AI论文速读 | 当大语言模型遇上时间序列:大语言模型能否执行多步时间序列推理与推断
论文标题: When LLM Meets Time Series: Can LLMs Perform Multi-Step Time Series Reasoning and Inference
作者: Wen Ye, Jinbo Liu, Defu Cao, Wei Yang, Yan Liu
机构:南加州大学(USC)
论文链接:https://arxiv.org/abs/2509.01822
Cool Paper:https://papers.cool/arxiv/2509.01822
Code:https://github.com/USC-Melady/TSAIA
Hugging Face:https://huggingface.co/datasets/Melady/TSAIA
TL;DR:论文研究大语言模型(LLM)在时间序列分析中的表现,提出了TSAIA基准来评估LLM在多步推理和复杂任务中的能力。基准涵盖预测、诊断、分析和决策四大类任务,共33种任务类型。实验发现,尽管LLM在简单任务上表现尚可,但在复杂任务中普遍失败,显示出在多步推理、数值精度和约束满足方面的局限性。结果强调了开发专门方法以提升LLM在时间序列分析中的能力的必要性。
关键词:大语言模型、时间序列分析、多步推理、基准测试、人工智能助手

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
大型语言模型(LLMs)的快速发展引发了人们对其在时间序列分析任务中应用的日益浓厚的兴趣。然而,它们在现实世界应用领域中对时序数据进行复杂推理的能力仍有待深入探索。为实现这一目标,第一步是建立一个严谨的评估基准数据集。在这项工作中,本文引入了TSAIA基准,这是首次尝试将LLMs作为时间序列人工智能助手进行评估。为确保科学严谨性和实际相关性,作者们调研了20多篇学术论文,并确定了33种现实世界的任务设定。该基准涵盖了广泛的挑战,从具有约束感知的预测到带阈值校准的异常检测,这些任务都需要组合推理和多步骤时间序列分析。问题生成器设计为动态且可扩展的,支持在引入新数据集或任务类型时进行持续扩展。鉴于这些任务的异质性,本文采用特定于任务的成功标准和定制的推理质量指标,以确保对每个任务的评估都具有意义。应用该基准,在统一的评估协议下对八个最先进的LLMs进行了评估。分析揭示了当前模型在构建复杂时间序列分析工作流方面的能力局限性,强调了针对特定领域适配的专门方法的必要性。
Q: 这篇论文试图解决什么问题?
A: 论文旨在回答一个尚未被充分研究的核心问题:
当前的大语言模型(LLM)能否在真实世界场景中,像专业数据分析师一样,完成需要多步推理、数值精确计算、领域知识整合以及操作约束满足的时间序列全流程分析?
为回答该问题,论文提出并构建了 TSAIA Benchmark(Time Series Artificial Intelligence Assistant),其具体目标包括:
- 建立首个面向 LLM 的时间序列 AI 助手评测基准
现有评测要么只关注纯文本时间问答,要么局限于单一任务、固定窗口,缺乏对“复杂、端到端、约束感知”的真实工作流的覆盖。TSAIA 通过 33 种任务类型、1054 个实例,首次系统评估 LLM 在预测、诊断、分析、决策四大类任务上的综合能力。 - 揭示 LLM 在时间序列推理中的能力与局限
通过统一协议评测 8 个 SOTA 模型,发现:- 模型在单一、格式化的子任务上尚可,但在需要组合推理、数值精度、约束满足、阈值校准等复杂流程时普遍失败。
- 失败模式包括:执行错误、约束违反、低质量/平凡预测、无法整合参考样本等。
- 推动面向时间序列的 LLM 方法论研究
结果强调需要新的“混合范式”——将符号推理、执行反馈、领域对齐与 LLM 结合,才能构建真正可用的时间序列 AI 助手。TSAIA 为后续算法与系统研究提供了可扩展、可复现的评估基础。
Q: 有哪些相关研究?
A:与 TSAIA 相关的研究可分为三类:
- 时间序列专用基准(仅覆盖单一任务、静态数据集);
- 时间-文本混合基准(引入文本上下文但仍为固定任务);
- 纯文本时间推理基准(无真实数值序列)。
下表列出代表性工作及其与 TSAIA 的对比维度(✓=具备,✗=缺)
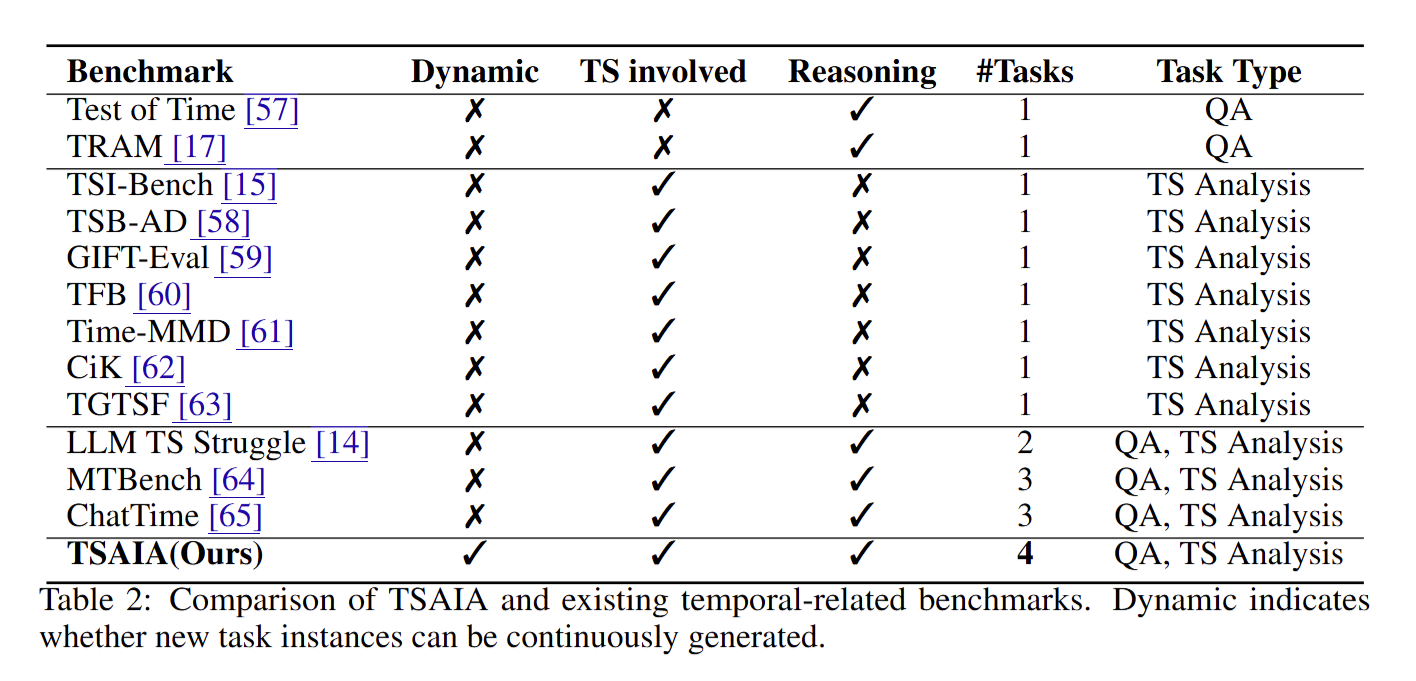
此外,下列工作虽不直接提供基准,但启发了 TSAIA 的任务设计:
- 约束预测:电力系统最大负荷与爬坡率限制 [32, 33, 34]
- 异常检测:利用参考样本校准阈值 [8, 35, 36]
- 因果发现:结合领域先验的图推理 [38]
- 金融分析:风险-收益指标计算与投资组合选择 [39, 43, 44]
Q: 论文如何解决这个问题?
通过构建一套系统化、可扩展的评测框架(TSAIA Benchmark)来“诊断”现有 LLM 在时间序列复杂推理中的瓶颈,从而为后续方法研究指明方向。具体解决路径分为三步:
1. 任务与数据层:把真实需求形式化
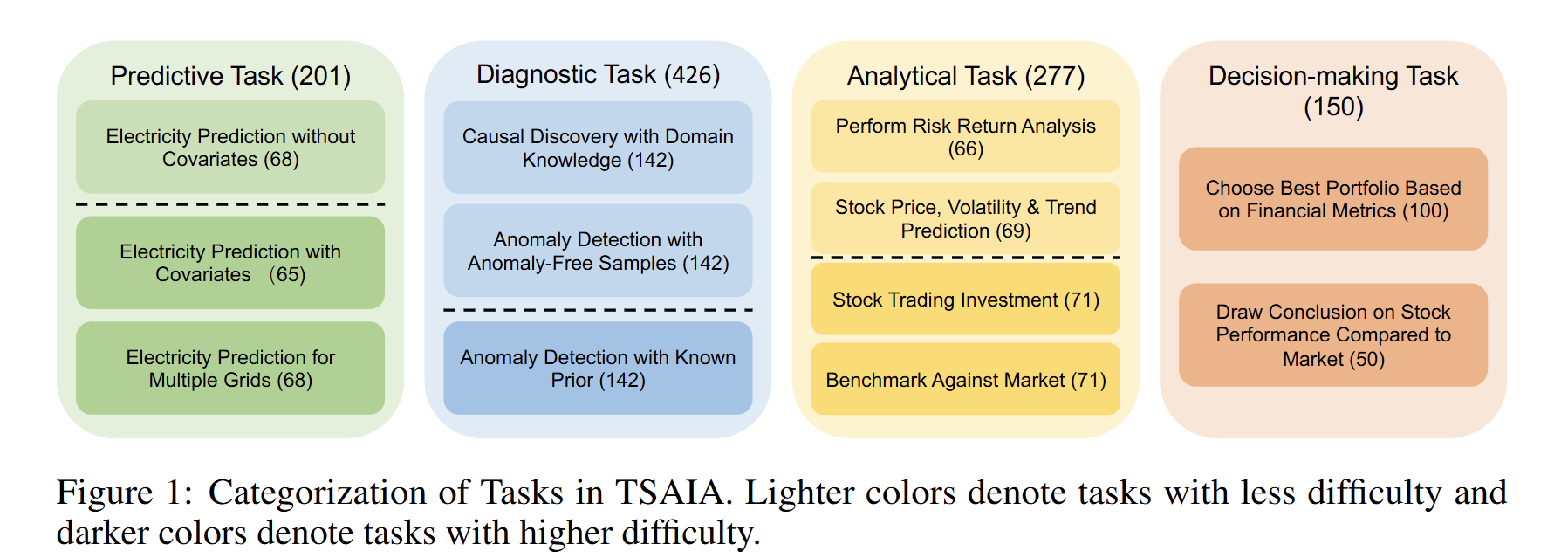
- 调研 → 抽象 → 模板化
调研 20 + 篇跨领域文献,提炼 33 种真实场景任务模板(预测 / 诊断 / 分析 / 决策)。 - 动态实例生成器
五步骤流水线(任务类型 → 数据源采样 → 上下文参数化 → 约束/知识注入 → 真值构造),支持持续扩展新数据集或任务。 - 多域数据整合
覆盖能源、气候、金融、医疗等公开数据集,确保任务实例具备领域知识与操作约束。
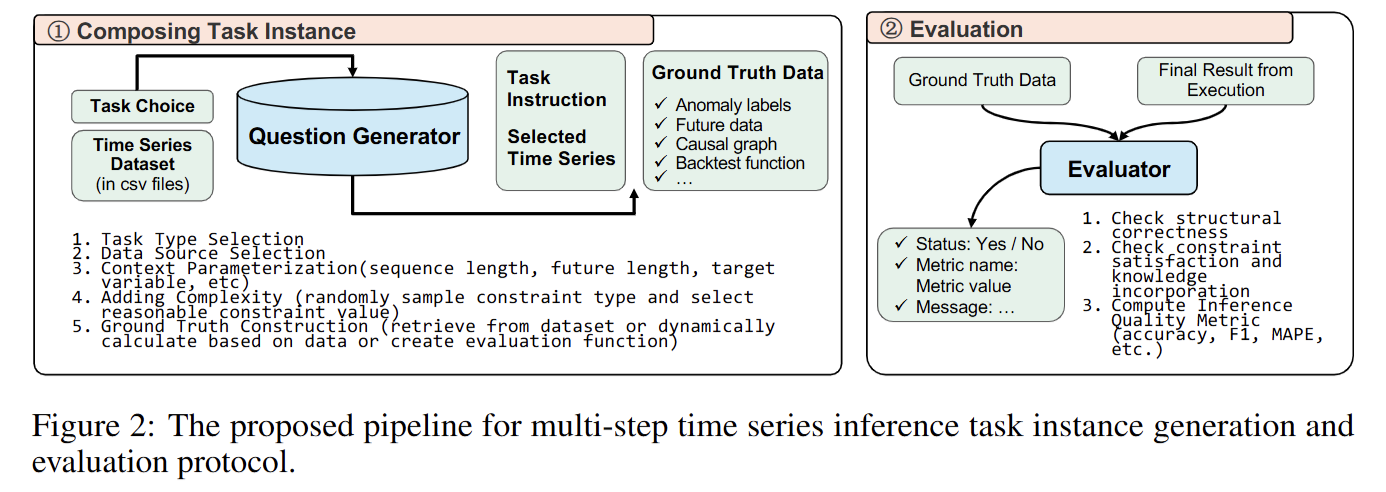
2. 评测层:为异构任务定制统一协议
- 任务专用成功准则
每类任务定义“格式正确 + 约束满足 + 非平凡输出”三重门槛(见 Table 1)。 - 三级评估流程
① 结构/格式检查 → ② 约束与领域知识验证 → ③ 任务特定质量指标(MAPE、F1、绝对误差、回测收益等)。 - 失败模式分类
执行错误 / 约束违反 / 低质量预测,便于后续针对性改进。

3. 实验层:用统一 CodeAct 框架评测 8 个 SOTA LLM
- CodeAct 代理机制
让模型生成可执行 Python 代码,通过执行-反馈-迭代方式绕过长序列输出与数值 token 化限制。 - 结果诊断
- 量化成功率与质量指标(表 3–5)。
- 错误分布可视化(图 7–14)揭示:复杂约束、参考样本校准、金融指标计算是主要瓶颈。
- 交互轮次与 token 消耗分析(图 4、6)显示 DeepSeek-R 更“执着”,GPT-4o 更“节俭”。
总结
论文通过“任务-数据-评测-实验”闭环,把“LLM 能否胜任时间序列 AI 助手”这一开放问题转化为可度量、可复现的科学问题,并明确指出:当前通用 LLM 在组合式数值推理与约束满足方面存在系统性缺陷,需要后续研究在符号推理、执行反馈、领域对齐等方向进行突破。
Q: 论文做了哪些实验?
A: 论文在统一的 CodeAct 代理框架下,对 8 个 SOTA 大语言模型进行了端到端实验,覆盖 TSAIA 基准的全部 1 054 个任务实例。实验设计、指标与结果可概括为以下 4 组:
1. 实验设置
- 模型列表
GPT-4o、Qwen2.5-Max、Llama-3.1-70B-Instruct、Claude-3.5-Sonnet、DeepSeek-Chat、Gemini-2.0、Codestral、DeepSeek-R1 - 统一接口
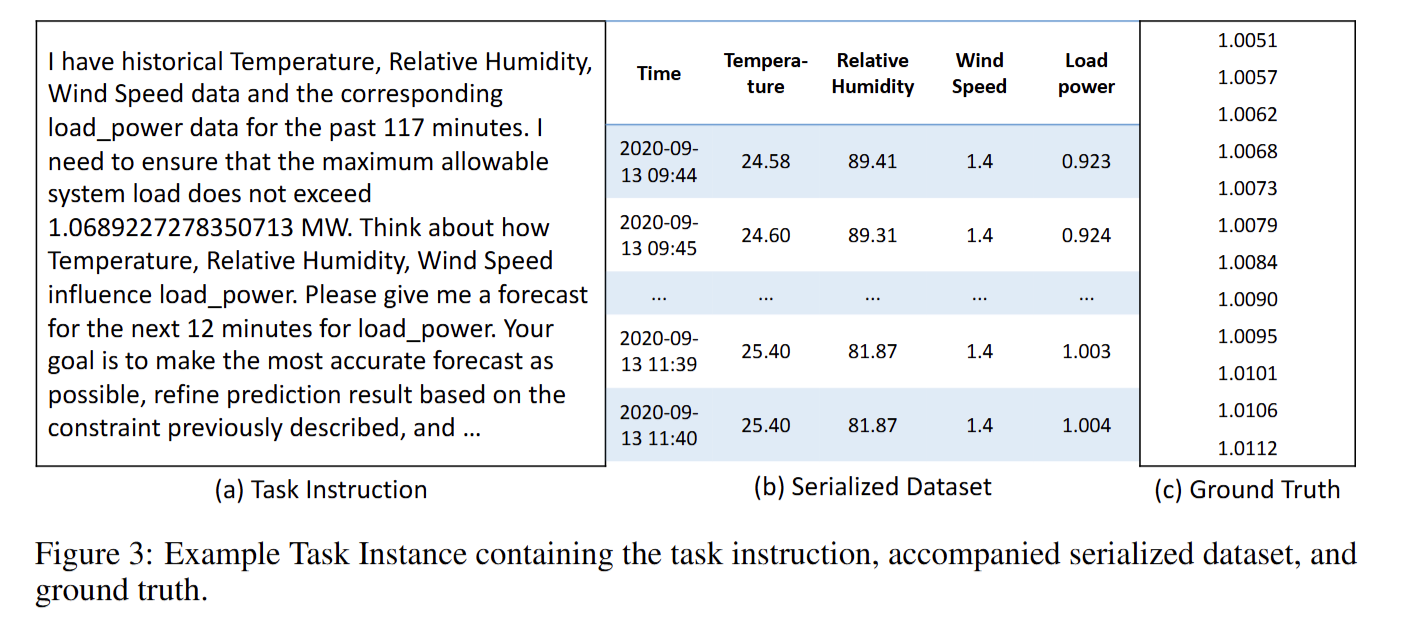
所有模型均通过 AgentScope 的 CodeAct agent 运行,温度=0,top-p=1,单张 A40 48 GB GPU。 - 输入输出协议
每实例提供:自然语言任务指令 +.pkl序列数据 → 模型生成 Python 代码 → 自动执行 → 任务专用评估器打分。 - 评估维度
- 成功率(是否满足格式、约束、非平凡输出)
- 质量指标(MAPE、F1、绝对误差、CR/AR/MDD 等)
- 失败模式(执行错误 / 约束违反 / 低质量或平凡预测)
- 资源消耗(平均 token 数、交互轮次)
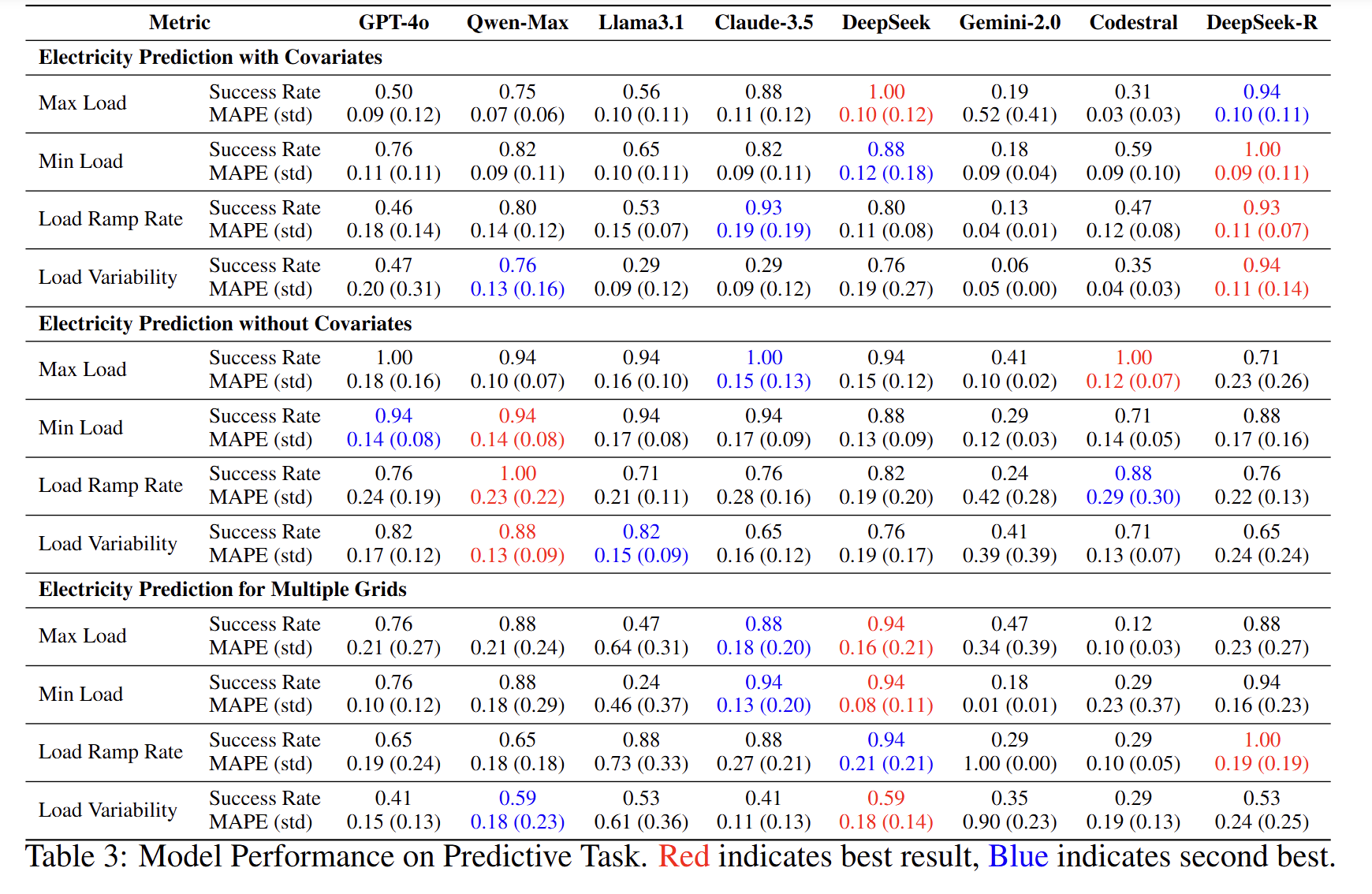
2. 预测类任务实验(表 3)
- 子任务
单序列无协变量、单序列带协变量、多电网联合预测;每种均嵌入最大负荷、最小负荷、爬坡率、波动性四类约束。 - 主要发现
- 简单上下界约束成功率高(0.71–1.00),但爬坡率/波动性约束显著降低成功率(0.06–0.94)。
- 多电网场景因数据维度增加,MAPE 普遍升高。
- DeepSeek-R 在多数约束场景成功率领先;Codestral、Gemini-2.0 明显落后。
3. 诊断类任务实验(表 4)
- 子任务
- 异常检测:已知先验频率 vs. 提供无异常参考样本
- 因果发现:给定定量或定性领域知识
- 主要发现
- 有参考样本的异常检测整体成功率低(0.10–0.34),模型倾向于输出全 0 标签,反映无法自主完成阈值校准流程。
- 因果发现任务在提供明确先验时成功率普遍 >0.90,显示结构化知识易被 LLM 利用。

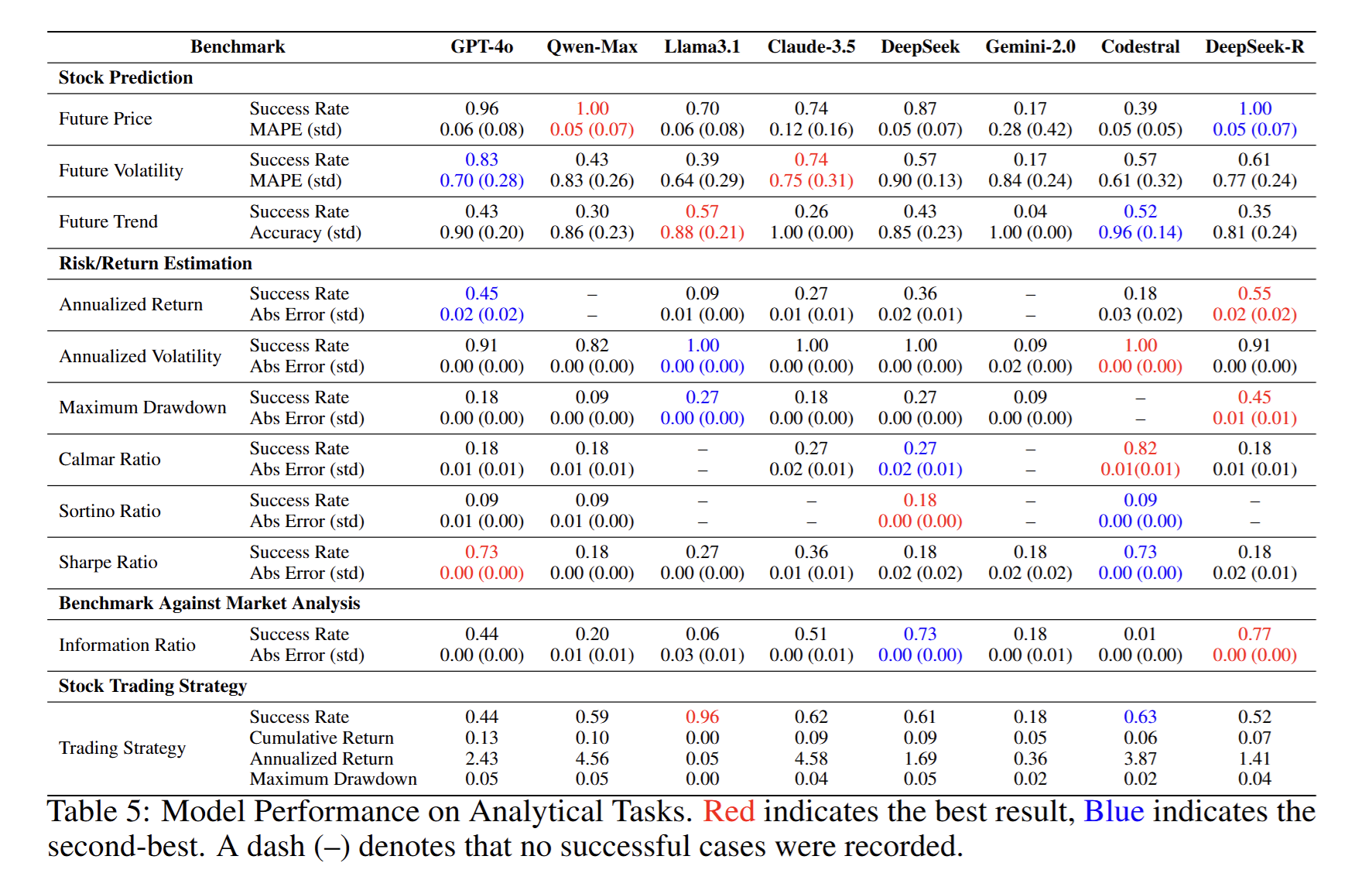
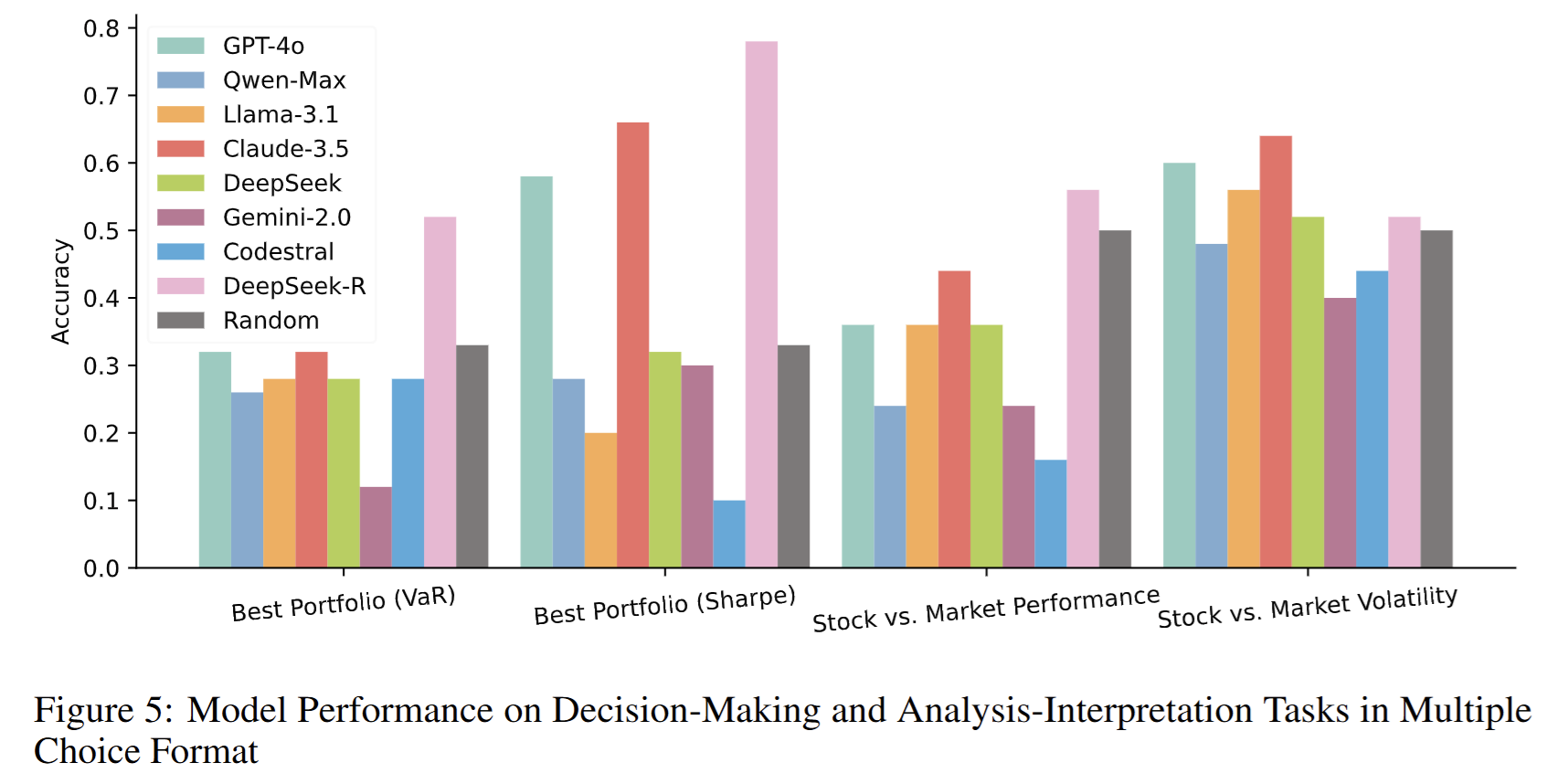
4. 分析与决策类任务实验(表 5 & 图 5)
- 子任务
- 金融预测:未来价格、波动率、趋势
- 风险-收益估计:年化收益、波动率、最大回撤、夏普/索提诺/卡尔玛比率
- 组合选择:基于 VaR 或夏普的最优组合多选题
- 相对市场评价:股票 vs. 市场比较多选题
- 投资策略:生成交易信号并回测
- 主要发现
- 价格预测成功率最高(0.70–1.00),趋势预测最低(0.26–0.57)。
- 复杂指标(最大回撤、索提诺比率)成功率显著低于简单指标(年化波动率)。
- 多选题格式下,多数模型接近随机猜测;仅 DeepSeek-R 持续优于随机。
- 回测类任务整体成功率 0.18–0.63,年化收益差异大(0.05 %–4.58 %)。
5. 深度分析实验
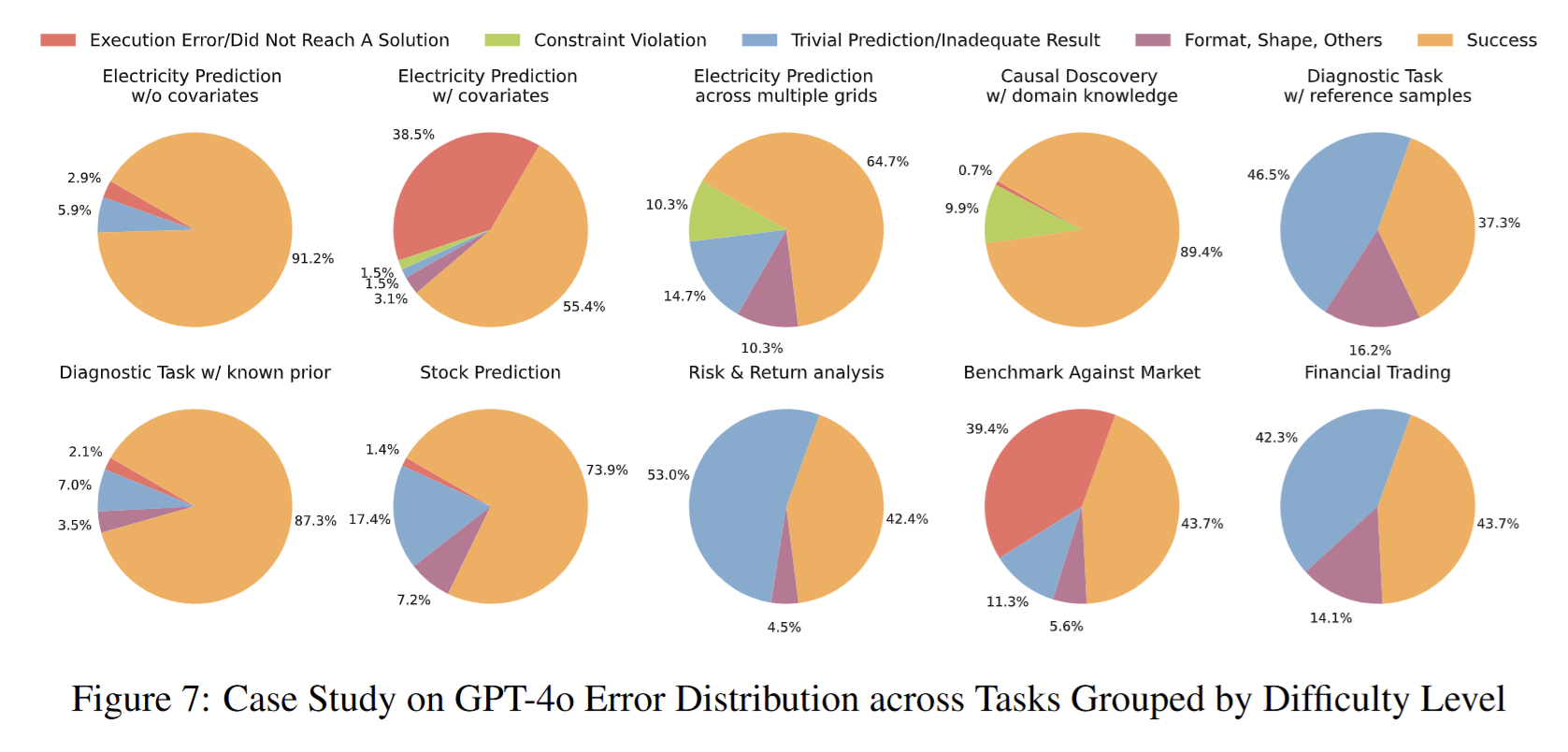
-
错误分布案例研究(图 7–14)
对 8 个模型逐任务统计三类失败占比,揭示:
- 约束违反在电力预测中随任务复杂度增加而上升;
- 参考样本类诊断任务以“平凡预测”失败为主;
- Gemini-2.0、Codestral 执行错误率居高不下。
- 交互轮次与 token 消耗(图 4、6)
- 难度越高,平均轮次越多(上限 6)。
- DeepSeek-R 轮次与 token 均最高,对应更高成功率;GPT-4o 与 DeepSeek-Chat token 效率最佳。
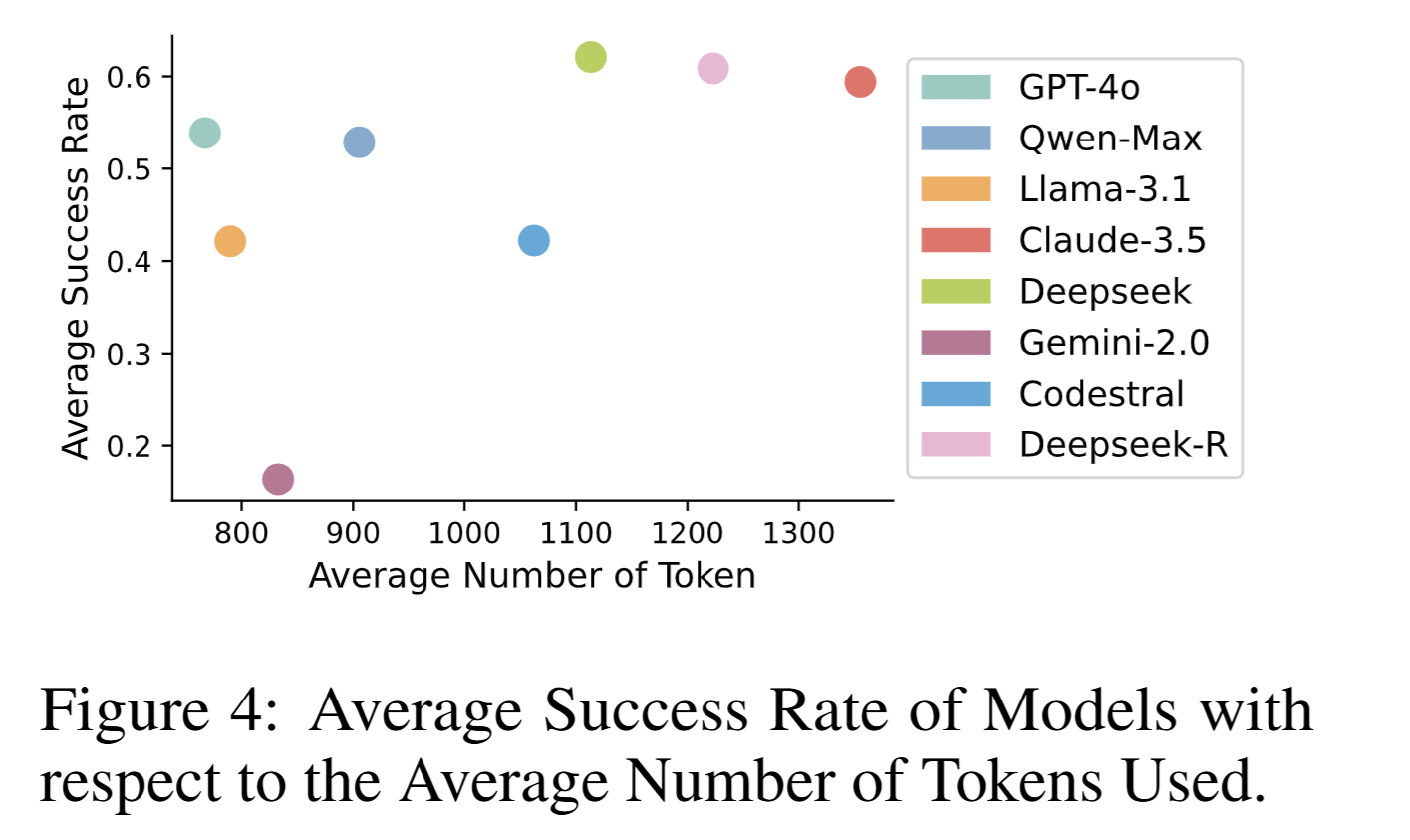
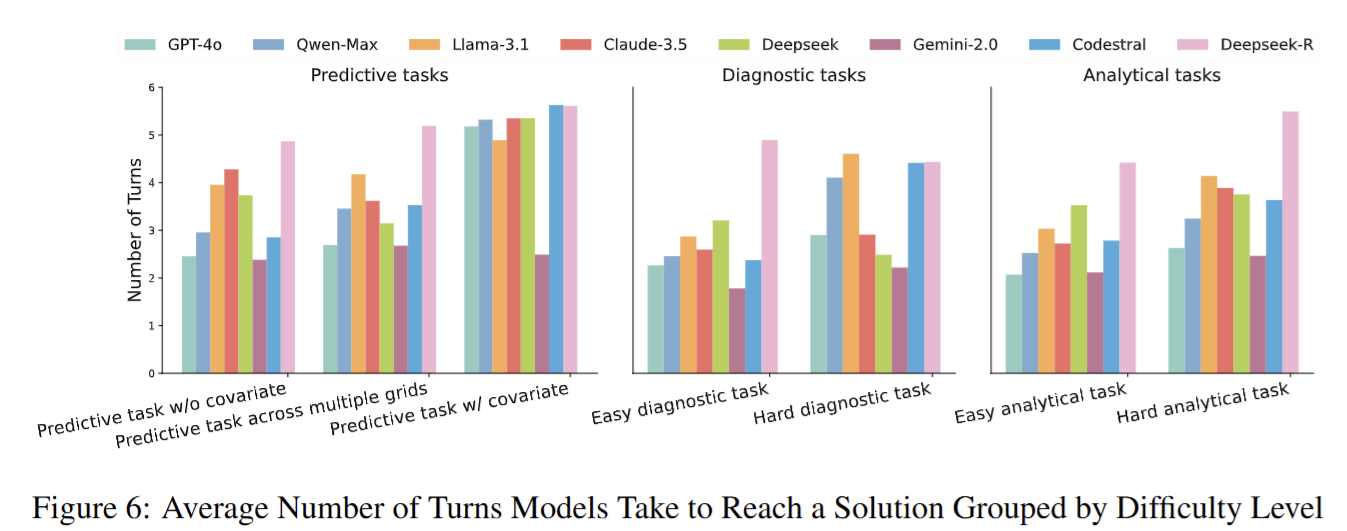
综上,实验系统刻画了当前 LLM 在时间序列复杂推理任务中的能力边界与典型失效模式,为后续模型改进与系统设计提供了量化依据。
附录中有更加详细的实验结果和分析,阅读原文获取详细的信息。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅