C++初阶(10)string类
来学习STL的第一个容器——string。
1. 为什么学习string类
1.1 C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合。
C语言中的字符串有两种存储方式:
- 字符数组:
- 用常量字符串初始化字符数组;(字符串拷贝在栈上,可改)
- 用单个字符的元素列表来初始化字符数组;(不自动存储'\0')
- 字符指针:
- 用常量字符串初始化(常)字符指针;(字符串在常量区,不可改)
为了操作方便,C标准库中提供了一些str-系列库函数(字符串操作函数),但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
面向对象程序设计、面向对象编程(Object Oriented Programming)
1.2 两个面试题(暂不做讲解)
字符串转整形数字
字符串相加
在OJ中,有关字符串的题目基本以string类的形式出现;而且在常规工作中,为了简单、方便、快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数。
2. 标准库中的string类
来学习STL的第一个容器——string。string的含义就是“串”。
可以把string理解为传统的字符数组。

string在日常中使用得非常非常多的——这些数据结构本质就是存储各种各样的数据,:
整型、浮点是表示数据的大小,还有一些其他更复合的信息都是用string存的。
例如:身份证号码就不能用整型存,原因:
- 表示大小范围的问题;
- 有些身份证号码里面带X,就只能用字符串存。
名称、地址……现实中有很多信息都需要用字符串去存。
C语言的字符串是面向过程的实现方式(Procedure Oriented Programming)——数据和方法是分离的,数据(内存空间)是用户自己管理,方法是标准库提供,就特别不方便管理。
举个例子:
- strcpy:把一块空间拷贝到另一块空间——两块空间都得自己提供,还得保证目的空间至少和被拷贝空间一样大或更大,如果目的空间更小,就越界了。但strcpy不管,在copy之前你自己要注意;
数据和方法分离就会有很多的问题,用起来就会很麻烦——既要管空间,又要管方法/使用。
- strcat:在当前字符串后面追加,有两个很挫的地方:
1.会从前到尾地去找\0,效率很低;
2.追加的空间得自己准备好,得有足够的空间——strcat不负责,它只管追加数据;
所以C语言的串使用起来是不好用的,C++的string明显好用多了。
- string是一个管理字符数组的一个类。
string和C的char数组有相似之处,也有差别。
严格来说,string不是属于STL。
string的发展历史:
- 祖师爷搞完模版,就去搞库,直接搞可能不太好,就先搞了个探路的——string,其实就是属于是数据结构里的串,那在祖师爷设计string的时候,HP就把STL整个给设计出来了。
string在下面,不属于STL。
可以理解为string的产生早于STL,属于是一个探路的,打先锋的。
string设计好之后,C++标准库的团队还没来得及设计STL,发现已经有人写好了。
后面就直接把这个设计好的数据结构库纳入了C++标准库里面。
学string的时候会感受到它的设计跟后面的STL的设计是有所不同的——相对不那么成熟。
2.1 string类(了解)
string类的文档介绍
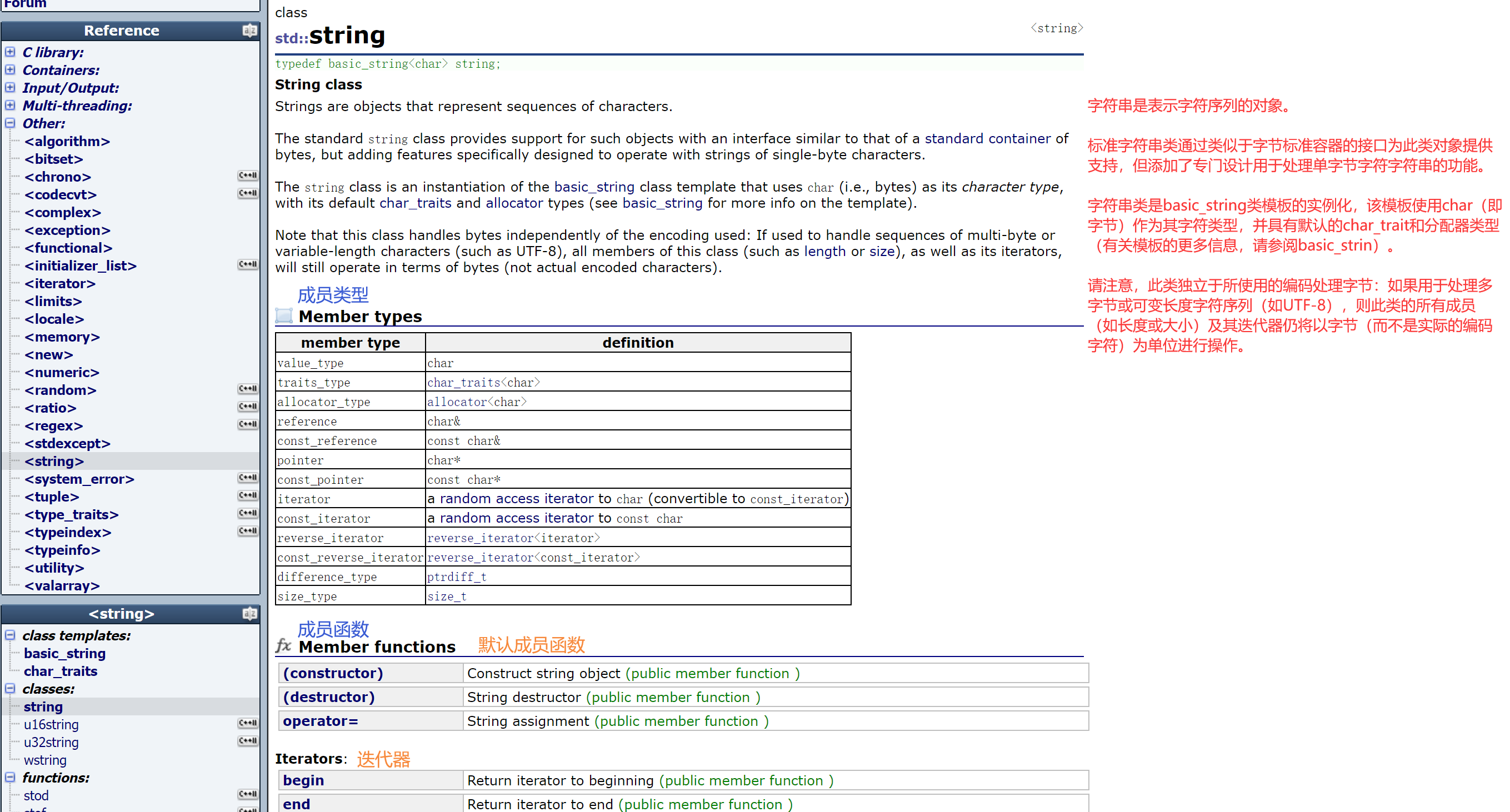
其中:

string类的原名是basic_string<char>,是一个类模版。为什么是类模版???
简单来说,编码有:
- ASCode——char的编码,表示英文;
- UNICode——万国码,表示全世界其他国家的文字,例如中文(GBK),UNIcode里面一个非常有名的东西叫UTF8……
可以认为string是一个管理char的数组,wstring就是管理wchar(两个字节)的数组……

最常用的就是string,string就是一个char数组的串(顺序表)。
学习STL,或者学习库函数,最重要的就是要学会看文档。
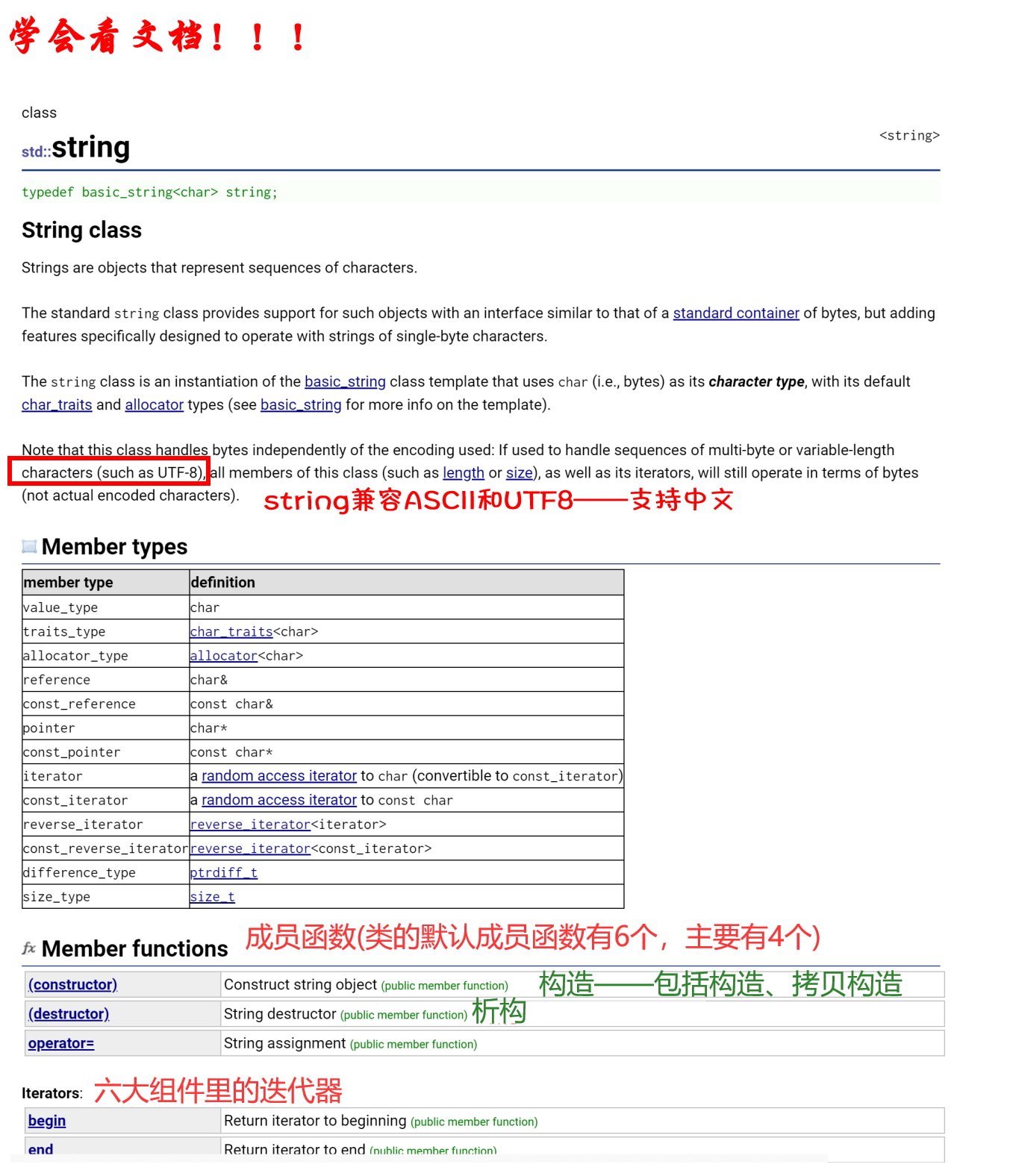
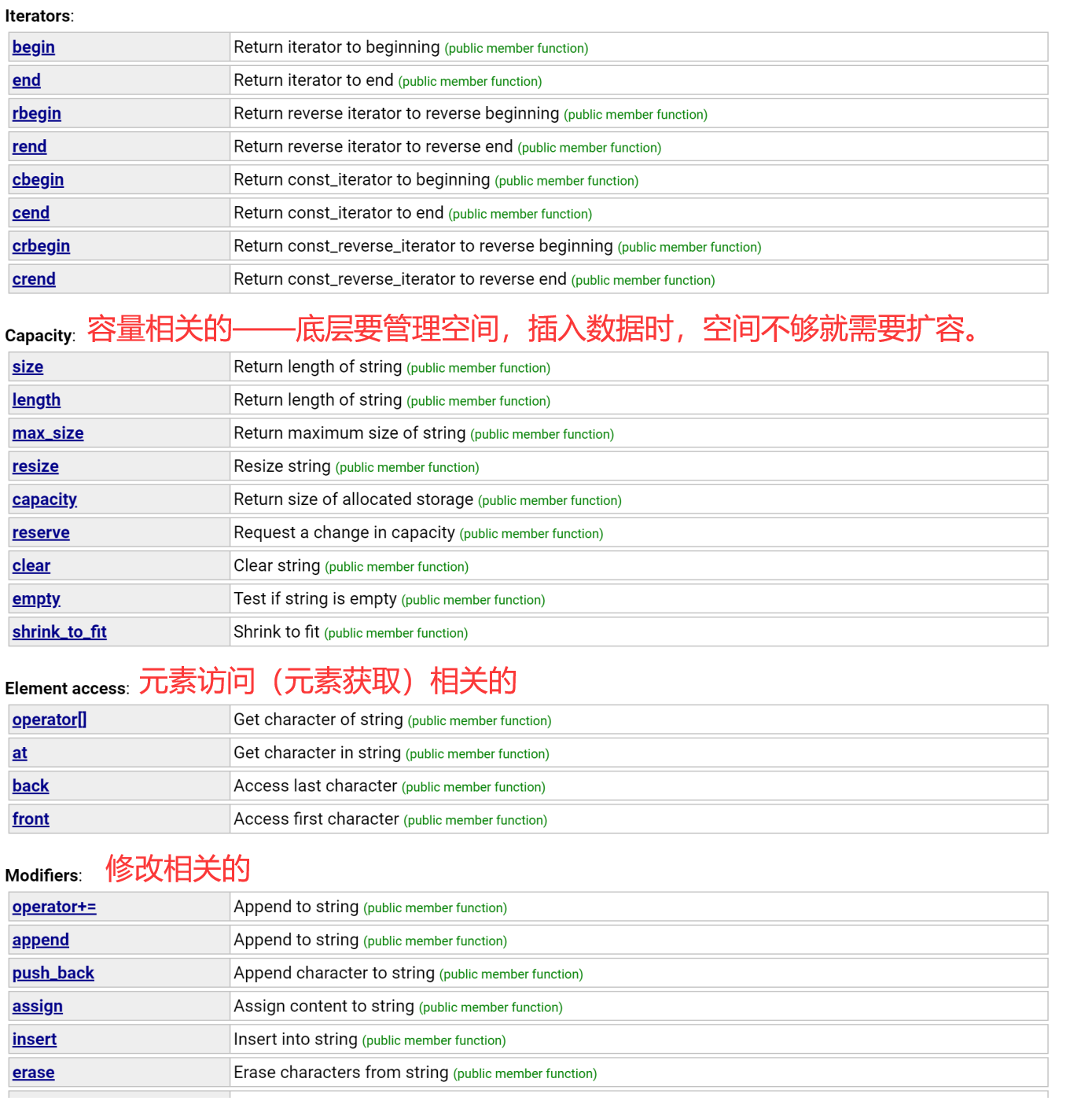
string有一百多个成员函数——string的设计有点冗余。
【说明】
- 字符串是表示字符序列的类
- 标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性。
- string类是使用char作为它的字符类型,使用它的默认char_traits和分配器类型(关于模板的更多信息,请参阅basic_string)。
- string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并用char_traits和allocator作为basic_string的默认参数(关于更多的模板信息请参考basic_string)。
- 注意,这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符(如UTF-8)的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际编码的字符)来操作。
【总结】
- string是表示字符串的字符串类。
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator> string;
- 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含头文件#include <string>以及using namespace std;
2.2 string类的常用接口说明(注意下面我只讲解最常用的接口)
2.2.1 默认成员函数
2.2.1.1 构造函数
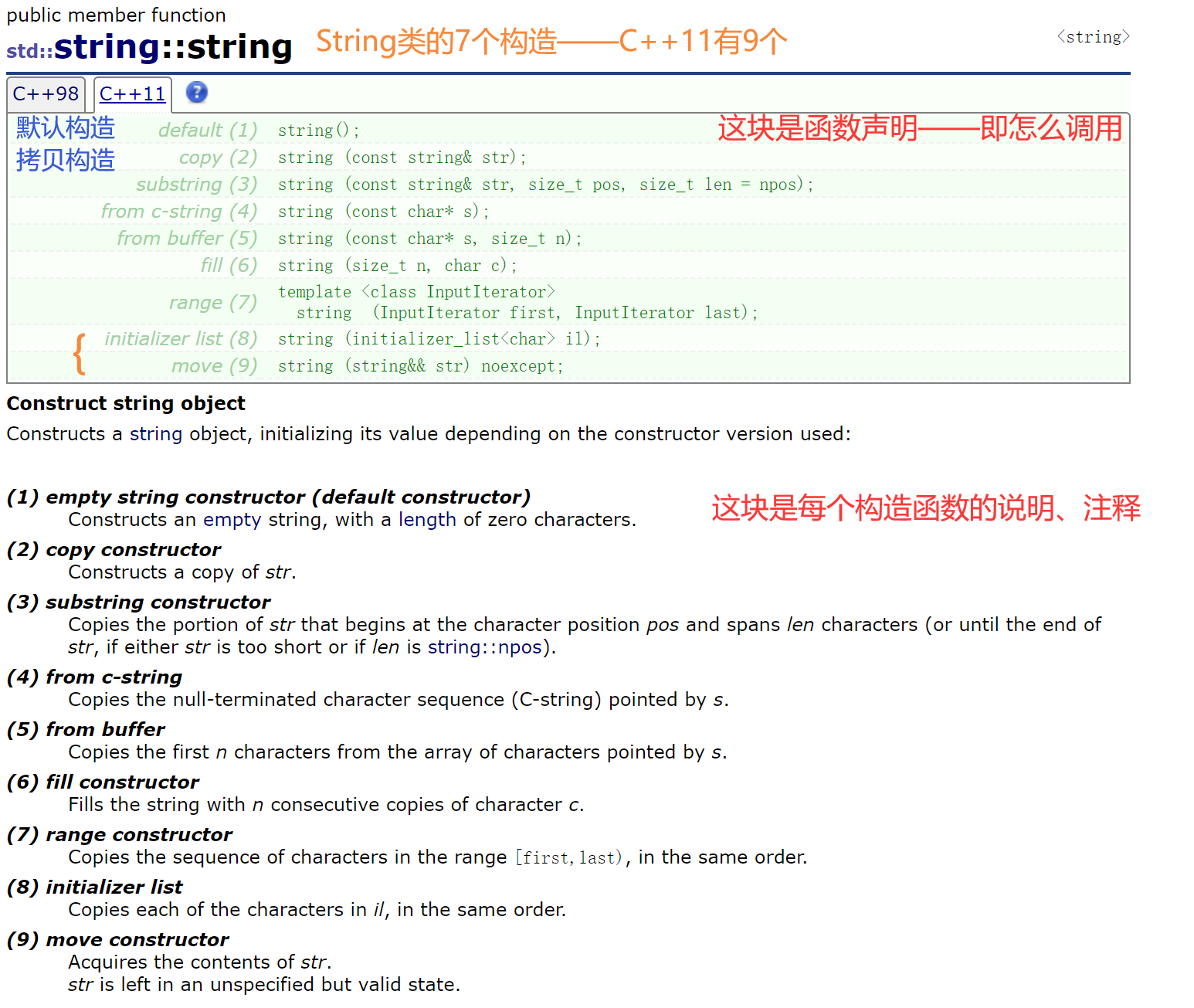
C++11中string有9个构造——多的2个构造类型还没学过,暂时先以C++98为标准学。
七个构造函数·文档解读
前2个
- default:默认构造——构造空串,有0个字符。
- copy:拷贝构造——构造一个串的拷贝。
第3~5个——构造的再扩展。
- substring:子串构造——部分拷贝,仅拷贝str的pos位置(下标)开始的len个字符,或者直到str的结尾——如果str太短或者len是 string::npos 的话。
(len带缺省参数npos,默认拷贝到结束)
- from C-string:字符串常量构造。
- from buffer:字符串常量部分构造——取前n个。(不足n个会越界访问)
- fill:填充构造——用n个c字符去构造。
- range:迭代器构造。

【说明】
- pos位置指的是下标,即pos==3的话,是第4个元素。
- npos是string里面的一个静态的const成员变量, 值为-1——存补码,全f,size_t类型(无符号整型)的-1是最大的正整型42亿多 (注:最大的整型INT_MAX是21亿多)。

string不可能有那么长,所以len=npos就告诉编译器拷贝的时候直接找\0,找到才结束拷贝。
“二八原则”:只需要掌握常用的二三十个成员函数,其余的了解有这么个东西,用到的时候再查文档。
七个构造函数·使用练习
#include <iostream>
#include <string>void Teststring()
{// 常用的3个——重点掌握string s1; //第1个构造——默认构造:构造一个空的string类对象string s2("hello world"); //第4个构造(最常用)——带参构造:用一个字符串常量去构造string s3(s2); //第2个构造,拷贝构造cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;cin >> s1;cout << s1 << endl;
}执行结果:
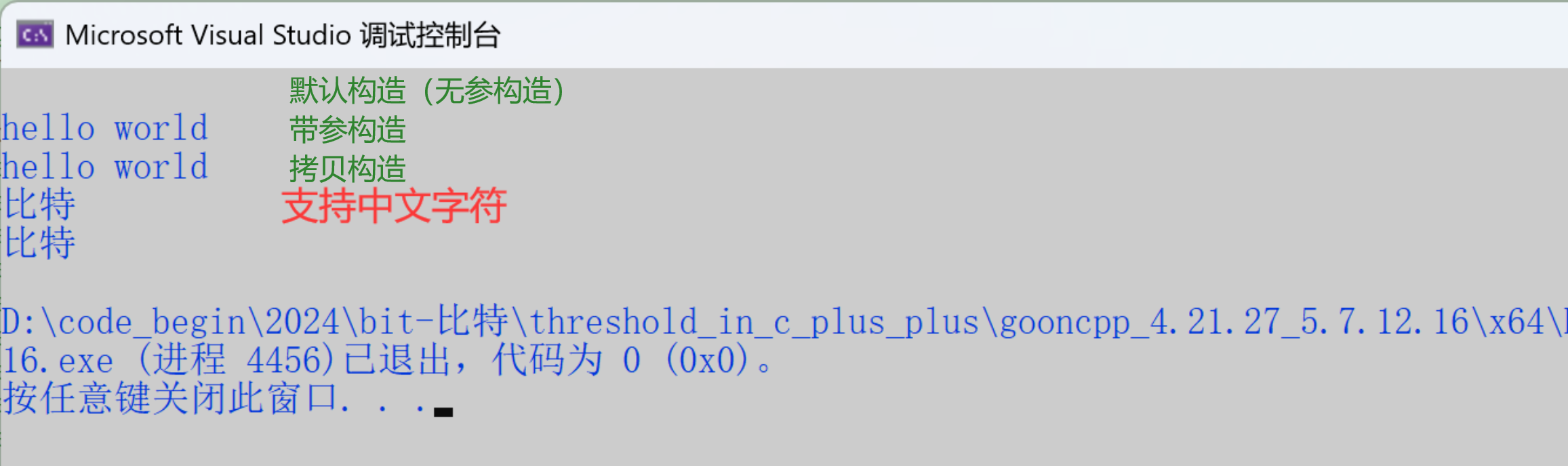
原因是string默认用的char底层对应的编码是变长编码,可以兼容ASCode(英文)和UTF-8(中文)。
可以看到:
- string是支持直接用cout打印、cin输入的——自定义类型想支持流插入、流提取,必须有流插入、流提取运算符重载。
- 而流插入、流提取为了迎合默认使用习惯,不能重载为成员函数,只能重载为非成员函数,即全局函数。
【注意】
- c语言的scanf和printf和cin、cout相比需要取地址,而cin、cout有了引用就方便多了。
- 其次,对于自定义类型,cin、cout就成了唯一选择,c语言那套在这就行不通了――成员变量是私有的。
void test_string1()
{string s2("hello world"); //第4个构造(最常用)——带参构造:用一个字符串常量去构造// 不常用——了解string s4(s2, 3, 5); //第3个构造——部分拷贝,从s2的第3个位置(下标3——第四个字符)开始拷贝5个字符string s5(s2, 3); //第3个构造——部分拷贝,使用缺省值,有多少拷贝多少string s6(s2, 3, 30); //第3个构造——部分拷贝,类似的场景,当错误地给到len一个长于数组剩余长度的值,也是拷贝到\0停止cout << s2 << endl;cout << s4 << endl;cout << s5 << endl;cout << s6 << endl;
}执行结果:

len > 后面的字符长度有两种情况:
- 不传给len缺省值npos;
- 或者给len一个较大的值;
都会触发str is too short,拷贝到\0结束。
测试第5个构造:
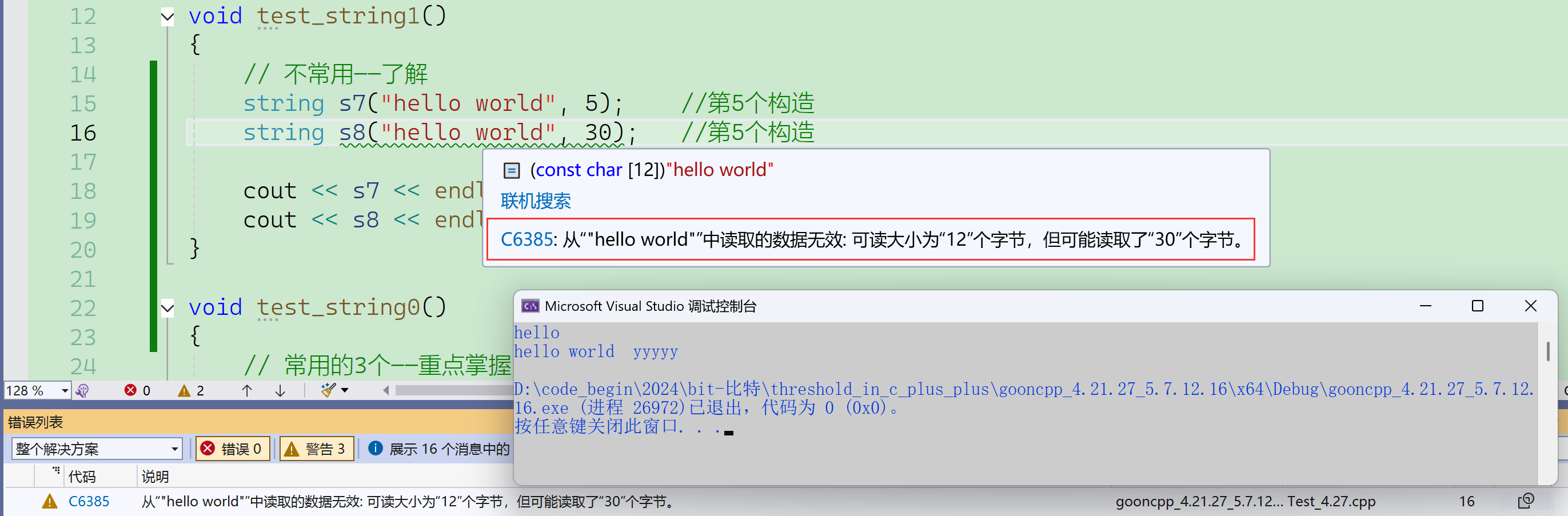
跟第4个类似,用字符串常量进行初始化,多了一个参量n——使用前n个字符来初始化
这个也是被吐槽的部分, 很多人觉得这个构造压根就没必要, 大家几乎都不太会这么去用,太呆了。其实就是一开始设计的时候想多了 觉得大家会这样用,会那样用, 其实不是的。
测试第6个构造:
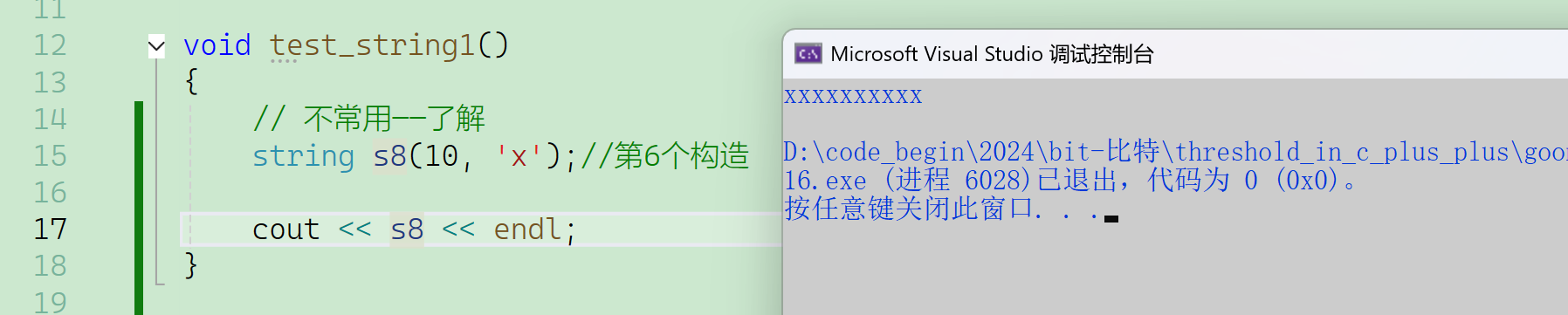
第7个构造涉及迭代器,后面再说。
【完整测试代码】
#include <iostream>
#include <string>void Teststring()
{// 常用的3个——重点掌握string s1; //第1个构造——默认构造:构造一个空的string类对象string s2("hello world"); //第4个构造(最常用)——带参构造:用一个字符串常量去构造string s3(s2); //第2个构造,拷贝构造// 不常用——了解string s4(s2, 3, 5);//第3个构造,部分拷贝构造,从s2的第3个位置(下标3——第四个字符)开始拷贝5个字符string s5(s2, 3);//第3个构造,部分拷贝,使用缺省值string s6(s2, 3, 30);//第3个构造,部分拷贝,类似的场景,当错误地给到len一个长于数组剩余长度的值,也是拷贝到\0停止string s7("hello world", 5);//第5个构造string s8(10, 'x');//第6个构造cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;cout << s4 << endl;cout << s5 << endl;cout << s6 << endl;cout << s7 << endl;cout << s8 << endl;cin >> s1;cout << s1 << endl;
}【总结】
| (constructor)函数名称 | 功能说明 |
| string() (重点) | 构造空的string类对象,即空字符串 |
| string(const char* s) (重点) | 用C-string来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string&s) (重点) | 拷贝构造函数 |
第3个、第5个不常用。
2.2.1.2 析构函数

析构函数:
- 释放底层空间,清理资源;
- 自动调用,程序员不用管;
2.2.1.3 赋值重载
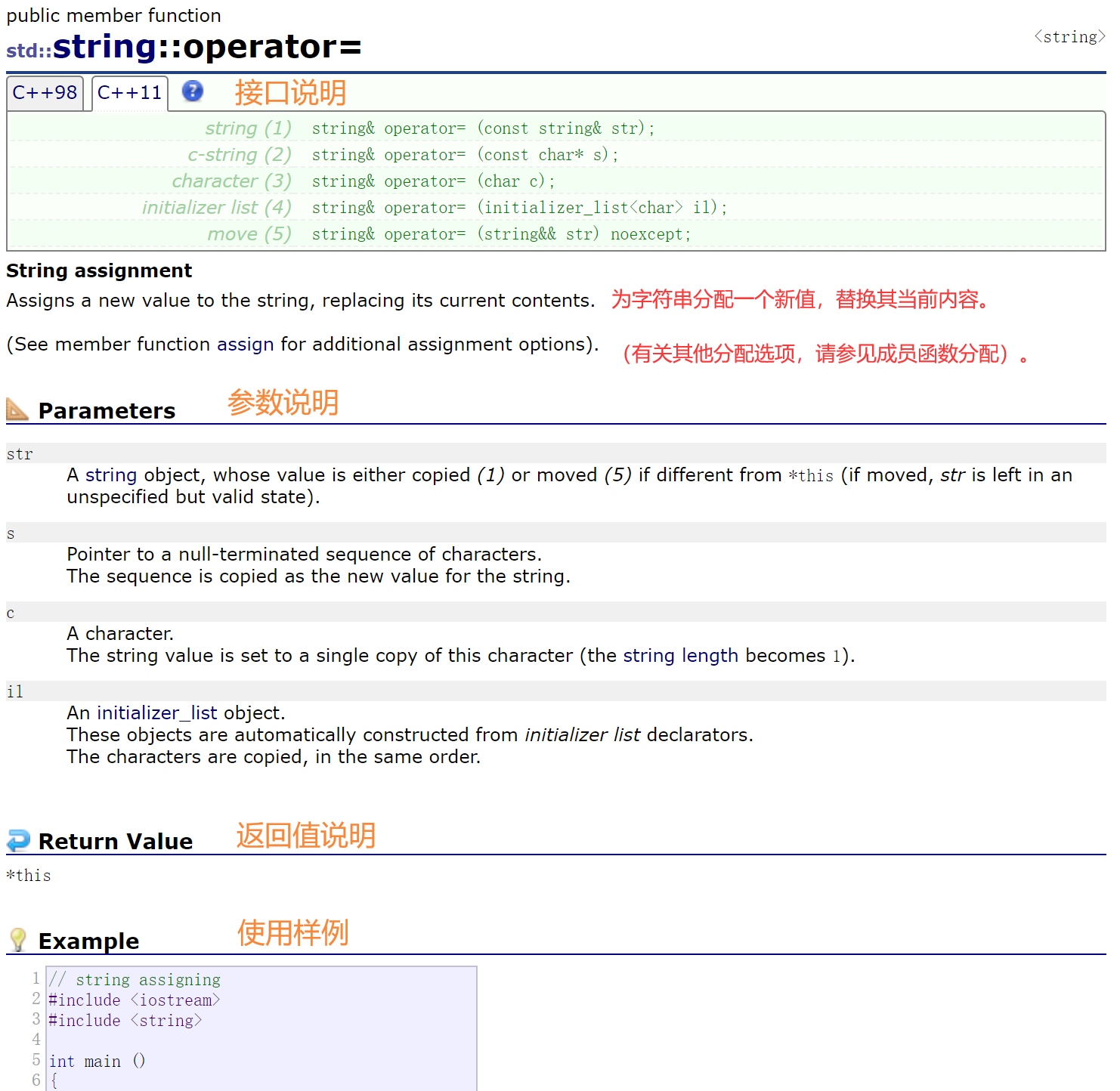
C++98支持3种类型的赋值,C++11支持5种类型的赋值。
- string赋值给string;
- 常量字符串赋值给string;;(用得少)
- char赋值给string;(用得少)
也是一个比较偏冗余的设计。
代码测试——拷贝构造
void test_string2()
{//最常用的——第4种构造(两种写法)string s1("hello world");string s2 = "hello world"; //隐式类型转换(构造一个临时对象) + 拷贝构造——>优化成一个构造
}代码测试——引用
void test_string2()
{//隐式类型转换(构造一个临时对象,具有常性)const string& s3 = "hello world";
}- 引用的话,好处就是没有拷贝构造,只有构造;
- 引用的不是这个常量字符串,而是是一个临时string类对象;
- 不能直接引用,要加const;
假设其他数据结构(如:链表、顺序表)的pushback尾插,插入的数据是一个string,以前得先创建一个有名对象,或者写匿名对象,但是现在最方便的方式是单参构造的隐式类型转换:
//尾插
void push_back(const string& s) //引用接收
{}void test_string2()
{// 以前调用尾插,需要创建有名对象string s4("hello world"); //只有构造(没有拷贝构造。没有优化)push_back(s4);// 或者写匿名对象// 现在最方便的方式是直接传字符串——隐式类型转换push_back("hello world"); //只有构造(没有拷贝构造。没有优化)
}2.2.2 string类对象的容量操作
怎么去遍历一个字符串???——有两种方式:
- 获取长度len,然后使用operator[];
- 迭代器;
2.2.2.1 size()
(1)遍历方式1:size() + [ ]重载
获取长度不是使用strlen——只适应于常量字符串、C语言的字符数组。

返回字符串长度——不算\0。
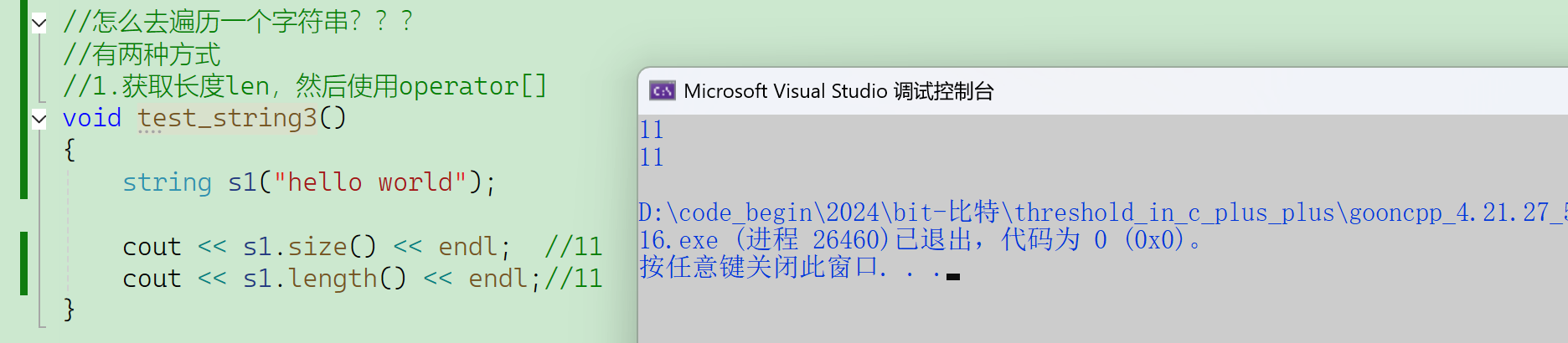
它们没有什么不同,那为什么会有两个不同的接口???
- string出来地比STL早,一开始设计的string的长度接口函数叫length。
- 后来STL出来之后又增加了一个size,就是为了跟后面的STL里面的一些容器的长度接口size保持一致。
- 字符串string、顺序表vector的长度接口叫length都没问题,而树set还叫length就不合适了,所以STL里面为了保持一致,无论是谁,计算数据规模都是使用size,没有length这个接口。
- 总而言之:string设计length是从个例的角度去考虑的,STL设计size是从整体去考虑的。
- 结论:以后统一使用size()
【】重载:返回pos位置的字符。
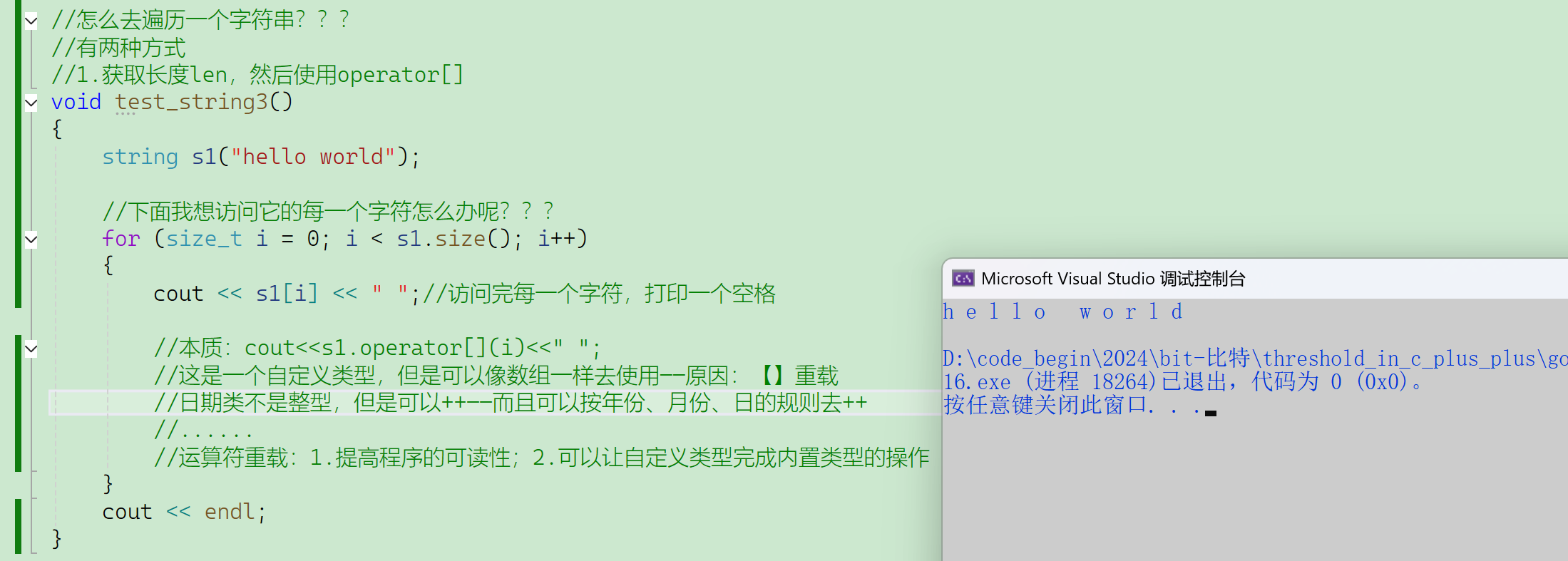
运算符重载:1.提高程序的可读性;2.可以让自定义类型完成内置类型的操作。
来看一下一个简易的string类:
//简易的string,类似的底层结构就是这样的
class string
{
public://【】运算符重载——返回数组里面第i个位置的字符char& operator[](size_t i){assert(i < _size); //暴力检查——STL喜欢暴力解决问题,越界直接报错return _str[i];}//传值返回char——返回的是返回对象的拷贝//引用返回char&——返回的是返回对象的别名,减少拷贝——在深拷贝的时候能有效减少消耗,浅拷贝时优势不明显//引用的2个意义——之前只讲了第一个// 1、减少拷贝——浅拷贝时优势不明显,这时候第2个意义就来了// 2、修改返回对象private:char* _str;size_t _size;size_t _capacity;//管理字符数组的顺序表,有一个指向字符数组的指针、数据规模size、容量capacity——不够就扩容
};//这个简易的string只作演示,要注释掉,留下来就跟库里面冲突了这就是传引用返回,之前没有讲到的第2层意义——能修改返回对象。
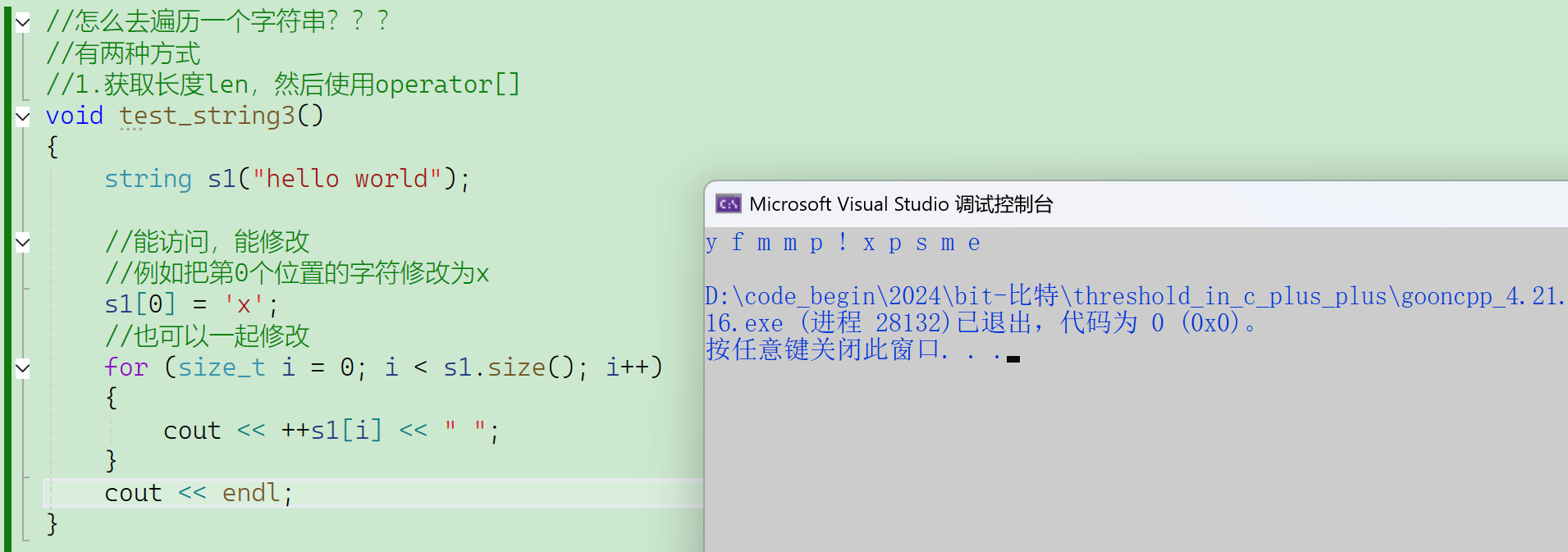
调用operator[],返回数组第i个位置字符的别名,因为出了作用域这个数组依然还在(对象在堆上),所以可以返回别名,因为调用时使用的是this*指针,所以出了作用域还在。
常规数组越界访问,不一定能检查出来,这时候就很危险,读程序检查不出来,执行也没有报错。
string像数组一样使用时,若越界访问,则程序会暴力中止(有assrt越界检查)。
报了一个断言错误。
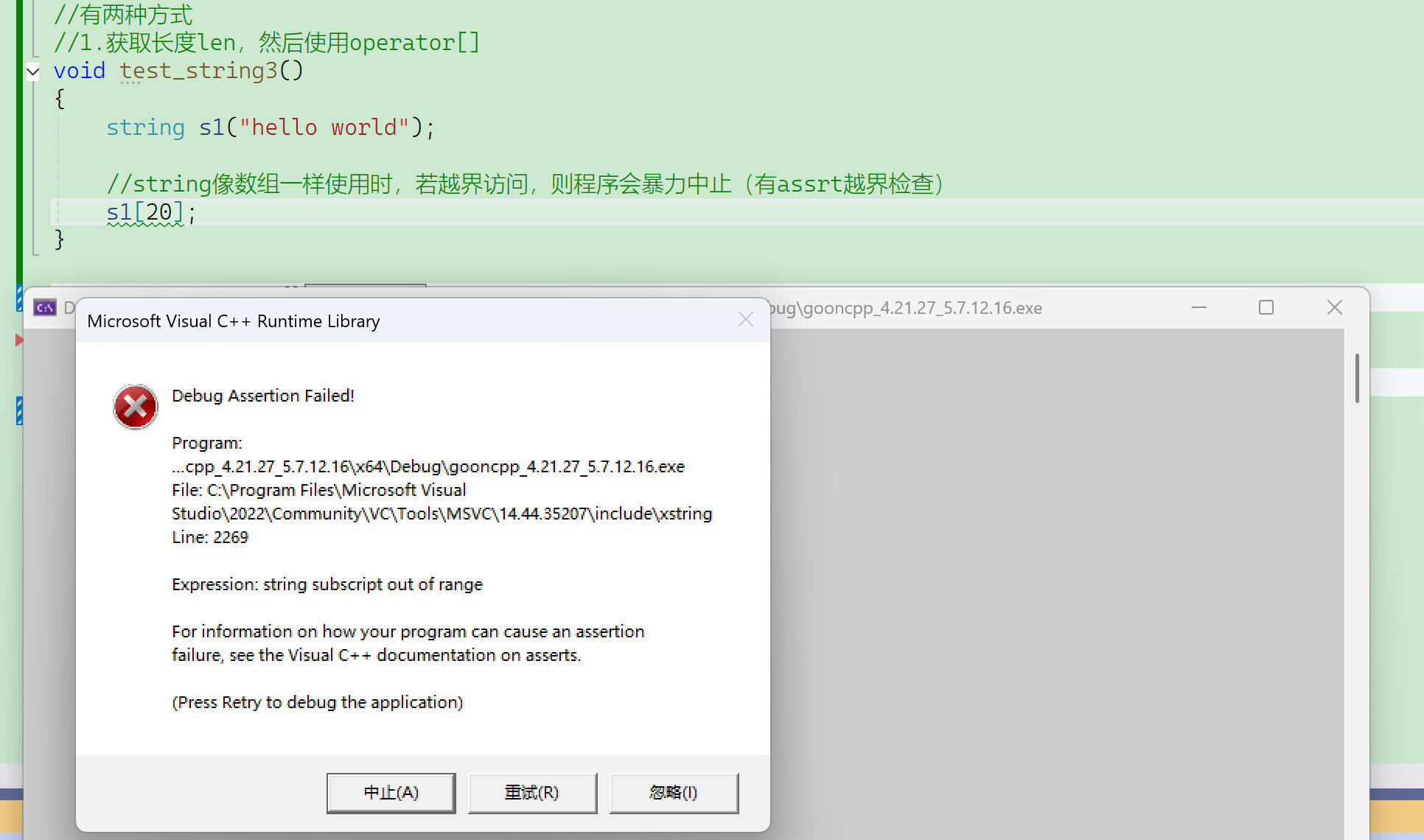
这也是C++比C优越的地方。
【】重载写了两个版本:
- 普通版本;
- const版本;(size、length都只有const版本)
为了应对常对象不能被修改。

第2种【】的重载——不是直接返回引用,而是返回常引用,保证常对象不能被修改。
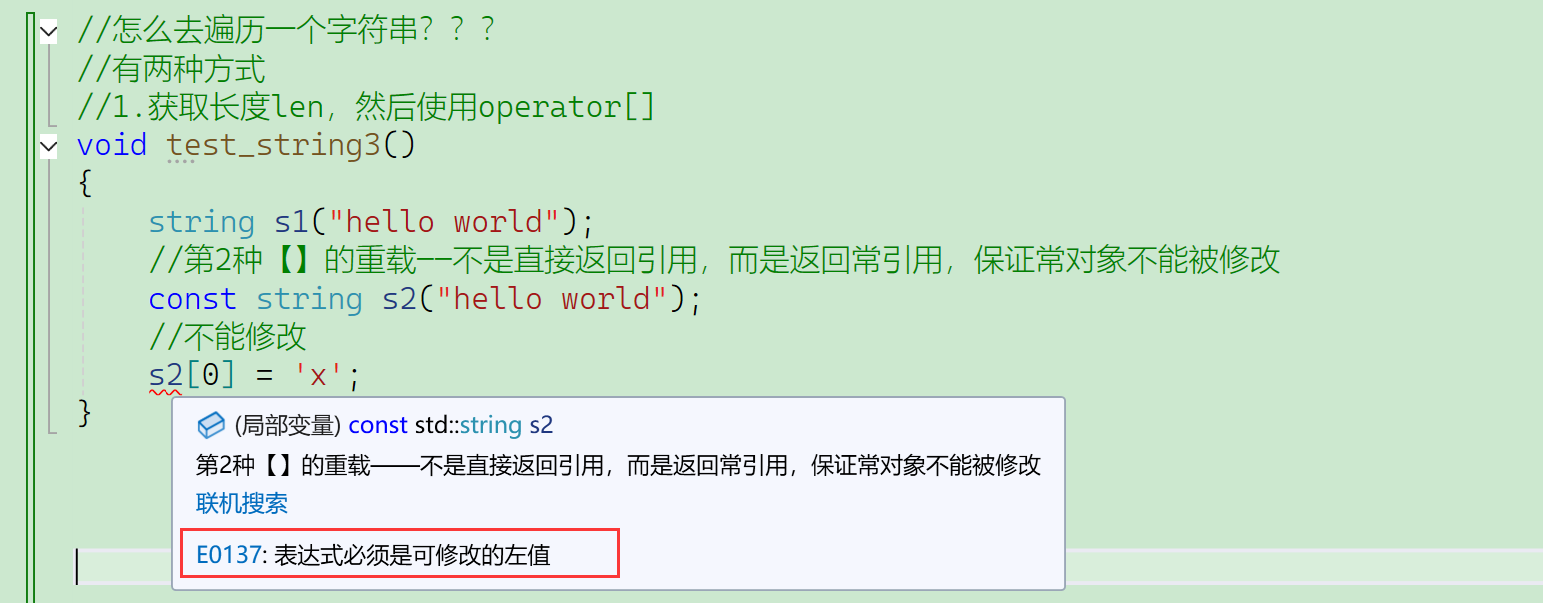
这也体现了有函数重载时,编译器进行匹配的时候是匹配更适合的:
- 如果没有下面的第2个重载,常对象也不能调用第1个 ——权限的放大;
- 如果只提供了一个const版本,非const对象也能调用;
- 但是普通的string对象也不让修改了,不能修改不符合需求;
【原则】
- 一般的成员函数只需要写一个const版本(只读)。——const对象、普通对象都能调用
- 引用返回的这类非const版本的成员函数,要多重载一个const版本,接收常对象,返回常引用。(可读可写)
2.2.2.2 max_size、clear、empty、capacity
capacity就是返回容量,没什么好说的。

clear清除数据;
empty判断数据是否为空。
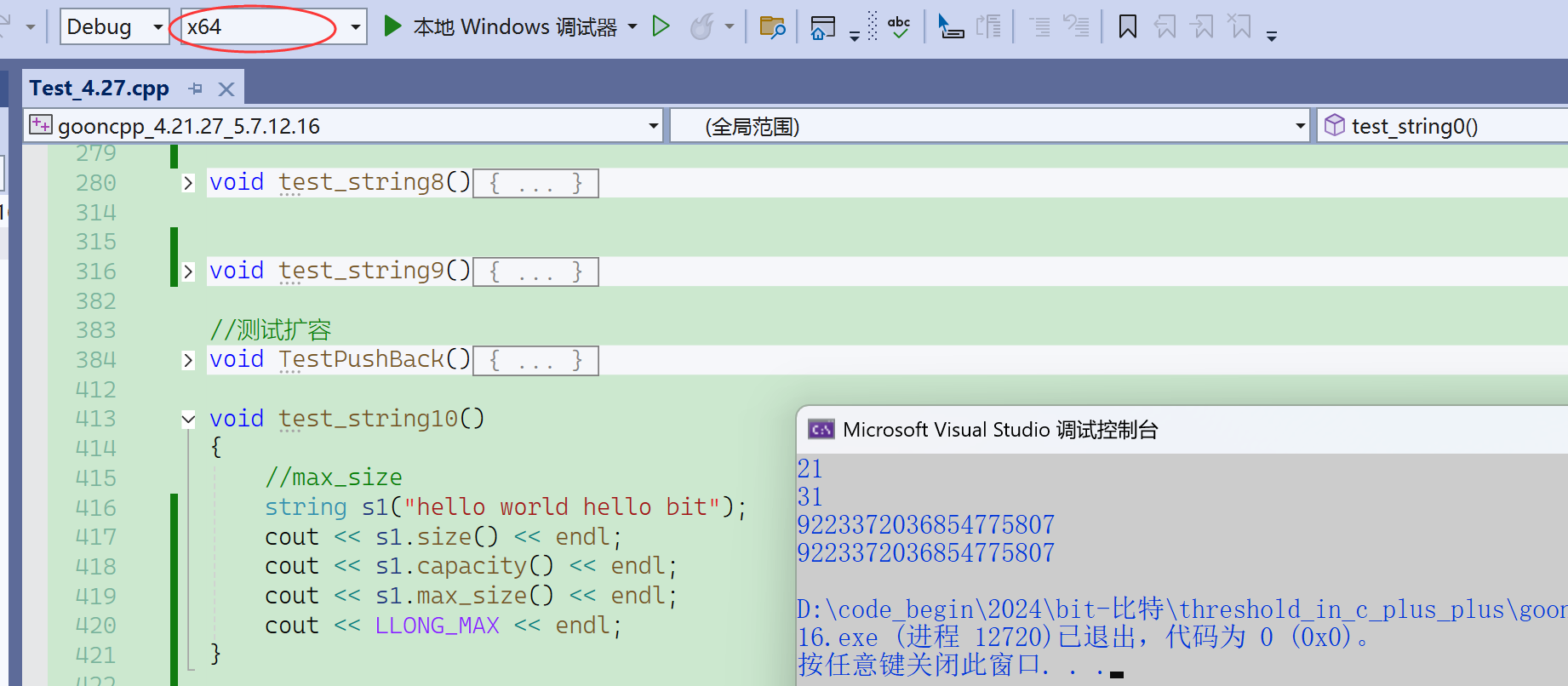
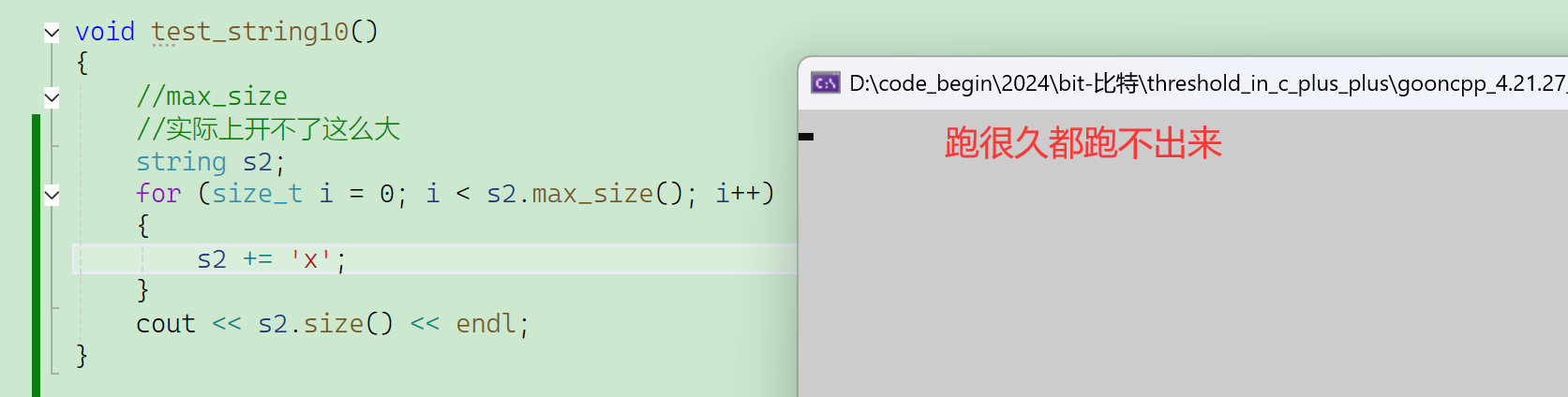
max_size是早期的理想设计,告诉一下这个字符串能有多长,结果变成一个没啥用的接口。
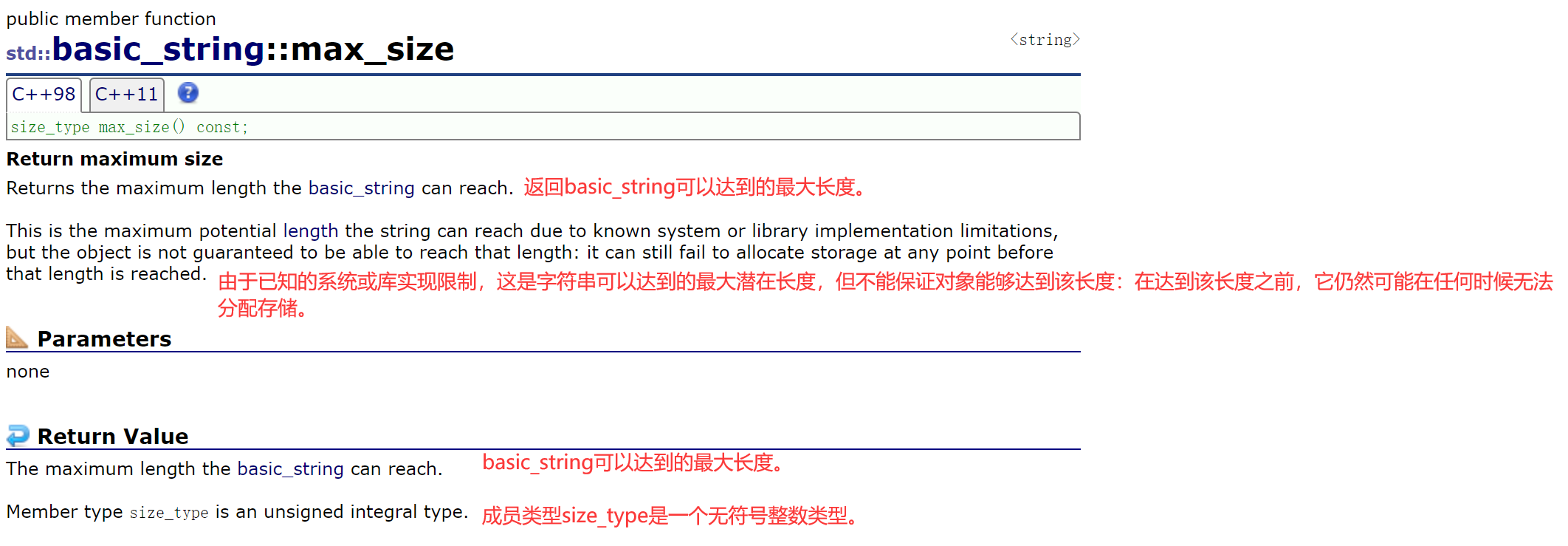
实际上开不了这么大,所以max_size成了一个没什么用的接口。
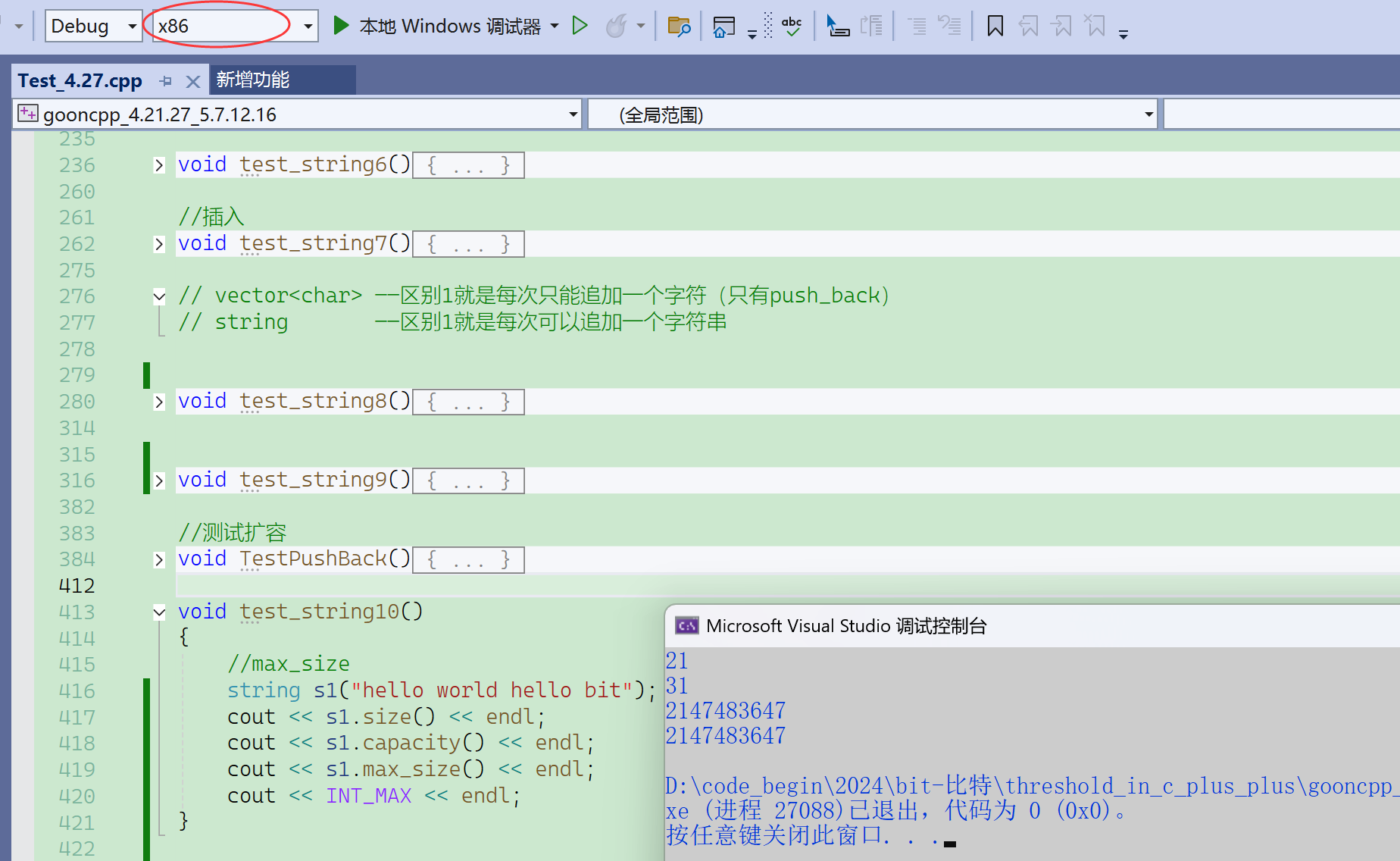
21亿多字节,大概是2G的空间。
2.2.2.3 reserve()、resize()

2.2.2.3.1 reserve()

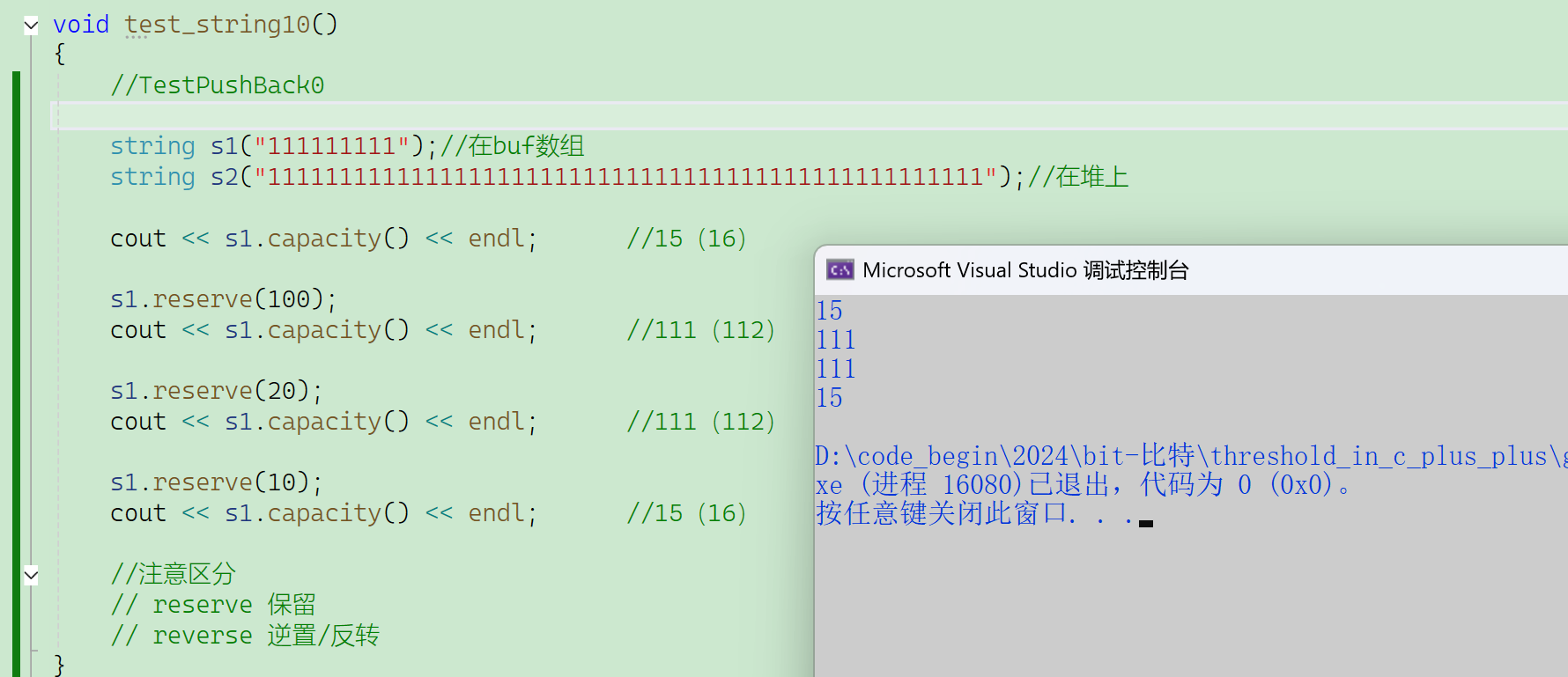
【说明】
- VS 下reverse之后的capacity可能比预置的更大;
- 传的值比当前capacity小,VS默认是不缩容的;
- 除非传的值比15小,就会缩到buf;
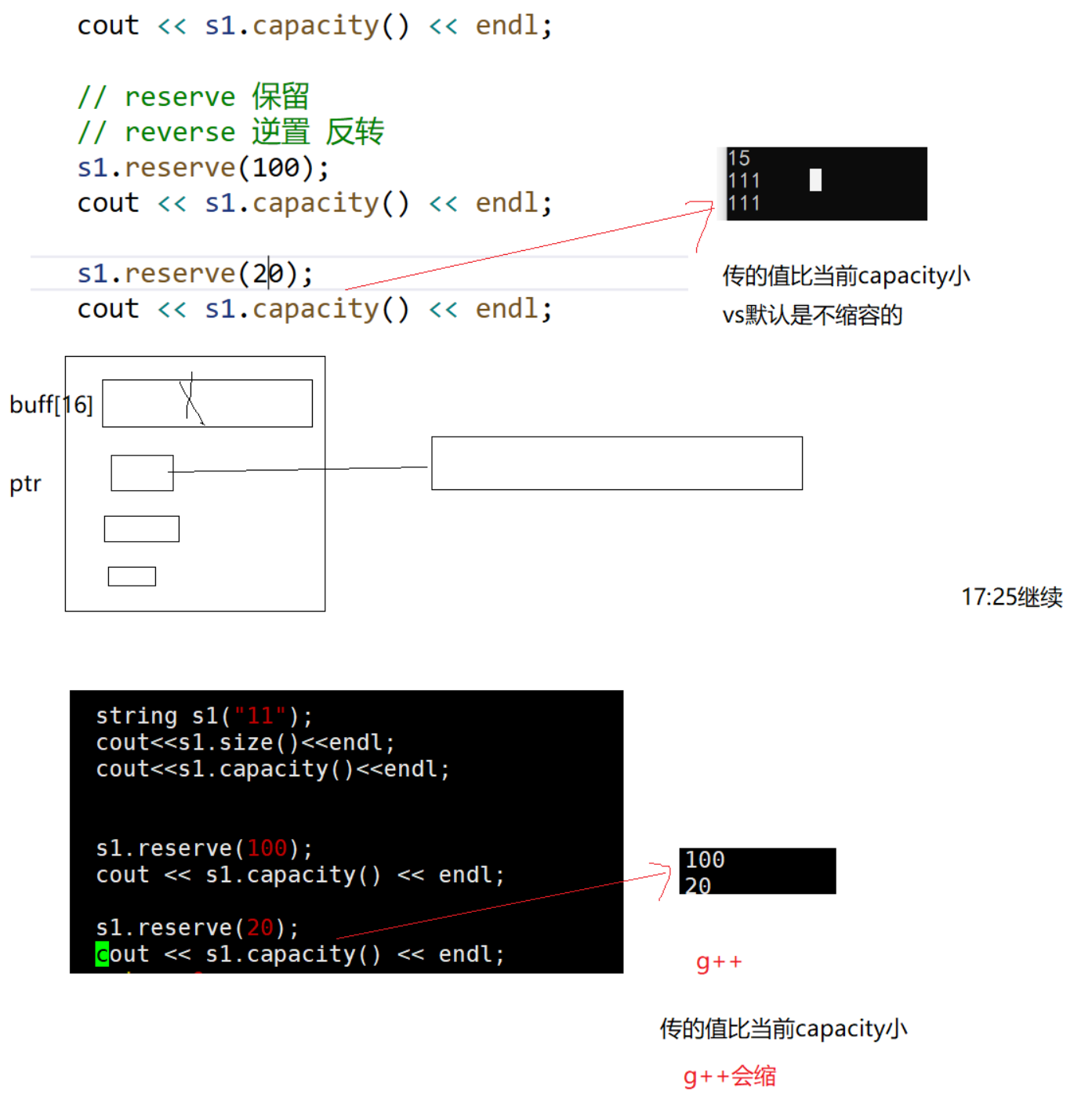
【总结】reverse会扩容,不一定会缩容,不同的编译器不一样。
(扩容后的容量不一定是指定容量)
一般也不用reserve()来缩容。reserve的应用一般是知道需要多少空间,提前开好。
(扩容不一定指定多少就开多少,可能比指定的大——VS)
场景1:
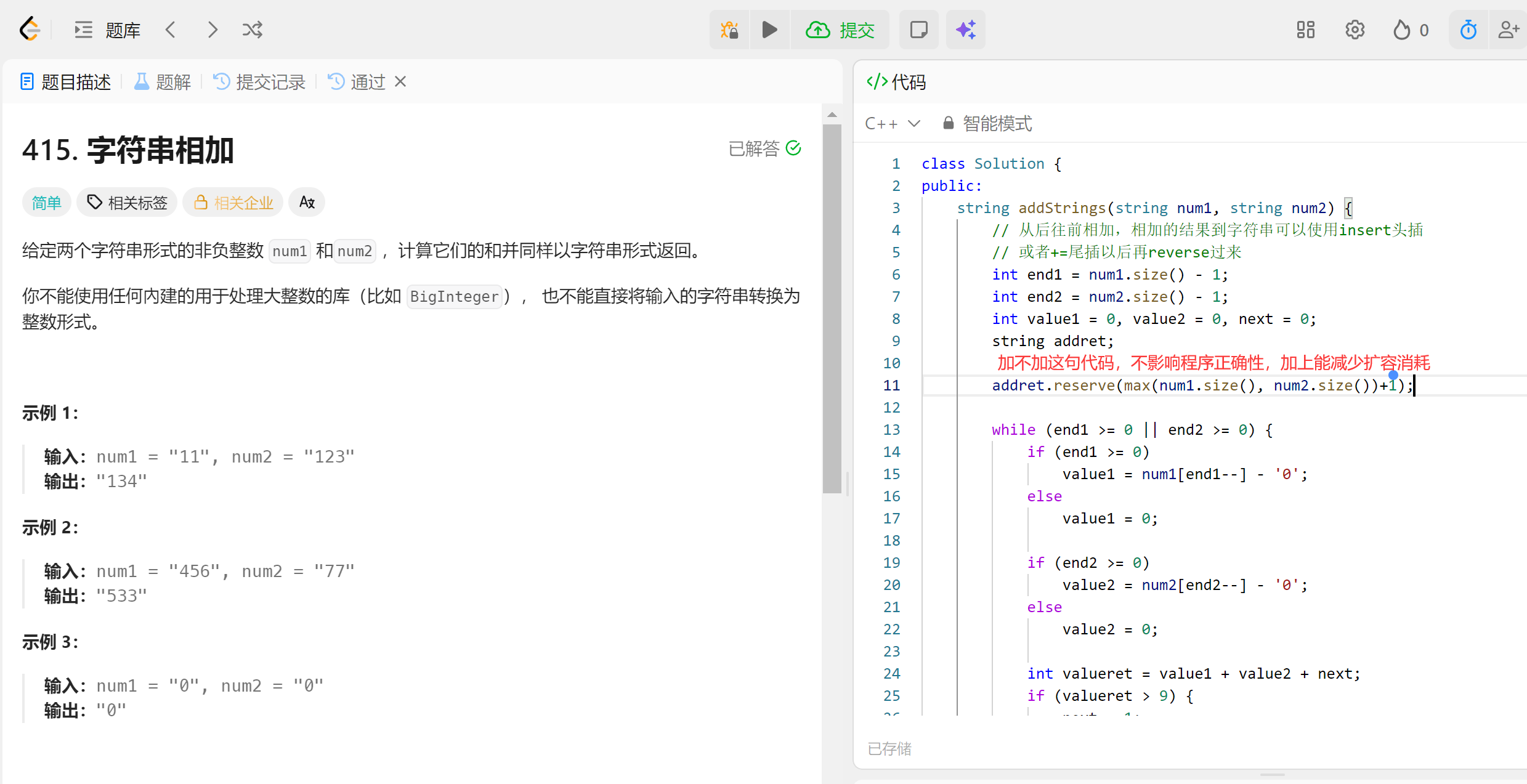
场景2:

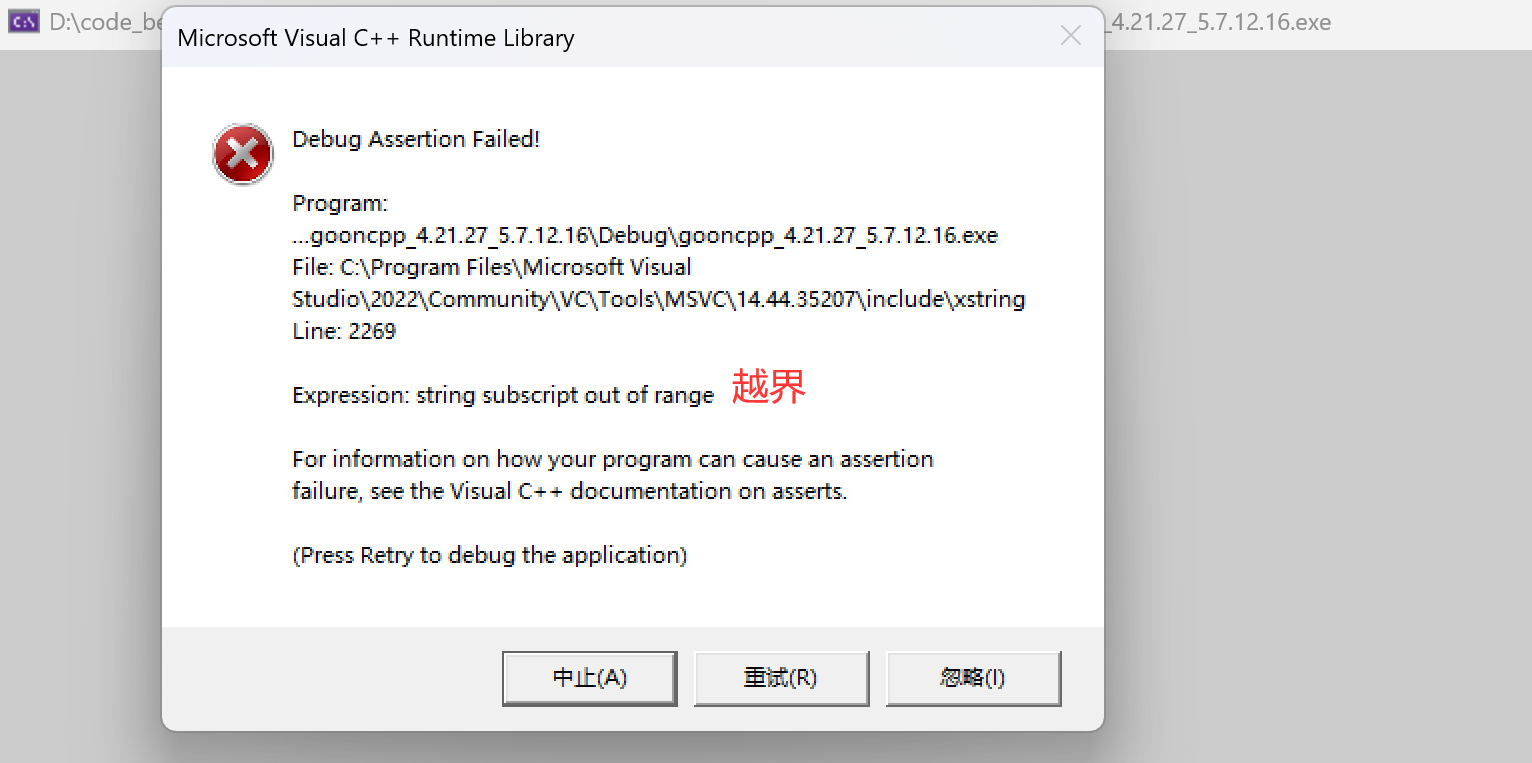
- reserve之后最容易犯的一个错误就是直接访问扩容的空间。
- []会调底层的operator[],会检查[]里的数字是不是小于size。
- 空间变大了,数据量(size)没变,【】只允许访问有效数据部分。
2.2.2.3.2 resize()
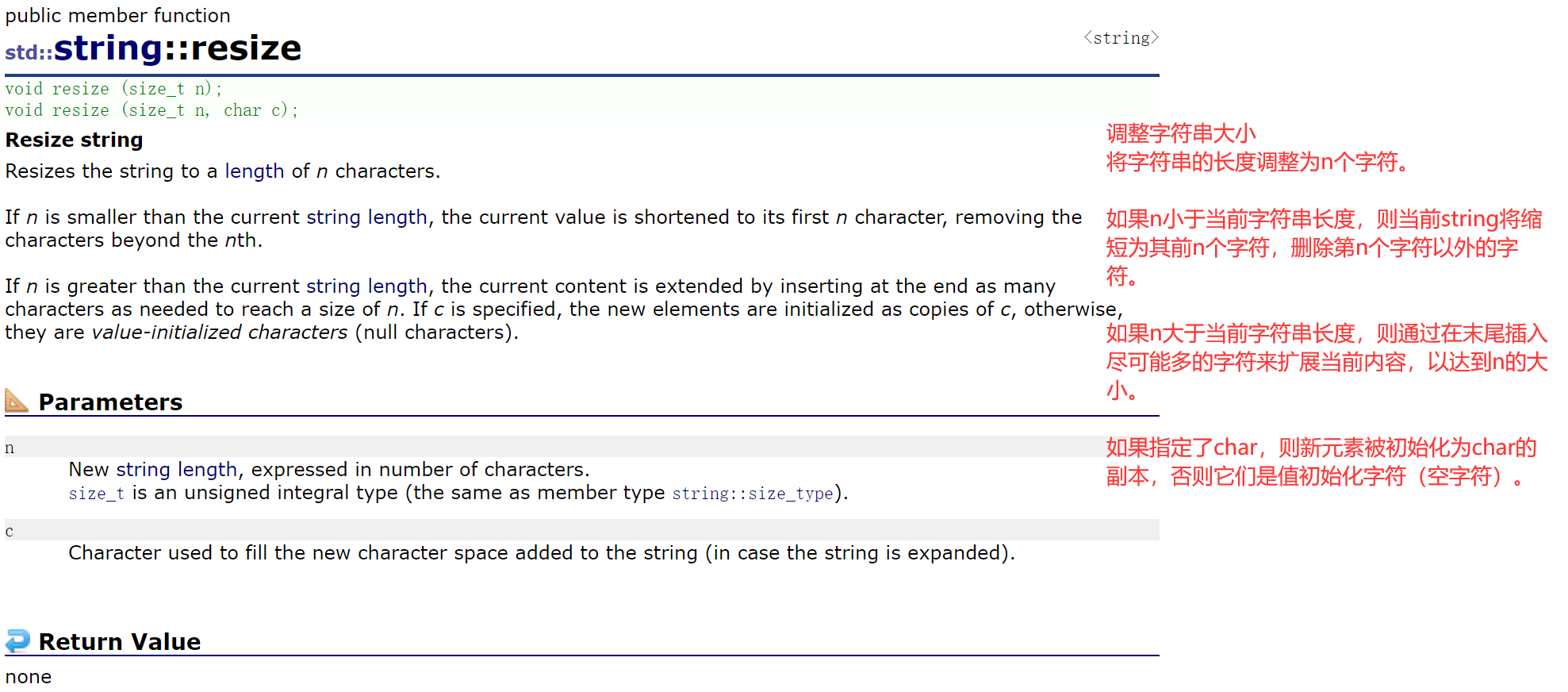
重载了两个版本:
- 第一个版本是不给cahr
- 第二个版本是给char——n大于原size,会给后面补char;否则这个char没用。
当已知num1和num2的和str为76543,要存到str就不能用reserve——只扩容不扩size。
就要用到resize——对有效数据个数size的扩充,必要时会扩capacity。
s1.resize(5, '0');//开5个位置,每个位置都初始给成0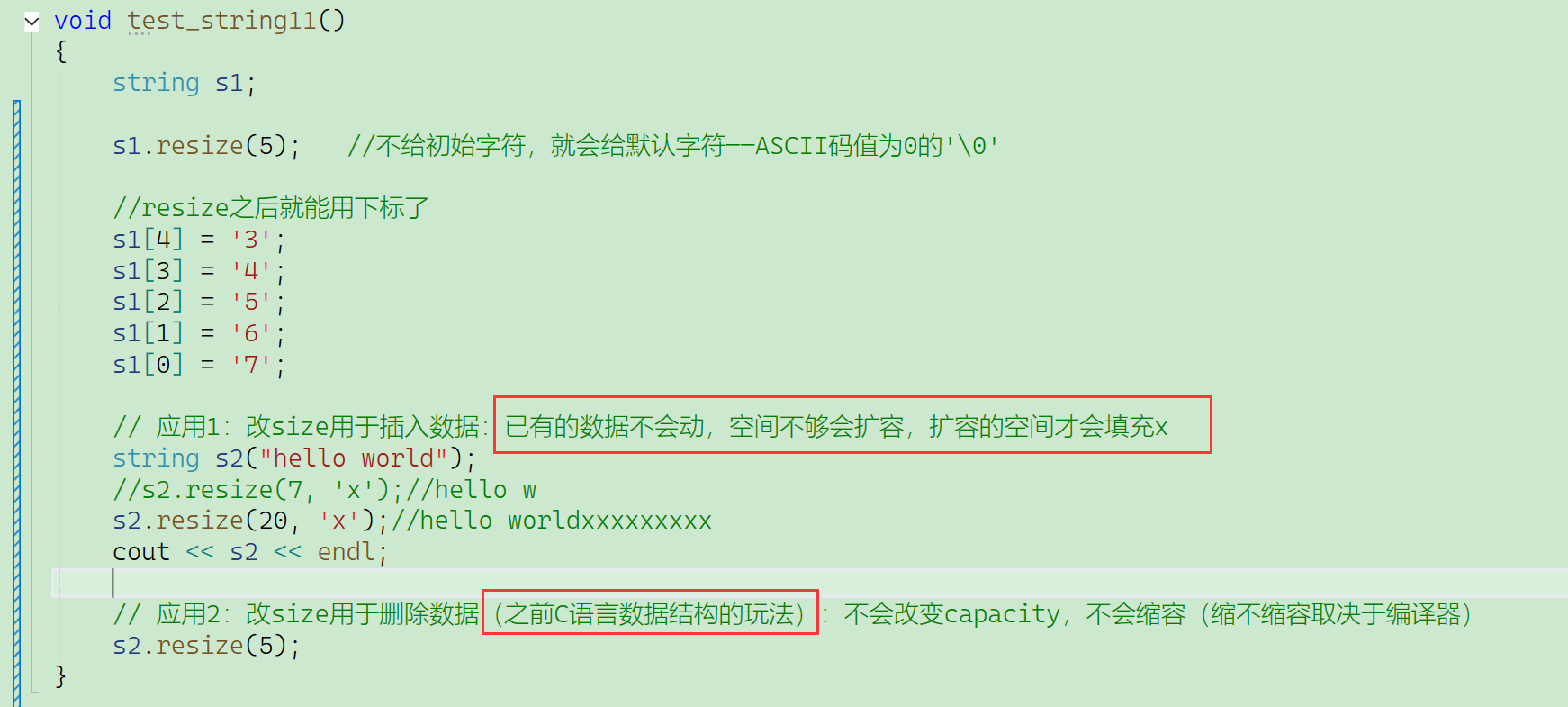
2.2.2.4 shrink_to_fit()
前面提到reserve不用于缩容——C++标准并没有规定:给一个较小值时,reserve是否要缩容。
缩容有专门的函数——shrink_to_fit()。
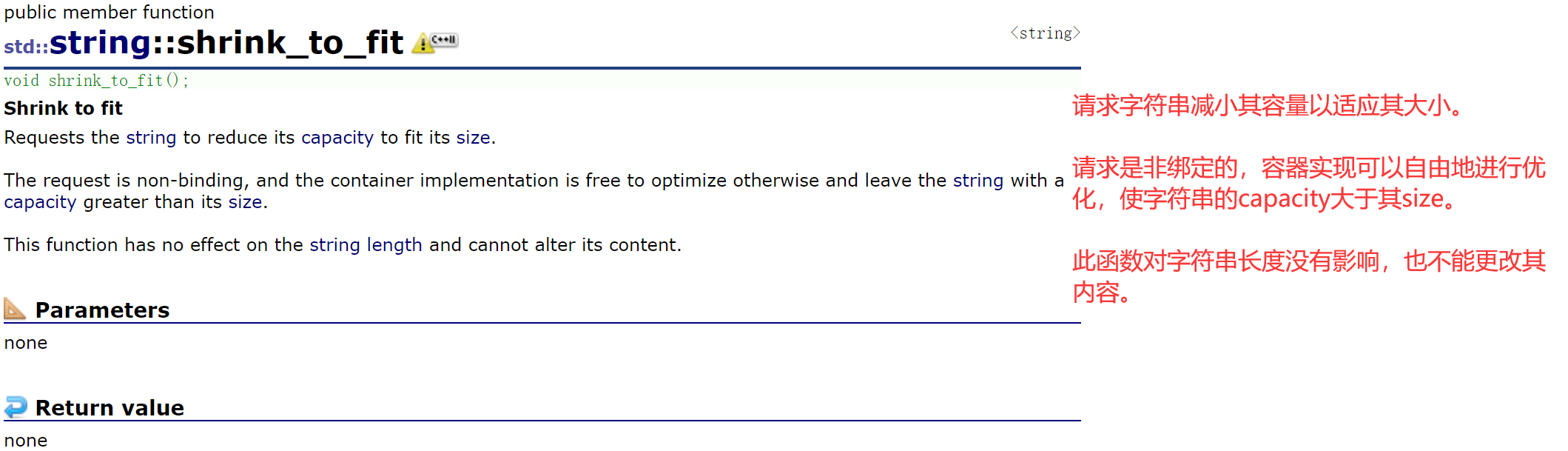
函数功能:让capacity去适应size,一般是让capacity和size保持一致。
使用场景:频繁地对一个容器插入、插入、删除、插入、插入、删除、删除、删除……,然后决定现在数据量不大,空间浪费得有点多,想把空间释放一下,就可以调用这个接口。
不要经常调用这个接口——这个接口效率不高。
缩容不是在原空间上缩——空间不能分段释放!!!
- 实际的缩容不是把多的释放掉,而是开一块更小的空间,拷贝数据,再释放原空间。
所以缩容的本质是以时间换空间。 建议:缩容的消耗很大,不要轻易缩容。
【总结】
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty (重点) | 检测字符串释放为空串,是返回true,否则返回false |
| clear (重点) | 清空有效字符 |
| reserve (重点) | 为字符串预留空间** |
| resize (重点) | 将有效字符的个数该成n个,多出的空间用字符c填充 |
【注意】
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
- clear()只是将string中有效字符清空,不改变底层空间大小。
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
2.2.3 string类对象的访问及遍历操作
2.2.3.1 迭代器
(2)遍历方式2:迭代器
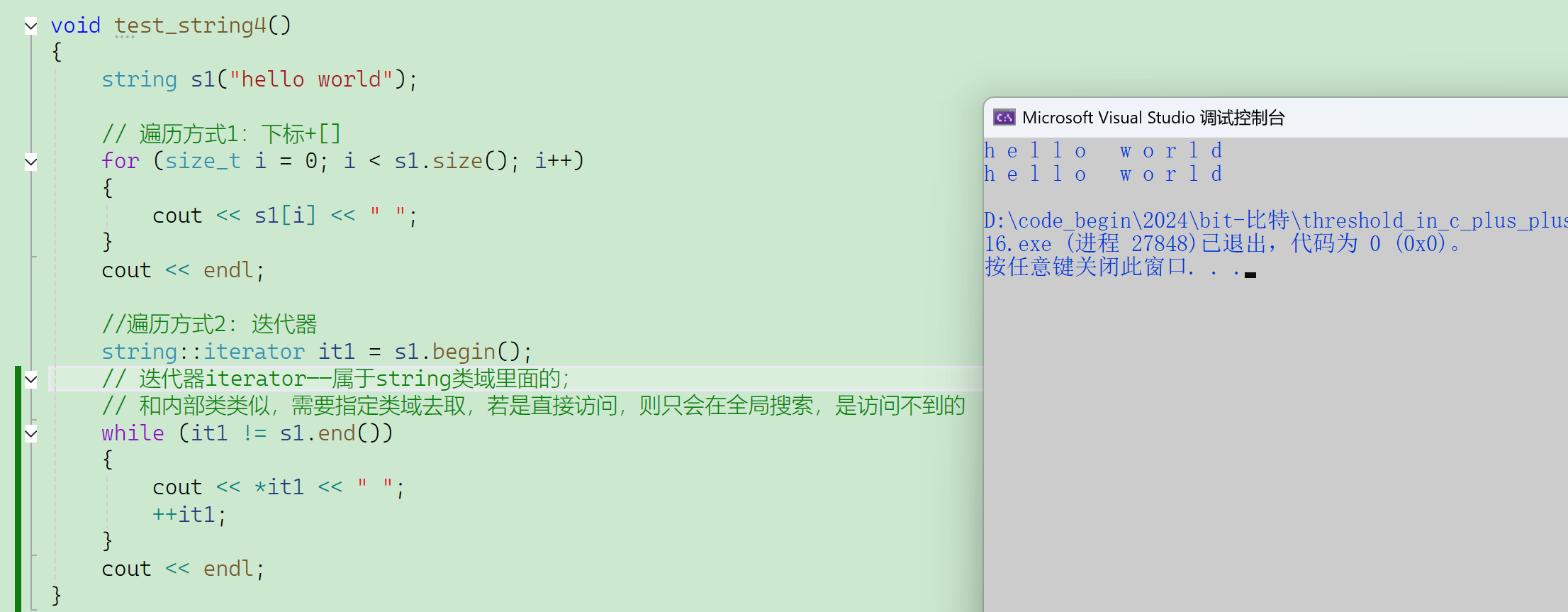
所有的iterator(迭代器)都是定义在类域里面的,受类域限制,使用的时候需要指定类域,有点像内部类,但是实际实现不一定是内部类,是typedef过的。



输出的是解引用的it1。
迭代器的遍历,就类似于指针的遍历,访问的方式——解引用,也和指针类似。
用法上类似于指针,但一定是指针吗???——>不一定,即可能是指针,也可能不是指针。
- 迭代器的底层到底是什么,不同的平台(编译器)实现的是不同的。标准只规定执行规则和执行结果,至于底层怎么实现,不作规定。
就像构造(拷贝构造)+构造的优化,C++标准没说要不要优化,按原生语法应该全都要走,但是效率确实有点低,只要你能保证优化之后不出问题,优化不优化最终程序的结果应该是一致的,优化达到的效果不影响程序的正确性。
像VS下就不是指针,而是一个类_string_iterator,后面套了一些东西。
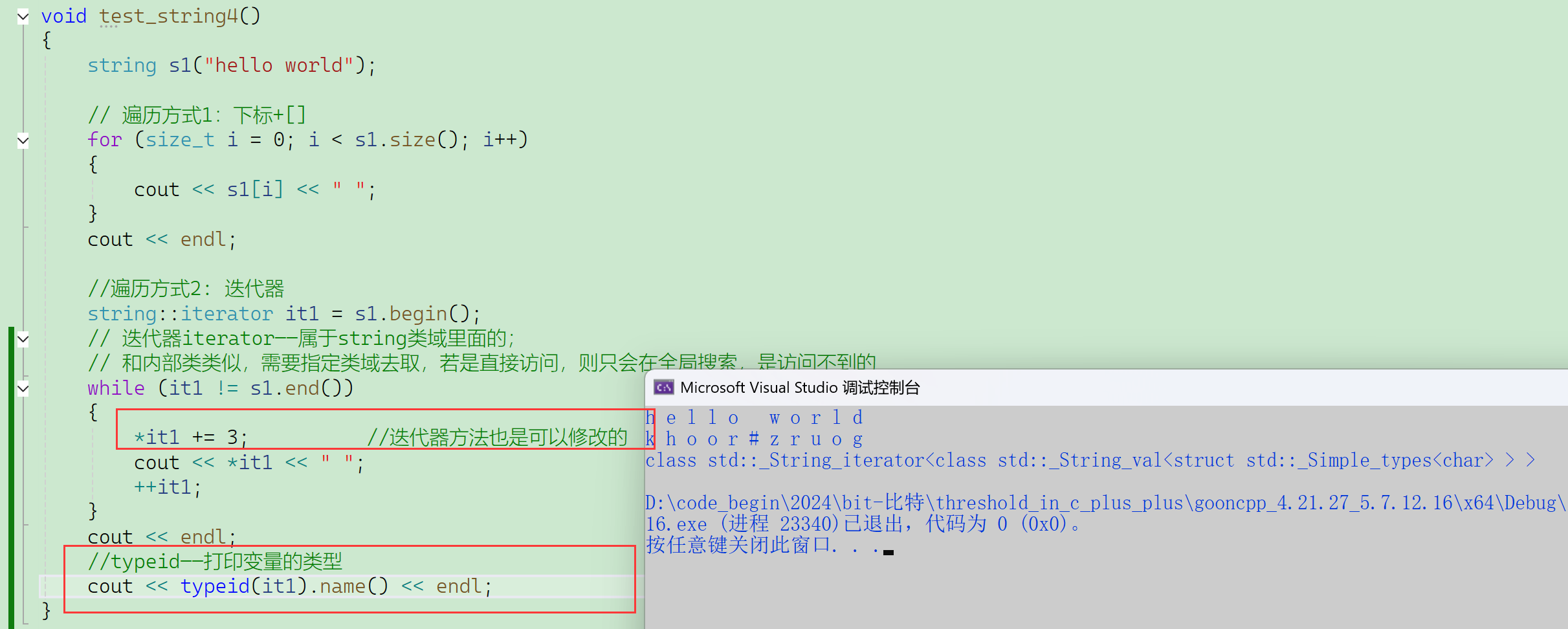
行为上像指针,但底层不一定是指针。
typeid既可以打印对象的类型,也可以打印类型的原类型——有些类型被typedef过。
linux下使用typeid需要包含头文件<typeinfo>,VS下不用——间接地包含了。

不同编译器,针对同一个对象的大小、类型可能都不同。
这是比较新版的g++,有些旧版的g++打印出来可能会是char*。
可以简单解释一下VS2019(X86)下的28——和正常的顺序表没什么差异,只是多了一个16字节数组。
string有:
- 1个char*指针;
- 2个int变量(size,capacity)
- 1个16字节数组(buf数组)
总共是28 = 12 + 16,当字符串较小就存到16字节数组,较大就存到堆上。

VS2022的x86也是28,x64是40。
讨论:两种方式都可修改,下标+【】还更方便,那有下标+【】的形式遍历,为什么还要设计迭代器??
解答:只能说是因为——下标+【】不是主流(通用)的访问方式。

数据结构这块都得写成类模版,不然写了之后只支持一种数据类型。
写成类模版想存什么数据,就给什么——链表就是一个类模版。
- 下标+【】的方式:要求底层是连续的物理空间——数组。
- 只有string、vector支持这种方式。
- 所有的迭代器都支持迭代器遍历。

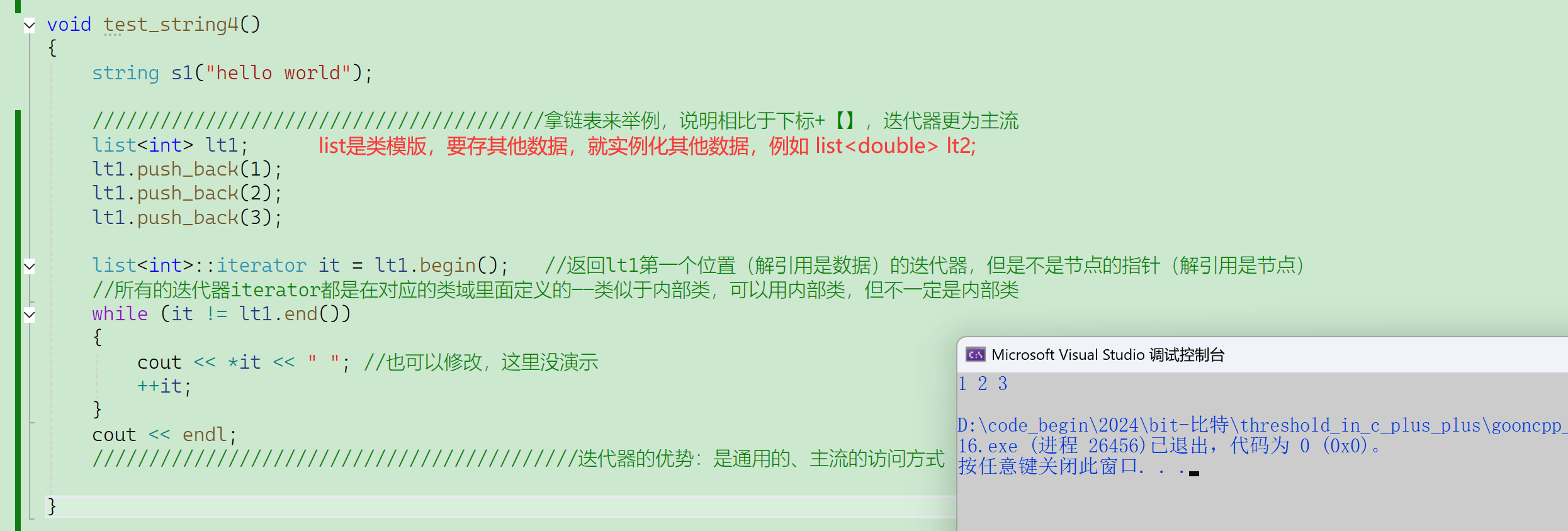


(3)遍历方式3:范围for
所有容器都支持这种遍历方式。
范围for是C++11从其他语言抄的,C++11里面有一些小语法比较好用,提前把范围for这个语法讲一下,以后再统一讲C++11里面的其他语法。
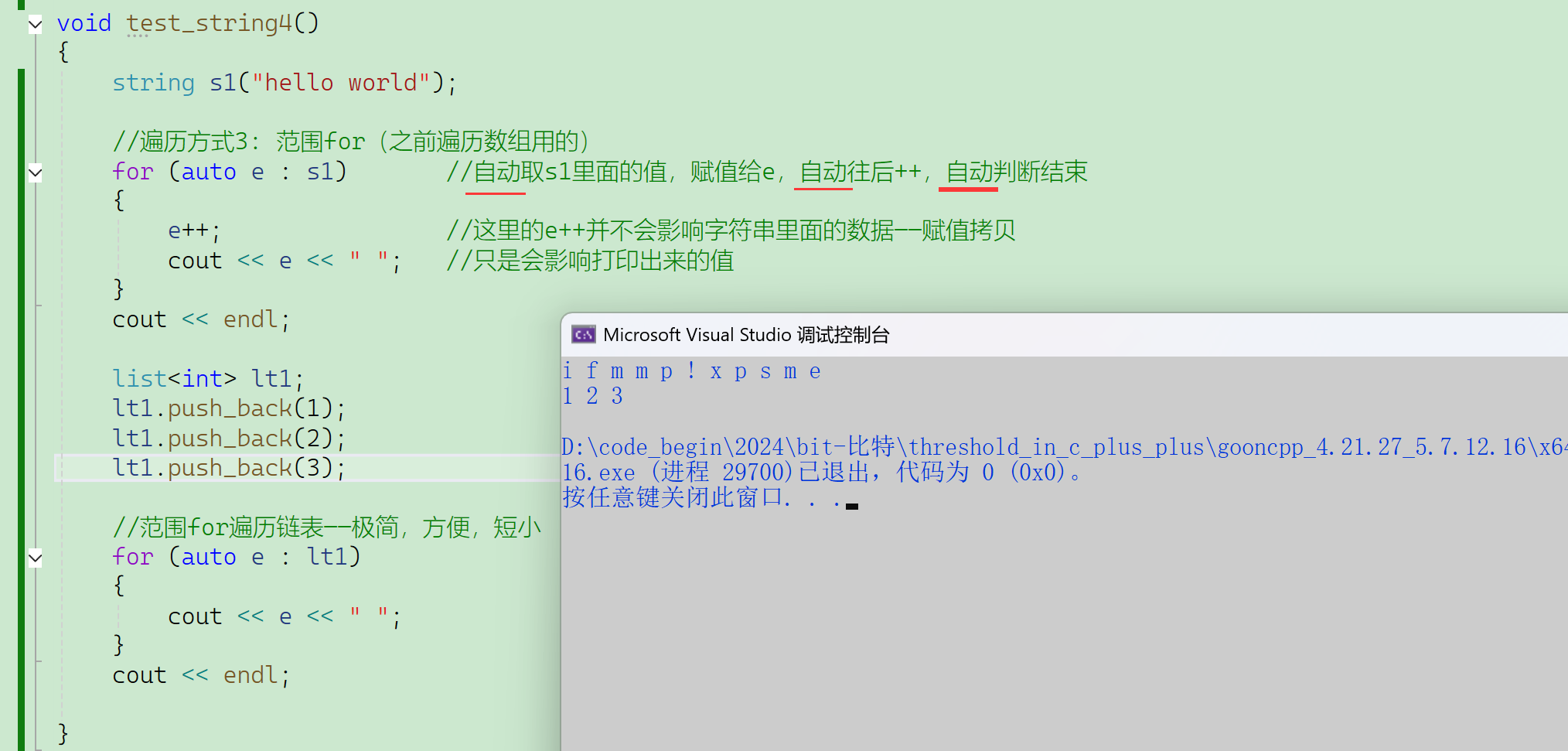
使用范围for,自动化程度极高。
- 为什么所有容器都支持呢,原因就是范围for的底层其实就是迭代器。

所有的“自动”都是编译器帮你干了你该干的活。
范围for看起来全自动很优越,很神秘,但是对编译器而言,这两段代码在底层翻译成指令之后是一样的,跟模版int、double、……替代T一样,在实际语法编译之前,在预处理的时候被替换成上面那段,迭代器每次的it2解引用给e,即e=*it2。
自动++其实是迭代器自动++,自动判断结束其实是迭代器自动判断结束。
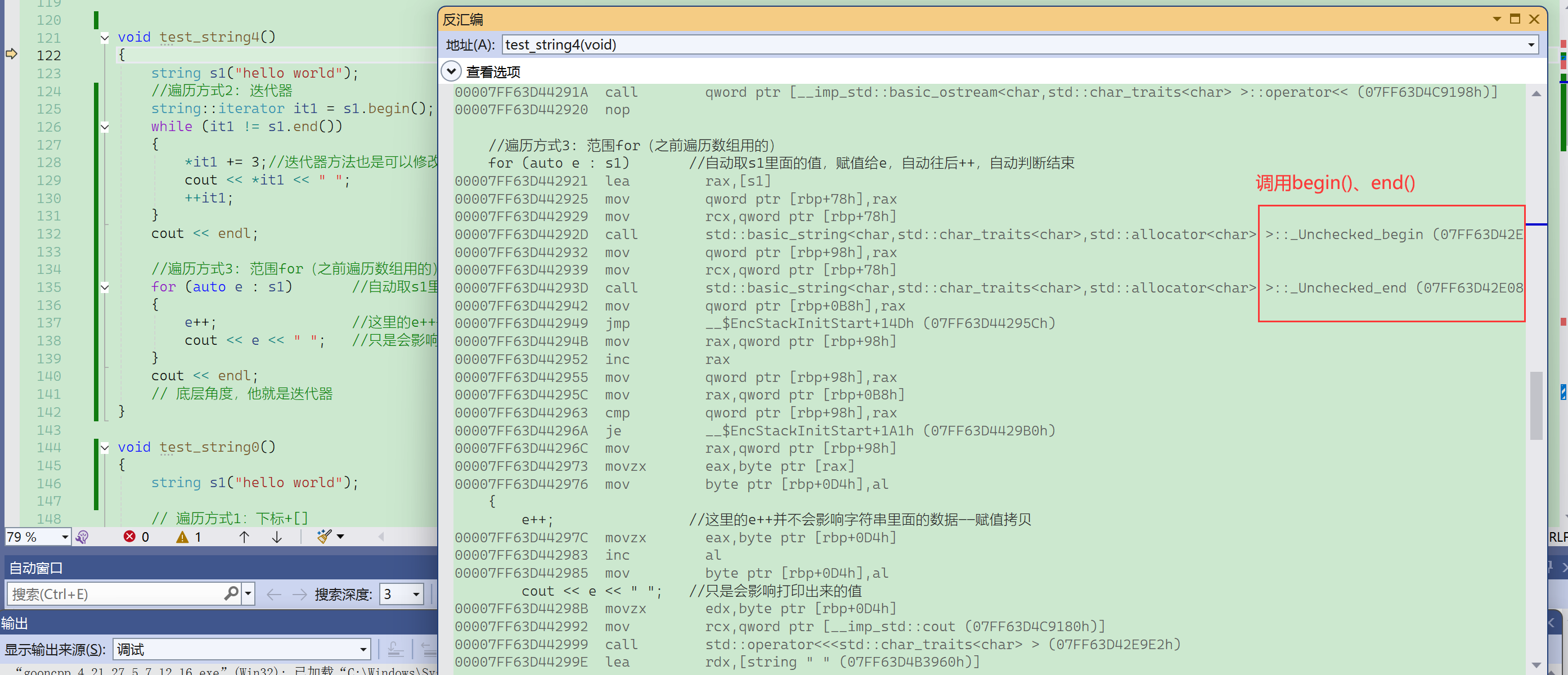
【范围for的引用】
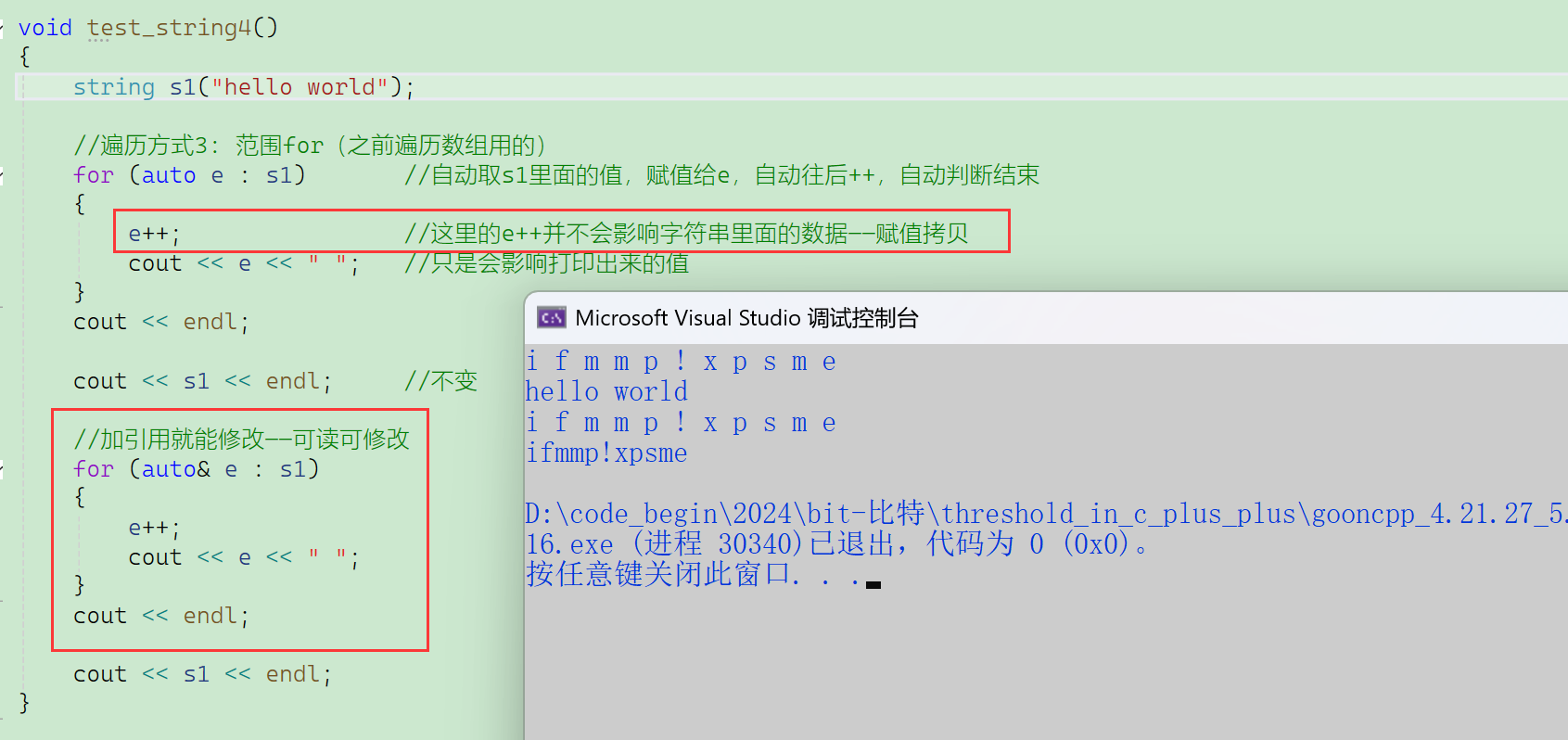
范围for就是直直地替换,不仅能替换库里面的,自己实现的STL的拓展也能替换。
遇到范围for,编译器就去看有没有实现好的迭代器,有就调用迭代器,没有就报语法错误。
从语法层来看,学了3种字符串的遍历方式,从底层来看是两种:下标+[]、迭代器。
迭代器就学完了第一部分,简单使用。
2.2.3.2 const-迭代器
再来看到迭代器的其他内容
【const 迭代器】
string的迭代器也实现了两个版本:
- 普通迭代器:普通对象用;
- const迭代器:const对象用;

s1是const,所以会调用下面这个begin(),返回值是const_iterator,不是iterator。
用iterator接收,编译器就会报错。
迭代器分为const_iterator和iterator,区别就是一个只读,一个是可读可写。
- const iterator——保护迭代器本身不能写/修改;
- const_iterator——保护迭代器指向的数据不能写/修改;
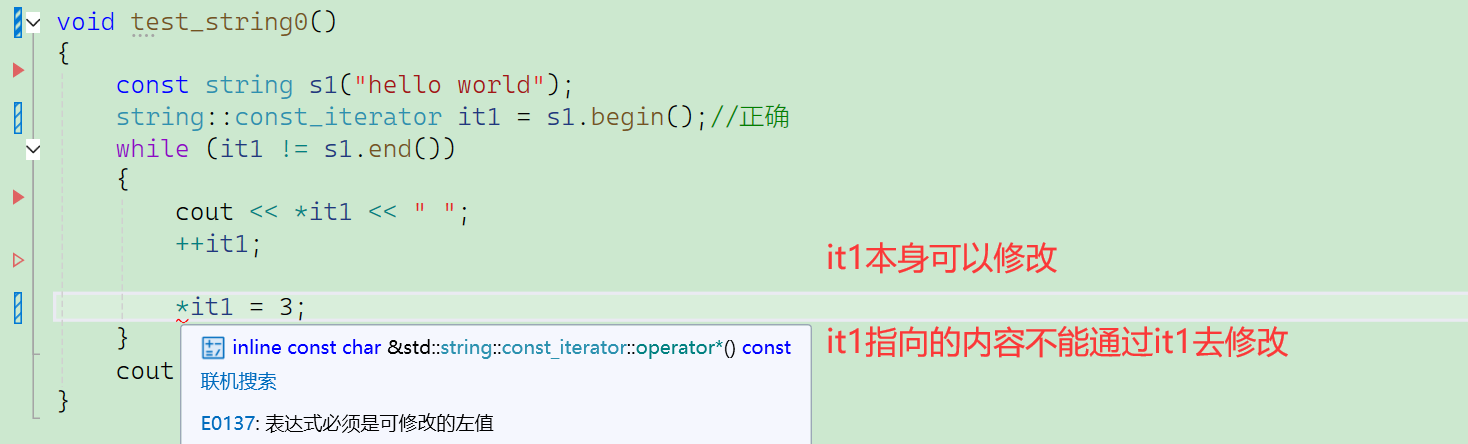
it1本身可以修改,确保it1可以迭代往后走。
string是类模版,而模版这部分的一个缺陷就是编译报错会复杂很多:
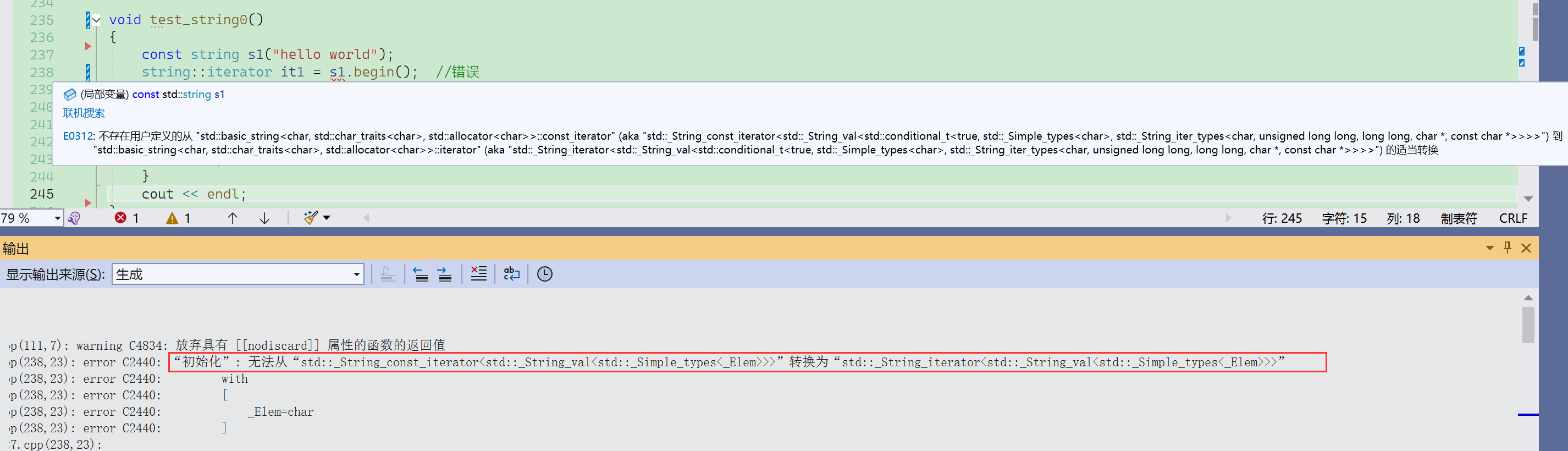
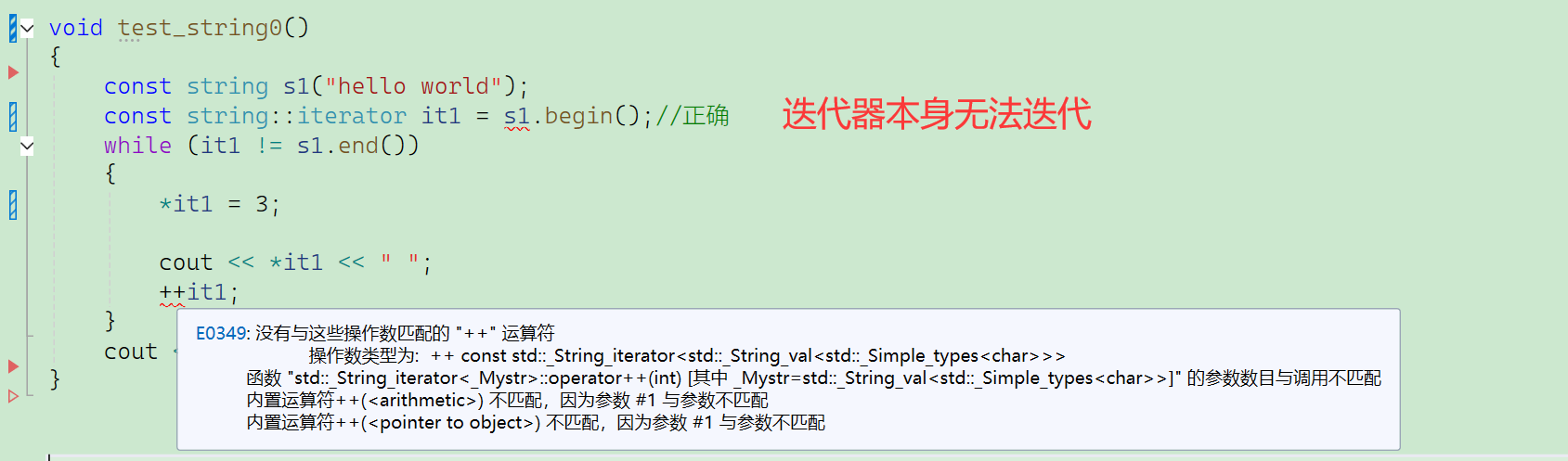
正确用法:
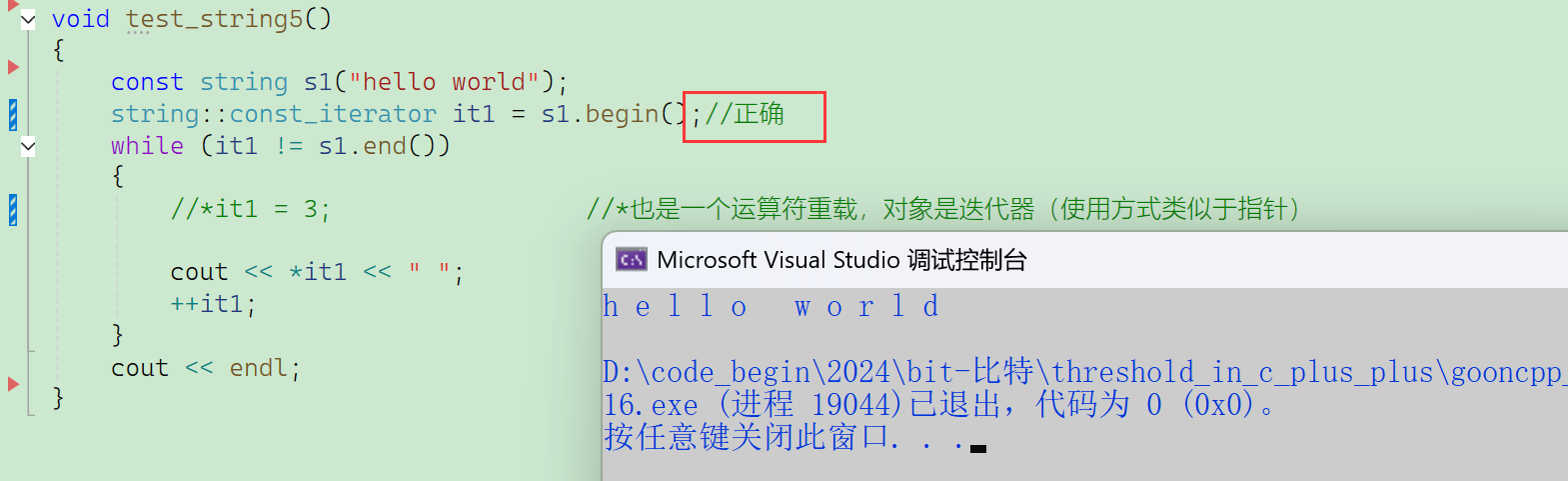
可以遍历const的string对象,但是不能修改数据。
【最好的写法】——auto
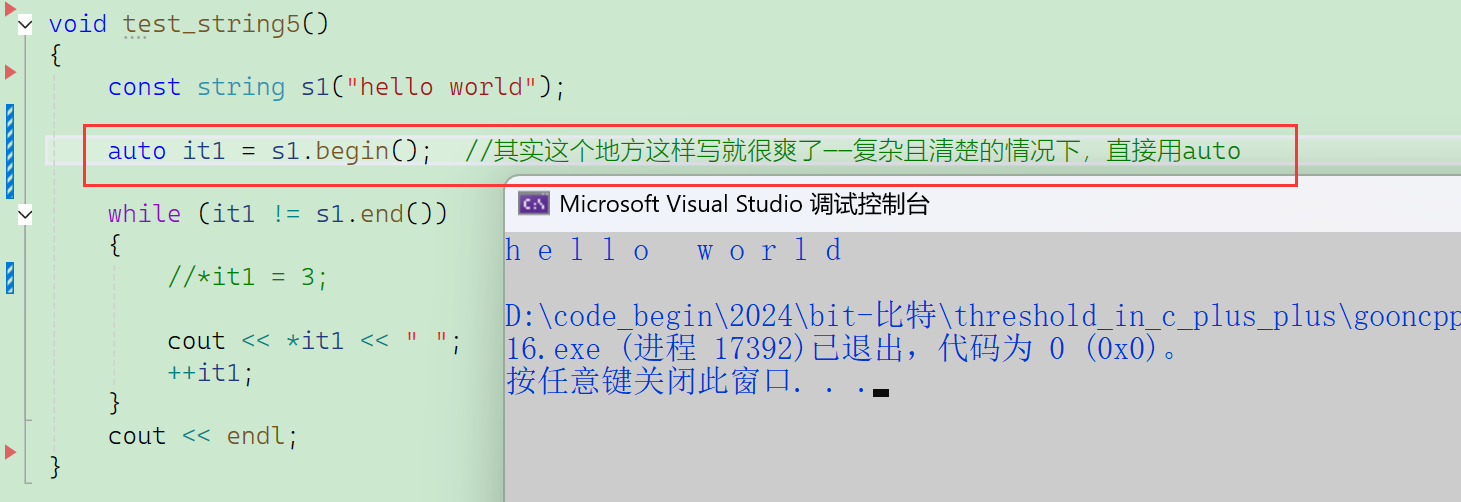
- const对象,调用const的begin,返回的是const_iterator。
【小技巧】
- VS下把鼠标放在变量、函数上,就能知道 它的类型/返回值类型;
【切记】
- 在清楚的情况下使用auto。
2.2.3.3 反向迭代器
除了:
- 普通迭代器begin/end;
- const迭代器begin/end;
还有:
- 反向迭代器rbegin/rend;
- 普通版;
- const版;
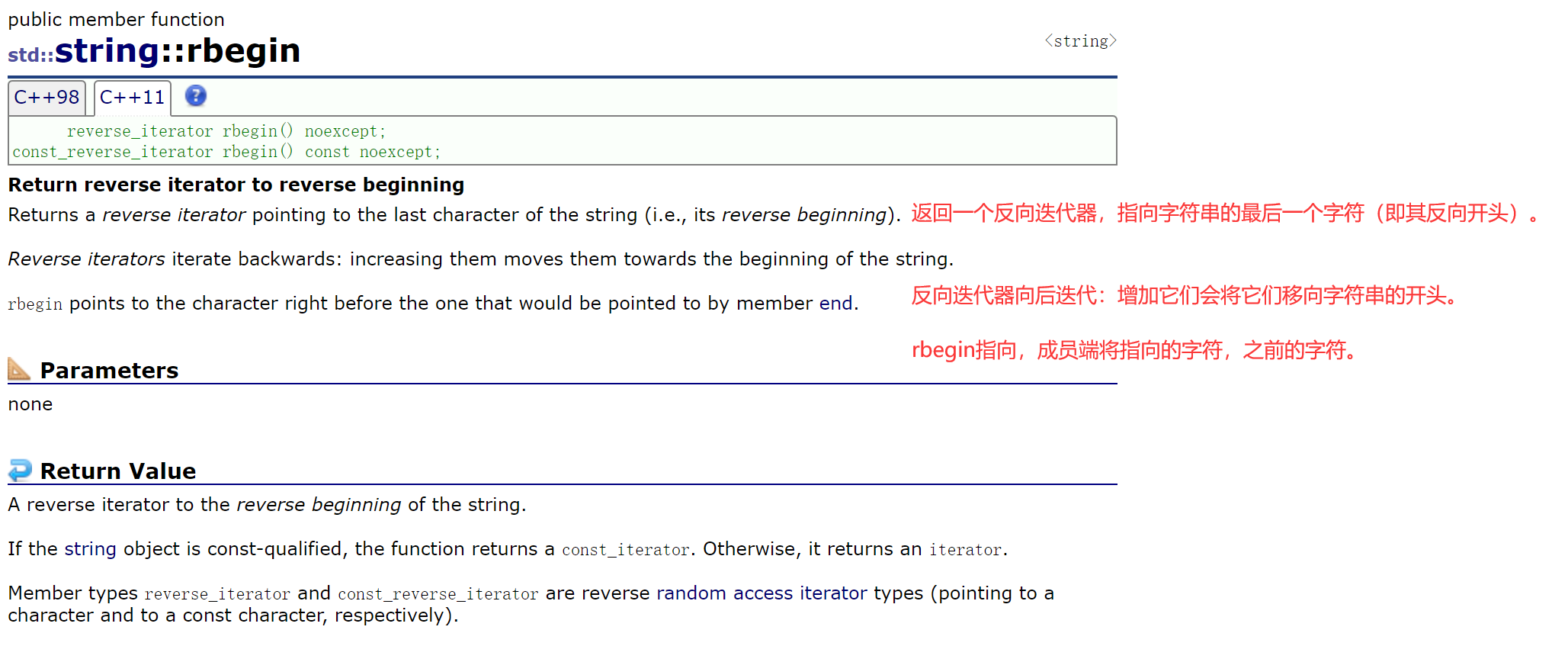
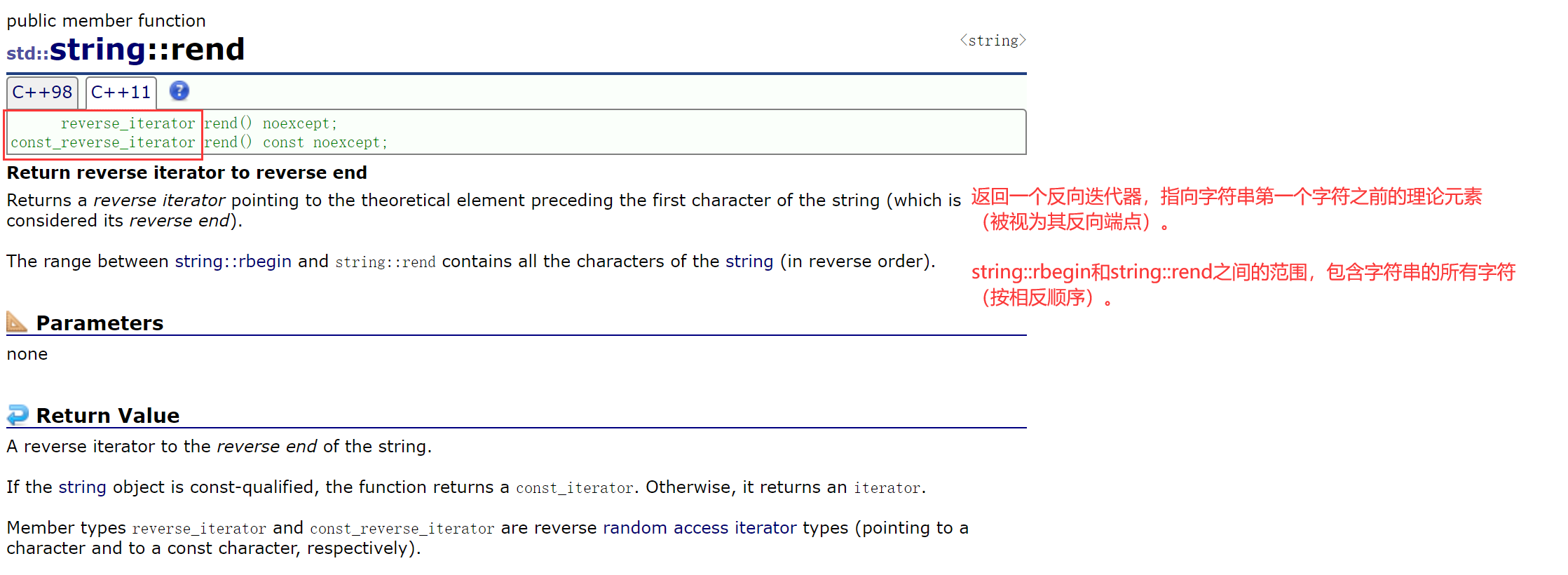
iterator就是从头到尾遍历,假如想倒着遍历,
就使用rbegin、rend,返回的是反向迭代器reverse_iterator。
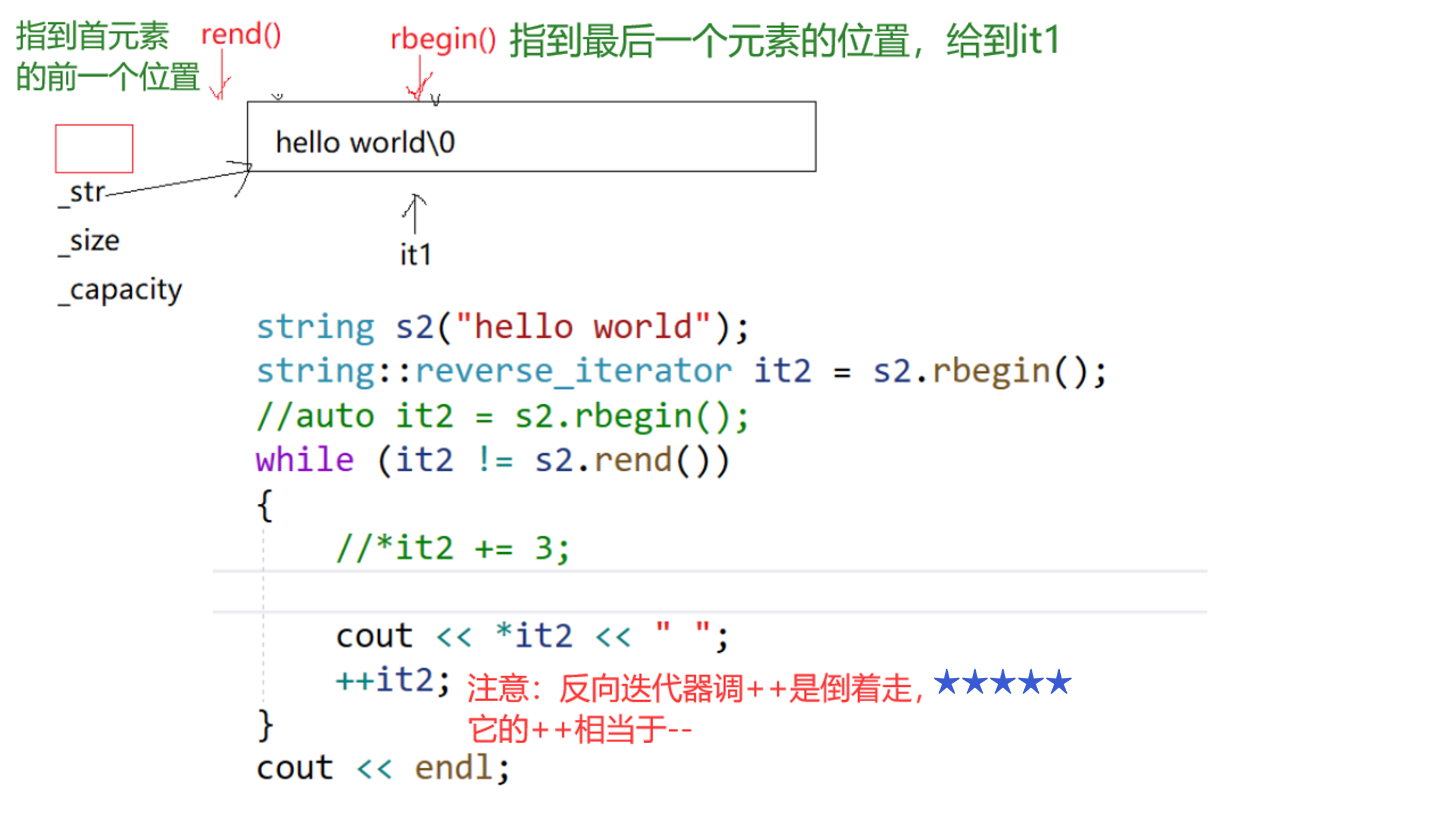
【反向迭代器】
- 位置是反的;
- ++的方向也是反的;(重载++,封装的--,反向迭代器是使用适配器模式实现的)
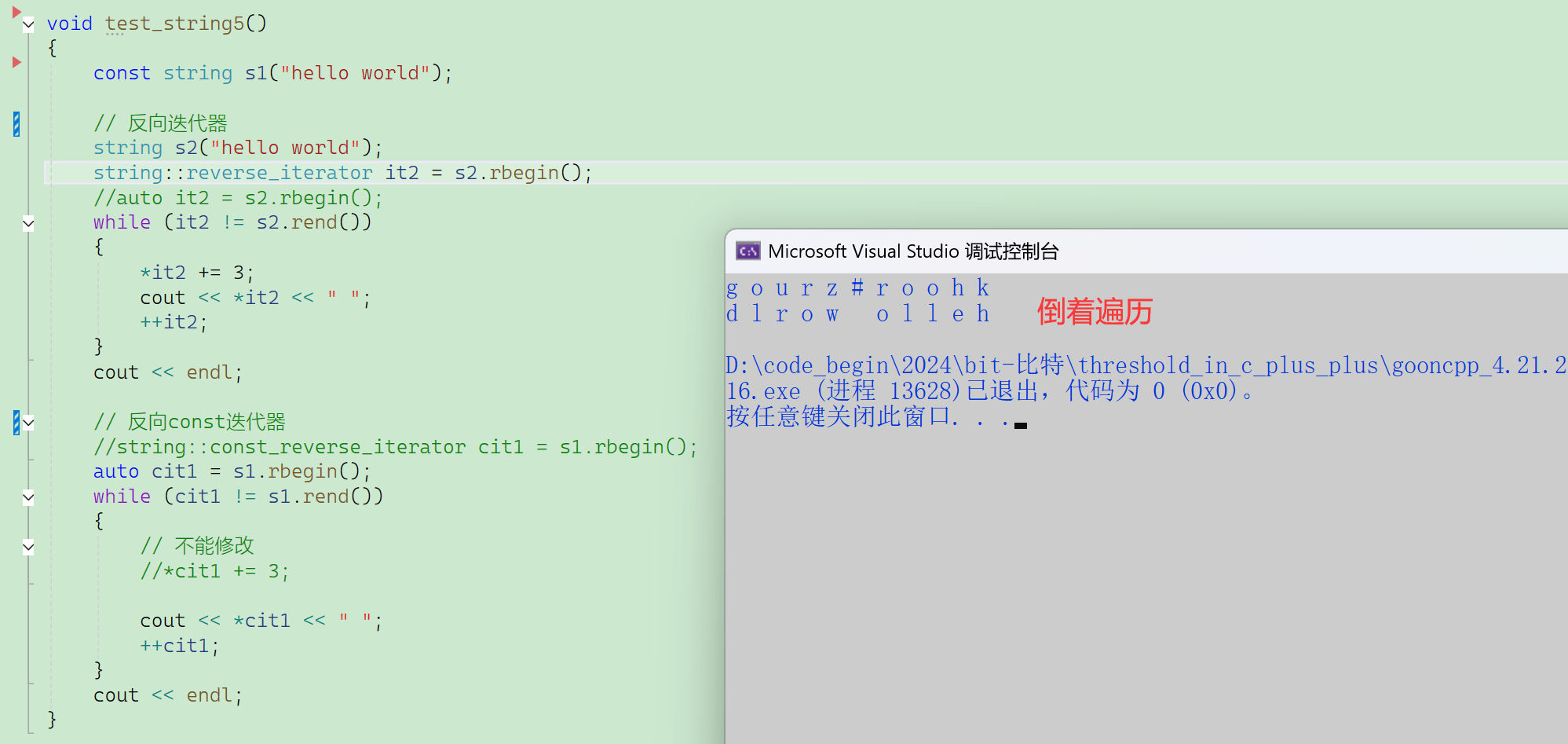
总结:严格来说,这里的迭代器总共有4种
- iterator(最常用)
- const_iterator
- reverse_iterator
- const_reverse_iterator
实际:string不爱用迭代器,无论正向反向迭代器,下标+【】都能完成,而且更方便。
2.2.3.4 c-迭代器
迭代器就讲到这,实际上还有一些迭代器——C-系列(设计冗余)

迭代器讲了这么多,总结一下: string不爱用迭代器的用法。
但是从学习的角度要学得细一点,需要掌握好, 因为后面通用遍历方式还是迭代器。
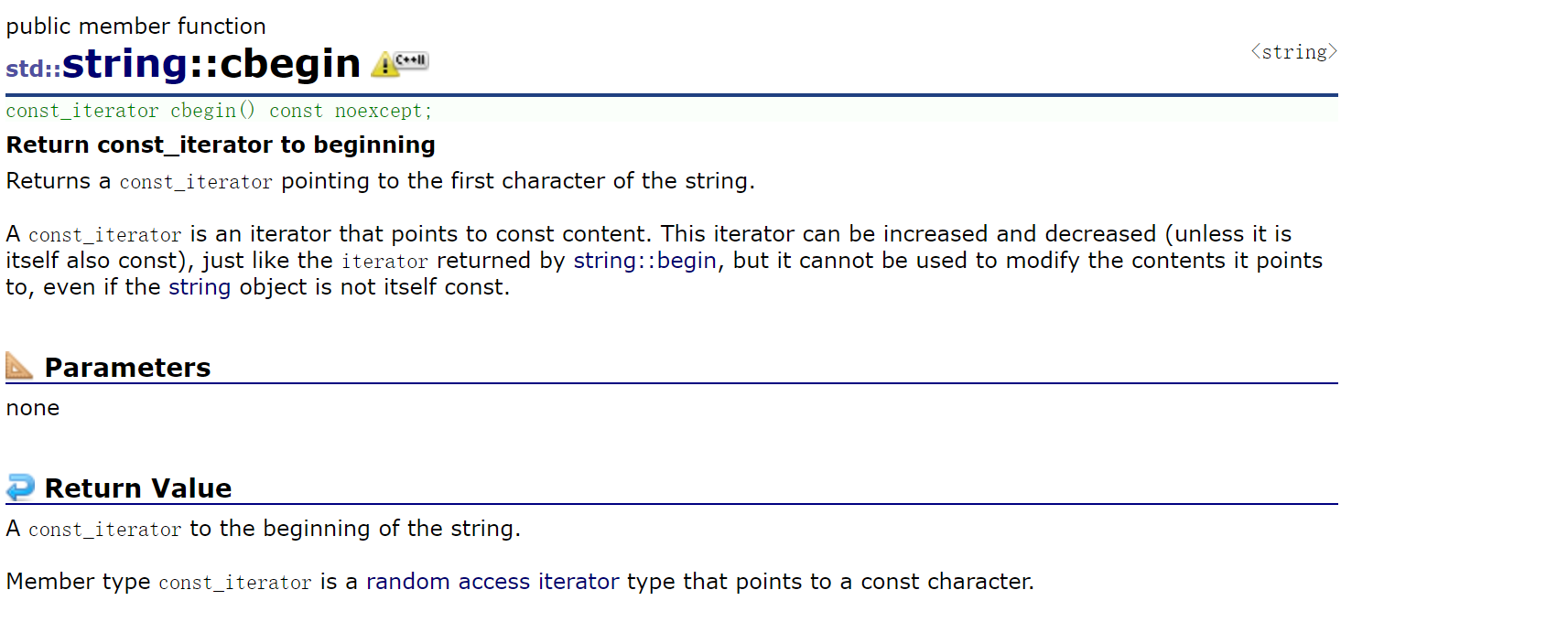
实际上就是想把begin的第2个重载——const版本,给独立出来。
cbegin相当于begin的const版本。
是C++11增加的,意在形成区分,不想混着用,但是很多人用惯了之前的用法,不爱用新函数。
之前讲string的遍历,相比于迭代器,更倾向于使用下标+【】。
那迭代器有没有下标+【】替代不了的功能呢???——有,例如:排序。
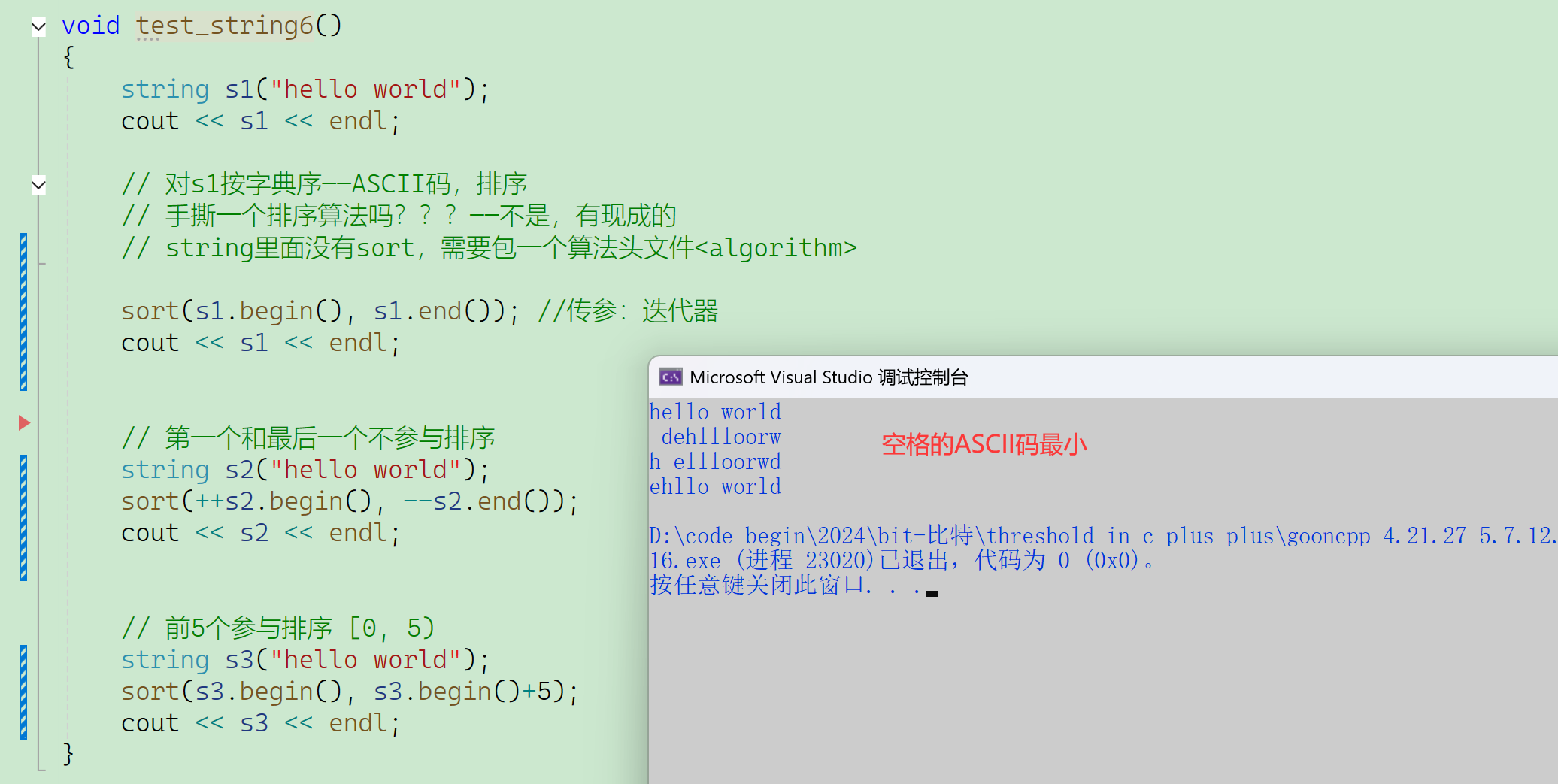
sort对字符串的迭代器,按字典序、升序进行排序。
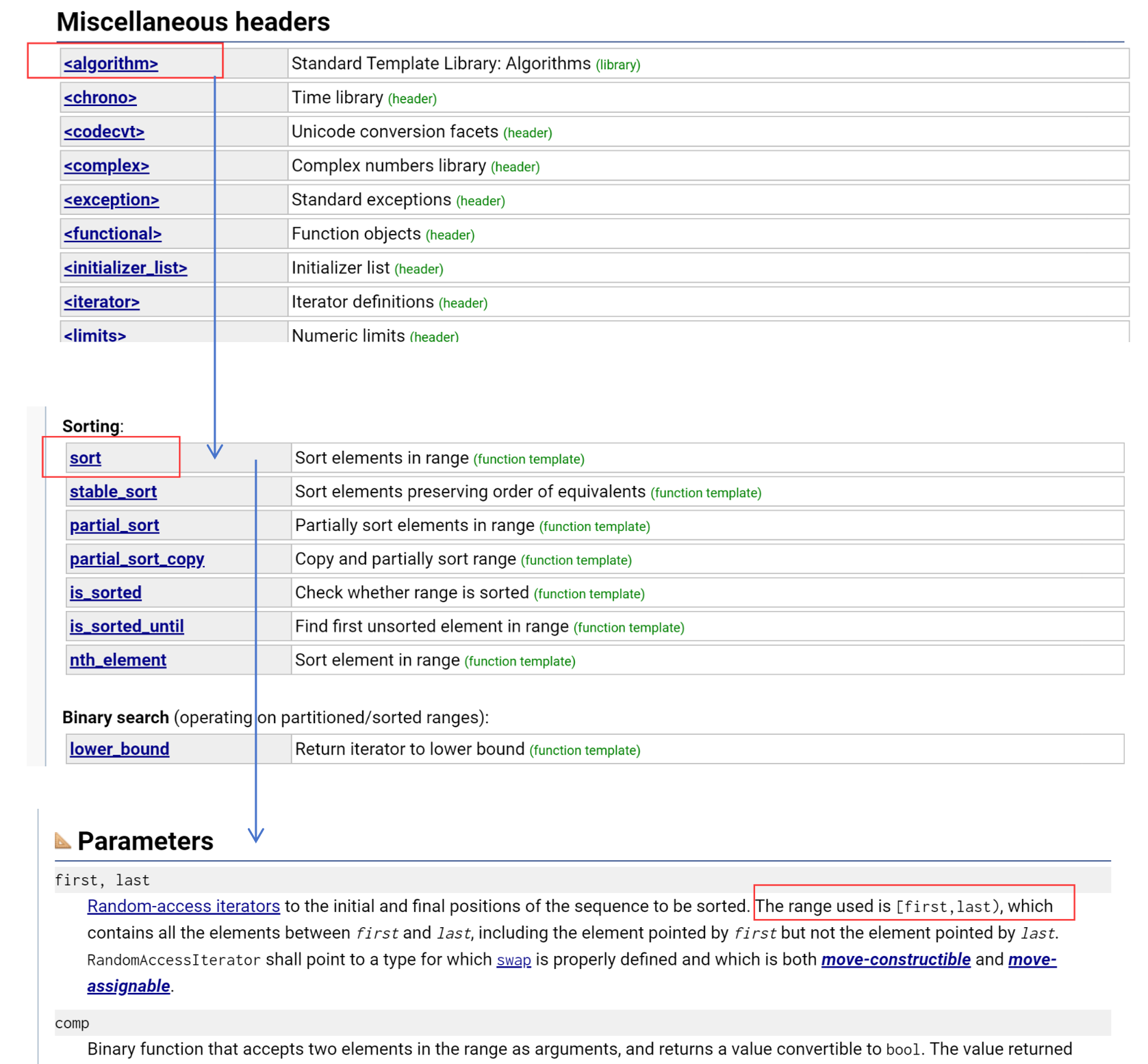

我们去访问容器:借助迭代器。
算法去访问容器:借助迭代器。
- C++的迭代区间一定是左闭右开[ , )。
sort的第一个迭代器参数:是一个闭区间位置,指向一个有效位置。
sort的第二个迭代器参数:是一个开区间位置——即不作为本次算法的有效位置。
sort的优点:
- 是函数模版,可以支持各种类型的数据结构——string、vector(list不行)
- 传的是区间,就很灵活,可以对整个数据进行处理,也可以对部分数据进行处理
2.2.3.5 at
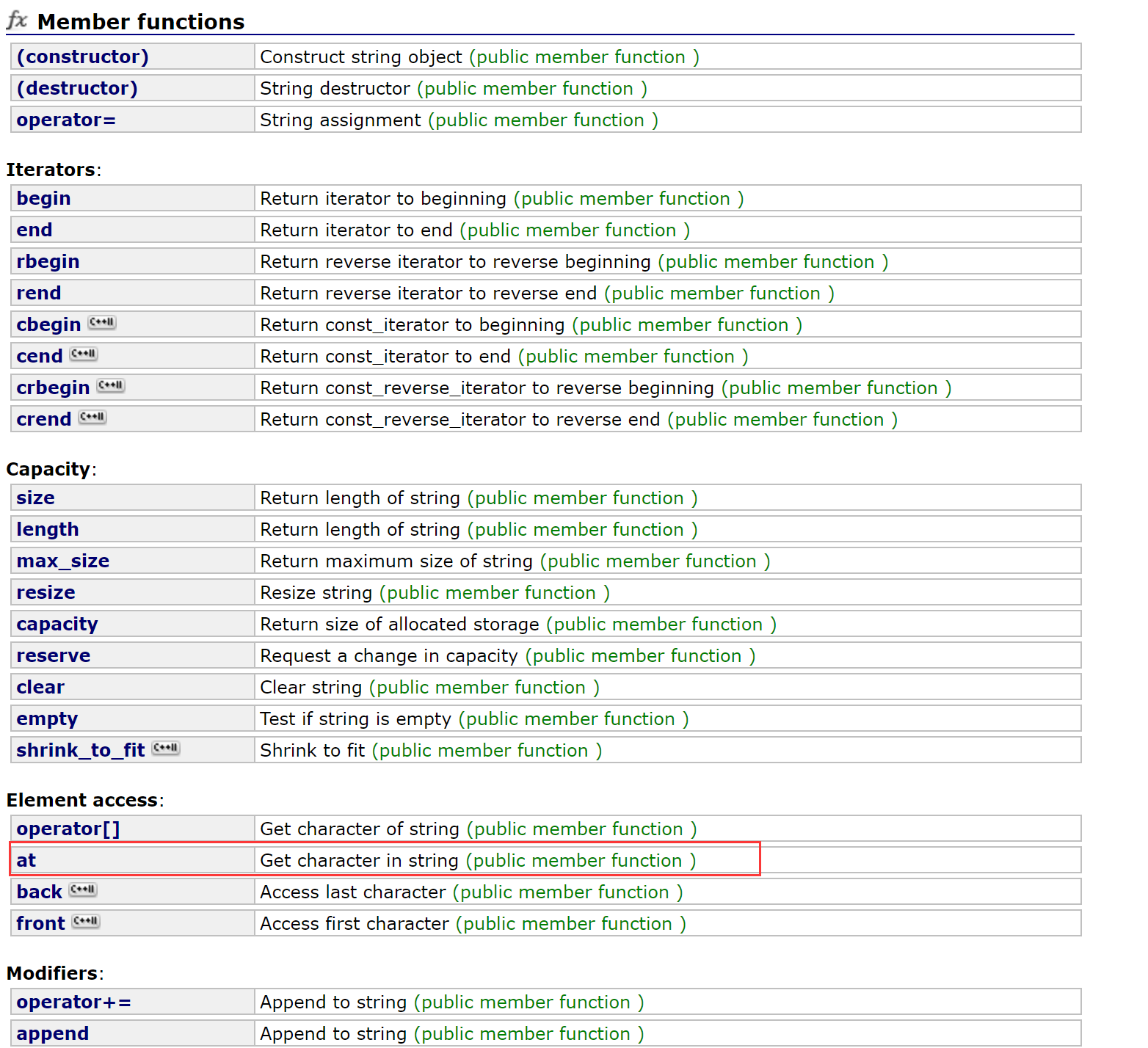
at可以访问pos位置的字符。

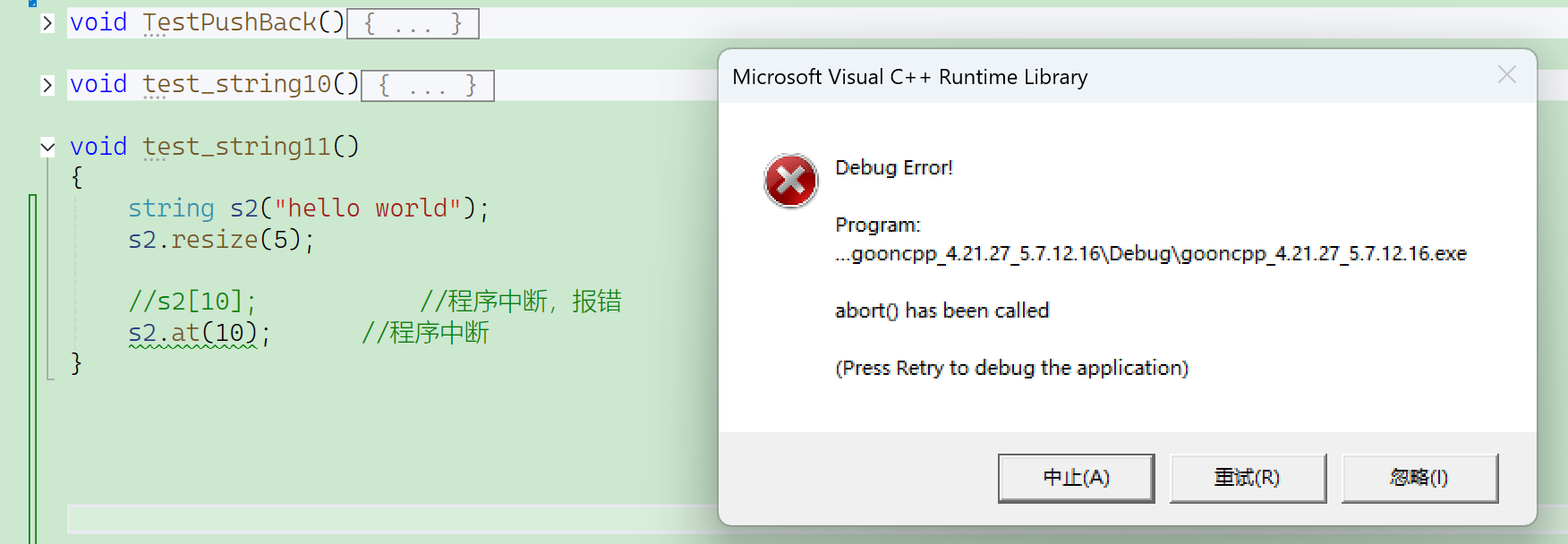
at和[ ]的区别:
- []是暴力检查,一旦越界访问,程序就直接中断并报错——断言;
- at是抛异常;
功能是一样的,只是底层处理越界的方式不同。
第2种方式的优势在于可以捕获异常。
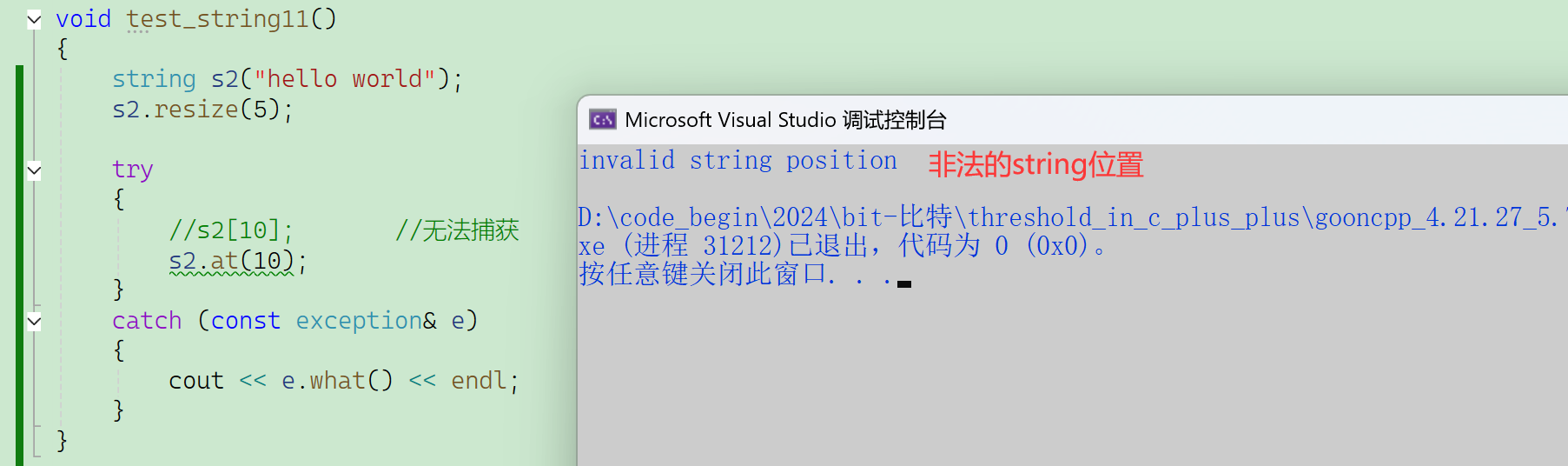
2.2.3.6 front和back
功能:访问首、尾元素。
[ ]和at也能访问首尾元素。
str[0];
str.at(str.size()-1);【总结】
| 函数名称 | 功能说明 |
| operator[](重点) | 返回pos位置的字符,const string类对象调用 |
| begin + end | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| rbegin + rend | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
2.2.4 string类对象的修改操作
接下来看字符串修改。
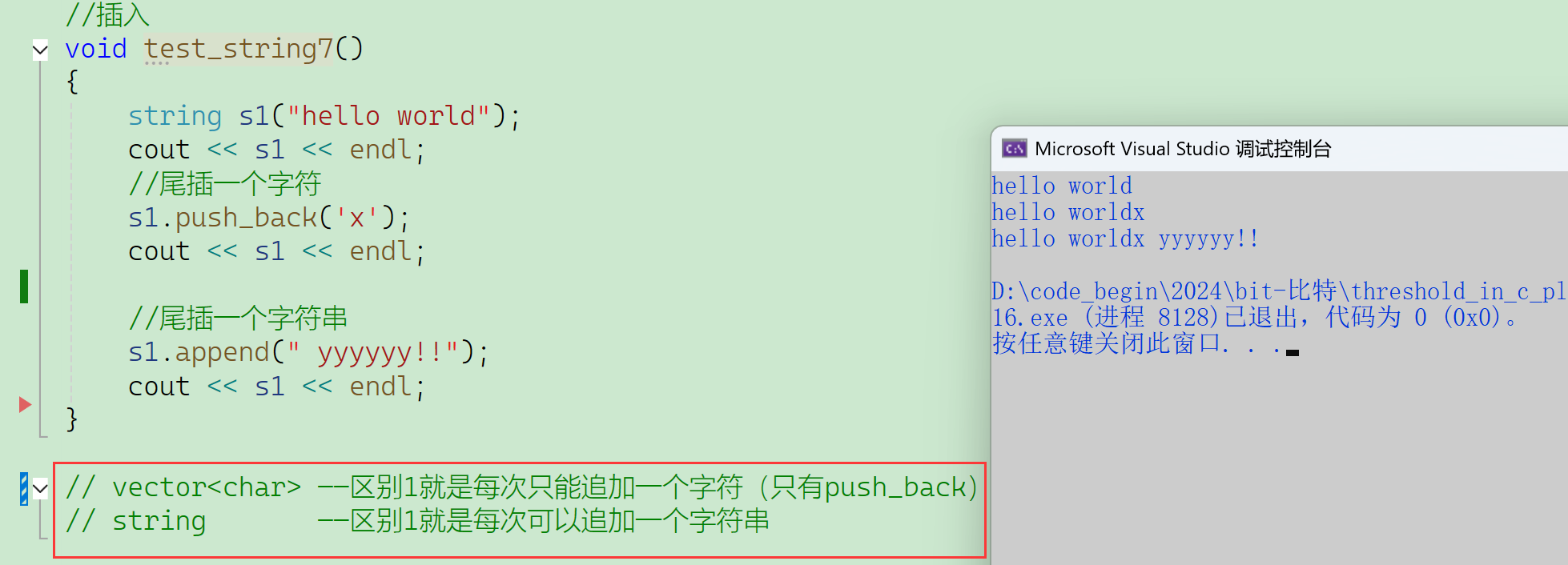
2.2.4.1 push_back()
第一种修改:插入——3个函数。
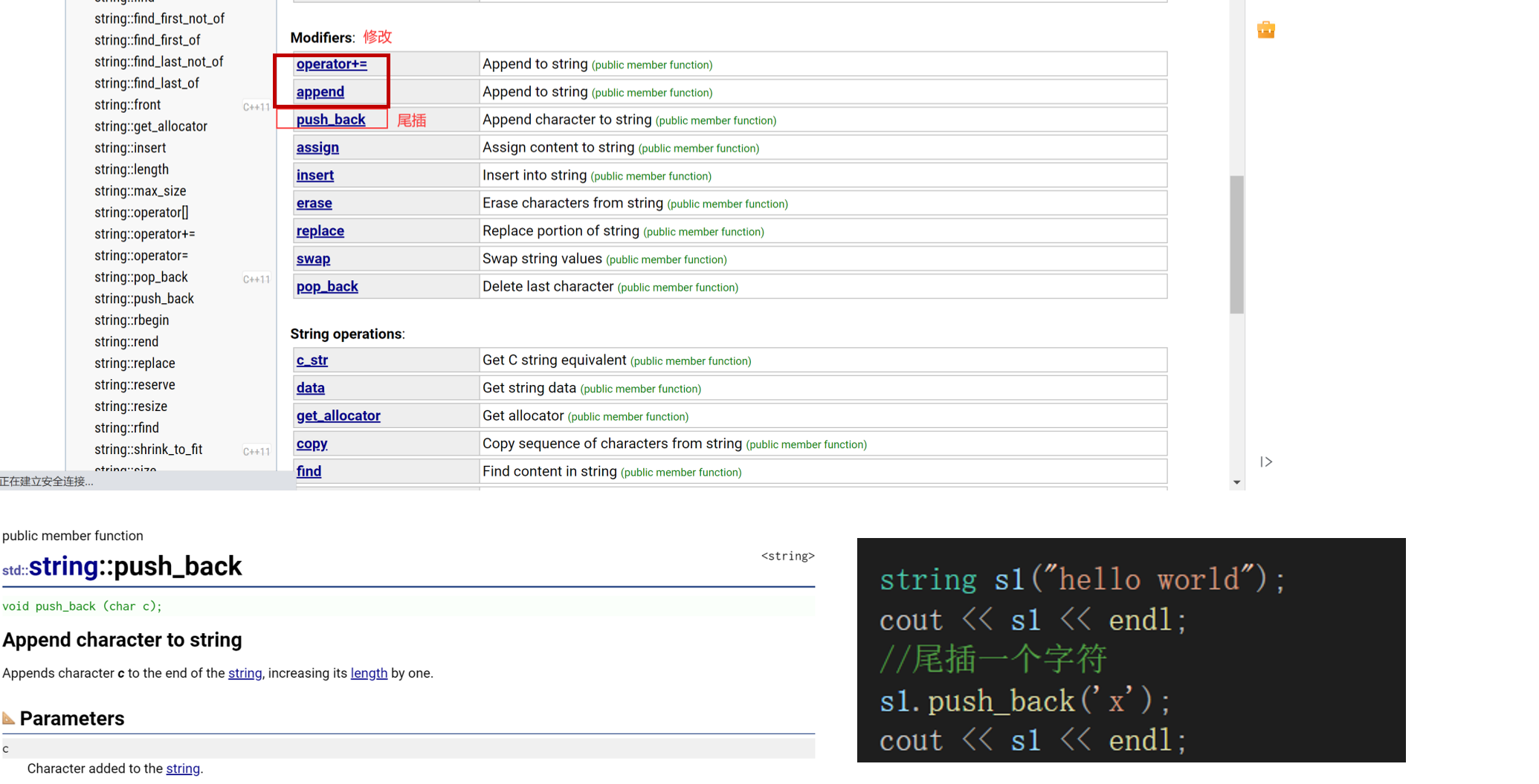
2.2.4.2 append()
为什么说string设计得比较挫,没有什么经验呢,从这个地方就能看出来:
插入有push_back——尾插一个字符。
还有append(追加)——不仅能追加一个字符,还能追加一个字符串。
append设计得很复杂——和string的构造设计得很相似。

代码练习:
2.2.4.3 +=重载(重点)
实际上,push_back和append都不喜欢用,最常用的还是+=的重载。
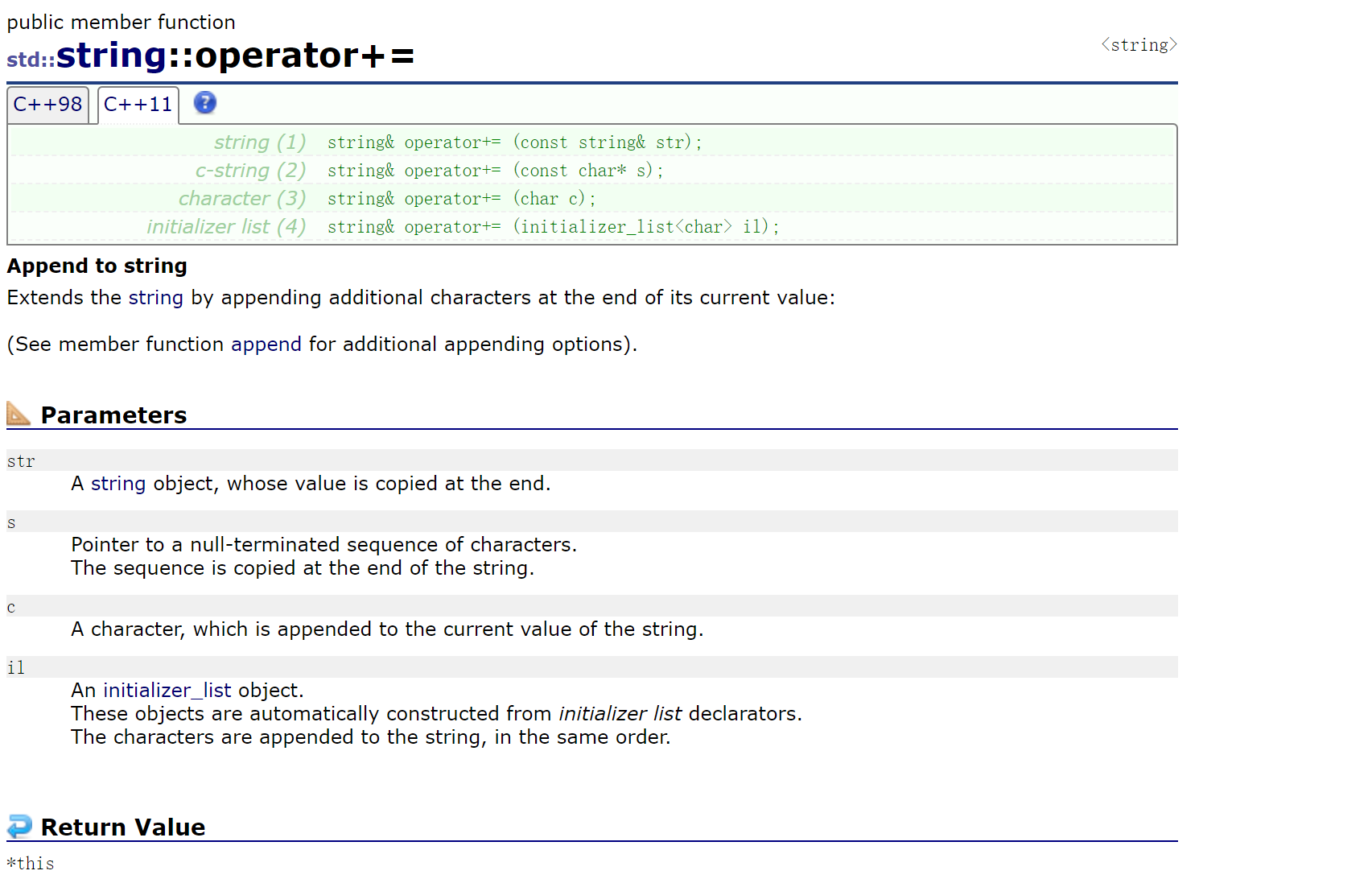
重载哪些运算符是看实际需求,+=重载就比较好用了。
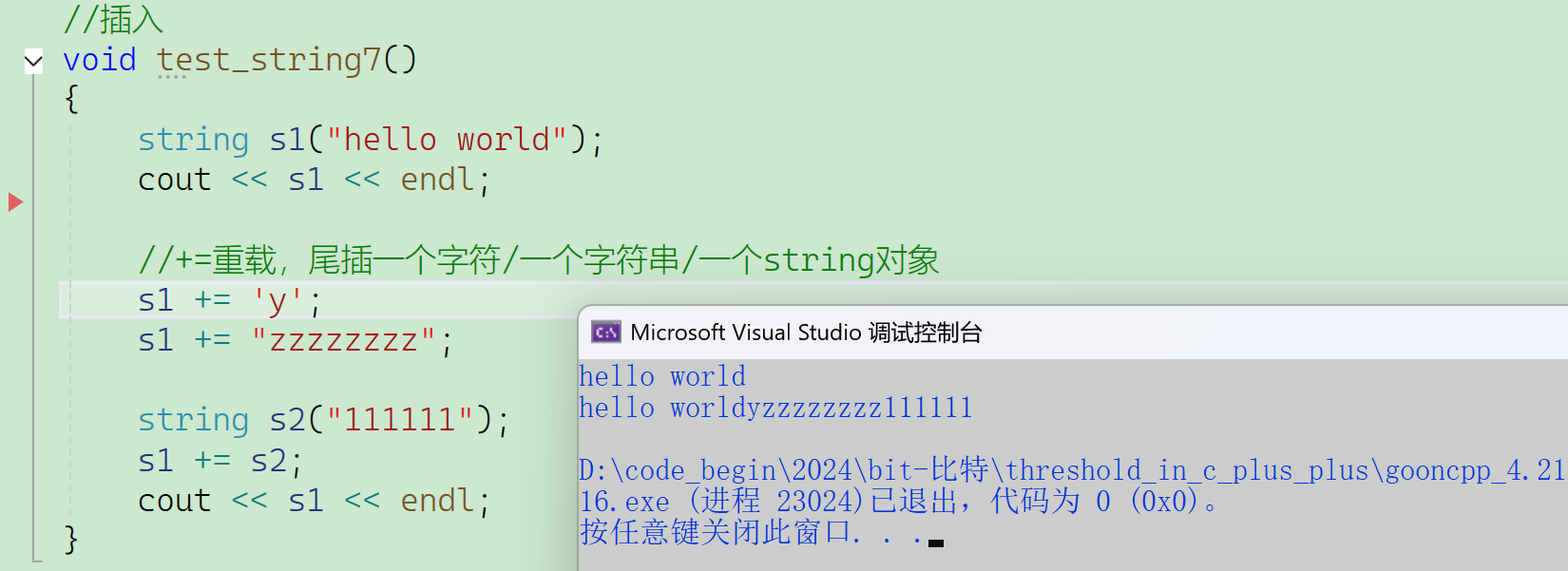
注:没有-=的重载。
2.2.4.4 pop_back()、erase()
尾删pop_back,删除一个字符,就不太好用了。
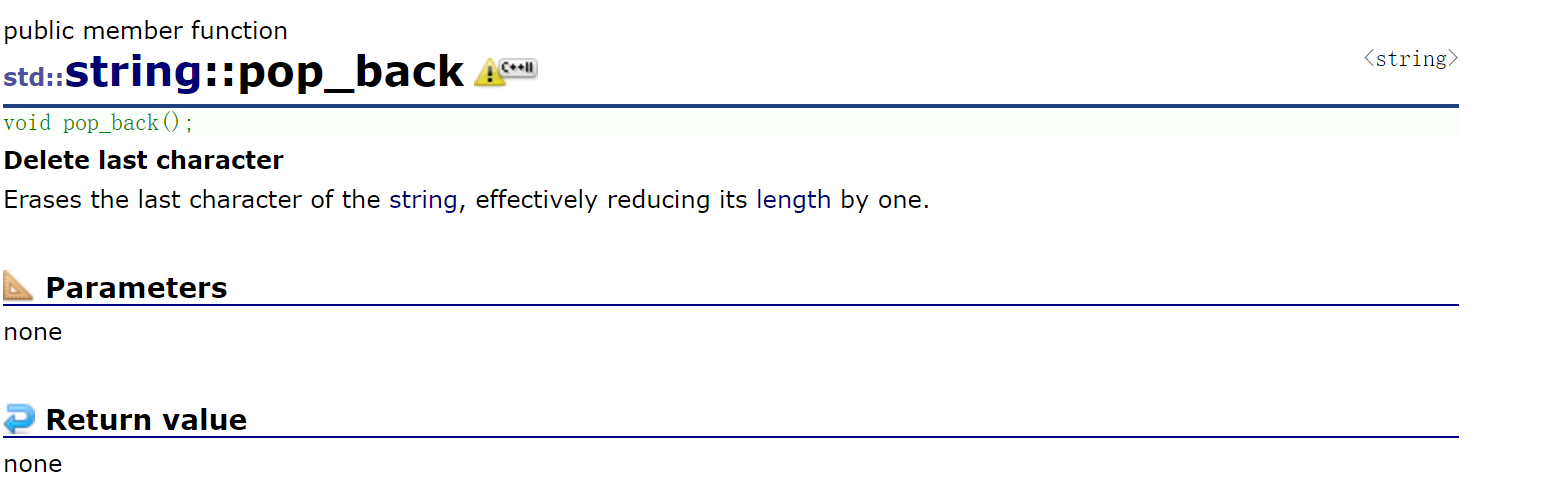
erase可以从一个位置开始删除一段。
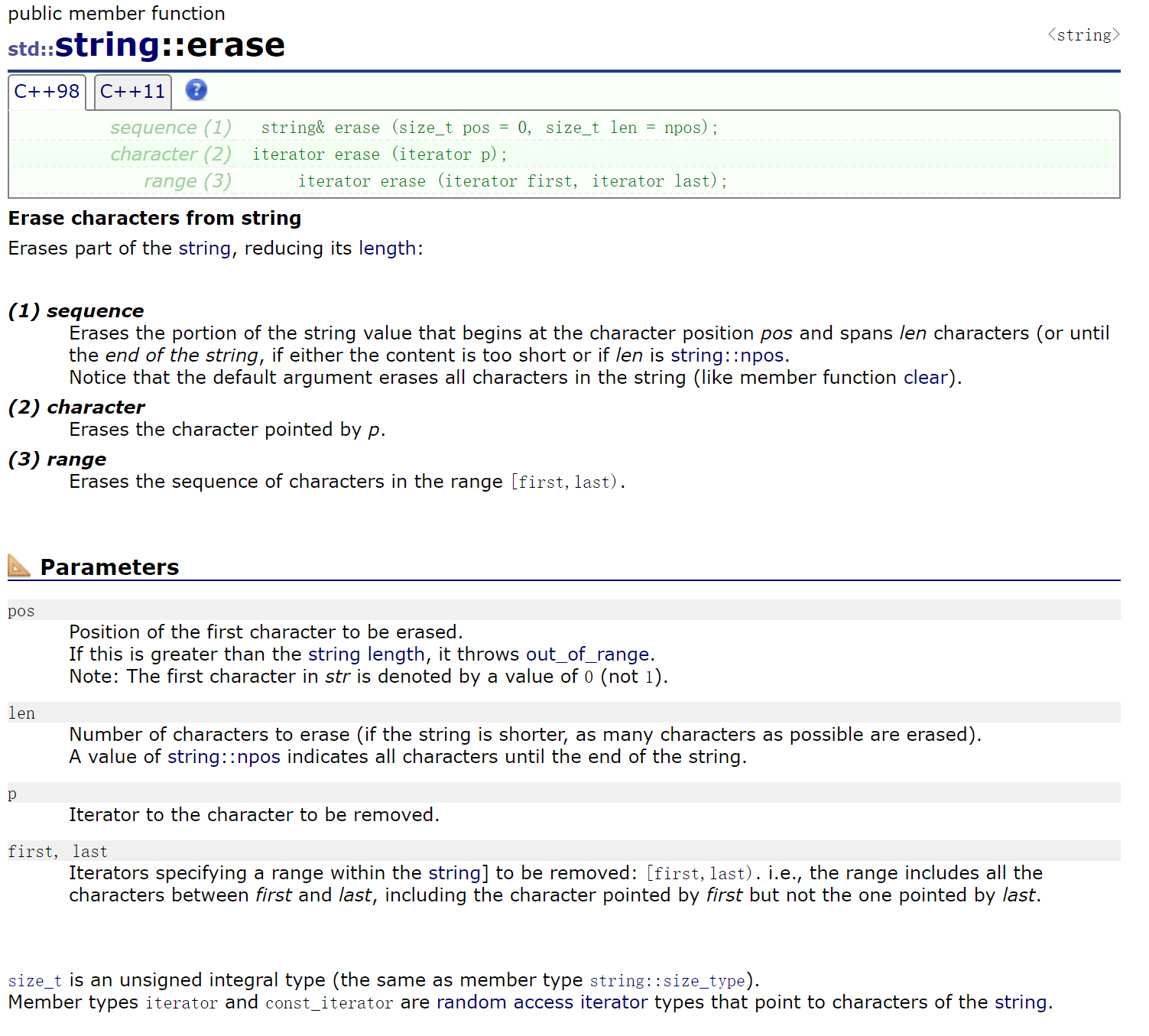
(1)删除pos位置开始的len个字符——直接调用erase(),使用缺省参数,全部删完。
(2)删除迭代器位置的1个字符。
(3)删除迭代区间内的字符。

之前写数据结构删除用erase不用delete,就是跟着STL库走的。
2.2.4.5 assign()、insert()
再来看看modifiers里面的其他函数。

assign本质是一种变相的赋值:清空当前的内容,填入新的内容。
但是已经有默认成员函数operator=了。
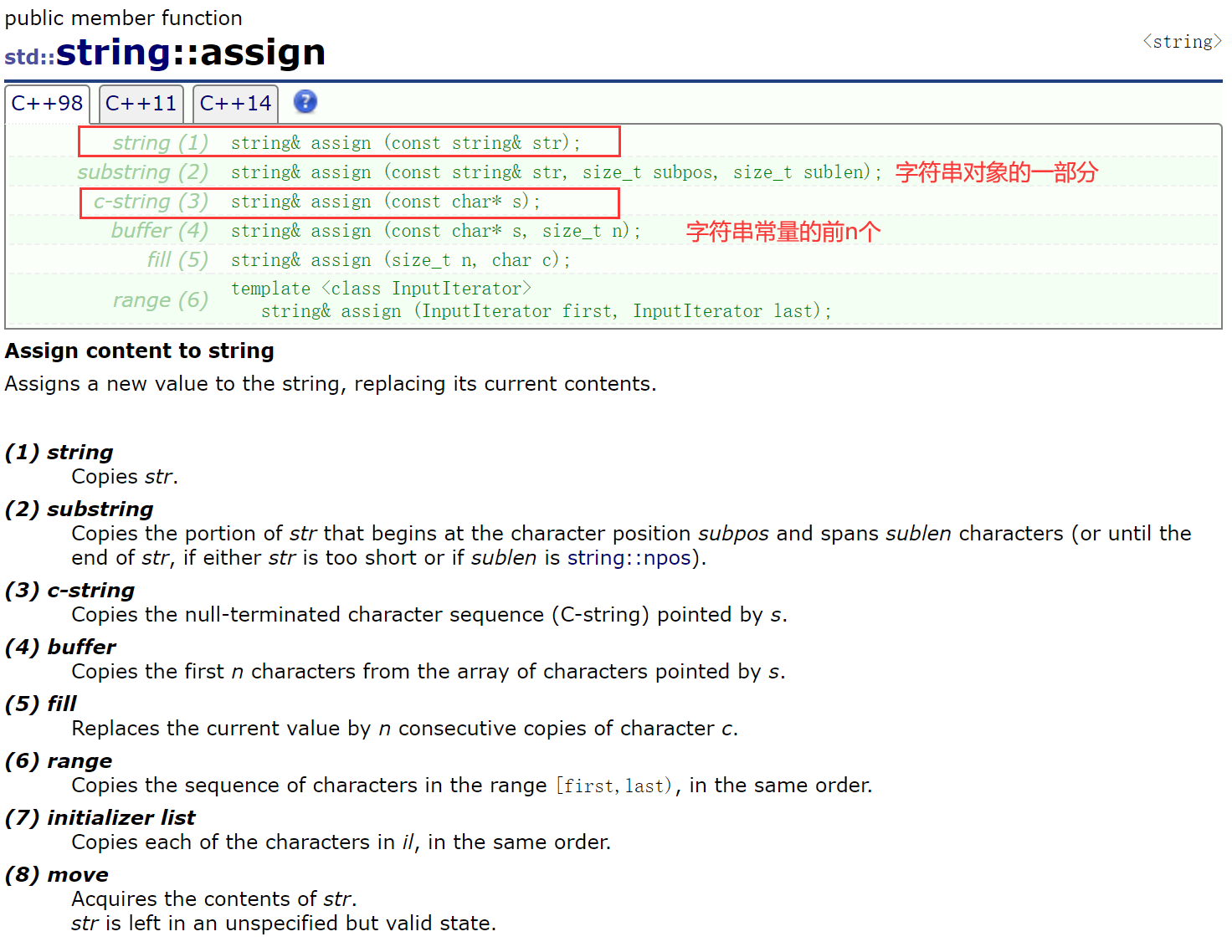
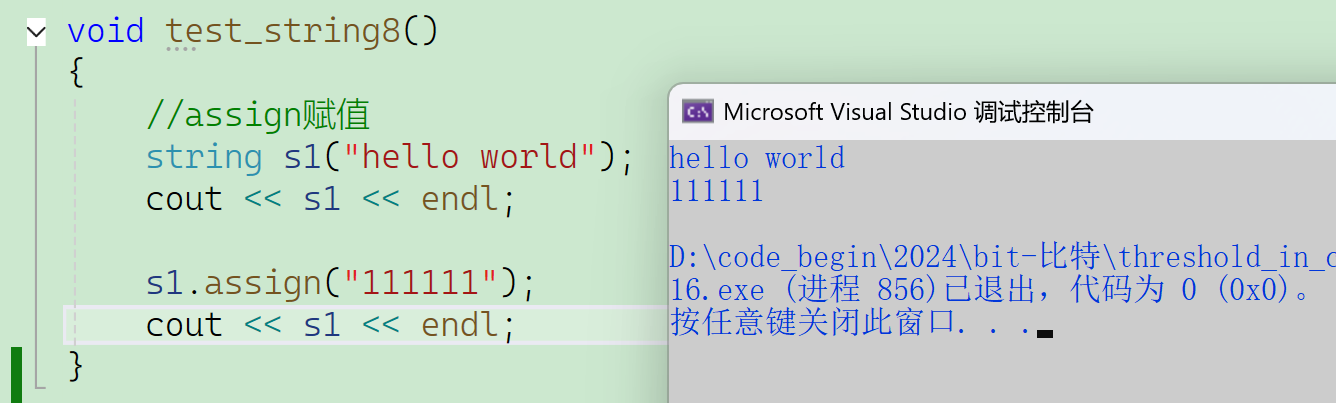
assign在实践当中用得非常少,用assign也是一般只用(1)或(3)——string设计得比较冗余。
代码练习:
- string类有尾插尾删,但是没有头插头删——效率不高。
- 但是间接支持了头插、头删——insert()、erase()。
- 慎用,效率不高
(顺序表的插入、删除,时间复杂度O(N))- 实践中需求也不高。
string的设计确实是当时经验偏少,设计得比较乱。
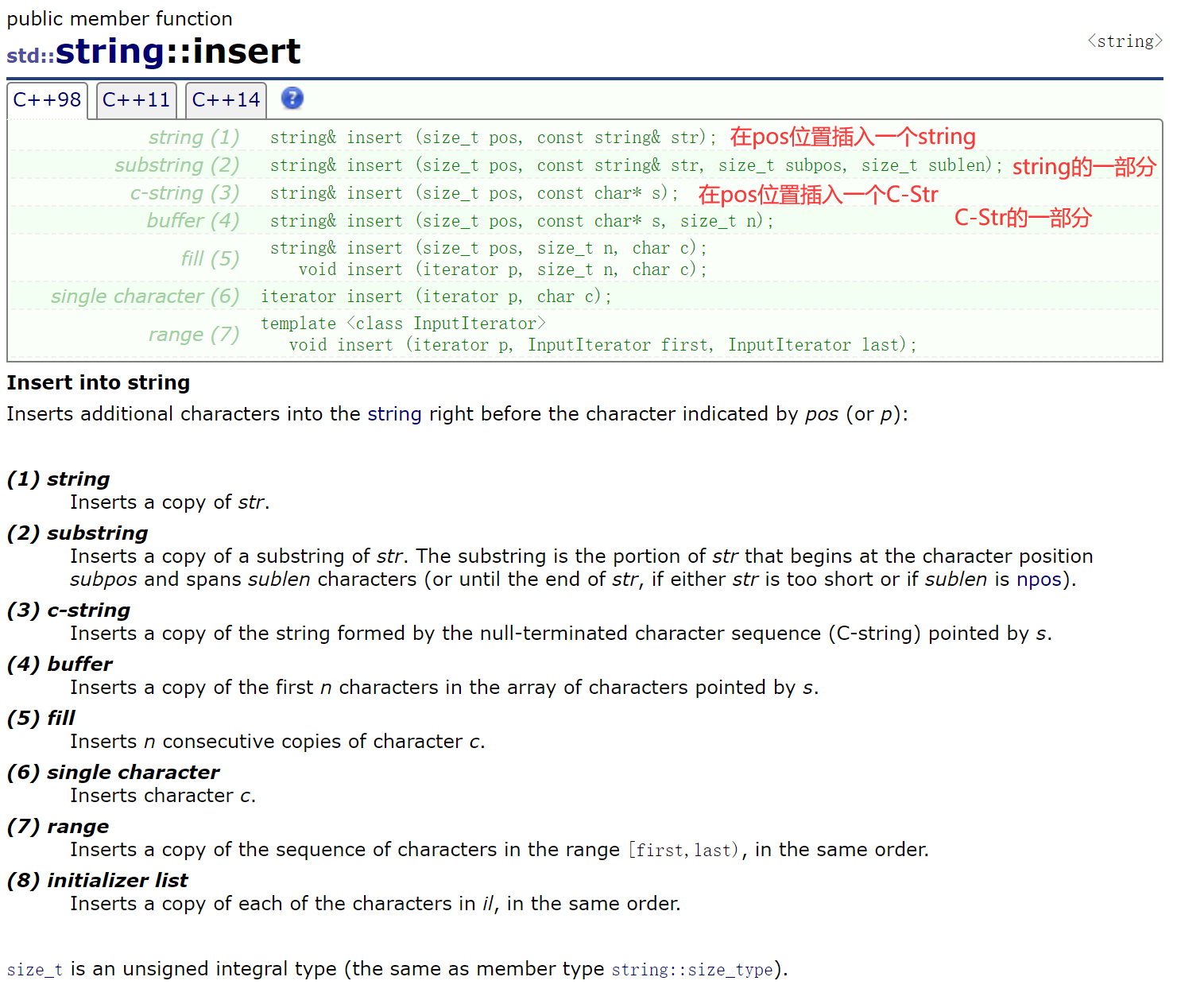
第(5)个:在pos位置插入n个c——由于没有(size_t pos,char c)这个形式,做不到在指定位置插入一个字符,所以只能用(size_t pos,size_t n,char c)来头插一个字符——(0, 1, 'x')。
第(7)个:在s2的p位置之前插入s1的[first,last)迭代区间的数据。
- C-Str:C语言风格的字符串——常量字符串、const char*、字符数组char ch[]。
- 特点:以'\0'结尾。

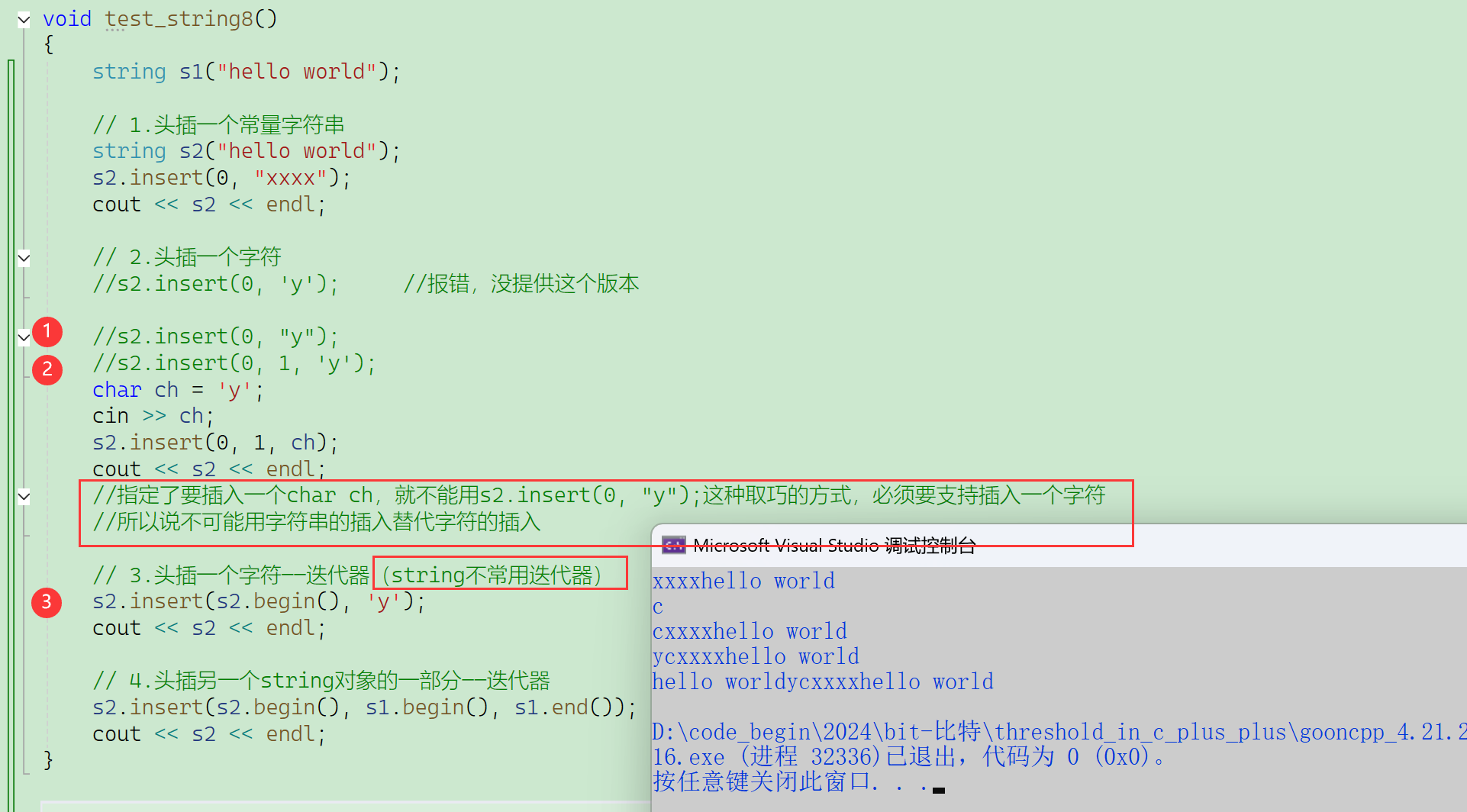
- 不可能用字符串的插入取代字符的插入。
注意使用迭代器,在写迭代区间时要写正确:
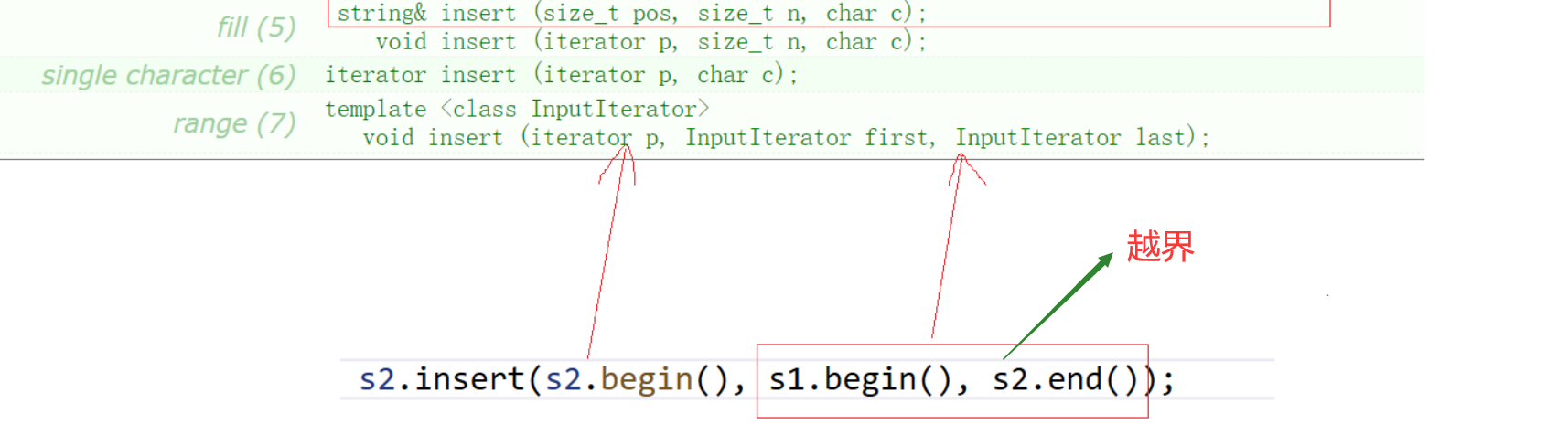
string的设计冗余是C++的缺陷之一,这是语言发展的历史导致的,当时人家设计出来可能感觉也还蛮好,但是后来出现的了更好的东西,就会发现string设计得确实不太好。但是也无法改变,一旦改变,很多陈旧的代码就需要大改特改,所以后面的C++标准只能在兼容旧标准的同时增加新标准,而不太好直接修改旧标准。
2.2.4.6 replace()
replace——替换,把我的一部分替换。
replace这个接口也是设计得非常冗余:
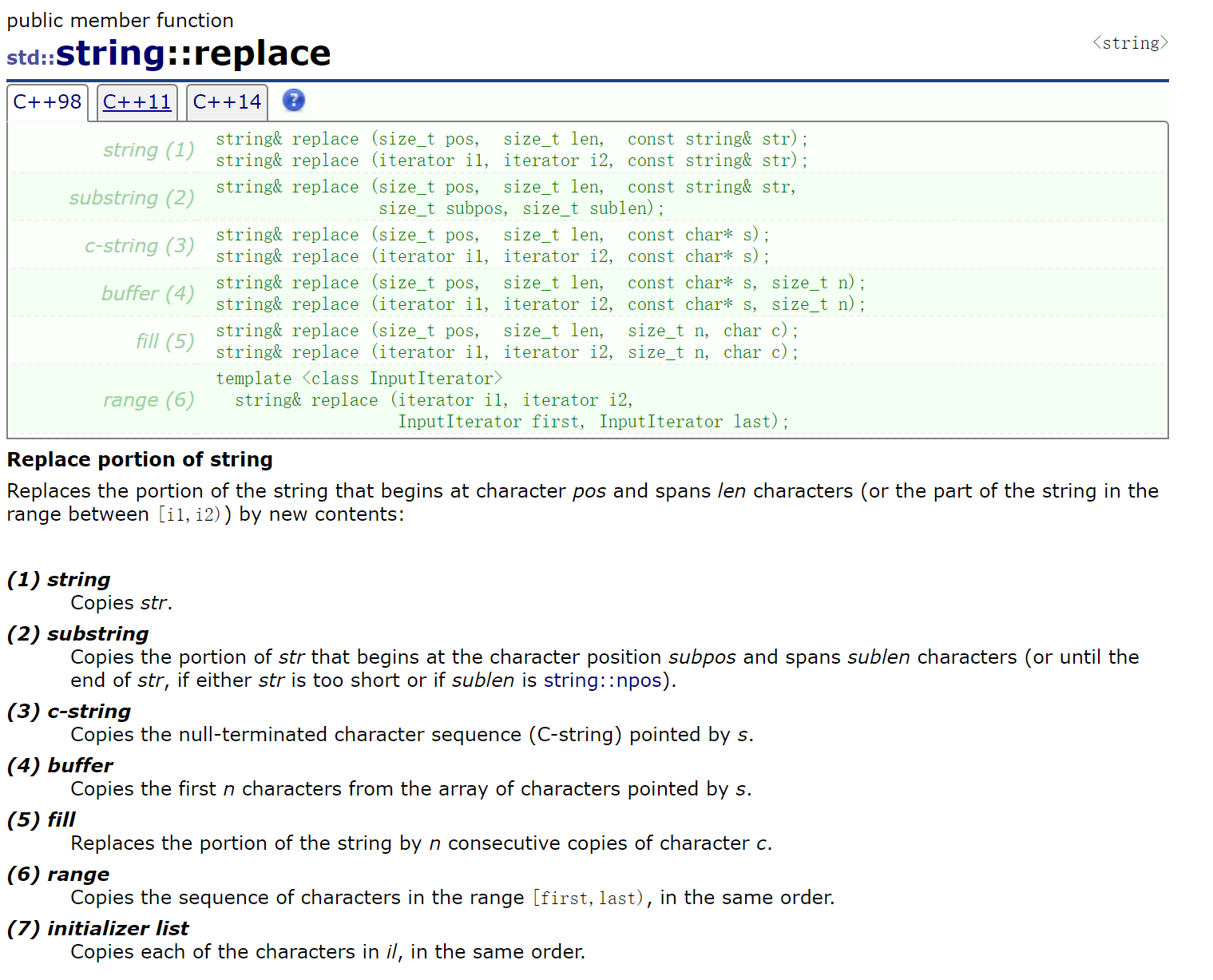
(1)下标版本:把从pos位置开始的len个字符替换成string。
迭代器版本:把迭代区间[i1, i2)替换成string。
(2)把从pos位置开始的len个字符替换成str的一部分。
(3)把从pos位置开始的len个字符替换成char*
(有了(1),这个版本就不必要——const char* 可以类型转换,构造const string&,但是效率会低)(4)把从pos位置开始的len个字符替换成char*的前n个。
(5)把从pos位置开始的len个字符替换成n个c。
(6)把s1的迭代区间[i1, i2)替换成s2的迭代区间[first, last)。
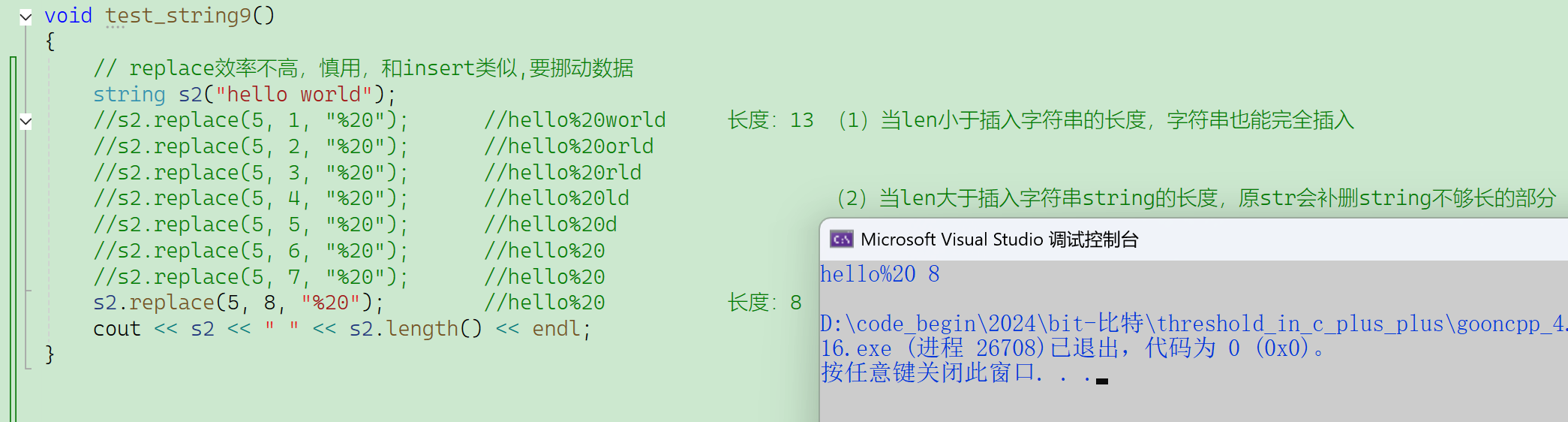
总结一句话:把str从pos位置开始的len个字符替换成string
- string能完全插入进去。
- str也完全固定消失从pos位置起的len个字符。
那显然len小于string的长度时,string要完全替代进去就需要扩容。
同时len大于string长度时,string替代进去后,字符串缩容了。
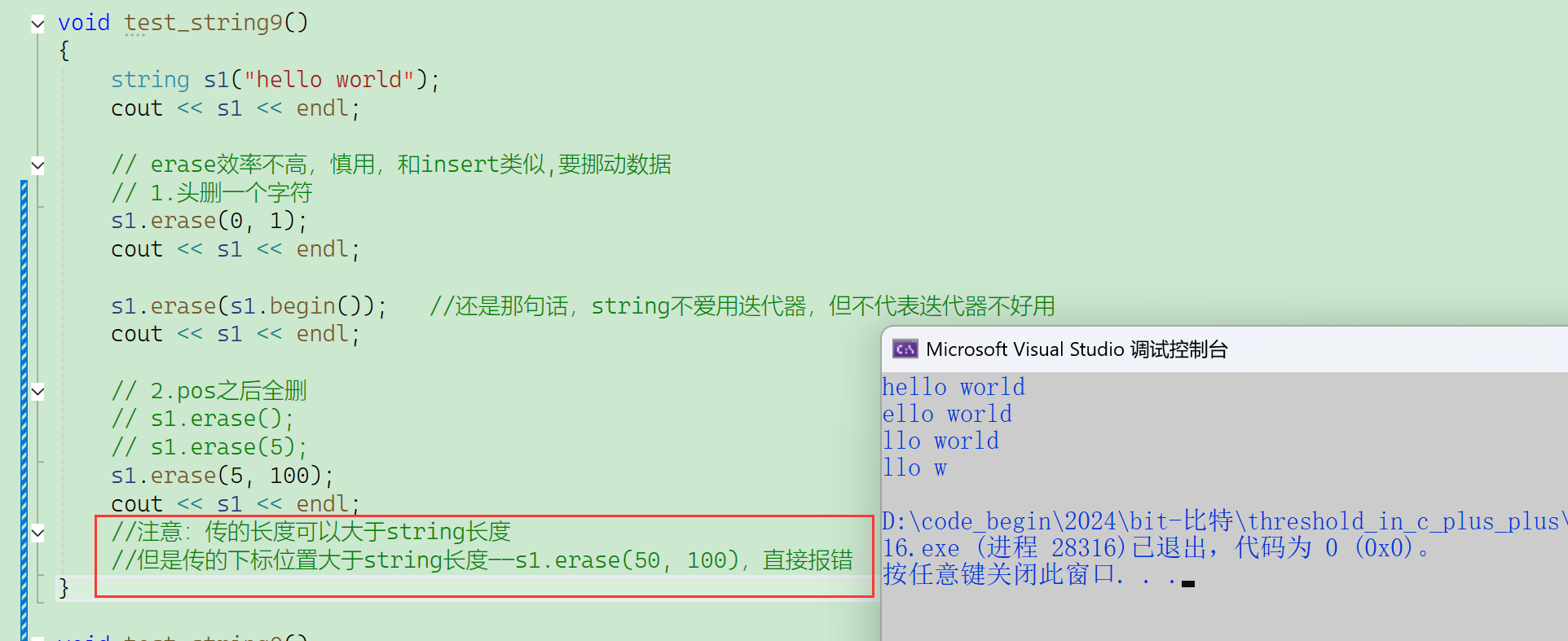
void test_string9()
{//C语言做过一个题,把字符串里的所有空格,都替换成%20string s3("hello world hello bit");for (size_t i = 0; i < s3.size(); ){if (s3[i] == ' '){s3.replace(i, 1, "%20");i += 3;}else{i++;}}cout << s3 << endl;//不建议这样写,因为s3.replace(i, 3, "%20")是不用挪动数据//而s3.replace(i, 1, "%20")是要挪动数据,效率比较低//建议写法1:如果在原串上搞,建议从后往前替换,并且数一下多少个空格一次全部挪动到位//建议写法2:如下string s4("hello world hello bit");string s5;for (auto ch : s4)//用范围for遍历s4{if (ch != ' '){s5 += ch;//不是空格就接收}else{s5 += "%20";}}cout << s5 << endl;//效率高多了(但是这种写法牺牲了空间,绝大多数情况下都是要时间不要空间)
}2.2.4.7 string类的扩容测试

其实第一次不算2倍扩容,一开始是存在string内的buf数组(16字节) ——栈上。
满了之后,再到堆上开新的空间来存储。
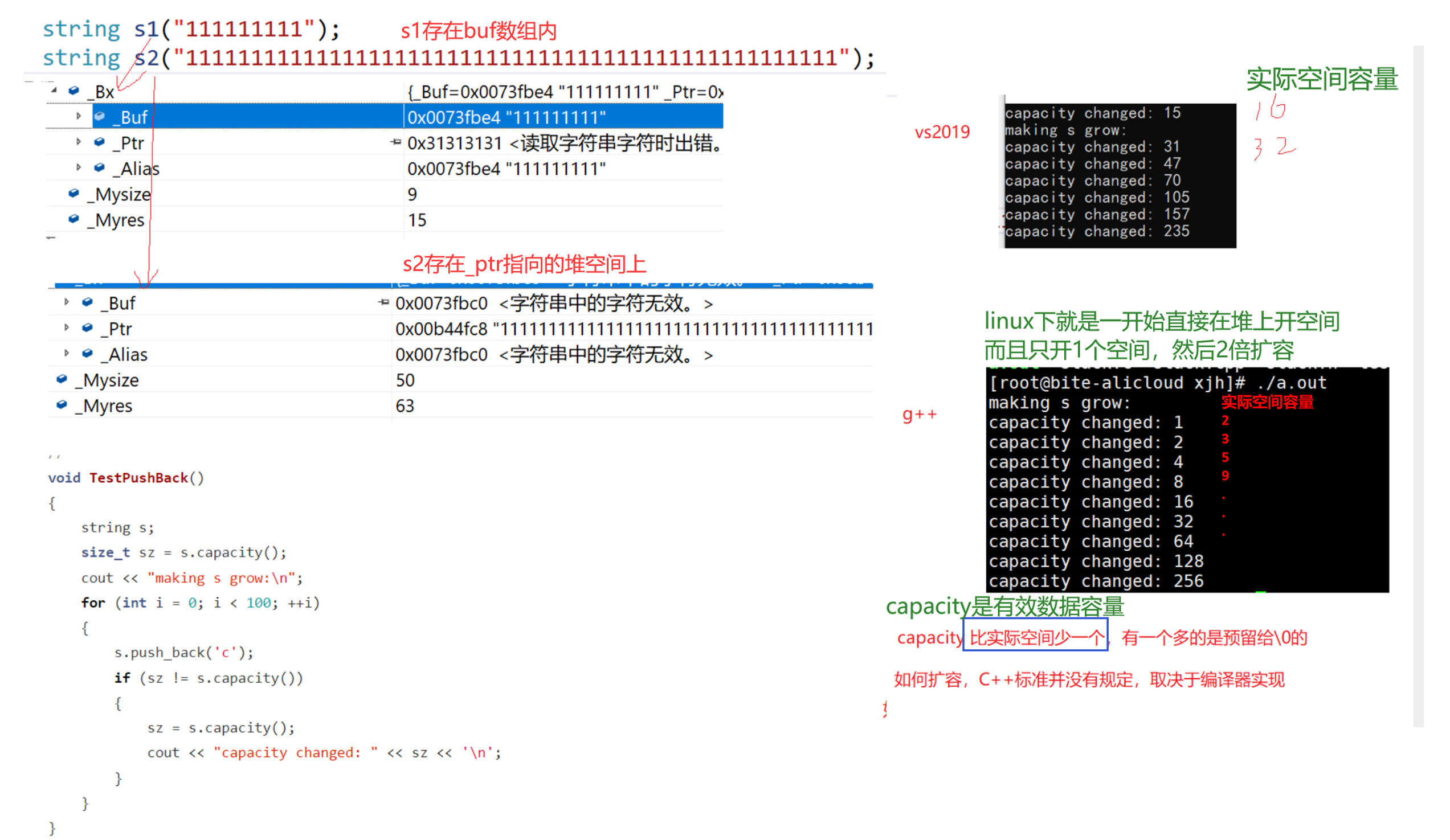
如何扩容:1.5倍、2倍……,C++标准并没有规定,由编译器自己实现。
linux的g++(版本4.8)底层就没有一个预留数组buf,容量从1开始,逐渐2倍扩容下去。
- VS下扩容的基准:capacity + 1,扩容1.5倍;(实际大小比capacity大1)
- G++下扩容的基准:capacity,扩容2倍,再+1;(实际大小比capacity大1)
由于连续的扩容(一般都是异地扩容)有较大的消耗,这里可以用reserve提前开好空间。

【空串】
- 有效数据个数:都是0。
- 实际大小:
- VS下的空字符数组也有一个\0;
- G++的空string也有一个\0;
- VS的空string有16个\0


VS的string相当于是空间换时间,处理起来相对麻烦,但是长度小于16的大量常用字符串都不用去堆上申请空间,提高了效率,减少了内存碎片。(有内存池的思想在这里)
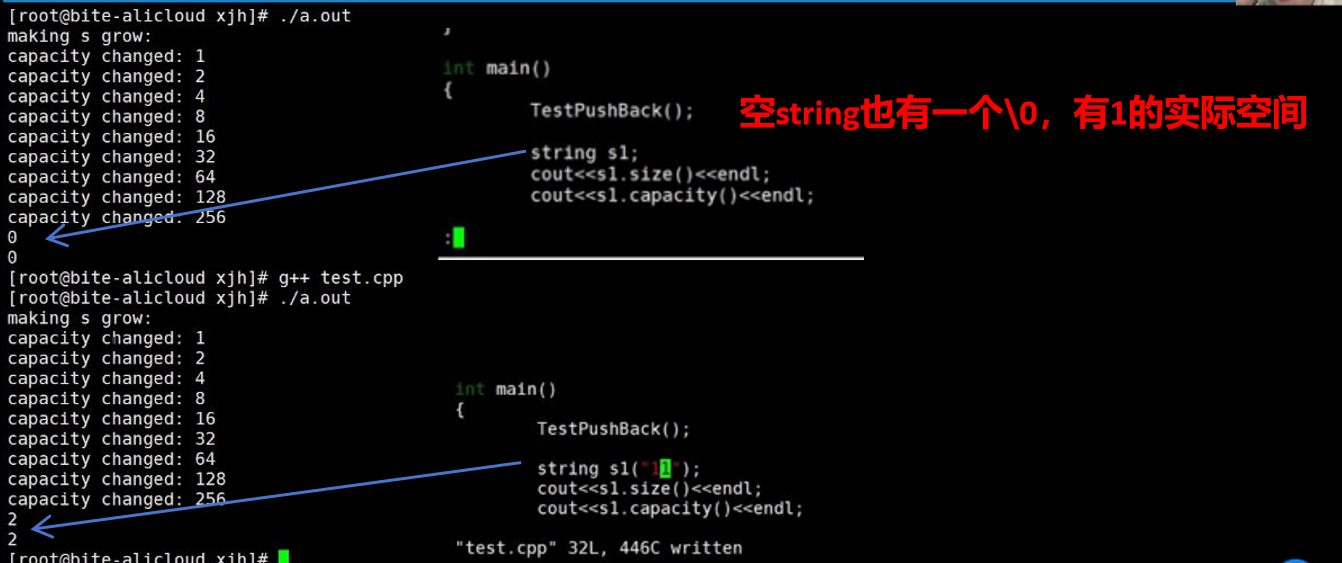
linux环境下,string的\0也不算在capacity内。
swap()函数暂时不太能讲清楚,之后把深、浅拷贝讲了,模拟实现的时候再来看这个swap()。
【总结】
| 函数名称 | 功能说明 |
| push_back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符串 |
| operator+=(重点) | 在字符串后追加字符串str |
| c_str(重点) | 返回C格式字符串 |
| find + npos(重点) | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
【注意】
- 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
- 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
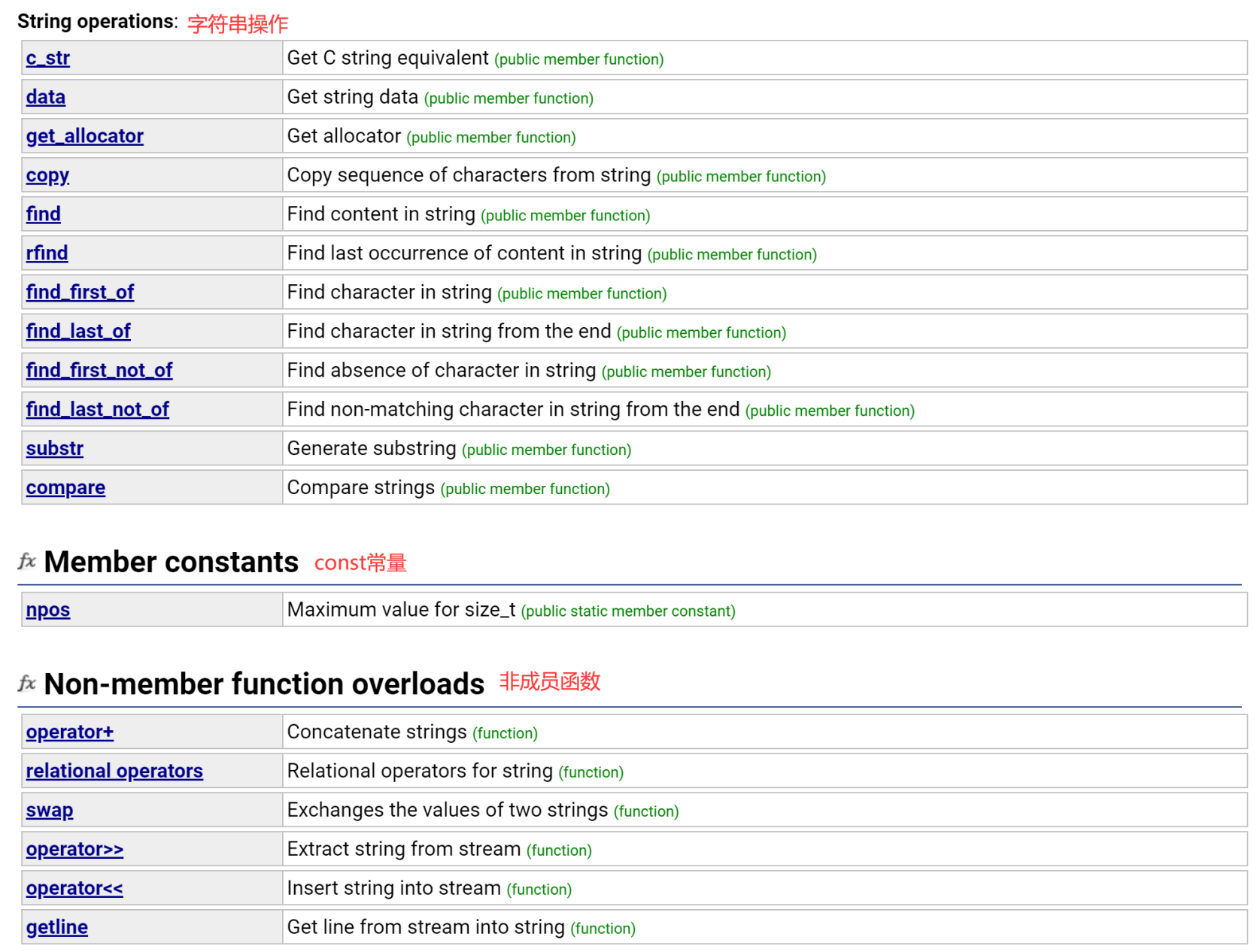
2.2.5 string类操作函数
2.2.5.1 c_str()

VS下就是返回数组首元素的地址。
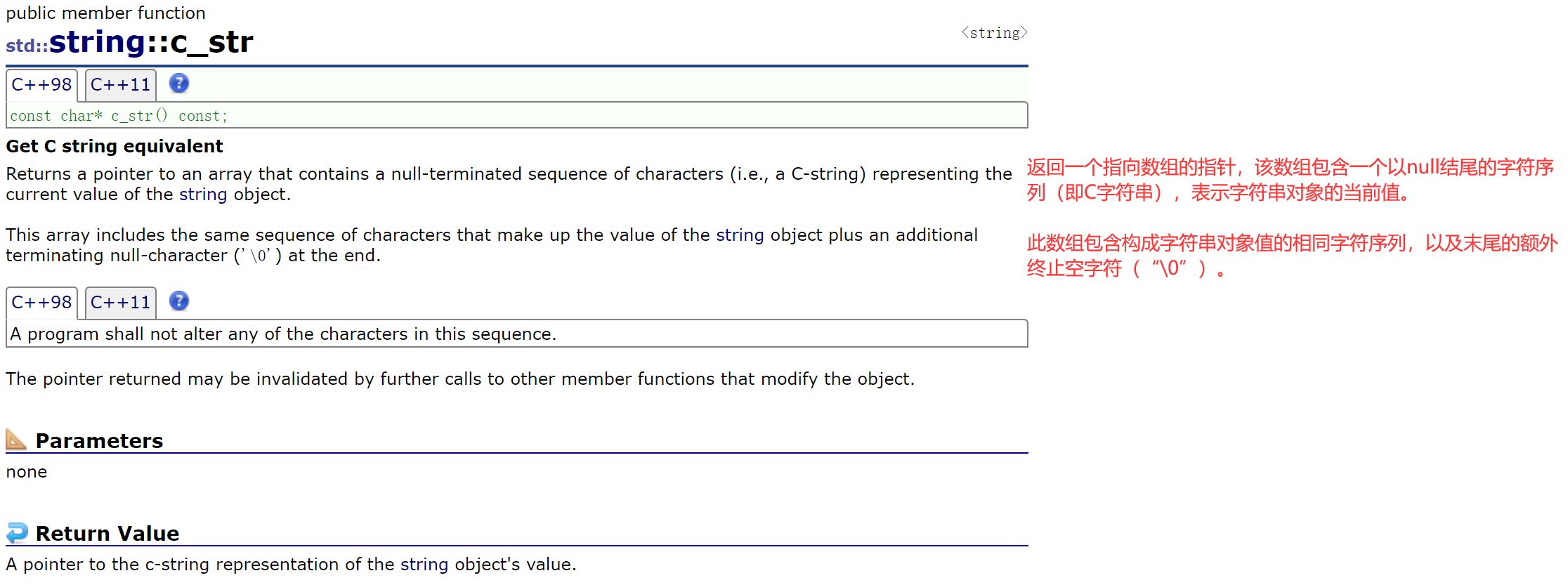
应用场景:用适配C的接口函数去操作string时没法传参,string需要转换成C风格的字符串。
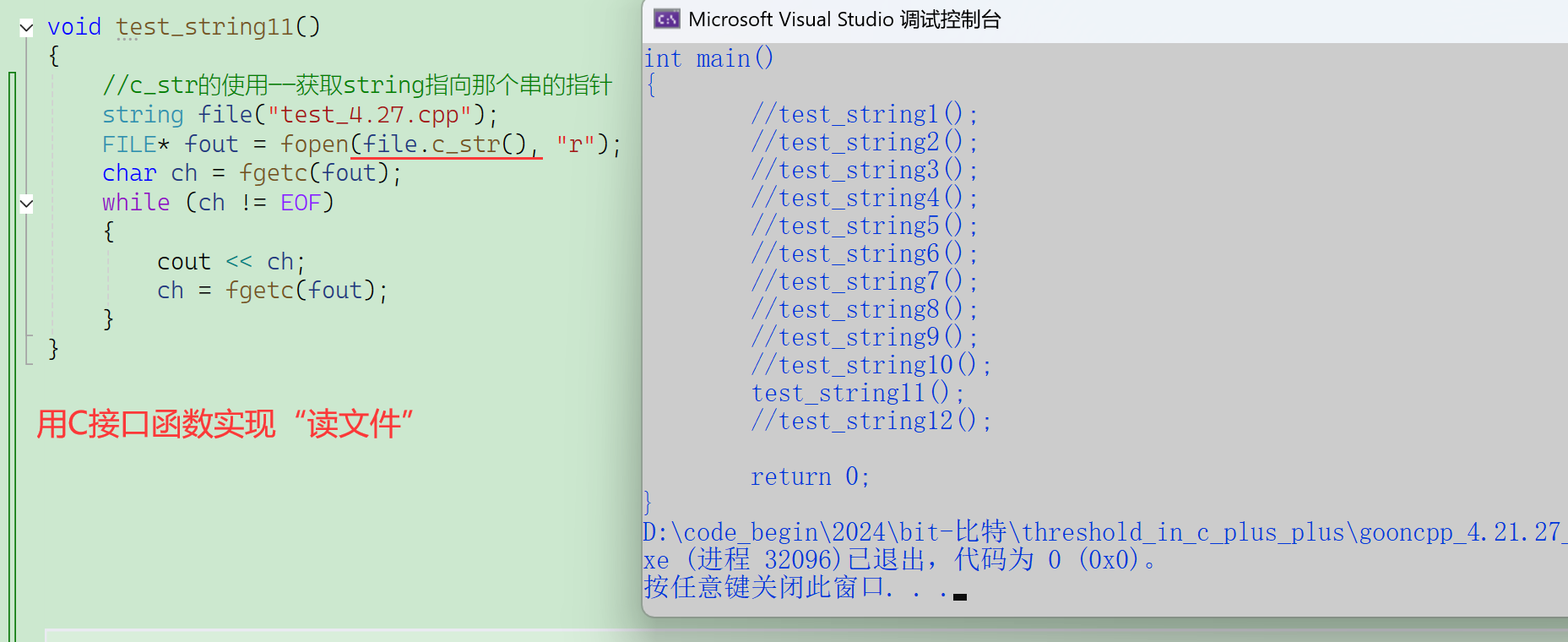
有些库只提供C的接口,这样C++兼容C,C++和C都能使用这个库。
2.2.5.2 data()

data和c_str类似,平时只用c_str就够了。
data和c_str的关系类似于size和length——不同时期的产物导致的。
2.2.5.3 其他
- get_allocator():是指string下面的空间配置器,这些数据结构底层都用了一个内存池,后面再讲。
- copy():就是把string的一部分拷贝到char*(C风格字符串)里面去。(很少用)
2.2.5.4 find()、rfind()、substr()
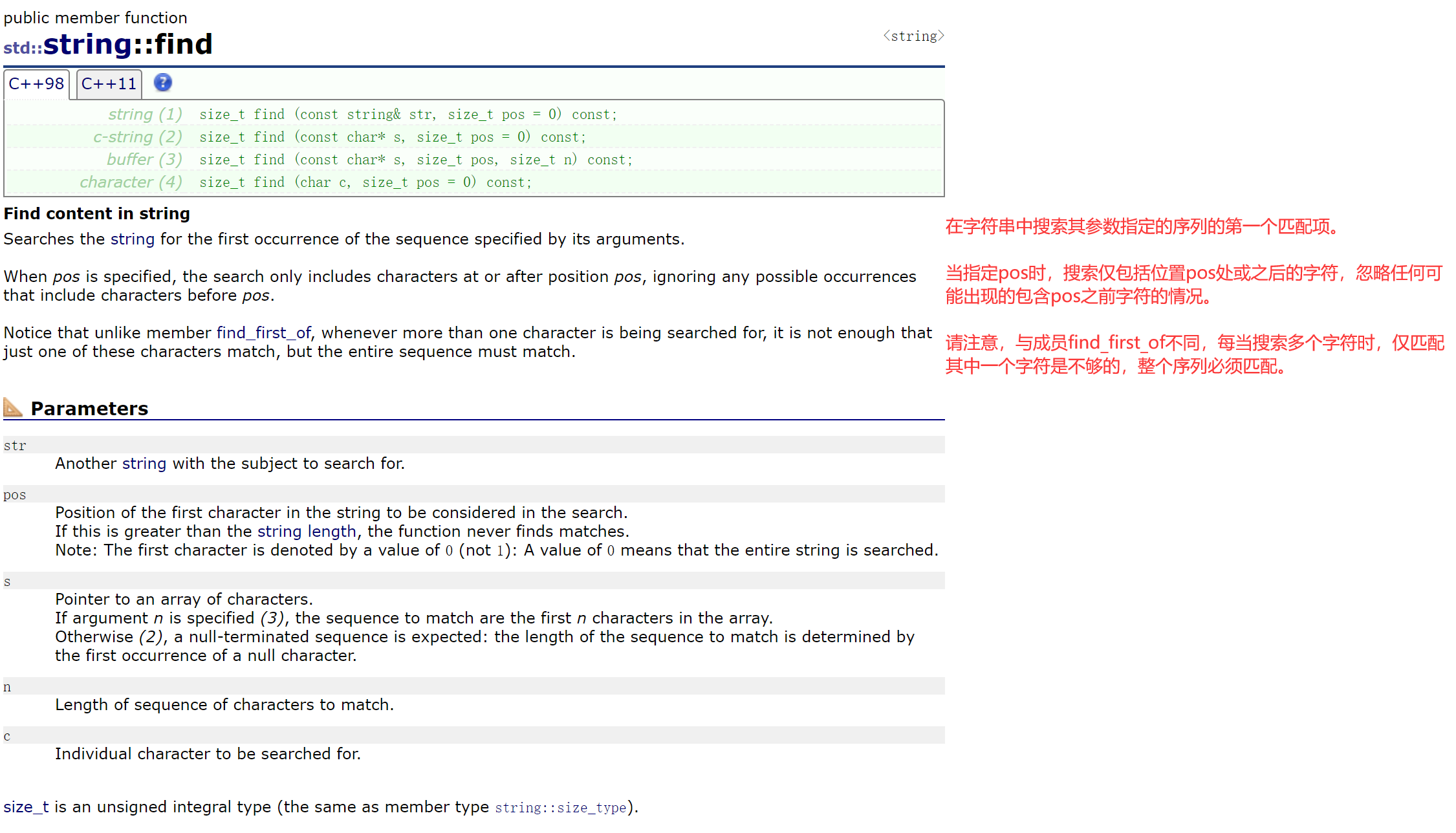
(1):查找一个string对象;(可指定开始查找的位置,默认从0位置开始查找)
(2):查找一个C-字符串
(3):查找一个C-字符串的前n个
(4):查找一个字符
注:const char*不一定是常量字符串,而是C风格字符串,非常量C字符串可以权限的缩小传参。
rfind()就是倒着找。
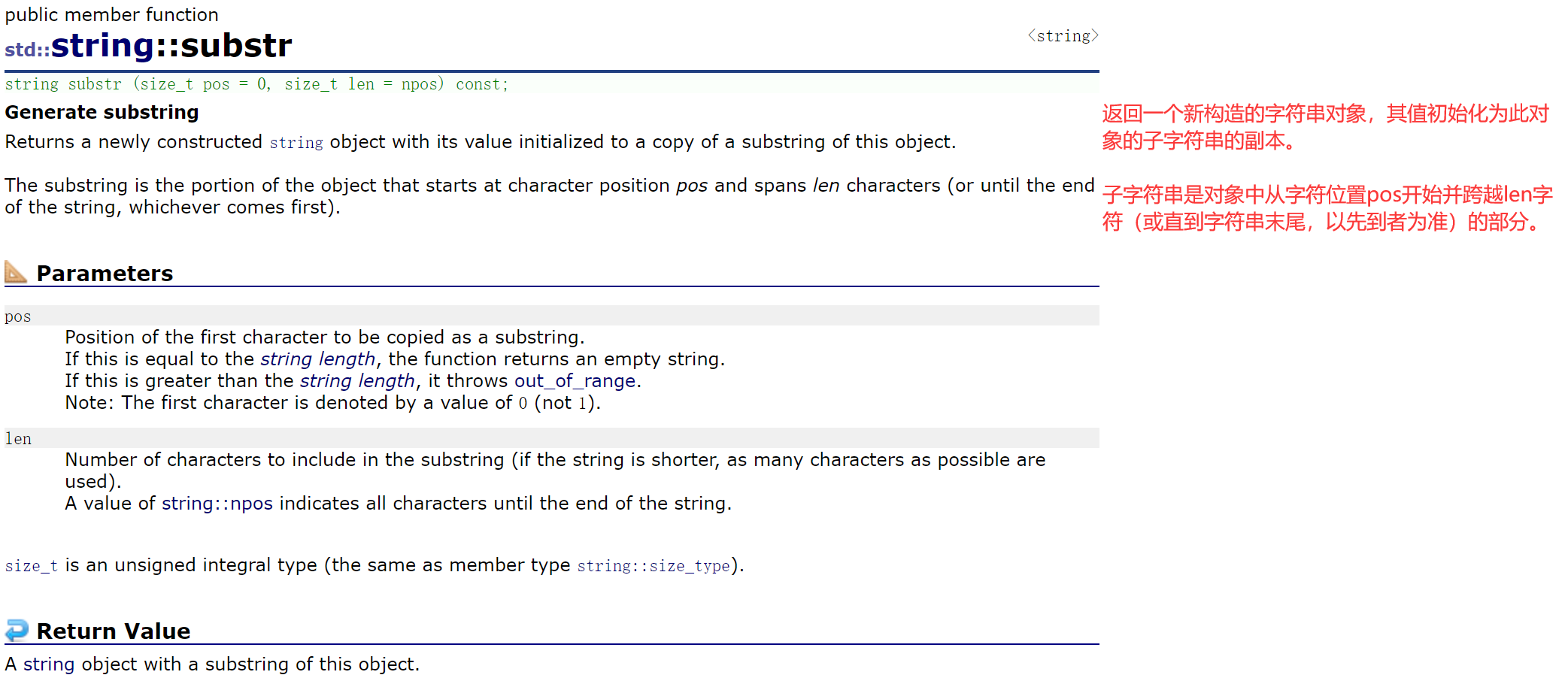
用从pos位置开始的len个字符生成一个子串返回。
- len比较长、或、len没给,就取npos——pos之后全用于生成子串。
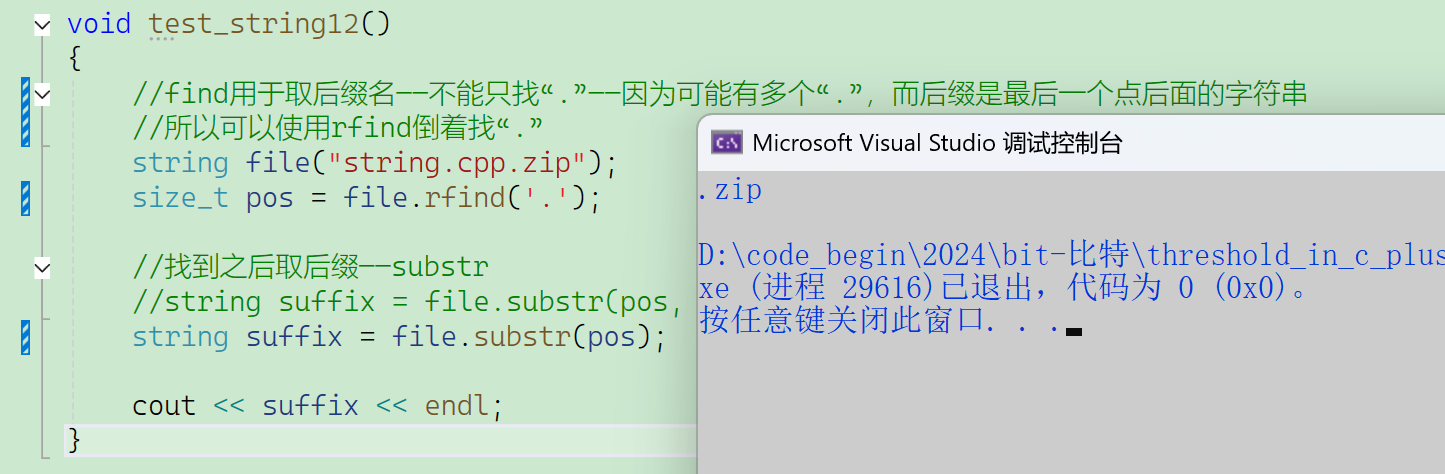
void test_string12()
{//find用于取后缀名——不能只找“.”——因为可能有多个“.”,而后缀是最后一个点后面的字符串//所以可以使用rfind倒着找“.”string file("string.cpp.zip");size_t pos = file.rfind('.'); //找到.的位置pos//找到之后取后缀——substr//string suffix = file.substr(pos, file.size() - pos);//具体给出字符个数就是——file.size() - posstring suffix = file.substr(pos); //也可以不给字符个数——从pos位置之后一直取完cout << suffix << endl;
}
【练习】划分URL的三大组件
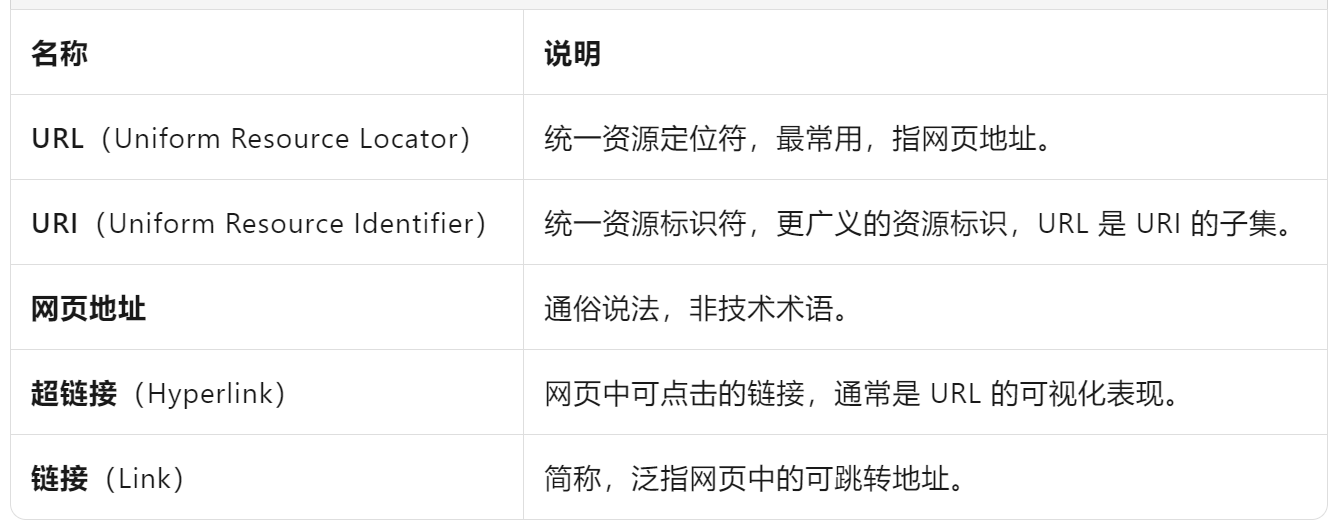

域名用来获取服务器的IP地址。
想把网络连接的3部分分别取出来:
- 协议https
- 域名gitee.com
- 路径ailiangshilove/cpp-class/blob/master/TestString.cpp
用这个协议,在这个域名描述的服务器上,取这些资源——不同的网页,后面的资源定位符部分都是不一样的。
- 核心操作:不断地用find找到这些标志,然后取子串。
void test_string12()
{string url("https://gitee.com/ailiangshilove/cpp-class/blob/master/TestString.cpp");//核心操作:查找+取子串// 1.查找——查找协议// 从起始位置开始找(从h开始找),找“冒号”size_t pos1 = url.find(':'); //不给pos,默认从pos=0(缺省值)开始找// 2.取子串——取协议string url1 = url.substr(0, pos1 - 0); //左闭右开的区间[0,10),这样的区间,左右下标相减就是个数;左闭右闭,则:右-左+1,才是个数cout << url1 << endl;// 1.查找——域名// 从中间开始找(从g开始找),找“第一个斜杠”size_t pos2 = url.find('/', pos1 + 3); //g在pos1+3的位置// 2.取子串——取域名string url2 = url.substr(pos1 + 3, pos2 - (pos1 + 3));cout << url2 << endl;// 2.取子串——取路径// 从中间开始取到结束(从a开始取到结束)string url3 = url.substr(pos2 + 1); //a在pos2+1的位置cout << url3 << endl;
}注意取子串substr函数的两个参数:
- 取子串的起始位置
- 取子串的长度
所以取域名要:从pos1+3位置开始取,一共取pos2-pos1-3个字符。
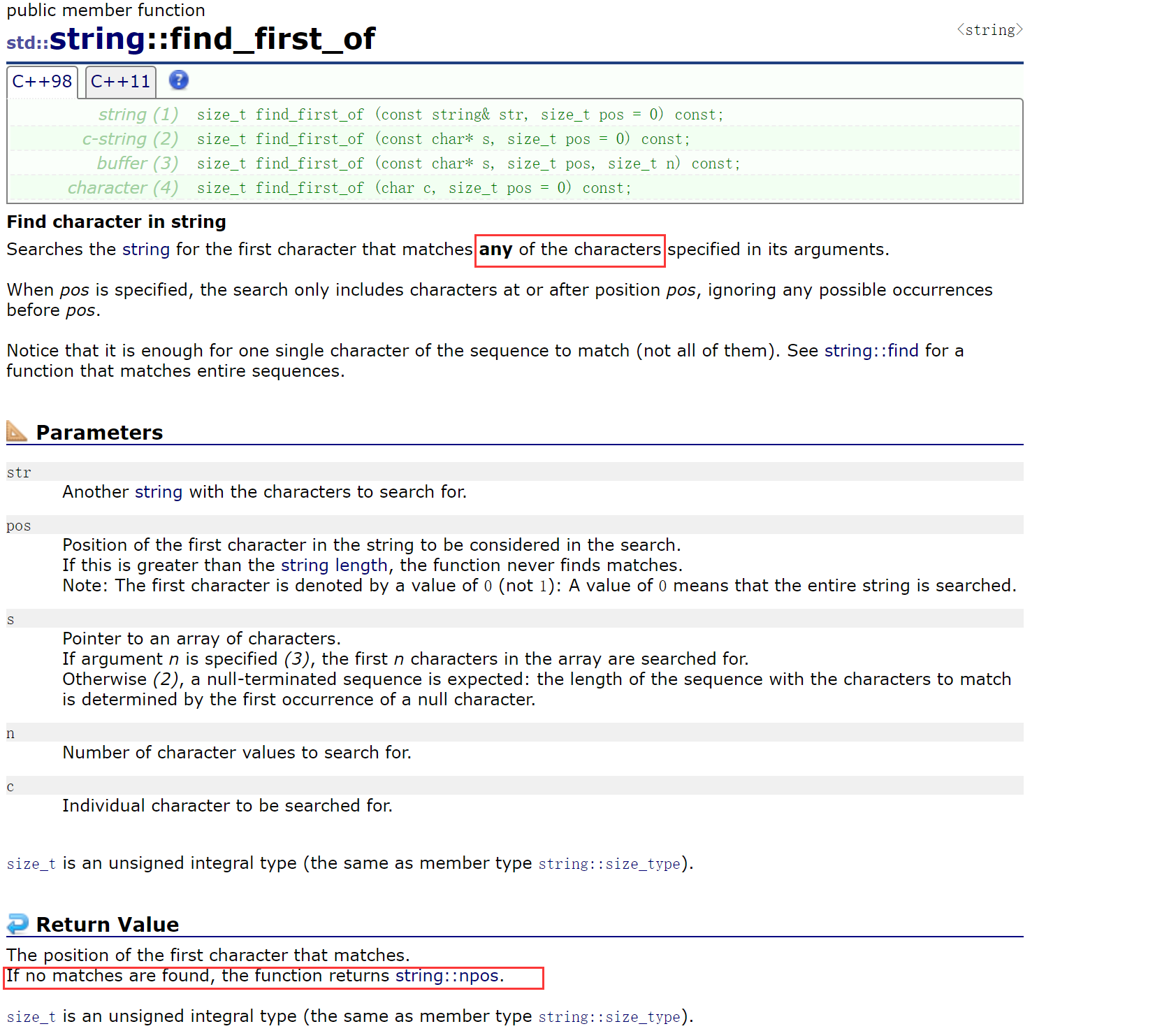
2.2.5.5 find_first_of()、find_last_of()

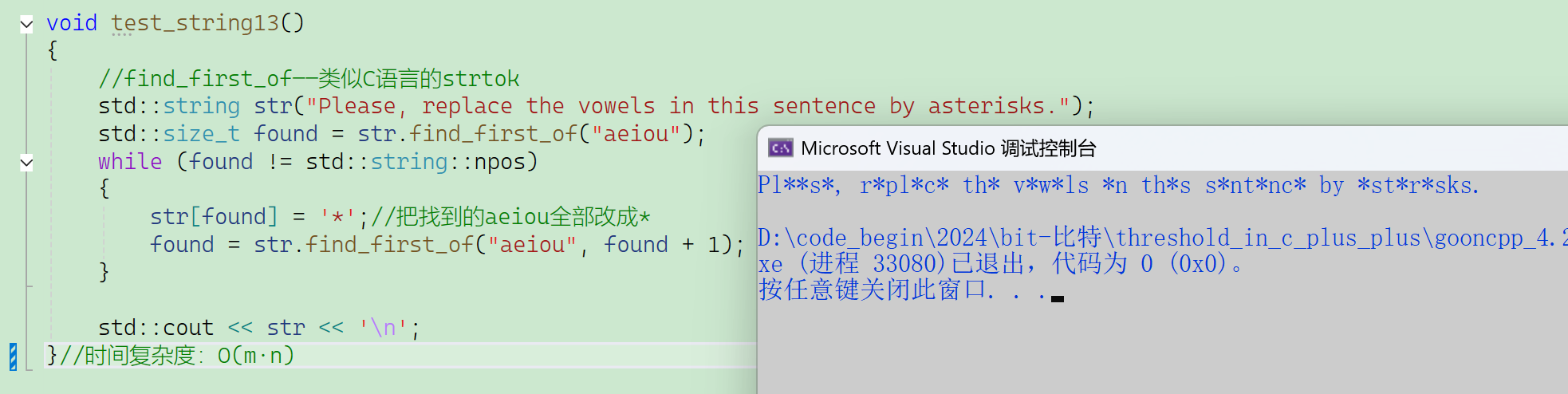
2.2.5.6 find_last_of()
相当于倒着走的find_first_of:

倒着找,可以用于分装路径和文件:
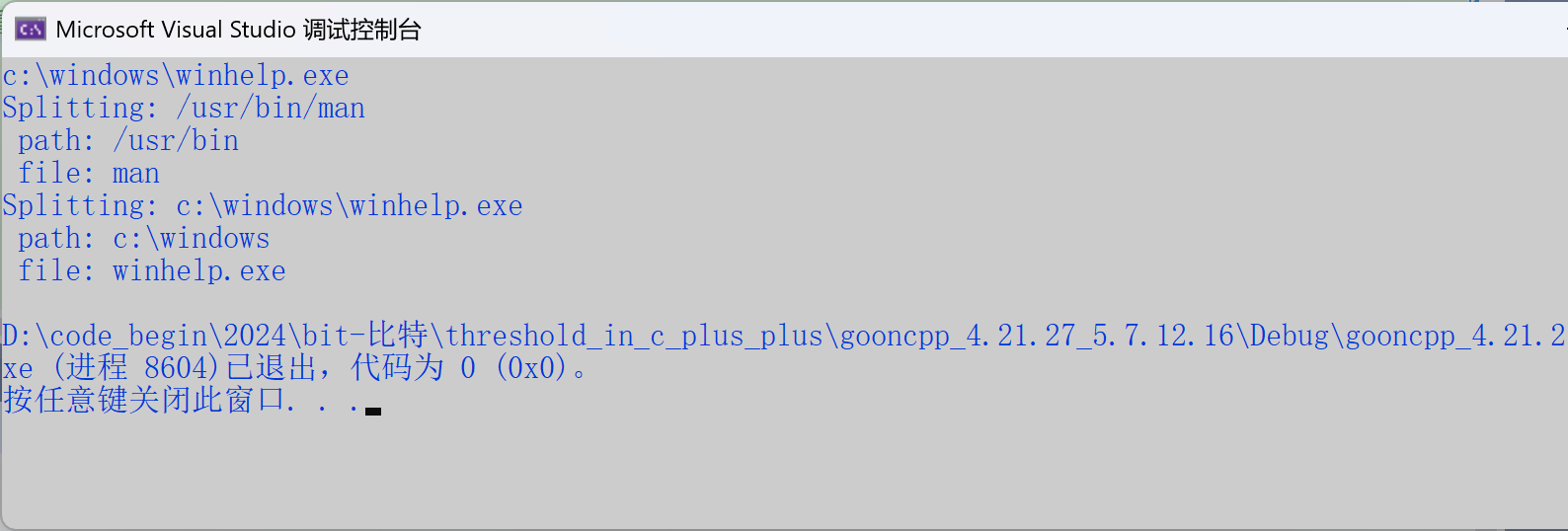
//find_last_of
void SplitFilename(const std::string& str)
{std::cout << "Splitting: " << str << '\n'; //split分装std::size_t found = str.find_last_of("/\\"); //实际的调用是str.find_last_of("/\")std::cout << " path: " << str.substr(0, found) << '\n'; //对路径、文件进行分装std::cout << " file: " << str.substr(found + 1) << '\n';
}
int main()
{std::string str1("/usr/bin/man"); //linux下的路径是右斜杠std::string str2("c:\\windows\\winhelp.exe"); //windows下的路径是左斜杠//这里双左斜杠是转义成单斜杠,单斜杠表示转义不是真的斜杠//实际的str2是c:\windows\winhelp.execout << str2 << endl;//打印出来看只有单斜杠SplitFilename(str1);SplitFilename(str2);return 0;
}
- find_first_not_of:找不是这些里面的任何一个在str中首次出现的位置。
- find_last_not_of:倒着找不是这些里面的任何一个在str中首次出现的位置。
2.2.5.7 compare()

2.2.6 string类非成员函数
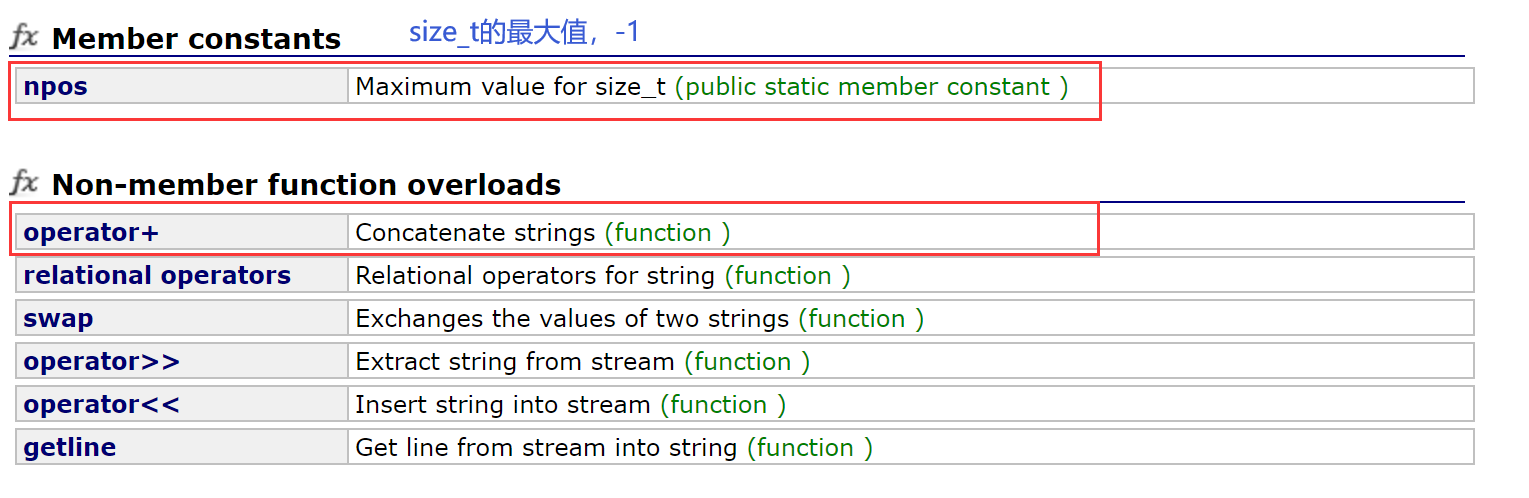
2.2.6.1 +重载
- =重载是默认成员函数
- +=重载是成员函数
- +重载是非成员函数

string operator+(const char* lhs,const char* lhs),两个参数(对应两个操作数)都是内置类型。
这是不支持的——不支持对内置类型进行运算符重载,至少有一个是自定义类型。
——成员函数天然满足。
- +重载为了支持后两种用法的加法交换律,所以重载为了全局函数。
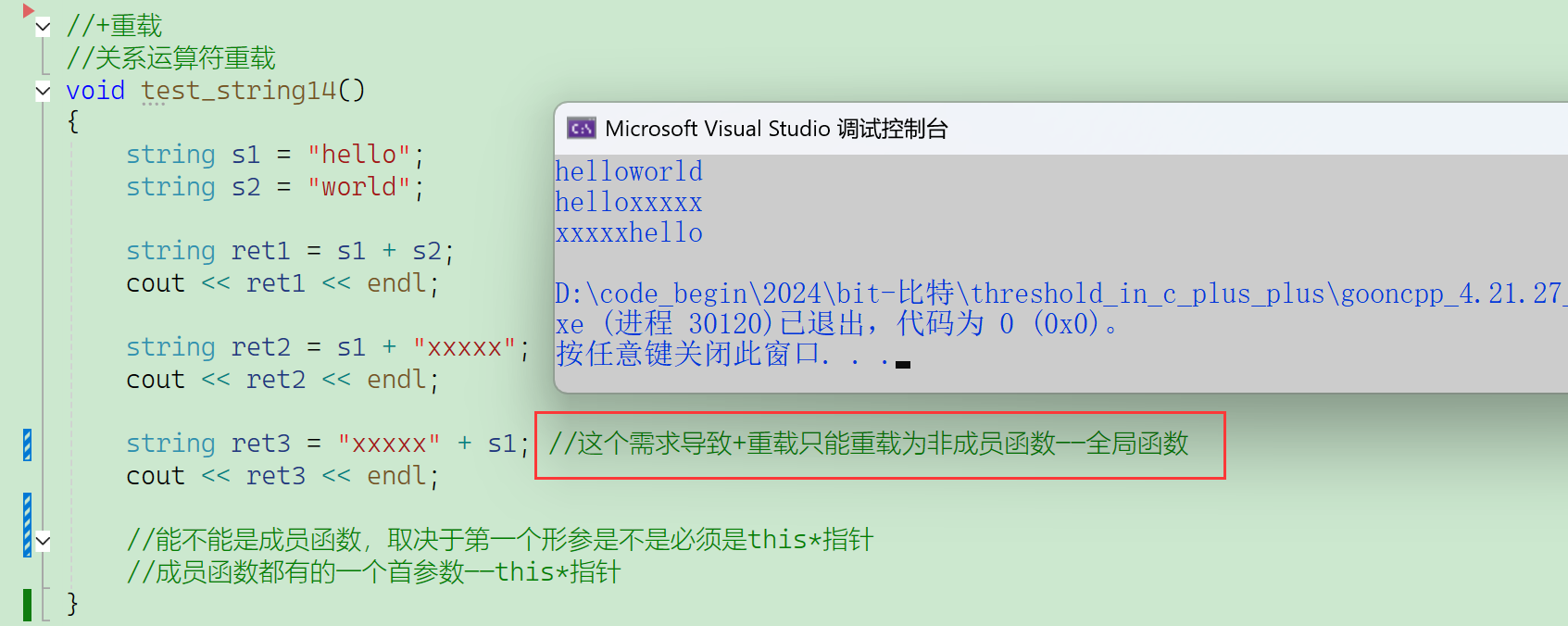
2.2.6.2 关系运算符重载
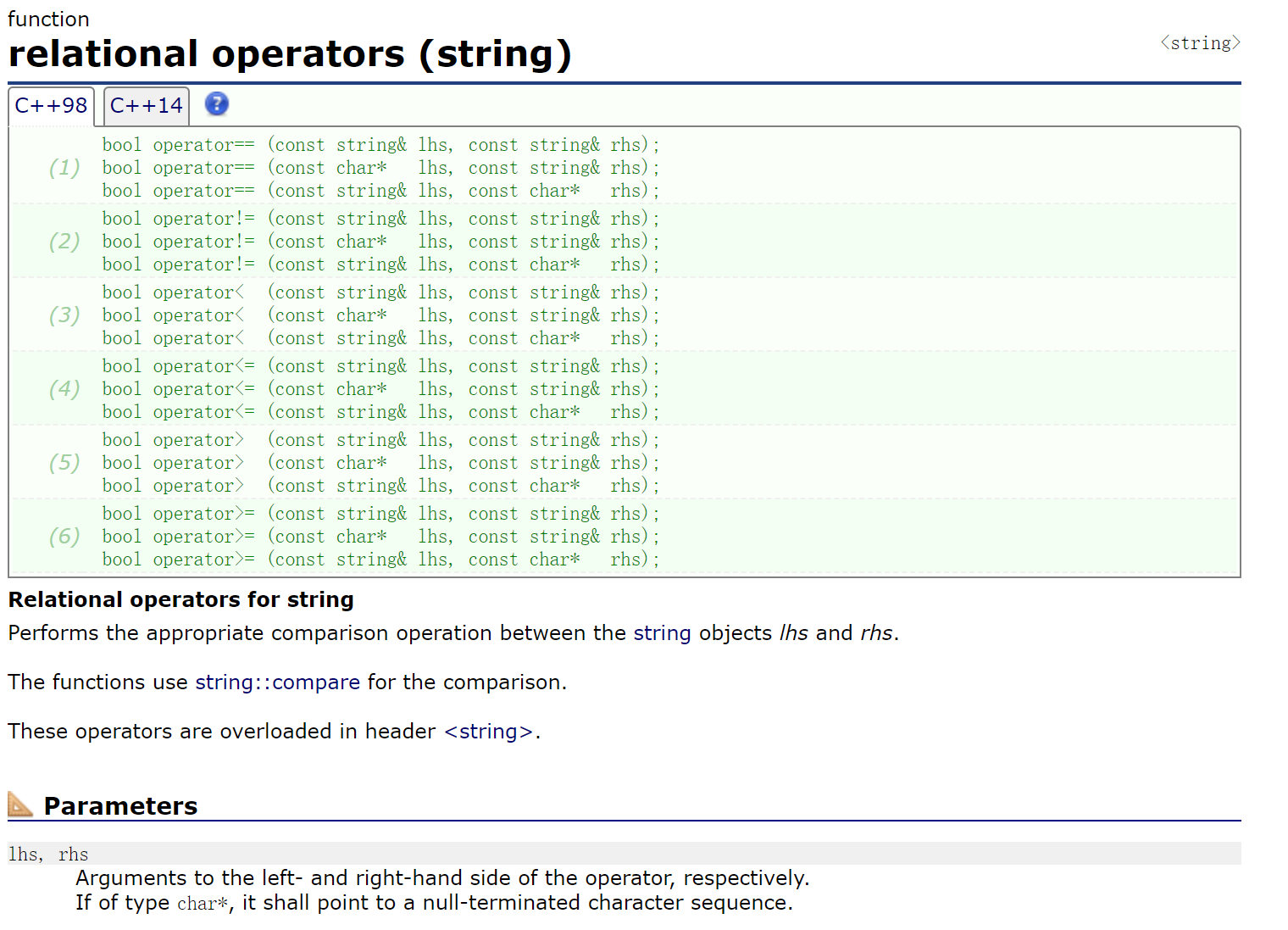
这6个重载函数中,它们每个的后两个版本的const char*可以隐式类型转换成const string&,属于是没必要。
可能是不想要消耗,因为早期的电脑性能不高,能少一点消耗是一点。
所以就考虑了很多现在看来很冗余的设计。
(早期电脑性能不高,所以早期代码风格的{}并不提行写)
- 为了支持C风格的字符串、C++的字符串在比较运算符哪一端都能正常比较,只能重载为全局函数。
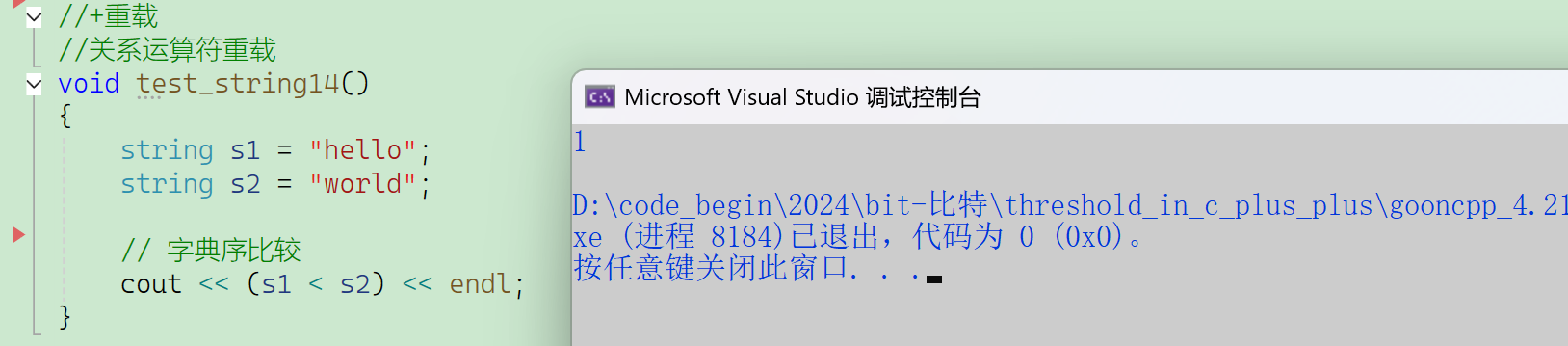
注意操作符优先级问题,要加括号。
【字符串比较】——不是按首字母,而是按ASCII码比(按字典序)
- 比的不是总体的ASCII码总值,而是按顺序比,相同才往下继续比,不同直接返回。
- 如果前面都相同,谁先走到\0谁小,\0不参与比较,例:“hello” < “hello11”
- 返回值都是布尔类型。
2.2.6.3 其他


返回一个istream类的对象。
【总结】
| 函数 | 功能说明 |
| operator+ | 尽量少用,因为传值返回,导致深拷贝效率低 |
| operator>>(重点) | 输入运算符重载 |
| operator<<(重点) | 输出运算符重载 |
| getline(重点) | 获取一行字符串 |
| relational operators(重点) | 大小比较 |
上面的几个接口大家了解一下,下面的OJ题目中会有一些体现他们的使用。string类中还有一些其他的操作,这里不一一列举,大家在需要用到时不明白了查文档即可。
2.2.7 vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
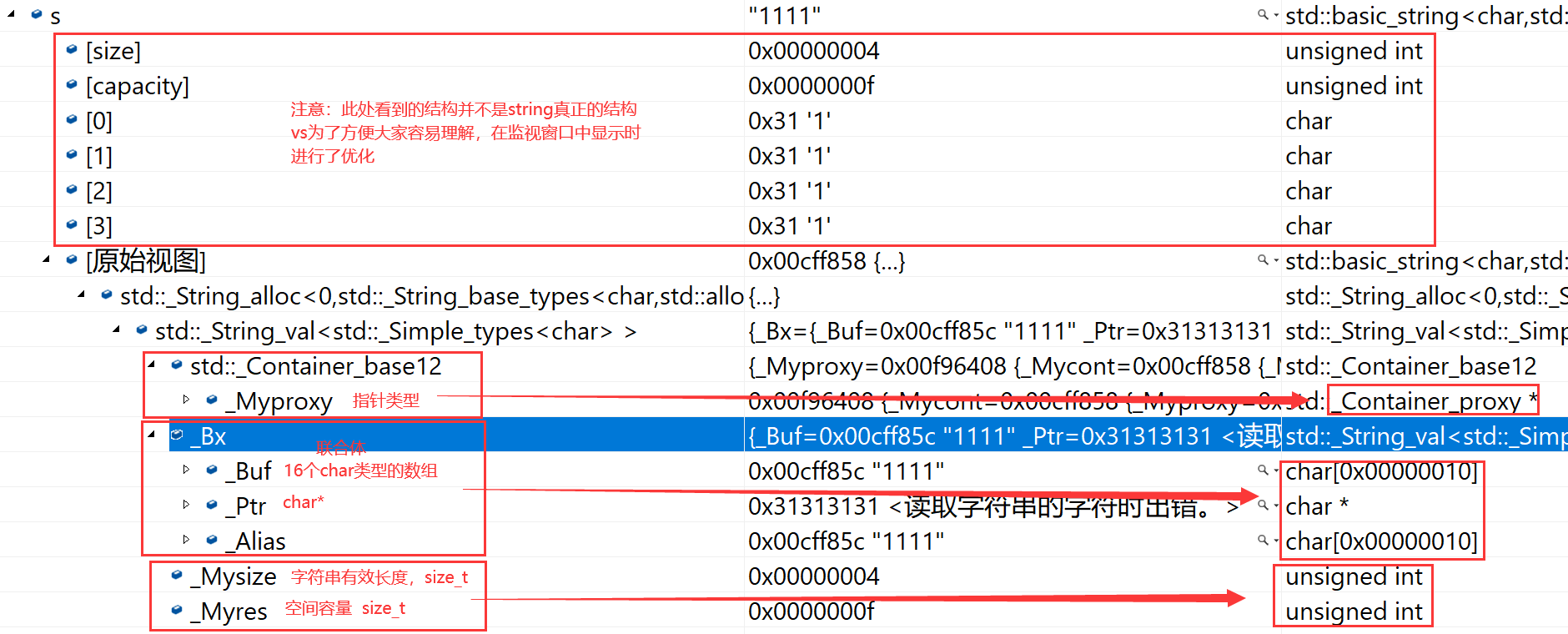
(1)vs下string的结构
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字符串的存储空间:
- 当字符串长度小于16时,使用内部固定的字符数组来存放。
- 当字符串长度大于等于16时,从堆上开辟空间。

这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节。
(2)g++下string的结构
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:

- 空间总大小
- 字符串有效长度
- 引用计数
- 指向堆空间的指针,用来存储字符串。
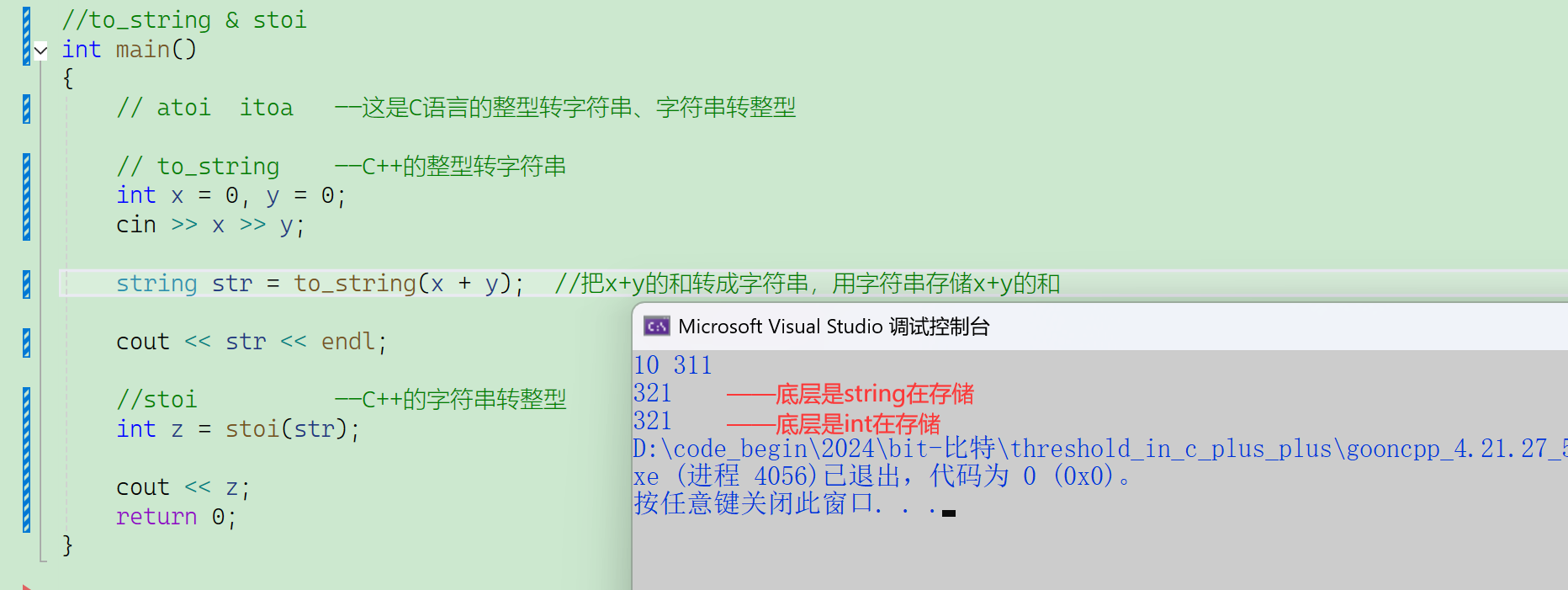
2.2.8 <string>库函数
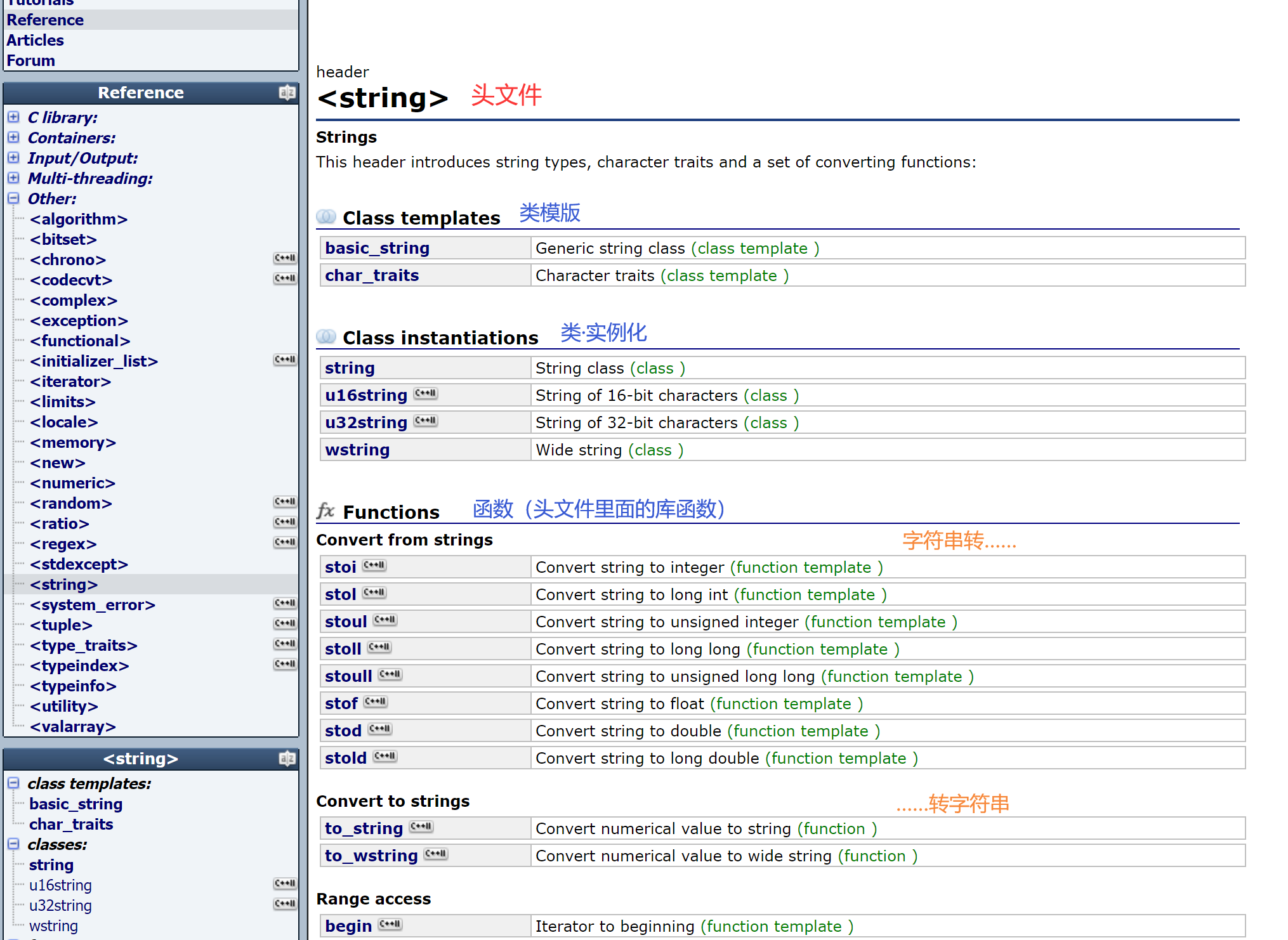
C语言的字符串转整型是用atoi。
C++也有现成的库函数:string_to_int、string_to_long、string_to_unsignedlong……
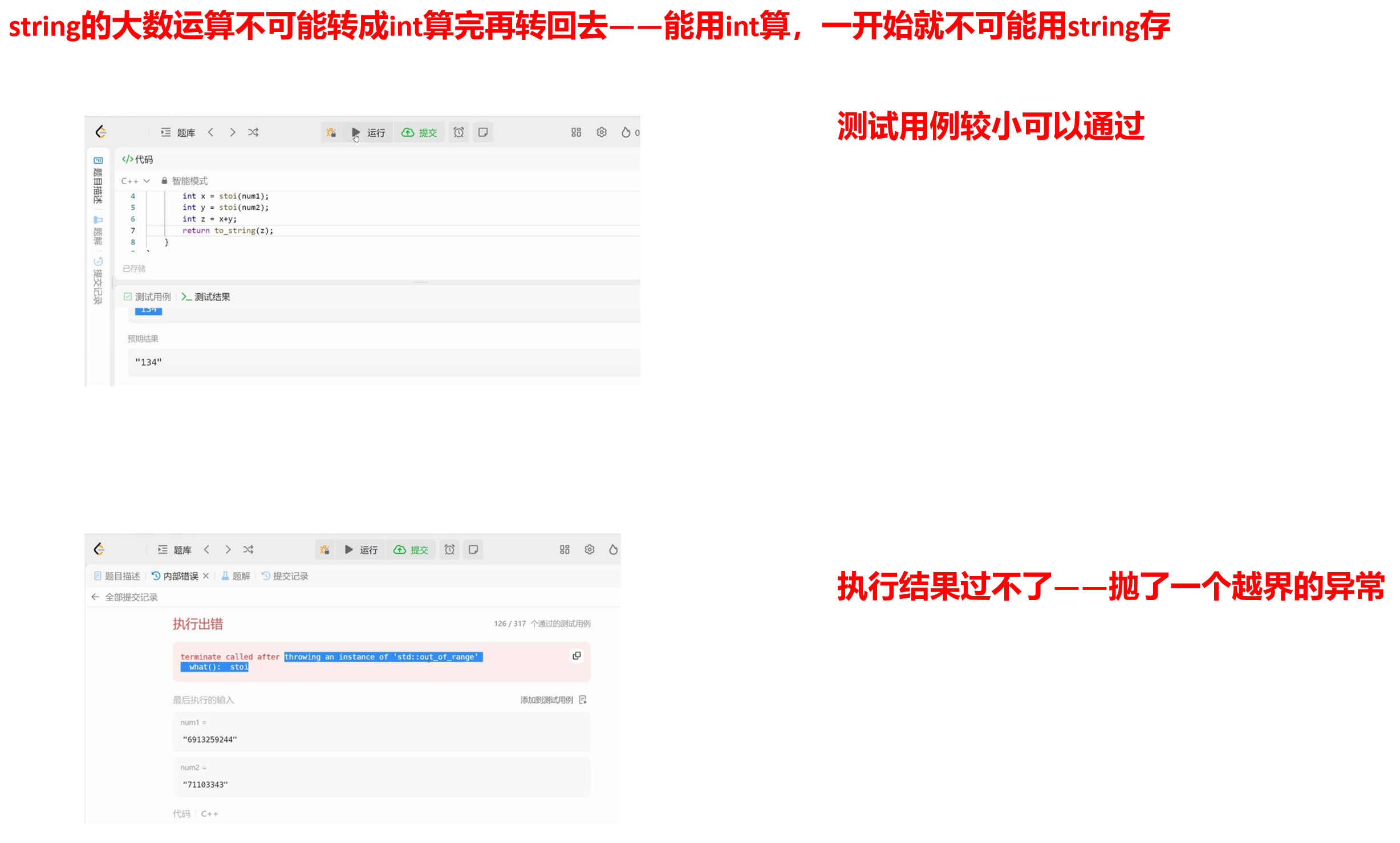
注意:字符串转整型有可能存在整型溢出的问题——存不下。
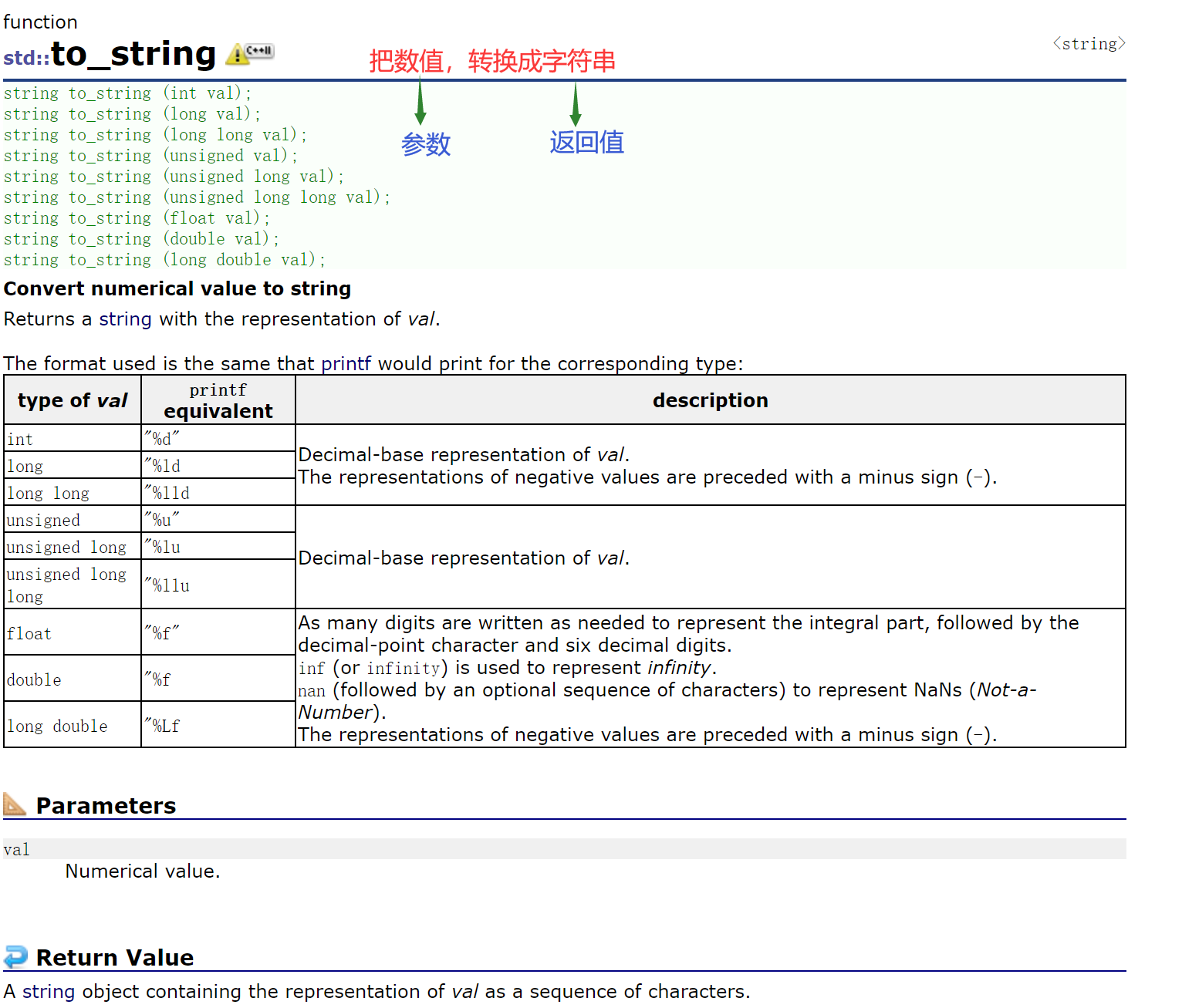
OJ题“大数运算”不能转成int来算。
2.2.9 OJ练习
(1)仅仅反转字母
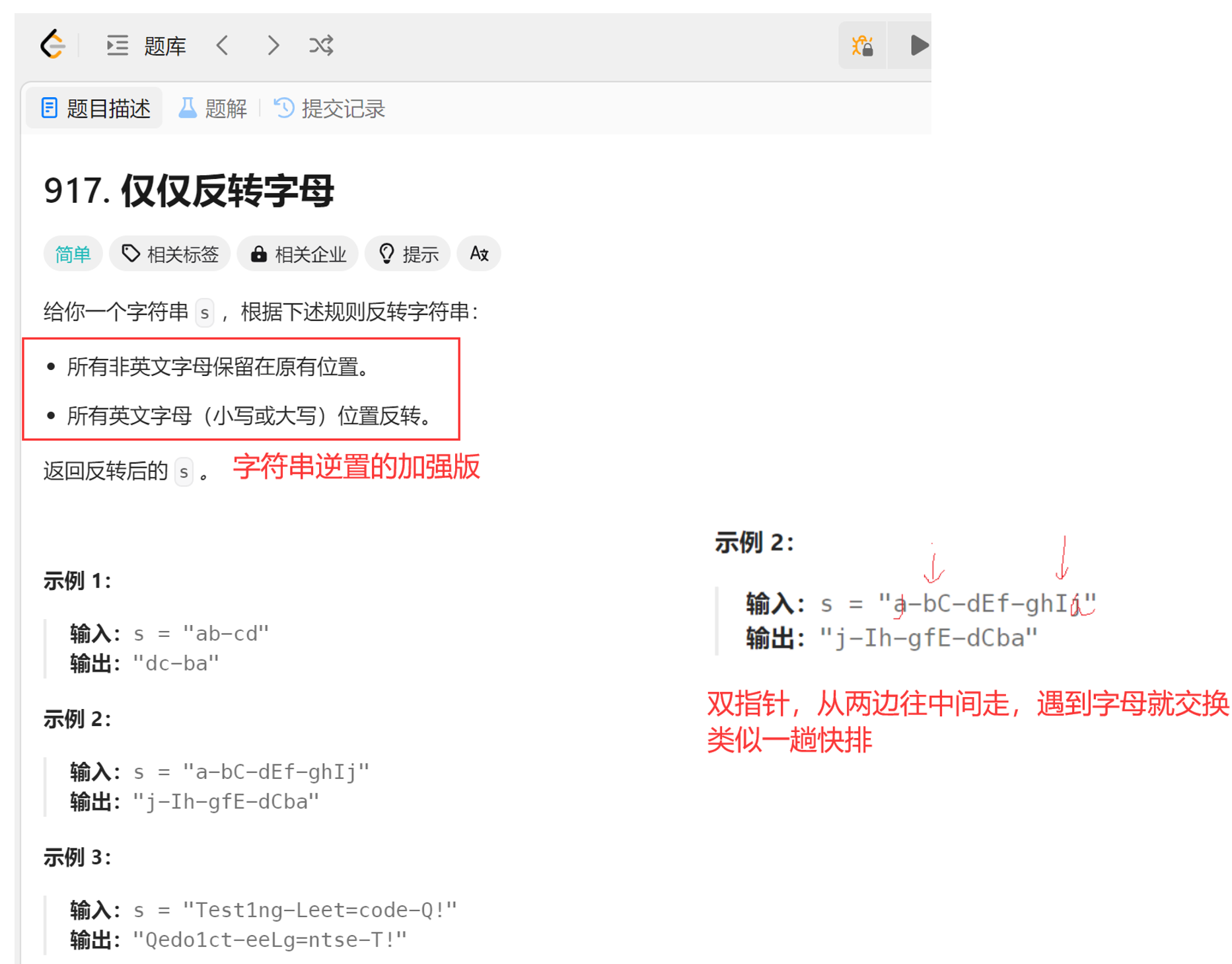
经典的左右双指针法的应用就是单趟快排。
(单趟快排只能确定一个key的位置,之后还要递归调用)
这里一趟左右双指针法跑完,题目的要求就完成了。
class Solution {
public://判断是字母bool isLetter(char ch){if(ch >= 'a' && ch <= 'z')return true;if(ch >= 'A' && ch <= 'Z')return true;return false;}string reverseOnlyLetters(string S) {if(S.empty())return S;//和快排一样,左边0,右边size-1,快排右边先走因为左边作key,这里哪边先走都可以size_t begin = 0, end = S.size()-1;while(begin < end){ //不是字母,left一直往右走 while(begin < end && !isLetter(S[begin]))++begin;//不是字母,right一直往左走 while(begin < end && !isLetter(S[end]))--end;//是字母,则交换完再继续走 //交换——当begin和end在同一位置,交换也没事,下面直接就能出循环了swap(S[begin], S[end]);++begin;--end;}return S;}
}【说明】
- 交换可以用下标+[],也可以用迭代器。
- 使用迭代器要注意:left=begin(),right=end()-1,注意right不要用rbegin——类型不一样,不能比较。
(2)找字符串中第一个只出现一次的字符
力扣(接口型)、牛客(IO型)
找单身狗是整型数组(异或法),这道题是字符数组。
这道题的要求还是找第一个唯一字符,说明可能有多个唯一字符。
异或还有一个缺陷就是只能解决重复元素的重复次数为偶次的场景,当重复元素的重复次数为奇次时,异或也是不适用的。
【思路】
- 异或——有较大的局限性,在这里不适用。
① 有多个唯一字符的时候,不适用;
② 异或只适用于偶数个重复——如成对重复,奇数个重复用不了。- 暴力查找——可以用,效率极低——O(N^2)。
- 统计字符出现次数——映射,类比计数排序的思想(适合范围集中的),这里字符最多256个,更何况这里只包含小写字母,范围集中。【建立映射的思想】
统计完次数,如何找第一个只出现1次的字母?
思路1:去看计数数组里的第一个1对应的元素——>不行。

上图第一个1是a,但是a不是第一个只出现一次的,所以不能按计数数组里的顺序找第一个1。
思路2:按字符串的顺序,从头到尾遍历字符串,去对应看计数数组的出现的第一个1。
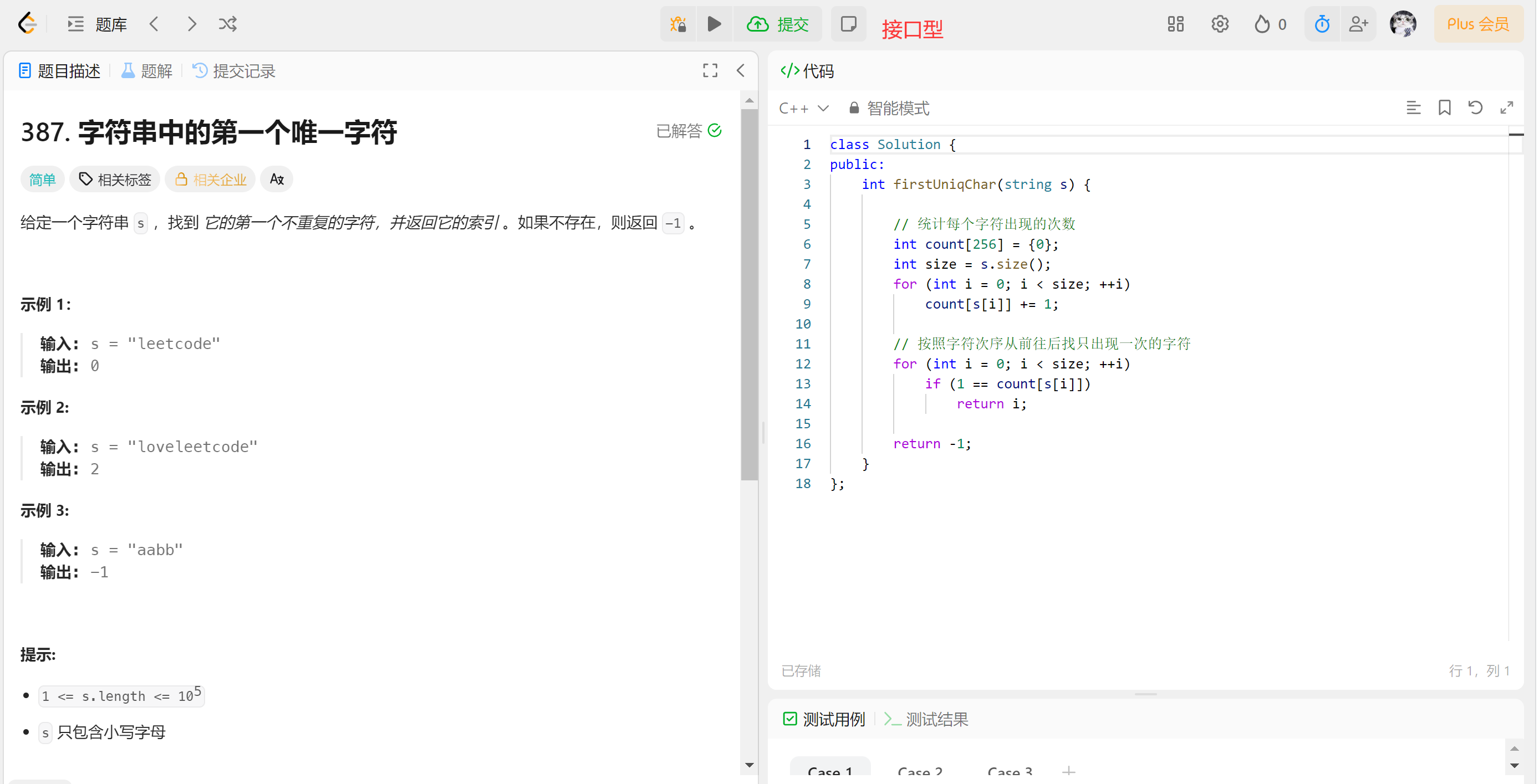
这道题要求返回索引(下标),所以第2个for循环不能用范围for。

接口型的OJ题更简单,只需要写一个接口函数。
IO型的OJ题比较复杂,要写完整的测试代码。
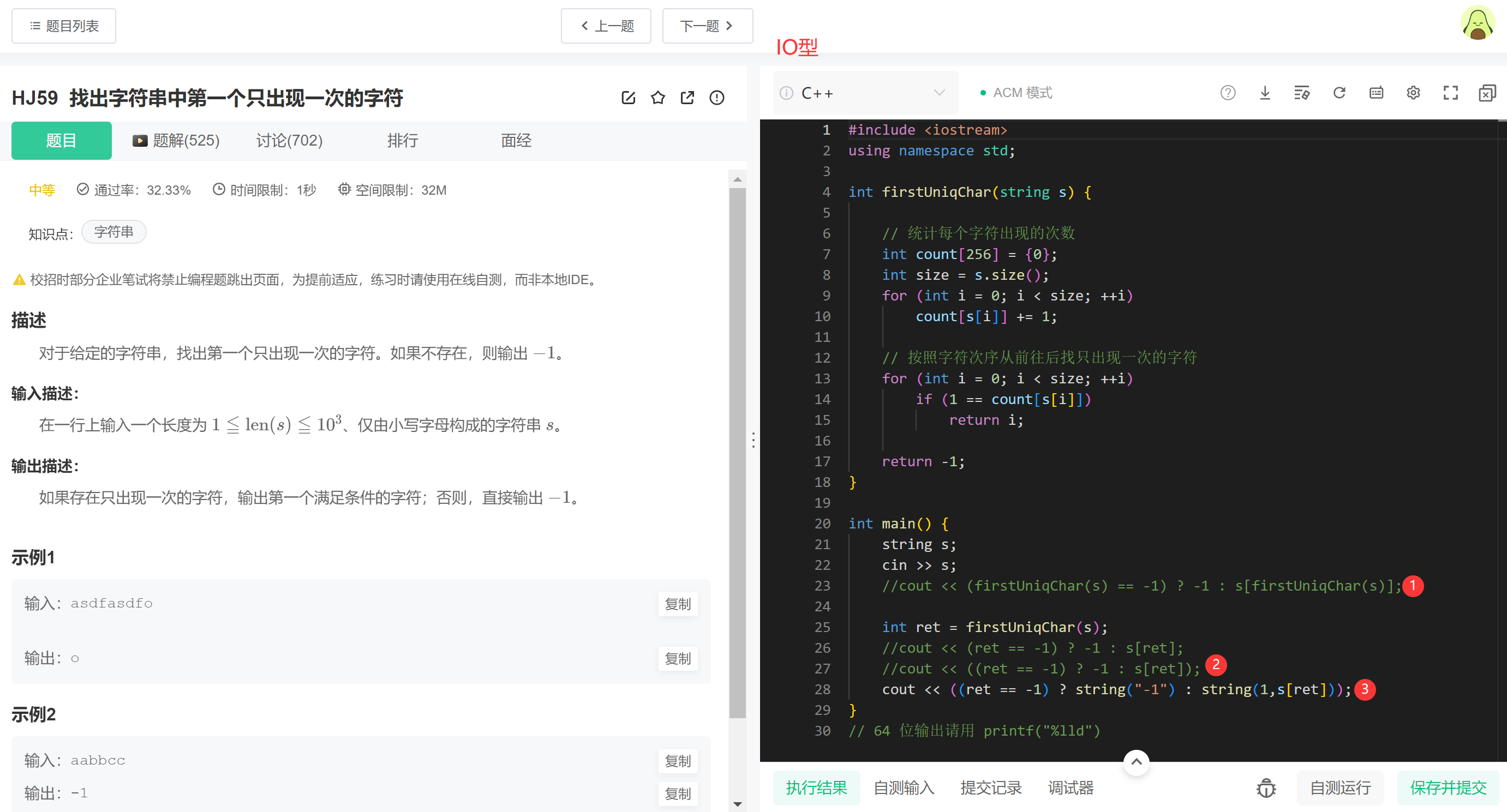
【说明】
- ①:连续的“判断+输出”,最好创建一个变量接收函数的返回值;不然有两个麻烦:
- 第一个麻烦就是会进行两次函数调用,有不必要的多一次消耗。
- 第二个麻烦就是对于记忆性的函数调用,第二次函数调用的结果不一样时就会出错
- ②:要注意操作符的优先级,最好加个括号,否则一直输出0(cout << ret == -1)
- ③:三目操作符的经典陷阱。

(3)字符串里面最后一个单词的长度
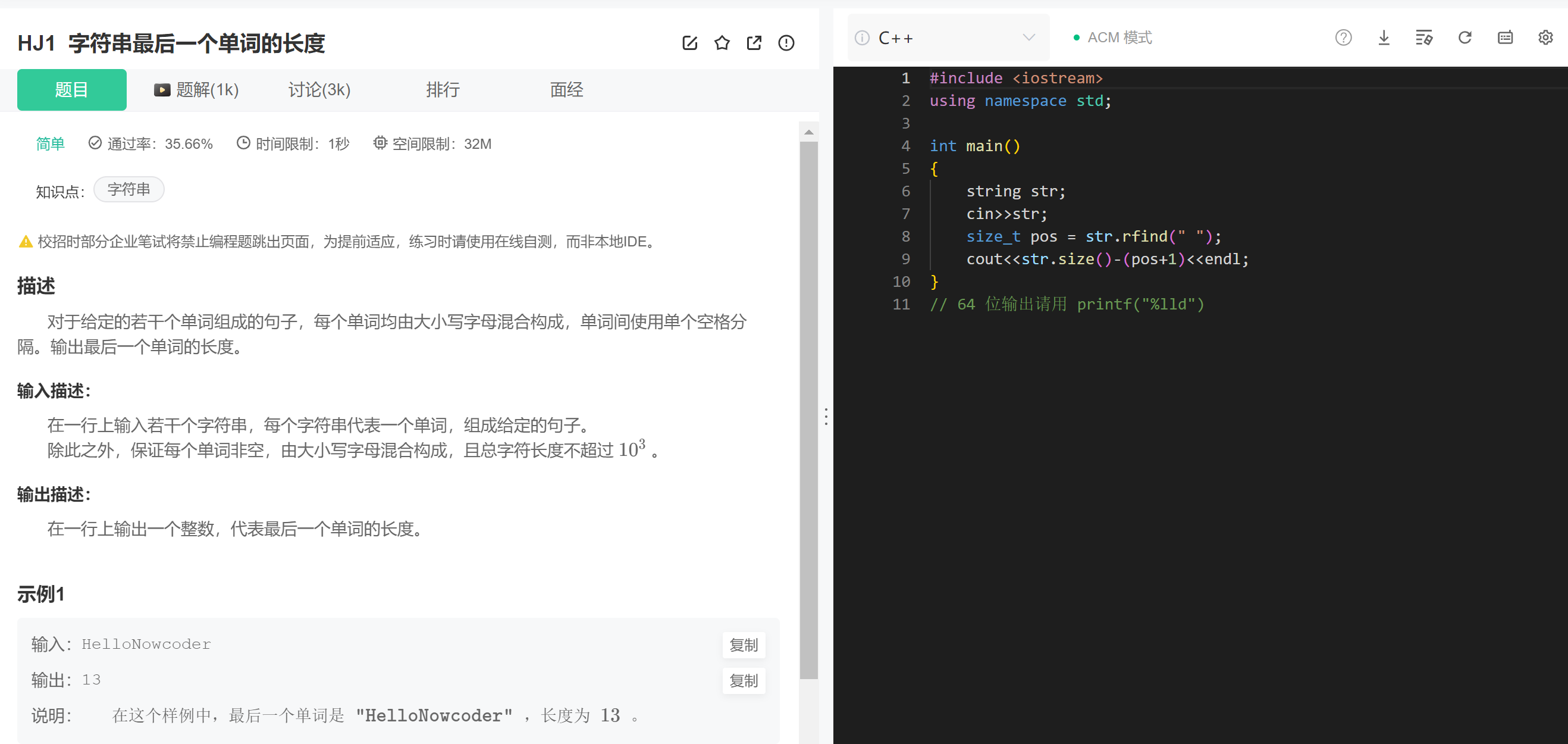
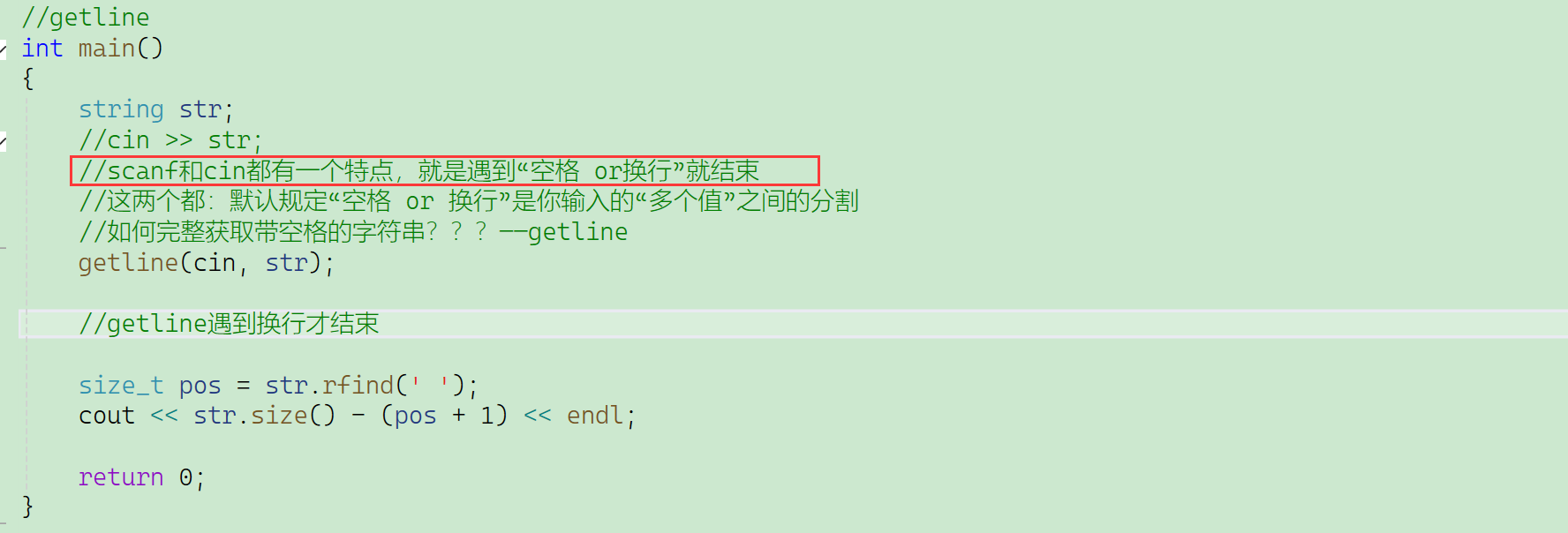
跟之前的找字符串后缀类似。(倒着找)
#include<iostream>
#include<string>
using namespace std;
int main()
{string line; //存储流插入的数据// 不要使用cin>>line,因为会它遇到空格就结束了// while(cin>>line)while(getline(cin, line)) {size_t pos = line.rfind(' '); //倒着找空格cout << line.size() - (pos + 1) <<endl;}return 0;
}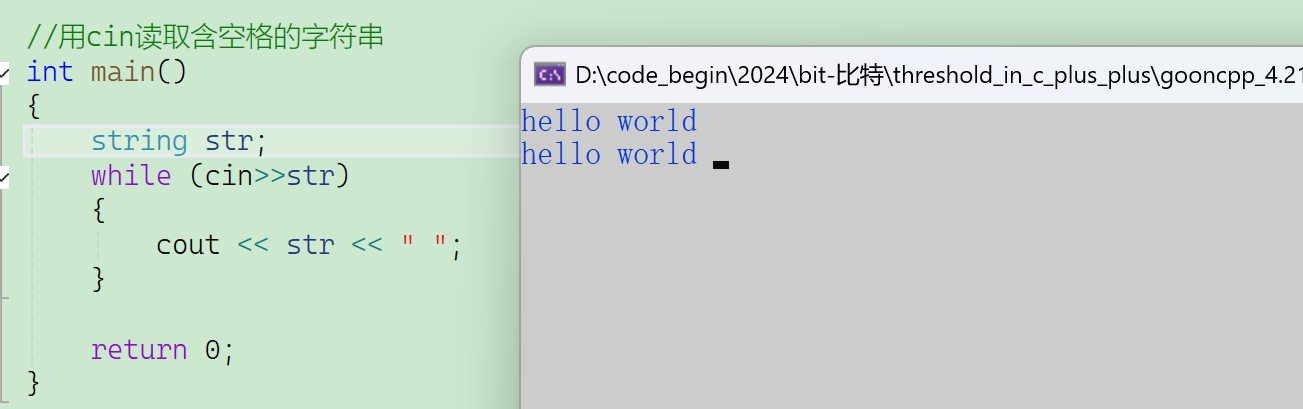
- 空格和换行都会导致cin读取结束。
- 一敲换行就下来了。
- 但是敲空格不会马上下来,cin不会马上去读。
- 刷新缓冲去读取数据,的标志是换行,空格不会,但是空格是默认的分割符。
- 按换行,刷新缓冲区之前,还能移动光标位置、删除控制台以打出来的字符、……
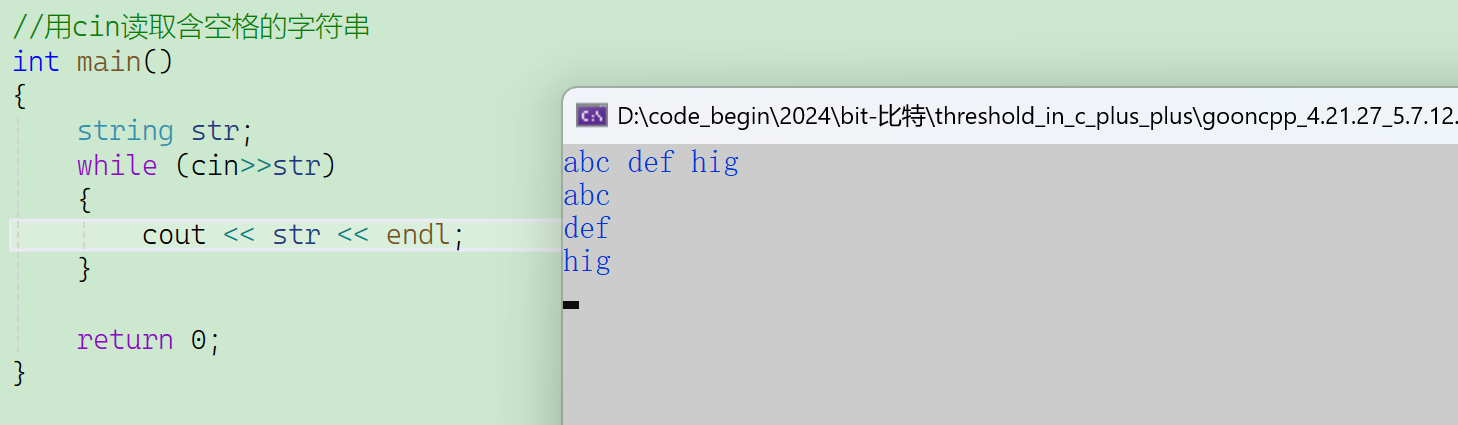
循环结束方式①:Ctrl+z、回车

循环结束方式②:Ctrl+C(杀进程)

(4)验证一个字符串是否是回文

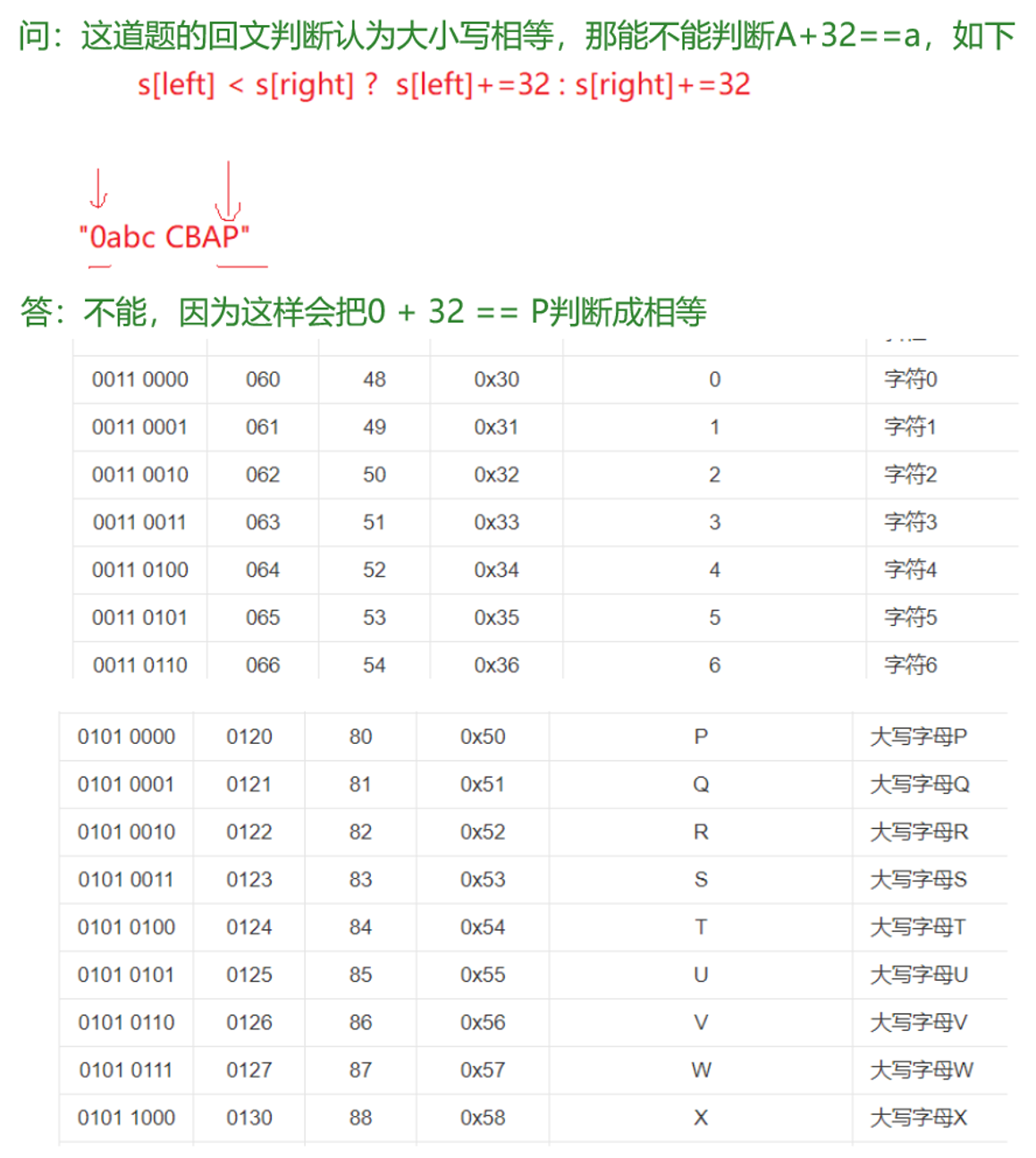
只有字母才是小的+32==大的,用来判断大小写。
所以想用那个三目判断,还要先判断小的是字母。
class Solution {
public://判断是:字母、数字bool isLetterOrNumber(char ch) {return (ch >= '0' && ch <= '9')|| (ch >= 'a' && ch <= 'z')|| (ch >= 'A' && ch <= 'Z');}bool isPalindrome(string s) {// 先遍历string,把小写字母转换成大写,再进行判断(或大→小)for(auto& ch : s){if(ch >= 'a' && ch <= 'z')ch -= 32;}//for(auto& ch : s){// if(ch >= 'A’&& ch <= 'Z')// ch += 32;//}//遍历把大写全部转换成小写——范围for的参数加个&,可修改//不用判断“大写 == 小写”,直接全部转换成大写(小写),然后判断相等int begin = 0, end = s.size()-1;while(begin < end){while(begin < end && !isLetterOrNumber(s[begin]))++begin;while(begin < end && !isLetterOrNumber(s[end]))--end;if(s[begin] != s[end]) //直接判断是不是都是大写(小写)、同一个数字{return false;}else{++begin;--end;}}return true;}
};(5)字符串相加
这道题是大数运算的一部分。
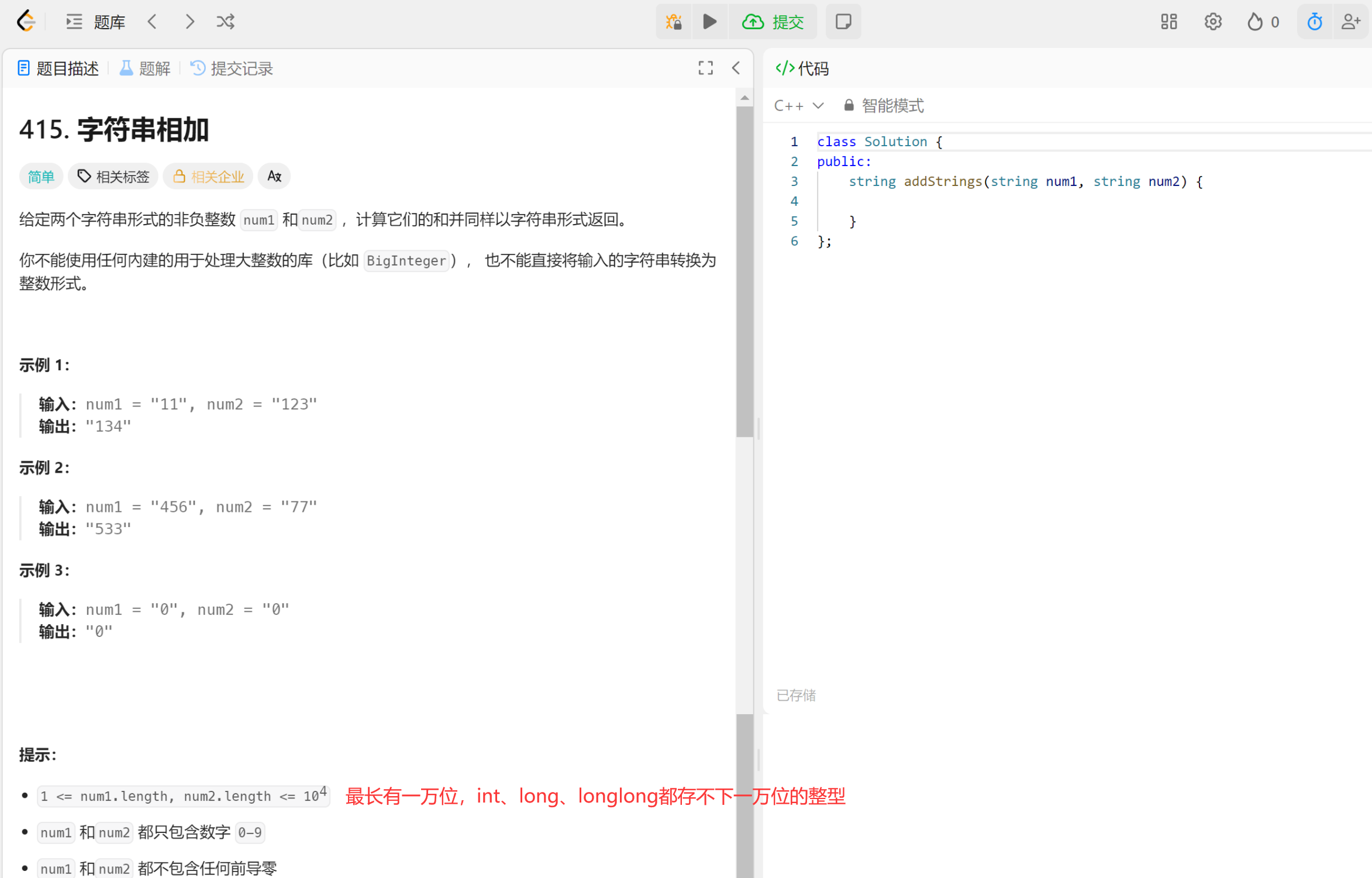

字符串的加减法,很滑稽的思路是使用atoi(),算完在itoa()——这道题本来就是int存不下才转换成string。
使用string的遍历之处:
- 方便遍历
- 加完的结果存入ret_string,若是C语言解就需要在计算之前,预开好用于存储结果的空间,但是不确定具体开多少合适。(加法还好,加完最多多开一位的空间,乘法就不好开了)
class Solution {
public:string addstrings(string num1, string num2) {// 找到个位,从后往前相加// 相加的结果到字符串可以使用insert头插// 或者+=尾插以后再reverse过来//下标变量(位置变量)——使用下标比迭代器更好操控int end1 = num1.size()-1;int end2 = num2.size()-1;int value1 = 0, value2 = 0, next = 0; //保存进位值的变量string addret;while(end1 >= 0 || end2 >= 0) //长的字符串结束,加法才结束,短的字符串结束,加法继续{//value1 = num1[end1]//value2 = num1[end2] //不能直取字符,要转换成对应的数字,还要注意迭代,还要注意先判断字符串还没结束再取if(end1 >= 0)value1 = num1[end1--]-'0'; //char→intelsevalue1 = 0; //短的结束了,要取0给长的字符串继续加(或者直接给短的把前面的0全部补上)if(end2 >= 0)value2 = num2[end2--]-'0';elsevalue2 = 0;//取各位置的数据,求该位的和(注意加上进位值) //value1 = end1 >= 0 ? num1[end1--] - '0' : 0;//后置--是返回--之前的值//value2 = end2 >= 0 ? num2[end2--] - '0' : 0;//在里面--的好处是end小于0就直接走数字0,就不减了,在外面减,就end<0之后还会继续减//求和int valueret = value1 + value2 + next; //处理进位——在下一次循环发挥作用if(valueret > 9){next = 1;valueret -= 10;}else{next = 0;}//处理进位,两句代码就够了——不用判断//next = valueret / 10; 商//valueret = valueret % 10; 余数//string的头插一个字符——没有直接的(0,'0'+valueret)的调用方法,有以下两种写法//addret.insert(0, 1, valueret+'0'); //这种可读性不如下一行那种//addret.insert(addret.begin(), valueret+'0'); //int→char//连续头插,每次挪动的次数成等差数列//尾插+reverseaddret += (valueret+'0');}//处理最高位的进位if(next == 1){//头插//addret.insert(addret.begin(), '1');//尾插addret += '1';}//若是头插,就不用;若是尾插,就需要reversereverse(addret.begin(), addret.end());return addret;}
};【总结】
- 从后往前遍历计算;
- 位置变量 & 接收变量,str变量,进位变量;
- 循环结束条件;
- 如何接收数据;
- 迭代——在什么位置;
- char<——>int转换;
- 处理进位;
- 取和,头插;
- 处理最后的进位;
- 时间复杂度;
原本时间复杂度是O(N)——遍历,取值,求和。
但是头插把时间复杂度拉到O(N^2)。
更好的方式是尾插+逆置——时间复杂度O(N)。
reverse在算法头文件里面。
这是个模版函数,可以传任意类的迭代器。(通用模版函数)
优化:
其他思路:提前开好空间,然后使用下标访问的方式存储每一位的和。
思路分析:不太好,只有算完了才知道是不是会多一位,要是没多还得往前挪一位。
思路分析:再者而言加法还好,对于乘法就不适用了。
思路分析:这样子的优化也不能用reserve,要用resize。
(6)翻转字符串II:区间部分翻转
……
(7)翻转字符串III:翻转字符串中的单词
……
(8)字符串相乘
……
x. 编码
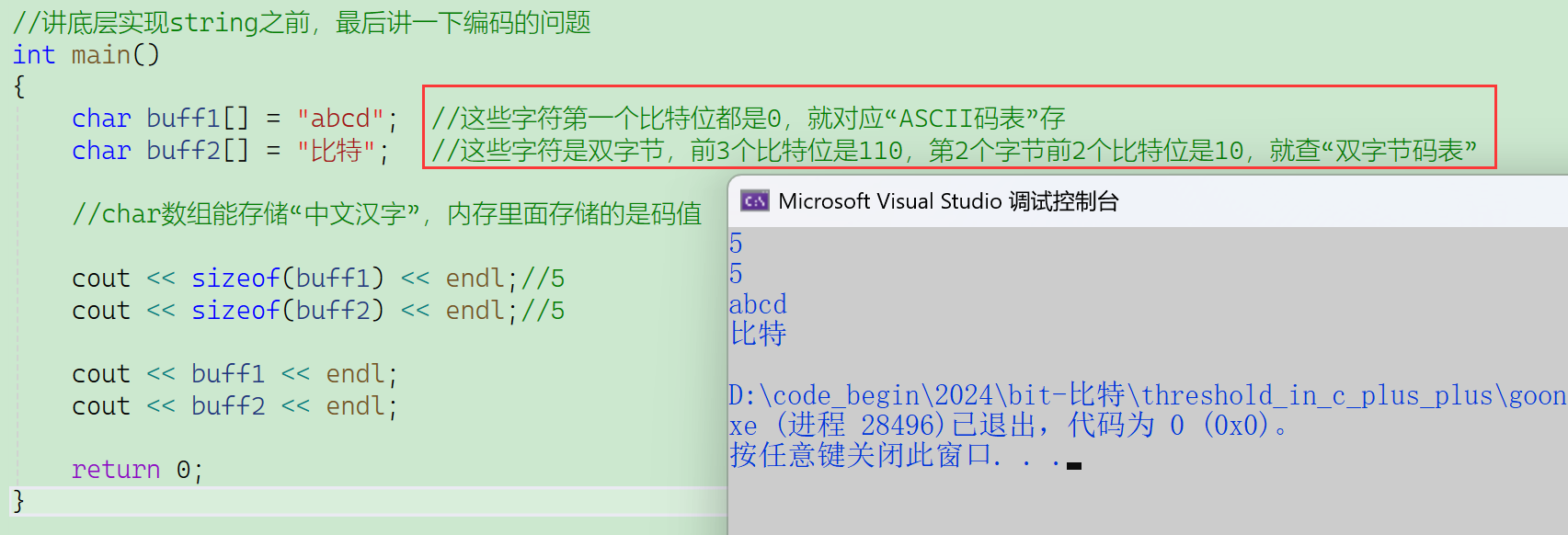
- buff1内存里存的不是字符,是ASICC码;
- buff2里面也是存的编码——负码;
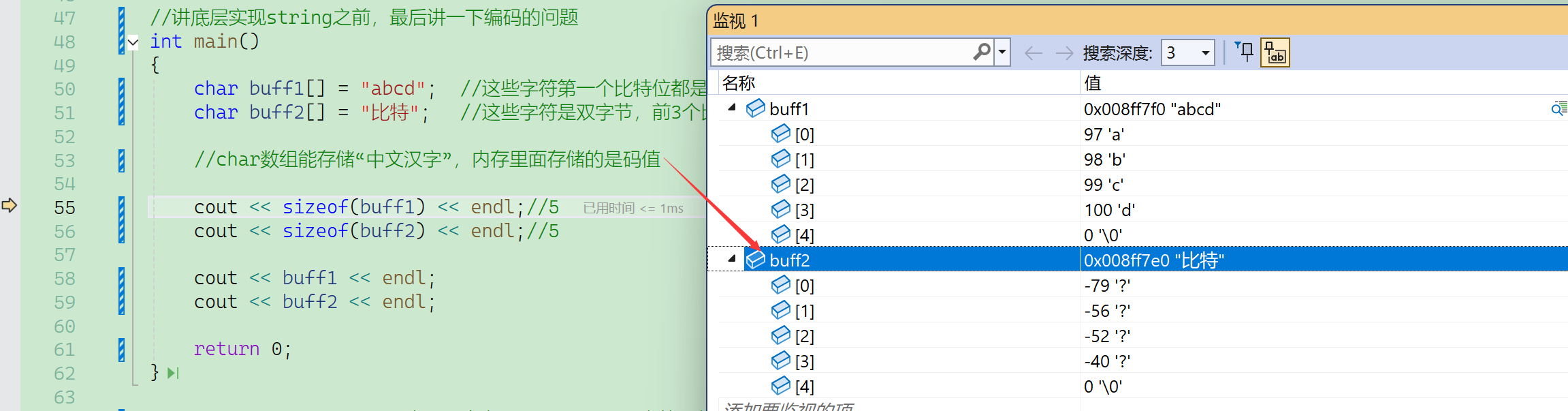
监视的对应行的值97旁边的'a'只是方便观察内容。
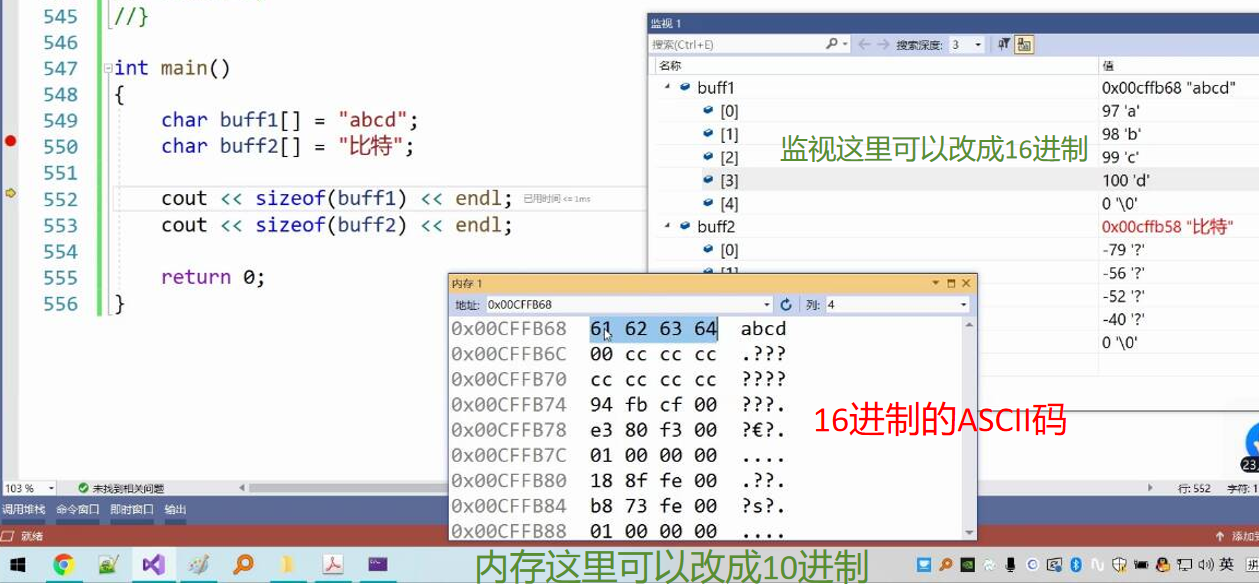
从最真实的内存窗口来看,只存储了97(十六进制61)。
最开始发明计算机的先驱,希望在计算机中表示文字——只考虑英文,面临的2个问题:
- 文字怎么存储?
- 文字怎么表示?
计算机中只有“0、1”两种信号,怎么表示文字?
美国使用的文字系统:字母abcd……、数字1234……、特殊符号><&%#……合计100+。
于是想到给每一个“符号”一串“二进制代码”,这个过程就叫 编码 。
(映射:一串码值,对应一个具体的符号)
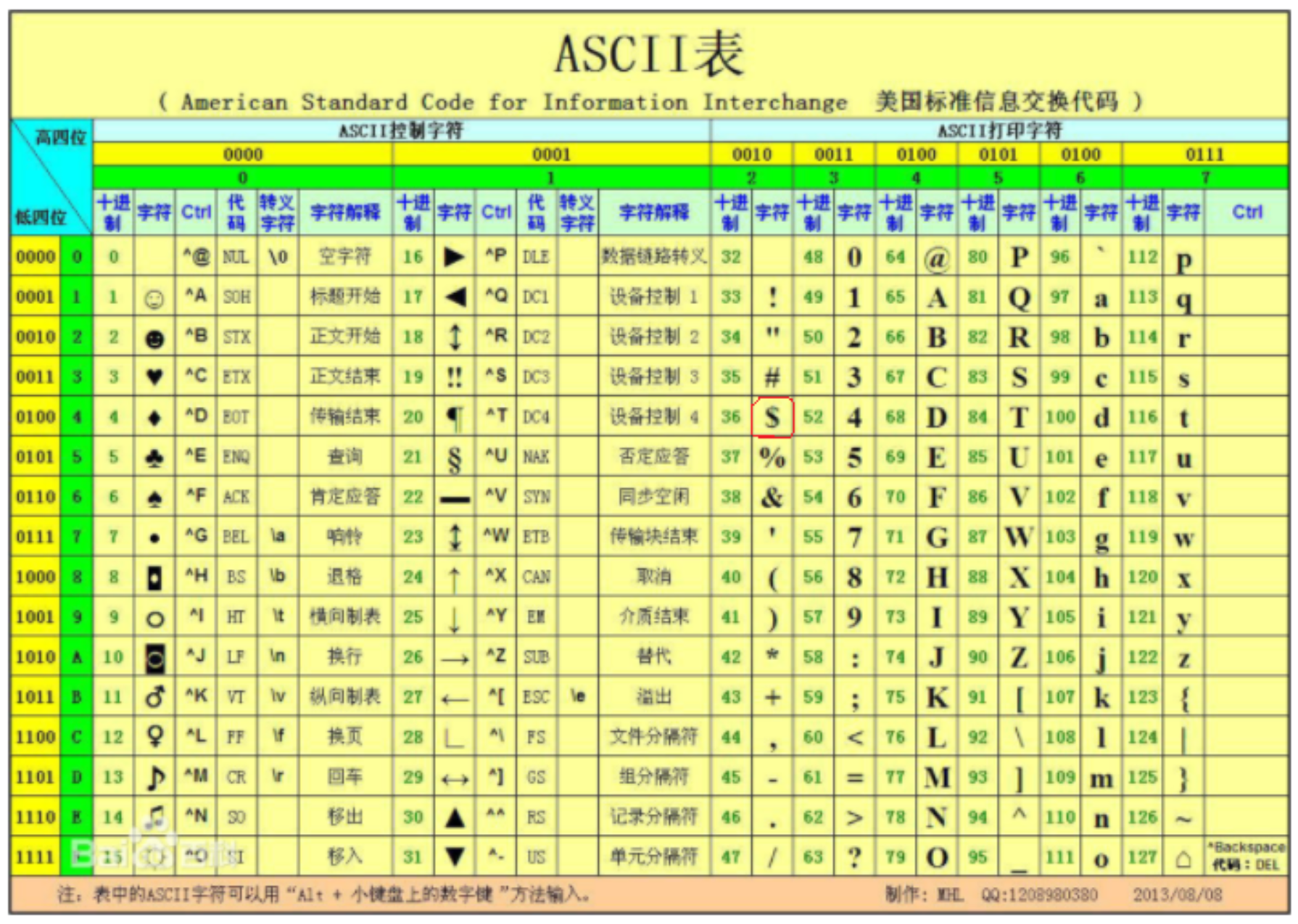
于是形成了 编码表 。最早产生的编码表就是 ASCII编码表 。
![]()
- 在内存中存储的是二进制数字编码,在显示器上显示的是对应编码映射的字符。
这个数字编码的范围是:0~127,128个数字——7位二进制,就能完成对美国文字体系的编码。
早期的计算机只在英美使用,后来要加入表示世界各国的文字、符号,就需要新的编码表。
这时就产生了 Unicode(万国码)。

有3套编码方案:
- UTF-8
- UTF16
- UTF32


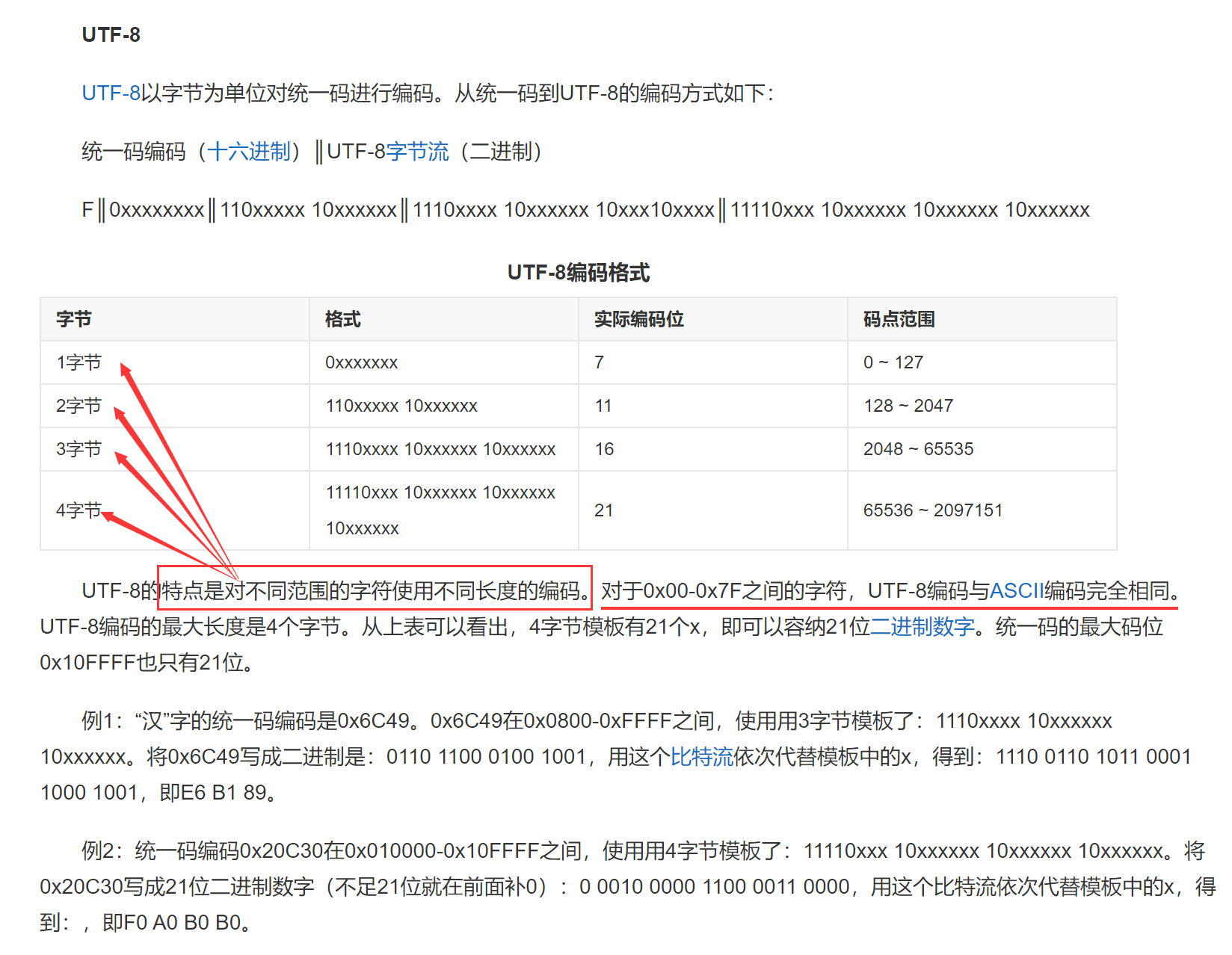
【UTF-8的特点】
- 变长编码;
- 兼容ASCII;
注1:基于这两个特点,UTF-8是最常用的“非ASCII”编码。
注2:linux下的默认编码就是UTF-8。
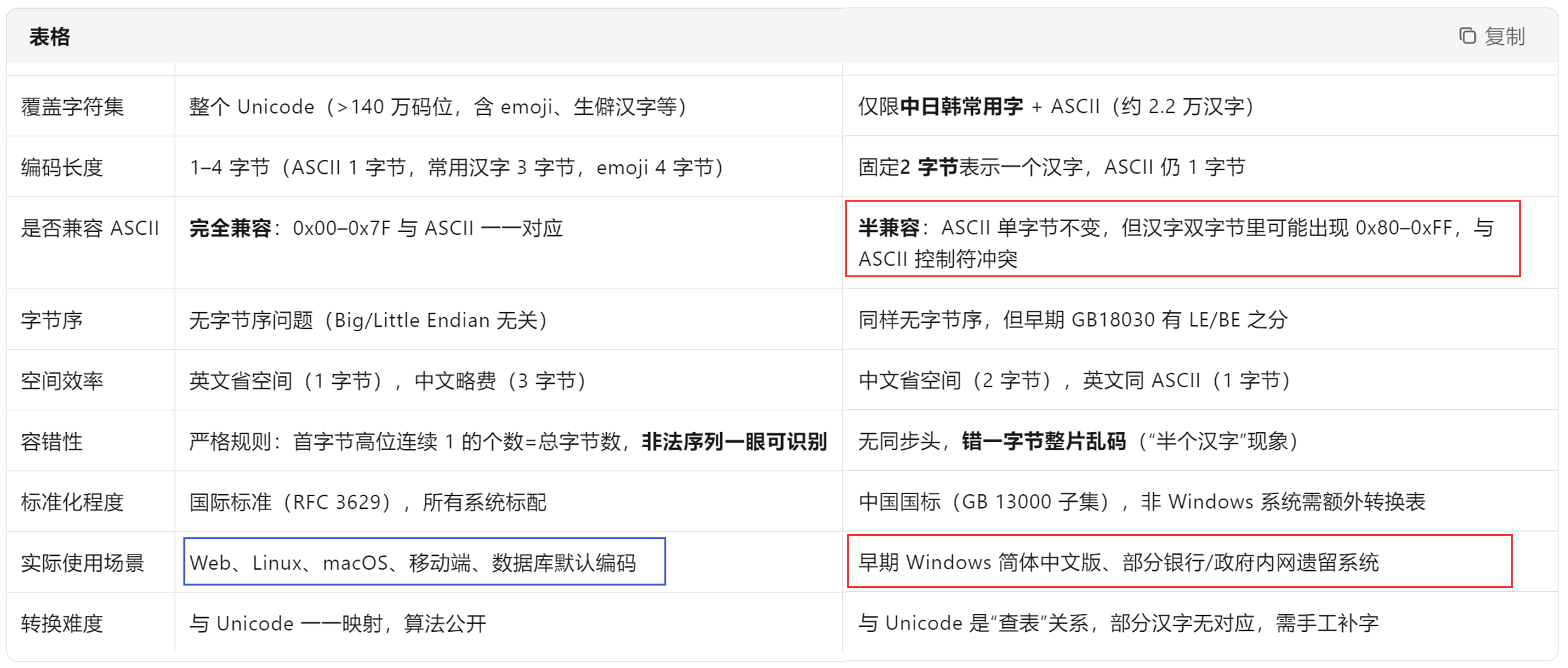
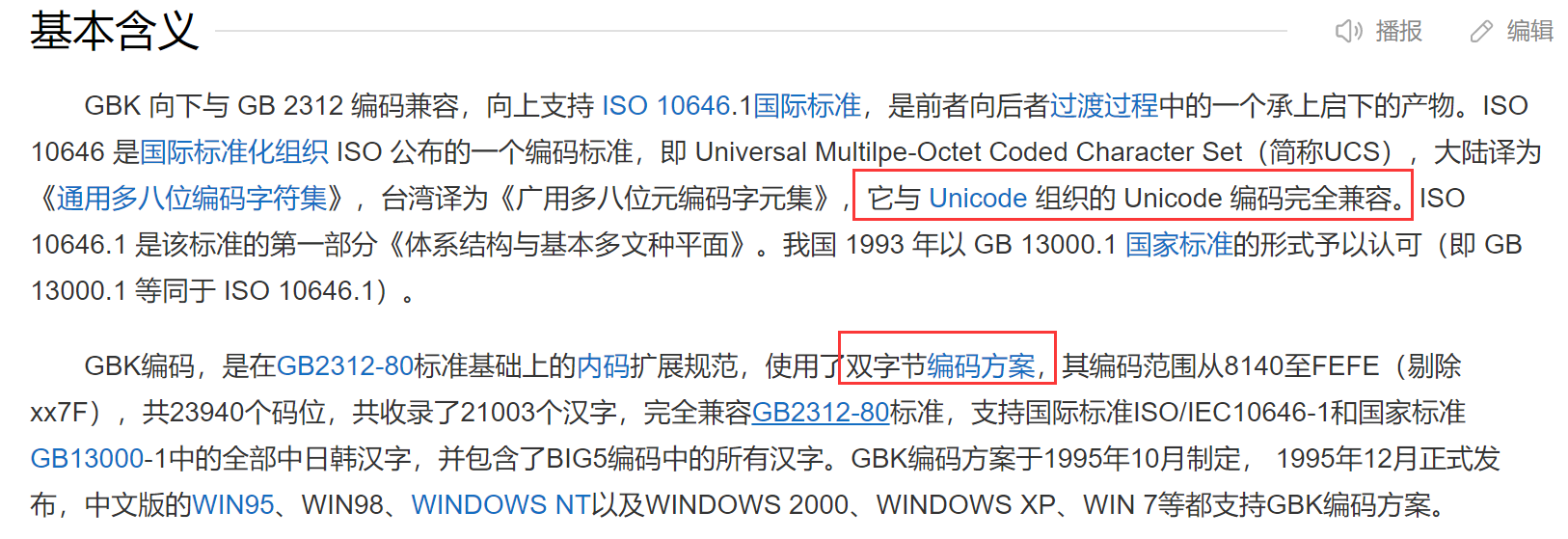
注3:windows默认是GBK。(汉化版)
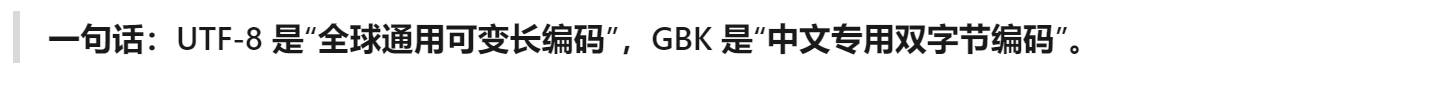


UTF-8的变长编码:
- 如果是1个字节:第一个比特位是0(标识位),实际编码位是7个,执行ASCII码对应关系
- 如果是2个字节:第一字节前3个比特位是110,第二字节前两个比特位是10,实际编码位是11个,执行2字节码表。
- 以此类推……
如此:
常见的汉字(约2000个)编成双字节,不那么常见的编成三字节,再不那么常见的编成四字节

大部分国家的文字都可以用双字节编码覆盖。(256*256 = 65535)
UTF-8是支持全世界文字的编码系统,对中国文字体系的支持并没有特别完善,一些不常用的字支持得不是特别好,于是中国出了自己的编码标准GBK。

- UTF-8针对不同情况有1字节、2字节、3字节、4字节不同的编码表;
- UTF-16就是定长2字节编码;
- UTF-32就是定长4字节编码;

- UTF-16和UTF-32的存储成本都比较高,实践中用得比较少。

- string本质就是basic_string<char>(类型重命名)
有时候会看到typedef那个位置是using,这是把using这个关键字又重新定义了一种用法,在这里和typedef是同一个含义,极个别地方using有一些些的好处。

string默认支持UTF-8编码,但是:
无论编码如何,
string的所有操作(如length()、迭代器等)都以字节为单位,不会考虑字符的实际编码边界。


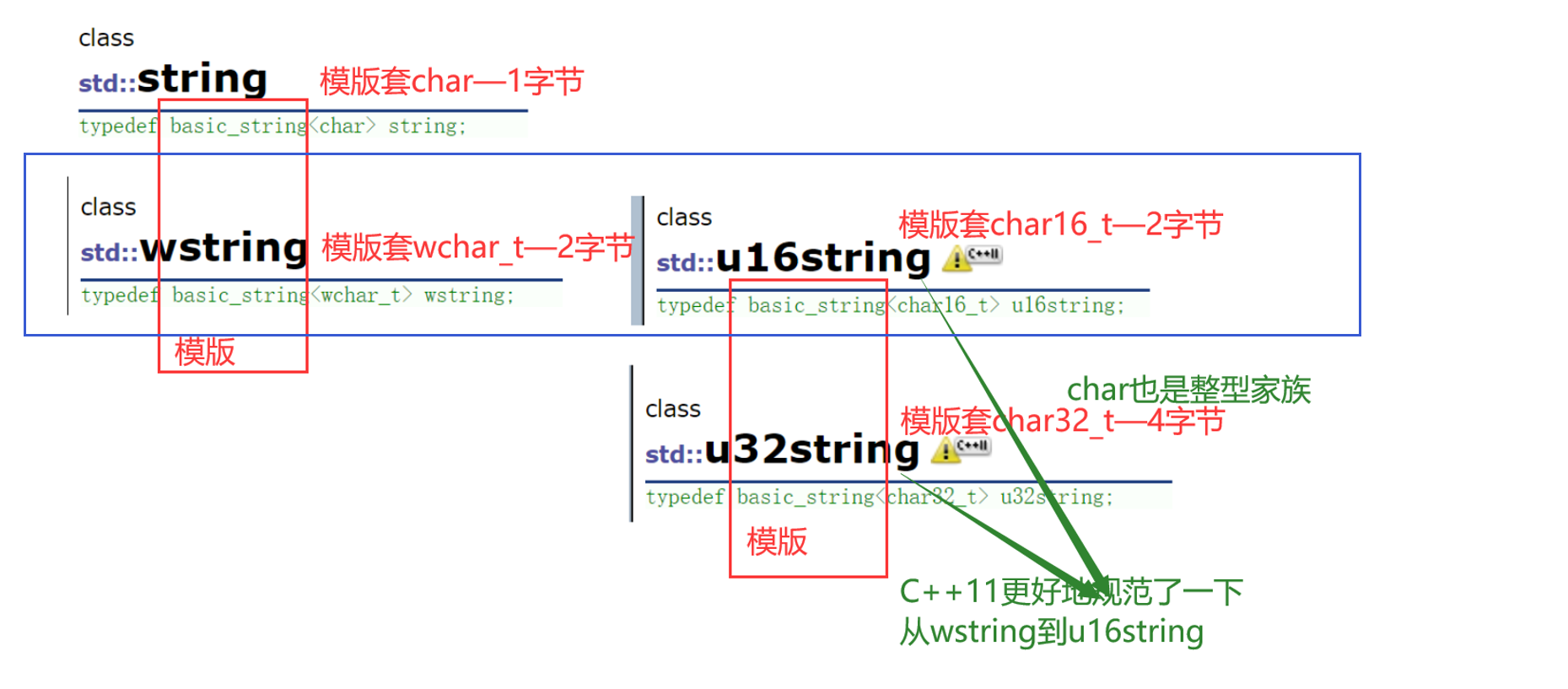
c++98只有string、wstring(存储宽字符),c++11新增u16string、u32string。
总结:计算机底层存储的还是0-1序列,只是说按哪种编码方式去存,显式的时候就按哪种编码方式去取。
ASCII值就是字符在内存中按ASCII编码方式编码的对应存储值。
汉字在内存中按对应编码方式编码的对应存储值可能叫UTF-8值。