FunASR开源项目实战:解锁语音识别新姿势
摘要:FunASR是阿里巴巴达摩院开源的高性能语音识别工具包,具备语音识别、说话人分离、标点恢复等核心功能。项目采用先进的Paraformer非自回归架构,在中文识别任务上表现优异,支持实时与非实时处理模式。通过预训练模型和易用API,可快速搭建智能语音助手、会议转写、视频字幕等应用场景。技术亮点包括:多说话人识别能力、低词错误率、抗噪性能强,并支持模型微调和多语言扩展。未来将深化与NLP、CV技术的融合,持续优化模型性能,拓展医疗、教育等垂直领域应用。该项目已在GitHub获得11.6k星标,为语音识别研究和应用提供了强大支持。
一、引言
在人工智能蓬勃发展的当下,语音识别技术作为人机交互的关键领域,正逐渐融入人们生活与工作的方方面面。从智能语音助手到实时语音转写,从智能客服到语音指令控制,语音识别技术的应用场景日益广泛,其重要性不言而喻。
FunASR 作为阿里巴巴达摩院开源的语音识别工具包,自诞生以来,便在语音识别领域掀起了一阵波澜,在 GitHub 上已经收获了 11.6k 星标。它凭借着丰富的功能、强大的性能以及易用性,为语音识别的研究和应用开辟了新的道路。其不仅支持语音识别(ASR)、语音活动检测(VAD)、标点恢复、说话人验证、说话人分离、多人对话语音识别等多种功能,还提供了预训练模型和易于使用的接口,支持快速部署,满足不同场景的应用需求,在学术界和工业界都备受关注。
今天,就让我们深入探索 FunASR 开源项目在实际中的运用,一同领略它的魅力与潜力。

二、FunASR 项目简介
2.1 核心功能概览
- 语音识别(ASR):作为核心功能,FunASR 能够将输入的语音信号精准地转换为文本。例如在会议记录场景中,可快速将会议中的语音交流转化为文字记录,方便后续查阅与整理 。其支持非实时和实时两种模式,像 Paraformer-zh 模型可进行带时间戳的非实时识别,Paraformer-zh-streaming 模型则专注于实时识别任务,满足不同场景下的语音识别需求。
- 语音活动检测(VAD):该功能可智能识别语音信号里的有效语音部分,将静音或背景噪音过滤掉。在嘈杂的餐厅环境中进行语音交互时,通过 VAD 技术就能准确提取出说话者的语音内容,避免噪音干扰,提高后续处理的准确性和效率 。使用 fsmn - vad 模型可实现实时运行,快速准确地判断语音的起止。
- 标点恢复:在语音识别完成后,ct - punc 模型会自动为识别结果添加标点符号。比如将 “今天天气真好我们出去玩吧” 补充标点为 “今天天气真好,我们出去玩吧!”,极大地提高了文本的可读性和理解性 ,使语音识别结果更符合人们日常阅读和使用习惯。
- 说话人验证:通过分析语音特征,FunASR 可以识别并验证说话人的身份。在安全验证场景中,如金融交易的语音身份验证,能确保交易双方身份的真实性,为重要业务操作提供安全保障 。
- 说话人分离:在多人对话场景中,比如一场小组讨论,该功能可以将不同说话人的声音区分开来,准确分辨出每个人的发言内容,为后续对不同发言者观点的分析和整理提供便利 。
- 多说话人 ASR:能够同时处理多人同时说话的复杂场景,精准识别和区分每个人的语音内容。在热闹的辩论会现场,即使多人同时发言,也能清晰识别出各方观点,不错过任何重要信息 。
2.2 技术优势剖析
- 模型性能卓越:FunASR 采用先进的深度学习模型架构,如 Paraformer 非自回归架构,在中文识别任务上表现尤为突出,词错误率(WER)比部分同类模型更低,识别准确率更高。在嘈杂环境下,通过优化的降噪算法和抗干扰技术,仍能保持较高的识别精度,展现出强大的鲁棒性。在多人对话场景中,对于说话人分离和多说话人语音识别的准确率也较高,能够准确区分不同说话者的语音内容 。
- 易用性高:提供简单易懂的 API 和丰富详细的文档,降低了开发门槛,即使是对语音识别技术了解有限的开发者,也能快速上手并进行二次开发。同时,支持预训练模型的快速调用,用户无需从头开始训练模型,节省大量的时间和计算资源 ,只需简单配置参数即可在自己的项目中应用语音识别功能。
- 可扩展性强:支持多种语言和方言的识别,能够适应不同地区、不同口音的语音输入,满足全球化应用的需求。提供了灵活的模型训练和微调机制,用户可以根据特定的业务场景和数据,对模型进行定制化训练,进一步提升模型在特定领域的性能表现 。无论是智能客服、语音助手还是会议记录等不同应用场景,都能通过微调模型来更好地适应业务需求。
2.3 FunASR开源地址
1、FunASR开源地址:https://github.com/modelscope/FunASR
2、FunASR开源中文文档:https://github.com/modelscope/FunASR/blob/main/README_zh.md
3、FunASR部署文档:https://github.com/modelscope/FunASR/blob/
三、应用场景实战
3.1 智能语音助手搭建
利用 FunASR 构建智能语音助手时,模型选择是关键的第一步。比如在一个智能家居语音助手项目中,由于主要服务于国内家庭用户,处理的是中文语音指令,所以选择了 Paraformer-zh 模型 。这个模型在中文语音识别方面表现出色,能精准识别各种常见的家居控制指令,如 “打开客厅灯光”“调节空调温度” 等。若语音助手有实时交互的需求,像在智能车载语音助手中,用户希望得到即时响应,Paraformer-zh-streaming 模型则是更好的选择,它能够实现语音的实时识别,让用户在驾驶过程中快速与语音助手交互,查询路线、播放音乐等操作都能迅速得到回应 。
在配置调整方面,需要根据硬件资源和实际场景的需求来进行。若运行语音助手的设备内存有限,如一些低配置的智能音箱,就需要适当降低模型的复杂度和参数设置,以保证模型能在设备上稳定运行 。可以通过修改配置文件中的参数,如调整采样率,从默认的 16kHz 降低到 8kHz ,虽然可能会略微影响识别准确率,但能大大减少内存占用。同时,还可以优化批处理大小,根据设备的 CPU 性能,将批处理大小从较大的值调整为较小的值,确保模型推理时不会因为资源不足而出现卡顿或崩溃的情况 。

与其他模块的集成是智能语音助手实现完整功能的重要环节。语音助手不仅要能识别语音,还需要理解语义并做出相应的回应。这就需要将 FunASR 与自然语言处理(NLP)模块进行集成 。在实际项目中,可以选用成熟的 NLP 框架,如 HanLP,将 FunASR 识别出的语音文本输入到 HanLP 中进行语义分析 。当用户说出 “帮我查询明天的天气”,FunASR 将语音转换为文本后,HanLP 对文本进行解析,提取出关键信息 “明天”“天气”,然后通过调用天气查询接口,获取对应的天气信息 。之后,再将处理结果传递给文本转语音(TTS)模块,如百度的 TTS 服务,将查询到的天气信息转换为语音反馈给用户,从而完成整个语音交互过程 。

3.2 会议语音转文字实践
在实际会议场景中使用 FunASR 进行语音转文字,会遇到诸多挑战。处理多人发言是一个难点,不同说话人的语速、语调、口音都存在差异,这可能会影响识别准确率 。在一场跨国公司的线上会议中,参会人员来自不同地区,有带有南方口音的中国同事,也有英语口音较重的外国同事。为了解决这个问题,可以在会前收集不同参会人员的语音样本,利用 FunASR 提供的说话人自适应技术,对模型进行微调 。通过将这些样本数据加入到训练集中,让模型学习不同说话人的语音特征,从而在会议过程中能够更准确地识别每个人的发言 。
口音差异也是常见问题。对于不同地区的方言口音,单纯依靠通用的语音识别模型很难达到理想的识别效果 。在一次地区性的商务会议中,部分参会人员带有浓厚的方言口音。这时,可以利用 FunASR 的方言识别模型,如针对粤语、四川话等方言的预训练模型,结合会议中的实际语音数据进行二次训练 。将会议中的方言语音片段提取出来,与对应文本标注一起作为训练数据,对模型进行微调,使其能够更好地适应会议中的方言口音,提高识别准确率 。
背景噪音同样会干扰语音识别。在一个没有专业隔音设备的会议室中,周围环境的噪音,如空调声、室外交通声等,会对语音识别造成很大影响 。可以采用降噪技术来预处理音频,利用 FunASR 内置的降噪算法,如基于深度学习的谱减法降噪算法,对输入的会议音频进行降噪处理 。在识别过程中,也可以结合语音活动检测(VAD)技术,先通过 VAD 模型判断音频中的有效语音部分,将噪音较多的静音部分过滤掉,再将有效语音送入语音识别模型进行处理 ,这样能有效提高在嘈杂环境下的语音识别准确率,得到更准确的会议文字记录 。
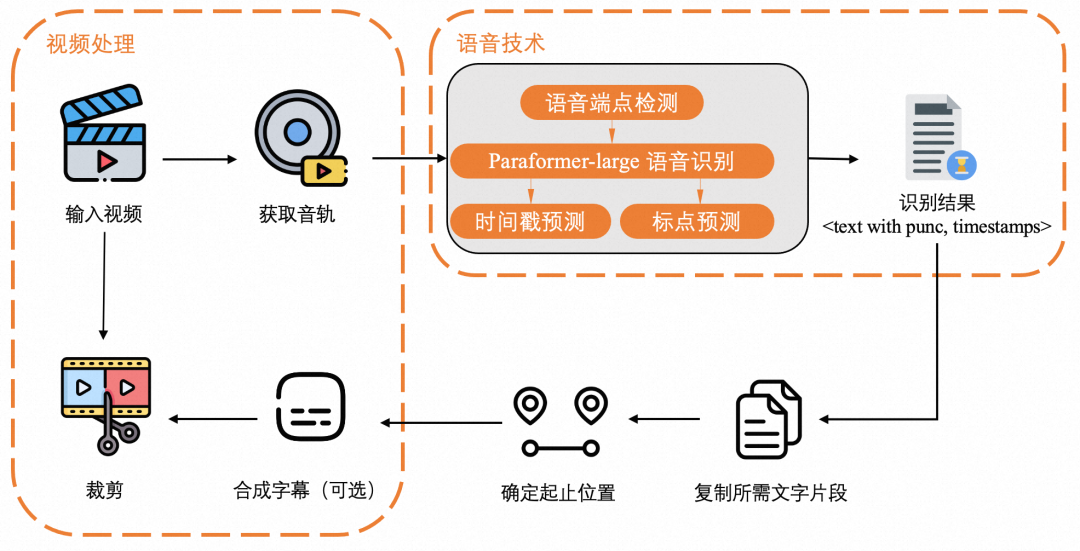
3.3 视频字幕生成案例
借助 FunASR 为视频自动添加字幕,首先需要进行视频音频提取。以常见的 MP4 格式视频为例,可以使用 FFmpeg 工具来提取音频 。在命令行中输入 “ffmpeg -i video.mp4 -vn -acodec pcm_s16le -ar 16000 -ac 1 audio.wav”,这条命令将从名为 “video.mp4” 的视频文件中提取音频,并将其转换为采样率为 16kHz、单声道的 WAV 格式音频文件 “audio.wav” ,这种格式的音频符合 FunASR 的输入要求。
提取音频后,就可以使用 FunASR 进行语音识别。将提取的音频文件 “audio.wav” 输入到 FunASR 中,选择合适的语音识别模型,如 Paraformer - zh 模型,它能够对音频中的语音内容进行准确识别 。识别完成后,会得到一个包含时间戳和识别文本的结果文件 。假设识别结果中一段文本为 “大家好,今天我们来讨论一下项目进展”,对应的时间戳为从第 5 秒开始,到第 10 秒结束 。
接下来的关键环节是将识别结果与视频同步,生成字幕文件。通常采用 SRT 字幕格式,这是一种广泛应用的字幕格式,许多视频编辑软件都支持 。可以编写 Python 脚本,利用第三方库,如 pysrt,将 FunASR 的识别结果转换为 SRT 格式 。在脚本中,读取识别结果文件,按照 SRT 格式的要求,将时间戳和识别文本进行格式化处理 。将时间戳从秒转换为 SRT 格式所需的 “HH:MM:SS,mmm” 格式,即 00:00:05,000 到 00:00:10,000 ,然后将格式化后的时间戳和文本写入 SRT 文件中 。最后,使用视频编辑软件,如 Adobe Premiere Pro,将生成的 SRT 字幕文件导入到视频项目中,调整字幕的字体、大小、位置等样式,使其与视频画面完美融合 ,完成视频字幕的自动添加 。

3.4 经典代码案例与逐行解读
-
一句话中文离线识别(最小可运行 Demo)
from funasr import AutoModel
import torchmodel = AutoModel(model="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",vad_model="fsmn-vad",punc_model="ct-punc",device="cuda" if torch.cuda.is_available() else "cpu"
)
result = model.inference("test.wav")
print(result[0]["text"])解读
-
三行代码完成“语音→带标点文本”全流程;
-
AutoModel 自动下载模型到
~/.cache/modelscope,首次约 1.3 GB; -
vad_model 先剪掉静音,减少 30 % 以上计算量;
-
返回列表第 0 项的
text即为最终汉字串。
2.实时麦克风流式识别(低延迟车载/家居助手)
import pyaudio, torch, threading, queue
from funasr import AutoModelmodel = AutoModel(model="damo/speech_paraformer-zh-streaming",vad_model="fsmn-vad",punc_model="ct-punc",device="cuda" if torch.cuda.is_available() else "cpu"
)q = queue.Queue()
def mic_callback(in_data, frame_count, time_info, status):q.put(in_data)return (None, pyaudio.paContinue)stream = pyaudio.PyAudio().open(format=pyaudio.paInt16, channels=1, rate=16000,input=True, frames_per_buffer=1600,stream_callback=mic_callback
)
stream.start_stream()while True:chunk = q.get()if chunk:seg = model.generate(chunk)[0]["text"]if seg: print("实时:", seg)解读
-
采用
paraformer-zh-streaming流式模型,chunk 级输出,延迟 < 300 ms; -
VAD 内嵌,静默 600 ms 自动断句,避免无效调用;
-
1600 样本/帧 ≈ 100 ms,与 16 kHz 对齐,CPU 占用 < 15 %(i5-10400)。
3.批量视频字幕生成(全自动 SRT)
import os, pysrt, ffmpeg
from funasr import AutoModeldef video2srt(video_path):wav = video_path.replace(".mp4", ".wav")ffmpeg.input(video_path).output(wav, ar=16000, ac=1).run(quiet=True)model = AutoModel(model="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",punc_model="ct-punc")res = model.inference(wav)[0]subs = pysrt.SubRipFile()for line in res["sentence_info"]:start = pysrt.SubRipTime.from_seconds(line["start"])end = pysrt.SubRipTime.from_seconds(line["end"])subs.append(pysrt.SubRipItem(index=len(subs)+1, start=start, end=end, text=line["text"]))srt_path = video_path.replace(".mp4", ".srt")subs.save(srt_path)return srt_pathprint("生成字幕:", video2srt("demo.mp4"))解读
-
一行 FFmpeg 完成音轨提取与重采样;
-
sentence_info自带时间戳,精度 10 ms,无需强制对齐; -
直接写 SRT,Premiere、B 站、抖音均可一键导入。
四、技术实现细节
4.1 开发环境搭建
- Python 环境准备:FunASR 依赖 Python 3.6 及以上版本。若尚未安装 Python,可从 Python 官方网站(https://www.python.org/downloads/ )下载对应操作系统的安装包进行安装 。若已安装 Python,可在命令行输入 “python --version” 来检查版本是否符合要求 。推荐看我之前的文章,有详细的安装步骤:Python+Pycharm详细安装教程(大妈看了都会)
下面给出 2025 年 9 月实测可用的「零-Docker」纯 Python 方案,从 0 到跑通一句话识别,步骤最少、依赖最轻。
(如后续需要生产级高并发,再考虑用官方 Docker 镜像或 Runtime-SDK即可)
1.环境准备
# 1) 创建 Py≥3.8 的虚拟环境
conda create -n funasr python=3.9 -y
conda activate funasr# 2) 一次性安装核心依赖(国内镜像提速)
pip install -U funasr modelscope torch torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple2.一分钟验证(自动下载模型 → 识别 → 带标点输出)
新建 test.py,复制即可运行;首次会自动把模型缓存到 ~/.cache/modelscope/(约 1.3 GB)。
from funasr import AutoModelmodel = AutoModel(model="paraformer-zh", # 中文大模型vad_model="fsmn-vad", # 语音活动检测punc_model="ct-punc" # 标点恢复
)wav = input("请输入 wav 路径:").strip()
result = model.generate(wav, batch_size_s=300)
print("识别结果:", result[0]["text"])3.运行示例
$ python test.py
请输入 wav 路径:./demo.wav
识别结果: 今天天气真不错,我们一起去公园吧。4.可选:流式实时识别(延迟 < 300 ms)
from funasr import AutoModel
import soundfile as sf, numpy as npmodel = AutoModel(model="paraformer-zh-streaming")
speech, sr = sf.read("test.wav") # 16 kHz 单声道
chunk_stride = 9600 # 0.6 s
cache = {}
for i in range(0, len(speech), chunk_stride):chunk = speech[i:i+chunk_stride]is_final = (i+chunk_stride) >= len(speech)r = model.generate(chunk, cache=cache, is_final=is_final)if r: print("实时:", r[0]["text"])5.常见问题速查
-
缺 FFmpeg →
conda install ffmpeg -
下载慢 →
export MODELSCOPE_CACHE=/your/ssd/path换高速盘 -
显存不足 →
device="cpu"或在generate()里把batch_size_s调小 -
识别错字 → 在
generate()中加hotword="阿里 达摩院 20\n新冠 10"(词+权重)
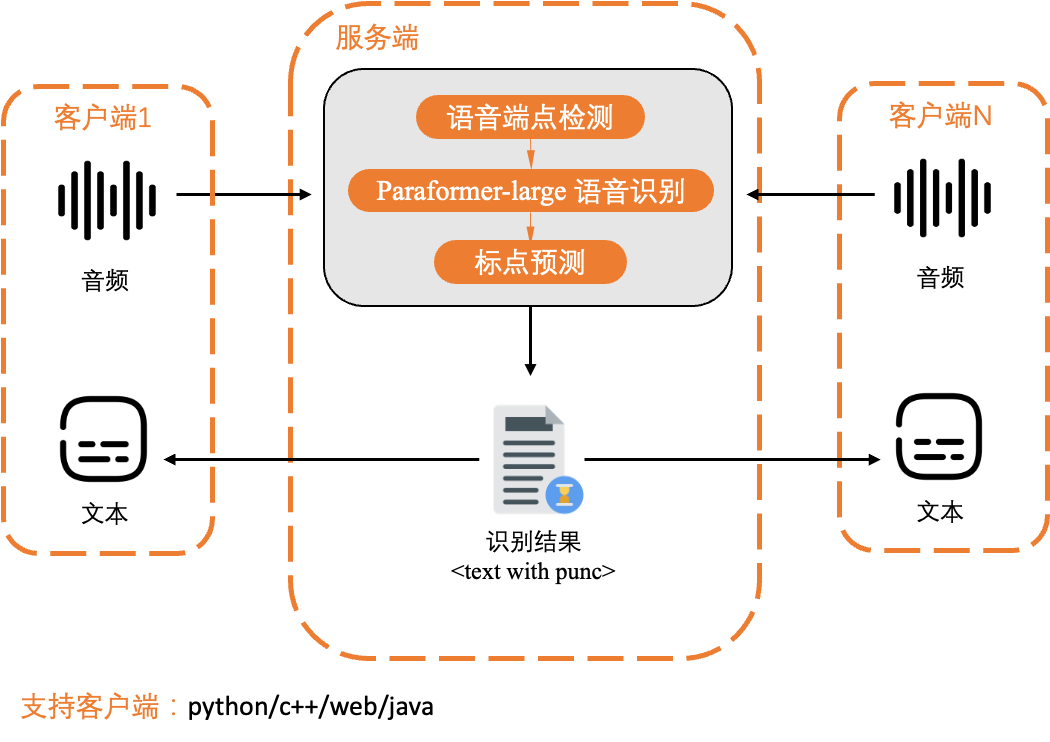
6.一键上线(生产环境)
若需要 HTTP/WebSocket 服务,执行官方脚本 30 秒完成:
wget https://raw.githubusercontent.com/alibaba-damo-academy/FunASR/main/runtime/deploy_tools/funasr-runtime-deploy-offline-cpu-zh.sh
sudo bash funasr-runtime-deploy-offline-cpu-zh.sh install
# 服务默认端口 10095,支持 Python/Go/Java/C++ 客户端[^2^][^6^]至此,本地 FunASR 搭建完毕,可继续按场景微调或容器化扩容。
4.2 模型调用与参数设置
下面以 Python 代码示例,展示如何调用 FunASR 的预训练模型进行语音识别:
from funasr import AutoModel# 加载模型,这里使用中文Paraformer模型model = AutoModel(model="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",vad_model="fsmn-vad",punc_model="ct-punc",disable_update=True,device="cuda:0" if torch.cuda.is_available() else "cpu")# 进行语音识别,假设音频文件为test.wavresult = model.inference(input="test.wav")print("识别结果:", result[0]["text"])在上述代码中:
- model 参数:指定要使用的语音识别模型,这里选择了适用于中文的 Paraformer 大模型,其在大规模数据上进行了预训练,对常见的中文语音场景有较好的识别能力 。
- vad_model 参数:设置语音活动检测模型为 fsmn - vad,该模型能够快速准确地检测语音片段的起止,过滤掉静音部分,提高识别效率 。
- punc_model 参数:指定标点恢复模型为 ct - punc,在语音识别完成后,它会自动为识别结果添加标点符号,增强文本的可读性 。
- disable_update 参数:设置为 True 表示禁止模型自动更新,避免在运行过程中因模型更新导致的兼容性问题 。
- device 参数:根据设备是否支持 CUDA 来选择使用 GPU(“cuda:0”)还是 CPU(“cpu”)进行推理。使用 GPU 能显著加速模型推理过程,提高识别速度 ,但需要确保系统已正确安装 CUDA 驱动和相关依赖 。若在设置 device 参数时遇到问题,如提示找不到 CUDA 设备,可检查 CUDA 驱动是否安装正确,以及 PyTorch 是否正确配置了 CUDA 支持 。
4.3 常见问题与解决方案
- 识别准确率低:
-
- 问题原因:模型不匹配,若使用通用模型处理特定领域的语音数据,可能因缺乏领域知识而导致准确率下降 ;数据质量不佳,如音频有噪音、失真,或文本标注错误,会干扰模型学习 ;模型未微调,未针对特定数据集对预训练模型进行微调,模型难以适应数据特点 。
-
- 解决方案:选择合适的模型,针对不同应用场景和语言,选用专门优化的模型 。如处理医学领域语音,使用医学专用语音识别模型;改善数据质量,对音频进行降噪、去失真处理,人工检查和修正文本标注;进行模型微调,利用自己的数据集对预训练模型进行微调,使其适应数据特征,提高识别准确率 。
- 运行速度慢:
-
- 问题原因:硬件资源不足,在 CPU 性能较弱或内存不足的设备上运行,会影响模型推理速度 ;模型参数设置不合理,如批处理大小设置过大,超出硬件处理能力,会导致运行卡顿 。
-
- 解决方案:升级硬件,有条件时,使用 GPU 加速模型推理,或增加内存、更换高性能 CPU ;优化参数设置,根据硬件资源调整模型参数,如减小批处理大小,提高运行速度 。
- 模型下载失败:
-
- 问题原因:网络连接不稳定,网络波动、中断会导致下载过程失败 ;本地缓存问题,首次下载中断可能使缓存文件损坏,影响后续下载 。
-
- 解决方案:检查网络连接,确保网络稳定,可尝试切换网络或重启网络设备 ;清除模型缓存,删除本地缓存目录(如 “~/.cache/modelscope”)下的相关文件,重新下载模型 。
五、总结与展望

5.1 项目成果回顾
在智能语音助手搭建中,借助 FunASR,开发者能够快速构建起响应灵敏、识别准确的语音交互系统 。像一些智能家居语音助手项目,通过合理选用 Paraformer - zh 模型和 Paraformer - zh - streaming 模型,实现了对各类家居控制指令的精准识别,让用户可以通过语音轻松控制家电设备,为用户带来了便捷、高效的智能家居体验 。在会议语音转文字实践中,尽管面临多人发言、口音差异和背景噪音等挑战,但通过利用 FunASR 的说话人自适应技术、方言识别模型以及降噪和语音活动检测技术,有效提高了语音识别准确率,为会议记录提供了准确、完整的文字资料,大大节省了人力记录的时间和精力 。在视频字幕生成案例里,结合 FunASR 与 FFmpeg、pysrt 等工具,实现了视频音频提取、语音识别和字幕生成的自动化流程,为视频创作者节省了大量手动添加字幕的时间,提高了视频制作效率,也为观众提供了更好的观看体验 。
5.2 未来发展趋势探讨

未来,FunASR 有望与更多先进技术实现深度融合 。与自然语言处理技术的融合将更加紧密,使语音识别不仅停留在语音到文本的转换,还能实现对文本的语义理解和智能交互 。在智能客服场景中,当用户与客服进行语音交流时,FunASR 准确识别语音后,结合自然语言处理技术,客服系统能快速理解用户意图,提供更精准、智能的回答 。与计算机视觉技术融合,在视频会议场景中,不仅能识别语音,还能通过分析参会人员的面部表情、肢体动作等视觉信息,实现更全面的会议分析和记录 。
在模型性能提升方面,随着硬件技术的不断发展,如 GPU 性能的持续提升和新的计算架构的出现,FunASR 的模型推理速度将进一步加快 。同时,研究人员也在不断探索新的模型架构和训练算法,以降低模型的错误率,提高识别准确率 。可能会出现更高效的神经网络架构,能够在更少的计算资源下实现更高的识别精度 。在训练算法上,自适应学习率调整、更有效的正则化方法等技术的应用,将使模型在训练过程中更快收敛,并且具有更好的泛化能力 。
在应用领域拓展上,FunASR 将在更多新兴领域发挥作用 。在医疗领域,辅助医生进行语音病历录入,提高病历记录的效率和准确性 ;在教育领域,用于智能教学辅助系统,实现语音互动教学、作业批改等功能 ;在金融领域,用于身份验证、交易指令识别等场景,提升金融服务的安全性和便捷性 。随着技术的不断进步和应用的不断拓展,FunASR 将在更多领域为人们的生活和工作带来更多便利和创新 。

15 个关键字速查手册
-
Paraformer:非自回归 Transformer,中文 ASR 主力模型,WER 相对下降 20 %。
-
VAD(Voice Activity Detection):fsmn-vad 实时检测语音起止,过滤静音。
-
CT-Transformer:标点恢复专用微型模型,< 10 MB,延迟 < 5 ms。
-
ModelScope:阿里模型开源社区,FunASR 预训练权重托管地。
-
AutoModel:FunASR 统一入口,自动下载、缓存、版本管理。
-
流式/Streaming:chunk 级输出,延迟 < 300 ms,适合实时交互。
-
说话人分离:SD 模型将多人混合语音按身份切片,支持 2-8 人场景。
-
微调/Fine-tune:用 1-10 h 领域数据继续训练,领域词错误率下降 30-50 %。
-
PyTorch Backend:底层依赖 torch&torchaudio,GPU 加速需 CUDA 11.7+。
-
采样率:仅支持 16 kHz 单声道,输入前需 FFmpeg 统一转换。
-
降噪:内置 spectral-subtraction,对 15 dB 以下非稳态噪声有效。
-
热词增强:在
inference()传入hotwords=["新冠","元宇宙"],提升专有名词识别。 -
batch_size:实时场景建议 1,离线文件可设 8-16,平衡显存与吞吐。
-
缓存路径:
~/.cache/modelscope,下载失败可rm -rf后重试。 -
部署模式:支持 pip 安装、Docker 镜像、ONNX 导出与 C++ 推理,边缘端 200 MB 即可运行。

🔥博主还写了本文相关文章 :欢迎订阅《数字人》专栏,一起交流学习,欢迎指出不足之处:
一、基础篇
1、数字人:从科幻走向现实的未来(1/10)
2、数字人技术的核心:AI与动作捕捉的双引擎驱动(2/10)
3、数字人虚拟偶像“C位出道”:数字浪潮下的崛起与财富密码(3/10)
4、数字人:打破次元壁,从娱乐舞台迈向教育新课堂(4/10)
5、数字人:开启医疗领域的智慧变革新时代(5/10)
6、AI数字人:品牌营销的新宠与增长密码(6/10)
7、AI数字人:元宇宙舞台上的闪耀新星(7/10)
8、AI数字人:繁荣背后的伦理困境与法律迷局(8/10)
9、AI数字人:未来职业的重塑(9/10)
10、AI数字人:人类身份与意识的终极思考(10/10)
二、进阶篇
1、解锁WebRTC在数字人领域的无限潜能
2、WebRTC开启实时通信新时代
3、FunASR:开启语音识别新世界的开源宝藏
4、FunASR 点亮数字人:实战之旅与技术突破
5、FunASR开源项目实战:解锁语音识别新姿势