实时数据如何实现同步?一文讲清数据同步方式
目录
一、什么是数据同步
4.数据同步的常见场景
二、数据同步的重要性
1.保证数据的一致性和准确性
2.提高业务效率
3.支持实时决策
4.促进数据共享和协同
三、实时数据如何实现同步
1.基于日志的同步方式
2.消息队列同步方式
3.触发器同步方式
4.中间件同步方式
四、实时数据同步的注意事项及应对措施
1.数据质量问题
2.性能问题
3.4网络问题
4.安全问题
Q&A 常见问答
总结
你是不是遇到过这种情况?门店的销售数据都到下午了,总部系统里还没更新,想调库存补热门款都没法儿下手;或者客服查客户信息,发现和销售系统里的手机号对不上,打电话打不通,客户还觉得你不专业。这些麻烦,说到底都是数据没同步好闹的。
我在数据领域待了这么多年,见过太多企业因为数据同步不及时、不一致,要么决策慢半拍,要么业务卡壳。今天就跟大家好好唠唠数据同步——到底啥是数据同步?为啥它这么重要?实时数据咋实现同步?还有哪些坑要避开?这儿必须提一句,FineDataLink在数据同步上真的靠谱,帮不少企业解决过实际难题,后面会跟大家细说。
一、什么是数据同步
1.数据同步的定义
简单来说,数据同步就是把一个地方的数据源(比如门店的销售库)里的数据,复制到另一个或多个地方的数据源(比如总部的中央库),还得保证这些地方的数据在需要的时候是一样的。说白了,就是让不同系统里的同一份数据“保持一致”,别你这儿是一个数,我那儿是另一个数。
就像连锁超市,每个门店都有自己的销售数据库,每天卖了多少瓶水、多少袋米都记在里面。总部要知道整体销量,还得调库存,总不能让每个门店每天手动传表格吧?这时候就需要数据同步——门店的数据变了,自动传到总部库,总部随时能看,不用等人工传。
2.数据同步的分类
数据同步分两类,按“同步速度”和“同步方向”来分,每类的用法都不一样:
- 先看按速度分:实时同步和非实时同步。实时同步就是数据一有变化,马上就同步到目标库,比如金融交易,客户刚转完账,余额就得马上更,不然客户查余额发现没少,还以为没转成功。非实时同步就是按固定时间更,比如每天凌晨同步前一天的报表数据,不用实时更,因为报表早上看就行,晚几个小时不影响。
- 再看按方向分:单向同步和双向同步。单向就是数据只从源库往目标库传,比如门店数据只往总部传,总部不改门店的库。双向就是两边能互相传,比如两个分公司的客户库,A分公司新增了客户,同步到B分公司;B分公司更新了客户信息,也同步回A分公司,两边都能拿到最新的。
FineDataLink这几种同步都支持,不管你是要实时更,还是每天更,单向还是双向,都能搞定,不用再找别的工具。
3.数据同步的原理
不同同步方式的原理不一样,但核心都是“抓变化、传数据、更目标”。
- 实时同步里最常用的是基于日志的同步:数据库会记录每一次数据变更的详细日志,比如谁改了数据、改了什么、什么时候改的——就像数据库的“操作账本”。同步工具会一直盯着这个日志,一旦发现新的记录,就会解析日志里的变更内容,然后把这些变更复制到目标数据库里,让目标库和源库保持一致。
- 非实时同步就简单多了:同步工具按你设的时间间隔(比如每天凌晨3点),定期去源库里抽数据,抽的时候会对比上次同步的时间,只抽新改的数据,然后传到目标库——不用一直盯着,到点干活就行。
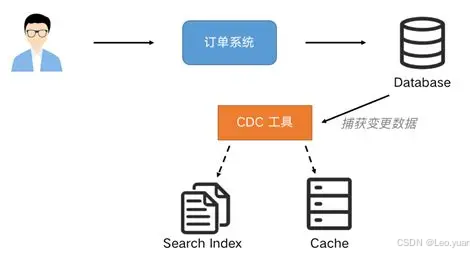
4.数据同步的常见场景
数据同步在企业里用得特别广,你随便找个业务流程,大概率都有同步的影子:
企业内部协作肯定要同步,比如销售系统的订单数据,得同步到财务系统做核算,同步到库存系统扣库存——总不能销售录了订单,财务还得手动输一遍,库存也不知道要减,最后账对不上,货也超卖。
企业和外部合作也得同步,比如你和供应商合作,你的库存数据得同步给供应商,供应商知道你缺啥了,才能及时补货;供应商的发货数据也得同步给你,你好安排入库。
还有数据备份和灾难恢复,也得靠同步:把主数据库的数据同步到备份库,要是主库坏了(比如硬盘坏了),备份库因为同步了数据,能马上顶上,业务不用停——不然数据丢了,损失就大了。
二、数据同步的重要性
1.保证数据的一致性和准确性
这是数据同步最核心的作用——要是数据不一致,后面干啥都错。
你想啊,销售系统里客户的手机号是138xxxx1234,客服系统里是139xxxx5678,客服按139打过去,要么打不通,要么是别人接的,客户还觉得你连他的手机号都记不准,多影响信任?还有库存数据,门店说某款产品剩5件,总部说剩15件,总部按15件安排补货,最后堆了10件卖不出去,这不就是浪费钱?
只有数据同步好了,所有系统里的数都一样,不管是销售、客服还是财务,用的都是同一套数据,才不会出这种低级错误。我一直强调,数据一致是做所有业务的基础,基础打不好,后面全白搭。
2.提高业务效率
数据同步能省不少人工,效率能提一大截。
以前没有同步的时候,数据都是手动传:销售每天下班前要把订单表导出来,发给财务;财务得手动把订单数据录到自己的系统里,才能做账,这一套下来至少得半天。现在同步一打开,销售录完订单,财务系统里马上就有了,财务直接做账就行,半天的活儿现在一小时搞定。
还有库存调整,以前得等门店每天传销售数据,总部才能算库存,要是某款产品卖断货了,等总部知道了再补货,得耽误好几天。现在实时同步,门店卖一件,总部库存就减一件,一看到快没货了,马上安排补货,根本不会断档。
3.支持实时决策
现在市场变化这么快,你得实时知道业务情况,才能及时调整策略——这就得靠实时数据同步。
比如电商搞大促,要是不知道实时销量,怎么调价格、补库存?有了实时同步,后台能看到每款产品的实时销量,哪款卖得好,马上加库存;哪款卖不动,马上降点价促销量。要是等大促结束了再看数据,早就错过最佳调整时机了。
还有连锁餐饮,通过实时同步看每家门店的菜品销量,哪款菜卖得火,中央厨房就多备点料;哪款菜没人点,就调整配方或者下架——不用等月底汇总数据,实时就能优化,利润自然能上去。
4.促进数据共享和协同
企业里的“数据孤岛”太常见了——销售有销售的库,客服有客服的库,研发有研发的库,互相不通,想协作都难。
比如研发要做新产品,得知道客户喜欢什么,要是没法拿到销售和客服的客户数据,只能瞎猜;要是数据同步到一个统一的平台,研发能直接看客户反馈、销售情况,做出来的产品才符合市场需求。
还有跨部门项目,比如做客户忠诚度计划,需要销售的消费数据、客服的服务数据、运营的活动数据,这些数据同步到一起,才能算出客户的忠诚度等级,制定合适的福利政策——不然各部门各拿各的数据,算出来的等级都不一样,计划根本推不动。
三、实时数据如何实现同步
1.基于日志的同步方式
- 原理:这种方式的核心是数据库的日志文件。不管是MySQL的Binlog,还是Oracle的归档日志,本质都是记录数据库的每一次变更——数据新增、修改、删除,都会在日志里记一笔,包括变更的内容、时间、操作人。
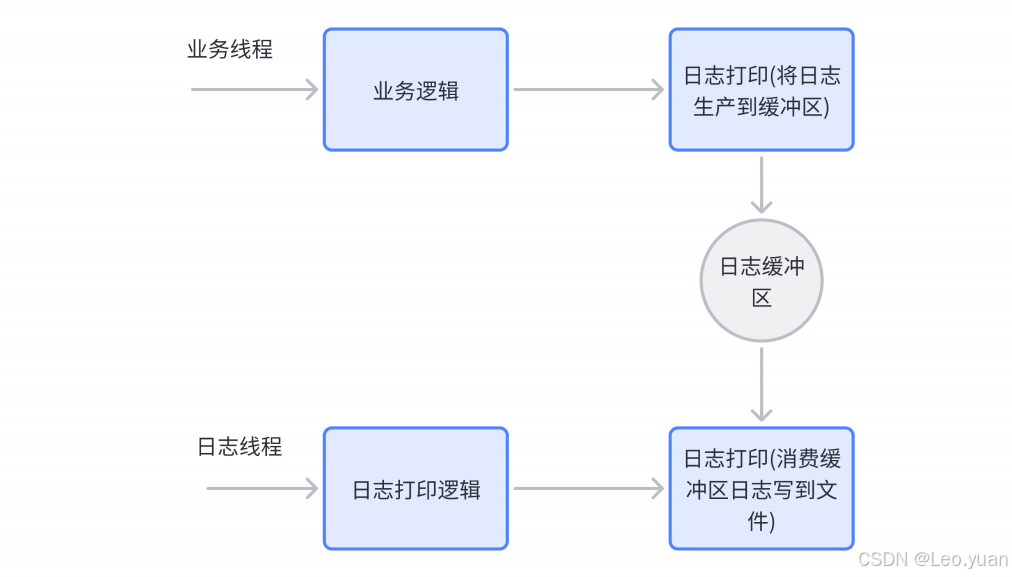
同步工具会一直监控这个日志文件,就像有人盯着账本看一样,一旦发现新的记录,就会马上解析日志:比如日志里写“2025-05-20 10:00,改了订单表的订单状态为‘已发货’,订单ID是12345”,同步工具就会提取出“订单ID12345改状态为已发货”这个信息,然后去目标数据库里做同样的操作,让目标库的订单表也更新这个状态。
整个过程几乎是实时的,源库数据变了,日志马上记,同步工具马上解析同步,目标库几秒内就能跟上。
- 适用场景:这种方式绝对适合对实时性要求极高的场景。比如金融交易系统,客户转完账,余额必须马上同步到所有相关系统,不然客户查余额没变化,会以为转账失败;还有实时监控系统,比如工厂的设备数据,设备出故障了,数据变了就得马上同步到监控平台,不然没法及时报警。
- 优缺点:优点很明显——实时性强,数据几乎零延迟;而且只同步变更的数据,不用全量传,效率高。但缺点也得说:日志的记录和解析会占用源数据库的资源,要是数据变更特别频繁(比如每秒几千次),源库可能会有点卡;另外,不同数据库的日志格式不一样,同步工具得适配,不然解析不了。
FineDataLink在这方面做得不错,已经适配了市面上主流的数据库日志格式,不用你自己开发适配工具,而且它有优化算法,能减少日志解析对源库性能的影响,就算数据变更多,源库也不会卡得太厉害。
2.消息队列同步方式
- 原理:这种方式得先有个“消息队列”——你可以把它理解成一个数据中转站。源数据库的数据变了之后,不会直接同步到目标库,而是先把变更的数据封装成“消息”,发给消息队列;然后同步工具从消息队列里拿这些消息,解析之后再同步到目标库。
消息队列的作用很关键:它能缓冲数据,要是源库一下子发了很多消息(比如大促时的订单数据),消息队列会先存着,慢慢发给目标库,不会让目标库一下子被挤爆;而且就算目标库暂时出问题,消息也会存在队列里,等目标库恢复了再接着发,不会丢数据。
- 适用场景:最适合高并发、大数据量的实时同步场景。比如电商的订单系统,大促的时候每秒可能有上千个订单,要是直接同步到库存、财务系统,这些系统可能扛不住;用消息队列缓冲一下,分批次同步,系统就不会崩。还有物流系统,每天有大量的物流状态变更,用消息队列同步,能保证每个状态变更都不丢,还不影响系统性能。
- 优缺点:优点是能扛高并发,保护目标系统不被冲垮;而且数据不会丢,就算中间出问题,消息队列里有备份。缺点是得额外部署和维护消息队列系统,增加了一点复杂度;另外,相比基于日志的同步,会多一点延迟(比如几百毫秒),虽然用户感觉不到,但对极致实时的场景可能不太够。
FineDataLink能和常见的消息队列(比如Kafka、RabbitMQ)无缝集成,不用你自己写集成代码,直接在界面上配一下消息队列的地址、账号,就能用,维护起来也方便。
3.触发器同步方式
- 原理:这种方式是在源数据库的表上“装”一个触发器——触发器就是一段预设的代码,只要表的数据发生指定操作(比如插入、更新、删除),这段代码就会自动执行。
比如你在客户表上建个更新触发器,只要有人改了客户的手机号,触发器就会自动把“客户ID、新手机号、变更时间”这些信息拿出来,同步到目标数据库的客户表里。整个过程不用同步工具一直监控,全靠触发器自动触发。
- 适用场景:适合数据变更不频繁的场景。比如企业的员工信息管理系统,员工入职、调岗、离职,数据变更不多,用触发器同步刚好;还有客户等级管理系统,客户等级几个月才变一次,触发器同步完全能满足需求。要是数据变更频繁(比如每秒几十次),就别用了,触发器会频繁执行代码,源库会很卡。
- 优缺点:优点是实现简单,不用部署复杂的同步工具,只要在数据库里建触发器就行;而且同步也比较实时,数据一变就触发。缺点也很突出:对源库性能影响大,数据变更多了会拖慢源库;另外,触发器的代码要是写得有问题(比如逻辑错了),会导致同步的数据不一致,而且排查起来麻烦。
要是你确实得用触发器同步,FineDataLink能帮你优化——它能检查触发器代码的逻辑,还能监控触发器的执行情况,要是触发器出问题了,会及时告警,不用你一直盯着数据库日志找问题。
4.中间件同步方式
- 原理:这种方式是用专门的数据同步中间件(比如FineDataLink)来做实时同步。中间件会在源数据库和目标数据库之间搭个“桥”,一边连源库,一边连目标库,实时监控源库的数据变更。
中间件的优势在于“一站式”——不用你自己搭日志监控、消息队列,中间件里都整合好了;而且大多有可视化界面,不用写代码,拖拖拽拽就能配置同步任务:比如选源库、选目标库、选要同步的表、设同步触发条件(数据变了就同步),配置完点一下启动,就能实时同步了。
- 适用场景:几乎所有场景都能用,不管是小公司的单一数据库同步,还是大公司的分布式数据库同步;不管是关系型数据库(MySQL、Oracle),还是非关系型数据库(MongoDB、Redis),中间件都能支持。比如中小企业要同步销售和库存数据,用中间件配一下就行,不用请专门的技术人员;大公司要同步多个地区的数据库,中间件能支持分布式部署,保证每个地区的数据都能实时同步。
- 优缺点:优点是通用性强,支持各种数据库、各种场景;配置简单,非技术人员也能上手;而且中间件会做性能优化、故障恢复,不用你自己操心。缺点是好的中间件可能要花点钱(比如商业版),但相比自己搭一套系统,成本还是低的;另外,要是同步的场景特别特殊(比如自定义的数据库),可能需要做少量定制开发。
FineDataLink就是典型的同步中间件,上面说的这些优点它都有,而且支持的数据库种类特别多,从常见的MySQL、Oracle,到小众的数据库,基本都能连;界面也简单,业务人员学半天就能自己配同步任务,不用麻烦技术岗。
四、实时数据同步的注意事项及应对措施
1.数据质量问题
- 问题表现:同步过来的数据要是质量差,还不如不同步。常见的问题有三种:数据缺失,比如源库的订单表有“客户ID”字段,同步到目标库居然空着,后面想关联客户信息都没法儿弄;数据重复,同一条订单同步了两次,算销量的时候多算了一笔;数据错误,源库的“金额”是100,同步过来变成1000,财务做账的时候就错了。
这些问题有的是源库本身数据就有问题,有的是同步过程中出了错(比如网络断了导致数据传一半)。
- 应对措施:首先得在同步前做数据清洗,源库的数据有问题,先处理干净再同步——比如用FineDataLink的清洗功能,空值按规则填(比如填“未知”)、重复数据一键删掉、错误数据标出来提醒你改。然后同步过程中要实时监控数据质量,比如设个规则:“金额不能大于10000”,要是同步过来的金额超了,马上告警,你好及时处理。最后同步完要做校验,比如对比源库和目标库的记录数、关键字段的值,确保没同步错。
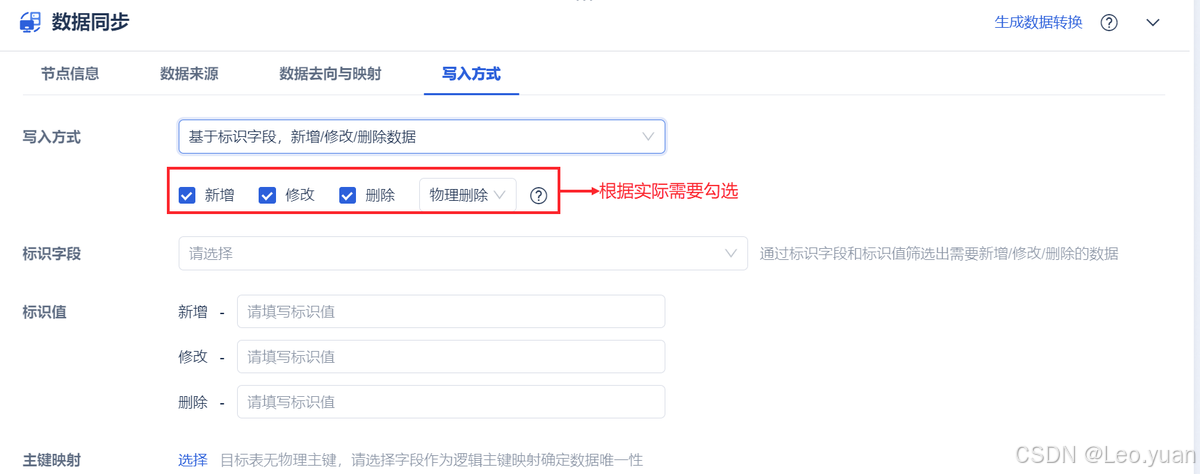
2.性能问题
- 问题表现:实时同步要是没做好性能优化,会拖慢整个系统。比如源库因为要记日志、触发同步,写数据的速度变慢了;目标库因为要接收大量同步数据,读数据的时候卡顿;还有同步工具本身性能不行,同步延迟越来越高,从几秒变成几分钟,实时同步变成了“准实时”。
- 应对措施:优化的方向有三个:一是优化源库配置,比如加内存、换更快的硬盘(SSD),让源库有足够的资源处理同步;二是优化同步策略,比如把同步任务分到多个节点上(分布式同步),别让一个节点扛所有活儿;三是选性能好的同步工具,比如FineDataLink有并行同步功能,能同时同步多个表的数据,还能智能调整同步速度,不会让目标库卡。
要是数据量特别大,还可以做“分库分表”,把大表拆成小表,比如按地区拆订单表,北京的订单同步到北京的目标库,上海的同步到上海的,不用全堆在一个库上。
3.4网络问题
- 问题表现:实时同步特别依赖网络,网络一出问题,同步就容易断。比如跨地区同步,总部在上海,门店在新疆,网络带宽不够,同步数据的时候特别慢,延迟越来越高;要是网络断了,同步就停了,等恢复了,中间断的那段数据可能丢了,导致源库和目标库不一致。
- 应对措施:首先得保证网络稳定,选靠谱的网络服务商,要是跨地区,最好用专线;其次要做网络冗余,比如拉两条不同服务商的网线,一条断了,自动切到另一条,不用停同步。同步工具也得支持断点续传,比如FineDataLink,网络断了之后,会记录上次同步到哪儿了,等网络恢复了,从记录的地方接着同步,不用重新同步所有数据,省时间还不会丢数据。
要是网络延迟实在高,可以在靠近源库的地方加个“缓存节点”,先把数据同步到缓存节点,再从缓存节点同步到目标库,能减少跨地区的延迟。
4.安全问题
- 问题表现:同步过程中数据要是被偷了、改了,后果会很严重。比如同步客户的银行卡信息,要是传输的时候没加密,被别人截获了,客户信息就泄露了;要是有人恶意改同步的数据,比如把订单金额从100改成10,财务算营收的时候就少了90,损失就大了。
- 应对措施:安全得从传输和访问两方面下手。传输的时候要加密,比如用SSL/TLS加密,数据传的时候变成“密文”,别人截了也看不懂;存储的时候也要加密,目标库里的敏感数据(比如手机号、银行卡号)加密存,就算数据库被黑了,数据也看不了。
访问权限也要严格控制,不是谁都能改同步任务、看同步的数据——比如只有管理员能配置同步任务,业务人员只能看自己权限内的数据,不能看敏感数据。FineDataLink就有细粒度的权限管理,能设角色,不同角色看不同的功能、数据,还能记操作日志,谁改了同步任务、什么时候改的,都能查,出了问题能追溯。

Q&A 常见问答
Q1:实时数据同步一定会影响数据库的性能吗?
A:不一定会“严重影响”,但多少会有点影响,关键看怎么优化。
要是数据量小、变更少(比如每天几百次变更),基本没感觉;要是数据量大、变更频繁(比如每秒几千次),要是不优化,源库可能会有点卡。但可以通过选对同步方式、优化配置来减影响——比如用基于日志的同步,只同步变更数据,比全量同步省资源;用FineDataLink这种优化过的工具,日志解析对源库的压力也小;还能给数据库加硬件,比如加内存、SSD,性能上来了,同步的影响就更小了。
我见过不少企业,每天同步几十万条实时数据,优化之后,数据库性能只降了5%左右,完全不影响正常业务。
Q2:如何选择适合的实时数据同步方式?
A:核心看你的业务需求,不用跟风选“最先进”的,适合的才是最好的。
先看实时性要求:要是必须“数据变了马上同步”(比如金融交易),就选基于日志的同步;要是能接受几百毫秒延迟(比如电商订单),选消息队列同步也行。
再看数据量和并发:数据量大、并发高(比如大促订单),必须用消息队列同步,不然会冲垮目标库;数据量小、并发低(比如员工信息),用触发器或者中间件同步就行。
最后看技术能力:要是你团队技术强,能自己维护消息队列、适配日志格式,选基于日志或消息队列的;要是技术能力一般,想省事儿,就选中间件(比如FineDataLink),拖拖拽拽就能配,不用写代码。
Q3:实时数据同步过程中出现数据不一致怎么办?
A:先别慌,第一步是找原因,常见的原因就那么几个:
要么是同步过程中丢了数据,比如网络断了没续传,或者消息队列漏发了;要么是源库数据本身有问题,比如同步前就有重复数据;要么是同步工具配置错了,比如没选对要同步的字段,少同步了一列。
找原因可以看同步日志,比如FineDataLink会记每一条同步记录,哪条数据同步成功了、哪条失败了、失败原因是什么,一看日志就清楚。要是丢了数据,就从上次同步成功的地方重新同步;要是源库数据有问题,就先清洗源数据再同步;要是配置错了,改了配置再重新同步。
同步完之后一定要校验,比如对比源库和目标库的记录数、关键字段值,确认一致了再用数据——别同步完不管,等用的时候才发现错了,那就晚了。
总结
实时数据同步说难不难,说简单也不简单——关键是搞懂自己的需求,选对同步方式和工具。它不是“可有可无”的,现在企业都靠数据决策、靠数据驱动业务,没有实时同步,数据就是“旧的”“错的”,根本没法儿用。
你要是刚接触实时同步,不用一下子搞懂所有技术细节,可以从简单的场景入手,比如先同步销售和库存数据,用FineDataLink这种工具配个任务试试,慢慢就有感觉了。要是场景复杂,比如跨地区、高并发,也可以先找小范围试点,没问题了再推到全公司。
记住,实时数据同步的核心是“让数据及时、准确地流起来”,流起来的数据才能帮你调库存、做决策、提效率——数据不流,就是一堆没用的数字。希望今天的分享能帮你搞懂实时同步,后面不管是配同步任务,还是选工具,都能少踩坑。