猫头虎AI开源项目分享:通过压缩-感知-扩展来改善RAG应用延迟的高效框架:REFRAG,速度快、质量高
猫头虎AI开源项目分享:通过压缩-感知-扩展来改善RAG应用延迟的高效框架:REFRAG,速度快、质量高
不掉精度的情况下,实现了最高30.85×的 TTFT 加速,将 LLM 的有效上下文长度扩展了 16×
大家好,我是猫头虎,周末发现了一个不错的项目:REFRAG。它用“压缩 → 感知/选择 → 扩展”的思路,显著降低 RAG 的推理延迟,并在不牺牲质量的前提下,把有效上下文放大 16 倍。下面是完整的技术解析与上手指南。
fork 版开源仓库(GitHub):https://github.com/MaoTouHU/refRAG

文章目录
- 猫头虎AI开源项目分享:**通过压缩-感知-扩展来改善RAG应用延迟的高效框架:REFRAG,速度快、质量高**
- 摘要(一图速览)
- 背景:为什么传统 RAG 又慢又贵?
- REFRAG 是如何做到快又稳的?
- 项目亮点(Features)
- 安装与加速矩阵
- 快速上手(脚本)
- 手动用法(CLI)
- 指标口径(怎么理解 TTFT / TTIT / 吞吐量)
- Demo 语料与可复现基线
- 故障排查(Troubleshooting)
- 最佳实践与落地建议
- 相关问题( FAQ)
摘要(一图速览)
传统 RAG 把检索到的所有文档直接塞进大模型,导致上下文很长、TTFT 高、吞吐低。
REFRAG 先把长文本压缩成向量并投影到解码器词向量空间,再用策略网络只把最有用的片段还原为 token,最后解码并统计 TTFT / TTIT / 吞吐量。
项目在不降质的情况下,实现最高 30.85× 的 TTFT 加速,16× 的有效上下文扩展。
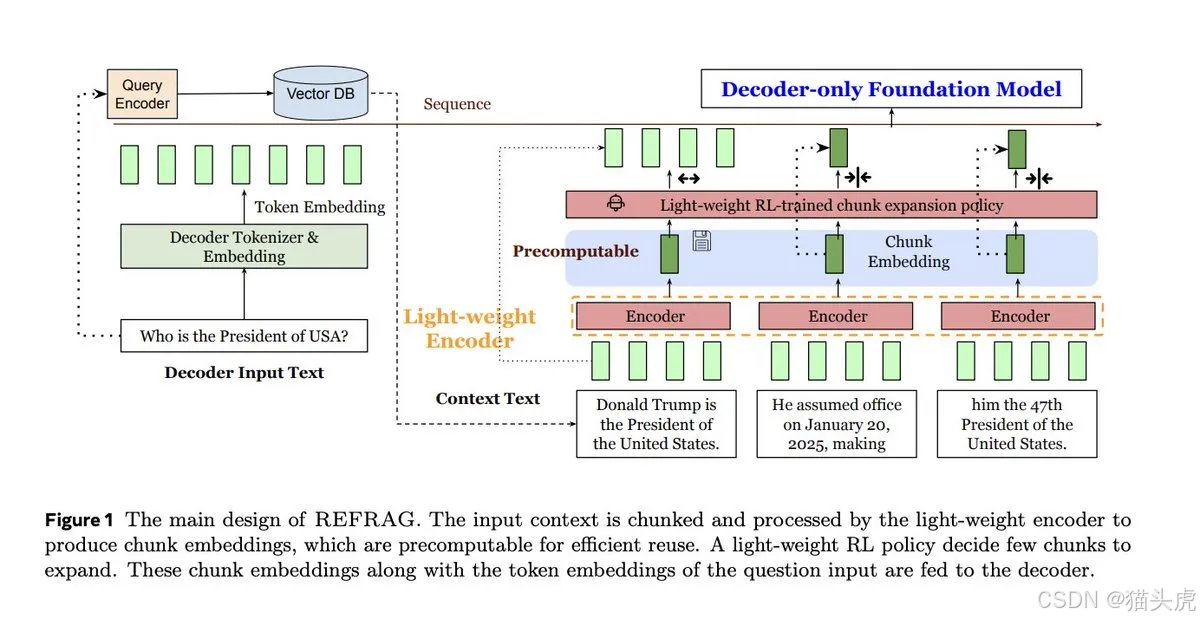
背景:为什么传统 RAG 又慢又贵?
- 全量拼接:检索的 N 条文档直接拼到 Prompt,动辄上万 token。
- 注意力开销大:上下文越长,首 token 延迟(TTFT)越高。
- 吞吐下降:显存与 KV Cache 压力增大,tokens/s 变低。
- 质量未必更好:冗余内容稀释了模型对关键信息的关注。
REFRAG 是如何做到快又稳的?
核心流程:压缩(compress)→ 感知/选择(sense/select)→ 扩展(expand)
- 压缩:把长上下文分块,用编码器生成块级 embedding(如 CLS 池化)。
- 投影:把块向量投影到解码器的 token 嵌入空间,与语言空间对齐。
- 选择性扩展:通过策略网络(REINFORCE)或PPL 启发式,只把最有信息量的块还原为 token,其余保持向量级。
- 解码与度量:常规解码,同时记录 TTFT / TTIT / 吞吐量。
论文脉络参考:Rethinking RAG based Decoding (REFRAG)(实现覆盖论文的“compress → sense/select → expand”架构要点,链接见仓库 README)。
项目亮点(Features)
- 🔎 检索:内置 FAISS 索引构建与搜索
- 🧱 块级编码器 + token 空间投影器(简化集成)
- 🎯 选择性扩展:轻量 策略网络(REINFORCE) + PPL 启发式兜底
- 📚 持续预训练(CPT):重构 → 下一段预测 两阶段
- 🧪 生成指标:TTFT、TTIT、Throughput 一站式统计
- 🧰 单文件 CLI 与自动加速脚本(CUDA/ROCm/MPS/CPU)
安装与加速矩阵
| OS / HW | PyTorch | FAISS | 备注 |
|---|---|---|---|
| Linux + NVIDIA CUDA | pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 | 优先 faiss-gpu,退回 faiss-cpu | CUDA 12.1 |
| Linux + AMD ROCm | pip install --index-url https://download.pytorch.org/whl/rocm6.0 torch torchvision torchaudio | faiss-cpu | ROCm 6.x,GPU FAISS 需源码编译 |
| macOS(Apple Silicon/Intel) | pip install torch torchvision torchaudio | faiss-cpu | 支持 MPS;设 PYTORCH_ENABLE_MPS_FALLBACK=1 |
| Windows(NVIDIA/CPU) | CUDA 同上;CPU: --index-url https://download.pytorch.org/whl/cpu | faiss-cpu | 官方无 faiss-gpu(pip) |
脚本会自动检测加速器,并设置设备优先级 CUDA → MPS → CPU(ROCm 在 PyTorch 中亦走
torch.cuda.is_available())。
快速上手(脚本)
请将
refrag.py放在仓库根目录(与脚本同级)。
Linux/macOS(自动 CUDA/ROCm/MPS/CPU)
chmod +x refrag_quickstart_auto_accel.sh
./refrag_quickstart_auto_accel.sh
Windows(自动 CUDA/CPU)
refrag_quickstart_auto_accel.bat
可选环境变量:ENC_MODEL, DEC_MODEL, EMBED_MODEL, TOPK, K, P, CTX_MAX, MAX_NEW, STEPS, LR_RECON, LR_NEXT, LR_POLICY。
手动用法(CLI)
0)创建虚拟环境并安装依赖
pip install "transformers==4.43.3" accelerate sentencepiece sacrebleu numpy faiss-cpu
# (Linux+CUDA 用户可尝试:pip install faiss-gpu)
1)构建 FAISS 索引
python refrag.py index --corpus data/wiki_lines.txt \ # one passage per line--index_dir runs/index --embed_model BAAI/bge-small-en-v1.5
2)生成(带压缩/扩展的 RAG)
python refrag.py generate --index_dir runs/index --embed_model BAAI/bge-small-en-v1.5 --enc roberta-base --dec meta-llama/Llama-3.2-3B --question "Who discovered penicillin?" --topk 4 --k 32 --p 0.25 --ctx_max 1024 --max_new 128 --temperature 0.0
# 加 --heuristic 可跳过 RL 策略,直接使用 PPL 启发式选择。
3)持续预训练(CPT)
- Phase A — 重构(冻结解码器)
python refrag.py cpt_recon --train_json data/cpt_train.jsonl --enc roberta-base --dec meta-llama/Llama-3.2-3B --k 64 --steps 300 --lr 2e-5 --log_every 20 --out_dir runs/cpt_recon
- Phase B — 下一段预测(全量解冻)
python refrag.py cpt_next --train_json data/cpt_train.jsonl --enc roberta-base --dec meta-llama/Llama-3.2-3B --k 64 --steps 300 --lr 2e-5 --expand_frac 0.25 --log_every 20 --load_dir runs/cpt_recon --out_dir runs/cpt_next
4)训练选择性扩展策略(REINFORCE)
python refrag.py train_policy --rag_json data/rag_train.jsonl --index_dir runs/index --embed_model BAAI/bge-small-en-v1.5 --enc roberta-base --dec meta-llama/Llama-3.2-3B --k 32 --steps 300 --lr 1e-4 --p 0.25 --topk 4 --log_every 20 --out_dir runs/policy
5)载入已训练权重进行生成
python refrag.py generate --index_dir runs/index --embed_model BAAI/bge-small-en-v1.5 --enc roberta-base --dec meta-llama/Llama-3.2-3B --load_dir runs/cpt_next \ # or runs/policy--question "Explain how penicillin was discovered and by whom." --topk 4 --k 32 --p 0.25 --max_new 192
指标口径(怎么理解 TTFT / TTIT / 吞吐量)
- TTFT(Time To First Token):发起推理到第一个 token 的时间。
- TTIT(Time To Informative Token):到第一个包含有效信息 的 token 的时间,更贴近用户体感。
- 吞吐量(Throughput, tok/s):单位时间生成的 token 数,衡量整体效率。
在不降质前提下,REFRAG 在测试中实现最高 30.85× TTFT 加速与16× 有效上下文扩展。实际表现取决于模型规模、硬件与参数(
k/topk/p/ctx_max等)。
Demo 语料与可复现基线
项目自带 refrag/data/,包含:
corpus_small.txt(500 条)、corpus_medium.txt(2,000 条)、corpus_large.txt(3,000 条)rag_train.jsonl(1,200 组合成 QA,对齐语料)cpt_train.jsonl(400 条长文本用于 CPT)README_DATA.md、make_corpus.py
快速演示
# 构建索引(large)
python refrag.py index --corpus data/corpus_large.txt --index_dir runs/index_large --embed_model BAAI/bge-small-en-v1.5# 训练策略
python refrag.py train_policy --rag_json data/rag_train.jsonl --index_dir runs/index_large --topk 8 --k 64 --p 0.25# 生成
python refrag.py generate --index_dir runs/index_large --question "Which river flows through City_101?" --topk 8 --k 64 --p 0.25
实践提示
- 语料覆盖城市/合金/传记/事件并含多语,增大分词与检索复杂度;
- QA 真值可确定,便于自动评测检索与答案正确率;
- CI/冒烟用
small,性能对比用medium/large;需要 10k+ 规模可在 Issue 中提需求。
故障排查(Troubleshooting)
- Hub 模型受限:
huggingface-cli login并在 Hub 接受许可; - CUDA OOM:换小一点的解码器或下调
--ctx_max / --k / --max_new,或减小--p; - MPS 特性:设
PYTORCH_ENABLE_MPS_FALLBACK=1,个别算子会 CPU 回退; - ROCm:确认运行时安装(
rocminfo可用),FAISS GPU 需源码编译,否则用faiss-cpu。
最佳实践与落地建议
- 在线问答/客服搜索:TTFT/TTIT 直接影响“秒开”体验;
- 长文阅读/报告生成:仅扩展关键片段,既快又稳;
- 算力受限场景:在相同显存/延迟预算下容纳更多上下文,相当于等效扩容。
参数起步参考
topk=4~8,k=32~64,p=0.25,temperature=0.0起步保证可复现;- 先用
--heuristic验证收益,再训练策略网络; - 对超长文档,建议先分块+去噪,利于策略收敛与稳定。
相关问题( FAQ)
Q1:REFRAG 是什么?有什么作用?
A:一种针对 RAG 的压缩-选择-扩展解码架构,在不降质的前提下降低 TTFT/TTIT,提升吞吐,并把有效上下文扩展到 16×。
Q2:如何降低 RAG 的 TTFT?
A:减少首轮需要处理的 token。REFRAG 通过先向量化、后选择性扩展,避免把所有检索结果都展开为 token。
Q3:TTFT 与 TTIT 有什么区别?
A:TTFT 是第一个 token 的时间,TTIT 是第一个包含关键信息的 token 的时间,后者更贴近用户体感。
Q4:REFRAG 与“把文档全塞进上下文”的做法相比,质量会下降吗?
A:在该项目的实验设置下没有下降;策略网络/启发式会 优先扩展关键信息,并保留必要上下文。
Q5:REFRAG 需要哪些依赖?支持哪些加速?
A:依赖 PyTorch、Transformers、FAISS 等;自动检测 CUDA/ROCm/MPS/CPU,按平台安装轮子即可(见上文表格)。
Q6:如何把 REFRAG 集成进现有 RAG?
A:把检索后的匹配块先编码+投影,用策略网络/启发式挑选需要扩展为 token 的片段,再接入原有解码器与评测逻辑。
Q7:哪些参数最影响效果?
A:topk/k/p/ctx_max 与策略网络训练步数。可先固定 topk=4~8, k=32~64, p=0.25 做消融,再细调。
Q8:REFRAG 适配哪些模型?
A:示例默认 roberta-base(编码)+ Llama-3.2-3B(解码);也可替换其他 Encoder/Decoder,只要维度与投影器适配。
Q9:如何评估是否“既快又准”?
A:统一统计 TTFT、TTIT、吞吐量,并用合成 QA 真值或业务指标(EM/F1/偏好打分)验证质量。
再次附上仓库地址:
👉 https://github.com/MaoTouHU/refRAG