[论文阅读] 人工智能 + 软件工程 | 从“人工扒日志”到“AI自动诊断”:LogCoT框架的3大核心创新
从“人工扒日志”到“AI自动诊断”:LogCoT框架的3大核心创新
论文信息
- 论文原标题:基于LLM的日志故障诊断(Log Fault Diagnosis Based on Large Language Models)
- 主要作者及研究机构:
- 许婷¹、肖桐²、张圣林¹、孙一丹¹、孙永谦¹、裴丹²*(*通讯作者)
- ¹ 南开大学软件学院,天津 300457;² 清华大学计算机科学与技术系,北京 100084
- 发表信息:电子学报(ACTA ELECTRONICA SINICA),2025年第4期(Vol. 53 No.4),DOI:10.12263/DZXB.20240801
- APA引文格式:许婷, 肖桐, 张圣林, 孙一丹, 孙永谦, 裴丹. (2025). 基于LLM的日志故障诊断. 电子学报, 53(4), 1123-19. https://doi.org/10.12263/DZXB.20240801
- 基金项目:国家自然科学基金(No.62272249, No.62302244)
一段话总结
针对现有日志故障诊断“只给结果不讲理”(缺乏可解释性)、中等规模LLM诊断不准、人工推理耗时的痛点,许婷团队提出LogCoT框架:通过Auto-FSC算法让超大规模闭源LLM(如Claude 3.5 Sonnet)自动生成推理示例,引导基座模型Mistral实现少样本高效推理;再用LLMf-IPO算法纠正错误结果,结合混合调优提升性能。在两大真实生产数据集上,LogCoT的Accuracy比现有最佳模型分别高31.88%和10.51%,还能输出清晰的根因分析报告,彻底解决运维人员“不敢信AI诊断”的问题。
思维导图
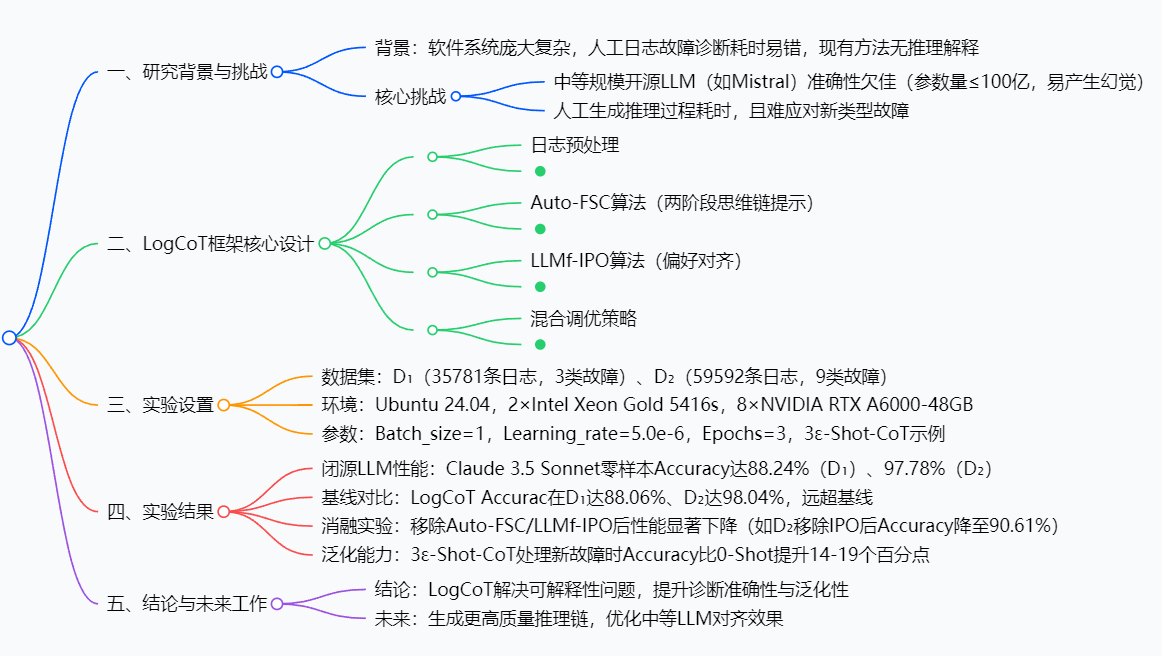
研究背景:日志故障诊断的“三大困境”
想象一下:某互联网公司服务器突然崩了,运维团队面对几十万条日志,要在1小时内找到故障原因——这就像在满是沙子的沙滩里找一颗特定的石头,不仅耗时,还容易漏掉关键信息。这就是当前日志故障诊断的真实场景,而这个场景还藏着三个更棘手的“困境”:
困境1:“黑箱”诊断,运维不敢信
现有方法(比如LogCluster、Cloud19)能告诉你“是CPU故障”,但说不出“为什么是CPU故障”——既不解释哪条日志指向CPU,也不说明推理逻辑。运维人员不敢直接用AI结果下决策,最后还是得人工复核,AI成了“摆设”。
困境2:大模型“选边难”
要让AI懂日志,得用大语言模型(LLM),但选模型却很纠结:
- 超大规模闭源LLM(如GPT-4o、Claude 3.5 Sonnet):推理准,但调用一次几块钱,企业天天用成本太高,还依赖外部接口稳定性;
- 中等规模开源LLM(如Mistral、Llama-3.1-8B):免费且部署灵活,但参数量少(≤100亿),分析日志时容易“胡思乱想”(产生“幻觉”),诊断 accuracy 只有60%-70%。
困境3:人工推理“跟不上”
要让中等LLM变准,得给它喂“日志+推理过程”的示例。但人工写这些示例太费劲:一个故障案例要分析10+条日志,写几百字推理,遇到新故障(比如从没见过的“CRC Error”),又得重新写——运维团队根本忙不过来。
正是这三个困境,让“AI自动诊断日志故障”在生产环境里一直推不开。而LogCoT框架,就是为解决这些问题而来。
创新点:LogCoT的“三大突破”
LogCoT没有重复现有方法的老路,而是从“推理逻辑”“模型优化”“成本控制”三个维度做了创新,每一个突破都精准命中痛点:
突破1:Auto-FSC算法——让AI自己写“推理教案”
不用人工写示例!Auto-FSC让超大规模闭源LLM(比如Claude 3.5 Sonnet)当“老师”,自动生成“日志+推理步骤+故障标签”的“教案”:
- 第一步:给闭源LLM喂无标注日志,加一句“Let’s think step by step”,它会自动分析“这条日志里的‘Processor Error’字段,说明CPU配置有问题”,并输出故障标签;
- 第二步:从这些“教案”里挑3个最有代表性的(比如分别对应CPU、内存、网络故障),喂给中等LLM(Mistral)当“例题”。
这样一来,Mistral不用人工教,也能学会怎么分析日志,推理 accuracy 直接从68%提升到86%+。
突破2:LLMf-IPO算法——让AI“知错就改”
中等LLM难免犯错(比如把“内存ECC错误”误判为“CPU故障”),LLMf-IPO让它能“自我纠错”:
- 先找3个“帮手”(Llama-3.1-8B、Gemma-2-9B、Qianwen-2-7B),让它们对同一条日志分别出诊断结果;
- 再让闭源LLM当“裁判”,给3个结果打分(比如“Llama的结果更准,因为它注意到了‘Memory DIMM’字段”),生成“好结果(Chosen)+坏结果(Rejected)”的对比数据;
- 最后用这些数据微调Mistral,让它记住“哪些错误不能犯”。
经过这一步,Mistral的诊断 accuracy 又能再涨5%-8%,还能对齐运维的判断习惯(比如优先关注“Asserted”状态的日志)。
突破3:混合调优——让中等LLM“更懂日志”
LogCoT没有只靠示例喂模型,而是用两种微调方式“双管齐下”:
- Prompt-Tuning(指令优化):给Mistral加“日志分析专用指令”(比如“优先关注Time、EventID、Content字段”),不用改模型参数,快速提升它对日志的理解;
- Preference-Tuning(偏好微调):用LLMf-IPO生成的“好/坏结果”数据,调整模型参数,让它更倾向于输出符合运维需求的结果。
这种混合调优,既避免了“只调指令效果弱”,又解决了“只调参数过拟合”的问题。
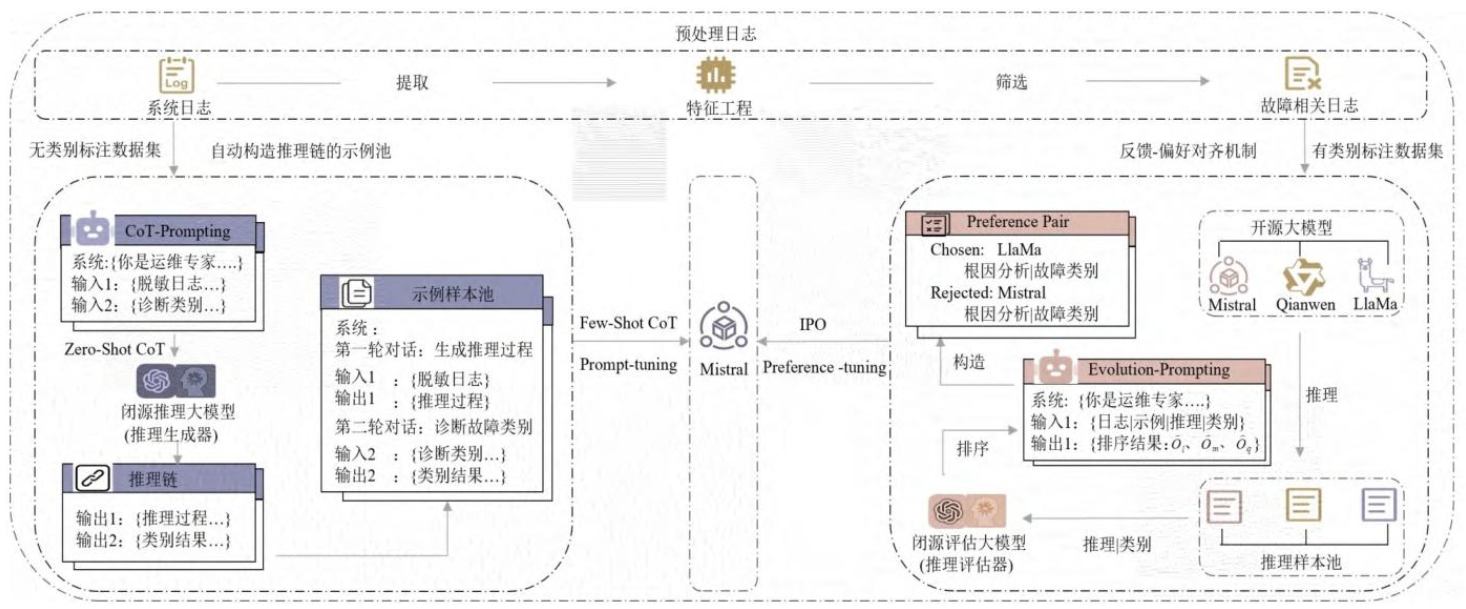
研究方法和思路:LogCoT的“四步工作流”
LogCoT的逻辑很清晰,就像给AI搭了一条“日志诊断流水线”,分四步就能完成从“原始日志”到“可解释结果”的转化:
第一步:日志预处理——把“有用的日志挑出来”
原始日志里有很多垃圾信息(比如正常的“系统启动日志”),先做两件事:
- 脱敏:把服务器序列号(SN)、型号(SM)等敏感信息换掉,避免数据泄露;
- 筛选:用TF-IDF算法给日志“打分”——比如“Processor”“Uncorrectable ECC”这些关键词权重高,对应的日志就被挑出来,当成“故障相关日志”。
这一步能把几十万条日志压缩到几百条,大大减少后续分析压力。
第二步:Auto-FSC生成示例——给Mistral找“例题”
让超大规模闭源LLM(以Claude 3.5 Sonnet为例)生成示例池:
- 零样本推理:给Claude喂筛选后的日志,它输出推理链(比如“日志1:Memory CPU0F0_DIMM_Stat显示Uncorrectable ECC→说明内存有不可纠正错误”)和故障标签(“Memory故障”);
- 筛选示例:从生成的示例里挑3个(3ε-Shot),覆盖不同故障类型,组成“示例集”。
第三步:Mistral推理——让“学生”做题
把“示例集+新日志”喂给Mistral,它会先学示例的推理逻辑,再分析新日志:
- 第一步:输出推理过程(比如“新日志里的‘Processor CPU0_Status’是Configuration Error→指向CPU故障”);
- 第二步:输出故障标签(“CPU故障”)。
这一步就能得到“可解释”的初步结果。
第四步:LLMf-IPO对齐——让结果“更准更贴合需求”
- 多模型生成回复:让Llama、Gemma、Qianwen三个模型,分别对Mistral的结果做“补充诊断”;
- 闭源LLM评分:Claude根据真实故障原因(ground-truth),给三个回复打分,选最高分的当“Chosen”,随机选一个低分的当“Rejected”;
- IPO训练:用“Chosen-Rejected”数据微调Mistral,优化它的判断逻辑。
最后输出的,就是既准又能说清道理的故障诊断结果。
主要成果和贡献:LogCoT到底有多厉害?
LogCoT的成果不是“纸上谈兵”,而是在两大真实生产数据集上跑出来的,每一个结果都能解决实际问题:
1. 性能碾压基线模型
在D₁(互联网服务商日志,3类故障)和D₂(云服务商日志,9类故障)上,LogCoT的三个核心指标(Accuracy、Macro-F1、Weighted-F1)都远超现有最佳方法:
| 数据集 | 指标 | LogCoT(本文) | 现有最佳模型 | 提升幅度 |
|---|---|---|---|---|
| D₁ | Accuracy | 88.06% | 56.18% | +31.88个百分点 |
| D₁ | Macro-F1 | 84.44% | 62.10% | +22.34个百分点 |
| D₁ | Weighted-F1 | 88.14% | 65.70% | +22.44个百分点 |
| D₂ | Accuracy | 98.04% | 87.53% | +10.51个百分点 |
| D₂ | Macro-F1 | 98.26% | 81.83% | +16.43个百分点 |
| D₂ | Weighted-F1 | 98.03% | 88.28% | +9.75个百分点 |
这意味着:在D₁这样数据不均衡的场景下,LogCoT能少漏判31.88%的故障;在D₂这样故障类型多的场景下,也能多判对10.51%的案例——运维团队不用再担心“AI漏报故障”了。
2. 可解释性落地
LogCoT会输出完整的推理链,比如对一条“CPU故障”日志,它会写:
- 日志Content字段包含“Processor CPU0_Status”和“Configuration Error”;
- “Processor”关键词权重最高(TF-IDF得分0.82),指向CPU相关组件;
- “Configuration Error”状态为“Deasserted”,说明CPU配置异常;
- 综上,故障类别为“CPU故障”。
运维人员能顺着这个逻辑复核,不用再“猜AI怎么想”,终于敢用AI结果了。
3. 泛化能力强,能应对新故障
遇到没见过的故障类型(比如D₂里的“BFD Down”),LogCoT也能处理:
- 0-Shot策略(没见过该故障):Accuracy只有71.22%;
- LogCoT(用其他8类故障的示例引导):Accuracy提升到85.31%,接近完整示例的性能(90.44%)。
这意味着系统新增故障时,不用重新写示例,LogCoT能自己“举一反三”。
4. 成本可控
LogCoT只用超大规模闭源LLM生成示例(一次生成能用很久),后续诊断用中等LLM(Mistral):
- 闭源LLM生成示例成本:D₁数据集51个案例,总成本约20元;
- 中等LLM诊断成本:单案例推理时间6-7秒,服务器本地部署,零调用费。
对企业来说,既省了钱,又不用依赖外部接口。
关键问题:一文读懂LogCoT核心
Q1:LogCoT怎么解决“运维不信AI结果”的问题?
A:核心是“强制AI写推理”。通过Auto-FSC算法,让LogCoT输出“日志关键词→推理步骤→故障标签”的完整链条,每一步都对应具体日志内容(比如“‘Memory DIMM’字段指向内存故障”)。运维人员能顺着链条复核,看到AI的“思考过程”,自然敢信。
Q2:Auto-FSC和LLMf-IPO有什么区别?
A:Auto-FSC是“教AI怎么想”,LLMf-IPO是“帮AI改错题”:
- Auto-FSC:用闭源LLM生成示例,教中等LLM“分析日志的方法”;
- LLMf-IPO:用多模型反馈和IPO训练,纠正中等LLM的“判断错误”(比如把内存故障误判为CPU故障)。
两者一前一后,前者打基础,后者提精度。
Q3:LogCoT为什么选Mistral当基座模型?
A:选Mistral是平衡“性能”和“成本”的结果:
- 性能上:Mistral在中等LLM里推理速度快(单案例0.4秒),支持指令微调;
- 成本上:参数量70亿,能在普通GPU(如RTX A6000)上部署,不用买超算;
- 灵活性上:开源可定制,企业能根据自己的日志格式改模型。
Q4:LogCoT在数据量少的场景下能用吗?
A:能用。论文里D₁数据集只有1717个故障案例,其中用于训练的只有51个(2%无标注+5%有标注),但LogCoT的Accuracy仍达88.06%。这是因为Auto-FSC能高效利用闭源LLM生成的示例,不用依赖海量标注数据,小公司也能落地。
总结
LogCoT框架用“Auto-FSC生成推理示例”“LLMf-IPO纠正错误”“混合调优提升性能”的组合拳,解决了日志故障诊断的三大核心痛点:
- 用推理链打破“黑箱”,让运维敢信AI结果;
- 用中等LLM+闭源LLM辅助,平衡“成本”和“精度”;
- 自动生成示例+泛化能力,减少人工工作量。
实验证明,它在真实生产数据集上的性能远超基线,还能落地可解释性和成本控制——这不仅是技术上的突破,更让“AI自动诊断日志故障”从“实验室”走进了“生产车间”。
未来,LogCoT团队计划进一步优化推理链质量,让AI的逻辑更贴近运维习惯,还会提升模型对“未见过日志格式”的适应能力,让框架更通用。对企业来说,这无疑是日志运维的“新工具”,也是AI落地运维领域的“新方向”。