们能够将精力完全集中在数据应用和业务逻辑的开发上,而不是耗费在与反爬机制的持续对抗中。
首先,在 Dify 平台中,我们开始创建一个新的空白应用。
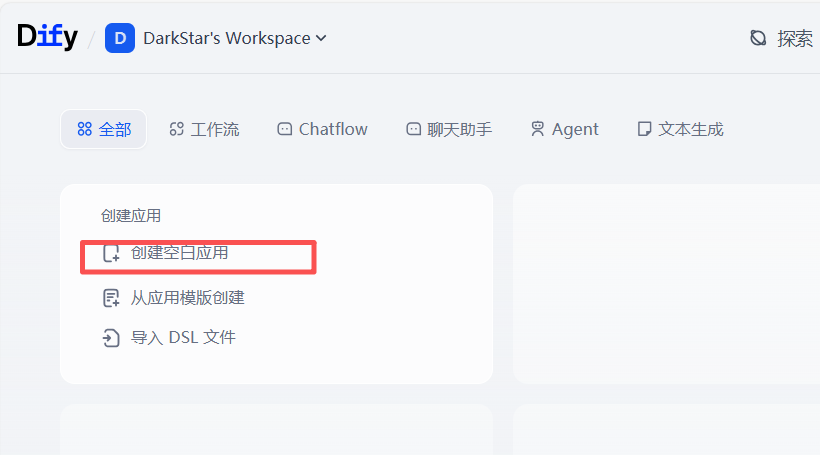
由于我们的目标是构建一个自动化的数据处理管道,因此在“选择应用类型”时,我们选择「工作流 (Workflow)」。这种类型专为处理自动化的、单轮次的任务(如批处理和数据分析)而设计,完美契合我们的需求。
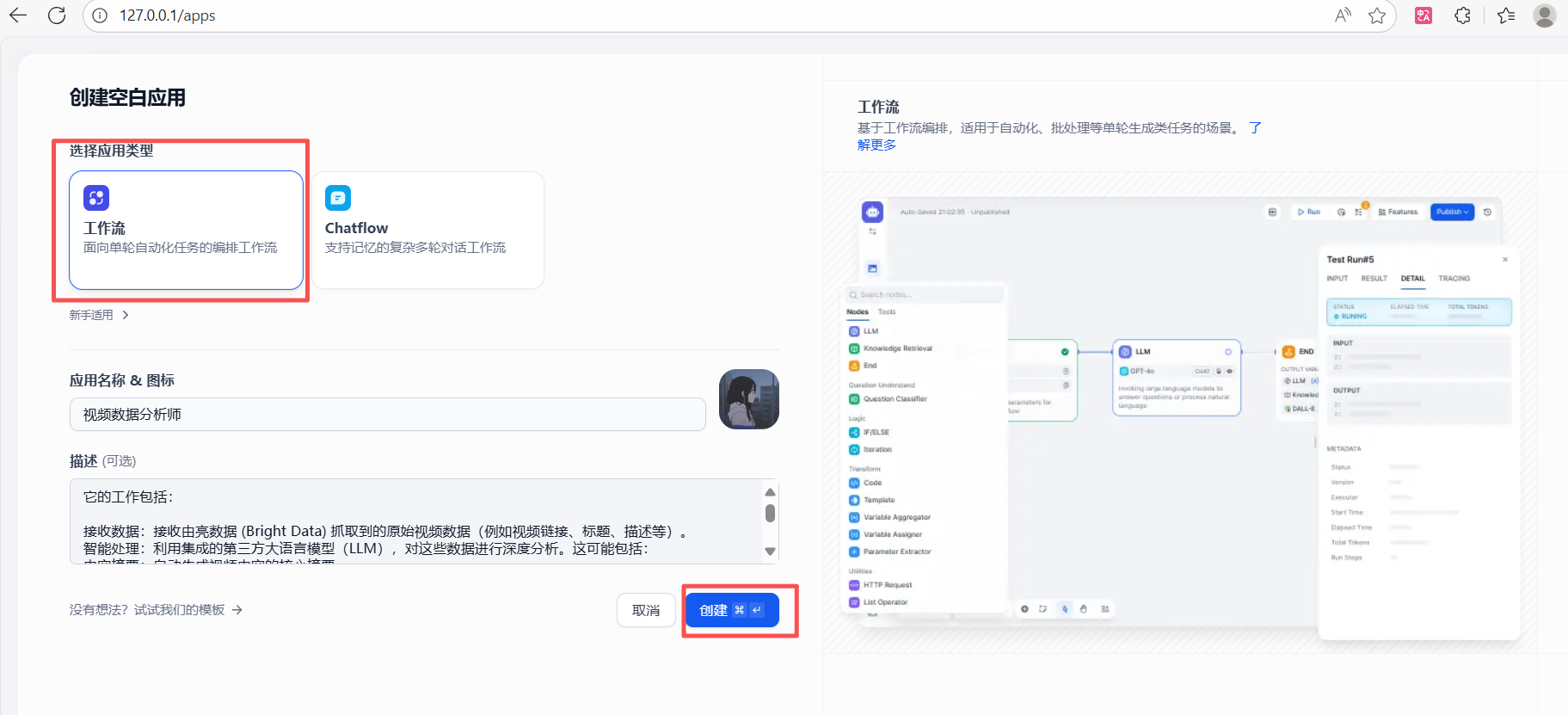
点击“创建”后,我们便进入了 Dify 强大的可视化工作流画布。在这里,我们可以像搭积木一样,通过从左侧的工具栏拖拽不同的功能节点(如调用大语言模型、知识库、执行代码等),并将它们连接起来,从而构建出完整的数据输入、处理和输出流程。整个过程非常直观,让复杂的自动化任务变得简单可控。
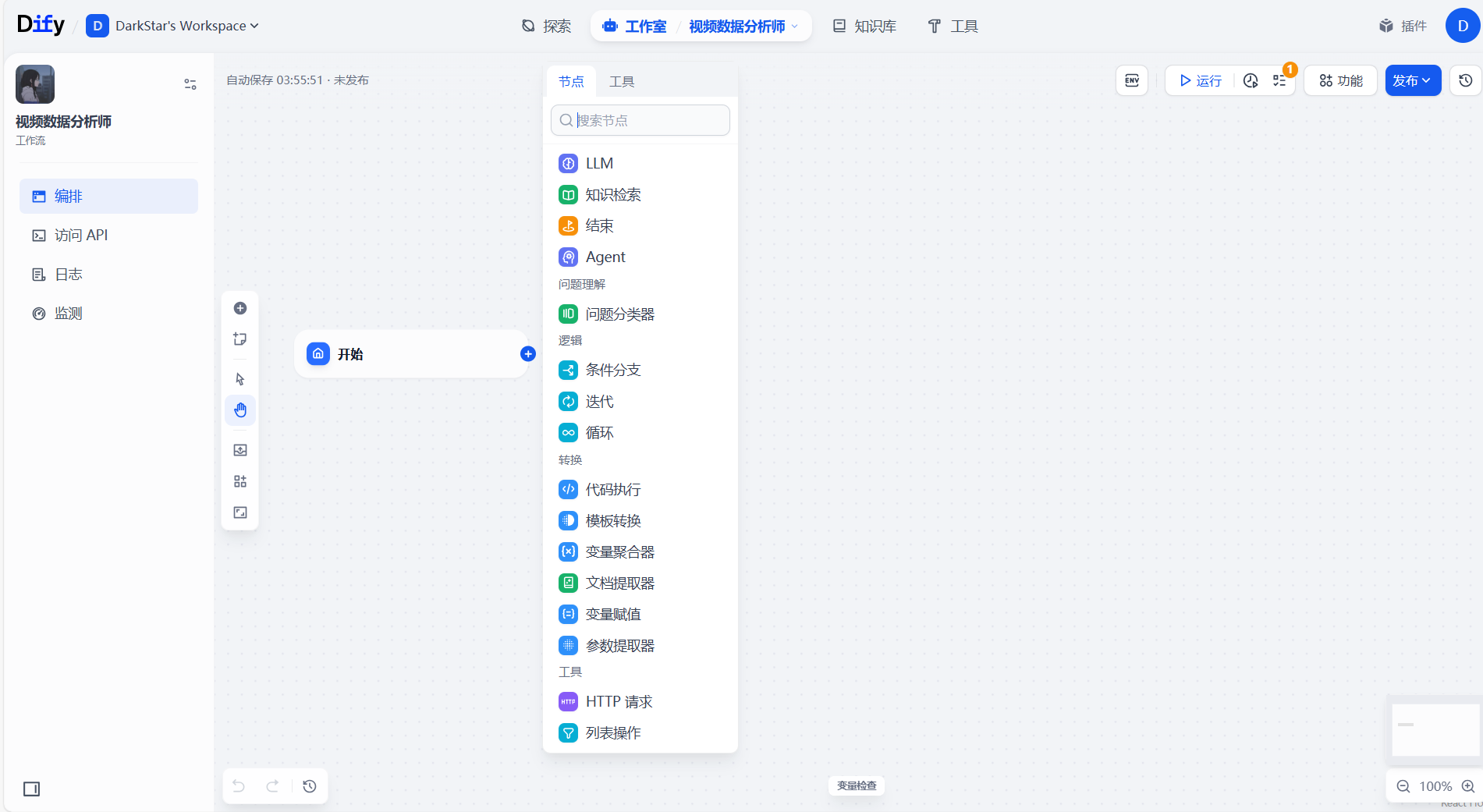
接下来,我们将通过四个核心节点来构建整个工作流。数据将依次流经这些节点,最终完成从原始数据输入到智能分析输出的全过程。
2.1 节点一:开始 (Start) - 定义工作流入口
**「开始」**节点是任何工作流的起点,它负责定义整个流程所需接收的输入变量。当外部服务(例如,我们稍后会用到的亮数据回调)触发此工作流时,传递的数据将首先被该节点捕获。
为了确保能接收亮数据服务返回的数据URL,我们进行如下配置:
- 字段类型:
段落 - 变量名:
INPUT_DATA - 最大长度:
200(设置为200个字符,以确保能够完整接收可能较长的URL。)
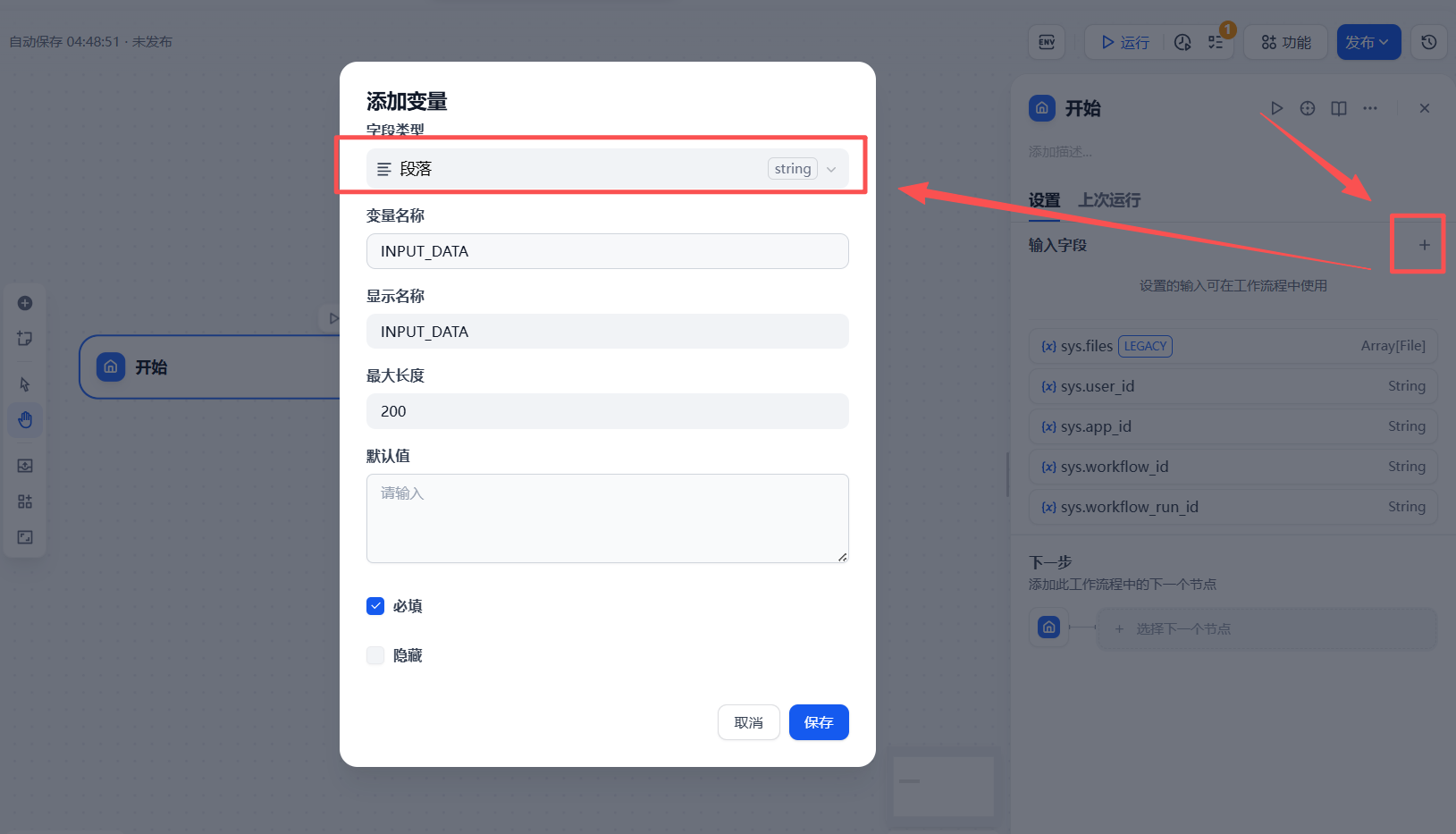
提供链接: https://www.tiktok.com/@inilahcom/video/7547726758842240312
可以使用提供的链接,进行工作流的测试。
2.2 节点二:数据采集 - 集成亮数据 Web Scraper 工具
这是实现自动化数据抓取的关键节点。我们将利用亮数据提供的强大网页抓取能力,根据上一步传入的URL,自动获取目标页面的完整数据,为后续的大语言模型(LLM)分析提供原始材料。
2.2.1 安装并授权 Bright Data 工具
首先,我们需要在 Dify 的工具库中找到并激活亮数据的官方工具。这是一个一次性的安装和授权过程。
- 添加工具:在 Dify 的工作流画布中,点击左侧的「工具」节点,在弹出的列表中搜索
bright。 - 选择工具:找到「Bright Data Web Scraper」工具并点击“添加”。
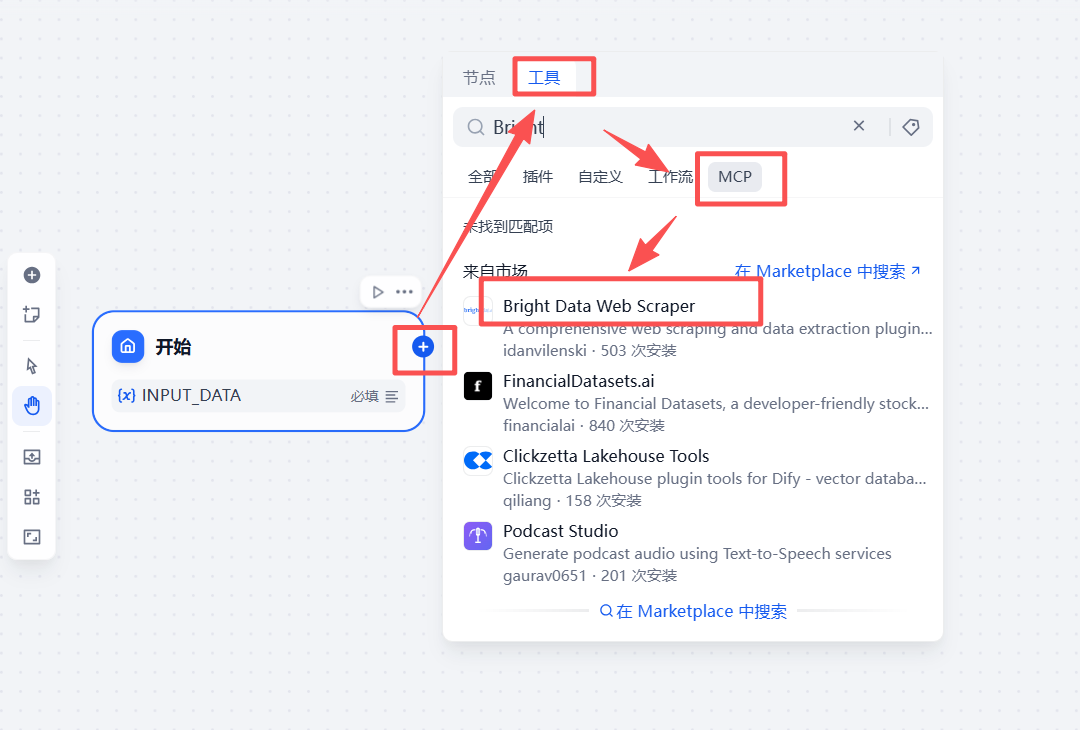
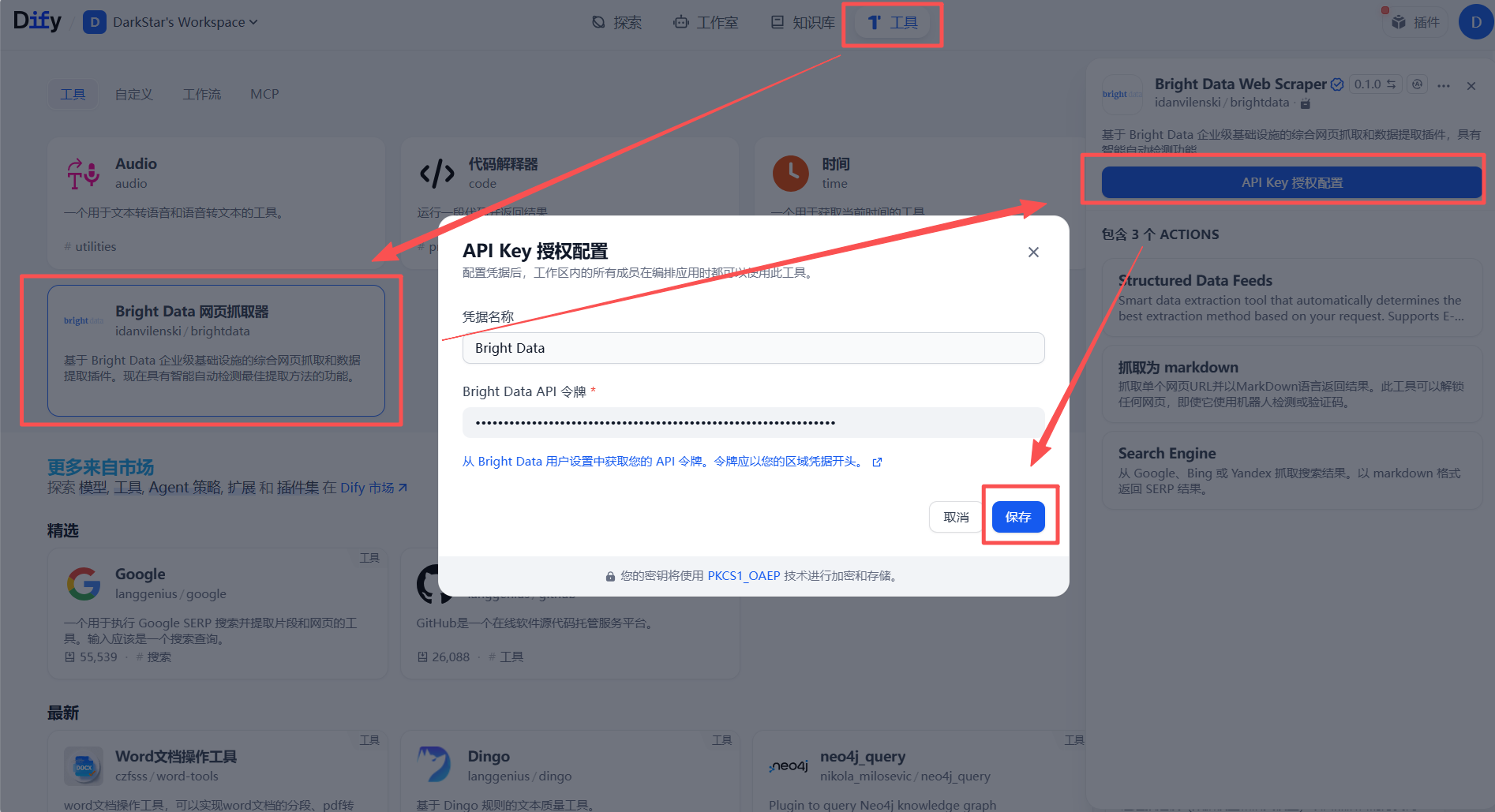
- 授权激活:添加后,系统会要求您提供授权凭证。在此处填入您之前获取的 Bright Data API 密钥,以激活该工具。
2.2.2 配置亮数据节点
授权成功后,返回工作流编辑界面。现在,我们将这个强大的工具作为节点添加到工作流中。
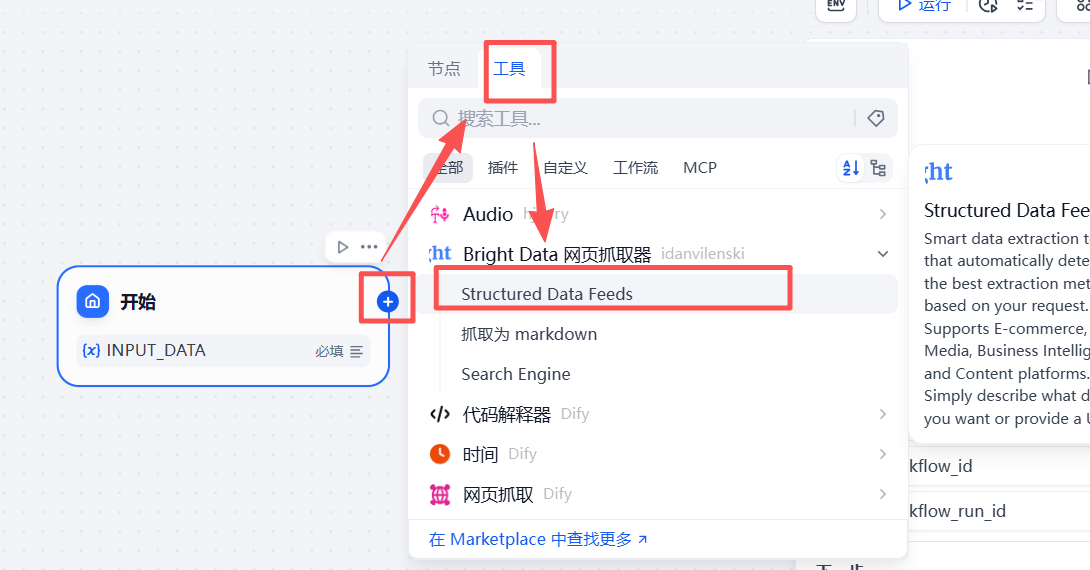
- 在「开始」节点后点击“+”号,依次选择「工具」->「Bright Data Web Scraper」,将其添加到流程中。
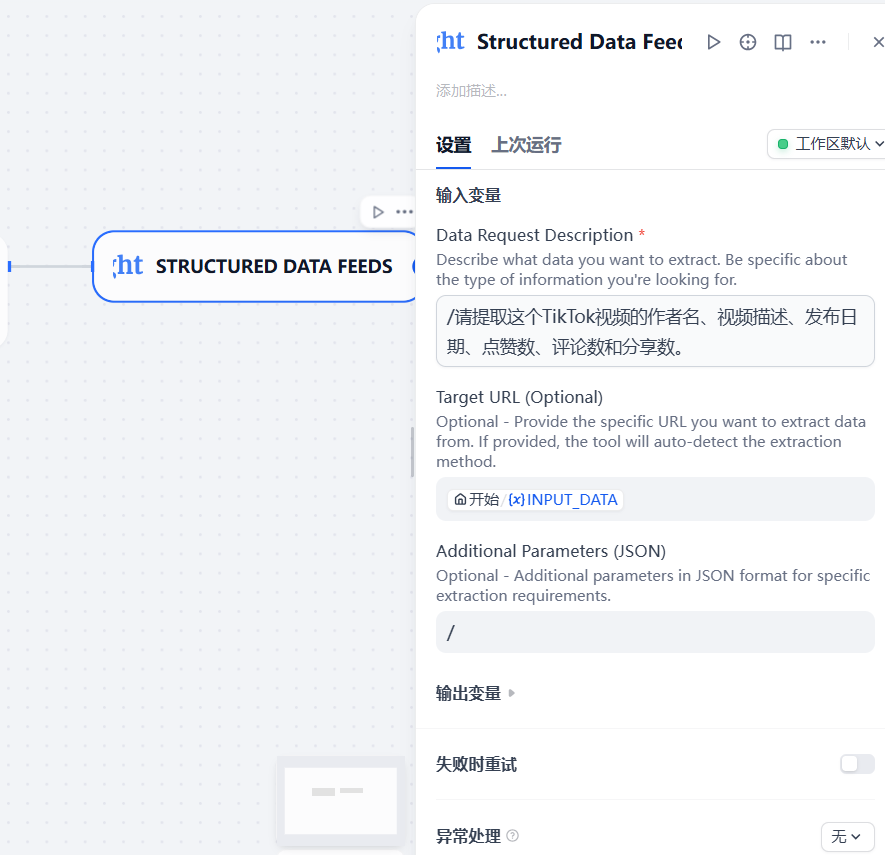
配置节点输入:这是将数据采集能力融入我们工作流的核心步骤。我们需要配置两个关键输入参数:
-
Target URL(目标URL): 这个字段需要接收我们要抓取数据的网址。我们将其与「开始」节点定义的INPUT_DATA变量进行关联。在输入框中键入/或{{,Dify 会智能提示所有上游可用变量,我们选择start.INPUT_DATA即可。 -
Data Request Description(数据请求描述): 这是亮数据服务强大能力的直观体现。我们无需编写任何复杂的CSS选择器或XPath,只需用自然语言描述想要从目标URL中获取哪些数据。例如,对于一个TikTok视频链接,我们可以这样描述:“请提取这个TikTok视频的作者名、视频描述、发布日期、点赞数、评论数和
总结一下:当这个节点运行时,它会:
- 接收到
INPUT_DATA传入的TikTok视频URL。 - 带着您的自然语言指令(“提取作者名、点赞数等”)去访问这个URL。
- 将抓取并结构化好的数据(作者名、点赞数等)作为这个节点的输出,传递给工作流的下一个节点。
2.3 节点三:集成大语言模型 (LLM) - 为工作流注入智能
数据抓取完成后,我们需要一个“大脑”来理解和分析这些数据。这就是大语言模型(LLM)节点的作用。在这一步,我们将把蓝耘提供的 Qwen2.5 模型接入 Dify。
2.3.1 准备工作:安装 OpenAPI 兼容插件
Dify 拥有一个强大的插件市场,可以方便地扩展其功能。由于蓝耘的 MaaS 平台提供了兼容 OpenAI 规范的 API,我们可以通过一个通用插件来接入它。
- 在 Dify 的设置中,导航至「工具」->「Didy插件市场」。
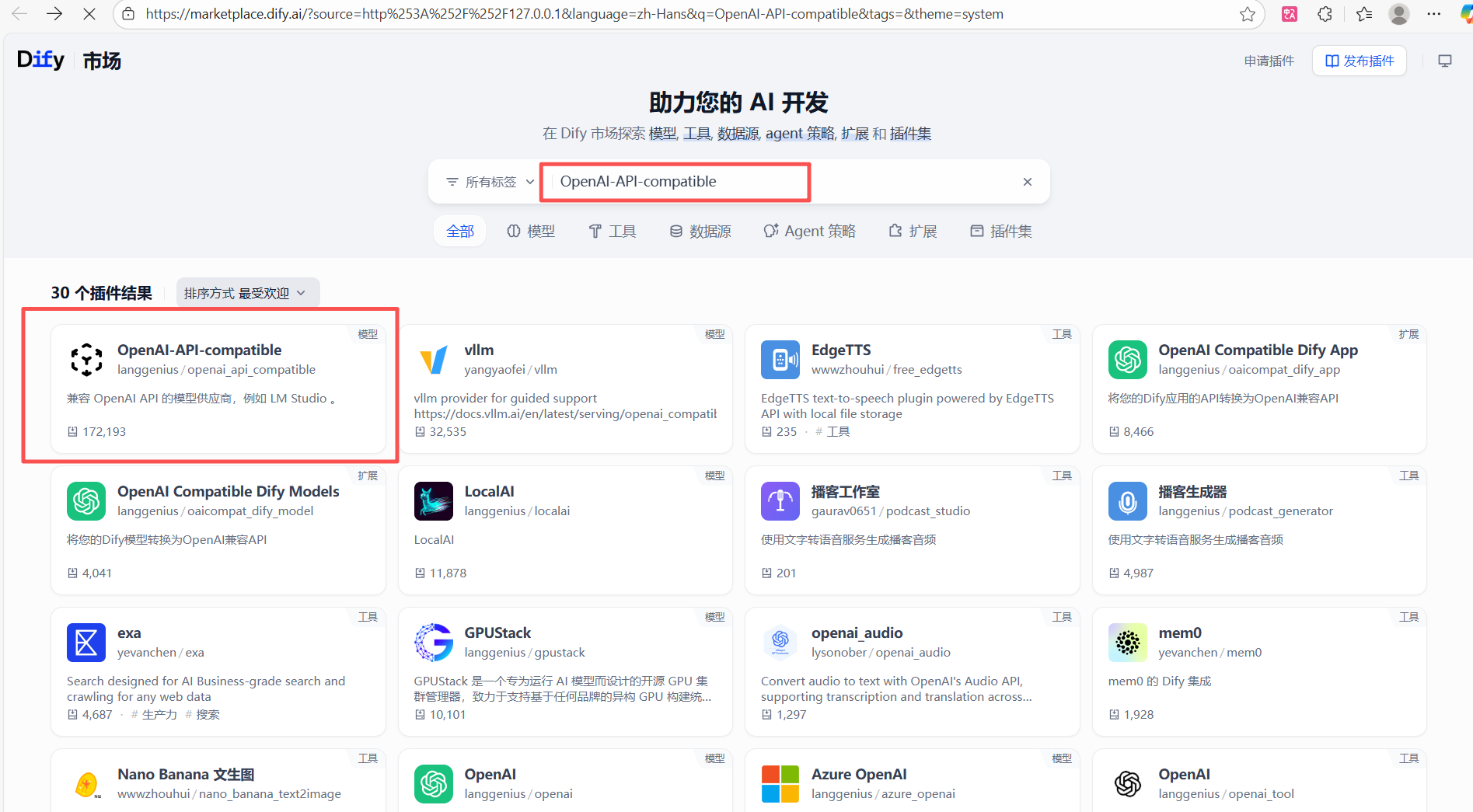
- 在搜索框中输入
OpenAI-API-compatible。 - 找到该插件并点击“安装”。
2.3.2 关键步骤:添加并配置新模型
插件安装成功后,我们就可以将蓝耘模型作为新的“供应商”添加到 Dify 中。
- 导航至「设置」->「模型供应商」,然后点击「添加模型」。
- 在弹出的窗口中,选择我们刚刚安装的
OpenAI-API-compatible。 - 现在,请仔细填写以下三个关键信息:
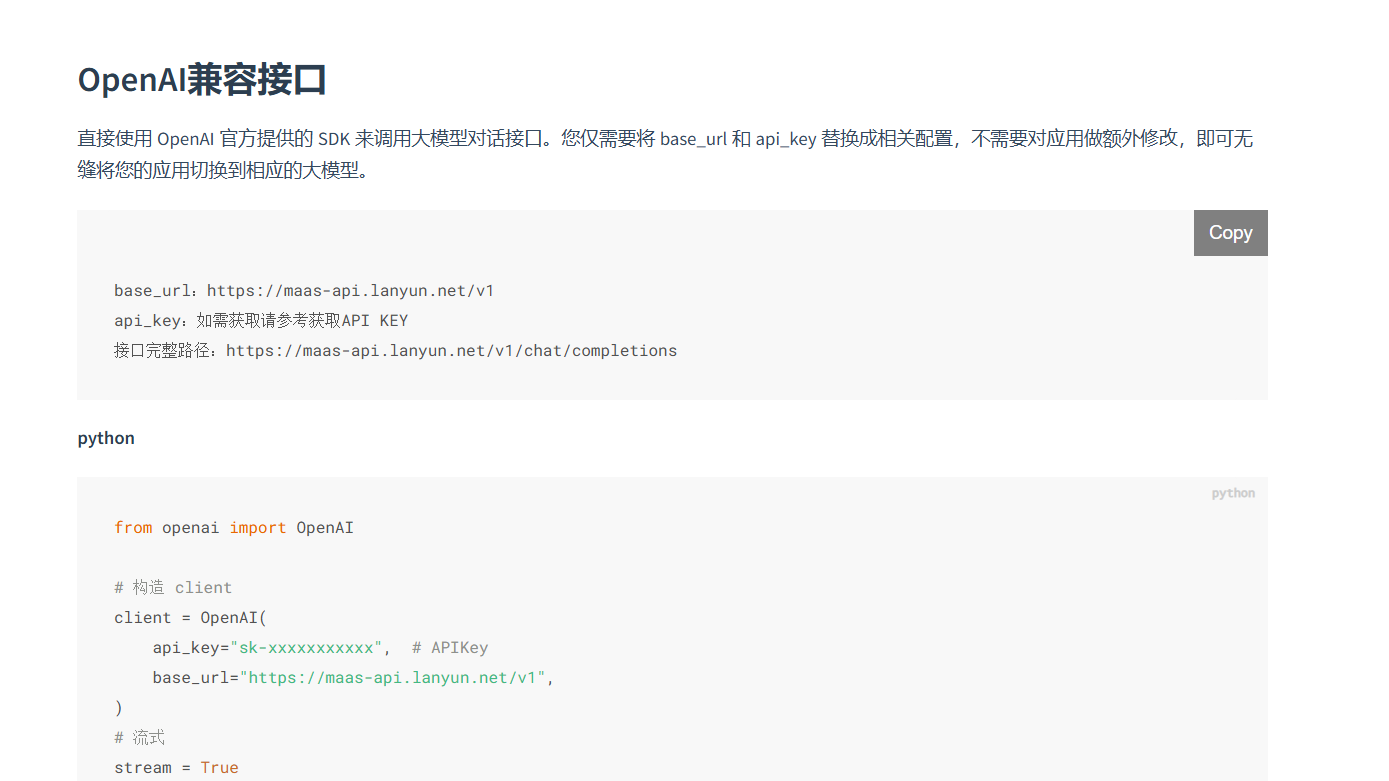
模型名称(Model Name)
- 【极其重要】:这是最容易出错的地方!此字段不是自定义名称,而必须填写服务商(蓝耘)提供的官方API模型ID。Dify 会将此名称直接用于API调用。
- 正确示例:根据蓝耘平台的API文档,我们应该填写
Qwen2.5-VL-72B-Instruct。- 错误示例:填写自定义的
Lanyun-Qwen2.5-72B会导致 “model not found” 错误。
API Key
- 将您从蓝耘 MaaS 平台获取的 API 密钥完整地粘贴到此处。
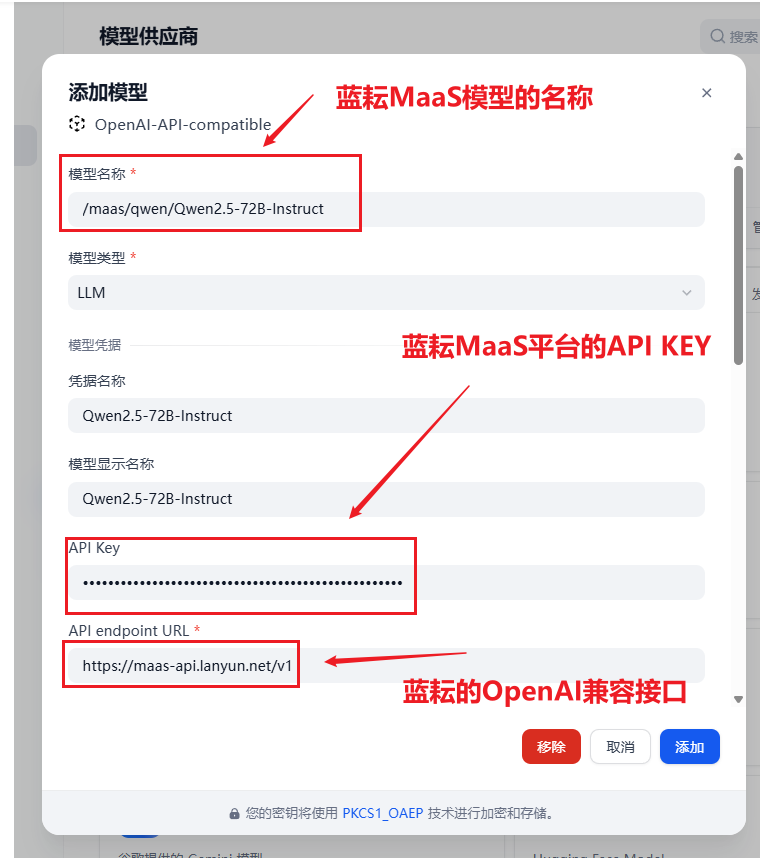
API endpoint URL
- 这里需要填写蓝耘 MaaS 平台的 API 服务地址。
- 正确地址:
https://maas-api.lanyun.net/v1
教学提示:如果读者在配置时遇到 model not found 的错误,99%的原因是「模型名称」填写错误。请务必引导他们去服务商的 API 开发文档 或 代码示例 中查找 model 参数的确切值。
配置完成后,点击“添加”。Dify 会自动验证您的凭证。如果一切顺利,这个强大的 Qwen2.5 模型就成功入驻您的 Dify 平台了!
2.3.3 在工作流中使用新模型
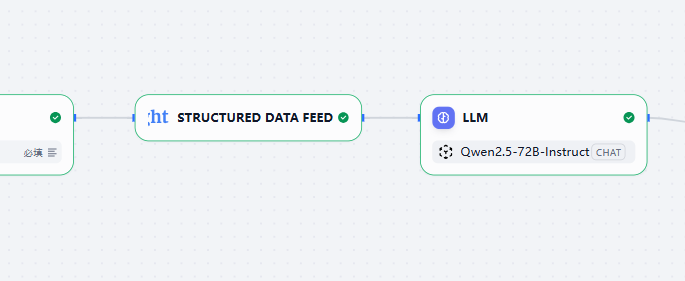
现在,回到我们的工作流画布,在「亮数据」节点后添加一个「LLM」节点。在节点配置中,您就可以从模型列表中选择我们刚刚添加的 Qwen2.5-VL-72B-Instruct 模型了。
2.3.4 核心步骤:编写提示词 (Prompt Engineering)
这是为工作流注入“智能”的核心环节。我们需要在「LLM」节点的“PROMPT”输入框中,设计一段指令(即提示词),来引导大语言模型完成我们期望的分析任务。
一个优秀的提示词通常包含两部分:
- 静态指令:定义模型的角色和任务。例如,告诉它“你是一个资深数据分析师,请总结以下数据”。
- 动态数据:引用上游节点(即「亮数据」节点)的输出结果作为分析的原材料。
操作步骤如下:
在“PROMPT”输入框中,我们先写下静态指令。然后,在需要插入数据的地方,通过键入 / 或 {{ 来引用上游节点的输出变量。根据 Dify 的默认设置,亮数据节点成功抓取并返回的结构化数据,会被存放在一个名为 text 的变量中。我们选择这个变量,它就会被动态地插入到提示词里。
【示例 Prompt】:
## 任务
请将下面提供的 JSON 数据,严格按照预定义的结构化格式输出。不要进行任何修改或分析。## 输入数据
```json
{{#code_execution._output}}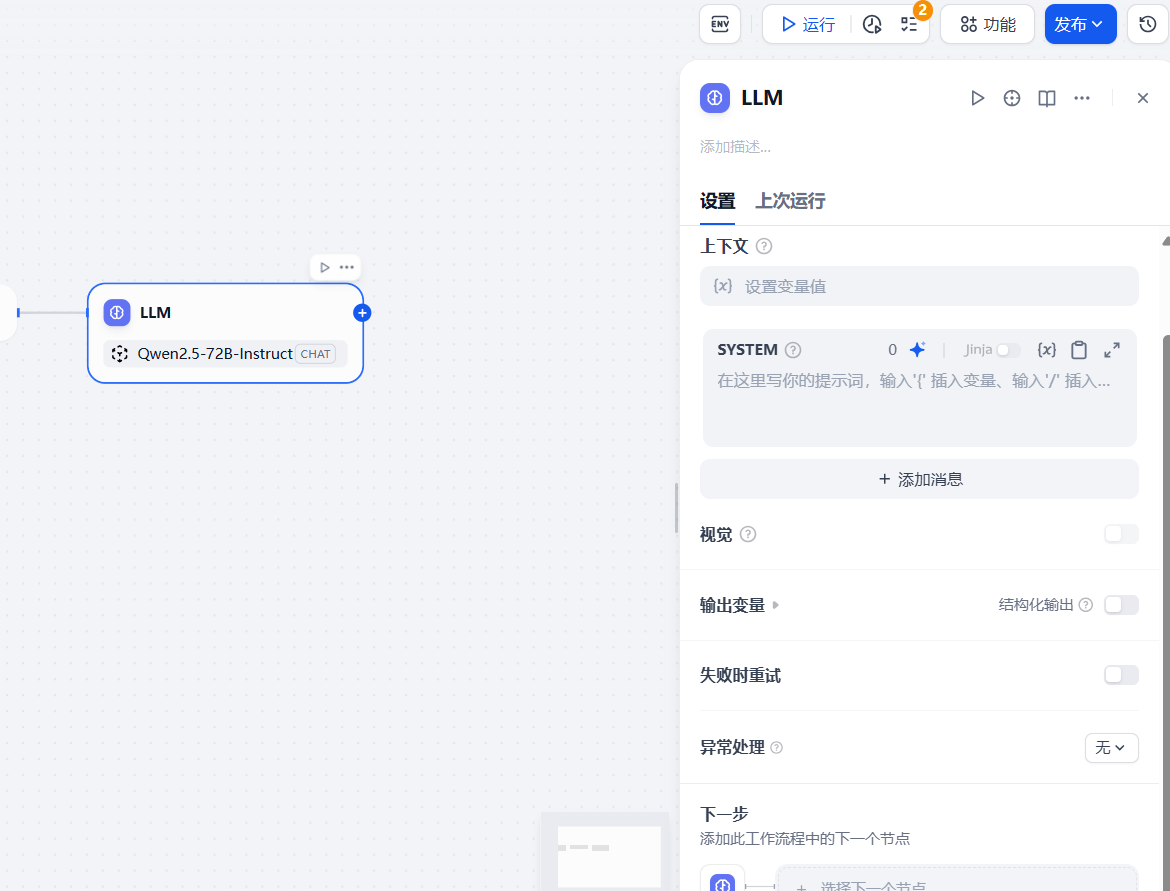
变量的完整名称(如 bright_data_web_scraper_0.text)取决于上游节点的名称和其输出。使用 / 智能提示是选择正确变量的最佳方式。
如果测试通过,说明我们工作流的“大脑”已经可以正常工作了!接下来,我们只需配置最后的输出节点即可。
配置 LLM 节点的“结构化输出 (structured_output)”,让它能够根据您定义的格式,生成一个包含完整视频分析结果的 JSON 对象

{"type": "object","properties": {"play_count": {"type": "integer","description": "视频的播放量"},"like_count": {"type": "integer","description": "视频的点赞数"},"comment_count": {"type": "integer","description": "视频的评论数"},"share_count": {"type": "integer","description": "视频的分享数"},"collect_count": {"type": "integer","description": "视频的收藏数"},"video_duration_seconds": {"type": "integer","description": "视频时长(单位:秒)"},"description": {"type": "string","description": "视频的描述文案"},"hashtags": {"type": "array","items": {"type": "string"},"description": "视频使用的话题标签列表"}},"required": ["play_count","like_count","comment_count","share_count","collect_count","video_duration_seconds","description","hashtags"]
}
2.4 节点四:结束 (End) - 定义工作流的最终输出
「结束」节点是工作流的终点站,它负责收集上游节点的处理结果,并将其作为整个工作流的最终输出。
- 在「LLM」节点后,添加一个「结束」节点。
- 在「结束」节点的配置中,我们需要定义一个输出变量,例如
analysis_result。 - 将这个变量的值与「LLM」节点的输出进行关联。同样,通过键入
/或{{,选择上游LLM节点的输出变量(例如{{llm_0.text}})即可
最后也是如愿以偿,得到我们要想的结果
{"analysis_result": {"play_count": 12345,"like_count": 678,"comment_count": 90,"share_count": 120,"collect_count": 345,"video_duration_seconds": 60,"description": "这是一段非常有趣的视频,希望大家喜欢!","hashtags": ["#有趣","#视频","#分享快乐"]}
}
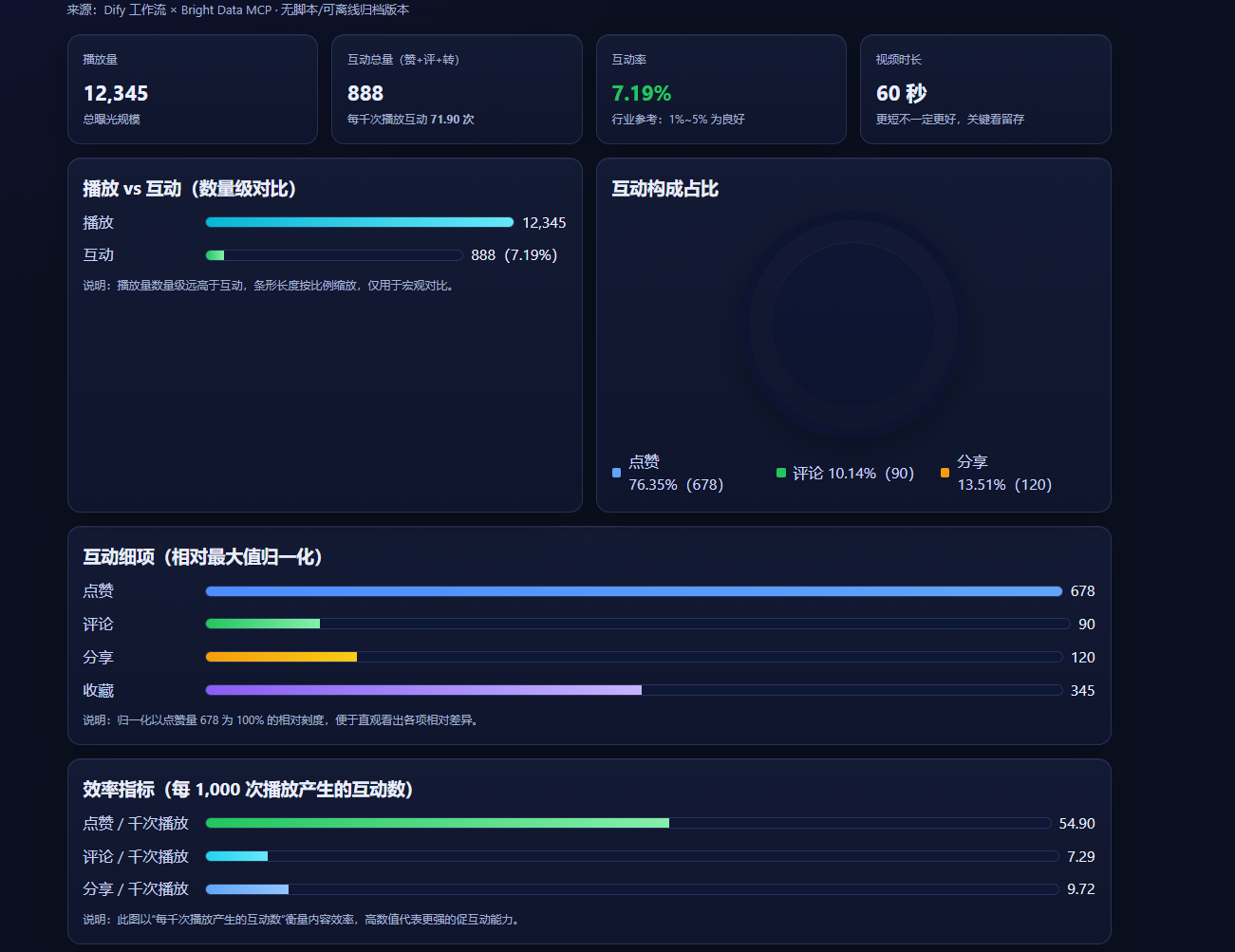
2.5 释放数据价值:我们能用这份数据做什么?
我们成功获取的这份干净、结构化的JSON数据,是整个自动化流程的“黄金产物”。它为我们打开了数据应用的大门,以下是几个核心应用场景:
1. 自动化监控与报告
- 告别手动:无需再手动复制粘贴数据,实现对您或竞争对手视频表现的自动化追踪。
- 实时战报:可将数据定时推送到数据库、BI仪表盘或飞书/钉钉等内部工具,生成每日/每周的内容“战报”,让团队实时掌握动态。
2. 深度分析与策略优化
- 计算核心指标:基于现有数据,轻松计算互动率(
(点赞+评论+分享)/播放量)等关键指标,量化内容质量。 - 发现爆款模式:通过对比分析,快速洞察哪种主题、标题风格或视频时长更容易成为爆款,用数据指导创作。
3. 赋能高级AI应用
- AI分析师:将这份干净数据作为下一个AI节点的输入,让AI自动撰写专业的分析报告或优化建议。
- 情感洞察:如果结合评论数据,还可以让AI进行观众情感分析,了解舆论风向。
4. 驱动商业决策
- 市场趋势洞察:批量分析行业热门视频,快速捕捉市场趋势和用户偏好。
- KOL价值评估:量化评估网红的真实互动水平和影响力,为投放决策提供依据。
简而言之,我们搭建的不仅是一个数据提取工具,更是一个商业智能引擎的起点。它打通了从原始信息到可操作洞察的关键链路,为后续更复杂的自动化分析奠定了坚实的基础。
三、总结与展望:开启你的自动化分析之旅
通过这个实践,我们不仅是构建了一个具体的工作流,更是掌握了一种现代化的数据处理范式:通过低代码平台,将专业的SaaS工具(如亮数据)与强大的AI模型像乐高积木一样自由组合,快速解决复杂的实际问题。
在此流程中,亮数据 (Bright Data) 扮演了不可或缺的“开路先锋”角色。它凭借其强大的代理网络和智能解析能力,攻克了数据获取阶段最困难、最繁琐的挑战,使得开发者和分析师能够彻底告别与反爬机制的斗争,将宝贵的精力完全集中在数据应用和价值挖掘上。
这种“专业工具 + 编排平台 + AI模型”的组合,不仅极大地降低了数据采集和分析的技术门槛,也为从海量网络内容中提取商业智能、进行市场研究和舆情监控,提供了前所未有的效率和深度。
小二诚挚你尝试使用Bright Data MCP,前 3 个月免费额度为每月 5,000 次请求。同时也推荐大家,使用亮数据其他产品。
亮数据注册连接:https://get.brightdata.com/d_mcpserver