分布式协议与算法实战-实战篇
16丨InfluxDB企业版一致性实现剖析:他山之石,可以攻玉
实战是学习的最终目的。为了帮你更好地掌握前面的理论
和算法,接下来,我用 5 讲的时间,分别以 InfluxDB 企业版一致性实现、Hashicorp Raft、KV 系统开发实战为例,带你了解如何在实战中使用技术,掌握分布式的实战能力。
今天这一讲,我就以 InfluxDB 企业版为例,带你看一看系统是如何实现一致性的。有的同学可能会问了:为什么是 InfluxDB 企业版呢?因为它是排名第一的时序数据库,相比其他分布式系统(比如 KV 存储),时序数据库更加复杂,因为我们要分别设计 2 个完全不一样的一致性模型。当你理解了这样一个复杂的系统实现后,就能更加得心应手地处理简单系统的问题了。
那么为了帮你达到这个目的。我会先介绍一下时序数据库的背景知识,因为技术是用来解决实际场景的问题的,正如我之前常说的“要根据场景特点,权衡折中来设计系统”。所以当你了解了这些背景知识后,就能更好的理解为什么要这么设计了。
什么是时序数据库?
你可以这么理解,时序数据库,就是存储时序数据的数据库,就像 MySQL 是存储关系型数据的数据库。而时序数据,就是按照时间顺序记录系统、设备状态变化的数据,比如 CPU 利用率、某一时间的环境温度等,就像下面的样子:
> insert cpu_usage,host=server01,location=cn-sz user=23.0,system=57.0
> select * from cpu_usage
name: cpu_usage
time host location system user
---- ---- -------- ------ ----
1557834774258860710 server01 cn-sz 55 25
>
在我看来,时序数据最大的特点是数据量很大,可以不夸张地说是海量。时序数据主要来自监控(监控被称为业务之眼),而且在不影响业务运行的前提下,监控埋点是越多越好,这样才能及时发现问题、复盘故障。
那么作为时序数据库,InfluxDB 企业版的架构是什么样子呢?
你可能已经了解过,它是由 META 节点和 DATA 节点 2 个逻辑单元组成的,而且这两个节点是 2 个单独的程序。那你也许会问了,为什么不能合成到一个程序呢?答案是场景不同。
- META 节点存放的是系统运行的关键元信息,比如数据库
(Database)、表(Measurement)、保留策略(Retention policy)等。它的特点是一致性敏感,但读写访问量不高,需要一定的容错能力。 - DATA 节点存放的是具体的时序数据。它有这样几个特点:最终一致性、面向业务、性能越高越好,除了容错,还需要实现水平扩展,扩展集群的读写性能。
我想说的是,对于 META 节点来说,节点数的多少代表的是容错能力,一般 3 个节点就可以了,因为从实际系统运行观察看,能容忍一个节点故障就可以了。但对 DATA 节点而言,节点数的多少则代表了读写性能,一般而言,在一定数量以内(比如 10 个节点)越多越好,因为节点数越多,读写性能也越高,但节点数量太多也不行,因为查询时就会出现访问节点数过多而延迟大的问题。
所以,基于不同场景特点的考虑,2 个单独程序更合适。如果 META节点和 DATA 节点合并为一个程序,因读写性能需要,设计了一个 10 节点的 DATA 节点集群,这就意味着 META 节点集群(Raft 集群)也是 10 个节点。在学了 Raft 算法之后,你应该知道,这时就会出现消息数多、日志提交慢的问题,肯定不行了。
现在你了解时序数据库,以及 InfluxDB 企业版的 META 节点和 DATA节点了吧?那么怎么实现 META 节点和 DATA 节点的一致性呢?
如何实现 META 节点一致性?
你可以这样想象一下,META 节点存放的是系统运行的关键元信息,那么当写操作发生后,就要立即读取到最新的数据。比如,创建了数据库“telegraf”,如果有的 DATA 节点不能读取到这个最新信息,那就会导致相关的时序数据写失败,肯定不行。
所以,META 节点需要强一致性,实现 CAP 中的 CP 模型。
那么,InfluxDB 企业版是如何实现的呢?
因为 InflxuDB 企业版是闭源的商业软件,通过官方文档,我们可以知道它使用 Raft 算法实现 META 节点的一致性(一般推荐 3 节点的集群配置)。那么说完 META 节点的一致性实现之后,我接着说一说DATA 节点的一致性实现。
如何实现 DATA 节点一致性?
DATA 节点存放的是具体的时序数据,对一致性要求
不高,实现最终一致性就可以了。但是,DATA 节点也在同时作为接入层直接面向业务,考虑到时序数据的量很大,要实现水平扩展,所以必须要选用 CAP 中的 AP 模型,因为 AP 模型不像 CP 模型那样采用一个算法(比如 Raft 算法)就可以实现了,也就是说,AP 模型更复杂,具体有这样几个实现步骤。
自定义副本数
首先,你需要考虑冗余备份,也就是同一份数据可能需要设置为多个副本,当部分节点出问题时,系统仍然能读写数据,正常运行。
那么,该如何设置副本呢?答案是实现自定义副本数。
关于自定义副本数的实现,我们在12 讲介绍了,在这里就不啰嗦了。
不过,我想补充一点,相比 Raft 算法节点和副本必须一一对应,也就是说,集群中有多少个节点就必须有多少个副本,你看,自定义副本数,是不是更灵活呢?学到这里,有同学可能已经想到了,当集群支持多副本时,必然会出现一个节点写远程节点时,RPC 通讯失败的情况,那么怎么处理这个问题呢?
Hinted-handoff
一个节点接收到写请求时,需要将写请求中的数据转发
一份到其他副本所在的节点,那么在这个过程中,远程 RPC 通讯是可能会失败的,比如网络不通了,目标节点宕机了,等等,就像下图的样子。
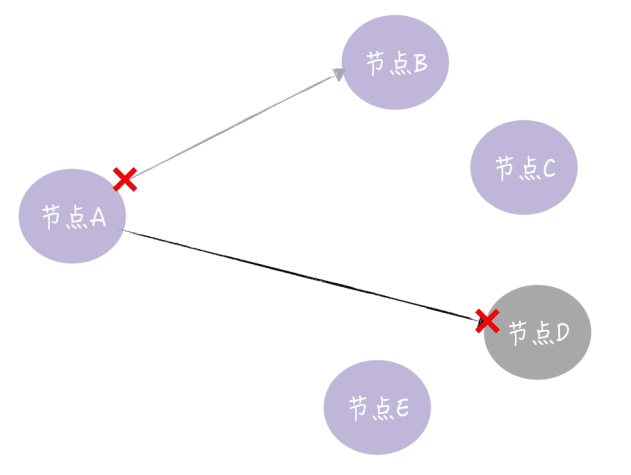
那么如何处理这种情况呢?答案是实现 Hinted-handoff。在 InfluxDB 企业版中,Hinted-handoff 是这样实现的:
- 写失败的请求,会缓存到本地硬盘上 ;
- 周期性地尝试重传 ;
- 相关参数信息,比如缓存空间大小 (max-szie)、缓存周期(maxage)、尝试间隔(retry-interval)等,是可配置的。
在这里我想补充一点,除了网络故障、节点故障外,在实际场景中,临时的突发流量也会导致系统过载,出现 RPC 通讯失败的情况,这时也需要 Hinted-handoff 能力。
虽然 Hinted-handoff 可以通过重传的方式来处理数据不一致的问题,但当写失败请求的数据大于本地缓存空间时,比如某个节点长期故障,写请求的数据还是会丢失的,最终的节点的数据还是不一致的,那么怎么实现数据的最终一致性呢?答案是反熵。
反熵
需要你注意的是,时序数据虽然一致性不敏感,能容忍短暂的不一致,但如果查询的数据长期不一致的话,肯定就不行了,因为这样就会出现“Flapping Dashboard”的现象,也就是说向不同节点查询数据,生成的仪表盘视图不一样,就像下图的样子。
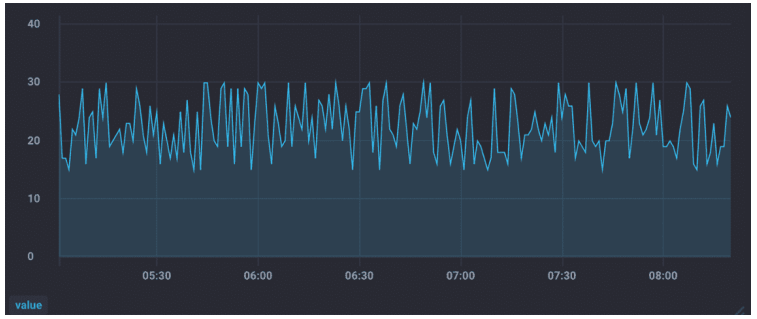
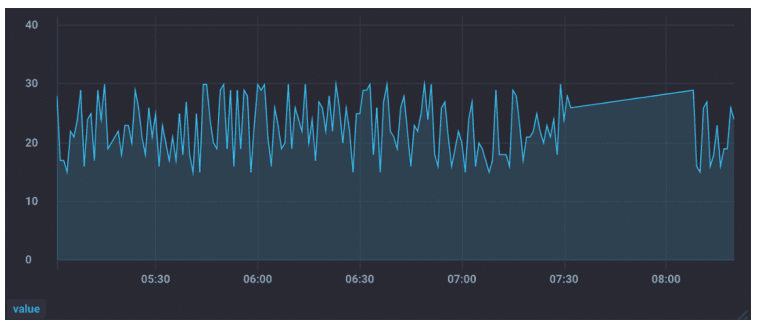
从上面的 2 个监控视图中你可以看到,同一份数据,查询不同的节点,生成的视图是不一样的。那么,如何实现最终一致性呢?
答案就是咱们刚刚说的反熵,而我在11 讲以自研 InfluxDB 系统为例介绍过反熵的实现,InfluxDB 企业版类似,所以在这里就不啰嗦了。
不过有的同学可能会存在这样的疑问,实现反熵是以什么为准来修复数据的不一致呢?我想说的是,时序数据像日志数据一样,创建后就不会再修改了,一直存放在那里,直到被删除。
所以,数据副本之间的数据不一致,是因为数据写失败导致数据丢失了,也就是说,存在的都是合理的,缺失的就是需要修复的。这时我们可以采用两两对比、添加缺失数据的方式,来修复各数据副本的不一致了。
Quorum NWR
这时我们就要实现强一致性(Werner Vogels 提到的强一致性),也就是每次读操作都要能读取最新数据,不能读到旧数据。
那么在一个 AP 型的分布式系统中,如何实现强一致性呢?
答案是实现 Quorum NWR。同样,关于 Quorum NWR 的实现,我们在 12 讲已介绍,在这里也就不啰嗦了。
最后我想说的是,你可以看到,实现 AP 型分布式系统,比实现 CP 型分布式要复杂的。另外,通过上面的内容学习,我希望你能注意到,技术是用来解决场景需求的,没有十全十美的技术,在实际工作中,需要我们深入研究场景特点,提炼场景需求,然后根据场景特点权衡折中,设计出适合该场景特点的分布式系统。
内容小结
我主要带你了解时序数据库、META 节点一致性的实现、DATA节点一致性的实现。以一个复杂的实际系统为例,带你将前面学习到的理论串联起来,让你知道它们如何在实际场景中使用。我希望你明确的重点如下:
- CAP 理论是一把尺子,能辅助我们分析问题、总结归纳问题,指导我们如何做妥协折中。所以,我建议你在实践中多研究多思考,一定不能认为某某技术“真香”,十全十美了,要根据场景特点活学活用技术。
- 通过 Raft 算法,我们能实现强一致性的分布式系统,能保证写操作完成后,后续所有的读操作,都能读取到最新的数据。
- 通过自定义副本数、Hinted-handoff、反熵、Quorum NWR 等技术,我们能实现 AP 型分布式系统,还能通过水平扩展,高效扩展集群的读写能力。
最后,我想再强调下,技术是用来解决场景的需求的,只有当你吃透技术,深刻理解场景的需求,才能开发出适合这个场景的分布式系统。另外我还想让你知道的是,InfluxDB 企业版一年的 License 费高达 1.5 万美刀,为什么它值这个价钱?就是因为技术带来的高性能和成本优势。比如:
- 相比 OpenTSDB,InfluxDB 的写性能是它的 9.96 倍,存储效率是它的 8.69 倍,查询效率是它的 7.38 倍。
- 相比 Graphite,InfluxDB 的写性能是它的 12 倍,存储效率是 6.3 倍,查询效率是 9 倍。
在这里我想说的是,数倍或者数量级的性能优势其实就是钱,而且业务规模越大,省钱效果越突出。
另外我想说的是,尽管 influxdb-comparisons 的测试比较贴近实际场景,比如它的 DevOps 测试模型,与我们观察到常见的实际场景是一致的。但从实际效果看,InfluxDB 的优势更加明显,成本优势更加突出。因为传统的时序数据库不仅仅是性能低,而且在海量数据场景下,接入和查询的痛点突出。为了缓解这些痛点,引入和堆砌了更多的开源软件。比如:
- 往往需要引入 Kafka 来缓解,因突发接入流量导致的丢数据问题;
- 需要引入 Storm、Flink 来缓解,时序数据库计算性能差的问题;
- 需要做热数据的内存缓存,来解决查询超时的问题。
所以在实施中,除了原有的时序数据库会被替换掉,还有大量的开源软件会被省掉,成本优势突出。在这里我想说的是,从实际实施看(自研 InfluxDB 系统),性能优势和成本优势也是符合这个预期的。
最后我想说的是,我反对堆砌开源软件,建议谨慎引入 Kafka 等缓存中间件。老话说,在计算机中,任何问题都可以通过引入一个中间层来解决。这句话是正确的,但背后的成本是不容忽视的,尤其是在海量系统中。我的建议是直面问题,通过技术手段在代码和架构层面解决它,而不是引入和堆砌更多的开源软件。其实,InfluxDB 团队也是这么做,比如他们两次重构存储引擎。
课堂思考
我提到没有十全十美的技术,而是需要根据场景特点,权衡折中,设计出适合场景特点的分布式系统。那么你试着思考一下,假设有这样一个场景,一个存储系统,访问它的写请求不多(比如 1K QPS),但访问它的读请求很多(比如 1M QPS),而且客户端查询时,对数据的一致性敏感,也就是需要实现强一致性,那么我们该如何设计这个系统呢?为什么呢?
17丨Hashicorp Raft(一):如何跨过理论和代码之间的鸿沟?
如果你在使用 Raft 开发分布式系统的时候,仅仅阅读 Raft 论
文或者 Raft 实现的 API 手册,是远远不够的。你还要吃透 API 背后的代码实现,“不仅知其然,也要知其所以然”,这样才能“一切尽在掌握中”,从而开发实现能稳定运行的分布式系统。那么怎么做才能吃透Raft 的代码实现呢?
要知道,任何 Raft 实现都承载了两个目标:实现 Raft 算法的原理,设计易用的 API 接口。所以,你不仅要从算法原理的角度理解代码实现,而且要从场景使用的角度理解 API 接口的用法。
而我会用两节课的时间,从代码实现和接口使用两个角度,带你循序渐进地掌握当前流行的一个 Raft 实现:Hashicorp Raft(以最新稳定版 v1.1.1 为例)。希望你在这个过程中集中注意力,勾划重点,以便提高学习效率,吃透原理对应的技术实现,彻底掌握 Raft 算法的实战技巧。
本节课,我会从算法原理的角度,聊一聊 Raft 算法的核心功能(领导者选举和日志复制)在 Hashicorp Raft 中是如何实现的。
Hashicorp Raft 如何实现领导者选举?
在我看来,阅读源码的关键,在于找到代码的入口函数,比如在Golang 代码中,程序的入口函数一般为 main() 函数,那么领导者选举的入口函数是哪个呢?
我们知道,典型的领导者选举在本质上是节点状态的变更。具体到Hashicorp Raft 源码中,领导者选举的入口函数 run(),在 raft.go 中以一个单独的协程运行,来实现节点状态变迁,就像下面的样子:
func (r *Raft) run() {for {select {// 关闭节点case <-r.shutdownCh:r.setLeader("")returndefault:}switch r.getState() {// 跟随者case Follower:r.runFollower()// 候选人case Candidate:r.runCandidate()// 领导者case Leader:r.runLeader()}}
}
从上面这段代码中,你能看到,Follower(跟随者)、Candidate(候选人)、Leader(领导者)三个节点状态对应的功能,都被抽象成一个函数,分别是 runFollower()、runCandidate() 和 runLeader()。
数据结构
在07 讲中,我们先学习了节点状态,不过主要侧重理解节点状态的功能作用(比如说,跟随者相当于普通群众,领导者是霸道总裁),并没有关注它在实际代码中是如何实现的,所以我们先来看看在 Hashicorp Raft 中是如何实现节点状态的。
节点状态相关的数据结构和函数,是在 state.go 中实现的。跟随者、候选人和领导者的 3 个状态,是由 RaftState 定义的,一个无符号 32 位的只读整型数值(uint32):
type RaftState uint32
const (// 跟随者Follower RaftState = iota// 候选人Candidate// 领导者Leader// 关闭状态Shutdown
)
需要注意的是,也存在一些需要使用字符串格式的节点状态的场景(比如日志输出),这时你可以使用 RaftState.String() 函数。
你应该还记得,每个节点都有属于本节点的信息(比如任期编号),那么在代码中如何实现这些信息呢?这就要说到 raftState 数据结构了。
raftState 属于结构体类型,是表示节点信息的一个大数据结构,里面包含了只属于本节点的信息,比如节点的当前任期编号、最新提交的日志项的索引值、存储中最新日志项的索引值和任期编号、当前节点的状态等,就像下面的样子:
type raftState struct {// 当前任期编号currentTerm uint64// 最大被提交的日志项的索引值commitIndex uint64// 最新被应用到状态机的日志项的索引值lastApplied uint64// 存储中最新的日志项的索引值和任期编号 lastLogIndex uint64lastLogTerm uint64// 当前节点的状态state RaftState......
}
节点状态与节点信息的定义就是这么简单,这里我就不多说了。而在分布式系统中要实现领导者选举,更重要的一层内容是实现 RPC 消息,因为领导者选举的过程,就是一个 RPC 通讯的过程。
在理论篇中我说过,Raft 算法中支持多种 RPC 消息(比如请求投票 RPC 消息、日志复制 RPC 消息)。所以接下来我们看一看,在 Hashicorp Raft 中又是怎样实现 RPC 消息的。又因为在一个 RPC 消息中,最重要的部分就是消息的内容,所以我们先来看一看 RPC 消息对应的数据结构。
RPC 消息相关的数据结构是在 commands.go 中定义的,比如,日志复制 RPC 的请求消息,对应的数据结构为 AppendEntriesRequest。而 AppendEntriesRequest 是一个结构体类型,里面包含了 Raft 算法论文中约定的字段,比如以下这些内容。
- Term:当前的任期编号。
- PrevLogEntry:表示当前要复制的日志项,前面一条日志项的索引值。
- PrevLogTerm:表示当前要复制的日志项,前面一条日志项的任期编号。
- Entries:新日志项。
具体的结构信息,就像下面的样子:
type AppendEntriesRequest struct {// 当前的任期编号,和领导者信息(包括服务器ID和地址信息)Term uint64Leader []byte// 当前要复制的日志项,前面一条日志项的索引值和任期编号PrevLogEntry uint64PrevLogTerm uint64// 新日志项Entries []*Log// 领导者节点上的已提交的日志项的最大索引值LeaderCommitIndex uint64
}
建议你可以采用上面的思路,对照着算法原理去学习其他 RPC 消息的实现,这样一来你就能掌握独立学习的能力了。其他 RPC 消息的数据结构我就不一一描述了。
现在,你已经了解了节点状态和 RPC 消息的格式,掌握了这些基础知识后,我们继续下一步,看看在 Hashicorp Raft 中是如何进行领导者选举的。
选举领导者
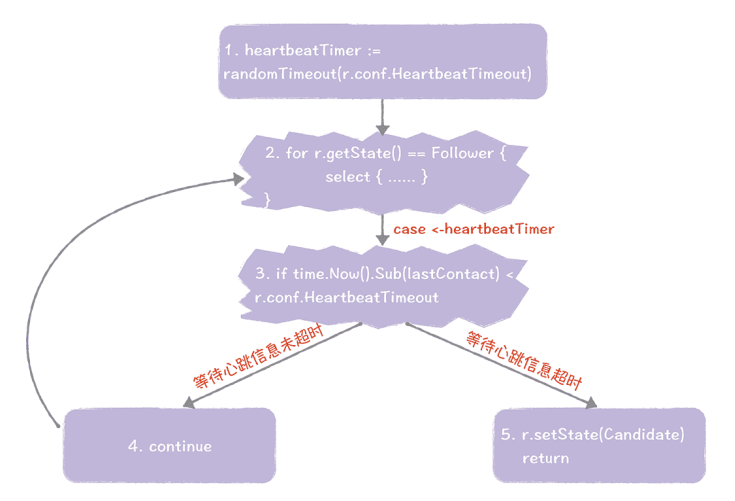
首先,在初始状态下,集群中所有的节点都处于跟随者状态,函数runFollower() 运行,大致的执行步骤,就像下图的样子:
我带你走一遍这五个步骤,便于你加深印象。
- 根据配置中的心跳超时时长,调用 randomTimeout() 函数来获取一个随机值,用以设置心跳超时时间间隔。
- 进入到 for 循环中,通过 select 实现多路 IO 复用,周期性地获取消息和处理。如果步骤 1 中设置的心跳超时时间间隔发生了超时,执行步骤 3。
- 如果等待心跳信息未超时,执行步骤 4,如果等待心跳信息超时,执行步骤 5。
- 执行 continue 语句,开始一次新的 for 循环。
- 设置节点状态为候选人,并退出 runFollower() 函数。
当节点推举自己为候选人之后,函数 runCandidate() 执行,大致的执行步骤,如图所示:
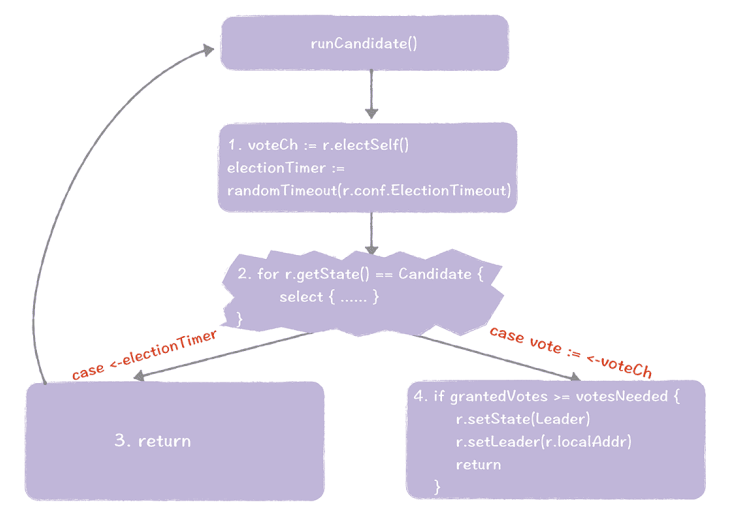
同样的,我们走一遍这个过程,加深一下印象。
- 首先调用 electSelf() 发起选举,给自己投一张选票,并向其他节点发送请求投票 RPC 消息,请求他们选举自己为领导者。然后调用 randomTimeout() 函数,获取一个随机值,设置选举超时时间。
- 进入到 for 循环中,通过 select 实现多路 IO 复用,周期性地获取消息和处理。如果发生了选举超时,执行步骤 3,如果得到了投票信息,执行步骤 4。
- 发现了选举超时,退出 runCandidate() 函数,然后再重新执行runCandidate() 函数,发起新一轮的选举。
- 如果候选人在指定时间内赢得了大多数选票,那么候选人将当选为领导者,调用 setState() 函数,将自己的状态变更为领导者,并退出 runCandidate() 函数。
当节点当选为领导者后,函数 runLeader() 就执行了:
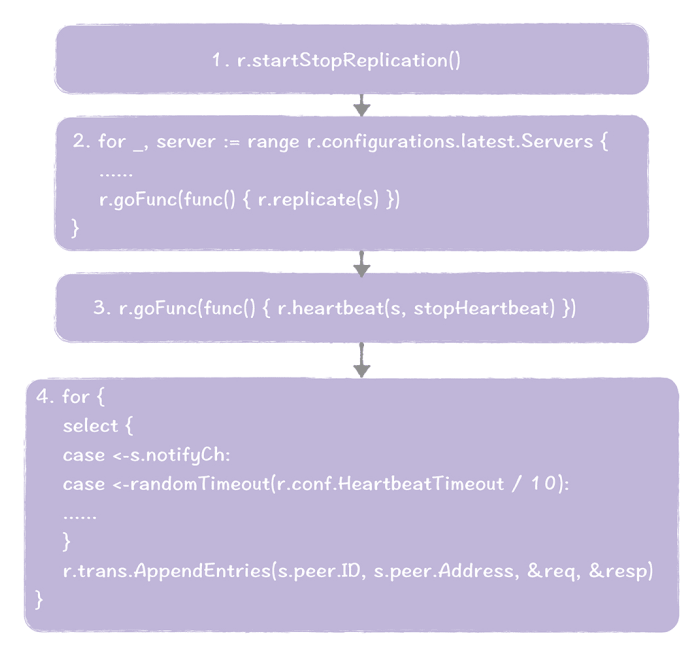
整个过程,主要有 4 个步骤。
- 调用 startStopReplication(),执行日志复制功能。
- 然后启动新的协程,调用 replicate() 函数,执行日志复制功能。
- 接着在 replicate() 函数中,启动一个新的协程,调用 heartbeat() 函数,执行心跳功能。
- 在 heartbeat() 函数中,周期性地发送心跳信息,通知其他节点,
我是领导者,我还活着,不需要你们发起新的选举。
其实,在 Hashicorp Raft 中实现领导者选举并不难,你只要充分理解上述步骤,并记住,领导者选举本质上是节点状态变迁,跟随者、候选人、领导者对应的功能函数分别为 runFollower()、runCandidate()、runLeader(),就可以了。
Hashicorp Raft 如何复制日志?
学习08讲之后,你应该知道了日志复制的重要性,因为 Raft 是基于强领导者模型和日志复制,最终实现强一致性的。那么你该如何学习日志复制的代码实现呢?和学习“如何实现领导者选举”一样,你需要先了解了日志相关的数据结构,阅读日志复制相关的代码。
学习了理论篇后,你应该还记得日志复制是由领导者发起的,跟随者来接收的。可能有同学已经想到了,领导者复制日志和跟随者接收日志的入口函数,应该分别在 runLeader() 和 runFollower() 函数中调用的。赞!理解正确!
- 领导者复制日志的入口函数为 startStopReplication(),在
runLeader() 中,以 r.startStopReplication() 形式被调用,作为一个单独协程运行。 - 跟随者接收日志的入口函数为 processRPC(),在 runFollower() 中以 r.processRPC(rpc) 形式被调用,来处理日志复制 RPC 消息。
不过,在分析日志复制的代码实现之前,咱们先来聊聊日志相关的数据结构,便于你更好地理解代码实现。
数据结构
08 讲中我提到过,一条日志项主要包含了 3 种信息,分别是指令、索引值、任期编号,而在 Hashicorp Raft 实现中,日志对应的数据结构和函数接口是在 log.go 中实现的,其中,日志项对应的数据结构是结构体类型的,就像下面的样子:
type Log struct {// 索引值Index uint64// 任期编号Term uint64// 日志项类别Type LogType// 指令Data []byte// 扩展信息Extensions []byte
}
我强调一下,与协议中的定义不同,日志项对应的数据结构中,包含了 LogType 和 Extensions 两个额外的字段:
- LogType 可用于标识不同用途的日志项,比如,使用
LogCommand 标识指令对应的日志项,使用 LogConfiguration 表示成员变更配置对应的日志项。 - Extensions 可用于在指定日志项中存储一些额外的信息。这个字段使用的比较少,在调试等场景中可能会用到,你知道有这么个字段就可以了。说完日志复制对应的数据结构,我们分步骤看一下,在 Hashicorp Raft 中是如何实现日志复制的。
领导者复制日志
日志复制是由领导者发起,在 runLeader() 函数中执行的,主要有这样几个步骤。
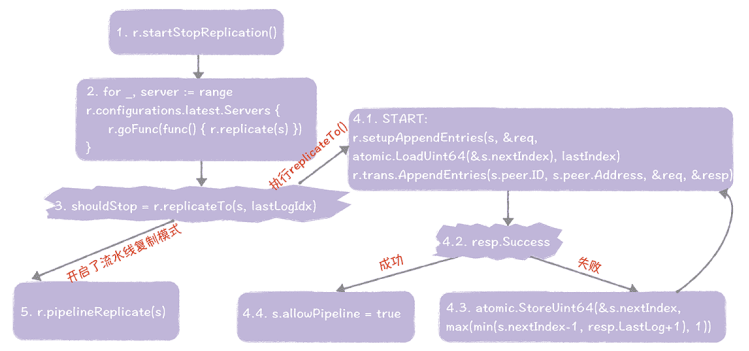
- 在 runLeader() 函数中,调用 startStopReplication() 函数,执行日志复制功能。
- 启动一个新协程,调用 replicate() 函数,执行日志复制相关的功能。
- 在 replicate() 函数中,调用 replicateTo() 函数,执行步骤 4,如果开启了流水线复制模式,执行步骤 5。
- 在 replicateTo() 函数中,进行日志复制和日志一致性检测,如果日志复制成功,则设置 s.allowPipeline = true,开启流水线复制模式。
- 调用 pipelineReplicate() 函数,采用更高效的流水线方式,进行日志复制。
在这里我强调一下,在什么条件下开启了流水线复制模式,很多同学可能会在这一块儿产生困惑,因为代码逻辑上有点儿绕。你可以这么理解,是在不需要进行日志一致性检测,复制功能已正常运行的时候,开启了流水线复制模式,目标是在环境正常的情况下,提升日志复制性能,如果在日志复制过程中出错了,就进入 RPC 复制模式,继续调用 replicateTo() 函数,进行日志复制。
跟随者接收日志
领导者复制完日志后,跟随者会接收日志并开始处理日志。跟随者接收和处理日志,是在 runFollower() 函数中执行的,主要有这样几个步骤。
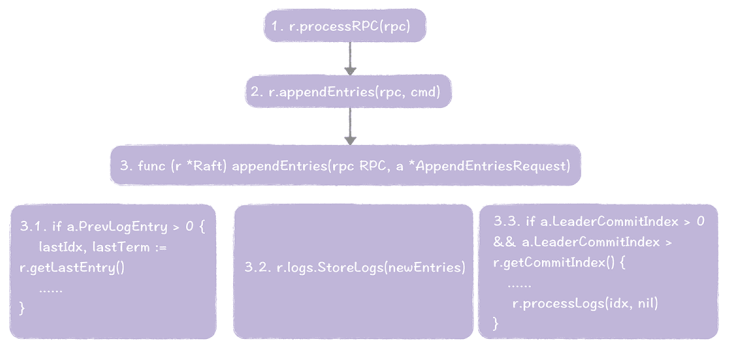
- 在 runFollower() 函数中,调用 processRPC() 函数,处理接收到的 RPC 消息。
- 在 processRPC() 函数中,调用 appendEntries() 函数,处理接收到的日志复制 RPC 请求。
- appendEntries() 函数,是跟随者处理日志的核心函数。在步骤3.1 中,比较日志一致性;在步骤 3.2 中,将新日志项存放在本地;在步骤 3.3 中,根据领导者最新提交的日志项索引值,来计算当前需要被应用的日志项,并应用到本地状态机。
讲到这儿,你应该可以了解日志复制的代码实现了吧。关于更多的Raft 原理的代码实现,你可以继续阅读源码来学习。
内容小结
本节课我主要带你了解了如何从算法原理的角度理解 Hashicorp Raft 实现,有几个重点我想强调一下:
- 跟随者、候选人、领导者 3 种节点状态都有分别对应的功能函数,当需要查看各节点状态相关的功能实现时(比如,跟随者如何接收和处理日志),都可以将对应的函数作为入口函数,来阅读代码和研究功能实现。
- raft.go 是 Hashicorp Raft 的核心代码文件,大部分的核心功能都是在这个文件中实现的,平时可以多研究这个文件中的代码,直到彻底吃透,掌握。
- 在 Hashicorp Raft 中,支持两种节点间通讯机制,内存型和 TCP 协议型,其中,内存型通讯机制,主要用于测试,2 种通讯机制的代码实现,分别在文件 inmem_transport.go 和 tcp_transport.go 中。
- Hashicorp Raft 实现,是常用的 Golang 版 Raft 算法的实现,被众多流行软件使用,如 Consul、InfluxDB、IPFS 等,相信你对它并不陌生。其他的实现还有Go-Raft、LogCabin、Willemt-Raft 等,不过我建议你在后续开发分布式系统时,优先考虑 HashicorpRaft,因为 Hashicorp Raft 实现,功能完善、代码简洁高效、流行度高,可用性和稳定性被充分打磨。
最后,关于如何高效地阅读源码,我还想多说一说。在我看来,高效阅读源码的关键在于抓住重点,要有“底线”,不要芝麻和西瓜一把抓,什么都想要,最终陷入到枝节琐碎的细节中出不来。什么是重点呢?我认为重点是数据结构和关键的代码执行流程,比如在 Hashicorp Raft 源码中,日志项对应的数据结构、RPC 消息对应的数据结构、选举领导者的流程、日志复制的流程等,这些就是重点。
在阅读源码的时候,如果遇到不是很明白的代码,该怎么办呢?我建议你可以通过打印日志或 GDB 单步调试的方式,查看上下文中的变量的内容、代码执行逻辑等,帮助理解。
课堂思考
在 Hashicorp Raft 实现中,我讲了如何实现选举领导者,以及如何复制日志等,那么在 Hashicorp Raft 中,网络通讯是如何实现的呢?
18|Hashicorp Rat(二):如何以"集群节点"为中心使用API?
我们知道,开发实现一个 Raft 集群的时候,首先要做的第一个事情就是创建 Raft 节点,那么在 Hashicorp Raft 中如何创建节点呢?
如何创建Raft节点
在 Hashicorp Raft 中,你可以通过 NewRaft() 函数,来创建 Raft 节点。我强调一下,NewRaft() 是非常核心的函数,是 Raft 节点的抽象实现,NewRaft() 函数的原型是这样的:
func NewRaft(conf *Config, fsm FSM, logs LogStore, stable StableStore, snaps SnapshotStore, trans Transport) (*Raft, error)
你可以从这段代码中看到,NewRaft() 函数有这么几种类型的参数,它们分别是:
- Config(节点的配置信息);
- FSM(有限状态机);
- LogStore(用来存储 Raft 的日志);
- StableStore(稳定存储,用来存储 Raft 集群的节点信息等);
- SnapshotStore(快照存储,用来存储节点的快照信息);
- Transport(Raft 节点间的通信通道)。
这 6 种类型的参数决定了 Raft 节点的配置、通讯、存储、状态机操作等核心信息,所以我带你详细了解一下,在这个过程中,你要注意是如何创建这些参数信息的。
Config 是节点的配置信息,可通过函数 DefaultConfig() 来创建默认配置信息,然后按需修改对应的配置项。一般情况下,使用默认配置项就可以了。不过,有时你可能还是需要根据实际场景,调整配置项的,比如:
- 如果在生产环境中部署的时候,你可以将 LogLevel 从 DEBUG 调整为 WARM 或 ERROR;
- 如果部署环境中网络拥堵,你可以适当地调大 HeartbeatTimeout的值,比如,从 1s 调整为 1.5s,避免频繁的领导者选举;
那么 FSM 又是什么呢?它是一个 interface 类型的数据结构,借助Golang Interface 的泛型编程能力,应用程序可以实现自己的Apply(*Log)、Snapshot()、Restore(io.ReadCloser) 3 个函数,分别实现将日志应用到本地状态机、生成快照和根据快照恢复数据的功能。FSM 是日志处理的核心实现,原理比较复杂,不过不是咱们本节课的重点,现在你只需要知道这 3 个函数就可以了。在 20 讲,我会结合实际代码具体讲解的。
第三个参数 LogStore 存储的是 Raft 日志,你可以用raft-boltdb来实现底层存储,持久化存储数据。在这里我想说的是,raft-boltdb 是Hashicorp 团队专门为 Hashicorp Raft 持久化存储,而开发设计的,使用广泛,打磨充分。具体用法是这样的:
logStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-log.db"))
NewBoltStore() 函数只支持一个参数,也就是文件路径。
第四个参数 StableStore 存储的是节点的关键状态信息,比如,当前任期编号、最新投票时的任期编号等,同样,你也可以采用 raftboltdb 来实现底层存储,持久化存储数据。
stableStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-stable.db"))
第五个参数 SnapshotStore 存储的是快照信息,也就是压缩后的日志数据。在 Hashicorp Raft 中提供了 3 种快照存储方式,它们分别是:
- DiscardSnapshotStore(不存储,忽略快照,相当于 /dev/null,一般来说用于测试);
- FileSnapshotStore(文件持久化存储);
- InmemSnapshotStore(内存存储,不持久化,重启程序后,数据会丢失)。
这3种方式,在生产环境中,建议你采用FileSnapshotStore实现快照,使用文件持久化存储,避免因程序重启,导致快照数据丢失。具体代码如下:
snapshots, err := raft.NewFileSnapshotStore(raftDir, retainSnapshotCount, os.Stderr)
NewFileSnapshotStore() 函数支持 3 个参数。也就是说,除了指定存储路径(raftDir),还要指定需要保留的快照副本的数量(retainSnapshotCount),以及日志输出的方式。一般而言,将日志输出到标准错误 IO 就可以了。
最后一个 Transport 指的是 Raft 集群内部节点之间的通信机制,节点之间需要通过这个通道来进行日志同步、领导者选举等等。Hashicorp Raft 支持两种方式:
- 一种是基于 TCP 协议的 TCPTransport,可以跨机器跨网络通信的;
- 另一种是基于内存的 InmemTransport,不走网络,在内存里面通过 Channel 来通信。
在生产环境中,我建议你使用 TCPTransport,使用 TCP 进行网络通讯,突破单机限制,提升集群的健壮性和容灾能力。具体代码实现如下:
addr, err := net.ResolveTCPAddr("tcp", raftBind)
transport, err := raft.NewTCPTransport(raftBind, addr, maxPool, timeout, os.Stderr)
NewTCPTransport() 函数支持 5 个参数,也就是,指定创建连接需要的信息。比如,要绑定的地址信息(raftBind、addr)、连接池的大小(maxPool)、超时时间(timeout),以及日志输出的方式,一般而言,将日志输出到标准错误 IO 就可以了。
以上就是这 6 个参数的详细内容了,既然我们已经了解了这些基础信息,那么如何使用 NewRaft() 函数呢?其实,你可以在代码中直接调用 NewRaft() 函数,创建 Raft 节点对象,就像下面的样子:
raft, err := raft.NewRaft(config, (*storeFSM)(s), logStore, stableStore, snapshots, transport)
接口清晰,使用方便,你可以亲手试一试。
现在,我们已经创建了 Raft 节点,打好了基础,但是我们要实现的是一个多节点的集群,所以,创建一个节点是不够的,另外,创建了节点后,你还需要让节点启动,当一个节点启动后,你还需要创建新的节点,并将它加入到集群中,那么具体怎么操作呢?
如何增加集群节点
集群最开始的时候,只有一个节点,我们让第一个节点通过 bootstrap 的方式启动,它启动后成为领导者:
raftNode.BootstrapCluster(configuration)
BootstrapCluster() 函数只支持一个参数,也就是 Raft 集群的配置信息,因为此时只有一个节点,所以配置信息为这个节点的地址信息。
后续的节点在启动的时候,可以通过向第一个节点发送加入集群的请求,然后加入到集群中。具体来说,先启动的节点(也就是第一个节点)收到请求后,获取对方的地址(指 Raft 集群内部通信的 TCP 地址),然后调用 AddVoter() 把新节点加入到集群就可以了。具体代码如下:
raftNode.AddVoter(id, addr, prevIndex, timeout)
AddVoter() 函数支持 4 个参数,使用时,一般只需要设置服务器 ID
信息和地址信息 ,其他参数使用默认值 0,就可以了:
- id(服务器 ID 信息);
- addr(地址信息);
- prevIndex(前一个集群配置的索引值,一般设置为 0,使用默认值);
- timeout(在完成集群配置的日志项添加前,最长等待多久,一般设置为 0,使用默认值)。
当然了,也可以通过 AddNonvoter(),将一个节点加入到集群中,但不赋予它投票权,让它只接受日志记录,这个函数平时用不到,你只需知道有这么函数,就可以了。
在这里,我想补充下,早期版本中的用于增加集群节点的函数,AddPeer() 函数,已废弃,不再推荐使用。
你看,在创建集群或者扩容时,我们尝试着增加了集群节点,但一旦出现不可恢复性的机器故障或机器裁撤时,我们就需要移除节点,进行节点替换,那么具体怎么做呢?
如何移除集群节点
我们可以通过 RemoveServer() 函数来移除节点,具体代码如下:
raftNode.RemoveServer(id, prevIndex, timeout)
RemoveServer() 函数支持 3 个参数,使用时,一般只需要设置服务器 ID 信息 ,其他参数使用默认值 0,就可以了:
- id(服务器 ID 信息);
- prevIndex(前一个集群配置的索引值,一般设置为 0,使用默认值);
- timeout(在完成集群配置的日志项添加前,最长等待多久,一般设置为 0,使用默认值)。
我要强调一下,RemoveServer() 函数必须在领导者节点上运行,否则就会报错。这一点,很多同学在实现移除节点功能时会遇到,所以需要注意一下。
最后,我想补充下,早期版本中的用于移除集群节点的函数,
RemovePeer() 函数也已经废弃了,不再推荐使用。
关于如何移除集群节点的代码实现,也比较简单易用,通过服务器 ID信息,就可以将对应的节点移除了。除了增加和移除集群节点,在实际场景中,我们在运营分布式系统时,有时需要查看节点的状态。那么该如何查看节点状态呢?
如何查看集群节点状态
在分布式系统中,日常调试的时候,节点的状态信息是很重要的,比如在 Raft 分布式系统中,如果我们想抓包分析写请求,那么必须知道哪个节点是领导者节点,它的地址信息是多少,因为在 Raft 集群中,只有领导者能处理写请求。
那么在 Hashicorp Raft 中,如何查看节点状态信息呢?
我们可以通过 Raft.Leader() 函数,查看当前领导者的地址信息,也可以通过 Raft.State() 函数,查看当前节点的状态,是跟随者、候选人,还是领导者。不过你要注意,Raft.State() 函数返回的是RaftState 格式的信息,也就是 32 位无符号整数,适合在代码中使用。如果想在日志或命令行接口中查看节点状态信息,我建议你使用RaftState.String() 函数,通过它,你可以查看字符串格式的当前节点状态。
为了便于你理解,我举个例子。比如,你可以通过下面的代码,判断当前节点是否是领导者节点:
func isLeader() bool {return raft.State() == raft.Leader
}
了解了节点状态,你就知道了当前集群节点之间的关系,以及功能和节点的对应关系,这样一来,你在遇到问题,需要调试跟踪时,就知道登录到哪台机器,去调试分析了。
内容小结
本节课我主要以“集群节点”为核心,带你了解了 Hashicorp Raft 的常用 API 接口,我希望你明确的重点如下:1. 除了提到的 raft-boltdb 做作为 LogStore 和 StableStore,也可以
调用 NewInmemStore() 创建内存型存储,在测试时比较方便,重新执行程序进行测试时,不需要手动清理数据存储。
2. 你还可以通过 NewInmemTransport() 函数,实现内存型通讯接口,在测试时比较方便,将集群通过内存进行通讯,运行在一台机器上。
3. 你可以通过 Raft.Stats() 函数,查看集群的内部统计信息,比如节点状态、任期编号、节点数等,这在调试或确认节点运行状况的时候很有用。
我以集群节点为核心,讲解了 Hashicorp Raft 常用的 API 接口,相信现在你已经掌握这些接口的用法了,对如何开发一个分布式系统,也有了一定的感觉。既然学习是为了使用,那么我们学完这些内容,也应该用起来才是,所以,为了帮你更好地掌握 Raft 分布式系统的开发实战技巧,我会用接下来两节课的时间,以分布式 KV 系统开发实战为例,带你了解 Raft 的开发实战技巧。
课堂思考
我提到了一些常用的 API 接口,比如创建 Raft 节点、增加集群节点、移除集群节点、查看集群节点状态等,你不妨思考一下,如何创建一个支持 InmemTransport 的 Raft 节点呢?
19丨基于Raft的分布式KV系统开发实战(一):如何设计架构?
在接下来的 2 节课中,我会分别从架构和代码实现的角度,以一个基本的分布式 KV 系统为例,具体说一说,如何基于 Raft 算法构建一个分布式 KV 系统。那么我希望你能课下多动手,自己写一遍,不给自己留下盲区。如果条件允许的话,你还可以按需开发实现需要的功能,并将这套系统作为自己的“配置中心”“名字路由”维护下去,不断在实战中加深自己对技术的理解。
为什么不以 Etcd 为例呢?它不是已经在生产环境中落地了吗?
我是这么考虑的,这个基本的分布式 KV 系统的代码比较少,相对纯粹聚焦在技术本身,涉及的 KV 业务层面的逻辑少,适合入门学习(比如你可以从零开始,动手编程实现),是一个很好的学习案例。另外,对一些有经验的开发者来说,这部分知识能够帮助你掌握 Raft算法中,一些深层次的技术实现,比如如何实现多种读一致性模型,让你更加深刻地理解 Raft 算法。
今天这节课,我会具体说一说如何设计一个基本的分布式 KV 系统,也就是需要实现哪些功能,以及在架构设计的时候,你需要考虑哪些点(比如跟随者是否要转发写请求给领导者?或者如何设计接入访问的 API?)
好了,话不多说,一起进入今天的课程吧!
在我看来,基于技术深度、开发工作量、学习复杂度等综合考虑,一个基本的分布式 KV 系统,至少需要具备这样几块功能,就像下图的样子。
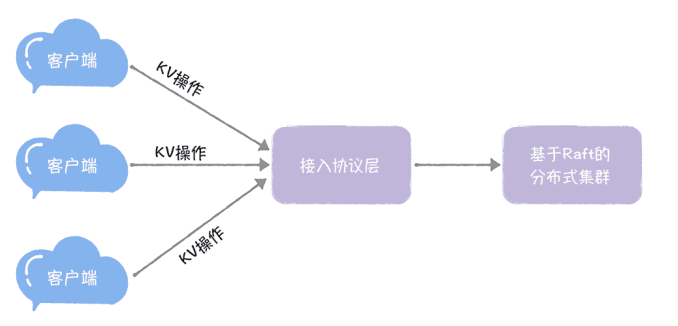
- 接入协议:供客户端访问系统的接入层 API,以及与客户端交互的通讯协议。
- KV 操作:我们需要支持的 KV 操作(比如赋值操作)。
- 分布式集群:也就是说,我们要基于 Raft 算法实现一个分布式存储集群,用于存放 KV 数据。
需要你注意的是,这 3 点就是分布式 KV 系统的核心功能,也就是我们需要编程实现的需求。
在我看来,要实现一个基本的分布式 KV 系统,首先要做的第一件事,就是实现访问接入的通讯协议。因为如果用户想使用这套系统,对他而言的第一件事,就是如何访问这套系统。那么,如何实现访问接入的通讯协议呢?
如何设计接入协议?
在早些时候,硬件性能低,服务也不是很多,开发系统
的时候,主要矛盾是性能瓶颈,所以,更多的是基于性能的考虑,采用 UDP 协议和实现私有的二进制协议,比如,早期的 QQ 后台组件,就是这么做的。
现在呢,硬件性能有了很大幅度的提升,后台服务器的 CPU 核数都近百了,开发系统的时候,主要的矛盾已经不是性能瓶颈了,而是快速增长的海量服务和开发效率,所以这时,基于开发效率和可维护性的考虑,我们就需要优先考虑标准的协议了(比如 HTTP)。
如果使用 HTTP 协议,那么就需要设计 HTTP RESTful API,作为访问接口。具体怎么设计呢?
我想说的是,因为我们设计实现的是 KV 系统,肯定要涉及到 KV 操作,那么我们就一定需要设计个 API(比如"/key")来支持 KV 操作。也就是说,通过访问这个 API,我们能执行相关的 KV 操作了,就像下面的样子(查询指定 key(就是 foo)对应的值)。
curl -XGET http://raft-cluster-host01:8091/key/foo
另外,需要你注意的是,因为这是一个 Raft 集群系统,除了业务层面(KV 操作),我们还需要实现平台本身的一些操作的 API 接口,比如增加、移除集群节点等。我们现在只考虑增加节点操作的 API(比如"/join"),就像下面的样子。
http://raft-cluster-host01:8091/join
另外,在故障或缩容情况下,如何替换节点、移除节点,我建议你在线下对比着增加节点的操作,自主实现。
除此之外,在我看来,实现 HTTP RESTful API,还有非常重要的一件事情要做,那就是在设计 API 时,考虑如何实现路由,为什么这么说呢?你这么想象一下,如果我们实现了多个 API,比如"/key"和"/join",那么就需要将 API 对应的请求和它对应的处理函数一一映射起来。
我想说的是,我们可以在 serveHTTP() 函数(Golang)中,通过检测URL 路径,来设置请求对应处理函数,实现路由。大概的原理,就像下面的样子。
func (s *Service) ServeHTTP(w http.ResponseWriter, r *http.Request) { // 设置HTTP请求对应的路由信息if strings.HasPrefix(r.URL.Path, "/key") {s.handleKeyRequest(w, r)} else if r.URL.Path == "/join" {s.handleJoin(w, r)} else {w.WriteHeader(http.StatusNotFound)}
}
从上面代码中,我们可以看到,当检测到 URL 路径为“/key”时,会调用 handleKeyRequest() 函数,来处理 KV 操作请求;当检测到 URL路径为"/join"时,会调用 handleJoin() 函数,将指定节点加入到集群中。
你看,通过"/key"和"/join"2 个 API,我们就能满足这个基本的分布式KV 系统的运行要求了,既能支持来自客户端的 KV 操作,也能新增节点并将集群运行起来。
当客户端通过通讯协议访问到系统后,它最终的目标,还是执行 KV操作。那么,我们该如何设计 KV 操作呢?
如何设计KV操作?
我想说的是,常见的 KV 操作是赋值、查询、删除,也就是说,我们实现这三个操作就可以了,其他的操作可以先不考虑。具体可以这么实现。
- 赋值操作:我们可以通过 HTTP POST 请求,来对指定 key 进行赋值,就像下面的样子。
curl -XPOST http://raft-cluster-host01:8091/key -d '{"foo": "bar"}'
- 查询操作:我们可以通过 HTTP GET 请求,来查询指定 key 的值,就像下面的样子。
curl -XGET http://raft-cluster-host01:8091/key/foo
- 删除操作:我们可以通过 HTTP DELETE 请求,来删除指定 key和 key 对应的值,就像下面的样子。
curl -XDELETE http://raft-cluster-host01:8091/key/foo
在这里,尤其需要你注意的是,操作需要具有幂等性。幂等性这个词儿你估计不会陌生,你可以这样理解它:同一个操作,不管执行多少次,最终的结果都是一样的,也就是,这个操作是可以重复执行的,而是重复执行不会对系统产生预期外的影响。
为什么操作要具有冥等性呢?
因为共识算法能保证达成共识后的值(也就是指令)就不再改变了,但不能保证值只被提交一次,也就是说,共识算法是一个“at least once”的指令执行模型,是可能会出现同一个指令被重复提交的情况,为什么呢?我以 Raft 算法为例,具体说一说。
比如,如果客户端接收到 Raft 的超时响应后,也就是这时日志项还没有提交成功,如果此时它重试,发送一个新的请求,那么这个时候Raft 会创建一个新的日志项,并最终将新旧 2 个日志项都提交了,出现了指令重复执行的情况。
在这里我想强调的是,你一定要注意到这样的情况,在使用 Raft 等共识算法时,要充分评估操作是否具有幂等性,避免对系统造成预期外的影响,比如,直接使用“Add”操作,就会因重复提交,导致最终的执行结果不准了,影响到业务。这就可能会出现,用户购买了 100Q币,系统却给他充值了 500Q 币,肯定不行了。
说完如何设计 KV 操作后,因为我们的最终目标是实现分布式 KV 系统,那么,就让我们回到分布式系统最本源的一个问题上,如何实现分布式集群?
如何实现分布式集群?
我想说的是,正如在 09 讲中提到的,我推荐使用 Raft 算法实现分布式集群。而实现一个 Raft 集群,我们首先要考虑的是如何创建集群,为了简单起见,我们暂时不考虑节点的移除和替换等。
创建集群
在 Raft 算法中,我们可以这样创建集群。
- 先将第一个节点,通过 Bootstrap 的方式启动,并作为领导者节点。
- 其他节点与领导者节点通讯,将自己的配置信息发送给领导者节点,然后领导者节点调用 AddVoter() 函数,将新节点加入到集群中。
创建了集群后,在集群运行中,因为 Raft 集群的领导者不是固定不变的,而写请求是必须要在领导者节点上处理的,那么如何实现写操作,来保证写请求都会发给领导者呢?
写操作
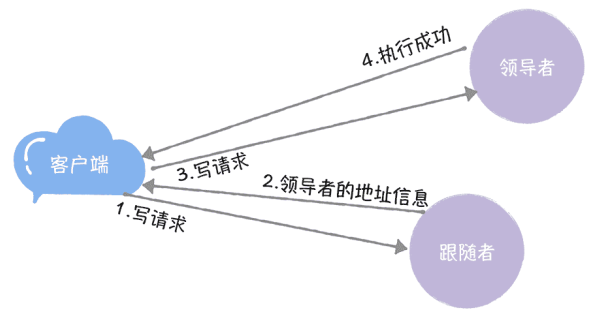
一般而言,有 2 种方法来实现写操作。我来具体说说。
方法 1:跟随者接收到客户端的写请求后,拒绝处理这个请求,并将领导者的地址信息返回给客户端,然后客户端直接访问领导者节点,直到该领导者退位,就像下图的样子。
 方法 2:跟随者接收到客户端的写请求后,将写请求转发给领导者,并将领导者处理后的结果返回给客户端,也就是说,这时跟随者在扮演“代理”的角色,就像下图的样子。
方法 2:跟随者接收到客户端的写请求后,将写请求转发给领导者,并将领导者处理后的结果返回给客户端,也就是说,这时跟随者在扮演“代理”的角色,就像下图的样子。
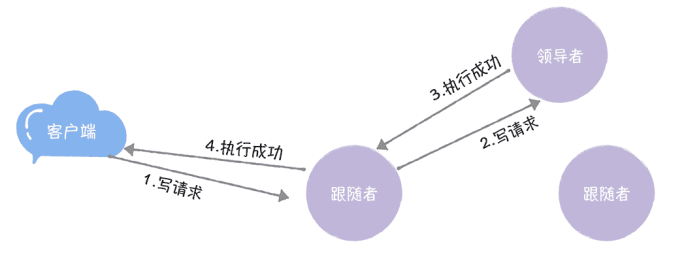
在我看来,虽然第一种方法需要客户端的配合,但实现起来复杂度不高;另外,第二种方法,虽然能降低客户端的复杂度,客户端像访问一个黑盒一样,访问系统,对领导者变更完全无感知。
但是这个方法会引入一个中间节点(跟随者),增加了问题分析排查的复杂度。而且,一般情况下,在绝大部分的时间内(比如 Google Chubby 团队观察到的值是数天),领导者是处于稳定状态的,某个节点一直是领导者,那么引入中间节点,就会增加大量的不必要的消息和性能消耗。所以,综合考虑,我推荐方法 1。
学习了 Raft 算法后,我们知道,相比写操作(只要在领导者节点执行就可以了)而言,读操作要复杂些,因为如何实现读操作,关乎着一致性的实现,也就是说,怎么实现读操作,决定了客户端是否会读取到旧数据。那么如何实现读操作呢?
读操作
其实,在实际系统中,并不是实现了强一致性就是最好的,因为实现了强一致性,必然会限制集群的整体性能。也就是说,我们需要根据实际场景特点进行权衡折中,这样,才能设计出最适合该场景特点的读操作。比如,我们可以实现类似 Consul 的 3 种读一致性模型。
- default:偶尔读到旧数据。
- consistent:一定不会读到旧数据。
- stale:会读到旧数据。
如果你不记得这 3 种模型的含义了,你可以去 09 讲回顾下,在这
里,我就不啰嗦了。
也就是说,我们可以实现多种读一致性模型,将最终的一致性选择权交给用户,让用户去选择,就像下面的样子。
curl -XGET http://raft-cluster-host02:8091/key/foo?level=consistent -L
内容小结
本节课我主要带你了解了一个基本的分布式 KV 系统的架构,和需要权衡折中的技术细节,我希望你明确的重点如下。
-
在设计 KV 操作时,更确切的说,在实现 Raft 指令时,一定要考虑冥等性,因为 Raf 指令是可能会被重复提交和执行。
-
推荐你采用这种方式来实现写操作:跟随者接收到客户端的写请求时,拒绝该请求并返回领导者的地址信息给客户端,然后客户端直接访问领导者。
-
在 Raft 集群中,如何实现读操作,关乎一致性的实现,推荐实现 default、consistent、stale 三种一致性模型,将一致性的选择权交给用户,让用户根据实际业务特点,按需选择,灵活使用。
最后,我想说的是,这个基本的分布式 KV 系统,除了适合入门学习外,也比较适合配置中心、名字服务等小数据量的系统。另外我想补充一下,对于数据层组件,不仅性能重要,成本也很重要,而决定数据层组件的成本的最关键的一个理念是冷热分离,一般而言,可以这么设计三级缓存:
- 热数据:经常被访问到的数据,我们可以将它们放在内存中,提升访问效率。
- 冷数据:有时会被访问到的数据,我们可以将它们放在 SSD 硬盘上,访问起来也比较快。
- 陈旧数据:偶尔会被访问到的数据,我们可以将它们放在普通磁盘上,节省存储成本。
在实际系统中,你可以统计热数据的命中率,并根据命中率来动态调整冷热模型。在这里,我想强调的是,冷热分离理念在设计海量数据存储系统时尤为重要,比如,自研 KV 存储的成本仅为 Redis 数十分之一,其中系统设计时非常重要的一个理念就是冷热分离。希望你能重视这个理念,在实际场景中活学活用。
课堂思考
我提到了其他节点与领导者节点通讯,将自己的配置信息发送给领导者节点,然后领导者节点调用 addVoter() 函数,将新节点加入到集群中,那么,你不妨思考一下,当节点故障时,如何替换一个节点呢?
20丨基于Raft的分布式KV系统开发实战(二):如何实现代码?
相信你已经了解了分布式 KV 系统的架构设计,同时应该也很好奇,架构背后的细节代码是怎么实现的呢?
别着急,今天这节课,我会带你弄明白这个问题。我会具体讲解分布式 KV 系统核心功能点的实现细节。比如,如何实现读操作对应的 3 种一致性模型。而我希望你能在课下反复运行程序,多阅读源码,掌握所有的细节实现。
话不多说,我们开始今天的学习。
在上一讲中,咱们将系统划分为三大功能块(接入协议、KV 操作、分布式集群),那么今天我会按顺序具体说一说每块功能的实现,帮助你掌握架构背后的细节代码。首先,先来了解一下,如何实现接入协议。
如何实现接入协议?
在 19 讲提到,我们选择了 HTTP 协议作为通讯协议,并设计了"/key"和"/join"2 个 HTTP RESTful API,分别用于支持 KV 操作和增加节点的操作,那么,它们是如何实现的呢?
接入协议的核心实现,就是下面的样子。
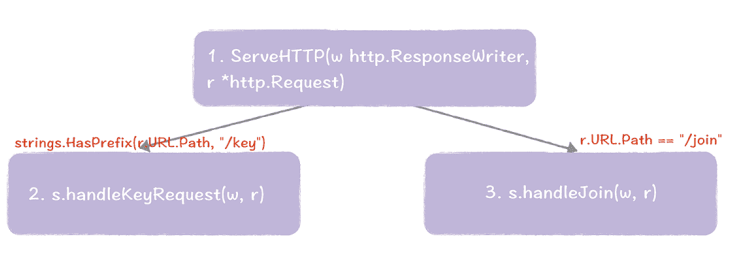
我带你走一遍这三个步骤,便于你加深印象。
在 ServeHTTP() 中,会根据 URL 路径设置相关的路由信息。比如,会在 handlerKeyRequest() 中处理 URL 路径前缀为"/key"的请求,会在 handleJoin() 中处理 URL 路径为"/join"的请求。
在 handleKeyRequest() 中,处理来自客户端的 KV 操作请求,也就是基于 HTTP POST 请求的赋值操作、基于 HTTP GET 请求的查询操作、基于 HTTP DELETE 请求的删除操作。
在 handleJoin() 中,处理增加节点的请求,最终调用 raft.AddVoter() 函数,将新节点加入到集群中。
在这里,需要你注意的是,在根据 URL 设置相关路由信息时,你需要考虑是路径前缀匹配(比如 strings.HasPrefix(r.URL.Path, “/key”)),还是完整匹配(比如 r.URL.Path == “/join”),避免在实际运行时,路径匹配出错。比如,如果对"/key"做完整匹配(比如 r.URL.Path == “/key”),那么下面的查询操作会因为路径匹配出错,无法找到路由信息,而执行失败。
curl -XGET raft-cluster-host01:8091/key/foo
另外,还需要你注意的是,只有领导者节点才能执行 raft.AddVoter() 函数,也就是说,handleJoin() 函数,只能在领导者节点上执行。
说完接入协议后,接下来咱们来分析一下第二块功能的实现,也就是,如何实现 KV 操作。
如何实现KV操作?
上一节课,我提到这个分布式 KV 系统会实现赋值、查询、删除 3 类操作,那具体怎么实现呢?你应该知道,赋值操作是基于 HTTP POST 请求来实现的,就像下面的样子。
curl -XPOST http://raft-cluster-host01:8091/key -d '{"foo": "bar"}'
也就是说,我们是通过 HTTP POST 请求,实现了赋值操作。
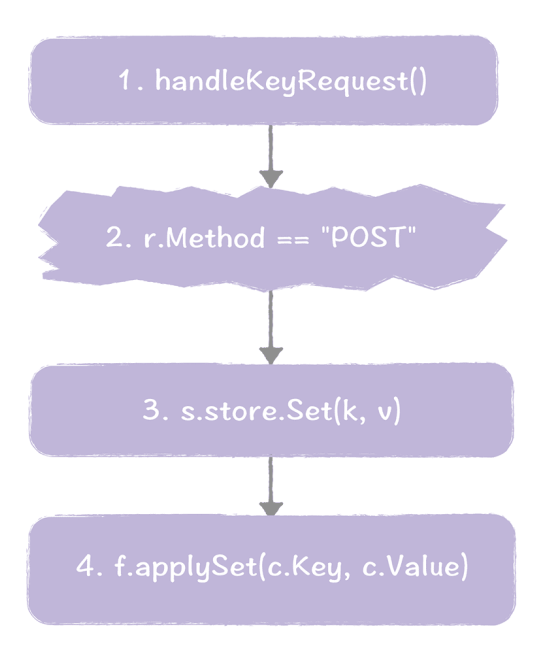
同样的,我们走一遍这个过程,加深一下印象。
- 当接收到 KV 操作的请求时,系统将调用 handleKeyRequest() 进行处理。
- 在 handleKeyRequest() 函数中,检测到 HTTP 请求类型为 POST 请求时,确认了这是一个赋值操作,将执行 store.Set() 函数。
- 在 Set() 函数中,将创建指令,并通过 raft.Apply() 函数将指令提交给 Raft。最终指令将被应用到状态机。
- 当 Raft 将指令应用到状态机后,最终将执行 applySet() 函数,创建相应的 key 和值到内存中。
在这里,我想补充一下,FSM 结构复用了 Store 结构体,并实现了 fsm.Apply()、fsm.Snapshot()、fsm.Restore()3 个函数。最终应用到状态机的数据,以 map[string]string 的形式,存放在 Store.m 中。
那查询操作是怎么实现的呢?它是基于 HTTP GET 请求来实现的。
curl -XGET http://raft-cluster-host01:8091/key/foo
也就是说,我们是通过 HTTP GET 请求实现了查询操作。在这里我想强调一下,相比需要将指令应用到状态机的赋值操作,查询操作要简单多了,因为系统只需要查询内存中的数据就可以了,不涉及状态机。具体的代码流程如图所示。
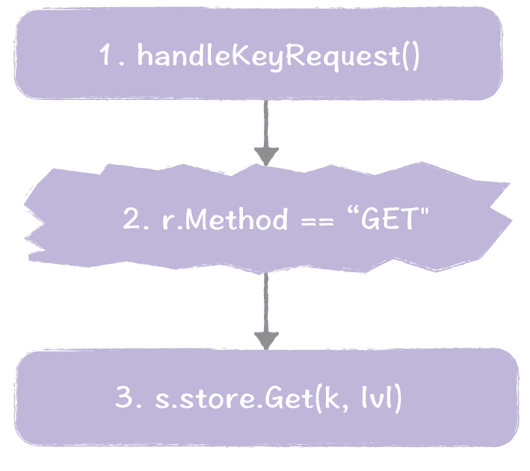
我们走一遍这个过程,加深一下印象。
- 当接收到 KV 操作的请求时,系统将调用 handleKeyRequest() 进行处理。
- 在 handleKeyRequest() 函数中,检测到 HTTP 请求类型为 GET 请求时,确认了这是一个赋值操作,将执行 store.Get() 函数。
- Get() 函数在内存中查询指定 key 对应的值。
而最后一个删除操作,是基于 HTTP DELETE 请求来实现的。
curl -XDELETE http://raft-cluster-host01:8091/key/foo
也就是说,我们是通过 HTTP DELETE 请求,实现了删除操作。
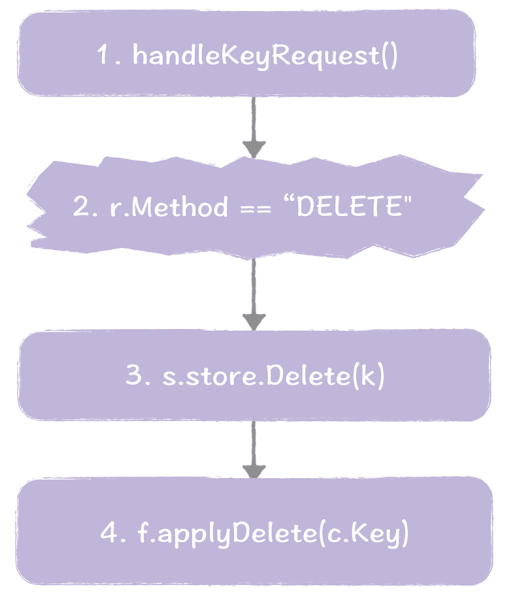
同样的,我们走一遍这个过程。
- 当接收到 KV 操作的请求时,系统将调用 handleKeyRequest() 进行处理。
- 在 handleKeyRequest() 函数中,检测到 HTTP 请求类型为 DELETE 请求时,确认了这是一个删除操作,将执行 store.Delete() 函数。
- 在 Delete() 函数中,将创建指令,并通过 raft.Apply() 函数,将指令提交给 Raft。最终指令将被应用到状态机。
- 当前 Raft 将指令应用到状态机后,最终执行 applyDelete() 函数,删除 key 和值。
学习这部分内容的时候,有一些同学可能会遇到,不知道如何判断指定的操作是否需要在领导者节点上执行的问题,我给的建议是这样的。
- 需要向 Raft 状态机中提交指令的操作,是必须要在领导者节点上执行的,也就是所谓的写请求,比如赋值操作和删除操作。
- 需要读取最新数据的查询操作(比如客户端设置查询操作的读一致性级别为 consistent),是必须在领导者节点上执行的。
说完了如何实现 KV 操作后,来看一下最后一块功能,如何实现分布式集群。
如何实现分布式集群?
创建集群
实现一个 Raft 集群,首先我们要做的就是创建集群,创建 Raft 集群,主要分为两步。首先,第一个节点通过 Bootstrap 的方式启动,并作为领导者节点。启动命令就像下面的样子。
$GOPATH/bin/raftdb -id node01 -haddr raft-cluster-host01:8091 -raddr raft-cluster-host01:8089 ~/.raftdb
这时将在 Store.Open() 函数中,调用 BootstrapCluster() 函数将节点启动起来。
接着,其他节点会通过 -join 参数指定领导者节点的地址信息,并向领导者节点发送,包含当前节点配置信息的增加节点请求。启动命令就像下面的样子。
$GOPATH/bin/raftdb -id node02 -haddr raft-cluster-host02:8091 -raddr raft-cluster-host02:8089 -join raft-cluster-host01:8091 ~/.raftdb
当领导者节点接收到来自其他节点的增加节点请求后,将调用 handleJoin() 函数进行处理,并最终调用 raft.AddVoter() 函数,将新节点加入到集群中。
在这里,需要你注意的是,只有在向集群中添加新节点时,才需要使用 -join 参数。当节点加入集群后,就可以像下面这样,正常启动进程就可以了。
$GOPATH/bin/raftdb -id node02 -haddr raft-cluster-host02:8091 -raddr raft-cluster-host02:8089 ~/.raftdb
集群运行起来后,因为领导者是可能会变的,那么如何实现写操作,来保证写请求都在领导者节点上执行呢?
写操作
在 19 讲中,我们选择了方法 2 来实现写操作。也就是,当跟随者接收到写请求后,将拒绝处理该请求,并将领导者的地址信息转发给客户端。后续客户端就可以直接访问领导者(为了演示方便,我们以赋值操作为例)。
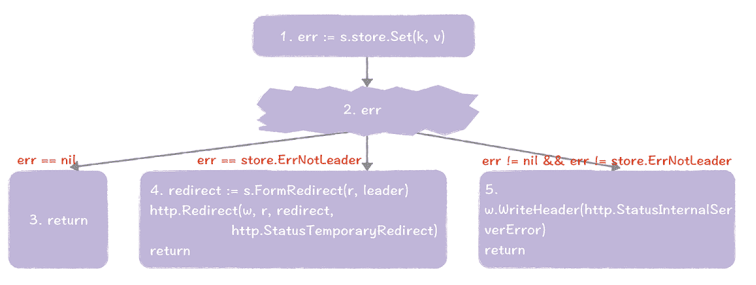
我们来看一下具体的内容。
- 调用 Set() 函数执行赋值操作。
- 如果执行 Set() 函数成功,将执行步骤 3;如果执行 Set() 函数出错,且提示出错的原因是当前节点不是领导者,那这就说明了当前节点不是领导者,不能执行写操作,将执行步骤 4;如果执行 Set() 函数出错,且提示出错的原因不是因为当前节点不是领导者,将执行步骤 5。
- 赋值操作执行成功,正常返回。
- 节点将构造包含领导者地址信息的重定向响应,并返回给客户端。然后客户端直接访问领导者节点执行赋值操作。
- 系统运行出错,返回错误信息给客户端。
需要你注意的是,赋值操作和删除操作属于写操作,必须在领导者节点上执行。而查询操作,只是查询内存中的数据,不涉及指令提交,可以在任何节点上执行。
而为了更好的利用 curl 客户端的 HTTP 重定向功能,我实现了 HTTP 307 重定向,这样,你在执行赋值操作时,就不需要关心访问节点是否是领导者节点了。比如,你可以使用下面的命令,访问节点 2(也就是 raft-cluster-host02,192.168.0.20)执行赋值操作。
curl -XPOST raft-cluster-host02:8091/key -d '{"foo": "bar"}' -L
如果当前节点(也就是节点 2)不是领导者,它将返回包含领导者地址信息的 HTTP 307 重定向响应给 curl。这时,curl 根据响应信息,重新发起赋值操作请求,并直接访问领导者节点(也就是节点 1,192.168.0.10)。具体的过程,就像下面的 Wireshark 截图。

读操作
我想说的是,我们可以实现 3 种一致性模型(也就是 stale、default、consistent),这样,用户就可以根据场景特点,按需选择相应的一致性级别,是不是很灵活呢?
具体的读操作的代码实现,就像下面的样子。
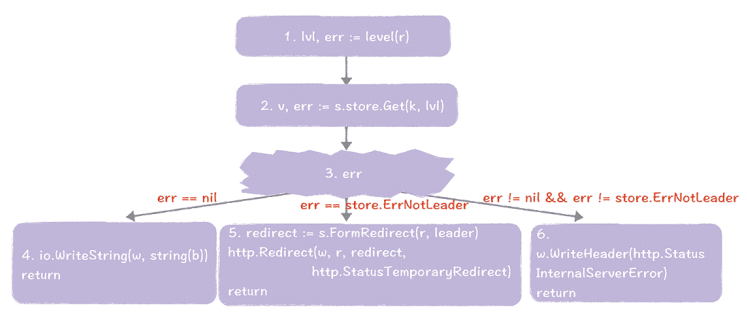
我们走一遍这个过程。
- 当接收到 HTTP GET 的查询请求时,系统会先调用 level() 函数,来获取当前请求的读一致性级别。
- 调用 Get() 函数,查询指定 key 和读一致性级别对应的数据。
- 如果执行 Get() 函数成功,将执行步骤 4;如果执行 Get() 函数出错,且提示出错的原因是当前节点不是领导者节点,那么这就说明了,在当前节点上执行查询操作不满足读一致性级别,必须要到领导者节点上执行查询操作,将执行步骤 5;如果执行 Get() 函数出错,且提示出错的原因不是因为当前节点不是领导者,将执行步骤 6。
- 查询操作执行成功,返回查询到的值给客户端。
- 节点将构造,包含领导者地址信息的重定向响应,并返回给客户端。然后客户端直接访问领导者节点查询数据。
- 系统运行出错,返回错误信息给客户端。
在这里,为了更好地利用 curl 客户端的 HTTP 重定向功能,我同样实现了 HTTP 307 重定向(具体原理,前面已经介绍了,这里就不啰嗦了)。比如,你可以使用下面的命令,来实现一致性级别为 consistent 的查询操作,不需要关心访问节点(raft-cluster-host02)是否是领导者节点。
curl -XGET raft-cluster-host02:8091/key/foo?level=consistent -L
内容小结
本节课我主要带你了解了接入协议、KV 操作、分布式集群的实现,我希望你记住下面三个重点内容:
- 我们可以借助 HTTP 请求类型,来实现相关的操作,比如,我们可以通过 HTTP GET 请求实现查询操作,通过 HTTP DELETE 请求实现删除操作。
- 你可以通过 HTTP 307 重定向响应,来返回领导者的地址信息给客户端,需要你注意的是,curl 已支持 HTTP 307 重定向,使用起来很方便,所以推荐你优先考虑 curl,在日常中执行 KV 操作。
- 在 Raft 中,我们可以通过 raft.VerifyLeader() 来确认当前领导者,是否仍是领导者。
在这里,我还想强调的一点,任何大系统都是由小系统和具体的技术组成的,比如能无限扩展和支撑海量服务的 QQ 后台,是由多个组件(协议接入组件、名字服务、存储组件等)组成的。而做技术最为重要的就是脚踏实地彻底吃透和掌握技术本质,小系统的关键是细节技术,大系统的关键是架构。所以,在课程结束后,我会根据你的反馈意见,再延伸性地讲解大系统(大型互联网后台)的架构设计技巧,和我之前支撑海量服务的经验。
这样一来,我希望能帮你从技术到代码、从代码到架构、从小系统到大系统,彻底掌握实战能力,跨过技术和实战的鸿沟。
虽然这个分布式 KV 系统比较简单,但它相对纯粹聚焦在技术,能帮助你很好的理解 Raft 算法、Hashicorp Raft 实现、分布式系统开发实战等。所以,我希望你不懂就问,有问题多留言,咱们一起讨论解决,不要留下盲区。
另外,我会持续维护和优化这个项目,并会针对大家共性的疑问,开发实现相关代码,从代码和理论 2 个角度,帮助你更透彻的理解技术。我希望你能在课下采用自己熟悉的编程语言,将这个系统重新实现一遍,在实战中,加深自己对技术的理解。如果条件允许,你可以将自己的分布式 KV 系统,以“配置中心”、“名字服务”等形式,在实际场景中落地和维护起来,不断加深自己对技术的理解。
课堂思考
我提到了通过 -join 参数,将新节点加入到集群中,那么,你不妨思考一下,如何实现代码移除一个节点呢?
加餐 | 拜占庭将军问题:如何基于签名消息实现作战计划的一致性?
我发现很多同学还是对一些知识有一些误区,再三考虑之后,决定利用今天这节课,先解决留言区提到的一个比较多的问题:如何基于签名消息实现作战计划的一致性?
除此之外,在论文学习中,很多同学遇到的共性问题比较多(比如 ZAB 协议的细节,后面我会补充几讲),在这里,我十分感谢你提出了这样宝贵的意见,不同的声音会帮助我不断优化课程。
所以,在课程结束之后,我会再从头梳理一遍,按照关注点通过更多的加餐不断优化内容,把相关的理论和算法的内容展开,帮你彻底吃透相关的内容。
说回咱们的拜占庭将军问题。在01 讲中,为了不啰嗦,让你举一反三地学习,我对签名消息型拜占庭问题之解,没有详细展开,而是聚焦在最核心的点“签名约束了叛徒的作恶行为”,但从留言来看,很多同学在理解签名和如何实现作战一致性上,还是遇到了问题。比如不理解如何实现作战计划的一致性。
另外,考虑到签名消息是一些常用的拜占庭容错算法(比如 PBFT)的实现基础,很重要,所以这节课我会对签名消息型拜占庭问题之解进行补充。在今天的内容中,除了具体讲解如何基于签名消息实现作战计划的一致性之外,我还会说一说什么是签名消息。希望在帮你掌握签名消息型拜占庭问题之解的同时,还帮你吃透相关的基础知识。
在这里,我想强调一下,为了更好地理解这一讲的内容,我建议你先回顾一下 01 讲,加深印象。当然,在学完 01 讲之后,相信你已经明白了,签名消息拜占庭问题之解,之所以能够容忍任意数量的叛徒,关键就在于通过消息的签名,约束了叛徒的作恶行为,也就是说,任何篡改和伪造忠将的消息的行为,都会被发现。
既然签名消息这么重要,那么什么是签名消息呢?
什么是签名消息?
签名消息指的就是带有数字签名的消息,你可以这么理解“数字签名”:类似在纸质合同上进行签名来确认合同内容和证明身份。
在这里我想说的是,数字签名既可以证实内容的完整性,又可以确认内容的来源,实现不可抵赖性(Non-Repudiation)。既然签名消息优点那么多,那么如何实现签名消息呢?
你应该还记得密码学的学术 CP(Bob 和 Alice)吧(不记得的话也没关系,你把他们当作 2 个人就可以了),今天 Bob 要给 Alice 发送一个消息,告诉她,“我已经到北京了”,但是 Bob 希望这个消息能被 Alice 完整地接收到,内容不能被篡改或者伪造,我们一起帮 Bob 和 Alice 想想办法,看看如何实现这个消息。
首先,为了避免密钥泄露,我们推荐 Bob 和 Alice 使用非对称加密算法(比如 RSA)。也就是说,加密和解密使用不同的秘钥,在这
里,Bob 持有需要安全保管的私钥,Alice 持有公开的公钥。
然后,Bob 用哈希算法(比如 MD5)对消息进行摘要,然后用私钥对摘要进行加密,生成数字签名(Signature),就像下图的样子:
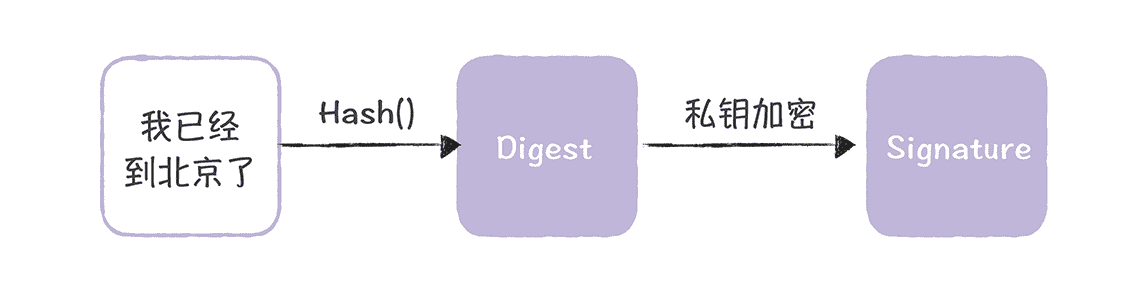
接着,Bob 将加密摘要和消息一起发送给 Alice:
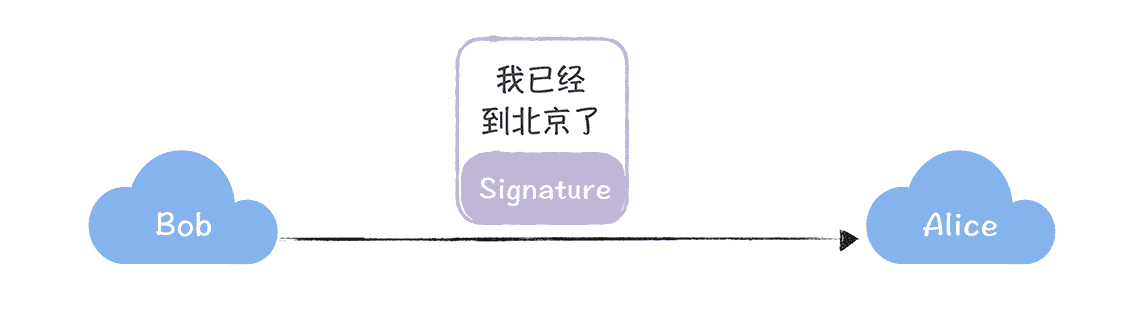
接下来,当 Alice 接收到消息和加密摘要(Signature)后,她会用自己的公钥对加密摘要(Signature)进行解密,并对消息内容进行摘要(Degist-2),然后将新获取的摘要(Degist-2)和解密后的摘要(Degist-1)进行对比,如果 2 个摘要(Digest-1 和 Digest-2)一致,就说明消息是来自 Bob 的,并且是完整的,就像下图的样子:
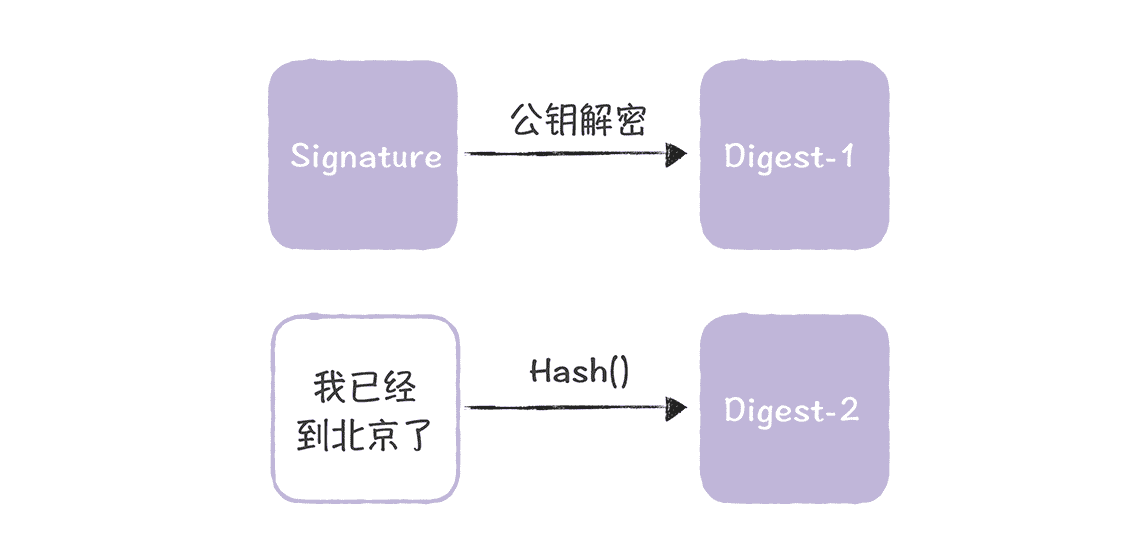
你看,通过这种方法,Bob 的消息就能被 Alice 完整接收到了,任何篡改和伪造 Bob 消息的行为,都会因为摘要不一致,而被发现。而这个消息就是签名消息。
在,你应该理解了什么是签名消息了吧?另外,关于在留言区提到的“为什么签名消息能约束叛将们的作恶行为?”,在这里,我再补充下,通过上面的 Bob 和 Alice 的故事,我们可以看到,在数字签名的约束下,叛将们是无法篡改和伪造忠将的消息的,因为任何篡改和伪造消息的行为都会被发现,也就是作恶的行为被约束了。也就是说,叛将这时能做“小”恶(比如,不响应消息,或者叛将们相互串通发送指定的消息)但他们无法篡改或伪造忠将的消息了。
既然数字签名约束了叛将们的作恶行为,那么苏秦怎么做才能实现作战的一致性的呢?也就是忠将们执行一致的作战计划。
如何实现作战计划的一致性?
之前我已经提到了,苏秦可以通过签名消息的方式,不仅能在不增加将军人数的情况下,解决二忠一叛的难题,还能实现无论叛将数多少,忠诚的将军们始终能达成一致的作战计划。
为了方便你理解,我以二忠二叛(更复杂的叛徒作恶模型,因为叛徒们可以相互勾结串通)为例具体演示一下,是怎样实现作战计划的一致性的:

需要你注意的是,4 位将军约定了一些流程来发送作战信息、执行作战指令。
第一轮:
先发送作战指令的将军,作为指挥官,其他的将军作为副官。
指挥官将他的签名的作战指令发送给每位副官。
每位副官,将从指挥官处收到的新的作战指令(也就与之前收的作战指令不同),按照顺序(比如按照首字母字典排序)放到一个盒子里。
第二轮:
除了第一轮的指挥官外,剩余的 3 位将军将分别作为指挥官,在上一轮收到的作战指令上,加上自己的签名,并转发给其他将军。
第三轮:
除了第一、二轮的指挥官外,剩余的 2 位将军将分别作为指挥官,在上一轮收到的作战指令上,加上自己的签名,并转发给其他将军。
最后,各位将军按照约定,比如使用盒子里最中间的那个指令来执行作战指令。(假设盒子中的指令为 A、B、C,那中间的指令也就是第 n /2 个命令。其中,n 为盒子里的指令数,指令从 0 开始编号,也就是 B)。
为了帮你直观地理解,如何基于签名消息实现忠将们作战计划的一致性,我来演示一下作战信息协商过程。而且我会分别以忠将和叛将先发送作战信息为例来演示,这样可以完整地演示叛将对作战计划干扰破坏的可能性。
那么忠诚的将军先发送作战信息的情况是什么呢?
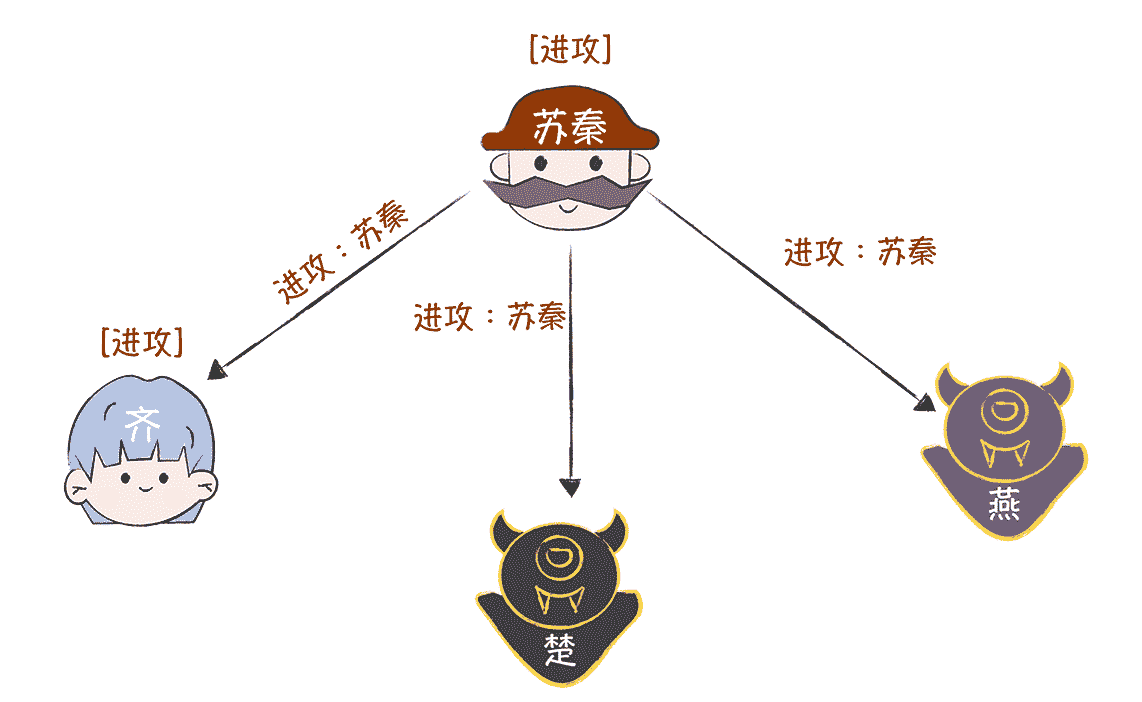
为了演示方便,假设苏秦先发起带有签名的作战信息,作战指令是“进攻”。那么在第一轮作战信息协商中,苏秦向齐、楚、燕发送作战指令“进攻”。
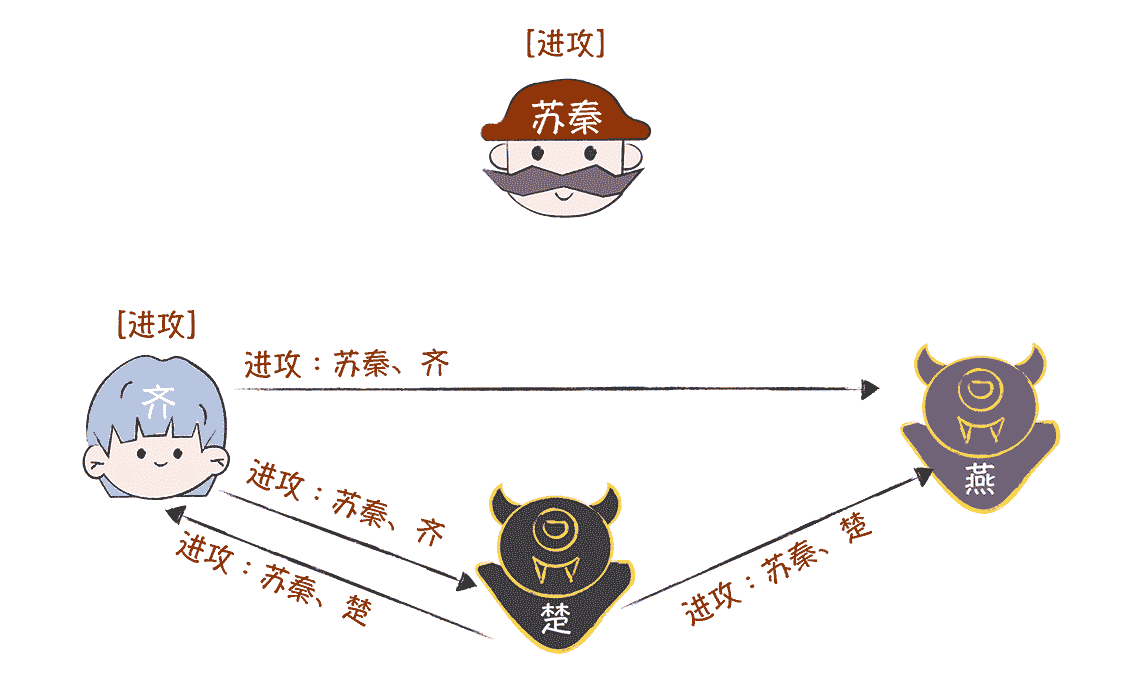
在第二轮作战信息协商中,齐、楚、燕分别作为指挥官,向另外 2 位发送作战信息“进攻”。可是楚、燕已经叛变了,但在签名的约束下,他们无法篡改和伪造忠将的消息,为了达到干扰作战计划的目的,他们俩一个选择发送消息,一个默不作声,不配合。
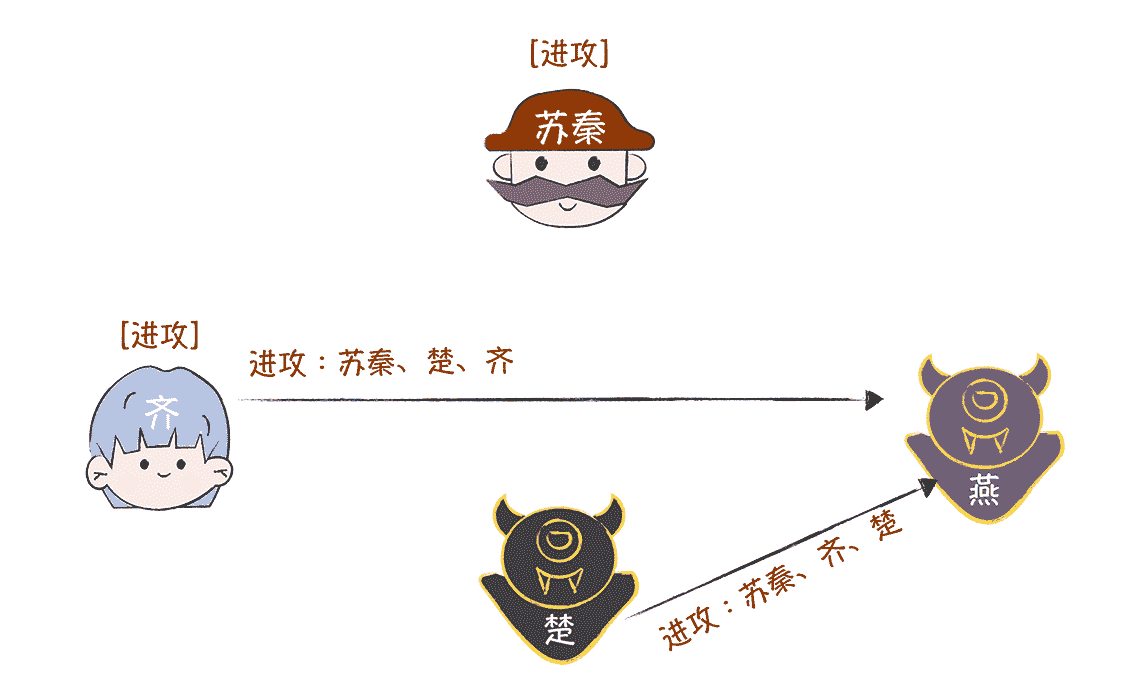
在第三轮作战信息协商中,齐、楚分别作为指挥官,将接收到的作战信息,附加上自己的签名,并转发给另外一位(这时的叛徒燕,还是默不作声,不配合)。
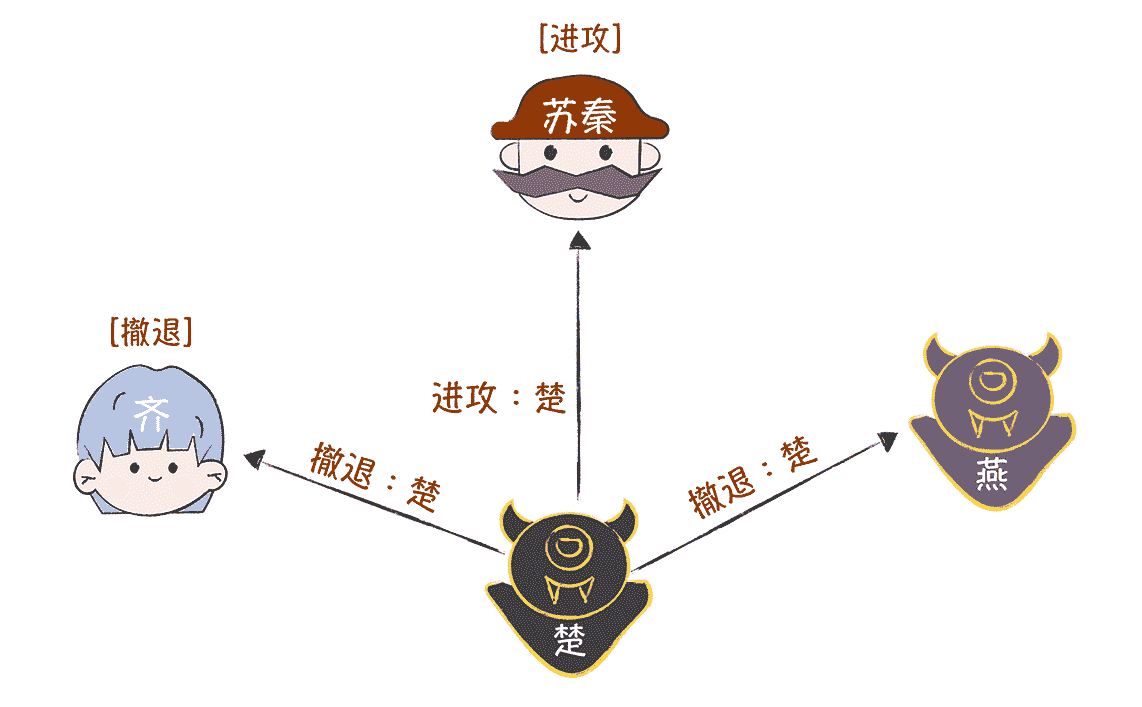
最终,齐收到的作战信息都是“进攻”(它收到了苏秦和楚的),按照“执行盒子最中间的指令”的约定,齐会和苏秦一起执行作战指令“进攻”,实现忠将们作战计划的一致性。
那么如果是叛徒楚先发送作战信息,干扰作战计划,结果会有所不同吗?我们来具体看一看。在第一轮作战信息协商中,楚向苏秦发送作战指令“进攻”,向齐、燕发送作战指令“撤退”。(当然还有其他的情况,这里只是选择了那么如果是叛徒楚先发送作战信息,干扰作战计划,结果会有所不同吗?我们来具体看一看。在第一轮作战信息协商中,楚向苏秦发送作战指令“进攻”,向齐、燕发送作战指令“撤退”。(当然还有其他的情况,这里只是选择了其中一种,其他的情况,你可以都推导着试试,看看结果是不是一样?)
然后,在第二轮作战信息协商中,苏秦、齐、燕分别作为指挥官,将接收到的作战信息,附加上自己的签名,并转发给另外两位。
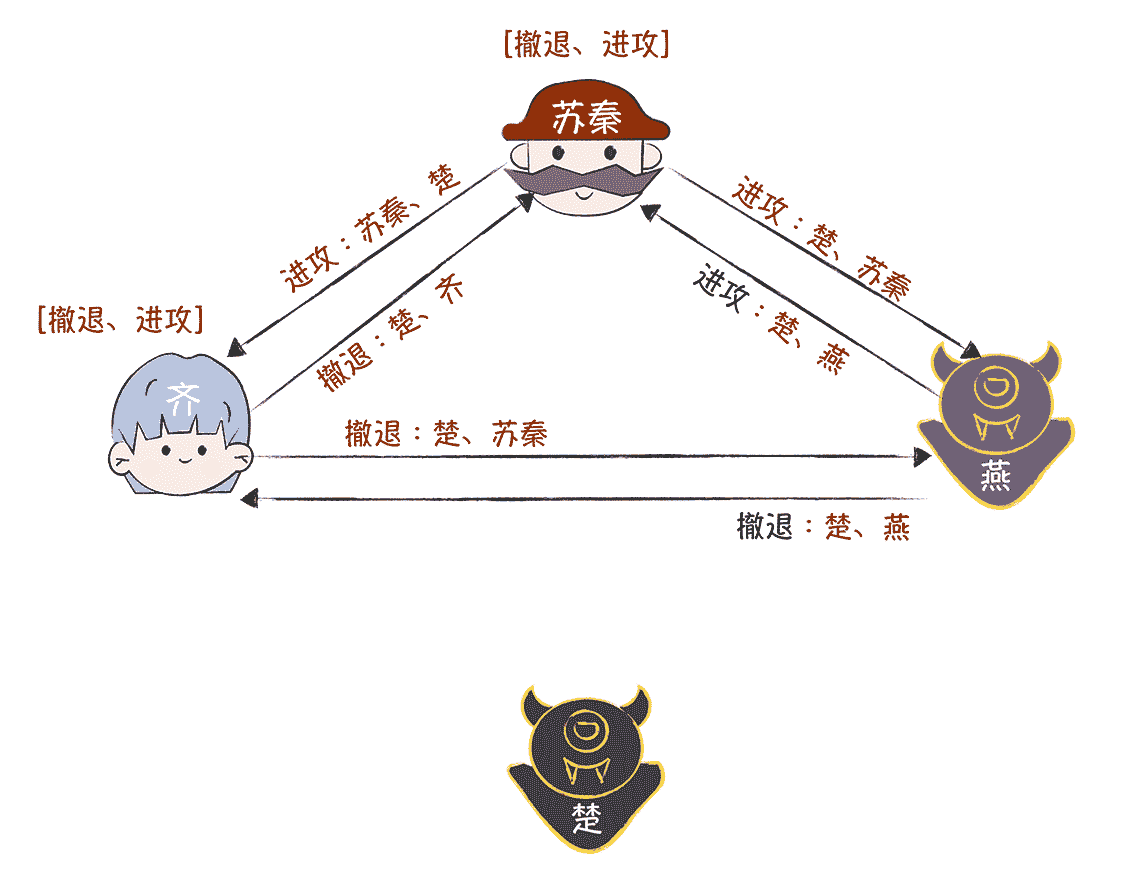
为了达到干扰作战计划的目的,叛徒楚和燕相互勾结了。比如,燕拿到了楚的私钥,也就是燕可以伪造楚的签名,这个时候,燕为了干扰作战计划,给苏秦发送作战指令“进攻”,给齐发送作战指令却是“撤退”。
接着,在第三轮作战信息协商中,苏秦、齐、燕分别作为指挥官,将接收到的作战信息,附加上自己的签名,并转发给另外一位。
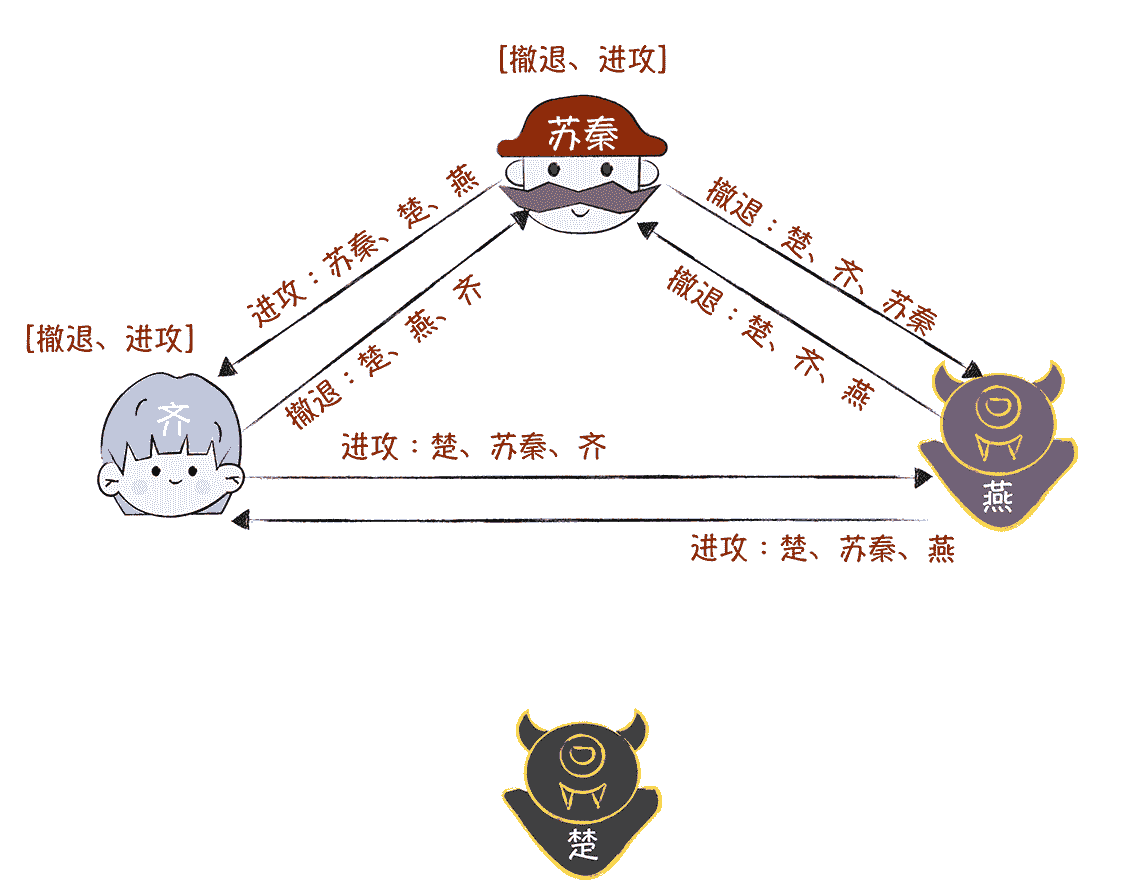
最终,苏秦和齐收到的作战信息都是“撤退、进攻”,按照“执行盒子最中间的指令”的约定,苏秦、齐和燕一起执行作战指令“撤退”,实现了作战计划的一致性。也就是说,无论叛将楚和燕如何捣乱,苏秦和齐都能执行一致的作战计划,保证作战的胜利。
另外在这里,我想补充一点,签名消息的拜占庭问题之解,也是需要进行 m+1 轮(其中 m 为叛将数,所以你看,只有楚、燕是叛变的,那么就进行了三轮协商)。你也可以从另外一个角度理解:n 位将军,能容忍 (n - 2) 位叛将(只有一位忠将没有意义,因为此时不需要达成共识了)。关于这个公式,你只需要记住就好了,推导过程你可以参考论文。
最后,我想说的是,签名消息型拜占庭问题之解,解决的是忠将们如何就作战计划达成共识的问题,也就只要忠将们执行了一致的作战计划就可以了。但它不关心这个共识是什么,比如,在适合进攻的时候,忠将们可能执行的作战计划是撤退。也就是,这个算法比较理论化。
关于理论化这一点,有的同学会想知道它如何去用,在我看来呢,这个算法解决的是共识的问题,没有与实际场景结合,是很难在实际场景中落地的。在实际场景中,你可以考虑后来的改进过后的拜占庭容错算法,比如 PBFT 算法。
内容小结
本节课我主要带你了解了什么签名消息,以及忠将们如何通过签名消息实现作战的一致性,我希望你明确这样几个重点:
-
数字签名是基于非对称加密算法(比如 RSA、DSA、DH)实现的,它能防止消息的内容被篡改和消息被伪造。
-
签名消息约束了叛徒的作恶行为,比如,叛徒可以不响应,可以相互勾结串通,但叛徒无法篡改和伪造忠将的消息。
-
需要你注意的是,签名消息拜占庭问题之解,虽然实现了忠将们作战计划的一致性,但它不关心达成共识的结果是什么。
最后,我想说的是,签名消息、拜占庭将军问题的签名消息之解是非常经典的基础知识,影响和启发了后来的众多拜占庭容错算法(比如 PBFT),理解了本讲的内容后,你能更好地理解其他的拜占庭容错算法,以及它们如何改进的?为什么要这么改进?比如,在 PBFT 中,基于性能的考虑,大部分场景的消息采用消息认证码(MAC),只有在视图变更(View Change)等少数场景中采用了数字签名。
课堂思考
我演示了在“二忠二叛”情况下,忠将们如何实现作战计划的一致性,那么你不妨推演下,在“二忠一叛”情况下,忠将们如何实现作战计划的一致性呢?
结束语 | 静下心来,享受技术的乐趣
就要说再见了,借今天这个机会,我想跟你唠点儿心里话。我问自己,如果只说一句话会是啥?想来想去,我觉得就是它了:静下心来,享受技术的乐趣。其实这与我之前的经历有关,我想你也能从我的经历中,看到你自己的影子。
我们都有这样的感觉,无论任何事情,如果想把它做好,其实都不容易。我记得自己在开发 InfluxDB 系统期间,为了确保进度不失控,常常睡在公司,加班加点;在写稿期间,为了交付更高质量的课程,我总是会有很多想法,偶尔会通宵写稿,核对每句话、每个细节;再比如,为了解答 kernel_distribution 同学的一个关于外部 PPT 的问题,
我通过 Google 找到相关代码的出处,然后反复推敲,在凌晨 4 点准备了一个答案。
当然,技术的学习就更加不容易了,不是读几遍材料、调调代码就可以了,而是需要我们设计检测模型,来验证自己是否准确地理解了技术。我曾见过一些团队,做技术决策的依据是不成立的,设计和开发的系统,尽管迭代多版,也始终稳定不下来。在我看来,这些团队最大的问题,就是对技术的理解不准、不够。
在我看来,我们需要调整下心态,也就是静下心来,全身心地投入,去体会技术的乐趣,“Hack it and enjoy it!”。然后学习和工作中的小成就,又会不断地给我们正反馈,激励我们,最终可以行云流水般地把事情越做越好。
为什么要考虑这些?因为我真心希望你是分布式系统的架构师、开发者,而不仅仅是开源软件的使用者。