(华为杯)数学建模比赛编程助手
界面
效果演示(以2023年C题为例)
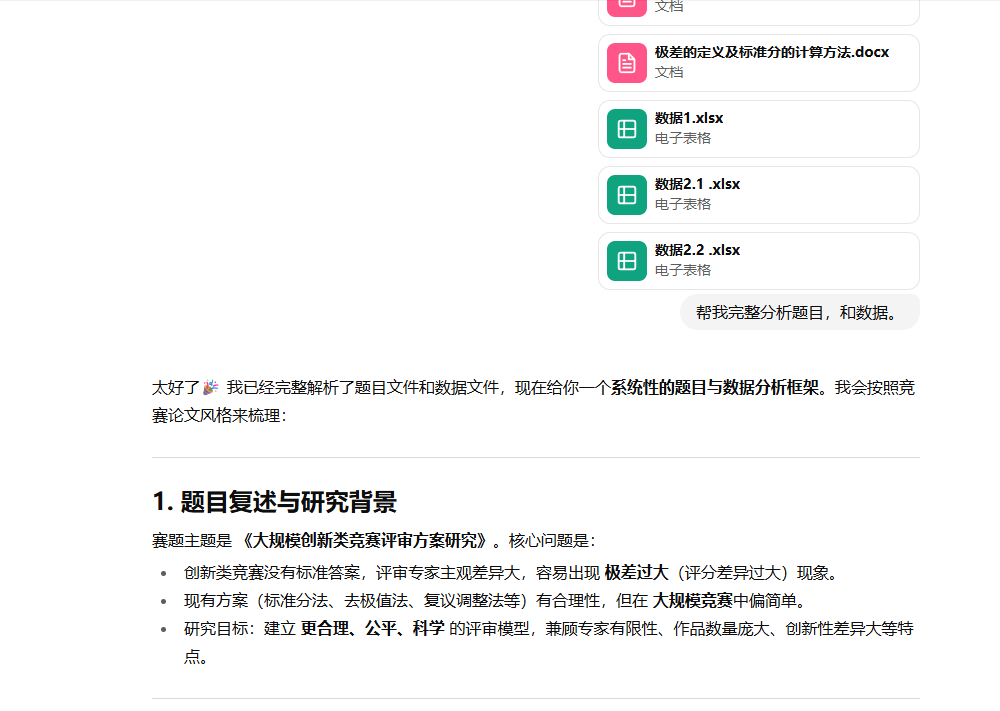
第一步:文件上传
帮我完整分析题目,和数据。
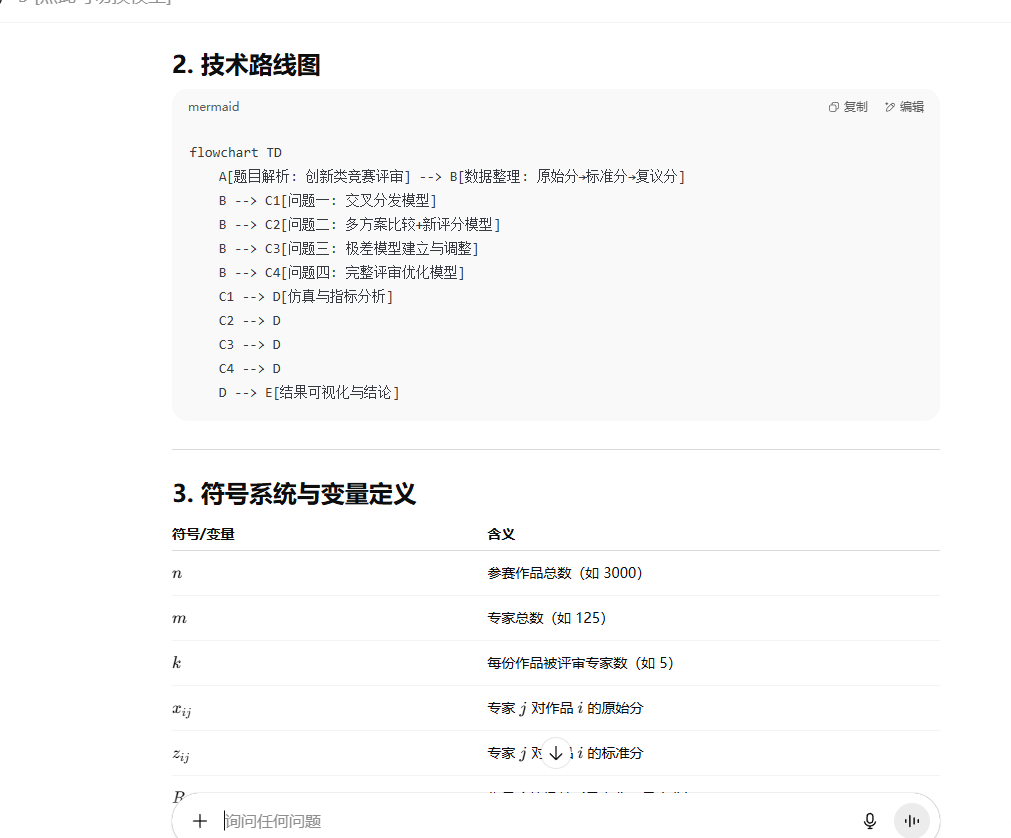

第二步:问出每一问的思路和模型
请认真审题和数据,帮我总体理解题目数据,给出每一个问题的详细思路和数学模型。









第三步:确认好模型之后,生成代码







进一步提问,代码补充与输出。
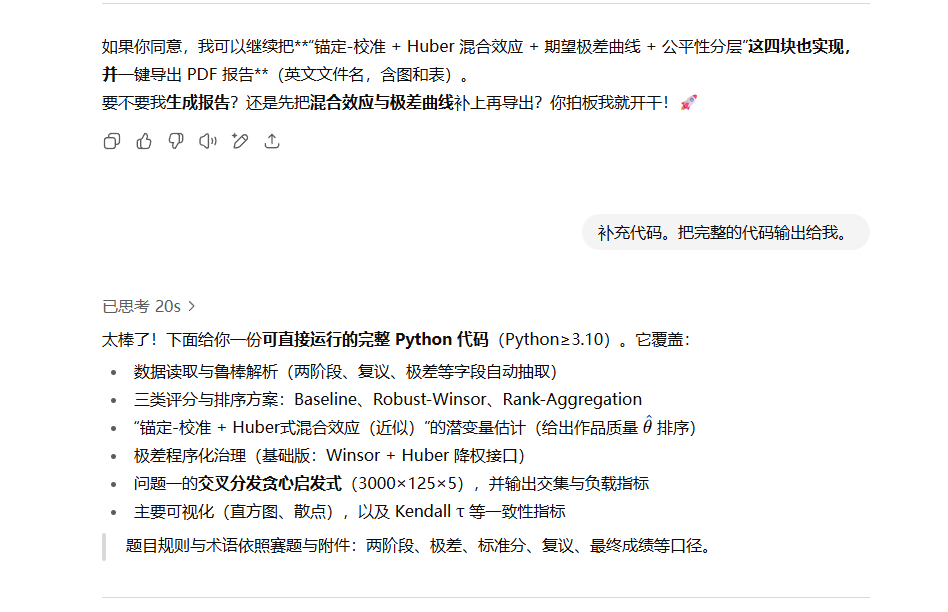
balabala输出了下面一堆代码(肯定有bug,可以把代码分散在jupyter上面,一步步调试)
# -*- coding: utf-8 -*-
"""
Competition Evaluation Modeling (Huawei Cup Graduate MM)
End-to-end: data parsing -> scoring models -> discrepancy handling -> assignment -> metrics & plotsAuthor: Your Team
Python >= 3.10
"""import re
import math
import json
import random
import numpy as np
import pandas as pd
from typing import List, Dict, Tuple, Optional
from collections import defaultdict, Counter# SciPy for Kendall tau and robust stats
from scipy.stats import kendalltau, rankdata, norm
from scipy.stats.mstats import winsorize# Matplotlib (rules: matplotlib only, one chart per figure, no color spec)
import matplotlib.pyplot as plt# -------------------------
# File paths (modify if needed)
# -------------------------
FILE_DATA1 = "/mnt/data/数据1.xlsx"
FILE_DATA21 = "/mnt/data/数据2.1 .xlsx"
FILE_DATA22 = "/mnt/data/数据2.2 .xlsx"# -------------------------
# Utility
# -------------------------def try_read_excel(path: str) -> pd.DataFrame:"""Try reading Excel with robust header handling.Many sheets have top 1-2 rows with commentary headers. We try multiple header rows."""for hdr in [1, 0, 2]:try:df = pd.read_excel(path, sheet_name="Sheet1", header=hdr)# Drop all-empty columnsdf = df.loc[:, ~df.columns.astype(str).str.startswith("Unnamed")]return dfexcept Exception:continue# Fallbackreturn pd.read_excel(path, sheet_name="Sheet1")def safe_float(x):try:if pd.isna(x): return np.nanreturn float(x)except Exception:return np.nandef nanmean(lst):arr = np.array(lst, dtype=float)return np.nanmean(arr)def nanstd(lst):arr = np.array(lst, dtype=float)return np.nanstd(arr, ddof=1)def robust_mad(arr: np.ndarray) -> float:"""Median Absolute Deviation scaled to std (approx)."""med = np.nanmedian(arr)mad = np.nanmedian(np.abs(arr - med))return 1.4826 * maddef norm_rank_transform(ranks, n):"""Blom transform: Phi^{-1}((r-0.375)/(n+0.25))."""return norm.ppf((ranks - 0.375) / (n + 0.25))# -------------------------
# Parsing to long format
# -------------------------def parse_phase_blocks(df_raw: pd.DataFrame,fallback_k1: int = 5,fallback_k2: int = 3,id_col_name: str = "作品ID") -> pd.DataFrame:"""Parse messy wide tables to a long table with columns:[item_id, phase, expert_code, raw, z, z_revised]Heuristics:- We expect repeated groups per expert like: ["专家编码","原始分","标准分", optional "复议分"].- Phase1 should have around k1 experts (default 5), Phase2 around k2 (default 3).- If item ID is absent, use row index as item_id.Returns a long-format DataFrame."""df = df_raw.copy()# Try to find an item identifier column, else generate onepotential_id_cols = [c for c in df.columns if any(k in str(c) for k in ["作品", "队", "ID", "编号", "队伍"])]if potential_id_cols:idc = potential_id_cols[0]else:idc = id_col_namedf[idc] = np.arange(len(df)) + 1# Try to detect known meta columns# We'll not drop them; they can be merged later for reporting.cols = list(df.columns)# Detect expert group starts by '专家编码'starts = [i for i, c in enumerate(cols) if str(c).strip() == "专家编码"]# Each group ideally is ['专家编码','原始分','标准分'] + optional '复议分'groups = []for s in starts:grp = [s]if s + 1 < len(cols) and str(cols[s+1]).strip() in ["原始分", "原始分数", "原始成绩"]:grp.append(s+1)if s + 2 < len(cols) and "标准分" in str(cols[s+2]):grp.append(s+2)if s + 3 < len(cols) and "复议" in str(cols[s+3]):grp.append(s+3)# valid group if at least expert_code + 标准分if len(grp) >= 3:groups.append(grp)# Split into phase1 and phase2 by expected counts; if ambiguous, use first k1 groups as phase1 and next k2 as phase2if len(groups) >= (fallback_k1 + fallback_k2):phase1_groups = groups[:fallback_k1]phase2_groups = groups[fallback_k1:fallback_k1 + fallback_k2]elif len(groups) >= fallback_k1:phase1_groups = groups[:fallback_k1]phase2_groups = groups[fallback_k1:]elif len(groups) > 0:# Minimal case: treat first half as phase1, rest as phase2half = max(1, len(groups)//2)phase1_groups = groups[:half]phase2_groups = groups[half:]else:# If no structured groups found, try to infer generic expert blocks by keyword# fall back: emptyphase1_groups, phase2_groups = [], []long_records = []def extract_group(row, grp_idx_list, phase_val):# grp_idx_list contains indices in df.columns for this group (length 3 or 4)mapping = {str(cols[i]): row.iloc[i] for i in grp_idx_list}code = mapping.get("专家编码", np.nan)raw = np.nanz = np.nanz_rev = np.nanfor k, v in mapping.items():if "原始分" in k:raw = safe_float(v)if "标准分" in k and "复议" not in k:z = safe_float(v)if "复议" in k:z_rev = safe_float(v)return dict(expert_code=code, raw=raw, z=z, z_revised=z_rev, phase=phase_val)# Iterate rowsfor _, row in df.iterrows():item_id = row[idc] if idc in df.columns else _# Phase 1for grp in phase1_groups:rec = extract_group(row, grp, phase_val=1)rec["item_id"] = item_idlong_records.append(rec)# Phase 2for grp in phase2_groups:rec = extract_group(row, grp, phase_val=2)rec["item_id"] = item_idlong_records.append(rec)long_df = pd.DataFrame(long_records)# Clean expert code to stringlong_df["expert_code"] = long_df["expert_code"].astype(str).str.strip()# Prefer revised z if present (phase 2 uses revised when available)long_df["z_eff"] = np.where(long_df["phase"] == 2,np.where(~long_df["z_revised"].isna(), long_df["z_revised"], long_df["z"]),long_df["z"])# Compute per item-phase range and meanreturn long_df# -------------------------
# Scoring methods
# -------------------------def compute_phase_stats(long_df: pd.DataFrame) -> pd.DataFrame:"""Compute per item-phase mean and range (before & after revision proxy)."""# before revision: use z (not z_revised)df_before = long_df.copy()df_before["z_use"] = df_before["z"]stats_b = df_before.groupby(["item_id", "phase"])["z_use"].agg(["mean", "min", "max", "count"]).reset_index()stats_b["range"] = stats_b["max"] - stats_b["min"]stats_b.rename(columns={"mean": "mean_before", "range": "range_before"}, inplace=True)# after revision (effective): z_effdf_after = long_df.copy()df_after["z_use"] = df_after["z_eff"]stats_a = df_after.groupby(["item_id", "phase"])["z_use"].agg(["mean", "min", "max", "count"]).reset_index()stats_a["range"] = stats_a["max"] - stats_a["min"]stats_a.rename(columns={"mean": "mean_after", "range": "range_after"}, inplace=True)merged = pd.merge(stats_b[["item_id","phase","mean_before","range_before","count"]],stats_a[["item_id","phase","mean_after","range_after"]],on=["item_id","phase"], how="outer")return mergeddef baseline_total_score(long_df: pd.DataFrame) -> pd.DataFrame:"""Baseline per rules:- Phase1: average of standard scores (z)- Phase2: sum of standard scores (prefer revised when available)- Total: P1_mean + P2_sum"""p1 = long_df[long_df["phase"]==1].groupby("item_id")["z"].mean().rename("p1_mean").reset_index()p2 = long_df[long_df["phase"]==2].groupby("item_id")["z_eff"].sum().rename("p2_sum").reset_index()all_items = pd.DataFrame({"item_id": long_df["item_id"].unique()})res = all_items.merge(p1, on="item_id", how="left").merge(p2, on="item_id", how="left")res["p1_mean"] = res["p1_mean"].fillna(0.0)res["p2_sum"] = res["p2_sum"].fillna(0.0)res["total_baseline"] = res["p1_mean"] + res["p2_sum"]return resdef winsor_total_score(long_df: pd.DataFrame, limits=(0.1,0.1)) -> pd.DataFrame:"""Robust winsorized mean for P1, sum for P2 (with revised preferred)."""def wmean(x):arr = np.array(x, dtype=float)if len(arr) == 0: return np.nanarr = winsorize(arr, limits=limits)return np.mean(arr)p1 = long_df[long_df["phase"]==1].groupby("item_id")["z"].apply(wmean).rename("p1_wmean").reset_index()p2 = long_df[long_df["phase"]==2].groupby("item_id")["z_eff"].sum().rename("p2_sum").reset_index()all_items = pd.DataFrame({"item_id": long_df["item_id"].unique()})res = all_items.merge(p1, on="item_id", how="left").merge(p2, on="item_id", how="left")res["p1_wmean"] = res["p1_wmean"].fillna(0.0)res["p2_sum"] = res["p2_sum"].fillna(0.0)res["total_winsor"] = res["p1_wmean"] + res["p2_sum"]return resdef rank_aggregation_total_score(long_df: pd.DataFrame) -> pd.DataFrame:"""Rank->Normal per expert within phase, then aggregate:- Phase1: mean of transformed scores- Phase2: sum of transformed scores (revised preferred)"""df = long_df.copy()# Choose z sourcedf["z_use"] = np.where(df["phase"]==2,np.where(~df["z_revised"].isna(), df["z_revised"], df["z"]),df["z"])# rank within (expert, phase)def transform(group):vals = group["z_use"].values# Higher z -> higher rank; use rankdata with 'average' methodr = rankdata(vals, method="average")t = norm_rank_transform(r, len(vals))group["z_rn"] = treturn groupdf = df.groupby(["expert_code","phase"], group_keys=False).apply(transform)p1 = df[df["phase"]==1].groupby("item_id")["z_rn"].mean().rename("p1_rn_mean").reset_index()p2 = df[df["phase"]==2].groupby("item_id")["z_rn"].sum().rename("p2_rn_sum").reset_index()all_items = pd.DataFrame({"item_id": df["item_id"].unique()})res = all_items.merge(p1, on="item_id", how="left").merge(p2, on="item_id", how="left")res["p1_rn_mean"] = res["p1_rn_mean"].fillna(0.0)res["p2_rn_sum"] = res["p2_rn_sum"].fillna(0.0)res["total_rankagg"] = res["p1_rn_mean"] + res["p2_rn_sum"]return res# -------------------------
# Anchor-Calibration + Huber-like Mixed Effects (lightweight)
# -------------------------def huber_weight(resid: np.ndarray, c: float = 1.345) -> np.ndarray:"""Huber weights for residuals."""s = np.nanstd(resid) if np.nanstd(resid) > 1e-8 else 1.0r = resid / sw = np.where(np.abs(r) <= c, 1.0, c / np.abs(r))return wdef estimate_theta_beta_huber(long_df: pd.DataFrame,max_iter: int = 20,eps: float = 1e-4,phase_weight: Dict[int, float] = None) -> Tuple[pd.DataFrame, pd.DataFrame]:"""Simple alternating updates for:x_ijs = mu + theta_i + beta_j + gamma_s + noiseUsing Huber weights and optional phase weights (e.g., phase 2 > phase 1).Inputs use z_eff (revised preferred for phase 2).Returns theta (items) and beta (experts)."""df = long_df.copy()df["y"] = np.where(df["phase"]==2,np.where(~df["z_revised"].isna(), df["z_revised"], df["z"]),df["z"])# Initializeitems = df["item_id"].unique()experts = df["expert_code"].unique()phases = sorted(df["phase"].unique())theta = pd.Series(0.0, index=items) # item qualitybeta = pd.Series(0.0, index=experts) # expert severitygamma = {s: 0.0 for s in phases} # phase effectmu = float(np.nanmean(df["y"]))if phase_weight is None:phase_weight = {1:1.0, 2:1.4} # phase2 more authoritative (tunable)for it in range(max_iter):# Compute residualsr = []w_list = []idxs = []for idx, row in df.iterrows():i = row["item_id"]j = row["expert_code"]s = row["phase"]y = row["y"]pred = mu + theta.get(i,0.0) + beta.get(j,0.0) + gamma.get(int(s),0.0)resid = y - predr.append(resid)idxs.append((i,j,s,idx))r = np.array(r)w_huber = huber_weight(r, c=1.345)# phase weightsw_phase = np.array([phase_weight.get(int(s),1.0) for (_,_,s,_) in idxs])w = w_huber * w_phase# Update mumu_old = mumu = np.nansum(w * (df["y"].values - np.array([theta[i]+beta[j]+gamma[int(s)] for (i,j,s,_) in idxs]))) / (np.nansum(w) + 1e-8)# Update theta (items)for i in items:mask = [1 if ii==i else 0 for (ii,_,_,_) in idxs]if sum(mask)==0: continuey_i = df["y"].values[np.array(mask)==1]w_i = w[np.array(mask)==1]res_i = y_i - (mu + np.array([beta[j]+gamma[int(s)] for (_,j,s,_) in np.array(idxs)[np.array(mask)==1]]))theta[i] = np.nansum(w_i * res_i) / (np.nansum(w_i) + 1e-8)# Update beta (experts)for j in experts:mask = [1 if jj==j else 0 for (_,jj,_,_) in idxs]if sum(mask)==0: continuey_j = df["y"].values[np.array(mask)==1]w_j = w[np.array(mask)==1]res_j = y_j - (mu + np.array([theta[i]+gamma[int(s)] for (i,_,s,_) in np.array(idxs)[np.array(mask)==1]]))beta[j] = np.nansum(w_j * res_j) / (np.nansum(w_j) + 1e-8)# Update gamma (phase)for s in phases:mask = [1 if ss==s else 0 for (_,_,ss,_) in idxs]if sum(mask)==0: continuey_s = df["y"].values[np.array(mask)==1]w_s = w[np.array(mask)==1]res_s = y_s - (mu + np.array([theta[i]+beta[j] for (i,j,_,_) in np.array(idxs)[np.array(mask)==1]]))gamma[s] = np.nansum(w_s * res_s) / (np.nansum(w_s) + 1e-8)# Convergence checkif abs(mu - mu_old) < eps:breaktheta_df = pd.DataFrame({"item_id": theta.index, "theta_hat": theta.values})beta_df = pd.DataFrame({"expert_code": beta.index, "beta_hat": beta.values})return theta_df, beta_df# -------------------------
# Discrepancy (Range) programmatic handling (basic)
# -------------------------def range_based_adjustment(long_df: pd.DataFrame,center_quantiles=(0.4, 0.7),range_z_thresh=1.0,iqr_kappa=1.5) -> pd.DataFrame:"""Programmatic handling for mid-band large ranges:- Identify items with phase==1 and mean z in [q40,q70], and high range z-score.- Apply per-item Winsorization + Huber-weighted center to smooth outliers.- Only adjust phase 1; phase 2 already uses revised scores if any.Returns a copy with column 'z_prog' (programmatically adjusted z)."""df = long_df.copy()# base z to adjust (phase1 only)df["z_prog"] = df["z"].copy()# compute per-item statsstats = df[df["phase"]==1].groupby("item_id")["z"].agg(["mean","min","max","count"])stats["range"] = stats["max"] - stats["min"]q_low, q_high = stats["mean"].quantile(center_quantiles[0]), stats["mean"].quantile(center_quantiles[1])# expected range ~ function of mean: simple binningbins = np.quantile(stats["mean"].dropna(), np.linspace(0,1,11))stats["bin"] = pd.cut(stats["mean"], bins=bins, include_lowest=True, duplicates='drop')exp_range = stats.groupby("bin")["range"].mean()sd_range = stats.groupby("bin")["range"].std()def is_midband_highrange(r):m = r["mean"]rg = r["range"]b = r["bin"]if pd.isna(b): return Falseif m < q_low or m > q_high: return Falsemu_r = exp_range.loc[b]sd_r = sd_range.loc[b] if not np.isnan(sd_range.loc[b]) else 1.0zscore = (rg - mu_r) / (sd_r + 1e-8)return zscore >= range_z_threshcandidates = stats[stats.apply(is_midband_highrange, axis=1)].index.tolist()# Apply per-item Winsor + Huber re-centeringfor iid in candidates:idx = (df["item_id"]==iid) & (df["phase"]==1)arr = df.loc[idx, "z"].values.astype(float)if len(arr) >= 3:# Winsorize by IQRq1, q3 = np.nanpercentile(arr, [25, 75])iqr = q3 - q1low, high = q1 - iqr_kappa*iqr, q3 + iqr_kappa*iqrarr_w = np.clip(arr, low, high)# Huber centerr = arr_w - np.nanmean(arr_w)w = huber_weight(r, c=1.345)cen = np.nansum(w * arr_w) / (np.nansum(w) + 1e-8)# shift towards center (soft adjustment)alpha = 0.5 # partial shrinkagearr_adj = alpha*cen + (1-alpha)*arr_wdf.loc[idx, "z_prog"] = arr_adjreturn df# -------------------------
# Problem 1: Greedy Cross-Assignment (n=3000, m=125, k=5)
# -------------------------def greedy_assignment(n: int = 3000, m: int = 125, k: int = 5, seed: int = 42) -> Dict:"""Greedy heuristic:- Maintain target pair overlap lambda ~ n*C(k,2)/C(m,2)- Assign each item to k experts minimizing (pair overlap variance + load variance).Returns assignment dict and summary stats."""random.seed(seed)np.random.seed(seed)# Target lambdatotal_pairs = n * (k*(k-1)//2)m_pairs = (m*(m-1))//2lam = total_pairs / m_pairs# Stateloads = np.zeros(m, dtype=int)pair_overlaps = defaultdict(int) # (p,q) -> countassign = [[] for _ in range(n)]experts_idx = list(range(m))def score_choice(choice: List[int]) -> float:# compute variance penalty of resulting pair overlaps + load vartmp_pairs = Counter()for a in choice:for b in choice:if a < b:tmp_pairs[(a,b)] += 1# simulatevar_pairs = []for (p,q), inc in tmp_pairs.items():new = pair_overlaps[(p,q)] + incvar_pairs.append((new - lam)**2)var_pairs = np.mean(var_pairs) if var_pairs else 0.0# load varnew_loads = loads.copy()for a in choice:new_loads[a] += 1var_load = np.var(new_loads)return var_pairs + 0.01 * var_loadfor i in range(n):# Candidate subset by load sorting to balance capacitysorted_experts = sorted(experts_idx, key=lambda e: loads[e])# sample a pool from lowest loads to keep balancepool = sorted_experts[:min(m, 40)]# pick k experts minimizing the score; try several random subsetsbest = Nonebest_sc = float("inf")tries = 200for _ in range(tries):cand = sorted(np.random.choice(pool, size=k, replace=False).tolist())sc = score_choice(cand)if sc < best_sc:best_sc = scbest = cand# commitassign[i] = bestfor a in best:loads[a] += 1for u in range(k):for v in range(u+1, k):p, q = best[u], best[v]if p > q: p, q = q, ppair_overlaps[(p,q)] += 1# statspair_vals = np.array(list(pair_overlaps.values()))stats = {"n": n, "m": m, "k": k, "lambda_target": lam,"pair_overlap_mean": float(np.mean(pair_vals)) if len(pair_vals)>0 else 0.0,"pair_overlap_var": float(np.var(pair_vals)) if len(pair_vals)>0 else 0.0,"pair_overlap_min": int(np.min(pair_vals)) if len(pair_vals)>0 else 0,"pair_overlap_max": int(np.max(pair_vals)) if len(pair_vals)>0 else 0,"load_mean": float(np.mean(loads)),"load_var": float(np.var(loads)),"load_min": int(np.min(loads)),"load_max": int(np.max(loads)),}return {"assign": assign, "loads": loads, "pair_overlaps": pair_overlaps, "stats": stats}# -------------------------
# Plots
# -------------------------def plot_hist(data: np.ndarray, title: str, xlabel: str):plt.figure()plt.hist(data[~np.isnan(data)], bins=30)plt.title(title)plt.xlabel(xlabel)plt.ylabel("Count")plt.tight_layout()plt.show()def plot_scatter(x: np.ndarray, y: np.ndarray, title: str, xlabel: str, ylabel: str):plt.figure()plt.scatter(x, y, s=14)plt.title(title)plt.xlabel(xlabel)plt.ylabel(ylabel)plt.tight_layout()plt.show()# -------------------------
# Main pipeline
# -------------------------def main():# 0) Read rawdf1_raw = try_read_excel(FILE_DATA1)df21_raw = try_read_excel(FILE_DATA21)df22_raw = try_read_excel(FILE_DATA22)# 1) Parse long# Heuristic: Phase1 k=5, Phase2 k=3 per题面long1 = parse_phase_blocks(df1_raw, fallback_k1=5, fallback_k2=3)long21 = parse_phase_blocks(df21_raw, fallback_k1=5, fallback_k2=3)long22 = parse_phase_blocks(df22_raw, fallback_k1=5, fallback_k2=3)# 2) Phase statsstats22 = compute_phase_stats(long22)# Exportstats22.to_csv("phase_stats_data22.csv", index=False)# Print key stats (Phase 2 before/after)p2 = stats22[stats22["phase"]==2].copy()mean_before = np.nanmean(p2["range_before"].values)median_before = np.nanmedian(p2["range_before"].values)p90_before = np.nanpercentile(p2["range_before"].values[~np.isnan(p2["range_before"].values)], 90)mean_after = np.nanmean(p2["range_after"].values)median_after = np.nanmedian(p2["range_after"].values)p90_after = np.nanpercentile(p2["range_after"].values[~np.isnan(p2["range_after"].values)], 90)print("\n=== Phase 2 Range (Data2.2) ===")print(f"Before Revision: mean={mean_before:.2f}, median={median_before:.2f}, P90={p90_before:.2f}")print(f"After Revision: mean={mean_after:.2f}, median={median_after:.2f}, P90={p90_after:.2f}")# 3) Total scores by three methods (on Data2.2)base22 = baseline_total_score(long22)win22 = winsor_total_score(long22, limits=(0.1,0.1))rank22 = rank_aggregation_total_score(long22)# Mergetotal22 = base22.merge(win22[["item_id","total_winsor"]], on="item_id", how="outer") \.merge(rank22[["item_id","total_rankagg"]], on="item_id", how="outer")total22.to_csv("total_scores_data22.csv", index=False)# 4) Pairwise Kendall tau between methodsdf_tau = []for a, b, name in [("total_baseline","total_winsor","baseline_vs_winsor"),("total_baseline","total_rankagg","baseline_vs_rank"),("total_winsor","total_rankagg","winsor_vs_rank"),]:va = total22[a].valuesvb = total22[b].valuestau, p = kendalltau(va, vb, nan_policy="omit")df_tau.append({"pair": name, "kendall_tau": tau, "p_value": p})tau_df = pd.DataFrame(df_tau)print("\n=== Pairwise Kendall Tau (Data2.2) ===")print(tau_df)tau_df.to_csv("method_kendall_tau_data22.csv", index=False)# 5) Programmatic range adjustment for Phase1 (Data2.2)long22_prog = range_based_adjustment(long22, center_quantiles=(0.4,0.7), range_z_thresh=1.0, iqr_kappa=1.5)# Recompute phase1 mean after programmatic adjustmentp1_prog = long22_prog[long22_prog["phase"]==1].groupby("item_id")["z_prog"].mean().rename("p1_prog_mean").reset_index()total22_prog = total22.merge(p1_prog, on="item_id", how="left")total22_prog["total_prog"] = total22_prog["p1_prog_mean"].fillna(0.0) + total22_prog["total_baseline"].fillna(0.0) - total22_prog["p1_mean"].fillna(0.0)total22_prog.to_csv("total_scores_with_prog_data22.csv", index=False)# 6) Lightweight Huber Mixed-Effects (Data2.2)theta22, beta22 = estimate_theta_beta_huber(long22, max_iter=20, eps=1e-4, phase_weight={1:1.0, 2:1.4})theta22.to_csv("theta_hat_data22.csv", index=False)beta22.to_csv("beta_hat_data22.csv", index=False)# Rank items by theta_hattheta22_sorted = theta22.sort_values("theta_hat", ascending=False).reset_index(drop=True)theta22_sorted.to_csv("theta_ranking_data22.csv", index=False)# 7) Plots (Data2.2 Phase2 range before/after + scatter mean vs range)# Hist beforeplot_hist(p2["range_before"].values.astype(float),title="Phase 2 Range (Before Revision) - Data2.2",xlabel="Range (max - min)")# Hist afterplot_hist(p2["range_after"].values.astype(float),title="Phase 2 Range (After Revision) - Data2.2",xlabel="Range (max - min)")# Scatter mean_before vs range_before (Phase2)m_before = stats22.loc[stats22["phase"]==2, "mean_before"].values.astype(float)r_before = stats22.loc[stats22["phase"]==2, "range_before"].values.astype(float)plot_scatter(m_before, r_before,title="Phase 2 Mean vs Range (Before) - Data2.2",xlabel="Phase 2 Mean (before)",ylabel="Phase 2 Range (before)")# 8) Problem 1: Greedy cross-assignment stats (n=3000, m=125, k=5)assign_res = greedy_assignment(n=3000, m=125, k=5, seed=42)stats = assign_res["stats"]print("\n=== Greedy Assignment Stats (n=3000, m=125, k=5) ===")for k_, v_ in stats.items():print(f"{k_}: {v_}")# Export assignment summaryloads = assign_res["loads"]pair_overlaps = assign_res["pair_overlaps"]pd.DataFrame({"expert_index": np.arange(len(loads)), "load": loads}).to_csv("assignment_loads.csv", index=False)po_df = pd.DataFrame([{"pair": f"{p}-{q}", "overlap": c} for (p,q), c in pair_overlaps.items()])po_df.to_csv("assignment_pair_overlaps.csv", index=False)print("\nPipeline finished.\n")print("Key outputs:")print("- phase_stats_data22.csv")print("- total_scores_data22.csv")print("- method_kendall_tau_data22.csv")print("- total_scores_with_prog_data22.csv")print("- theta_hat_data22.csv / beta_hat_data22.csv / theta_ranking_data22.csv")print("- assignment_loads.csv / assignment_pair_overlaps.csv")if __name__ == "__main__":main()
到此就完成代码输出。当然只能是初步代码,跑通后再继续一点点的去完善细节,可视化吧。
网站
https://share.searchknowledge.cloud
https://share-hk.zhangsan.cool
https://share.zhangsan.cool
https://hello.aiforme.cloud
