StandardScaler,MinMaxScaler等四个内置归一化函数学习
不求甚解欠的债全是要还的!
- 某次实验使用不同归一化函数数据
- 基于Max_min归一化:
- 基于Stand归一化:
- 基于Robust归一化:
- 基于Max_min归一化:
- 归一化
- StandardScaler 和 MinMaxScaler
- StandardScaler
- MinMaxScaler
- 理解源码
- 基本数学原理
- fit方法
- transform方法是最重要的
- 验证代码
- 结果
- MinMaxScaler
- 验证代码
- Examples
- 附件:四个归一化函数复现
尊敬的组织,事情的经过是这样的:。。。。。。
自己写了一下归一化函数,跑一个线性神经网络跑出来一坨,想来想去肯定是归一化函数的问题。
还是调用方便。
sklearn.preprocessing库里面一共集成了4种Scaler方法,这个单词翻译叫定标器。
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import MaxAbsScaler
某次实验使用不同归一化函数数据
基于Max_min归一化:
**************************************************
模型评估指标:
平均绝对误差 (MAE): 42.4816
均方误差 (MSE): 3853.2547
中值绝对误差 (MedAE): 22.8512
可解释方差值 (Explained Variance Score): 0.9893
R方值 (R² Score): 0.9891
基于Stand归一化:
**************************************************
模型评估指标:
平均绝对误差 (MAE): 37.6559
均方误差 (MSE): 3362.8448
中值绝对误差 (MedAE): 24.0749
可解释方差值 (Explained Variance Score): 0.9905
R方值 (R² Score): 0.9905
基于Robust归一化:
爆炸了,压根就没拟合
**************************************************
模型评估指标:
平均绝对误差 (MAE): 443.5110
均方误差 (MSE): 441783.8972
中值绝对误差 (MedAE): 216.5900
可解释方差值 (Explained Variance Score): 0.0000
R方值 (R² Score): -0.2528
基于Max_min归一化:
**************************************************
模型评估指标:
平均绝对误差 (MAE): 45.0075
均方误差 (MSE): 4169.0116
中值绝对误差 (MedAE): 30.7425
可解释方差值 (Explained Variance Score): 0.9888
R方值 (R² Score): 0.9882
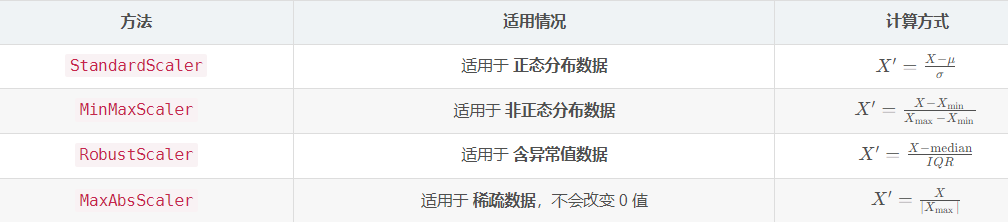
归一化
我们知道归一化,就像是跑图像的时候,先除以255,再给个方差,平均数矩阵,再甩给函数就成了。
简单的理解就是不能让e^6 和 e^-1 两个数量级的东西作为不同的特征一起去计算。
[1000,0.1,2] 这三个特征显然是有注意力差异的。这点可以通过注意力机制去理解,注意力机制就是特征*一个注意力矩阵,再去计算下一层嘛。
粗浅的估计就是一个x_scaler = (x -u)/sita .减去平均数,除以标准差,如果没有记错就是标准正态了吧。
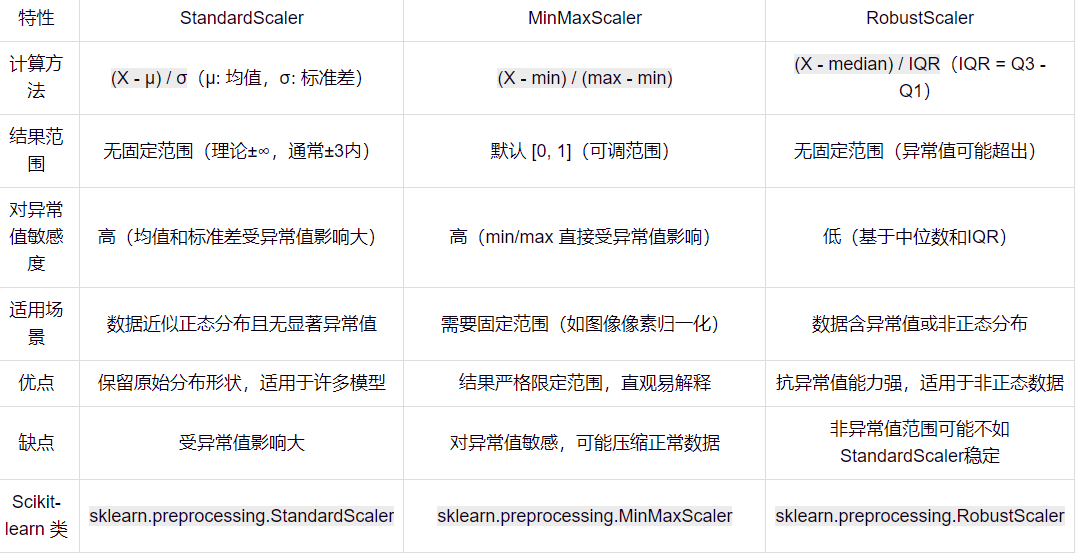
StandardScaler 和 MinMaxScaler
参考https://baijiahao.baidu.com/s?id=1825808807439588177这一篇写得很好。
就实操而言,StandardScaler 明显更好。用MinMaxScaler有时候会出问题。
它不会像魔法那样改变数据分布。就像你把一个面团擀成不同形状,虽然面团大小(尺度)发生变化,但面团原本的形状(分布)依然保留。它只是将数据“尺度”调整,使数据在模型训练时更加稳定。可以将 StandardScaler 理解为给数据换上统一战袍,让数据不因尺度差异而干扰模型学习,而能专注于特征本身规律。这样一来,模型处理数据时不再遇到天差地别的量级问题,训练过程更高效,预测结果也更加可靠。希望这个解释能帮助你对两种标准化方法有更深入理解和清晰认识。
StandardScaler
StandardScaler 就像一位精准的裁判,把数据的均值调整为 0,标准差调整为 1,适合数据服从正态分布的情况。想象参加跑步比赛,每个选手起点都设置在相同的水平线上,赛道长度也完全一致,这样大家都能公平竞争。StandardScaler 就是给数据设定统一标准,让每个数据点站在同一条起跑线上。
MinMaxScaler
MinMaxScaler 则像一位热衷于量化的教练,把所有数据拉伸或压缩到 [0,1] 或 [-1,1] 范围内,适合没有明显分布特征的数据。可以把它想象成一位严格的裁判,强迫每个选手的成绩都必须处于某个范围内,无论你跑得快或慢,成绩都必须在规定范围内。这种方式使得不同选手成绩易于比较,但它并不关注选手的实际表现,只关注排名情况。
理解源码
遇事不决研究源码。想不懂就拿代码来说话吧。
class StandardScaler(_OneToOneFeatureMixin, TransformerMixin, BaseEstimator):"""Standardize features by removing the mean and scaling to unit variance.The standard score of a sample `x` is calculated as:z = (x - u) / swhere `u` is the mean of the training samples or zero if `with_mean=False`,and `s` is the standard deviation of the training samples or one if`with_std=False`.Centering and scaling happen independently on each feature by computingthe relevant statistics on the samples in the training set. Mean andstandard deviation are then stored to be used on later data using:meth:`transform`.Standardization of a dataset is a common requirement for manymachine learning estimators: they might behave badly if theindividual features do not more or less look like standard normallydistributed data (e.g. Gaussian with 0 mean and unit variance).For instance many elements used in the objective function ofa learning algorithm (such as the RBF kernel of Support VectorMachines or the L1 and L2 regularizers of linear models) assume thatall features are centered around 0 and have variance in the sameorder. If a feature has a variance that is orders of magnitude largerthat others, it might dominate the objective function and make theestimator unable to learn from other features correctly as expected.This scaler can also be applied to sparse CSR or CSC matrices by passing`with_mean=False` to avoid breaking the sparsity structure of the data.Read more in the :ref:`User Guide <preprocessing_scaler>`.Parameters----------copy : bool, default=TrueIf False, try to avoid a copy and do inplace scaling instead.This is not guaranteed to always work inplace; e.g. if the data isnot a NumPy array or scipy.sparse CSR matrix, a copy may still bereturned.with_mean : bool, default=TrueIf True, center the data before scaling.This does not work (and will raise an exception) when attempted onsparse matrices, because centering them entails building a densematrix which in common use cases is likely to be too large to fit inmemory.with_std : bool, default=TrueIf True, scale the data to unit variance (or equivalently,unit standard deviation).Attributes----------scale_ : ndarray of shape (n_features,) or NonePer feature relative scaling of the data to achieve zero mean and unitvariance. Generally this is calculated using `np.sqrt(var_)`. If avariance is zero, we can't achieve unit variance, and the data is leftas-is, giving a scaling factor of 1. `scale_` is equal to `None`when `with_std=False`... versionadded:: 0.17*scale_*mean_ : ndarray of shape (n_features,) or NoneThe mean value for each feature in the training set.Equal to ``None`` when ``with_mean=False``.var_ : ndarray of shape (n_features,) or NoneThe variance for each feature in the training set. Used to compute`scale_`. Equal to ``None`` when ``with_std=False``.n_features_in_ : intNumber of features seen during :term:`fit`... versionadded:: 0.24feature_names_in_ : ndarray of shape (`n_features_in_`,)Names of features seen during :term:`fit`. Defined only when `X`has feature names that are all strings... versionadded:: 1.0n_samples_seen_ : int or ndarray of shape (n_features,)The number of samples processed by the estimator for each feature.If there are no missing samples, the ``n_samples_seen`` will be aninteger, otherwise it will be an array of dtype int. If`sample_weights` are used it will be a float (if no missing data)or an array of dtype float that sums the weights seen so far.Will be reset on new calls to fit, but increments across``partial_fit`` calls.See Also--------scale : Equivalent function without the estimator API.:class:`~sklearn.decomposition.PCA` : Further removes the linearcorrelation across features with 'whiten=True'.Notes-----NaNs are treated as missing values: disregarded in fit, and maintained intransform.We use a biased estimator for the standard deviation, equivalent to`numpy.std(x, ddof=0)`. Note that the choice of `ddof` is unlikely toaffect model performance.For a comparison of the different scalers, transformers, and normalizers,see :ref:`examples/preprocessing/plot_all_scaling.py<sphx_glr_auto_examples_preprocessing_plot_all_scaling.py>`.Examples-------->>> from sklearn.preprocessing import StandardScaler>>> data = [[0, 0], [0, 0], [1, 1], [1, 1]]>>> scaler = StandardScaler()>>> print(scaler.fit(data))StandardScaler()>>> print(scaler.mean_)[0.5 0.5]>>> print(scaler.transform(data))[[-1. -1.][-1. -1.][ 1. 1.][ 1. 1.]]>>> print(scaler.transform([[2, 2]]))[[3. 3.]]"""def __init__(self, *, copy=True, with_mean=True, with_std=True):self.with_mean = with_meanself.with_std = with_stdself.copy = copydef _reset(self):"""Reset internal data-dependent state of the scaler, if necessary.__init__ parameters are not touched."""# Checking one attribute is enough, because they are all set together# in partial_fitif hasattr(self, "scale_"):del self.scale_del self.n_samples_seen_del self.mean_del self.var_def fit(self, X, y=None, sample_weight=None):"""Compute the mean and std to be used for later scaling.Parameters----------X : {array-like, sparse matrix} of shape (n_samples, n_features)The data used to compute the mean and standard deviationused for later scaling along the features axis.y : NoneIgnored.sample_weight : array-like of shape (n_samples,), default=NoneIndividual weights for each sample... versionadded:: 0.24parameter *sample_weight* support to StandardScaler.Returns-------self : objectFitted scaler."""# Reset internal state before fittingself._reset()return self.partial_fit(X, y, sample_weight)
基本数学原理
The standard score of a sample
xis calculated as:z = (x - u) / s
可见,StandardScaler的基本原理是正态化,这里当然应该是每一个特征的u和s。每个特征分别作这个操作。每一个列做标准化。
Examples
--------
>>> from sklearn.preprocessing import StandardScaler
>>> data = [[0, 0], [0, 0], [1, 1], [1, 1]]
>>> scaler = StandardScaler()
>>> print(scaler.fit(data))
StandardScaler()
>>> print(scaler.mean_)
[0.5 0.5]
>>> print(scaler.transform(data))
[[-1. -1.][-1. -1.][ 1. 1.][ 1. 1.]]
>>> print(scaler.transform([[2, 2]]))
[[3. 3.]]
fit方法
def fit(self, X, y=None, sample_weight=None):
# Compute the mean and std to be used for later scaling.
fit方法就是求出当前输入数据的平均数,方差的函数。跑完这个方法后,归一化的参数就订好了。
scaler = StandardScaler()
scaler.fit(x_train) # 在训练数据上拟合缩放器
x_train_scaled = scaler.transform(x_train)
像是很多人根本就没看到有这么一个方法,以为直接调用scaler.transform(x)就行了。
所以 print(scaler.transform([[2, 2]]))用到的是 data = [[0, 0], [0, 0], [1, 1], [1, 1]]的平均数,方差。
transform方法是最重要的
inverse_transform方法是它的反函数。Scale back the data to the original representation.把数据返回到原本形式。
为了防止用户乱输入东西,别的反正写了一大堆判定。核心的东西就是-mean再/scale的操作。别的部分明明没写什么复杂的东西,但是我总感觉看不大懂,真的奇了怪了。
def transform(self, X, copy=None):"""Perform standardization by centering and scaling.Parameters----------X : {array-like, sparse matrix of shape (n_samples, n_features)The data used to scale along the features axis.copy : bool, default=NoneCopy the input X or not.Returns-------X_tr : {ndarray, sparse matrix} of shape (n_samples, n_features)Transformed array."""check_is_fitted(self)copy = copy if copy is not None else self.copyX = self._validate_data(X,reset=False,accept_sparse="csr",copy=copy,estimator=self,dtype=FLOAT_DTYPES,force_all_finite="allow-nan",)if sparse.issparse(X):if self.with_mean:raise ValueError("Cannot center sparse matrices: pass `with_mean=False` ""instead. See docstring for motivation and alternatives.")if self.scale_ is not None:inplace_column_scale(X, 1 / self.scale_)else:if self.with_mean:X -= self.mean_if self.with_std:X /= self.scale_return X
验证代码
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
import numpy as npdef min_max_scaler(x):x = np.array(x)min = x.min(axis=0)max = x.max(axis=0)x_sc = (x - min) / (max - min)return x_scdef stand_scaler(x):# 将列表转换为NumPy数组my_array = np.array(x)# 计算平均数mean_value = np.mean(my_array,axis=0)# 计算方差variance_value = np.std(my_array,axis=0)return (x-mean_value)/variance_valueif __name__ == '__main__':# print("11" * 50)# scaler = MinMaxScaler()# data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]# scaler.fit(data)# # print(scaler.transform([[2, 2]]))# print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]minmax标准化:", scaler.transform(data))# print(f"自写的min_max标准化函数:{min_max_scaler(data)}")print("11" * 50)scaler = StandardScaler()data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]scaler.fit(data)# print(scaler.transform([[2, 2]]))print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]stand标准化:\n", scaler.transform(data))print(f"自写的stand标准化函数:\n{stand_scaler(data)}")
结果
[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]stand标准化:[[-1.18321596 -1.18321596][-0.50709255 -0.50709255][ 0.16903085 0.16903085][ 1.52127766 1.52127766]]
自写的stand标准化函数:
[[-1.18321596 -1.18321596][-0.50709255 -0.50709255][ 0.16903085 0.16903085][ 1.52127766 1.52127766]]
MinMaxScaler
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))X_scaled = X_std * (max - min) + min
很好理解,核心原理就是 -min , /(max-min) 两个部分。至于那个+min,我也不明白是什么意思。
验证代码
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
import numpy as npdef min_max_scaler(x):min = x.min(axis=0)max = x.max(axis=0)x_sc = (x - min) / (max - min)return x_scif __name__ == '__main__':print("11" * 50)scaler = MinMaxScaler()data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]data = np.array(data)scaler.fit(data)# print(scaler.transform([[2, 2]]))print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]minmax标准化:", scaler.transform(data))print(f"自写的min_max标准化函数:{min_max_scaler(data)}")Examples
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler()
print(scaler.fit(data))
MinMaxScaler()
print(scaler.data_max_)
[ 1. 18.]
print(scaler.transform(data))
[[0. 0. ]
[0.25 0.25]
[0.5 0.5 ]
[1. 1. ]]
print(scaler.transform([[2, 2]]))
[[1.5 0. ]]
max=[1,18],min=[-1,2]
得到的结果就是
[[0. 0. ]
[0.25 0.25]
[0.5 0.5 ]
[1. 1. ]]
附件:四个归一化函数复现
"""
4个归一化函数和反函数,不写类了吧
"""import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import MaxAbsScalerdef robust_scaler(X):""":param X::return: Robust归一化,中位数,四分位距"""# 计算每个特征的中位数medians = np.median(X, axis=0)# 计算每个特征的第一四分位数和第三四分位数Q1 = np.percentile(X, 25, axis=0)Q3 = np.percentile(X, 75, axis=0)# 计算四分位距 (IQR)IQR = Q3 - Q1# 避免除以零的情况,创建一个新的数组来存储调整后的 IQR 值adjusted_IQR = np.where(IQR == 0, 1e-8, IQR)# print("*" * 20)# print(X)# print(medians)# print(adjusted_IQR)# # 标准化数据scaled_data = (X - medians) / adjusted_IQRreturn scaled_data, medians, adjusted_IQRdef inverse_robust_scaler(scaled_data, medians, adjusted_IQR):""":param scaled_data::param medians::param adjusted_IQR::return: Robust归一化还原"""# 反标准化数据original_data = scaled_data * adjusted_IQR + mediansreturn original_datadef min_max_scaler(x):x = np.array(x)min = x.min(axis=0)max = x.max(axis=0)x_sc = (x - min) / (max - min)return x_sc, max, mindef inverse_minmax_scaler(x, max, min):x_inv = x * (max - min) + minreturn x_invdef stand_scaler(x):# 将列表转换为NumPy数组my_array = np.array(x)# 计算平均数mean_value = np.mean(my_array, axis=0)# 计算方差variance_value = np.std(my_array, axis=0)return (x - mean_value) / variance_value, mean_value, variance_valuedef inverse_stand_scaler(x, mean, var):x_inv = x * var + meanreturn x_invdef maxabs_scaler(x):x = np.array(x)max = abs(x.max(axis=0))x_sc = x / maxreturn x_sc, maxdef insver_max_scaler(x, max):return x * maxif __name__ == '__main__':# print("11" * 50)# scaler = MinMaxScaler()# data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]# scaler.fit(data)# # print(scaler.transform([[2, 2]]))# print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]minmax标准化:", scaler.transform(data))# print(f"自写的min_max标准化函数:{min_max_scaler(data)}")# print("11" * 50)# scaler = StandardScaler()# data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]## data = np.array(data)# scaler.fit(data)# # print(scaler.transform([[2, 2]]))# print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]stand标准化:\n", scaler.transform(data))# print(f"自写的stand标准化函数:\n{stand_scaler(data)}")# print("11" * 50)# scaler = MaxAbsScaler()# data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]## data = np.array(data)# scaler.fit(data)# # print(scaler.transform([[2, 2]]))# print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]MAXABS标准化:\n", scaler.transform(data))# print(f"自写的MAXABS标准化函数:\n{maxabs_scaler(data)}")print("11" * 50)scaler = RobustScaler()data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]data = np.array(data)scaler.fit(data)# print(scaler.transform([[2, 2]]))print("[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]MAXABS标准化:\n", scaler.transform(data))print(f"自写的Robust准化函数:\n{robust_scaler(data)}")