从50ms到30ms:YOLOv10部署中图像预处理的性能优化实践
背景
承接《yolo v10 推理速度测试报告》,调研完推理速度后,我将报告、模型和代码交接给工程实施同事,让他们采用TensorRT方式部署。
结果实测反馈,接口响应时间为50ms,远大于报告中给出的20ms实测值。需要注意的是,报告中20ms为纯模型推理耗时,而工程部署的50ms包含完整业务链路(如数据读取、预处理、后处理等),两者指标范围不同,这也提示我们需关注推理外的性能瓶颈。
更关键的是,同事尝试通过减少日志打印优化接口速度——但性能优化的首要原则是“基于测量的针对性优化”,日志打印对接口耗时的影响通常在微秒级,盲目优化非核心路径只会浪费精力,显然不符合“先测量、再优化”的基本方案。
测量
所有的优化行为都应该基于准确的测量。为了细致分析整个业务链路的耗时分布,我的第一个想法是实现一个类似 Java 中 Google Guava Stopwatch 的轻量 Python 计时类,但实际使用时发现,部分函数逻辑嵌套较深,若要对每个关键节点做细致测量,需在代码中大量埋点,耗时且侵入性强。
于是我想起之前整理的《如何分析python程序cpu占用率问题》中提到的py-spy工具,它支持非侵入式生成函数火焰图,无需修改业务代码,命令如下:
py-spy record -o profile.svg -d 60 -p <pid>
实际使用过程中,遇到两个小问题:
- 采样率过高(
-d 60)时,py-spy会直接崩溃。最终我将采样率降至-d 50,并通过多跑 3-5 次测试来避免崩溃; - 程序高速执行场景下,采样存在一定延后,可能导致短时高频函数的耗时被低估。针对这一点,我还没有再细研究…
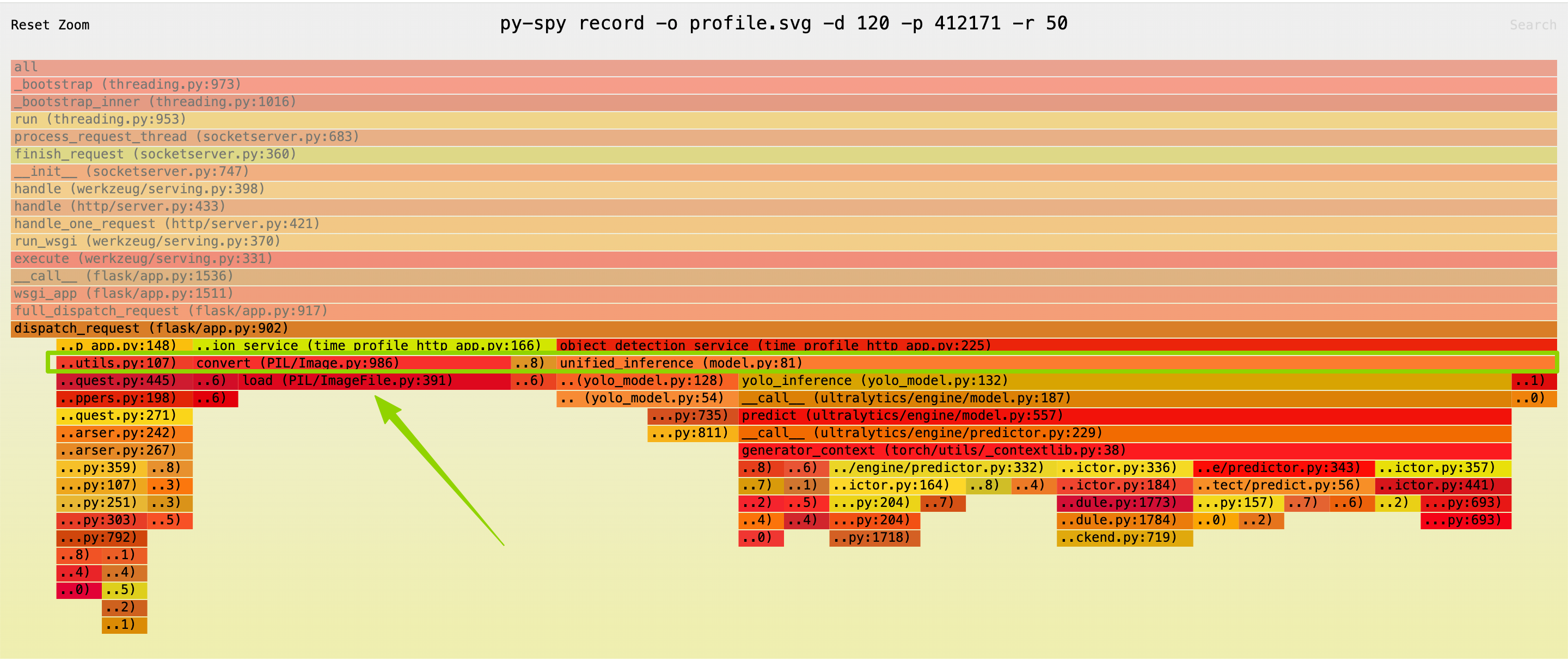
运行完成后,定位到业务代码相关的火焰图片段,发现PIL/Image.py的convert('RGB')函数耗时占预处理阶段的35%左右,是明显的性能瓶颈。
优化
找到对应的代码位置后,我分析了原代码的性能问题,并结合AI多次验证优化方向,最终确定用 OpenCV + NumPy 组合替代 PIL 方案,优化前后代码对比如下:
优化前(PIL方案)
image_file = request.files.get('image')
image_data = image_file.read()
image_stream = io.BytesIO(image_data) # 第一次冗余拷贝:基于image_data创建内存流缓冲区
img = Image.open(image_stream).convert('RGB') # 第二次冗余拷贝:转换色彩模式时生成新图像对象
优化后(OpenCV方案)
image_file = request.files.get('image')
image_data = image_file.read()
img_np = np.frombuffer(image_data, dtype=np.uint8) # 零拷贝:直接映射image_data的内存地址,不额外开辟空间
img = cv2.imdecode(img_np, cv2.IMREAD_COLOR) # 复用内存:解码时直接使用img_np指向的原始数据
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 仅1次必要拷贝:因OpenCV默认BGR格式,需转RGB适配后续流程
核心优化点在于减少“不必要的内存数据搬运”:原PIL方案通过两次拷贝处理数据(内存流缓冲+色彩转换)
而优化后方案用np.frombuffer实现“零拷贝”内存映射,仅保留色彩空间转换这一步必要操作,大幅降低了内存开销和数据搬运耗时。
结果
优化后实测,仅这一处改动就减少了20ms耗时,接口响应速度从50ms优化到30ms。
由于时间限制,我暂未继续深挖后续优化点。