六、kubernetes 1.29 之 Pod 控制器02
一、pod控制器
1、DaemonSet
1.1 概述
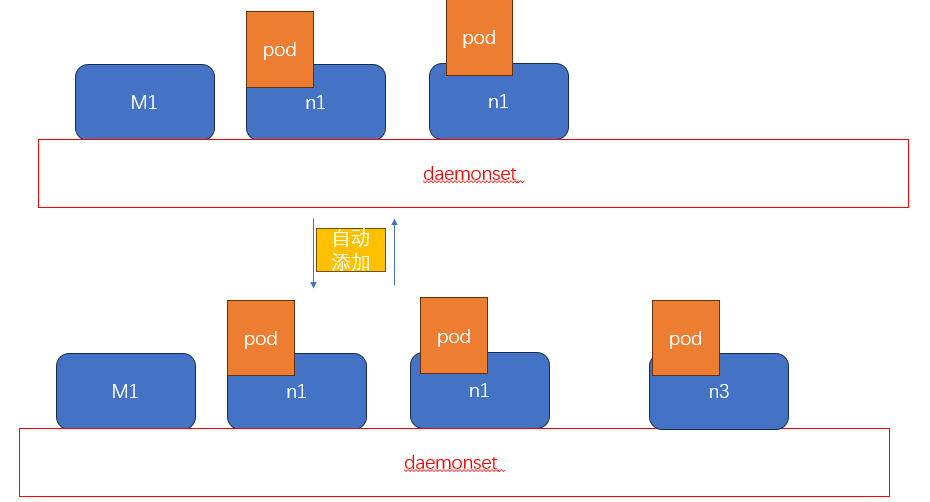
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
资源清单不需要设置 副本数量,它会自动调整
使用 DaemonSet 的一些典型用法:
运行集群存储 daemon,例如在每个 Node 上运行
glusterd、ceph。在每个 Node 上运行日志收集 daemon,例如
fluentd、logstash。在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、
collectd、Datadog 代理、New Relic 代理,或 Gangliagmond。
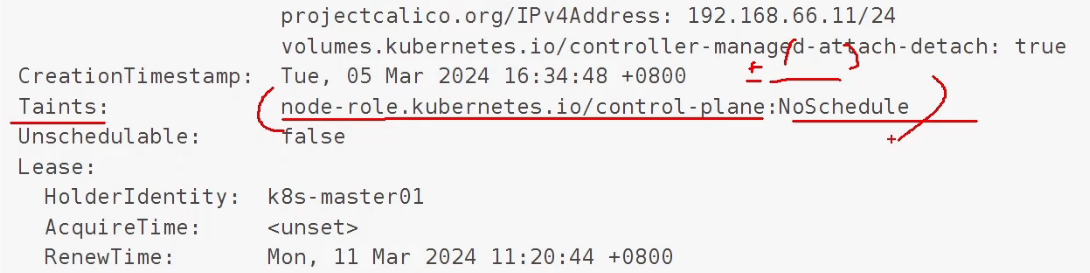
采用kubeadm部署集群 到时候,master默认会有一个污点,这个污点会让pod不能调度进来
kubectl create deploytment myapp --image=wangyanglinux/myapp:v1.0 --dry-run -o yaml deployment.yaml解释:--dry-run 只测试不运行结果: 不会创建控制器,只会测试后生成资源清单1.2 实验
DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:name: daemonset-demolabels:app: daemonset-demo
spec:selector:matchLabels:name: daemonset-demotemplate:metadata:labels:name: daemonset-demospec:containers:- name: daemonset-demo-containerimage: wangyanglinux/myapp:v1.0清除其他资源
创建控制器
2、批处理控制器 -- Job
2.1 批处理和守护进程
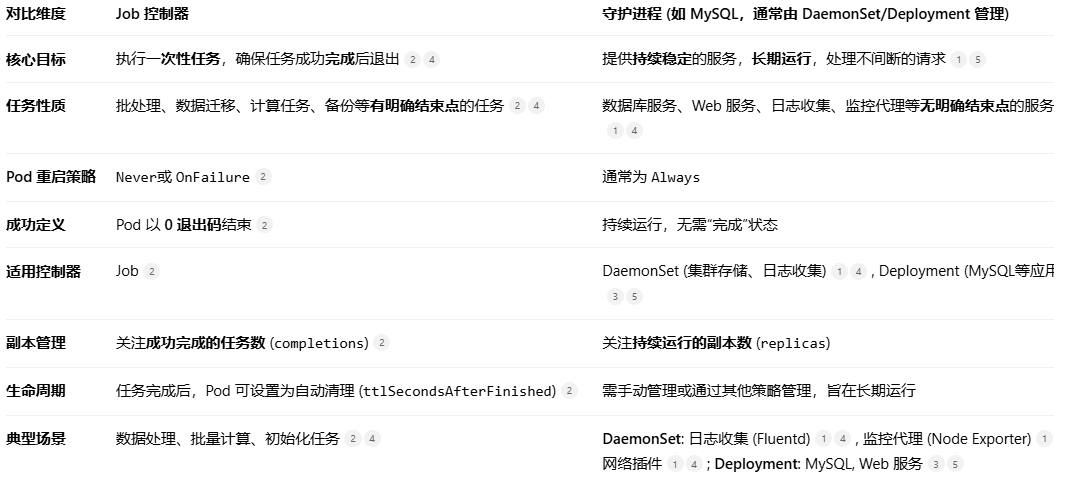
Kubernetes 中的 Job 控制器/批处理和守护进程(如 MySQL) 代表了两种不同的工作负载类型和管理方式。为了能快速把握它们的核心区别,先用一个表格来对比它们的关键特性:
2.2 概述
# Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
## 特殊说明
* **spec.template** 格式同 Pod。
* **RestartPolicy** 仅支持 `Never` 或 `OnFailure`。
* 单个 Pod 时,默认 Pod 成功运行后 Job 即结束。
* **`.spec.completions`** 标志 Job 结束需要成功运行的 Pod 个数,默认为 `1`。
* **`.spec.parallelism`** 标志并行运行的 Pod 的个数,默认为 `1`。
* **`.spec.activeDeadlineSeconds`** 标志失败 Pod 的重试最大时间,超过这个时间不会继续重试。
2.3 实验
用python 写一个计算 π 的gongshi
#-*-coding: utf-8-*-from __future__ import division#导入时间模块
import time#计算当前时间
time1 = time.time()#算法根据马青公式计算圆周率
number = 1000
#多计算10位,防止尾数取舍的影响
number1 = number + 10
#算到小数点后number1位
b = 10 ** number1#求含4/5的首项
x1 = b * 4 // 5
#求含1/239的首项
x2 = b // -239#求第一大项
he = x1 + x2#设置下面循环的终点,即共计算n项
number *= 2#循环初值=3,末值2n,步长=2
for i in xrange(3, number, 2):#求每个含1/5的项及符号x1 //= -25#求每个含1/239的项及符号x2 //= -57121#求两项之和x = (x1 + x2) // i#求总和he += x#求出π
pai = he * 4
#舍掉后十位
pai //= 10 ** 10#输出圆周率π的值
paistring = str(pai)
result = paistring[0] + str('.') + paistring[1:len(paistring)]
print(result)time2 = time.time()
print(u'Total time:' + str(time2 - time1) + 's')将代码打包成镜像
FROM python:2.7
ADD ./main.py /root
CMD /usr/bin/python /root/main.pyjob 资源清单
apiVersion: batch/v1
kind: Job
metadata:name: job-demo
spec:template:metadata:name: job-demo-podspec:containers:- name: job-demo-containerimage: wangyanglinux/tools:maqingpythonv1restartPolicy: Never创建执行 .... 漫长的下载 ...
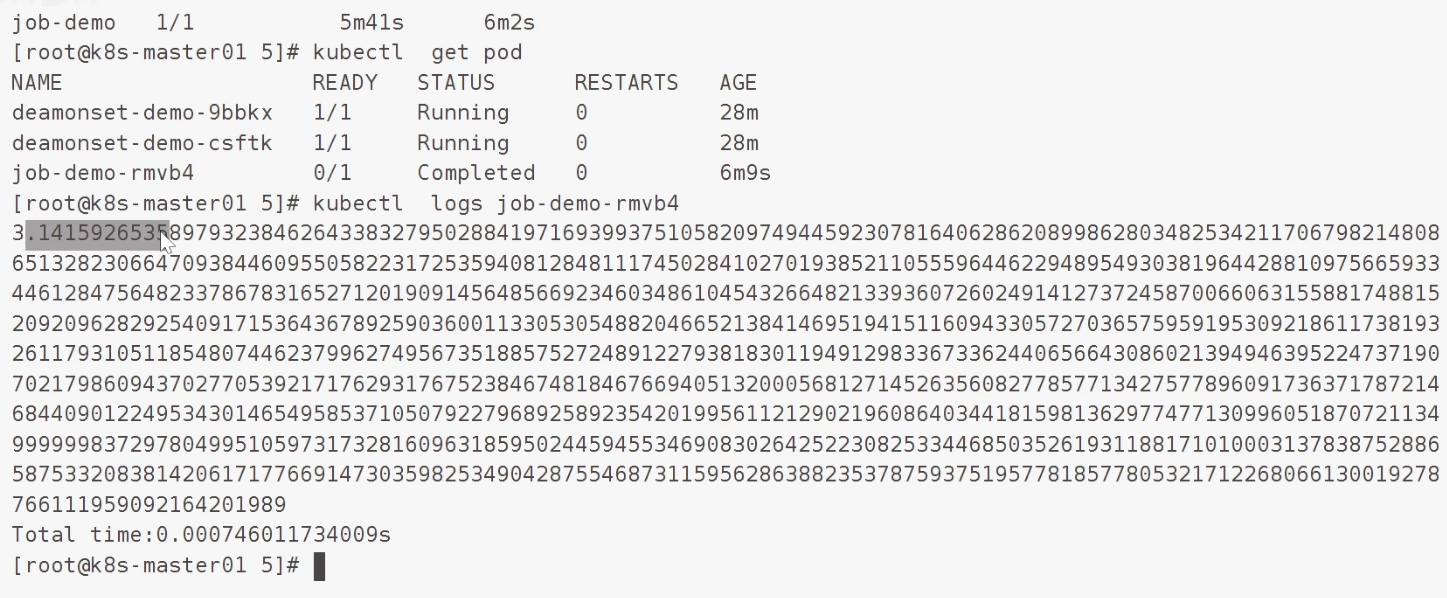
注意:
pod成功后返回码应该是 0
3、 周期的批处理 CronJob
3.1 概述
CronJob 管理基于时间的 Job,即:
在给定时间点只运行一次
周期性地在给定时间点运行
使用条件
当前使用的 Kubernetes 集群,版本 >= 1.8(对 CronJob)。
典型用法
典型的用法如下所示:
在给定的时间点调度 Job 运行
创建周期性运行的 Job,例如:
数据库备份
发送邮件
配置参数
⏰核心调度参数
参数
类型
说明
格式/可选值
.spec.schedule必需
定义任务的运行周期
Cron 格式字符串 (如
"*/1 * * * *")分时日月周
.spec.jobTemplate必需
定义要执行的 Job 模板
Job 对象格式
⚙️高级控制参数
参数
类型
说明
.spec.concurrencyPolicy可选
控制新调度的 Job 与旧 Job 的并发策略。可选值:
• Allow (默认):允许并发运行
• Forbid:禁止并发,跳过新调度
• Replace:取消旧 Job,替换为新 Job
.spec.startingDeadlineSeconds可选
启动 Job 的期限(秒)。如果因故错过调度,超过此期限后该次执行将被视为失败/跳过本次。
.spec.suspend可选
是否挂起后续所有调度。设置为
true时,CronJob 会被暂停。
📋 历史记录限制
参数
类型
说明
默认值
.spec.successfulJobsHistoryLimit可选
保留已完成成功 Job 的历史记录数量
3
.spec.failedJobsHistoryLimit可选
保留已失败 Job 的历史记录数量
1
3.2 实验
apiVersion: batch/v1
kind: CronJob
metadata:name: cronjob-demo
spec:schedule: "*/1 * * * *"jobTemplate:spec:completions: 3template:spec:containers:- name: cronjob-demo-containerimage: busyboxargs:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure创建

这里是 pod1 和 pod 2 之间间隔是 60 s,第一个 job 不一定是 60 s
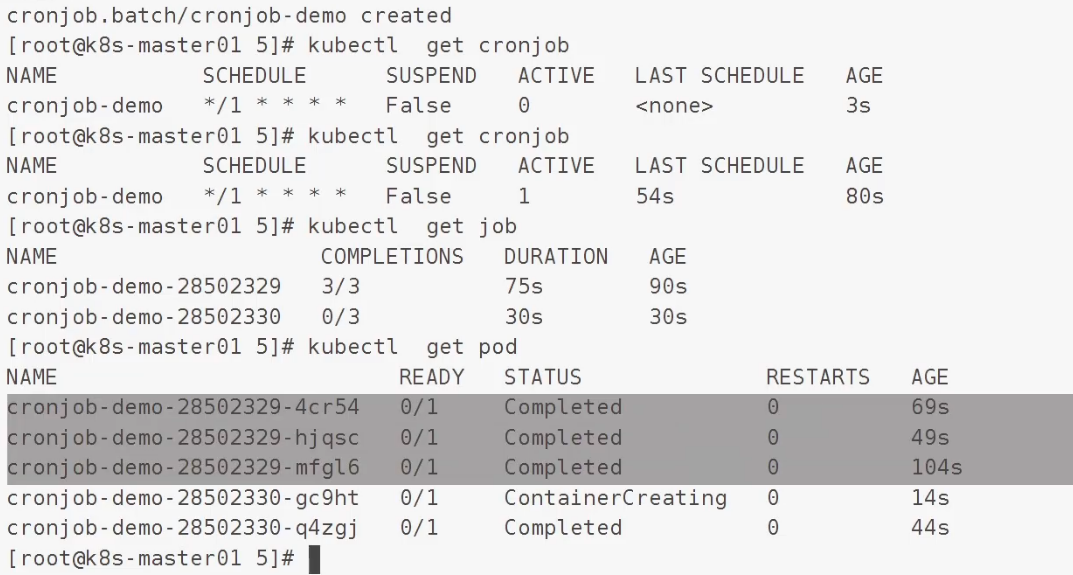
注意
cronjob 只能做到 分钟级别的,如果需要秒级别的还得去 pod当中
3.3 幂等
官方要求,cronjob操作需要是幂等的,避免发生意料之外的错误
想象一下,你有一个非常聪明的机器人保姆,她的名字就叫 CronJob。
1. CronJob:定时任务
你给机器人保姆下达了一个指令:
“每天下午5点整,准时把客厅的垃圾倒掉。”
这就是一个典型的 CronJob!
定时(Cron):
每天下午5点任务(Job):
倒垃圾无论你在不在家,心情好不好,这个机器人都会在每天下午5点准时执行“倒垃圾”这个任务。Kubernetes 的 CronJob 就是这样,它负责在指定的时间表(比如
0 2 * * *表示每天凌晨2点)周期性地创建一个 Job(任务)来执行。
2. 幂等(Idempotent):安全地重复执行
现在,我们加入“幂等”这个概念。“幂等”意味着一个操作可以用同样的参数重复执行多次,但只会产生一次性的效果。
这为什么重要呢?想象一下这个场景:
非幂等的危险情况(没有幂等性):
下午5点,机器人准备去倒垃圾。它走到垃圾桶边,“哔哔哔——检测到客厅里有一个垃圾桶,执行倒垃圾操作!”
第一次执行:成功。垃圾桶被清空。
如果某种原因(比如网络抖动、系统卡顿)导致它以为自己没成功,它又触发了第二次执行:机器人看着已经空了的垃圾桶,可能会报错:“错误!目标垃圾桶不存在!任务失败!” 或者更糟,它开始满屋子寻找“丢失”的垃圾桶,把不是垃圾的东西给扔了。
这很糟糕,对吧? 任务重复执行导致了错误或意外后果。
幂等的安全情况(拥有幂等性):
一个设计成“幂等”的倒垃圾任务会是这样的:
机器人走到垃圾桶边,“哔哔哔——检测到客厅里有一个‘未清理’的垃圾桶,执行倒垃圾操作!”
第一次执行:成功。垃圾桶被清空,并被标记为“已清理”。
同样,如果它因故触发第二次执行:机器人再次扫描,发现垃圾桶的状态是“已清理”。它的逻辑是:“哦,这个目标已经被处理过了。我的任务已经完成,无需再次操作,直接报告成功即可。”
看到了吗? 即使任务被重复调用了多次,最终的结果也和只调用一次一样——客厅没有垃圾。这就是幂等性的巨大价值:它让重复操作变得安全。
结论:CronJob 与 幂等 的关系
在 Kubernetes 和运维的世界里:
CronJob 就像是那个严格遵守时间的机器人保姆,它只负责按时触发任务(Job)。
而 幂等性 则是你编写的每个任务脚本(Job)自身应该具备的特性。
为什么幂等性对 CronJob 至关重要?
因为 CronJob 是定时周期性触发的,在很多意外情况下(比如网络问题、临时资源不足、节点重启),CronJob 控制器可能会多次启动同一个任务。如果你的任务脚本不具备幂等性,就可能导致:
重复插入数据(数据库出现脏数据)。
重复扣款(灾难性的金融事故)。
重复删除或覆盖文件。
因此,一个优秀的、由 CronJob 调度的任务(比如数据库备份),必须是幂等的。 例如,它的逻辑应该是:
“检查是否已经存在今天凌晨2点的备份文件?如果存在,就跳过;如果不存在,就创建。”
这样,无论这个任务被触发多少次,最终都只会产生一份备份文件。
简单总结:
CronJob 是闹钟,负责准时喊你;幂等是你起床后的动作规则:无论闹钟响多少次,你只起床一次。
二、总结
控制器
Pod 控制器
守护进程类型
RC 控制器
保障当前的 Pod 数量与期望值一致
RS 控制器
功能与 RC 控制器类似,但是多了标签选择的运算方式
Deployment
支持了声明式表达
支持滚动更新和回滚
原理:deployment > RS > pod
DaemonSet
保障每个节点有且只有一个 Pod 的运行,动态
批处理任务的类型
Job
保障批处理任务一个或多个成功为止
CronJob
周期性的创建 Job,典型的场景:数据库的周期性备份...
kubectl create 、apply 、replace
create
创建资源对象
-f 通过基于文件的创建,但是如果此文件描述的对象存在,那么那怕文件描述的信息发生了改变,再次提交时也不会应用
apply
创建资源对象、修改资源对象
-f 基于文件创建,如果目标对象与文件本身发生改变,那么会根据文件的指定一一修改目标对象的属性(部分更新)
replace
创建资源对象、修改资源对象
-f 基于文件创建,如果目标对象与文件本身发生改变,那么会重建此对象(替换)