【RAG-LLM】InfoGain-RAG基于文档信息增益的RAG
note
- 【RAG进展】InfoGain-RAG基于文档信息增益的RAG,还是量化文档重要性的思路【这个思路不错,相似度高的,不一定对生成结果有用,那就找出这个信息量,然后做成一个分类模型,用来辅助排序】。
文章目录
- note
- 一、InfoGain-RAG
一、InfoGain-RAG
【RAG进展】InfoGain-RAG基于文档信息增益的RAG,还是量化文档重要性的思路【这个思路不错,相似度高的,不一定对生成结果有用,那就找出这个信息量,然后做成一个分类模型,用来辅助排序】。
InfoGain-RAG: Boosting Retrieval-Augmented Generation via Document Information Gain-based Reranking and Filtering,https://arxiv.org/pdf/2509.12765,Document Information Gain(DIG)。
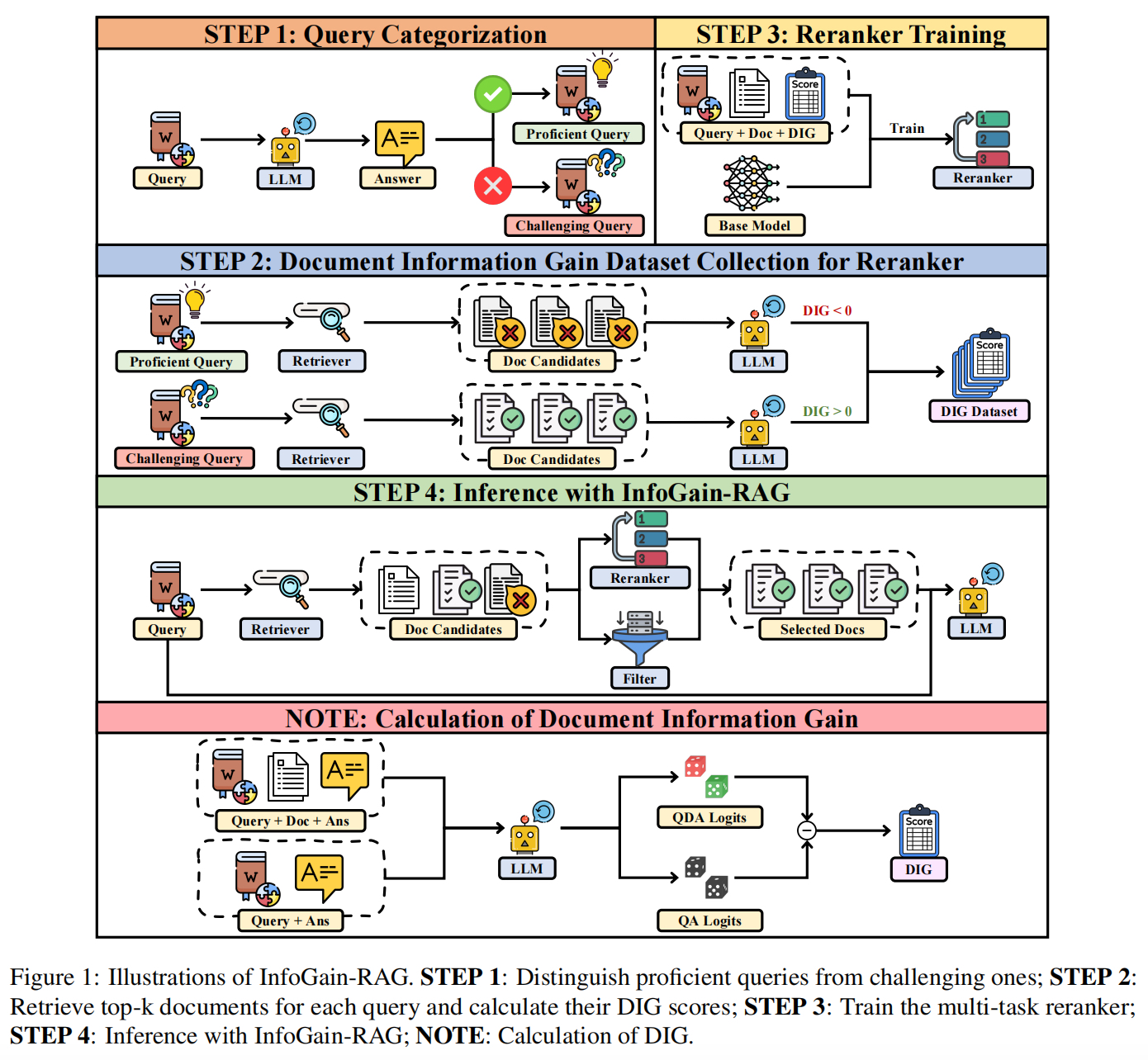
看4个技术点:
1)量化指标。量化检索文档对正确答案生成的贡献,通过计算“有无该文档时LLM生成置信度的差值”(结合查询x与文档di时,LLM生成正确答案y的置信度,减去仅基于查询x时,LLM生成正确答案y的置信度),然后,传统置信度计算的“长度偏差”与“token重要性不均”问题,采用两步优化,一个是滑动窗口平滑,然后将LLMlogits归一化后的token概率作为置信度,缓解长序列因单个低概率token导致的置信度偏低问题,然后,对token进行重要性加权,对答案前k个核心token赋予更高权重;
2)执行过程。“DIG量化+多任务重排序”,step1-查询分类【区分“模型熟练查询”与“模型挑战查询”,定向采集数据】->step2-DIG数据集构建【计算每个<查询-文档>对的DIG值,标注文档类型】->step3-多任务重排序器训练,使用RoBERTa-large【通过交叉熵(CE)损失与Margin损失联合优化,通过超参数β平衡两类损失,包括“文档相关性分类损失”【通过二分类区分“高价值文档”与“有害/无价值文档损失”】与“文档排序优化”【借鉴CircleLoss,通过LogSumExp近似极值,确保高价值文档得分高于有害文档】;->step4-推理【检索后先经重排序器过滤(保留DIG>阈值的文档),再传入LLM生成答案】。
3)DIG数据集构建。使用Qwen2.5-7B计算每个<查询-文档>对的DIG值,标注文档类型,文档类型分成三类,高价值文档【DIG>0,提升LLM生成置信度,重排时优先保留】+无价值文档【DIG≈0,无贡献(内容无关或LLM已掌握知识),过滤】+有害文档【DIG<0,降低置信度(含误导/矛盾信息),强制过滤】,共110K,计算了110K查询对应的1.42M个<查询-文档>对的DIG值
4)分类数据构建。分成2类,“模型熟练查询”【LLM可独立正确回答,用于识别有害文档,DIG<阈值b2,设置为-0.05】与“模型挑战查询”【LLM置信度低,用于识别高价值文档,DIG>阈值b1,0.5】,最终采样68K平衡样本。